Директивы препроцессора в C и C++: полный разбор с примерами

Работа с директивами препроцессора — это тот фундамент, который отличает понимающего разработчика от того, кто лишь копирует шаблоны из Stack Overflow. В этой статье мы разберём механизмы, которые выполняются ещё до того, как компилятор увидит первую строку вашего кода. Речь пойдёт о макросах, условной компиляции, подключении заголовков и других инструментах, которые формируют итоговую программу задолго до её запуска.
- Что такое препроцессор и зачем он нужен в C/C++
- Виды директив препроцессора: полный список
- Директива #include — подключение заголовочных файлов
- Макросы и #define: как работают и какие есть виды
- Условная компиляция: #if, #ifdef, #ifndef, #elif, #else, #endif
- Предотвращение повторного включения файлов: include guards и #pragma once
- Сообщения компилятора: #error и #warning
- Директива #pragma: специальные инструкции компилятору
- Как препроцессор трансформирует код: что происходит «до компиляции»
- Типичные ошибки при работе с директивами препроцессора
- Заключение
- Рекомендуем посмотреть курсы по С трудоустройством
Что такое препроцессор и зачем он нужен в C/C++
Препроцессор представляет собой отдельный этап обработки исходного кода, который предшествует непосредственной компиляции. Можно представить его как специализированный текстовый редактор, который получает ваш .cpp или .c файл и преобразует его согласно заданным инструкциям — директивам. Результатом работы препроцессора становится расширенный исходный код, который затем передаётся компилятору для преобразования в объектный файл.
Основные задачи препроцессора включают:
- Подключение содержимого заголовочных файлов (#include).
- Макроподстановку — замену определённых идентификаторов на заданные значения или фрагменты кода (#define).
- Условную компиляцию — включение или исключение отдельных участков кода в зависимости от заданных условий.
- Удаление комментариев из исходного текста.
- Обработку специальных директив для управления процессом сборки.
Путь исходного документа выглядит следующим образом: source.cpp → preprocessing → source.i (расширенный файл) → compilation → source.o (объектный файл)
Ключевое отличие директив препроцессора от обычных инструкций языка заключается в том, что они начинаются с символа # и обрабатываются до компиляции. Это означает, что препроцессор не понимает синтаксис C или C++ — он работает исключительно с текстом, выполняя замены и условные вставки. Именно поэтому директивы не требуют точки с запятой в конце: они не являются операторами языка, а представляют собой команды для текстового преобразователя.
Возникает резонный вопрос: зачем усложнять процесс компиляции дополнительным этапом? На практике препроцессор решает задачи, которые невозможно или крайне затруднительно реализовать средствами самого языка — например, условное включение платформозависимого кода или создание универсальных констант для всего проекта. Однако важно помнить, что мощь препроцессора требует осторожности: неправильное использование макросов может привести к трудноуловимым ошибкам и снижению читаемости кода.

препроцессор C++
Иллюстрация показывает разработчиков, которые обсуждают и используют директивы препроцессора C/C++. Макросы, условная компиляция и include обрабатываются ещё до компиляции и формируют итоговый код. Визуально подчёркивается, что препроцессор — отдельный и важный этап сборки программы.
Виды директив препроцессора: полный список
Директивы препроцессора можно классифицировать по их функциональному назначению. Каждая из них решает конкретную задачу в процессе подготовки кода к компиляции. Давайте рассмотрим полный перечень основных директив, с которыми сталкивается разработчик на C и C++.
Таблица основных директив препроцессора:
| Директива | Назначение |
|---|---|
| #include | Подключает содержимое указанного заголовочного документа в текущий файл |
| #define | Создаёт макрос — символическую константу или макрофункцию |
| #undef | Отменяет ранее определённый макрос |
| #if / #elif / #else / #endif | Управляют условной компиляцией на основе логических выражений |
| #ifdef / #ifndef | Проверяют наличие или отсутствие определённого макроса |
| #error | Принудительно останавливает компиляцию с выводом сообщения об ошибке |
| #warning | Генерирует предупреждение компилятора без остановки сборки |
| #pragma | Передаёт специфичные для компилятора инструкции |
Эти директивы — основные команды, с помощью которых управляют работой препроцессора. Стоит отметить, что некоторые из них, такие как #pragma, могут иметь различную реализацию в зависимости от используемого компилятора — это связано с тем, что стандарт языка оставляет определённую свободу для специфичных расширений.
Майнд-карта наглядно показывает основные группы директив препроцессора и их назначение. Светлый фон и чёткий контраст делают схему удобной для чтения на экране и при печати. Подходит как для быстрого повторения, так и для навигации по разделу.
На первый взгляд может показаться, что набор директив ограничен и прост. Однако их комбинирование открывает широкие возможности: от создания кроссплатформенного кода до реализации сложных систем условной компиляции для различных конфигураций сборки. В последующих разделах мы подробно разберём каждую из этих директив, рассмотрим практические примеры и обсудим типичные ошибки при их использовании.
