Как построить архитектуру, которая выдержит любые нагрузки
Знаете, что общего между популярным маркетплейсом в черную пятницу и системой продажи билетов на концерт Стаса Михайлова? Правильно – они обе рискуют «прилечь отдохнуть» в самый неподходящий момент под наплывом желающих что-то купить. И если первая ситуация еще может вызвать улыбку (особенно у конкурентов), то вторая грозит настоящим бунтом фанатов российского шансона.

А если серьезно, то высоконагруженные systems сегодня окружают нас повсюду – от банковских приложений до сервисов доставки еды. И их работоспособность напрямую влияет на успех бизнеса. Как технический директор с 15-летним опытом построения подобных систем, могу сказать – правильная архитектура здесь играет ключевую роль.
В этой статье я поделюсь практическими знаниями о том, как построить действительно надежную высоконагруженную систему, которая не «ляжет» в самый неподходящий момент. Мы разберем современные подходы, инструменты и практики, которые помогут вашей system оставаться в строю даже под серьезной нагрузкой. И да, обойдемся без лишней теории – только проверенные решения из реального опыта.
- Что такое высоконагруженные системы и почему их архитектура важна?
- Примеры высоконагруженных систем
- Источники нагрузки и проблемы роста
- Принципы проектирования высоконагруженных систем
- Почему важны отказоустойчивость и высокая доступность?
- Роль мониторинга и метрик
- Лучшие практики архитектуры высоконагруженных систем
- Микросервисная архитектура
- Разделение фронтенда и бэкенда
- Балансировка нагрузки
- Инструменты кластеризации: как заставить серверы работать в команде
- Основные подходы к кластеризации
- Популярные инструменты кластеризации
- Особенности настройки кластеров
- Обработка данных: оптимизация и инструменты
- Использование кеширования
- Сервисы очередей
- Базы данных
- Масштабирование высоконагруженных систем
- Горизонтальное и вертикальное масштабирование: различия
- Автоматическое масштабирование
- Тестирование и обеспечение надежности
- Нагрузочное и стресс-тестирование
- Тестирование отказоустойчивости
- Важность мониторинга в реальном времени
- Безопасность высоконагруженных систем
- Аутентификация и авторизация
- Использование SSL/TLS для защиты данных
- Защита от атак
- Инструменты и технологии для построения высоконагруженных систем
- Заключение: Как спроектировать эффективную высоконагруженную систему?
Что такое высоконагруженные системы и почему их архитектура важна?
Помните анекдот про то, как программист пытался объяснить жене, почему банкомат «завис» именно в момент снятия зарплаты? Так вот, это как раз пример того, что происходит с системой, которая не готова к высоким нагрузкам.
Примеры высоконагруженных систем
В моей практике (а она, поверьте, богата на «веселые» случаи) чаще всего в категорию высоконагруженных попадают:
- CRM-systems крупных компаний, где тысячи менеджеров одновременно пытаются обновить статус сделки (и желательно не в Excel)
- Колл-центры, где каждая секунда промедления может стоить потерянного клиента
- Онлайн-магазины, особенно во время распродаж (привет, «черная пятница» и падающие сервера!)
Источники нагрузки и проблемы роста
А теперь давайте разберем, откуда берется эта самая нагрузка (спойлер: не только от активных пользователей):
- Количество запросов — когда ваша система популярна как новый iPhone в день релиза. Представьте, что тысячи пользователей одновременно пытаются сделать что-то в вашей system – от просмотра котиков до оформления кредита.
- Объем данных — когда ваша база данных разрослась до размеров библиотеки Конгресса. И каждый запрос требует обработки терабайтов информации (причем желательно быстрее, чем за время жизни вселенной).
- «Кривые» скрипты — мой личный фаворит! Когда код написан так, будто его писал стажер после бессонной ночи. Простой запрос может превратиться в марафон по всем таблицам базы данных.
- Неоптимальные настройки — когда система настроена так, будто работает на суперкомпьютере, а на деле – на стареньком ноутбуке из 2010 года.
