Многопоточность в Golang: эффективное использование горутин и каналов
Go занимает особое место среди языков программирования именно благодаря элегантному решению вопросов параллельного выполнения. Там, где другие языки требуют сложной работы с потоками, мьютексами и семафорами, Go предлагает встроенные горутины и каналы — инструменты, которые делают многопоточное программирование не только эффективным, но и интуитивно понятным.

В этой статье мы рассмотрим, как работает многопоточность в Go на практике.
- Что такое многопоточность в Go
- Goroutine: легковесные потоки Go
- Каналы: коммуникация между горутинами
- Применение горутин и каналов в реальных задачах
- Практический пример: от последовательного к многопоточному коду
- Эффективное использование горутин и каналов
- Частые ошибки и подводные камни
- Заключение
- Рекомендуем посмотреть курсы по golang разработке
Что такое многопоточность в Go
Чтобы понять преимущества многопоточности в Go, давайте сначала разберемся с фундаментальными различиями между последовательным и параллельным выполнением кода.
Скриншот официальной страницы документации Go про concurrency.
В однопоточном приложении все операции выполняются строго по очереди — каждая функция должна полностью завершиться, прежде чем начнется выполнение следующей. Представьте себе конвейер, на котором работает только один сотрудник: он берет деталь, обрабатывает ее от начала до конца, кладет в готовую продукцию и только потом переходит к следующей детали. Такой подход предсказуем и прост для понимания, но крайне неэффективен при работе с задачами, которые можно выполнять параллельно.
Многопоточность кардинально меняет эту картину. Вместо одного работника у нас появляется целая команда, способная обрабатывать несколько деталей одновременно. Однако здесь возникает новая сложность — необходимо координировать работу между участниками процесса, обеспечивать безопасный доступ к общим ресурсам и синхронизировать результаты работы.
Особенность Go заключается в том, что язык был изначально спроектирован с учетом многоядерных процессоров и распределенных систем. Вместо традиционной модели потоков операционной системы, которая требует значительных ресурсов памяти (обычно несколько мегабайт на поток), Go использует собственную модель горутин — легковесных потоков, которые занимают всего несколько килобайт памяти и управляются встроенным планировщиком.
Эта архитектурная особенность позволяет запускать тысячи и даже миллионы goroutine одновременно без существенного влияния на производительность системы. Планировщик Go автоматически распределяет горутины между доступными ядрами процессора, обеспечивая оптимальное использование аппаратных ресурсов.
Результат такого подхода впечатляет: там, где традиционное многопоточное приложение может столкнуться с ограничениями по количеству потоков или проблемами с производительностью при их переключении, Go-приложение продолжает эффективно масштабироваться, используя все доступные вычислительные мощности.
Goroutine: легковесные потоки Go
Определение и особенности
Горутина представляет собой функцию, которая выполняется параллельно с другими частями программы. Однако называть goroutine просто «функцией» было бы серьезным упрощением — это скорее независимая единица выполнения, которая может работать асинхронно относительно основного потока программы.
Ключевое отличие горутин от традиционных потоков операционной системы заключается в их «весе». Если обычный поток требует выделения нескольких мегабайт памяти для своего стека, то goroutine начинает с минимального стека размером всего 2 килобайта, который может динамически расширяться по мере необходимости. Это фундаментальное различие позволяет создавать десятки тысяч горутин без существенного влияния на потребление памяти.
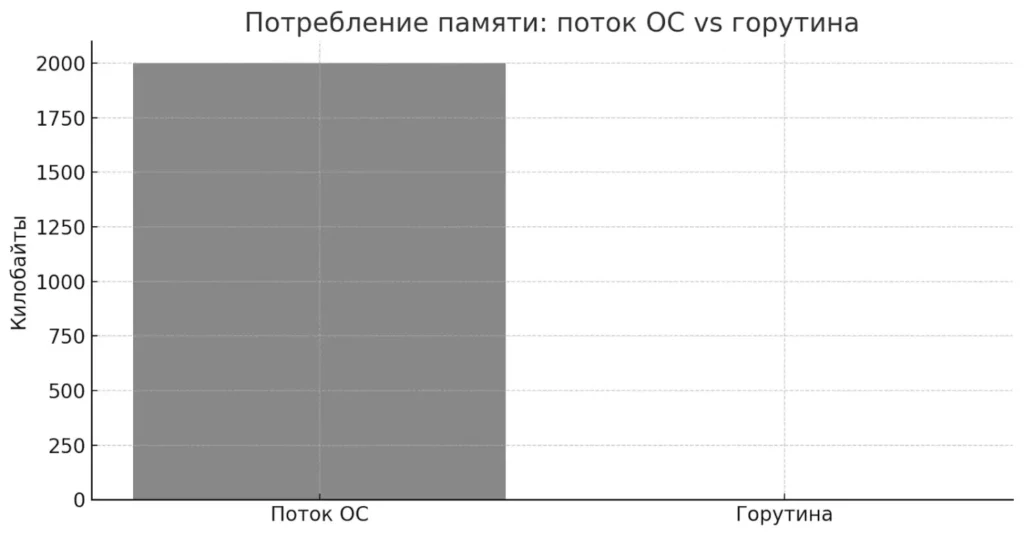
Диаграмма наглядно показывает, что горутины потребляют в сотни раз меньше памяти, чем традиционные потоки ОС. Это одно из ключевых преимуществ Go.
