Как работает дерево решений и почему его используют в бизнесе
В эпоху информационного бума и постоянно растущих объемов данных умение принимать взвешенные решения на основе аналитики становится ключевым конкурентным преимуществом. Одним из наиболее эффективных инструментов для структурирования процесса принятия solutions остаются деревья решений — метод, который, несмотря на кажущуюся простоту, продолжает доказывать свою актуальность даже в эпоху нейросетей и глубокого машинного обучения.

Дерево решений представляет собой алгоритм машинного обучения, который позволяет разбить большие массивы данных на управляемые группы и прогнозировать результаты на основе определенных условий. По сути, это графическая модель, визуализирующая процесс принятия solutions в виде древовидной структуры с узлами и ветвями.
Сегодня этот метод находит применение в самых разных сферах: от банковского сектора и медицинской диагностики до промышленного анализа и клиентского сервиса. В этой статье мы рассмотрим принципы работы decision tree, изучим алгоритмы их построения и разберемся, почему, несмотря на появление более сложных моделей искусственного интеллекта, этот инструмент остается востребованным среди аналитиков данных и бизнес-консультантов.
- Что такое дерево решений и как оно работает?
- Где используются?
- Как компании используют деревья решений на практике?
- Алгоритмы построения
- Принципы выбора признаков для разделения
- Как построить?
- Проблемы и ограничения
- Дерево решений vs другие алгоритмы
- Когда лучше использовать деревья решений, а когда – другие методы?
- Итоги и рекомендации
- Рекомендуем посмотреть курсы по разработке на языке C#
Что такое дерево решений и как оно работает?
Определение и ключевые характеристики
Дерево решений — это метод машинного обучения и аналитический инструмент, позволяющий моделировать последовательные решения в виде иерархической структуры. Если говорить простым языком, это своеобразная карта возможных путей принятия solutions, где каждый шаг зависит от результата предыдущего.
Ключевое преимущество данного метода заключается в его интуитивной понятности — decision tree представляет сложные аналитические процессы в виде логической последовательности условий и действий, что делает его доступным даже для специалистов без глубоких познаний в машинном обучении.
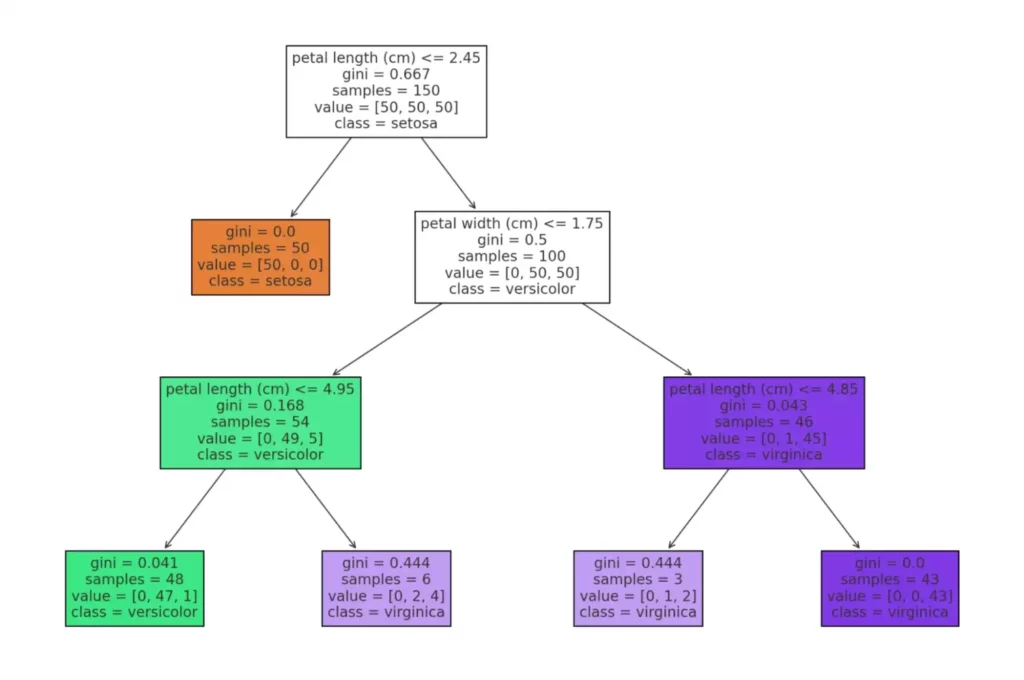
На изображении представлена схема дерева решений, построенного на классическом наборе данных Iris. Визуализация отображает полную структуру модели, начиная с корневого узла, в котором производится первое разбиение на основе признака (например, длины лепестка), и заканчивая листьями — конечными решениями, соответствующими предсказанным классам (виды ирисов: setosa, versicolor, virginica).