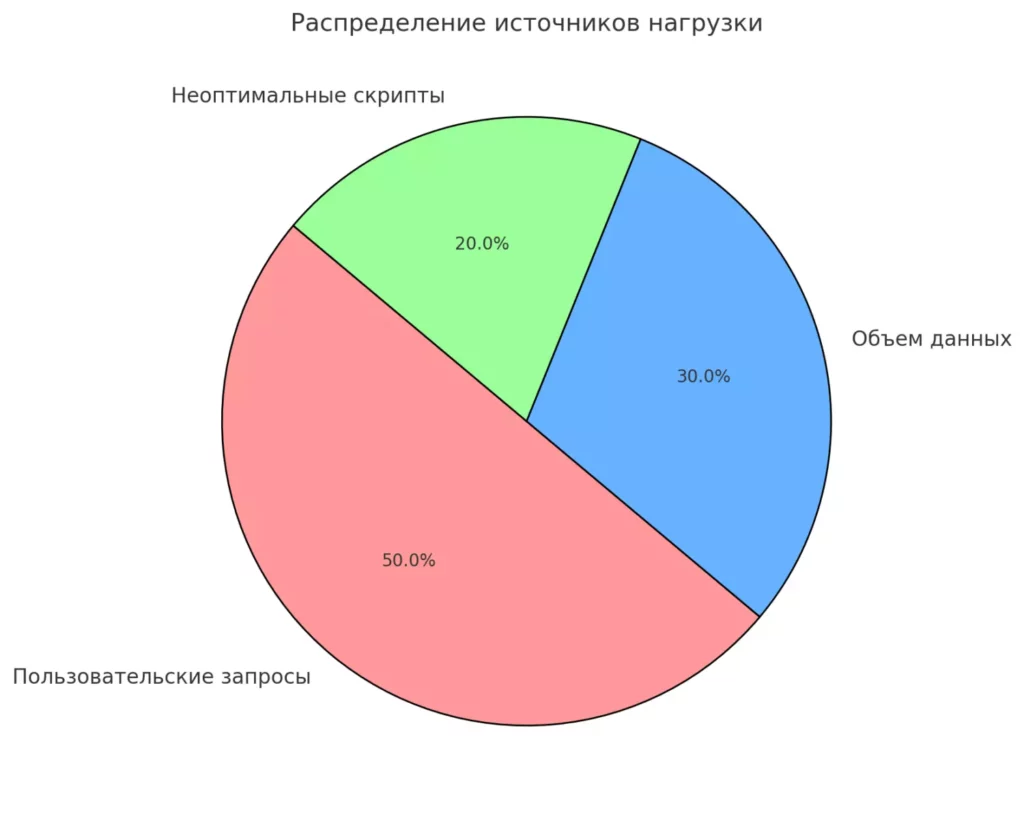
Круговая диаграмма, отображающая распределение источников нагрузки: 50% приходится на пользовательские запросы, 30% на объем данных, и 20% на неоптимальные скрипты
Важно понимать, что высоконагруженная система – это не просто «та, которая много работает». Это system, которая должна эффективно справляться с повышенной нагрузкой и при этом не превращаться в тыкву после полуночи. И да, построить такую систему сложнее, чем собрать икеевский шкаф без инструкции.
Принципы проектирования высоконагруженных систем
Знаете, что общего между архитектурой высоконагруженных систем и строительством небоскреба? В обоих случаях халтура в фундаменте выйдет боком (причем в случае с IT возможно даже дороже). Поэтому давайте разберем ключевые принципы, без которых ваша system рискует превратиться в долгострой с непредсказуемым финалом.
Почему важны отказоустойчивость и высокая доступность?
Представьте, что вы владелец онлайн-магазина, и ваша система легла во время распродаж (звучит как начало триллера, не правда ли?). Каждая минута простоя – это не только потерянные продажи, но и репутационные потери, которые потом придется замаливать скидками и промокодами.
Отказоустойчивость – это способность systems продолжать работу даже когда часть ее компонентов решила взять внеплановый отпуск. А высокая доступность гарантирует, что ваши пользователи смогут пользоваться сервисом в любое время (ну, почти в любое – даже Netflix иногда падает).
Роль мониторинга и метрик
Я люблю сравнивать мониторинг с походом к врачу – лучше регулярно проверяться, чем однажды очнуться в реанимации. Ключевые метрики, за которыми нужно следить:
- Доступность системы – процент времени, когда система работает (и желательно, чтобы это было близко к 100%, а не к шансам найти программиста, который любит документировать код)
- Время отклика – сколько времени проходит от запроса до ответа (если больше 3 секунд, то пользователь уже открыл вкладку с конкурентами)
- Загрузка ресурсов – использование CPU, памяти, дисков (когда графики напоминают кардиограмму при марафоне – это повод напрячься)
- Количество ошибок – частота сбоев и их характер (если растет быстрее, чем зарплаты в IT – у вас проблемы)
Важно понимать, что мониторинг – это не просто красивые графики для отчетов начальству. Это ваша система раннего оповещения, которая должна кричать «Хьюстон, у нас проблемы!» еще до того, как пользователи начнут писать гневные отзывы в соцсетях.