Директива #include — подключение заголовочных файлов
Директива #include выполняет, пожалуй, самую очевидную и при этом критически важную задачу — она буквально копирует содержимое указанного файла в то место, где она вызвана. Препроцессор находит требуемый файл, считывает его содержимое полностью и подставляет на место директивы. Это означает, что после препроцессирования ваш исходный документ значительно увеличивается в размерах за счёт включённого кода.
Две формы записи #include:
Существует принципиальная разница между двумя синтаксическими вариантами этой директивы:
- #include <filename> — используется для подключения системных и стандартных библиотечных заголовков. Препроцессор ищет файл в предопределённых системных каталогах (обычно /usr/include, /usr/local/include в Unix-подобных системах или стандартных путях компилятора в Windows).
- #include «filename» — применяется для подключения пользовательских заголовочных файлов. Поиск начинается с текущего каталога проекта, и только если документ не найден, препроцессор обращается к системным путям.
Эта разница может показаться незначительной, но она влияет на порядок поиска файлов и, соответственно, на скорость препроцессирования. Кроме того, использование угловых скобок для системных заголовков — это устоявшаяся конвенция, которая делает код более читаемым и позволяет сразу понять, откуда берётся та или иная функциональность.
Примеры использования #include
Подключение стандартной библиотеки:
#include
#include
#include
int main() {
std::vector numbers = {5, 2, 8, 1};
std::sort(numbers.begin(), numbers.end());
return 0;
}
Здесь мы подключаем три стандартных заголовка: для ввода-вывода, работы с векторами и алгоритмами сортировки.
Подключение пользовательского заголовка:
#include "my_functions.h"
#include "config.h"
int main() {
initialize_config();
process_data();
return 0;
}
В этом примере подключаются локальные заголовочные файлы проекта, которые содержат объявления пользовательских функций.
Типичные ошибки при работе с #include
Циклические include:
Одна из наиболее коварных проблем возникает, когда файл A подключает B, а файл B, в свою очередь, подключает A. Препроцессор попадает в бесконечный цикл взаимных подключений, что приводит к ошибкам компиляции или переполнению стека препроцессора. Решением этой проблемы служат include guards, о которых мы поговорим в отдельном разделе.
Дублирование подключения:
Даже без циклических зависимостей многократное включение одного и того же заголовочного документа может привести к ошибкам повторного определения. Представьте, что файл utils.h выявляет структуру Point, и этот заголовок подключается дважды через разные цепочки include — компилятор увидит два определения одной и той же структуры и сообщит об ошибке. Именно поэтому практически все заголовочные файлы должны содержать защиту от повторного включения.
Макросы и #define: как работают и какие есть виды
Директива #define представляет собой один из самых мощных и одновременно опасных инструментов препроцессора. Она позволяет создавать макросы — текстовые замены, которые препроцессор выполняет перед компиляцией. Важно понимать, что макросы работают на уровне текста: препроцессор буквально находит указанный идентификатор и заменяет его на заданное значение или выражение, не учитывая контекст или типы данных.
Простые макросы-константы
Наиболее распространённое применение #define — создание именованных констант:
#define PI 3.14159 #define MAX_BUFFER_SIZE 1024 #define APP_VERSION "2.1.3"
При препроцессировании каждое вхождение PI в коде будет заменено на 3.14159, MAX_BUFFER_SIZE — на 1024 и так далее. Эта техника делает код более читаемым и упрощает внесение изменений: достаточно изменить значение в одном месте, а не искать все вхождения числа по всему проекту.
Отличие от const:
В современном C++ для определения констант рекомендуется использовать const или constexpr вместо макросов:
const double PI = 3.14159; constexpr int MAX_BUFFER_SIZE = 1024;
Принципиальная разница заключается в том, что const создаёт типизированную константу, которая проверяется компилятором, имеет область видимости и может отлаживаться. Макрос же — это просто текстовая замена, лишённая какой-либо типовой информации. Однако макросы всё ещё используются для задач, недоступных константам — например, для условной компиляции или создания платформозависимых определений.
Макросы-функции
Более сложный вариант использования #define — создание макрофункций:
#define SQUARE(x) ((x) * (x)) #define MAX(a, b) ((a) > (b) ? (a) : (b)) #define ABS(x) ((x) < 0 ? -(x) : (x))
На первый взгляд такие макросы выглядят удобно — они работают с любыми типами данных и не требуют объявления функции. Однако здесь кроется множество подводных камней.
Риски макрофункций:
Отсутствие типов означает, что макрос не проверяет корректность переданных аргументов.