Планировщик Go работает на уровне пользовательского пространства, а не на уровне ядра операционной системы. Это означает, что переключение между goroutine происходит значительно быстрее, чем переключение между потоками ОС. Планировщик использует модель M:N, где M горутин выполняются на N потоках операционной системы, автоматически распределяя нагрузку между доступными ядрами процессора.
Запуск горутины
Синтаксис запуска goroutine поражает своей простотой — достаточно добавить ключевое слово go перед вызовом любой функции:
package main
import (
"fmt"
"time"
)
func printNumbers() {
for i := 1; i <= 5; i++ {
fmt.Printf("Число: %d\n", i)
time.Sleep(1 * time.Second)
}
}
func main() {
go printNumbers() // запуск горутины
fmt.Println("Основная программа продолжает работу")
time.Sleep(6 * time.Second) // ждем завершения горутины
fmt.Println("Программа завершена")
}
Принципиально важная особенность goroutine — они не блокируют выполнение основного потока программы. В приведенном примере после запуска горутины printNumbers() программа немедленно переходит к выполнению следующей строки, выводя сообщение о продолжении работы. Горутина выполняется параллельно, и без явного ожидания (в нашем случае time.Sleep) основная программа могла бы завершиться до того, как goroutine закончит свою работу.
Эта асинхронность является одновременно мощным инструментом и потенциальным источником ошибок — разработчик должен явно управлять жизненным циклом горутин и синхронизацией их работы с основной логикой приложения.
Каналы: коммуникация между горутинами
Что такое канал
Каналы в Go решают фундаментальную проблему многопоточного программирования — безопасную передачу данных между параллельно выполняющимися goroutine. Можно сказать, что каналы играют роль своеобразных «труб», через которые горутины могут обмениваться информацией без риска возникновения состояния гонки (race condition) или других проблем параллельного доступа к данным.
Философия Go в отношении параллельного программирования выражена в известном принципе: «Don’t communicate by sharing memory; share memory by communicating» («Не общайтесь через разделяемую память; разделяйте память через общение»). Каналы воплощают эту идею на практике — вместо того чтобы несколько goroutine одновременно изменяли общую переменную (что требует сложной синхронизации), данные передаются от одной goroutine к другой через канал.
Они обеспечивают автоматическую синхронизацию между горутинами. Когда одна goroutine отправляет данные в канал, а другая их получает, происходит синхронизация — отправитель блокируется до тех пор, пока получатель не будет готов принять данные (в случае небуферизованного канала). Это гарантирует, что данные будут переданы корректно и в нужный момент.
Пример работы
Рассмотрим базовый пример использования канала:
package main
import (
"fmt"
"time"
)
func main() {
// Создаем канал для передачи строк
messageChannel := make(chan string)
// Запускаем горутину, которая отправит сообщение
go func() {
time.Sleep(2 * time.Second) // имитируем работу
messageChannel <- "Данные обработаны!" // отправляем в канал
}()
fmt.Println("Ожидаем результат...")
// Получаем данные из канала (блокирующая операция)
result := <-messageChannel
fmt.Println("Получено:", result)
}
В этом примере демонстрируются две ключевые операции с каналами: отправка данных (messageChannel <- «Данные обработаны!») и получение данных (result := <-messageChannel). Символ стрелки интуитивно показывает направление передачи данных.
Критически важный момент: операция получения данных из канала блокирует выполнение до тех пор, пока в нем не появятся данные. Это означает, что строка result := <-messageChannel приостановит выполнение основной программы и будет ждать, пока горутина не отправит сообщение. Такое поведение делает их мощным инструментом синхронизации — мы можем быть уверены, что код после получения данных из канала выполнится только после того, как goroutine завершит свою работу и отправит результат.

Каналы обеспечивают передачу данных между горутинами. Схема показывает принцип обмена сообщениями без использования общей памяти.
