Что такое rune в Go и как с ними работать
Основная сложность работы с текстом заключается в том, что строки в Go представляют собой последовательности байтов в кодировке UTF-8, а не символов в привычном понимании. Это означает, что один символ может занимать от одного до четырех байтов — и здесь начинаются проблемы. Попробуйте подсчитать длину строки с эмодзи или китайскими иероглифами через функцию len(), и вы получите количество байтов, а не символов.

Именно для решения подобных задач в Go существует тип данных rune — специальная конструкция для работы с Unicode-символами. В этой статье мы разберем, что представляют собой руны, чем они отличаются от строк, и как правильно использовать их для обработки международного текста. Понимание этих концепций критически важно для создания приложений, которые корректно работают с текстом на любых языках мира.
- Что такое rune в Go
- Отличие rune от string
- Преобразования строк и рун в Go
- Итерация по символам Unicode в Go
- Операции с рунами
- Частые ошибки при работе с Unicode в Go
- Полезные пакеты и функции для работы с рунами
- Практические задачи с использованием рун
- Заключение
- Рекомендуем посмотреть курсы по golang разработке
Что такое rune в Go
В языке программирования Go тип rune представляет собой псевдоним для int32 — 32-битного целого числа, которое хранит код символа Unicode. По сути, руна — это не просто символ в привычном понимании, а числовое представление конкретной позиции в огромной таблице Unicode, содержащей более миллиона различных знаков.
Unicode был создан как универстандарт для представления текста практически на всех языках мира. Если ASCII ограничивался 128 символами (в основном латинскими буквами, цифрами и базовой пунктуацией), то Unicode охватывает символы китайского, арабского, русского языков, математические знаки, эмодзи и даже древние письменности. Каждому знаку присваивается уникальный номер — code point, который и хранится в руне.
Скриншот Unicode таблицы с символами. На скрине видно, что каждый символ имеет уникальный код — это поможет визуально понять концепцию code point.
Рассмотрим конкретный пример: ‘A’ имеет Unicode code point U+0041 (десятичное значение 65), китайский иероглиф ‘世’ — U+4E16 (20,022), а эмодзи ‘🚀’ — U+1F680 (128,640). Все эти значения помещаются в 32-битное число, что делает rune достаточно емким для представления любого символа Unicode.
Важно понимать, что руны решают фундаментальную проблему: в UTF-8 кодировке один знак может занимать от одного до четырех байтов. ASCII-символы занимают один байт, знаки кириллицы — два байта, многие азиатские — три байта, а некоторые эмодзи — четыре. Руны абстрагируют нас от этих деталей кодировки, позволяя работать с символами как с логическими единицами.
Отличие rune от string
Понимание различий между строками и рунами в Go — ключевой момент для корректной работы с текстом. Строка (string) в Go представляет собой неизменяемую последовательность байтов, закодированную в UTF-8. Руны (rune) же являются отдельными Unicode code points — логическими знаками, независимо от их байтового представления.
Рассмотрим практический пример, демонстрирующий эту разницу:
s := "Hello, 世界" fmt.Println(len(s)) // Выводит: 13 (байтов) fmt.Println(len([]rune(s))) // Выводит: 9 (символов)
Здесь мы видим, что строка содержит 13 байтов, но только 9 символов. Китайские иероглифы ‘世’ и ‘界’ занимают по три байта каждый в UTF-8, в то время как латинские символы — по одному байту.