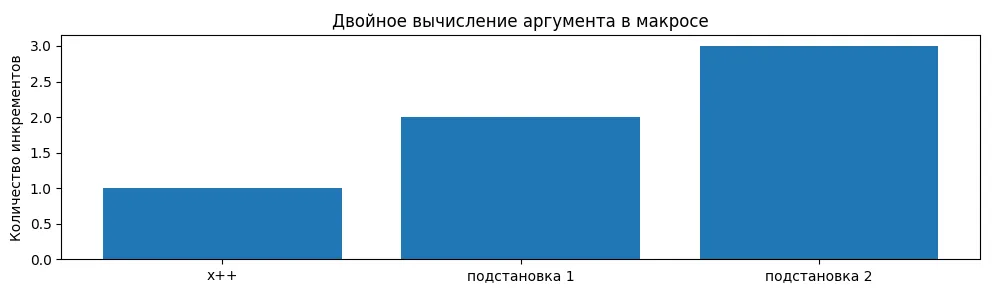
Иллюстрация демонстрирует, что аргумент макроса может вычисляться несколько раз. Это приводит к неожиданным побочным эффектам, например к двойному инкременту переменной. Такой визуальный пример хорошо поясняет, почему макросы опаснее inline-функций.
Более того, каждый параметр в макросе подставляется буквально, что может привести к двойному вычислению:
int x = 5; int result = SQUARE(x++); // Развернётся в ((x++) * (x++)) // x инкрементируется дважды! Результат непредсказуем
Правильное оформление макроса требует обильного использования скобок, чтобы избежать проблем с приоритетом операций. Сравните:
#define BAD_SQUARE(x) x * x #define GOOD_SQUARE(x) ((x) * (x)) int a = BAD_SQUARE(2 + 3); // Развернётся в 2 + 3 * 2 + 3 = 11 int b = GOOD_SQUARE(2 + 3); // Развернётся в ((2 + 3) * (2 + 3)) = 25
Переопределение и отмена макроса (#undef)
Директива #undef используется для отмены ранее определённого макроса:
#define TEMP_VALUE 100 // ... использование TEMP_VALUE ... #undef TEMP_VALUE #define TEMP_VALUE 200 // Переопределение
Это полезно в ситуациях, когда необходимо временно изменить значение макроса для конкретного участка кода или когда подключаемая библиотека определяет макрос, конфликтующий с вашим кодом.
Преимущества макросов:
- Не создают дополнительных вызовов функций (inline-подстановка на этапе препроцессирования).
- Работают с любыми типами данных.
- Позволяют создавать платформозависимые определения.
Недостатки макросов:
- Отсутствие проверки типов
- Проблемы с отладкой, когда видны развёрнутые выражения, а не макросы.
- Риск побочных эффектов при двойном вычислении аргументов.
- Могут конфликтовать с именами переменных и функций.
В современной разработке на C++ рекомендуется использовать inline-функции и шаблоны вместо макрофункций везде, где это возможно. Макросы стоит применять только там, где альтернативы действительно нет — например, для условной компиляции или специфичных задач метапрограммирования.
Макросы vs альтернативы в современном C++
| Задача | Макрос (#define) | Современная альтернатива |
| Константы | #define PI 3.14 | constexpr double PI = 3.14; |
| Простые функции | #define SQR(x) ((x)*(x)) | inline / шаблоны |
| Проверка типов | ❌ отсутствует | ✅ есть |
| Отладка | ❌ сложно | ✅ удобно |
| Побочные эффекты | ⚠️ возможны | ❌ отсутствуют |
| Рекомендация | Использовать осторожно | Предпочтительно |
Условная компиляция: #if, #ifdef, #ifndef, #elif, #else, #endif
Условная компиляция — это механизм, позволяющий включать или исключать фрагменты кода в зависимости от выполнения определённых условий на этапе препроцессирования. Можно сказать, что это своего рода «if-else» для препроцессора, который решает, какие части исходного текста попадут в финальную версию, передаваемую компилятору.
Назначение условной компиляции
Разные конфигурации сборки:
Один из классических сценариев — разделение debug и release версий программы. В режиме отладки нам требуется дополнительное логирование, проверки и диагностическая информация, которые совершенно не нужны в финальной сборке:
#ifdef DEBUG std::cout << "Debug: entering function with parameter = " << param << std::endl; #endif
Кроссплатформенность:
При разработке приложений, работающих на разных операционных системах, неизбежно возникают участки платформозависимого кода. Условная компиляция позволяет элегантно решить эту задачу:
#ifdef _WIN32 #include // Код для Windows #elif defined(__linux__) #include // Код для Linux #elif defined(__APPLE__) #include <mach/mach.h> // Код для macOS #endif
Отключение/включение фрагментов кода:
Во время разработки часто требуется временно отключить определённую функциональность, не удаляя код полностью. Условная компиляция предоставляет удобный способ «закомментировать» целые блоки:
#if 0 // Этот код не попадёт в компиляцию experimental_feature(); risky_optimization(); #endif
Основные конструкции условных директив
Директива #if — проверка логического выражения:
#if вычисляет константное выражение и включает код, если результат истинен (не равен нулю):
#define VERSION 2
#if VERSION >= 2
void new_feature() {
// Функциональность, доступная с версии 2
}
#endif
Выражение может содержать арифметические операции, сравнения и логические операторы. Важно помнить, что все неопределённые идентификаторы в таких выражениях трактуются как ноль.
