Управление конфигурацией сетей: как навести в них порядок
Микросервисная архитектура — это подход к созданию приложений, при котором система разбивается на независимые сервисы, каждый из которых выполняет свою функцию. В отличие от монолита, микросервисы позволяют проще масштабировать продукт, быстрее вносить изменения и снижать риски при сбоях. Такой подход активно используют компании вроде Netflix и Atlassian, чтобы адаптироваться к росту и повысить гибкость своих решений.
В этом курсе разберём, как устроены микросервисы, зачем они нужны, в чём их плюсы и подводные камни, и с чего начать переход от монолита. Всё — простым языком и с примерами из реального опыта. Даже если вы пока «в одной лодке» с монолитом — это будет полезное чтение перед следующим шагом.

Микросервисы требуют других подходов к инфраструктуре, логированию, тестированию и взаимодействию между сервисами. Но взамен дают свободу масштабирования и более устойчивую архитектуру, готовую к быстрым изменениям и высокой нагрузке.
- Анатомия микросервисной архитектуры
- Танцы с конфигурациями, или почему DevOps-инженеры седеют раньше времени
- От хаоса к порядку: базовые принципы управления конфигурациями
- Git как основа основ
- Spring Cloud Config: централизация с умом
- Автоматизация или «как перестать волноваться и полюбить конфиги»
- Безопасность превыше всего
- Джентльменский набор укротителя микросервисов, или что должно быть в арсенале современного DevOps-инженера
- Искусство развертывания, или как не сделать пятницу черной
- Подводные камни микросервисной архитектуры, или почему седеют архитекторы
- Истории с передовой: как выжить при переходе на микросервисы
- Гадаем на кофейной гуще: куда идут микросервисы
Анатомия микросервисной архитектуры
Если вы думаете, что микросервисы – это просто куча маленьких приложений, которые каким-то магическим образом общаются между собой, то… ну, в целом, вы не так уж далеки от истины. Но дьявол, как всегда, кроется в деталях, и этих деталей у нас тут целый чемодан.
Первое, без чего наш микросервисный зоопарк превратится в хаос – это сервис обнаружения (service discovery). Представьте себе офис, где все сотрудники постоянно меняют рабочие места, а вам нужно срочно найти Васю из бухгалтерии. Без централизованной системы навигации это превратится в квест уровня «найди иголку в стоге сена». В мире микросервисов роль такой системы навигации играют специальные реестры (например, Consul или Eureka), которые знают, где и что находится в любой момент времени.
Второй краеугольный камень – это API Gateway, или, как я его называю, «швейцар микросервисного отеля». Он встречает все входящие запросы, проверяет их документы (аутентификация), решает, кого и куда пропустить (маршрутизация), и следит, чтобы никто не устроил вечеринку с DDos-атаками. Без него наши сервисы были бы как проходной двор – заходи кто хочешь, делай что хочешь.
А теперь представьте, что все эти компоненты должны работать в облаке (потому что кто сейчас не в облаке, тот, очевидно, всё ещё живет в 2010 году). Это добавляет ещё один слой сложности – контейнеризацию и оркестрацию. Docker-контейнеры стали для микросервисов тем же, чем колесо для человечества – вроде бы простая штука, а без неё никуда.
Вот вам наглядная схема того, как это всё выглядит:
graph TB
Client[Клиент] --> Gateway[API Gateway]
Gateway --> ServiceDiscovery[Service Discovery]
Gateway --> Auth[Auth Service]
Gateway --> ServiceA[Сервис A]
Gateway --> ServiceB[Сервис B]
Gateway --> ServiceC[Сервис C]
ServiceDiscovery --> ConfigServer[Config Server]
subgraph Инфраструктура
ServiceDiscovery
ConfigServer
Auth
end
subgraph Бизнес-сервисы
ServiceA
ServiceB
ServiceC
end
style Client fill:#f9f,stroke:#333,stroke-width:4px
style Gateway fill:#bbf,stroke:#333,stroke-width:2px
style ServiceDiscovery fill:#dfd,stroke:#333,stroke-width:2px
style ConfigServer fill:#dfd,stroke:#333,stroke-width:2px
style Auth fill:#dfd,stroke:#333,stroke-width:2px
style ServiceA fill:#fdd,stroke:#333,stroke-width:2px
style ServiceB fill:#fdd,stroke:#333,stroke-width:2px
style ServiceC fill:#fdd,stroke:#333,stroke-width:2px
Красиво, правда? Хотя на практике это больше похоже на запутанную паутину с множеством стрелочек, где каждая стрелочка – потенциальная точка отказа. Но не будем о грустном – в конце концов, именно эта сложность и обеспечивает нам с вами работой!