И да, хороший мониторинг похож на параноика – он подозревает проблемы везде. Но в мире высоконагруженных systems лучше быть параноиком, чем оптимистом, верящим, что «оно само починится».
Лучшие практики архитектуры высоконагруженных систем
Знаете, что я больше всего люблю в современной разработке? То, как мы научились превращать монолитного монстра в элегантный танцующий ансамбль микросервисов. И нет, это не просто дань моде (хотя многие думают именно так).
Микросервисная архитектура
По данным последних исследований Gartner, тренд перехода на микросервисную архитектуру продолжает набирать обороты среди компаний всех размеров — от стартапов до корпораций. И это неудивительно — все больше команд «подают на развод» с монолитом. Почему?
Представьте, что ваша system – это ресторан. В монолитной архитектуре один повар делает всё: от салатов до десертов. В микросервисной – у вас есть отдельные специалисты для каждого типа блюд. Если су-шеф по десертам решит уйти в запой, основные блюда всё равно будут готовиться.
Разделение фронтенда и бэкенда
А это, друзья мои, как разделение церкви и государства – чем четче границы, тем меньше конфликтов. Фронтенд занимается тем, что видит пользователь (и да, тем самым модальным окном, которое никто не может закрыть), а бэкенд делает всю грязную работу по обработке данных.
Преимущества такого подхода:
- Можно обновлять интерфейс, не боясь уронить сервер
- Разные команды могут работать независимо (и обвинять друг друга в проблемах тоже независимо)
- Легче масштабировать каждую часть отдельно
Балансировка нагрузки
О, это моя любимая тема! Балансировка нагрузки – как искусство распределения очереди в супермаркете, только в digital. Представьте, что у вас есть несколько касс, и вы решаете, куда направить следующего покупателя.
Основные инструменты:
- Nginx – швейцарский нож балансировки (и да, его действительно можно настроить под любую извращенную схему распределения нагрузки)
- HAProxy – когда хочется чего-то более специализированного (и есть время разобраться в документации размером с «Войну и мир»)
Методы балансировки:
- Round Robin (по кругу) – самый простой способ, как передача микрофона на корпоративе
- Least Connections – отправляем запрос туда, где меньше всего очередь (работает лучше, чем выбор кассы в супермаркете)
- IP Hash – привязываем пользователя к определенному серверу (чтобы не терял свою корзину каждые 5 минут)
И помните: хорошая балансировка нагрузки как хороший дирижер – её работы не видно, пока всё идет хорошо. Зато когда что-то идет не так, все сразу понимают её важность.
Инструменты кластеризации: как заставить серверы работать в команде
Помните, как в детстве мы играли в командные игры? Чем слаженнее работала команда, тем выше были шансы на победу. В мире высоконагруженных систем кластеризация работает по тому же принципу – это как организовать группу серверов в хорошо координированную команду профессионалов.
Основные подходы к кластеризации
Знаете, что общего между футбольной командой и кластером серверов? Правильно – каждый игрок должен точно знать свою роль и уметь подстраховать товарища в случае чего. Давайте разберем основные схемы построения таких «команд»:
- Active-Active – как два вратаря на поле одновременно (да, в нашем случае это законно!):
- Все узлы работают параллельно
- Нагрузка распределяется равномерно
- Выход из строя одного узла не критичен
- Active-Passive – как основной игрок и запасной на скамейке:
- Основной узел делает всю работу
- Резервный готов вступить в игру в любой момент
- Идеально для систем, где важна консистентность данных
Популярные инструменты кластеризации
А теперь давайте заглянем в «раздевалку» и посмотрим на инструменты, которые помогают организовать эту командную работу:
RDN-Group – это как опытный тренер для ваших серверов:
- Автоматическое распределение нагрузки между узлами
- Мониторинг здоровья каждого сервера (и да, даже измеряет «пульс»)
- Мгновенное переключение на резервный узел при проблемах
- Поддержка географически распределенных кластеров (когда ваши «игроки» в разных городах)
Vaiti.io – как система видеоповторов в спорте, только для серверов:
- Детальная аналитика работы кластера
- Предсказание потенциальных проблем
- Автоматическая балансировка ресурсов
- Интеграция с Kubernetes (для тех, кто предпочитает современные подходы)
Вот как это выглядит на практике:
Load Balancer
│
┌─────────────┴─────────────┐
│ │
Node Pool A Node Pool B
┌─────────┬─────────┐ ┌─────────┬─────────┐
│ │ │ │ │ │
Server 1 Server 2 Server 3 Server 4 Server 5 Server 6
Особенности настройки кластеров
А теперь самое интересное – как заставить всё это работать так же слаженно, как швейцарские часы (или хотя бы как китайская их копия):
- Настройка репликации:
- Синхронная – когда все узлы должны подтвердить получение данных (как групповое фото – все должны сказать «сыр»)
- Асинхронная – когда можно продолжать работу, не дожидаясь подтверждения от всех (как рассылка в мессенджере – прочитают, когда смогут)
- Мониторинг кластера:
- Проверка доступности узлов
- Отслеживание задержек репликации
- Контроль равномерности распределения нагрузки
- Анализ производительности (чтобы понять, кто в вашей команде «звезда», а кто «сачок»)
И помните: правильно настроенный кластер – это как хорошо отрепетированный танец. Каждый знает свои движения, и даже если кто-то споткнется, шоу продолжится без заметных для зрителя (то есть пользователя) сбоев.