Директивы #elif и #else:
Для построения более сложных условных конструкций используются #elif (аналог else-if) и #else:
#if PLATFORM == 1 #define OS_NAME "Windows" #elif PLATFORM == 2 #define OS_NAME "Linux" #elif PLATFORM == 3 #define OS_NAME "macOS" #else #define OS_NAME "Unknown" #endif
Директива #endif:
Каждая условная конструкция должна завершаться директивой #endif, которая обозначает конец условного блока. Отсутствие #endif приведёт к ошибке препроцессирования.
Директива #ifdef — проверка существования макроса:
#ifdef проверяет, был ли определён указанный макрос (независимо от его значения):
#define FEATURE_ENABLED
#ifdef FEATURE_ENABLED
void use_feature() {
// Этот код скомпилируется
}
#endif
Эквивалентная запись через #if:
#if defined(FEATURE_ENABLED) // Тот же эффект #endif
Директива #ifndef — проверка отсутствия:
#ifndef работает противоположным образом — код компилируется, если макрос НЕ определён:
#ifndef MAX_CONNECTIONS #define MAX_CONNECTIONS 100 // Определяем, если ещё не определено #endif
Эта конструкция особенно полезна для предоставления значений по умолчанию.
Примеры реального использования
Платформозависимый код для Linux/Windows:
#ifdef _WIN32
#include
void clear_screen() {
system("cls");
}
#else
#include
void clear_screen() {
system("clear");
}
#endif
В этом примере функция очистки экрана реализована по-разному для Windows и Unix-подобных систем.
Настройка debug/release:
#ifdef DEBUG
#define LOG(msg) std::cerr << "[DEBUG] " << msg << std::endl
#define ASSERT(condition) \
if (!(condition)) { \
std::cerr << "Assertion failed: " #condition << std::endl; \
abort(); \
}
#else
#define LOG(msg) // В release режиме логирование отключено
#define ASSERT(condition) // Проверки также отключены
#endif
Такой подход позволяет включить подробное логирование в debug-сборке, при этом полностью исключив его из release-версии без изменения основного кода.
Отключение части кода при тестировании:
#ifndef UNIT_TEST
void connect_to_database() {
// Реальное подключение к базе данных
}
#else
void connect_to_database() {
// Заглушка для модульных тестов
std::cout << "Mock database connection" << std::endl;
}
#endif
При запуске тестов можно определить макрос UNIT_TEST, и вместо реального подключения к базе данных будет использоваться mock-реализация.
Условная компиляция становится особенно ценной в крупных проектах, где один и тот же код должен собираться для различных платформ, конфигураций и окружений. Грамотное использование этих директив позволяет поддерживать единую кодовую базу, избегая дублирования и упрощая сопровождение проекта.
Предотвращение повторного включения файлов: include guards и #pragma once
Одна из фундаментальных проблем при работе с заголовочными файлами в C и C++ — это возможность их многократного включения в процессе компиляции. Эта ситуация возникает естественным образом в любом проекте средней сложности и требует специальных механизмов защиты.
Проблема повторного включения заголовков
Представим типичную ситуацию: у нас есть заголовочный файл point.h, который определяет структуру Point. Два других заголовка — geometry.h и graphics.h — используют эту структуру и потому включают point.h. Теперь, если наш основной файл подключает оба заголовка, препроцессор дважды вставит содержимое point.h:
// point.h
struct Point {
int x, y;
};
// geometry.h
#include "point.h"
// ... геометрические функции
// graphics.h
#include "point.h"
// ... графические функции
// main.cpp
#include "geometry.h"
#include "graphics.h"
// Структура Point определена дважды -- ошибка компиляции!
Компилятор столкнётся с повторным определением структуры Point и выдаст ошибку. Эта проблема усугубляется с ростом проекта, когда цепочки включений становятся всё сложнее и запутаннее.
Include guards (#ifndef / #define / #endif)
Классическое решение этой проблемы — использование include guards (защитных макросов). Это стандартный идиом, который применяется в подавляющем большинстве заголовочных файлов:
// point.h
#ifndef POINT_H
#define POINT_H
struct Point {
int x, y;
};
#endif // POINT_H
Принцип работы:
При первом включении файла макрос POINT_H ещё не определён, поэтому условие #ifndef истинно, и препроцессор обрабатывает содержимое файла, попутно определяя макрос POINT_H. При повторном включении того же файла макрос уже определён, условие #ifndef ложно, и весь код между #ifndef и #endif игнорируется.