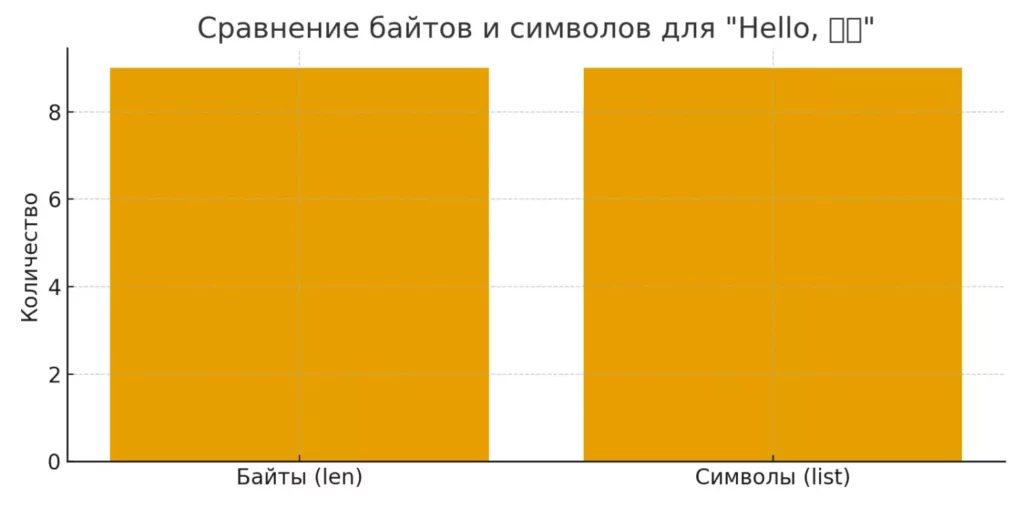
Диаграмма показывает разницу между количеством байтов и символов в строке «Hello, 世界». Хорошо видно, что длина строки в байтах больше, чем количество Unicode-символов.
Ключевые отличия можно сформулировать следующим образом:
- Представление данных: строка хранит байты, руна — Unicode code point.
- Размер элемента: байт в строке может быть частью знака, руна всегда представляет целый символ.
- Подсчет длины: len(string) возвращает количество байтов, len([]rune(string)) — количество знаков.
- Индексация: обращение к строке по индексу может дать байт посреди многобайтового символа.
- Итерация: цикл по строке через индексы может «разорвать» многобайтовые знаки.
Это различие становится критически важным при работе с международным текстом, где неправильное понимание может привести к искажению данных или некорректному поведению программы.
Преобразования строк и рун в Go
Преобразование между строками и рунами — базовая операция при работе с Unicode-текстом в Go. Язык предоставляет простые и понятные механизмы для таких преобразований, но важно понимать особенности каждого подхода.
Преобразование строки в срез рун выполняется через явное приведение типа:
s := "Привет, мир! 🌍" runes := []rune(s) fmt.Println(len(runes)) // Количество символов
Обратное преобразование — из среза рун в строку — работает аналогично:
runes := []rune{'П', 'р', 'и', 'в', 'е', 'т'}
s := string(runes)
fmt.Println(s) // "Привет"
Для получения байтового представления строки используется преобразование в []byte:
s := "Hello" bytes := []byte(s) backToString := string(bytes)
Здесь стоит обратить внимание на важное ограничение: прямое преобразование между []byte и []rune невозможно. Это логично, поскольку байты и руны представляют данные на разных уровнях абстракции. Если нужно получить руны из байтов, сначала преобразуйте байты в строку, а затем строку в руны:
bytes := []byte{0xD0, 0x9F, 0xD1, 0x80} // "Пр" в UTF-8
s := string(bytes)
runes := []rune(s)
При преобразованиях Go автоматически обрабатывает кодировку UTF-8, обеспечивая корректность работы с многобайтовыми знаками. Однако стоит помнить, что каждое преобразование создает новый объект в памяти, что может быть важно при работе с большими объемами текста.
Итерация по символам Unicode в Go
Правильная итерация по Unicode-символам — одна из наиболее частых задач при работе с международным текстом. Go предоставляет несколько подходов, каждый из которых имеет свои особенности и области применения.