Применение горутин и каналов в реальных задачах
Теоретические знания о goroutine и каналах приобретают истинную ценность только при решении практических задач. Рассмотрим основные сценарии, где многопоточность в Go демонстрирует свои преимущества наиболее ярко.
Обработка параллельных HTTP-запросов. Веб-приложения часто сталкиваются с необходимостью выполнения множественных внешних запросов — к базам данных, API сторонних сервисов или микросервисам. В однопоточном подходе каждый запрос блокирует выполнение до получения ответа, что приводит к неприемлемо долгому времени отклика.
Горутины позволяют запускать все необходимые запросы одновременно, а каналы — собирать результаты по мере их поступления. Типичный сценарий: загрузка профиля пользователя, списка его заказов и рекомендаций может выполняться параллельно, сокращая общее время ответа в несколько раз.
Параллельная обработка больших массивов данных. При работе с большими объемами данных — анализе логов, обработке изображений или вычислительных задачах — данные можно разбить на фрагменты и обработать каждый фрагмент в отдельной goroutine. Каналы служат для передачи обработанных результатов обратно в основной поток программы.
Особенно эффективен такой подход при CPU-интенсивных операциях, где каждая горутина может работать на отдельном ядре процессора. Например, применение фильтров к изображению можно распараллелить по областям, обрабатывая каждую область независимо.
Асинхронные задачи и ожидание результатов. Современные приложения часто выполняют фоновые задачи — отправку уведомлений, генерацию отчетов, резервное копирование данных. Горутины позволяют запустить такие задачи асинхронно, не блокируя основную логику приложения.
Каналы в этом контексте выполняют роль системы уведомлений — основная программа может продолжать работу и периодически проверять через них, завершились ли фоновые задачи, или дожидаться их завершения в нужный момент.
Реализация паттерна Worker Pool. Одним из наиболее эффективных применений горутин является создание пула воркеров — фиксированного количества горутин, которые обрабатывают задачи из общей очереди. Это позволяет контролировать потребление ресурсов и равномерно распределять нагрузку.
Каналы служат как для передачи задач воркерам (input channel), так и для сбора результатов (output channel). Такая архитектура особенно эффективна при обработке потокового ввода данных или в системах массовой обработки сообщений.
Возникает закономерный вопрос: как все это выглядит на практике? Переход от теории к реальному коду часто становится камнем преткновения для разработчиков, поэтому далее мы рассмотрим конкретный пример трансформации однопоточного приложения в многопоточное.
Практический пример: от последовательного к многопоточному коду
Однопоточная версия (пример: шахты и добыча ресурсов)
Рассмотрим практическую задачу, которая наглядно демонстрирует различия между однопоточным и многопоточным подходами. Представим систему добычи ресурсов из нескольких шахт, где каждая шахта содержит определенные материалы, а процесс извлечения требует времени.
package main
import (
"fmt"
"time"
)
func mining(name string, progress *int, resources *[]string) {
if *progress < len(*resources) {
time.Sleep(2 * time.Second) // имитация времени добычи
fmt.Printf("В шахте «%s» найдено: «%s»\n", name, (*resources)[*progress])
*progress++
mining(name, progress, resources) // рекурсивное продолжение
}
}
func main() {
mine1 := []string{"железо", "золото", "уголь", "железо"}
mine1Progress := 0
mine2 := []string{"медь", "серебро", "уголь"}
mine2Progress := 0
// Последовательная обработка шахт
mining("Северная", &mine1Progress, &mine1)
mining("Южная", &mine2Progress, &mine2)
}
В этой реализации шахты обрабатываются строго поочередно — сначала полностью исчерпывается «Северная», затем начинается работа с «Южной». Общее время выполнения составляет сумму времени обработки всех ресурсов (14 секунд для данного примера).