Теперь, когда мы разобрались с командной работой серверов, самое время поговорить о том, как всё это протестировать. Но об этом – в следующем разделе…
Обработка данных: оптимизация и инструменты
Знаете, что общего между обработкой данных в высоконагруженной системе и попыткой организовать поток людей в метро в час пик? В обоих случаях без правильной организации процесса вы получите хаос и недовольных пользователей.
Использование кеширования
Кеширование – это как заначка в холодильнике: положил заранее что-то часто используемое, чтобы не готовить каждый раз заново. В мире высоких нагрузок это не просто удобство, а вопрос выживания.
Популярные инструменты (испытано на собственных граблях):
- Redis – швейцарский нож кеширования, который может хранить практически всё, от простых строк до сложных структур данных (и да, он действительно настолько быстрый, как обещает документация)
- CacheCloud – для тех, кто любит облачные решения и не боится отдавать свой кэш в чужие руки
- Memcached – старичок, но все еще в строю (особенно если вам нужно что-то простое и надежное, как молоток)
Сервисы очередей
Если ваша система пытается обработать все запросы одновременно – это как пытаться пропустить всю толпу через одну дверь. Спойлер: ничем хорошим это не закончится.
Проверенные решения:
- RabbitMQ – король очередей, который умеет практически всё (включая сложные схемы маршрутизации сообщений)
- Apache Kafka – для тех случаев, когда даже RabbitMQ начинает задыхаться от объемов данных
- ZeroMQ – легковесное решение для тех, кто не хочет разворачивать целый зоопарк
Базы данных
А теперь самое интересное – где хранить все эти терабайты данных так, чтобы их можно было не только сложить, но и быстро достать.
| Тип БД | Когда использовать | Примеры |
| Реляционные | Когда важна консистентность данных и ACID | PostgreSQL, MySQL с шардингом |
| Распределенные | Для огромных объемов данных и высокой доступности | Cassandra, ClickHouse |
| NoSQL | Когда схема данных меняется чаще, чем погода в Питере | MongoDB, CouchDB |
Лайфхак из личного опыта: не бойтесь комбинировать разные типы баз данных. Например, хранить основные данные в PostgreSQL, а логи и аналитику в ClickHouse. Это как в кулинарии – иногда лучший результат получается при смешивании разных ингредиентов.
И помните: выбор базы данных – это как брак, развод обойдется дорого. Поэтому выбирайте с умом и учетом будущего роста.
Масштабирование высоконагруженных систем
Знаете, что объединяет успешный стартап и проблемы с масштабированием? То, что второе неизбежно следует за первым! И тут главное – не превратить рост вашей системы в эпическую драму в стиле «Игры престолов».
Горизонтальное и вертикальное масштабирование: различия
Давайте разберем это на простом примере. Представьте, что ваша system – это ресторан:
- Вертикальное масштабирование – это как увеличение кухни и замена плиты на более мощную
- Горизонтальное масштабирование – открытие новых филиалов по городу
| Параметр | Вертикальное | Горизонтальное |
| Сложность внедрения | Просто (просто докупаем железо) | Сложнее (нужна правильная архитектура) |
| Стоимость | Дорого (железо нынче недешево) | Относительно дешевле при большом масштабе |
| Предел роста | Есть (даже суперкомпьютер имеет лимит) | Практически неограничен |
| Отказоустойчивость | Низкая (одна точка отказа) | Высокая (система продолжит работать при отказе части серверов) |
Автоматическое масштабирование
А это, друзья мои, как умный термостат для вашей системы – сам решает, когда добавить мощности, а когда можно и сэкономить.