Итерация через срез []rune
Самый прямолинейный способ — преобразовать строку в срез рун и итерироваться по индексам:
s := "Go язык 🚀"
runes := []rune(s)
for i := 0; i < len(runes); i++ {
fmt.Printf("Позиция %d: %c (код: %d)\n", i, runes[i], runes[i])
}
Этот подход дает нам полный контроль над процессом: мы получаем как позицию знака в логической последовательности, так и его Unicode code point. Метод особенно полезен, когда требуется произвольный доступ к символам или обратная итерация.
Итерация через for range по строке
Go предоставляет более элегантный способ — использование конструкции for range непосредственно со строкой:
s := "Go язык 🚀"
for i, r := range s {
fmt.Printf("Байтовая позиция %d: %c (код: %d)\n", i, r, r)
}
Важная особенность: переменная i содержит байтовую позицию начала символа в строке, а не логический индекс символа. Это означает, что для многобайтовых символов позиции будут неравномерными (0, 1, 2, 4, 6, 7, …).
Конструкция for range автоматически декодирует UTF-8 последовательности и корректно обрабатывает знаки любой сложности — от простых ASCII до сложных эмодзи, состоящих из нескольких Unicode code points. Это делает данный подход предпочтительным для большинства задач обработки текста, поскольку он сочетает простоту использования с высокой производительностью.
Операции с рунами
Руны в Go ведут себя как обычные целые числа, что открывает широкие возможности для различных операций с символами. Поскольку руна — это псевдоним для int32, мы можем применять к ним все арифметические и логические операторы.
Сравнение рун работает на основе их числовых значений в таблице Unicode:
var r1 rune = 'a' var r2 rune = 'b' var r3 rune = 'А' // Кириллическая А fmt.Println(r1 < r2) // true (97 < 98) fmt.Println(r1 < r3) // true (97 < 1040)
Арифметические операции позволяют выполнять интересные манипуляции с символами:
| Операция | Пример | Результат | Описание |
|---|---|---|---|
| Сложение | ‘a’ + 1 | ‘b’ | Сдвиг к следующему знаку |
| Вычитание | ‘Z’ — ‘A’ | 25 | Расстояние между символами |
| Сравнение | ‘a’ == 97 | true | Проверка кода знака |
| Диапазон | ‘0’ <= r <= ‘9’ | bool | Проверка принадлежности |
Практическое применение операций с рунами часто встречается в задачах обработки текста:
func toUppercase(r rune) rune {
if 'a' <= r && r <= 'z' {
return r - 'a' + 'A'
}
return r
}
func isDigit(r rune) bool {
return '0' <= r && r <= '9'
}
При работе с условными конструкциями руны могут использоваться так же естественно, как и числа. Это особенно удобно для создания парсеров, валидаторов или систем классификации символов. Однако стоит помнить, что Unicode содержит множество диапазонов для разных языков, и простые арифметические операции работают корректно только в пределах одного алфавита.
Частые ошибки при работе с Unicode в Go
Работа с Unicode в Go часто становится источником трудноуловимых ошибок, особенно для разработчиков, привыкших к ASCII-окружению. Рассмотрим наиболее распространенные проблемы и способы их решения.
Ошибка подсчета длины строки через len()
// ❌ Неправильно s := "café" fmt.Println(len(s)) // 5 байтов, но 4 символа // ✅ Правильно fmt.Println(utf8.RuneCountInString(s)) // 4 символа
Проблемы с индексацией многобайтовых символов
// ❌ Может привести к некорректным байтам
s := "привет"
fmt.Printf("%c\n", s[1]) // Может вывести искаженный символ
// ✅ Правильная работа с символами
runes := []rune(s)
fmt.Printf("%c\n", runes[1]) // Корректный вывод символа
Некорректное обрезание строк
// ❌ Может разорвать многобайтовый символ
s := "мир🌍"
truncated := s[:3] // Обрезает посреди символа
// ✅ Безопасное обрезание
runes := []rune(s)
if len(runes) > 3 {
truncated := string(runes[:3])
}
Особую сложность представляют графем-кластеры — знаки, состоящие из нескольких Unicode code points. Например, эмодзи с модификаторами цвета кожи или символы с диакритическими знаками могут состоять из нескольких рун, но визуально представлять один знак:
s := "👨👩👧👦" // Семья (несколько code points) fmt.Println(len([]rune(s))) // 7 рун, но 1 визуальный символ
Для работы с графем-кластерами требуются специализированные библиотеки, поскольку стандартные средства Go оперируют на уровне отдельных code points, а не визуальных символов.