И да, я намеренно не упомянул о безопасности, мониторинге и логировании – это отдельные песни, каждая из которых достойна собственной симфонии. К тому же, если рассказать обо всём сразу, у вас может случиться когнитивная перегрузка, а нам ведь ещё предстоит поговорить об управлении конфигурациями. О, это будет весело!
Танцы с конфигурациями, или почему DevOps-инженеры седеют раньше времени
Знаете, что самое «веселое» в микросервисной архитектуре? Нет, не отладка распределенных транзакций (хотя это тоже то еще развлечение). Самое интересное начинается, когда вам нужно поддерживать конфигурации десятков, а то и сотен сервисов в актуальном состоянии. И нет, хранить их в текстовых файлах на рабочем столе – не вариант (хотя я встречал и такое, да простят меня боги чистого кода).
В мире микросервисов управление конфигурациями превращается в отдельное искусство. Представьте, что у вас есть 50 сервисов, каждому из которых нужно знать свои настройки базы данных, креды для API, URL-ы смежных сервисов, и еще пару десятков параметров. А теперь умножьте это на количество окружений (dev, staging, prod), добавьте необходимость версионирования и возможность быстрого отката изменений. Чувствуете, как начинает побаливать голова?
Основные проблемы, с которыми мы сталкиваемся:
- Согласованность конфигураций между сервисами (когда один чихнул, остальные должны знать об этом)
- Безопасное хранение чувствительных данных (потому что хардкодить пароли в git – это моветон)
- Динамическое обновление настроек (без перезапуска сервисов, ведь мы же не в каменном веке живем)
- Отслеживание изменений (кто, когда и главное – зачем поменял тот критичный параметр)
К счастью, индустрия не стоит на месте, и у нас есть целый арсенал инструментов для решения этих проблем. Spring Cloud Config, HashiCorp Vault, Consul – выбирай на вкус и цвет. Правда, иногда кажется, что количество инструментов для управления конфигурациями уже превысило количество самих конфигураций, но это, видимо, такой закон природы.
А знаете, что самое забавное? Несмотря на все эти крутые инструменты, все равно находится тот самый разработчик, который решает «просто быстренько поправить конфиг в проде». И вот тут-то и начинается настоящее веселье! Потому что в микросервисной архитектуре нет маленьких изменений – есть только те, последствия которых мы еще не осознали.