Структура
Как следует из названия, структура decision tree напоминает перевернутое дерево, где:
- Корневой узел — начальная точка, содержащая всю обучающую выборку и первое правило разделения данных.
- Внутренние узлы — промежуточные точки принятия solutions, где данные разветвляются на основе определенных условий.
- Листья (или терминальные узлы) — конечные точки, содержащие результат или решение.
- Ветви — связывают узлы, представляя собой возможные исходы проверяемых условий.
[Корневой узел]
/ \
[Условие верно] [Условие неверно]
/ \ / \
[Узел] [Узел] [Узел] [Узел]
/ \ / \ / \ / \
[Лист][Лист][Лист][Лист][Лист][Лист][Лист][Лист]
Как принимаются решения?
Процесс принятия solutions с помощью этого метода строится на последовательной проверке условий в каждом узле. Упрощенно алгоритм работает следующим образом:
- На корневом узле все данные проверяются на соответствие определенному условию (например, «возраст > 30 лет»).
- В зависимости от результата проверки, данные направляются по одной из веток к следующему узлу.
- В каждом последующем узле процесс повторяется с новым условием.
- Процесс продолжается до достижения листа, где получается финальное решение или классификация.
Важно отметить, что для каждого объекта существует только один путь от корня до листа, что обеспечивает однозначность классификации.
Примеры из жизни
Рассмотрим простой пример: банк решает, выдать ли кредит клиенту. Дерево решений для этой задачи может выглядеть так:
- Корневой узел:
Проверяем кредитный рейтинг клиента. Если рейтинг высокий — переходим влево, если низкий — вправо.
- Узел слева:
Проверяем доход клиента. Если высокий — переходим к листу «Одобрить кредит», если средний или низкий — к следующему узлу.
- Дополнительный узел:
Проверяем наличие залога. Если есть залог — «Одобрить кредит с повышенной ставкой», если нет — «Отказать».
- Узел справа:
Проверяем историю предыдущих кредитов. Если положительная — «Одобрить с повышенной ставкой и обязательным залогом», если отрицательная — «Отказать».
Этот пример демонстрирует, как комплексное решение можно разбить на последовательность простых проверок условий, что делает процесс прозрачным и объяснимым — в отличие, например, от нейросетей, которые часто работают как «черный ящик».
Где используются?
Применение в разных сферах
Универсальность и интуитивная понятность decision tree сделали этот метод востребованным в самых разных отраслях. Рассмотрим наиболее значимые области применения:
Бизнес-аналитика и менеджмент
В сфере бизнеса деревья решений помогают структурировать процесс принятия стратегических solutions. Например, при выборе между расширением ассортимента, выходом на новые рынки или модернизацией оборудования, алгоритм позволяет учесть множество параметров: от финансовых показателей до кадровых ресурсов. Это существенно снижает риск принятия необоснованных решений и позволяет оценить потенциальные выгоды различных стратегий.
Финансы и страхование
Финансовый сектор активно использует decision tree для оценки кредитоспособности клиентов, выявления потенциальных случаев мошенничества и определения страховых рисков. Банки применяют этот метод для создания автоматизированных систем скоринга, которые позволяют принимать solutions о выдаче кредита практически мгновенно. Страховые компании с помощью деревьев решений оценивают вероятность наступления страхового случая и рассчитывают оптимальные страховые премии.
Маркетинг и работа с клиентами
В маркетинге decision tree помогают сегментировать клиентскую базу, прогнозировать поведение потребителей и персонализировать предложения. Они позволяют выявить наиболее перспективных клиентов для таргетированных рекламных кампаний и определить, какие клиенты с высокой вероятностью откажутся от услуг компании. На основе этих данных маркетологи разрабатывают программы лояльности и специальные предложения.
Медицина и здравоохранение
В медицинской сфере decision tree применяются для диагностики заболеваний, оценки рисков развития патологий и определения оптимальных методов лечения. Например, при анализе симптомов алгоритм может предложить наиболее вероятные диагнозы и рекомендовать дополнительные обследования для подтверждения. Особенно эффективно применение этого метода при выявлении ранних признаков деменции, сердечно-сосудистых заболеваний и онкологии.
Машинное обучение и искусственный интеллект
В сфере машинного обучения деревья решений служат одним из базовых алгоритмов классификации и регрессии. Они используются как самостоятельно, так и в составе более сложных моделей, таких как случайный лес (Random Forest) или градиентный бустинг (Gradient Boosting). Важно отметить, что даже в эпоху нейросетей decision tree остаются актуальными благодаря своей интерпретируемости — они позволяют понять, почему модель принимает то или иное solutions.