Стандартный шаблон оформления:
#ifndef PROJECT_MODULE_FILENAME_H #define PROJECT_MODULE_FILENAME_H // Объявления и определения #endif // PROJECT_MODULE_FILENAME_H
Имя макроса обычно формируется из имени документа, переведённого в верхний регистр, с заменой точки на подчёркивание. Для уникальности в крупных проектах часто добавляют префикс с названием проекта или модуля. Например, для файла src/network/socket.h можно использовать MYPROJECT_NETWORK_SOCKET_H.
Где используется:
Include guards должны применяться практически в каждом заголовочном файле проекта, за исключением файлов, которые намеренно включаются многократно (например, некоторые специализированные библиотеки конфигурации).
#pragma once — современная альтернатива
Директива #pragma once представляет собой более компактный способ защиты от повторного включения:
// point.h
#pragma once
struct Point {
int x, y;
};
Преимущества:
Главное достоинство #pragma once — это лаконичность и отсутствие необходимости придумывать уникальные имена для макросов. Кроме того, некоторые компиляторы могут оптимизировать обработку таких файлов, поскольку директива явно сообщает о намерении препроцессору.
Недостатки:
Основной недостаток — это отсутствие #pragma once в официальном стандарте C++. Это означает, что формально директива является расширением компилятора, хотя и поддерживается всеми основными современными компиляторами (GCC, Clang, MSVC, Intel C++).
Ещё одна потенциальная проблема связана с файловыми системами: #pragma once определяет уникальность документа по его физическому расположению на диске. Если один и тот же файл доступен по разным путям (например, через символические ссылки или в некоторых сетевых конфигурациях), компилятор может не распознать, что это один и тот же, и включить его дважды. На практике такие ситуации встречаются редко.
Практические рекомендации: в современных проектах оба подхода считаются приемлемыми. Многие разработчики предпочитают #pragma once за краткость, особенно в новых проектах, где гарантированно используются современные компиляторы.
В проектах, требующих максимальной переносимости или поддержки устаревших компиляторов, традиционные include guards остаются более безопасным выбором. Некоторые команды даже комбинируют оба подхода для дополнительной надёжности:
#pragma once
#ifndef POINT_H
#define POINT_H
struct Point {
int x, y;
};
#endif // POINT_H
Независимо от выбранного метода, защита заголовочных файлов от повторного включения — это не опциональная практика, а обязательный элемент профессиональной разработки на C и C++.

Диаграмма наглядно показывает разницу между подключением заголовков без защиты и с использованием include guards. Слева видно, как код вставляется повторно и приводит к ошибкам компиляции. Справа показан корректный сценарий, при котором содержимое заголовка обрабатывается только один раз.
Сообщения компилятора: #error и #warning
Директивы #error и #warning предоставляют разработчику возможность управлять процессом компиляции, генерируя собственные сообщения об ошибках и предупреждениях. Эти инструменты особенно ценны для обеспечения корректности конфигурации проекта и раннего обнаружения потенциальных проблем.
#error — жёсткое завершение компиляции
Директива #error принудительно останавливает процесс компиляции и выводит указанное сообщение. Это позволяет создавать «контрольные точки», которые гарантируют, что код не будет собран в неподдерживаемой конфигурации.
Когда это полезно:
Типичный сценарий — проверка версии компилятора или платформы перед сборкой:
#if __cplusplus < 201103L #error "Этот проект требует компилятор с поддержкой C++11 или выше" #endif
В этом примере, если компилятор не поддерживает C++11, разработчик сразу увидит понятное сообщение об ошибке, вместо того чтобы столкнуться с непонятными ошибками компиляции в коде, использующем современные возможности языка.
Проверка обязательных определений:
#ifndef API_KEY #error "API_KEY должен быть определён! Используйте -DAPI_KEY=ваш_ключ" #endif #if !defined(TARGET_PLATFORM) #error "Необходимо указать целевую платформу: -DTARGET_PLATFORM=WINDOWS|LINUX|MACOS" #endif
Такие проверки защищают от попыток скомпилировать проект с неполной конфигурацией.
Контроль взаимоисключающих опций:
#if defined(USE_OPENGL) && defined(USE_DIRECTX) #error "Нельзя одновременно использовать OpenGL и DirectX. Выберите один графический API." #endif
#warning — предупреждение
Директива #warning работает аналогично #error, но не останавливает компиляцию — она лишь выводит предупреждающее сообщение в лог сборки.
Информирование разработчика:
#ifndef OPTIMIZATION_ENABLED #warning "Оптимизация отключена. Производительность может быть снижена." #endif
Это позволяет обратить внимание на потенциальные проблемы, не блокируя при этом процесс сборки.