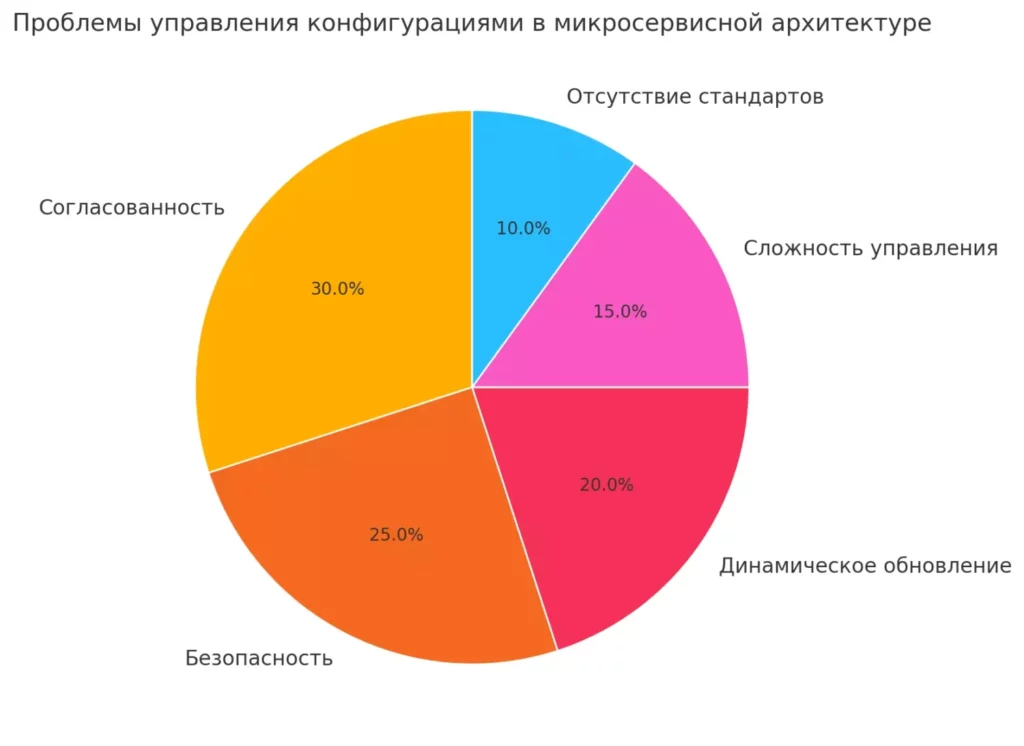
На данной диаграмме представлены основные проблемы управления конфигурациями в микросервисной архитектуре
Кстати, по личному опыту могу сказать – никогда не недооценивайте важность правильного управления конфигурациями. Это как страховка: кажется ненужной тратой денег, пока не случится что-нибудь действительно интересное. И тогда вы будете благодарны себе за то, что потратили время на настройку правильной инфраструктуры управления конфигурациями. Или будете клясть себя за то, что не сделали этого. Третьего не дано.
От хаоса к порядку: базовые принципы управления конфигурациями
Помните те времена, когда все настройки хранились в текстовых файлах на продакшн-сервере, а изменения вносились через SSH-сессию после третьей чашки кофе? К счастью, эволюция не стоит на месте, и сегодня у нас есть целый арсенал инструментов для управления конфигурациями. Давайте разберемся, как не утонуть в этом море возможностей.
Git как основа основ
Первое правило клуба управления конфигурациями — всё должно быть в Git. И нет, папка «backup_configs_final_final_v2» на рабочем столе не считается. Git дает нам не только версионирование, но и аудит изменений (кто, когда и, главное, зачем поменял тот критичный параметр), возможность отката и совместной работы.
# Пример структуры конфигурационных файлов в репозитории
configs/
├── development/
│ ├── app-config.yml
│ └── db-config.yml
├── staging/
│ ├── app-config.yml
│ └── db-config.yml
└── production/
├── app-config.yml
└── db-config.yml
Spring Cloud Config: централизация с умом
В мире Spring Cloud Config выступает как этакий банк для ваших конфигураций. Все настройки хранятся централизованно, а сервисы получают их по запросу. Это как банкомат — вводите свои креды, получаете нужные конфиги. И да, они тоже могут закончиться (но это уже совсем другая история).
@SpringBootApplication
@EnableConfigServer
public class ConfigServer {
public static void main(String[] args) {
SpringApplication.run(ConfigServer.class, args);
}
}
Автоматизация или «как перестать волноваться и полюбить конфиги»
А теперь давайте поговорим о трех китах автоматизации конфигураций: Ansible, Puppet и Chef. Каждый из них — как разные диалекты одного языка. Выбор зависит от того, какой акцент вам больше нравится.