Как компании используют деревья решений на практике?
Рассмотрим несколько реальных примеров применения decision tree в бизнесе:
Банковский сектор
Крупные финансовые организации применяют деревья решений для автоматизации процесса выдачи кредитов. Алгоритм анализирует кредитную историю, доход, возраст, образование и другие параметры клиента, а затем классифицирует его как надежного или рискованного заемщика. Это позволяет минимизировать человеческий фактор в принятии solutions и сократить время обработки заявок с нескольких дней до нескольких минут.
Телекоммуникационные компании
Операторы связи используют decision tree для прогнозирования оттока клиентов. Анализируя данные о длительности пользования услугами, среднем счете, количестве обращений в службу поддержки и других параметрах, алгоритм выявляет клиентов, которые с высокой вероятностью прекратят пользоваться услугами компании в ближайшее время. Это позволяет оперативно предложить таким клиентам специальные условия и удержать их.
Электронная коммерция
Онлайн-ритейлеры применяют деревья решений для оптимизации рекламных кампаний. Анализируя данные о покупательском поведении, алгоритм определяет, какие категории товаров следует рекламировать конкретным группам пользователей. Это значительно повышает эффективность маркетинговых бюджетов и увеличивает конверсию.
В каждом из этих случаев decision tree демонстрируют свою эффективность как инструмент структурирования данных и принятия обоснованных solutions на их основе.
Алгоритмы построения
Основные алгоритмы
В основе работы деревьев решений лежат различные алгоритмы, каждый из которых имеет свои особенности, преимущества и ограничения. Рассмотрим три наиболее распространенных алгоритма:
| Алгоритм | Основные характеристики | Преимущества | Ограничения |
|---|---|---|---|
| ID3 | Основан на концепции информационной энтропии, выбирает атрибуты с наибольшим информационным выигрышем | Простота реализации, высокая скорость работы с небольшими наборами данных | Подвержен переобучению, плохо работает с непрерывными данными, не поддерживает пропущенные значения |
| C4.5 | Усовершенствованная версия ID3, использует коэффициент выигрыша вместо информационного выигрыша | Работает с непрерывными данными, поддерживает пропущенные значения, включает механизм обрезки дерева | Требует больше вычислительных ресурсов, чем ID3, менее эффективен при работе с зашумленными данными |
| CART | Строит бинарные деревья, использует коэффициент Джини для оценки качества разбиения | Хорошо работает как с категориальными, так и с числовыми данными, устойчив к выбросам | Может создавать слишком сложные модели, требует тщательной настройки параметров для предотвращения переобучения |
Важно отметить, что выбор алгоритма зависит от конкретной задачи, характера данных и требований к модели. Нередко аналитики тестируют несколько алгоритмов, чтобы определить, какой из них дает наилучшие результаты в конкретном случае.
Принципы выбора признаков для разделения
Ключевой вопрос при построении decision tree — какой признак следует использовать для разделения данных в каждом узле. Существует несколько подходов к solutions этой задачи:
Информационный выигрыш (Information Gain)
Этот метод, используемый в алгоритмах ID3 и C4.5, основан на концепции энтропии — меры неопределенности в системе. Информационный выигрыш показывает, насколько снизится энтропия после разделения данных по определенному признаку.
Математически информационный выигрыш можно представить формулой:
IG(S, A) = Entropy(S) — Σ (|Sv| / |S|) * Entropy(Sv)
где:
- S — множество примеров
- A — атрибут
- Sv — подмножество S, для которого атрибут A имеет значение v
Алгоритм выбирает атрибут с наибольшим информационным выигрышем, т.е. тот, который максимально снижает неопределенность.
Коэффициент Джини (Gini Index)
Используемый в алгоритме CART, коэффициент Джини измеряет степень «нечистоты» (impurity) набора данных. Низкий коэффициент Джини означает, что большинство элементов принадлежит к одному классу, что указывает на хорошее разделение.
Математически коэффициент Джини рассчитывается как:
Gini(S) = 1 — Σ pi²
где pi — вероятность того, что случайно выбранный элемент из множества S будет принадлежать классу i.
Алгоритм CART выбирает для разделения признак, который обеспечивает наименьший средневзвешенный коэффициент Джини для получаемых подмножеств.
Критерии остановки
Без ограничений алгоритм построения decision tree продолжал бы разделять данные до тех пор, пока каждый лист не содержал бы только элементы одного класса. Однако такое дерево было бы чрезмерно сложным и, вероятно, переобученным. Поэтому необходимы критерии остановки, определяющие, когда процесс построения дерева следует прекратить.