Маркировка устаревшего кода:
#ifdef USE_OLD_API #warning "USE_OLD_API устарел и будет удалён в версии 3.0. Используйте новый API." #endif
Напоминания для разработчиков:
#if FEATURE_EXPERIMENTAL #warning "Включена экспериментальная функциональность. Не используйте в продакшене!" #endif
Практический пример:
// Проверка минимальной версии компилятора #ifdef _MSC_VER #if _MSC_VER < 1900 #error "Требуется Visual Studio 2015 или новее" #elif _MSC_VER < 1910 #warning "Рекомендуется обновить компилятор до Visual Studio 2017 или новее" #endif #endif // Проверка архитектуры #if !defined(__x86_64__) && !defined(_M_X64) #warning "Проект оптимизирован для 64-битных систем. 32-битная сборка может работать медленнее." #endif
Важно отметить, что директива #warning не является частью стандарта C++, хотя поддерживается большинством современных компиляторов (GCC, Clang, MSVC). В проектах, требующих строгой переносимости, следует учитывать этот факт.
Грамотное использование #error и #warning превращает процесс компиляции в дополнительный уровень контроля качества, помогая выявлять проблемы конфигурации на самой ранней стадии разработки.
Директива #pragma: специальные инструкции компилятору
Директива #pragma занимает особое место среди инструментов препроцессора. В отличие от других директив, которые имеют чётко определённое поведение согласно стандарту языка, #pragma предназначена для передачи специфичных для конкретного компилятора инструкций. Это своего рода «escape-люк», позволяющий использовать уникальные возможности различных компиляторов.
Что такое #pragma и зачем она нужна
Слово «pragma» происходит от «pragmatic» — прагматичный. Эта директива позволяет разработчику воздействовать на поведение компилятора способами, которые выходят за рамки стандарта языка. Каждый компилятор может определять собственные pragma-директивы, и код с использованием специфичных #pragma может не работать на других компиляторах.
Стандарт C++ гарантирует лишь одно: если компилятор не распознаёт конкретную pragma-директиву, он должен проигнорировать её без ошибки. Это позволяет использовать platform-specific оптимизации, не нарушая переносимость кода — на неподдерживаемых платформах директива просто не будет иметь эффекта.
Распространённые примеры использования
#pragma once — защита от повторного включения:
Мы уже рассматривали эту директиву в разделе о include guards. Это наиболее универсальная pragma-директива, поддерживаемая практически всеми современными компиляторами:
#pragma once
class MyClass {
// Определение класса
};
Отключение предупреждений:
Иногда компилятор выдаёт предупреждения для кода, который мы считаем корректным. В таких случаях можно избирательно отключить конкретные предупреждения:
// GCC/Clang #pragma GCC diagnostic push #pragma GCC diagnostic ignored "-Wunused-variable" int unused_var = 42; // Предупреждение подавлено #pragma GCC diagnostic pop // MSVC #pragma warning(push) #pragma warning(disable: 4101) int another_unused = 0; #pragma warning(pop)
Такой подход позволяет отключить предупреждения локально, только для конкретного участка кода, сохраняя их для остального проекта.
Управление оптимизацией:
#pragma GCC optimize("O3")
void performance_critical_function() {
// Эта функция будет скомпилирована с максимальной оптимизацией
}
#pragma GCC optimize("O0")
void debug_function() {
// Эта функция останется неоптимизированной для удобства отладки
}
Выравнивание данных в памяти:
#pragma pack(push, 1)
struct CompactData {
char a;
int b;
char c;
}; // Структура упакована без выравнивания
#pragma pack(pop)
Это особенно важно при работе с бинарными форматами данных или взаимодействии с внешними библиотеками.
Директивы для линковщика:
В MSVC можно указывать библиотеки для линковки прямо в коде:
#pragma comment(lib, "ws2_32.lib") #pragma comment(lib, "opengl32.lib")
Это избавляет от необходимости настраивать параметры линковщика отдельно в IDE или makefile.
Многопоточность и OpenMP:
#pragma omp parallel for
for (int i = 0; i < 1000000; i++) {
// Цикл будет автоматически распараллелен
array[i] = compute(i);
}
Стоит помнить, что чрезмерное использование #pragma снижает переносимость кода. В идеале специфичные для платформы директивы следует изолировать в отдельных модулях или оборачивать в условную компиляцию:
#ifdef _MSC_VER #pragma warning(disable: 4996) #elif defined(__GNUC__) #pragma GCC diagnostic ignored "-Wdeprecated-declarations" #endif
Директива #pragma предоставляет мощные инструменты для тонкой настройки компиляции, но требует осторожного применения и понимания особенностей целевых компиляторов.
Как препроцессор трансформирует код: что происходит «до компиляции»
Понимание внутренней работы препроцессора помогает разработчику избегать типичных ошибок и писать более надёжный код. Давайте разберёмся, что именно происходит с вашим исходным файлом на этапе препроцессирования — ещё до того, как компилятор увидит хотя бы одну строку.