Ansible — это как Python в мире конфигураций: простой, понятный, работает через SSH. Идеален для тех, кто хочет начать автоматизацию без лишней головной боли:
- name: Обновить конфигурацию nginx
hosts: web_servers
tasks:
- name: Копировать конфиг
copy:
src: nginx.conf
dest: /etc/nginx/nginx.conf
- name: Перезапустить nginx
service:
name: nginx
state: restarted
Puppet — больше похож на строгого учителя: требует соблюдения правил, но зато потом все работает как часы:
class nginx_config {
file { '/etc/nginx/nginx.conf':
ensure => file,
source => 'puppet:///modules/nginx/nginx.conf',
notify => Service['nginx']
}
service { 'nginx':
ensure => running,
enable => true
}
}
Chef — это как кулинарная книга для вашей инфраструктуры. Каждый рецепт описывает, как должна выглядеть конфигурация:
template '/etc/nginx/nginx.conf' do source 'nginx.conf.erb' notifies :restart, 'service[nginx]' end service 'nginx' do action [:enable, :start] end
Безопасность превыше всего
И помните: какой бы инструмент вы ни выбрали, безопасность должна быть в приоритете. Храните секреты отдельно (например, в HashiCorp Vault), используйте шифрование и всегда, ВСЕГДА делайте бэкапы перед изменениями. Потому что единственное, что хуже отсутствия автоматизации — это автоматизация, которая пошла не туда.
В следующих разделах мы глубже погрузимся в каждый из этих инструментов, но пока давайте запомним главное: управление конфигурациями — это не просто набор инструментов, это целая философия. Философия, которая помогает нам спать спокойно, зная, что наши конфиги в надежных руках (или репозиториях).
Джентльменский набор укротителя микросервисов, или что должно быть в арсенале современного DevOps-инженера
Помните, как в детстве у каждого был свой любимый набор инструментов? У кого-то конструктор LEGO, у кого-то набор юного химика. В мире микросервисов тоже есть свой джентльменский набор, без которого даже не стоит выходить на эту арену. Давайте посмотрим, что же должно быть в чемоданчике современного укротителя распределенных систем.
Docker – наш первый и самый верный друг. Если вы еще не слышали про Docker, то, вероятно, последние лет пять провели в криогенной заморозке (и я вам даже немного завидую – столько всего интересного впереди!). Docker делает с приложениями то же самое, что контейнеры сделали с морскими перевозками – стандартизирует упаковку и транспортировку. «It works on my machine» больше не отговорка – теперь ваша машина едет вместе с приложением.
Kubernetes (или просто K8s, потому что кто вообще может выговорить это название с первого раза?) – это как командир парада контейнеров. Он решает, где и когда запускать контейнеры, следит за их здоровьем и, если что-то пошло не так, проводит экстренную эвакуацию и развертывание новых. По сути, это автопилот для вашей инфраструктуры, только вместо «пристегните ремни» он говорит «проверьте ваши манифесты».
А теперь про «три богатыря» управления конфигурациями:
- Ansible – для тех, кто любит простоту и Python. Не требует агентов на серверах, работает через SSH, и конфигурации пишутся на YAML (потому что мир еще не придумал более человекочитаемого формата). Правда, иногда его простота может сыграть злую шутку – попробуйте как-нибудь написать сложный плейбук, и вы поймете, о чем я.
- Chef – для тех, кто не боится Ruby и любит чувствовать себя шеф-поваром на кухне инфраструктуры. Вместо плейбуков здесь «рецепты» и «поваренные книги». Очень мощный инструмент, но требует серьезного погружения – это как учиться готовить в ресторане со звездой Мишлен.
- Puppet – старейшина в этой компании, использует собственный декларативный язык для описания конфигураций. Если Chef — это ресторан высокой кухни, то Puppet — это промышленная кухня: менее гибкий, но более предсказуемый и стабильный. Идеален для больших предприятий, где важнее надежность, чем скорость изменений.
Вот вам небольшая шпаргалка для сравнения:
graph TB
subgraph Ansible
A1[Без агентов] --> A2[YAML конфиги]
A2 --> A3[Простой старт]
A3 --> A4[Python-based]
end
subgraph Chef
C1[Ruby DSL] --> C2[Сложная кривая обучения]
C2 --> C3[Гибкие рецепты]
C3 --> C4[Нужны агенты]
end
subgraph Puppet
P1[Собственный DSL] --> P2[Стабильность]
P2 --> P3[Enterprise-ready]
P3 --> P4[Нужны агенты]
end
style A1 fill:#d1f2ff
style A2 fill:#d1f2ff
style A3 fill:#d1f2ff
style A4 fill:#d1f2ff
style C1 fill:#ffd1d1
style C2 fill:#ffd1d1
style C3 fill:#ffd1d1
style C4 fill:#ffd1d1
style P1 fill:#d1ffd1
style P2 fill:#d1ffd1
style P3 fill:#d1ffd1
style P4 fill:#d1ffd1
И помните: выбор инструмента – это как выбор супруга/супруги. Вы не просто выбираете что-то, с чем будете работать, вы выбираете то, с чем придется жить долгие годы. Поэтому не спешите с решением, попробуйте разные варианты, и только потом делайте этот судьбоносный коммит в master.