Основные критерии остановки включают:
- Максимальная глубина дерева — ограничение количества уровней от корня до листьев.
- Минимальное количество примеров в узле — остановка разделения, если в узле остается меньше определенного числа примеров.
- Минимальное снижение неопределенности — прекращение разделения, если информационный выигрыш или снижение коэффициента Джини меньше заданного порога.
- Процент примеров одного класса — остановка, если определенный процент примеров в узле (например, 95%) принадлежит к одному классу.
Правильный выбор критериев остановки — это компромисс между точностью модели на обучающих данных и ее способностью к обобщению на новых данных. Слишком строгие критерии могут привести к недообучению, а слишком мягкие — к переобучению модели.
Как построить?
Этапы построения (пошагово)
Создание эффективного дерева решений — это не просто запуск алгоритма на наборе данных, а многоэтапный процесс, требующий внимательного подхода на каждом шаге. Рассмотрим основные этапы построения модели:
- Сбор и подготовка данных
Первый и, возможно, самый важный этап — сбор и анализ данных, которые будут использоваться для обучения модели. На этом этапе аналитики:
- Проводят разведочный анализ данных (EDA)
- Выявляют общие закономерности и аномалии
- Формулируют гипотезы о взаимосвязях между признаками и целевой переменной
Качество данных напрямую влияет на эффективность модели. Поэтому необходимо выполнить предварительную обработку:
- Заполнить пропущенные значения (средними, медианными или другими методами)
- Нормализовать или стандартизировать числовые признаки
- Преобразовать категориальные переменные в числовой формат (например, с помощью one-hot encoding)
- Удалить или скорректировать выбросы и аномалии
- Выбор признаков
Не все доступные признаки одинаково полезны для прогнозирования. На этом этапе определяются наиболее информативные признаки:
- Используются методы оценки важности признаков (feature importance)
- Проводится анализ корреляций между признаками
- Применяются методы отбора признаков (feature selection)
Использование только релевантных признаков не только улучшает производительность модели, но и делает ее более интерпретируемой и устойчивой к переобучению.
- Разбиение на узлы
Это ключевой этап построения tree, на котором происходит непосредственное формирование узлов и связей между ними:
- В каждом узле выбирается оптимальный признак для разделения данных
- Определяется пороговое значение для разделения (для числовых признаков)
- Рекурсивно создаются дочерние узлы для каждого подмножества данных
Процесс построения продолжается до тех пор, пока не будет достигнут один из критериев остановки, описанных в предыдущем разделе.
- Оценка качества модели
После построения tree необходимо оценить его эффективность. Для этого обычно используется отложенная выборка (validation set) или методы кросс-валидации:
- Рассчитываются метрики точности (accuracy, precision, recall, F1-score)
- Строится матрица ошибок (confusion matrix)
- Анализируются типичные ошибки модели
Важно сравнить результаты на обучающей и тестовой выборках. Если модель показывает значительно лучшие результаты на обучающих данных, это может свидетельствовать о переобучении.
- Оптимизация (обрезка)
На заключительном этапе дерево оптимизируется для повышения его обобщающей способности:
- Проводится обрезка (pruning) ветвей, которые вносят минимальный вклад в точность модели
- Настраиваются гиперпараметры (максимальная глубина, минимальное количество примеров в узле и т.д.)
- При необходимости применяются методы регуляризации
Целью оптимизации является создание модели, которая будет достаточно сложной, чтобы уловить существенные закономерности в данных, но при этом достаточно простой, чтобы избежать переобучения.
Пример на Python
Рассмотрим практический пример построения decision tree с использованием библиотеки scikit-learn в Python:
# Импортирование необходимых библиотек
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn import tree
import matplotlib.pyplot as plt
# Загрузка данных (в данном примере используем набор данных о кредитоспособности клиентов)
data = pd.read_csv('credit_data.csv')
# Предобработка данных
# Заполнение пропущенных значений
data['age'].fillna(data['age'].median(), inplace=True)
data['income'].fillna(data['income'].mean(), inplace=True)
# Преобразование категориальных переменных
data = pd.get_dummies(data, columns=['education', 'marital_status'], drop_first=True)
# Разделение на признаки и целевую переменную
X = data.drop('default', axis=1) # Признаки
y = data['default'] # Целевая переменная (1 - дефолт, 0 - нет дефолта)
# Разделение на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Создание и обучение модели
model = DecisionTreeClassifier(
max_depth=5, # Максимальная глубина дерева
min_samples_split=20, # Минимальное количество примеров для разделения узла
min_samples_leaf=10, # Минимальное количество примеров в листе
random_state=42 # Для воспроизводимости результатов
)
model.fit(X_train, y_train)
# Оценка модели
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Точность модели: {accuracy:.2f}")
print("\nОтчет о классификации:")
print(classification_report(y_test, y_pred))
# Визуализация дерева решений
plt.figure(figsize=(20, 10))
tree.plot_tree(model, feature_names=X.columns, class_names=['No Default', 'Default'], filled=True)
plt.savefig('decision_tree.png', dpi=300)
plt.show()
# Анализ важности признаков
feature_importance = pd.DataFrame({
'Feature': X.columns,
'Importance': model.feature_importances_
}).sort_values('Importance', ascending=False)
print("\nВажность признаков:")
print(feature_importance.head(10))
Этот код демонстрирует полный цикл построения модели дерева решений: от загрузки и предобработки данных до оценки качества модели и визуализации результатов. Обратите внимание на настройку гиперпараметров модели, которые помогают контролировать сложность tree и предотвращать переобучение.