Последовательность операций препроцессора:
Препроцессор выполняет свою работу в несколько этапов, последовательно преобразуя исходный текст:
- Удаление комментариев. Первым делом препроцессор полностью удаляет все комментарии из кода — как однострочные (//), так и многострочные (/* */). Это означает, что компилятор никогда не видит ваших комментариев:
// Исходный код: int x = 5; // Важная переменная /* Этот блок больше не нужен */ int y = 10; // После препроцессора: int x = 5; int y = 10;
- Обработка директив #include. Препроцессор находит все директивы #include, читает содержимое указанных документов и буквально вставляет его на место директивы. Этот процесс рекурсивен — если включаемый файл сам содержит #include, то и эти файлы будут развёрнуты:
// main.cpp #include "config.h" #include // Превращается в: // [полное содержимое config.h] // [полное содержимое iostream и всех файлов, которые он включает]
Именно поэтому после препроцессирования файл может увеличиться с нескольких сотен строк до десятков тысяч.
- Подстановка макросов. Препроцессор находит все вхождения определённых макросов и заменяет их на соответствующие значения или выражения:
// До препроцессора: #define PI 3.14159 #define SQUARE(x) ((x) * (x)) double area = PI * SQUARE(radius); // После препроцессора: double area = 3.14159 * ((radius) * (radius));
Важно понимать, что это именно текстовая замена без какого-либо анализа синтаксиса или семантики.
- Обработка условной компиляции. Препроцессор вычисляет условия в директивах #if, #ifdef, #ifndef и включает или исключает соответствующие блоки кода:
// До препроцессора:
#ifdef DEBUG
log("Entering function");
#endif
process_data();
#ifndef FAST_MODE
validate_results();
#endif
// После препроцессора (если DEBUG определён, а FAST_MODE нет):
log("Entering function");
process_data();
validate_results();
5. Формирование итогового файла. Результатом работы препроцессора становится расширенный исходный документ, обычно с расширением .i для C или .ii для C++. Этот файл содержит:
- Весь код из включённых заголовков.
- Развёрнутые макросы.
- Только те фрагменты, которые прошли условную компиляцию.
- Никаких комментариев.
- Специальные директивы для компилятора, указывающие исходное расположение кода (line markers).
Просмотр результата препроцессирования:
Большинство компиляторов позволяют увидеть результат работы препроцессора:
# GCC/Clang g++ -E source.cpp -o source.i # MSVC cl /E source.cpp > source.i
Изучение препроцессированного файла может быть чрезвычайно полезным при отладке проблем с макросами или понимании того, почему код компилируется не так, как ожидалось.
Практический пример трансформации:
// Исходный файл example.cpp
#include
#define MAX 100
#define DEBUG
int main() {
#ifdef DEBUG
std::cout << "Max value: " << MAX << std::endl;
#endif
return 0;
}
// После препроцессирования (сильно упрощённо):
// [тысячи строк из iostream и зависимых заголовков]
int main() {
std::cout << "Max value: " << 100 << std::endl;
return 0;
}
Понимание этих трансформаций объясняет многие особенности поведения препроцессора. Например, становится очевидно, почему макросы могут приводить к неожиданным результатам — ведь это буквальная текстовая замена без учёта контекста. Также становится понятно, почему include guards критически важны — без них содержимое заголовочного файла может быть вставлено многократно, создавая конфликты определений.
Типичные ошибки при работе с директивами препроцессора
Даже опытные разработчики периодически сталкиваются с проблемами, связанными с препроцессором. Давайте рассмотрим наиболее распространённые ошибки и способы их избежать.
Макросы без скобок:
Одна из классических ловушек — недостаточное количество скобок в определении макроса. Рассмотрим пример:
#define MULTIPLY(a, b) a * b int result = MULTIPLY(2 + 3, 4 + 5); // Развернётся в: 2 + 3 * 4 + 5 = 2 + 12 + 5 = 19 // Ожидалось: (2 + 3) * (4 + 5) = 5 * 9 = 45
Проблема возникает из-за приоритета операций. Правильное определение требует скобок вокруг каждого параметра и всего выражения:
#define MULTIPLY(a, b) ((a) * (b)) int result = MULTIPLY(2 + 3, 4 + 5); // Развернётся в: ((2 + 3) * (4 + 5)) = 45
Двойная подстановка и побочные эффекты:
Макросы вычисляют свои аргументы столько раз, сколько они встречаются в определении:
#define MAX(a, b) ((a) > (b) ? (a) : (b)) int x = 5, y = 10; int result = MAX(x++, y++); // Развернётся в: ((x++) > (y++) ? (x++) : (y++)) // x и y инкрементируются несколько раз!