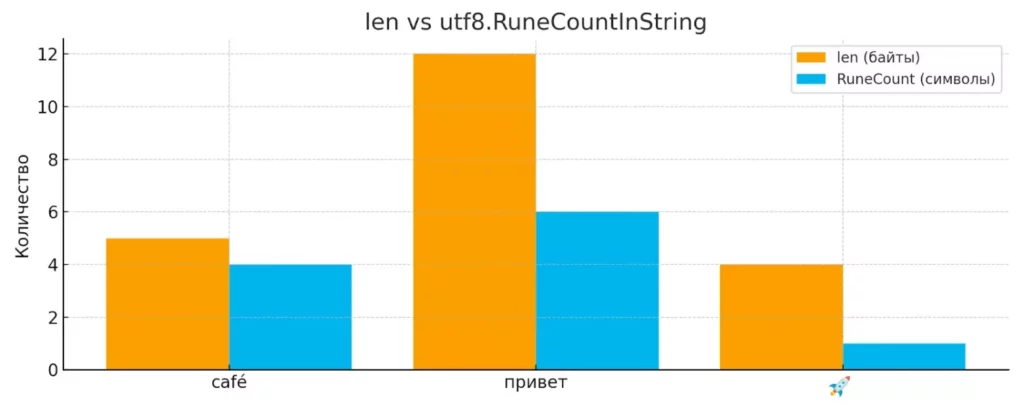
Сравнение результатов функций len() и utf8.RuneCountInString() для строк «café», «привет» и «🚀». Диаграмма подчёркивает типичную ошибку — путаницу между байтами и реальными символами.
Полезные пакеты и функции для работы с рунами
Стандартная библиотека Go предоставляет мощный инструментарий для работы с Unicode-текстом. Понимание возможностей основных пакетов поможет избежать написания собственных велосипедов и обеспечит корректную обработку международного текста.
Пакет unicode/utf8 содержит низкоуровневые функции для работы с UTF-8 кодировкой:
import "unicode/utf8"
s := "Go разработка 🔥"
fmt.Println(utf8.RuneCountInString(s)) // Количество символов
fmt.Println(utf8.ValidString(s)) // Проверка корректности UTF-8
// Декодирование первого символа
r, size := utf8.DecodeRuneInString(s)
fmt.Printf("Первый символ: %c, размер: %d байт\n", r, size)
Пакет unicode предоставляет функции для классификации символов:
import "unicode"
for _, r := range "Hello, мир! 123 🌍" {
switch {
case unicode.IsLetter(r):
fmt.Printf("%c - буква\n", r)
case unicode.IsDigit(r):
fmt.Printf("%c - цифра\n", r)
case unicode.IsSpace(r):
fmt.Printf("пробельный символ\n")
}
}
Пакет strings содержит высокоуровневые функции, которые корректно работают с Unicode:
import "strings" s := "ПРИВЕТ, МИР!" fmt.Println(strings.ToLower(s)) // Корректное преобразование регистра fmt.Println(strings.Fields(s)) // Разделение по пробельным символам
Когда выбирать []rune, а когда функции стандартной библиотеки?
Используйте преобразование в []rune, когда требуется произвольный доступ к символам, реверс строки или сложные манипуляции с позициями. Для простых операций (подсчет символов, проверка свойств, базовые преобразования) предпочтительнее функции стандартной библиотеки — они оптимизированы и не создают промежуточных срезов в памяти.