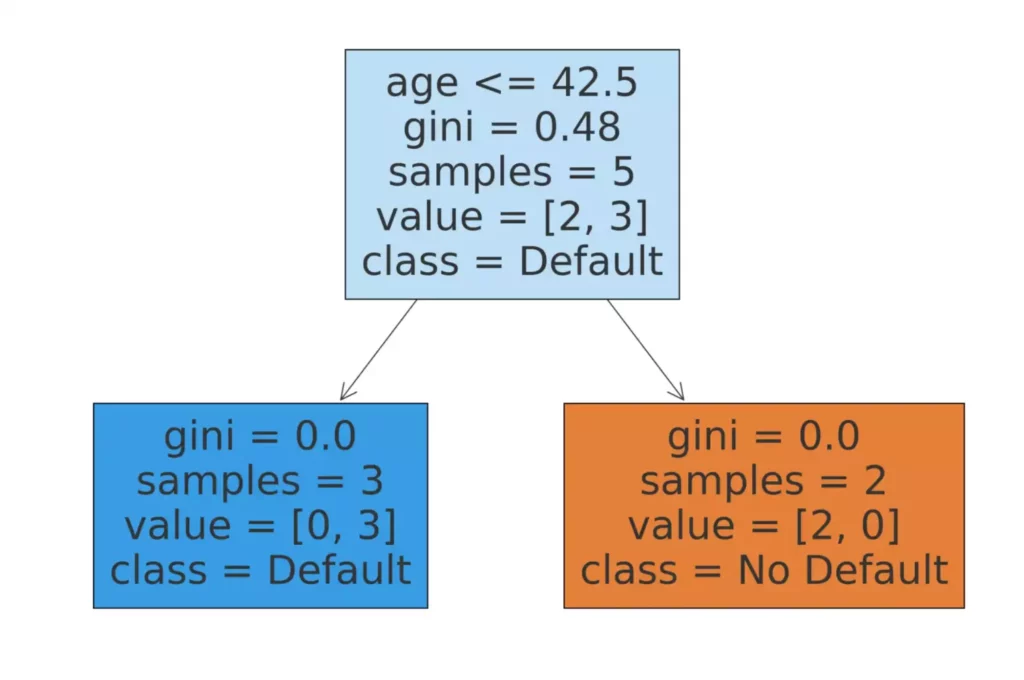
На изображении представлено дерево решений, обученное на наборе данных с признаками клиентов: возраст, доход, наличие залога и история кредитов. Модель принимает решение о возможном дефолте (неплатежеспособности) по комбинации этих факторов.
Визуализация дерева позволяет наглядно увидеть, какие признаки используются для принятия решений и какие пороговые значения применяются в каждом узле. Это делает модель интерпретируемой и понятной даже для непрофессионалов в области машинного обучения.
Анализ важности признаков помогает определить, какие факторы оказывают наибольшее влияние на целевую переменную. Эта информация может быть использована для дальнейшей оптимизации модели или для принятия бизнес-solutions на основе полученных знаний.
Проблемы и ограничения
Переобучение (overfitting)
Одной из наиболее серьезных проблем при работе с деревьями решений является риск переобучения. Это явление возникает, когда модель настолько точно подстраивается под обучающие данные, что теряет способность к обобщению и плохо работает с новыми, ранее не встречавшимися примерами.
Переобучение особенно характерно для decision tree по нескольким причинам:
- Высокая гибкость модели:
Деревья решений способны создавать сложные структуры, точно соответствующие обучающим данным, даже если эти данные содержат шум или случайные флуктуации.
- Неограниченный рост:
Без должных ограничений tree может расти до тех пор, пока каждый лист не будет содержать только примеры одного класса, что приводит к безупречной работе на обучающих данных, но плохой обобщающей способности.