А, и еще один совет из личного опыта: какой бы инструмент вы ни выбрали, обязательно заведите хороший бэкап стратегии и процедуру отката изменений. Потому что когда что-то пойдет не так (а оно обязательно пойдет), вы будете благодарить себя за эту предусмотрительность. Или проклинать за её отсутствие – выбор за вами!
Искусство развертывания, или как не сделать пятницу черной
За годы работы с микросервисами индустрия накопила столько «лучших практик», что впору издавать многотомник. Но давайте сосредоточимся на тех, которые действительно спасают жизни (ну, или как минимум, рабочие выходные).
Первое и святое – непрерывная интеграция и доставка (CI/CD). Если вы до сих пор разворачиваете сервисы вручную – пора выходить из каменного века. Современный процесс развертывания должен быть похож на конвейер на заводе: код попадает в репозиторий, автоматически тестируется, собирается и отправляется в нужное окружение. Всё как в рекламе – «set it and forget it» (только не забывайте мониторить логи, а то мало ли).
Стратегии развертывания – это отдельная песня. Знаете, что такое «сине-зеленое» развертывание? Нет, это не название нового сорта плесени. Это когда у вас есть две идентичные среды (синяя и зеленая), и вы переключаете трафик между ними при обновлении. Звучит просто? А теперь представьте, что у вас 50 сервисов, и каждый может быть в двух версиях. Чувствуете, как начинает кружиться голова?
Вот несколько ключевых принципов, которые помогут не сойти с ума:
- Автоматизируйте всё, что движется (и даже то, что не движется):
- Сборку и тестирование
- Развертывание и откат
- Проверки после развертывания
- Да, даже создание документации (потому что кто вообще любит писать доки?)
- Используйте канареечные релизы:
- Сначала на 1% пользователей
- Потом на 10%
- И только потом на всех (Потому что лучше разочаровать 1% пользователей, чем 100%)
- Мониторинг и логирование:
- Если вы не можете измерить – вы не можете улучшить
- Если вы не можете отследить – вы не можете починить
- Если вы не логируете – вы просто оптимист
И самое главное – никогда, НИКОГДА не разворачивайте важные обновления в пятницу вечером. Это не лучшая практика, это здравый смысл. Поверьте моему опыту – нет ничего хуже, чем провести выходные, пытаясь понять, почему вдруг все сервисы решили устроить коллективный протест против последнего обновления.
А, и еще один про-тип: всегда имейте план отката. Не план «А», не план «Б», а именно план отката. Потому что когда все планы пойдут наперекосяк (а они пойдут, поверьте), единственное, что вас спасет – это возможность быстро вернуться к последней рабочей версии. Это как кнопка «отмена» в реальной жизни – вроде редко нужна, но когда нужна – бесценна.
И помните: идеальное развертывание – это не то, к которому нельзя ничего добавить, а то, от которого нельзя ничего отнять, не нарушив работу системы. Хотя, если честно, такого я еще не видел. Но мы все к этому стремимся, правда?
Подводные камни микросервисной архитектуры, или почему седеют архитекторы
Знаете, что общего между микросервисами и отношениями? В обоих случаях главная проблема – коммуникация. И если в отношениях можно просто сходить к психологу, то в мире микросервисов всё немного сложнее. Давайте разберем основные «грабли», на которые наступают даже опытные разработчики.
Проблема №1: Интеграция сервисов Представьте, что у вас есть 20 микросервисов, и каждому нужно общаться минимум с пятью другими. Получаем паутину связей, в которой даже паук запутается. Решение? API-first подход и строгие контракты между сервисами. Да, это как брачный контракт – не самая романтичная штука, но зато потом меньше проблем.