Популярные решения (проверено на боевых условиях):
- AWS Auto Scaling – для тех, кто доверил свою инфраструктуру Amazon (и свой банковский счет тоже)
- Kubernetes – если вы любите контейнеры и не боитесь сложных конфигураций
- Docker Swarm – более простая альтернатива Kubernetes (да, такое бывает!)
Из личного опыта: автоматическое масштабирование – это как автопилот в самолете. Да, он прекрасно справляется в 99% случаев, но иногда нужно быть готовым взять управление в свои руки. Особенно когда метрики начинают показывать что-то совсем несуразное, например, внезапный рост трафика в 3 часа ночи (спойлер: обычно это DDoS-атака, а не внезапный наплыв энтузиастов).
Тестирование и обеспечение надежности
Помните старую поговорку «семь раз отмерь, один раз отрежь»? В мире высоконагруженных систем это звучит как «семьсот раз протестируй, один раз деплой». И даже этого может быть недостаточно!
Нагрузочное и стресс-тестирование
Эти два вида тестирования часто путают, как близнецов. Но разница существенная:
Нагрузочное тестирование – это как постепенное повышение веса в спортзале:
- Проверяем поведение systems при ожидаемой нагрузке
- Смотрим, как система справляется с постепенным увеличением нагрузки
- Измеряем время отклика и производительность
Стресс-тестирование – это уже как забег с препятствиями по пересеченной местности:
- Нагружаем систему до отказа (да, намеренно!)
- Смотрим, как она деградирует
- Проверяем, как восстанавливается после падения
Тестирование отказоустойчивости
А это мой любимый вид тестирования – когда мы намеренно ломаем system, чтобы убедиться, что она может «подняться и пойти дальше». Netflix, кстати, довел это до искусства со своей «обезьяной хаоса» (Chaos Monkey).
Методы тестирования:
- Отключение отдельных серверов (внезапно!)
- Имитация сетевых проблем (потеря пакетов, задержки)
- Эмуляция отказа жестких дисков
- Искусственное создание проблем с памятью
Важность мониторинга в реальном времени
Мониторинг – это как видеонаблюдение в банке. Без него вы узнаете о проблемах только когда придут недовольные клиенты (а это уже слишком поздно).
Инструменты, без которых как без рук:
- Prometheus – собирает метрики как белка орехи
- Grafana – превращает сухие цифры в красивые графики (чтобы даже менеджмент понял, что происходит)
- ELK Stack – для тех, кто хочет знать всё о каждом байте в системе
И помните: тестирование – это не то, что можно сделать «потом, когда будет время». Это как страховка – когда она понадобится, будет уже поздно её оформлять.
Безопасность высоконагруженных систем
Давайте поговорим о безопасности – теме, которую многие любят игнорировать до первого серьезного инцидента. Это как страховка от пожара – кажется ненужной тратой, пока не запахнет жареным (в прямом смысле).
Аутентификация и авторизация
Эти два термина путают чаще, чем «принести» и «принестись». Давайте разберемся:
Аутентификация – это как фейс-контроль в элитном клубе:
- Двухфакторная аутентификация (как второй охранник, который перепроверяет)
- Токены доступа (как VIP-браслет на руке)
- Single Sign-On (SSO) – когда один пропуск работает везде
Авторизация – это уже про то, куда именно вам можно пройти в этом клубе:
- Role-Based Access Control (RBAC) – разные бейджики для разных зон
- Attribute-Based Access Control (ABAC) – когда доступ зависит от множества факторов
- Политики безопасности (как свод правил клуба)
Использование SSL/TLS для защиты данных
Передача данных без шифрования – это как отправка любовного письма на открытке. Все могут прочитать! Поэтому:
- Используйте актуальные версии протоколов (TLS 1.3, а не музейный SSL 3.0)
- Настраивайте правильные cipher suites
- Регулярно обновляйте сертификаты (и да, напоминалки в календаре реально помогают)
Защита от атак
А теперь про самое «веселое» – атаки:
DDoS-защита:
- Используйте CDN как первую линию обороны
- Настройте rate limiting (чтобы один особо активный пользователь не положил всю system)
- Имейте план действий при атаке (спойлер: паника – не часть плана)
SQL-инъекции и другие радости:
- Используйте prepared statements (всегда!)