- Чувствительность к небольшим изменениям:
В переобученных моделях даже незначительные изменения в данных могут привести к созданию новых ветвей и значительному изменению результатов.
На практике переобучение проявляется в значительном разрыве между точностью на обучающей и тестовой выборках. Например, модель может демонстрировать точность 99% на обучающих данных, но только 70% — на тестовых.
Чувствительность к данным
Еще одно ограничение decision tree — их высокая чувствительность к составу обучающей выборки. Небольшие изменения в данных могут привести к построению совершенно другого tree, что делает модель нестабильной.
Эта проблема проявляется в следующих аспектах:
- Зависимость от первых разбиений:
Ошибка в выборе признака для разделения на верхних уровнях дерева может привести к каскаду ошибочных solutions на нижних уровнях.
- Чувствительность к выбросам:
Аномальные значения могут существенно исказить структуру tree, особенно если они попадают в малые подмножества данных.
- Проблема смещения данных:
Если распределение данных в обучающей выборке отличается от реального распределения в генеральной совокупности, tree может систематически ошибаться при работе с новыми примерами.
Эти особенности делают деревья решений менее надежными по сравнению с некоторыми другими алгоритмами машинного обучения, особенно при работе с зашумленными или неполными данными.
Способы улучшения модели
Несмотря на указанные ограничения, существует ряд методов, позволяющих повысить эффективность и надежность decision tree:
Обрезка (Pruning)
- Предварительная обрезка (pre-pruning):
Установка критериев остановки роста дерева (максимальная глубина, минимальное количество примеров в узле, минимальный информационный выигрыш).
- Последующая обрезка (post-pruning):
Построение полного tree с последующим удалением ветвей, которые вносят минимальный вклад в точность модели или увеличивают риск переобучения.
- Оптимизация по стоимости сложности (cost-complexity pruning): Последовательное удаление ветвей, начиная с тех, которые дают наименьшее увеличение ошибки в пересчете на сложность модели.
Усложнение данных
- Увеличение объема обучающей выборки:
Чем больше примеров, тем меньше вероятность случайных корреляций и переобучения.
- Аугментация данных:
Создание новых примеров путем незначительного изменения существующих (применимо в основном для задач компьютерного зрения и обработки текста).
- Сглаживание (smoothing):
Модификация вероятностей в листьях для учета ограниченного объема данных.
Ансамблевые методы
- Случайный лес (Random Forest):
Создание множества tree на различных подмножествах данных и признаков с последующим усреднением результатов. Это значительно повышает устойчивость модели и снижает риск переобучения.
- Градиентный бустинг (Gradient Boosting):
Последовательное построение tree, каждое из которых корректирует ошибки предыдущих. Этот метод часто демонстрирует наилучшие результаты в соревнованиях по машинному обучению.
- Бэггинг (Bagging):
Обучение нескольких деревьев на различных подмножествах данных с последующим голосованием.
Применение этих методов позволяет нивелировать недостатки decision tree и создавать более надежные и точные модели. Например, случайный лес сохраняет интерпретируемость отдельных tree, при этом значительно повышая устойчивость модели к шуму в данных и снижая риск переобучения.
Дерево решений vs другие алгоритмы
Сравнение с нейросетями, SVM и случайным лесом
Выбор оптимального алгоритма машинного обучения – задача нетривиальная и требует понимания сильных и слабых сторон каждого метода. Рассмотрим, как decision tree соотносятся с другими популярными алгоритмами:
| Критерий | Дерево решений | Нейронные сети | SVM (метод опорных векторов) | Случайный лес |
|---|---|---|---|---|
| Интерпретируемость | Высокая: модель представляет собой набор понятных правил «если-то» | Низкая: работает как «черный ящик» | Средняя: можно понять, какие примеры являются опорными, но сложно интерпретировать в многомерном пространстве | Средняя: отдельные деревья интерпретируемы, но их комбинация – нет |
| Требования к данным | Работает с различными типами данных, устойчив к выбросам | Требует нормализации данных, чувствителен к масштабированию | Требует нормализации, хорошо работает в многомерном пространстве | Работает с различными типами данных, устойчив к выбросам |
| Вычислительная сложность | Низкая при обучении и прогнозировании | Высокая при обучении, средняя при прогнозировании | Средняя при обучении, низкая при прогнозировании | Средняя при обучении, средняя при прогнозировании |
| Риск переобучения | Высокий без регуляризации | Средний (зависит от архитектуры и регуляризации) | Низкий при правильном выборе параметров | Низкий благодаря ансамблевой природе |
| Обработка нелинейных зависимостей | Хорошая, но может требовать глубоких tree | Отличная, особенно для глубоких сетей | Хорошая при использовании нелинейных ядер | Отличная благодаря комбинации множества моделей |
| Устойчивость к шуму | Низкая | Средняя (зависит от архитектуры) | Высокая благодаря концепции опорных векторов | Высокая благодаря усреднению результатов |
| Обработка пропущенных значений | Встроенная поддержка | Требует предварительной обработки | Требует предварительной обработки | Встроенная поддержка |
Это сравнение наглядно демонстрирует, что каждый алгоритм имеет свои преимущества и недостатки, и выбор конкретного метода должен определяться спецификой решаемой задачи.