Типичный диалог сервисов без контракта: Сервис A: "Привет, мне нужны данные о пользователе" Сервис B: "Какие именно?" Сервис A: "Ну... все?" Сервис B: *падает в обморок от нагрузки*
Проблема №2: Согласованность данных Распределенные транзакции – это как групповое фото большой семьи: все должны улыбаться одновременно, и обязательно кто-то моргнет. В микросервисах мы решаем это через паттерн Saga (что звучит эпично, но на практике напоминает цепочку домино) или через eventual consistency (когда мы говорим «да, данные будут согласованы… когда-нибудь»).
Проблема №3: Зависимости между сервисами Это классическая проблема «А вдруг он не ответит?». Решается через:
- Circuit Breaker (автоматические предохранители)
- Fallback-сценарии (план Б, В и до конца алфавита)
- Таймауты и ретраи (потому что надежда умирает последней)
Отдельный привет тем, кто пытается отследить проблему, когда сервис А не работает потому, что сервис Б не отвечает из-за того, что сервис В перегружен, потому что сервис А шлет слишком много запросов. Да, это реальный кейс из моей практики, и нет, я до сих пор не могу это забыть.
А теперь главный секрет: большинство этих проблем решается с помощью Service Mesh (например, Istio). Это как нанять профессионального переговорщика для ваших сервисов. Он берет на себя всю головную боль с маршрутизацией, балансировкой нагрузки и отказоустойчивостью. Правда, за это придется заплатить дополнительной сложностью инфраструктуры, но эй, нельзя же получить всё и сразу!
И запомните главное правило микросервисной архитектуры: любая проблема решается добавлением еще одного уровня абстракции. Кроме проблемы слишком большого количества уровней абстракции – тут уже придется думать самостоятельно.
P.S. Если вы думаете, что все эти проблемы преувеличены – поздравляю, вы либо гений, либо еще не запускали микросервисы в продакшен. В любом случае, держите под рукой номер хорошего психотерапевта. Просто на всякий случай.
Истории с передовой: как выжить при переходе на микросервисы
Сегодня я расскажу вам несколько историй из жизни компаний, которые решились на этот отважный шаг – переход на микросервисную архитектуру. Спойлер: все выжили, хотя некоторые до сих пор вздрагивают при словах «давайте разобьем монолит».
Кейс №1: «Как мы чуть не убили производительность» Одна финтех-компания (назовем её «Почти PayPal») решила разбить свой монолит на микросервисы. Звучит знакомо, да? Начали они с того, что выделили сервис аутентификации. Казалось бы, что может пойти не так?
День 1: "Отлично, всё работает!" День 2: "Хм, почему-то стало медленнее..." День 3: "ПОЧЕМУ ВСЁ ТАК МЕДЛЕННО?!"
Выяснилось, что каждый запрос теперь делал дополнительный круг через сервис аутентификации, создавая нагрузку на сеть. Решение? Внедрили кэширование токенов и настроили правильный мониторинг. Время отклика вернулось в норму, а команда получила седые волосы и бесценный опыт.
Кейс №2: «Даешь независимость сервисам!» Другая компания (в этот раз из e-commerce) решила, что каждая команда должна быть полностью автономной. Свой стек технологий, своя база данных, полная свобода! Через полгода у них было:
- 5 разных языков программирования
- 3 типа баз данных
- 2 очереди сообщений
- 1 большая головная боль с поддержкой
Спасла ситуацию разработка внутренних стандартов и создание платформенной команды, которая начала предоставлять готовые решения для типовых задач. Да, это ограничило «творческую свободу», зато сделало систему управляемой.
Кейс №3: «Распределенный монолит» А вот история одного стартапа, который решил сразу начать с микросервисов (потому что «так же современнее!»). Они разбили приложение на 15 сервисов, каждый со своей базой данных. Красота! Только вот незадача – при любом изменении приходилось деплоить все сервисы одновременно, потому что они были слишком тесно связаны.
Релиз-менеджер: "Какие сервисы затронуты изменениями?" Разработчик: "Да."