Решение — избегать передачи в макросы выражений с побочными эффектами или использовать вместо макросов inline-функции:
inline int max(int a, int b) {
return a > b ? a : b;
}
int result = max(x++, y++); // Каждый аргумент вычисляется ровно один раз
Конфликт имён макросов:
Макросы не имеют области видимости в обычном смысле — они действуют глобально после определения. Это может привести к неожиданным конфликтам:
#define SIZE 100
class Array {
int SIZE; // Ошибка! SIZE будет заменено на 100
// Превратится в: int 100;
};
Такие проблемы особенно коварны, когда макрос определён в подключаемой библиотеке. Рекомендуется использовать префиксы для макросов или применять #undef там, где макрос больше не нужен:
#define MY_PROJECT_SIZE 100 // или #undef SIZE
Проблемы с include guards:
Неправильное именование или забытый #endif могут создать серьёзные проблемы:
// file1.h #ifndef FILE_H // Неуникальное имя! #define FILE_H // ... #endif // file2.h #ifndef FILE_H // То же имя! #define FILE_H // ... #endif
В результате один из файлов никогда не будет включён. Используйте уникальные имена, желательно с полным путём:
#ifndef MY_PROJECT_UTILS_FILE1_H #define MY_PROJECT_UTILS_FILE1_H // ... #endif
Циклические include:
Когда файлы включают друг друга напрямую или через цепочку зависимостей:
// a.h
#include "b.h"
class A {
B* ptr;
};
// b.h
#include "a.h"
class B {
A* ptr;
};
Include guards предотвратят бесконечную рекурсию, но один из классов не увидит определение другого. Решение — использовать forward declarations:
// a.h
class B; // Опережающее объявление
class A {
B* ptr;
};
// b.h
class A; // Опережающее объявление
class B {
A* ptr;
};
Злоупотребление макросами как заменой функций или const:
Попытка использовать макросы там, где подходят обычные языковые конструкции:
// Плохо:
#define PI 3.14159
#define SQUARE(x) ((x) * (x))
// Хорошо:
constexpr double PI = 3.14159;
template
inline T square(T x) { return x * x; }
Современные const, constexpr, inline и шаблоны обеспечивают типобезопасность, которой макросы лишены.
Забытые зависимости в условной компиляции:
#ifdef FEATURE_A
void use_feature_a();
#endif
void main_function() {
#ifdef FEATURE_B
use_feature_a(); // Ошибка, если FEATURE_B определён, а FEATURE_A нет
#endif
}
Такие ошибки проявляются только в определённых конфигурациях сборки, что затрудняет их обнаружение.
Макросы, создающие неполные конструкции:
#define BEGIN_NAMESPACE namespace MyProject {
#define END_NAMESPACE }
BEGIN_NAMESPACE
class MyClass {};
END_NAMESPACE
Такие макросы сбивают с толку автоформатирование, подсветку синтаксиса и затрудняют чтение кода. Лучше писать явно:
namespace MyProject {
class MyClass {};
}
Понимание этих типичных ошибок позволяет избежать часов отладки загадочных проблем компиляции. Современный C++ предоставляет множество альтернатив макросам, и их следует использовать везде, где это возможно, оставляя директивы препроцессора для задач, где они действительно незаменимы — условной компиляции и управления включением файлов.
Заключение
Директивы препроцессора остаются неотъемлемой частью разработки на C и C++, несмотря на эволюцию языка и появление более современных альтернатив. Понимание их работы и грамотное применение отличает зрелого специалиста от новичка. Подведем итоги:
- Директивы препроцессора — это отдельный механизм обработки кода до компиляции. Они позволяют управлять подключением файлов, макросами и условной компиляцией.
- Препроцессор работает на уровне текста, а не синтаксиса языка. Из-за этого макросы требуют осторожного использования и чёткого понимания их поведения.
- Директивы #include, #define и условная компиляция лежат в основе кроссплатформенного кода. Без них невозможно гибко управлять сборкой проекта.
- Include guards и #pragma once защищают код от повторного включения заголовков. Это обязательная практика в профессиональной разработке.
- Грамотное использование директив повышает надёжность и читаемость кода. Ошибки в работе с препроцессором часто приводят к сложной отладке.
Если вы только начинаете осваивать профессию программиста, рекомендуем обратить внимание на подборку курсов по C и C++. В таких программах обычно сочетаются теоретическая часть и практические задания, которые помогают лучше понять препроцессор и этапы компиляции.
Рекомендуем посмотреть курсы по С трудоустройством
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Разработчик на C++
|
Skillbox
232 отзыва
|
Цена
138 734 ₽
277 467 ₽
Ещё -20% по промокоду
|
От
4 080 ₽/мес
Это минимальный ежемесячный платеж за курс.
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
C++ разработчик игр
|
XYZ School
21 отзыв
|
Цена
90 300 ₽
129 000 ₽
Ещё -14% по промокоду
|
От
6 500 ₽/мес
|
Длительность
4 месяца
|
Старт
26 марта
|
Подробнее |
|
C++. Практикум. Часть 1
|
Stepik
33 отзыва
|
Цена
850 ₽
|
|
Длительность
1 день
|
Старт
21 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.