- Валидируйте входные данные (не верьте пользователям, они коварны)
- Регулярно обновляйте зависимости (да, все 100500 npm-пакетов)
И помните: безопасность – это не пункт назначения, а постоянный процесс. Как говорят в определенных кругах: «Параноик – это не диагноз, а квалификация».
Инструменты и технологии для построения высоконагруженных систем
Знаете, как отличить опытного архитектора от новичка? Первый точно знает, что не существует серебряной пули, способной решить все проблемы разом. Зато существует целый арсенал инструментов, каждый из которых хорош в своей области. Давайте разберем самые интересные (и да, я их все попробовал на своей шкуре).
| Категория | Инструмент | Для чего используется | Особенности |
| Контейнеризация | Docker | Упаковка приложений | Как конструктор Lego для взрослых программистов |
| Оркестрация | Kubernetes | Управление контейнерами | Настолько мощный, что может управлять космическим кораблем (но мы используем для веб-приложений) |
| Базы данных | ClickHouse | Аналитика и большие данные | Быстрее, чем мысль вашего начальника о повышении зарплаты |
| Мониторинг | Prometheus + Grafana | Сбор и визуализация метрик | Как видеонаблюдение за вашей системой, только полезнее |
| Кеширование | Redis | In-memory хранилище | Настолько быстрый, что может обогнать свет (ну почти) |
| Балансировка | HAProxy | Распределение нагрузки | Как умный регулировщик на загруженном перекрестке |
| Очереди | Apache Kafka | Обработка событий | Справляется с потоком данных лучше, чем почта с новогодними открытками |
| CI/CD | Jenkins | Автоматизация сборки и деплоя | Трудолюбивый робот, который никогда не спит |
Из личного опыта могу сказать: важно не количество используемых инструментов, а их правильное сочетание. Это как в кулинарии – можно иметь все специи мира, но без понимания, как их правильно смешивать, рискуете приготовить что-то несъедобное.
И еще один важный момент: не гонитесь за модными технологиями только потому, что о них все говорят. Помните историю с MongoDB? Сколько проектов пострадало, потому что её использовали там, где нужен был обычный PostgreSQL…
Кстати, если после прочтения статьи вы загорелись идеей глубже изучить архитектуру высоконагруженных систем (а может, даже начать карьеру архитектора), на KursHub собрана отличная подборка профессиональных курсов по этому направлению. От базовых принципов до продвинутых практик построения отказоустойчивых систем — каждый найдет программу под свой уровень подготовки. Загляните на — уверен, вы найдете там что-то интересное для своего профессионального роста.
Заключение: Как спроектировать эффективную высоконагруженную систему?
Итак, друзья мои, мы с вами прошли длинный путь – от базовых принципов до конкретных инструментов. Пришло время собрать всё воедино и сделать выводы (спойлер: будет интересно).
Главное, что я вынес из своего опыта проектирования высоконагруженных систем:
- Начинайте с правильной архитектуры – это как фундамент дома, переделывать потом будет в разы дороже
- Не пренебрегайте мониторингом – лучше поймать проблему на этапе «что-то не так» чем на стадии «всё упало»
- Тестируйте, тестируйте и еще раз тестируйте – особенно под нагрузкой
- Безопасность должна быть встроена в систему изначально, а не прикручена потом
И самое важное – помните, что высоконагруженная система похожа на живой организм: она требует постоянного внимания, ухода и своевременной профилактики. Нет такого понятия как «настроил и забыл» – есть только «постоянно мониторю и улучшаю».
А теперь небольшой бонус – мой любимый совет начинающим архитекторам: представьте, что ваша system должна пережить зомби-апокалипсис. Серьезно! Если вы спроектируете систему, которая может работать в условиях полного хаоса, то с обычными нагрузками она справится играючи.
И да, удачи вам в построении ваших высоконагруженных систем. Помните: даже самая сложная задача решается – главное, подойти к ней с правильной стороны и нужными инструментами. А если что-то пойдет не так – ну, у вас всегда есть резервная копия. Ведь есть же?

Hexlet vs Skillbox: что выгоднее по цене «за навык», если считать проекты и ревью?
Что лучше — Hexlet или Skillbox, если считать не цену курса, а результат? Где быстрее прокачать навыки, получить проекты в портфолио и не потерять деньги — разберём в статье.

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!