Когда лучше использовать деревья решений, а когда – другие методы?
Выбор оптимального алгоритма зависит от множества факторов: характера данных, требований к модели, вычислительных ресурсов и т.д. Рассмотрим, в каких случаях предпочтительно использовать decision tree или их ансамбли, а когда стоит обратиться к другим методам.
Деревья решений предпочтительны, когда:
- Важна интерпретируемость модели
Если необходимо не только получить прогноз, но и понять, почему было принято то или иное решение, decision tree – идеальный выбор. Это особенно актуально в медицине, финансах и юриспруденции, где требуется объяснять причины принятия solutions.
- Данные имеют смешанный тип
Деревья решений одинаково хорошо работают с численными и категориальными признаками без необходимости их предварительного преобразования.
- Присутствуют пропущенные значения
Алгоритмы построения decision tree могут обрабатывать неполные данные, автоматически находя оптимальные пути для классификации примеров с пропущенными значениями.
- Требуется быстрая разработка и внедрение модели
Деревья решений относительно просты в реализации и не требуют сложной настройки гиперпараметров.
Нейронные сети предпочтительны, когда:
- Данные имеют сложную структуру
Для обработки изображений, аудио, видео или текста нейронные сети обычно превосходят другие алгоритмы благодаря способности автоматически извлекать сложные признаки.
- Требуется высокая точность прогнозирования
При наличии достаточного объема данных для обучения нейронные сети часто демонстрируют наилучшие результаты, особенно в задачах распознавания образов.
- Интерпретируемость модели не критична
Если важен только результат, а не процесс его получения, сложность нейронных сетей не является недостатком.
SVM предпочтителен, когда:
- Данные имеют четкую разделимость в пространстве признаков
SVM особенно эффективен, когда классы можно разделить гиперплоскостью (возможно, в преобразованном пространстве признаков).
- Количество примеров относительно невелико, но размерность пространства признаков высока
SVM хорошо справляется с задачами, где количество признаков превышает количество обучающих примеров.
- Требуется высокая устойчивость к выбросам
Благодаря концепции опорных векторов, SVM менее чувствителен к отдельным аномальным значениям.
Случайный лес предпочтителен, когда:
- Нужен компромисс между интерпретируемостью и точностью
Случайный лес сохраняет некоторую интерпретируемость отдельных tree, при этом значительно повышая точность прогнозирования.
- Данные содержат шум или выбросы
Ансамблевая природа случайного леса делает его устойчивым к шуму в данных.
- Требуется оценка важности признаков
Случайный лес предоставляет надежные оценки важности каждого признака, что полезно для отбора наиболее информативных переменных.
В современной практике машинного обучения часто используется комбинированный подход: сначала создаются простые модели для первичного анализа данных и выявления ключевых закономерностей, а затем, при необходимости, применяются более сложные алгоритмы для повышения точности прогнозирования.
Итоги и рекомендации
В эпоху глубоких нейронных сетей и сложных ансамблевых методов decision tree сохраняют свою актуальность как мощный и интуитивно понятный инструмент анализа данных. Подводя итоги нашего исследования, выделим ключевые моменты и практические рекомендации.
Основные выводы
-
Универсальность применения.
Деревья решений эффективны в различных областях: от финансового анализа и медицинской диагностики до систем рекомендаций и классификации изображений. Их гибкость позволяет адаптировать модель под специфику конкретной задачи.
-
Баланс между простотой и мощностью.
Несмотря на относительную простоту алгоритма, decision tree способны моделировать сложные нелинейные зависимости и работать с разнородными данными.
-
Интерпретируемость как ключевое преимущество.
В отличие от многих современных алгоритмов машинного обучения, деревья решений предоставляют прозрачную логику принятия solutions, что критически важно в ряде областей, где требуется объяснимый ИИ.
-
Развитие через ансамблевые методы.
Технологии случайного леса и градиентного бустинга, основанные на decision tree, входят в число наиболее эффективных алгоритмов машинного обучения, сочетая высокую точность с относительной интерпретируемостью.