Практические задачи с использованием рун
Работа с рунами становится особенно актуальной при решении реальных задач обработки текста. Рассмотрим несколько типичных сценариев, которые демонстрируют практическое применение концепций Unicode в Go.
Подсчет количества символов в строке
func countSymbols(s string) int {
return len([]rune(s))
}
// Альтернативный способ без создания среза
func countSymbolsEfficient(s string) int {
return utf8.RuneCountInString(s)
}
Реверс строки с поддержкой Unicode
func reverseString(s string) string {
runes := []rune(s)
for i, j := 0, len(runes)-1; i < j; i, j = i+1, j-1 {
runes[i], runes[j] = runes[j], runes[i]
}
return string(runes)
}
// Пример: reverseString("Привет! 🚀") → "🚀 !тевирП"
Фильтрация текста по типу символов
func keepLettersAndDigits(s string) string {
var result []rune
for _, r := range s {
if unicode.IsLetter(r) || unicode.IsDigit(r) {
result = append(result, r)
}
}
return string(result)
}
func removeAccents(s string) string {
var result []rune
for _, r := range s {
// Нормализация символов с диакритикой
if unicode.Is(unicode.Mn, r) { // Nonspacing marks
continue
}
result = append(result, r)
}
return string(result)
}
Безопасное обрезание строки
func truncateString(s string, maxLen int) string {
runes := []rune(s)
if len(runes) <= maxLen {
return s
}
return string(runes[:maxLen]) + "..."
}
Эти примеры демонстрируют ключевые принципы работы с Unicode-текстом: преобразование в руны для символьных операций, использование пакета unicode для классификации символов, и осторожность при работе с индексами. В реальных проектах подобные функции часто становятся основой для более сложных систем обработки текста, валидации пользовательского ввода или подготовки данных для поисковых индексов.
Заключение
Понимание различий между строками и рунами в Go — это не просто теоретическое знание, а практическая необходимость для создания надежных приложений. Мы рассмотрели, как строки представляют байтовые последовательности в UTF-8, в то время как руны работают с логическими символами Unicode, абстрагируясь от деталей кодировки. Подведем итоги:
- Строки в Go хранят байты. Это создаёт трудности при работе с многобайтовыми символами.
- Rune — это Unicode code point. Он обеспечивает корректное представление любого символа.
- Различие string и rune важно. Оно влияет на подсчёт длины, индексацию и итерацию.
- Преобразования между строками, байтами и рунами. Они позволяют безопасно обрабатывать текст.
- Итерация через for range и []rune. Это два основных способа корректного обхода символов.
- Полезные пакеты Go. unicode, utf8 и strings помогают работать с текстом без ошибок.
- Частые ошибки. Неверный подсчёт длины и обрезание строк приводят к искажениям данных.
Если вы только начинаете осваивать язык Go, рекомендуем обратить внимание на подборку курсов по Go-разработке. В них есть и теоретическая база, и практические задания, которые помогут закрепить работу с типами данных, строками и рунами.
Рекомендуем посмотреть курсы по golang разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Искусство написания сервиса на Go
|
GOLANG NINJA
14 отзывов
|
Цена
38 565 ₽
92 096 ₽
|
|
Длительность
5 месяцев
|
Старт
в любое время
|
Подробнее |
|
Go-разработчик
|
Нетология
46 отзывов
|
Цена
87 900 ₽
195 360 ₽
с промокодом kursy-online
|
От
4 070 ₽/мес
0% на 36 месяцев
8 041 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
2 раз в неделю после 18:00 МСК
|
Подробнее |
|
Искусство работы с ошибками и безмолвной паники в Go
|
GOLANG NINJA
14 отзывов
|
Цена
26 545 ₽
39 620 ₽
|
|
Длительность
9 недель
|
Старт
в любое время
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.