В итоге пришлось потратить три месяца на рефакторинг и правильное разделение доменов. Зато теперь у них действительно независимые сервисы, а не распределенный монолит.
Мораль всех этих историй? Микросервисы – это не серебряная пуля. Это мощный инструмент, который нужно применять с умом. И да, лучше учиться на чужих ошибках, чем набивать собственные шишки. Хотя, давайте будем честными – свои шишки всё равно набьете, просто, может быть, чуть меньше.
P.S. Имена компаний изменены, чтобы защитить невиновных (и виновных тоже).
Гадаем на кофейной гуще: куда идут микросервисы
Как человек, проведший немало бессонных ночей за отладкой распределенных систем, я часто задумываюсь – куда всё это движется? И хотя мой хрустальный шар временно в ремонте, некоторые тренды уже вырисовываются достаточно четко.
Serverless – это как микросервисы на стероидах. Представьте, что вам больше не нужно думать о серверах вообще. Вообще! Просто пишете функцию, и она магическим образом выполняется где-то в облаке. Звучит как утопия? AWS Lambda, Azure Functions и Google Cloud Functions уже делают это реальностью. Правда, теперь вместо проблем с серверами у вас будут проблемы с холодным стартом и неожиданными счетами от облачного провайдера.
Искусственный интеллект и машинное обучение прокладывают себе дорогу в мир микросервисов. Уже сейчас появляются системы, которые могут:
- Автоматически масштабировать сервисы на основе предсказания нагрузки
- Находить аномалии в работе системы до того, как всё упадет
- Оптимизировать конфигурации лучше, чем команда DevOps-инженеров (не показывайте это вашим DevOps’ам)
Но самое интересное – это тренд к упрощению. Да-да, вы не ослышались. После лет усложнения архитектур маятник начинает качаться в обратную сторону. Появляются подходы вроде «минисервисов» – что-то среднее между монолитом и микросервисами. Потому что иногда лучше иметь 5 хорошо продуманных сервисов, чем 50 мелких, которые никто не может удержать в голове.
И знаете что? Возможно, через пару лет мы будем смеяться над нашим нынешним увлечением разбивать всё на микроскопические части. Или нет. В конце концов, предсказывать будущее – дело неблагодарное. Особенно в IT, где единственное постоянное – это постоянные изменения.
А пока давайте просто постараемся не создавать распределенных монолитов и не деплоить в пятницу вечером. Остальное как-нибудь приложится!
И если вся эта история про микросервисы и управление конфигурациями вызвала у вас желание глубже погрузиться в системное администрирование – самое время начать обучение. На странице подборки курсов для системных администраторов вы найдете актуальные программы обучения по этому направлению. От базовых основ до продвинутых техник – выбирайте то, что подходит именно вам. Кстати, многие курсы как раз включают практику с теми инструментами, о которых мы говорили выше.
P.S. Если вы дочитали до этого места – поздравляю! Вы официально знаете о микросервисах больше, чем 90% людей, которые используют это слово в своих резюме. Используйте эту силу с умом!

Чек-лист для IT: как проверить, есть ли в курсе реальная практика по коду
Как проверить курс программирования до покупки и не потратить деньги впустую? Разбираем реальные признаки практики, задания, code review и ошибки, которые допускают новички.

SF Education vs Karpov.Courses: где больше домена в финансах, а где математики и аналитической строгости
SF Education или Karpov Courses — что выбрать, если вы хотите развиваться в финансах или аналитике данных? Разберём различия подходов, навыков и карьерных траекторий, чтобы вы приняли осознанное решение.

Чек-лист для IT: 10 признаков сильного курса по тестированию
Как выбрать курс по тестированию, который действительно приведёт к работе? На что смотреть в программе, практике и поддержке, чтобы не потратить деньги впустую — разбираем по шагам.

Hexlet vs SkillFactory: где меньше “маркетинга”, а больше задач и обратной связи
Hexlet vs SkillFactory — как понять, где больше практики и реального фидбэка? Разбираем форматы заданий, ревью и поддержку: что скрывается за обещаниями и как выбрать без ошибок?