В каких случаях дерево решений – лучший выбор
Деревья решений являются оптимальным выбором в следующих ситуациях:
- Когда важнее понять логику принятия solutions, чем добиться максимальной точности
- При работе с неоднородными данными, содержащими как числовые, так и категориальные переменные
- В задачах с пропущенными значениями, которые сложно восстановить
- Когда требуется быстрая разработка прототипа модели с минимальной предобработкой данных
- В образовательных целях для наглядной демонстрации принципов классификации или регрессии
Советы для начинающих
-
Начинайте с простого.
Строите сначала неглубокие tree с ограниченным числом параметров, постепенно усложняя модель и контролируя риск переобучения.
-
Уделяйте внимание предобработке данных.
Хотя decision tree менее чувствительны к масштабированию и нормализации, чем многие другие алгоритмы, качественная очистка данных и обработка выбросов значительно повысят точность модели.
-
Используйте кросс-валидацию.
Разделите данные на обучающую и тестовую выборки, применяйте k-fold кросс-валидацию для более надежной оценки качества модели и выбора оптимальных гиперпараметров.
-
Экспериментируйте с параметрами.
Тестируйте различные значения гиперпараметров (максимальная глубина, минимальное число примеров в листе и т.д.) для поиска оптимального баланса между точностью и обобщающей способностью.
-
Рассматривайте ансамблевые методы.
Если точность простого tree недостаточна, попробуйте случайный лес или градиентный бустинг, которые обычно значительно повышают качество прогнозирования.
Деревья решений – это не просто алгоритм, а философия структурированного подхода к принятию solutions. Даже в тех случаях, когда для финального прогнозирования используются более сложные модели, decision tree остаются незаменимым инструментом для первичного анализа данных, выявления значимых признаков и построения интерпретируемых моделей.
В мире искусственного интеллекта, где алгоритмы становятся все более сложными и непрозрачными, decision tree напоминают нам о важности понимания процесса принятия решений. Возможно, именно в этом и заключается их непреходящая ценность.
Если вы хотите глубже разобраться в алгоритмах машинного обучения и научиться применять деревья решений на практике, рассмотрите возможность пройти специализированное обучение. На странице с подборкой C#-курсов вы найдете актуальные программы, которые помогут не только освоить основы программирования, но и изучить прикладные аспекты работы с моделями анализа данных.
Рекомендуем посмотреть курсы по разработке на языке C#
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
C# для разработки игр
|
XYZ School
21 отзыв
|
Цена
60 200 ₽
86 000 ₽
Ещё -14% по промокоду
|
От
5 916 ₽/мес
|
Длительность
5 месяцев
|
Старт
12 февраля
|
Подробнее |
|
Профессия Разработчик игр на Unity
|
Skillbox
220 отзывов
|
Цена
127 280 ₽
254 560 ₽
Ещё -20% по промокоду
|
От
5 303 ₽/мес
Это минимальный ежемесячный платеж за курс.
|
Длительность
9 месяцев
|
Старт
15 февраля
|
Подробнее |
|
Профессия Разработчик игр на Unity
|
Skillfactory
55 отзывов
|
Цена
146 124 ₽
265 680 ₽
Ещё -5% по промокоду
|
От
4 059 ₽/мес
Это минимальный ежемесячный платеж за курс. От Skillfactory без %.
7 317 ₽/мес
|
Длительность
12 месяцев
|
Старт
5 марта
|
Подробнее |
|
Разработчик C#. Углубленный уровень
|
Otus
76 отзывов
|
Цена
102 600 ₽
114 000 ₽
|
От
10 260 ₽/мес
|
Длительность
6 месяцев
|
Старт
27 марта
|
Подробнее |

Кем можно работать в декрете: перспективные профессии и пошаговое руководство
Декрет — не повод ставить карьеру на паузу. В этой статье расскажем, какую профессию можно освоить в декрете, чтобы получать доход и развиваться, не отрываясь от семьи.

Эволюция фронтенд-разработки: неожиданные факты и технологии
Хотите узнать, как CSS, JavaScript и фреймворки изменили подходы к созданию веб-интерфейсов? В статье раскроем ключевые этапы и современные тренды.

Какие инструменты нужны проджект-менеджеру?
Менеджер проекта без инструментов — как дирижер без палочки. Разбираем топ сервисов, которые помогут структурировать задачи, автоматизировать процессы и избежать хаоса.

Почему тестировщики ошибаются: анализ причин и решений
Ошибки в тестировании — это нормально, но их можно минимизировать. В статье разберем основные причины, примеры и практические советы, которые помогут сделать процесс тестирования эффективнее.