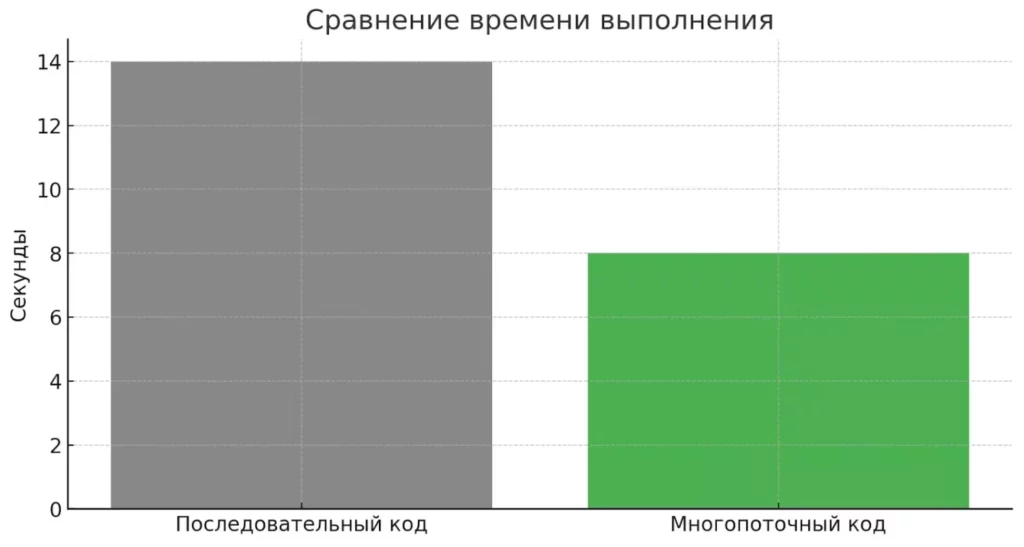
Многопоточный вариант кода работает почти в два раза быстрее. Диаграмма фиксирует разницу: 14 секунд против 8.
Ограничения такого подхода очевидны: если у нас есть достаточно ресурсов (в нашей метафоре — буров и рабочих), мы теряем время, заставляя оборудование простаивать, пока обрабатывается одна шахта за раз.
Многопоточная версия
Теперь трансформируем код для использования горутин и каналов:
package main
import (
"fmt"
"time"
)
type Mine struct {
name string
resources []string
progress int
finished chan bool
}
func dig(mine *Mine) {
for mine.progress < len(mine.resources) {
time.Sleep(2 * time.Second)
fmt.Printf("В шахте «%s» найдено: «%s»\n",
mine.name, mine.resources[mine.progress])
mine.progress++
}
mine.finished <- true // сигнализируем о завершении
}
func main() {
mines := []*Mine{
{"Северная", []string{"железо", "золото", "уголь", "железо"}, 0, make(chan bool)},
{"Южная", []string{"медь", "серебро", "уголь"}, 0, make(chan bool)},
{"Восточная", []string{"алмазы", "золото"}, 0, make(chan bool)},
}
// Запускаем все шахты одновременно
for _, mine := range mines {
go dig(mine)
}
// Ожидаем завершения всех шахт
for _, mine := range mines {
<-mine.finished
}
fmt.Println("Все шахты отработали")
}
В многопоточной версии принципиально изменилась логика выполнения. Все шахты начинают работу одновременно благодаря goroutine, а каналы finished обеспечивают синхронизацию — основная программа ждет завершения всех горутин перед своим завершением.
Результат впечатляет: общее время выполнения теперь определяется самой «глубокой» шахтой (8 секунд вместо 14), а в консоли мы видим перемешанные сообщения от разных шахт, что наглядно демонстрирует параллельное выполнение.
Ключевые изменения в архитектуре: структура Mine инкапсулирует данные и канал для синхронизации, функция dig работает с конкретным экземпляром шахты, а основная логика координирует запуск и ожидание завершения всех горутин.
Эффективное использование горутин и каналов
Ограничение количества
Несмотря на легковесность goroutine, неконтролируемое их создание может привести к серьезным проблемам. Запуск миллионов горутин одновременно способен исчерпать память системы и перегрузить планировщик Go, что парадоксальным образом снизит производительность вместо ее повышения.
Практическое решение этой проблемы — использование буферизованных каналов в качестве семафора для ограничения количества одновременно работающих горутин:
package main
import (
"fmt"
"sync"
"time"
)
func processTask(id int, semaphore chan struct{}, wg *sync.WaitGroup) {
defer wg.Done()
// Получаем разрешение на выполнение
semaphore <- struct{}{}
defer func() { <-semaphore }() // освобождаем слот после завершения
fmt.Printf("Обработка задачи %d начата\n", id)
time.Sleep(2 * time.Second) // имитация работы
fmt.Printf("Задача %d завершена\n", id)
}
func main() {
const maxWorkers = 3
const totalTasks = 10
semaphore := make(chan struct{}, maxWorkers) // буферизованный канал
var wg sync.WaitGroup
for i := 1; i <= totalTasks; i++ {
wg.Add(1)
go processTask(i, semaphore, &wg)
}
wg.Wait() // ждем завершения всех задач
fmt.Println("Все задачи выполнены")
}
В этом примере буферизованный канал semaphore выполняет роль ограничителя — в любой момент времени может работать не более трех goroutine. Остальные блокируются на операции semaphore <- struct{}{} до тех пор, пока не освободится слот.
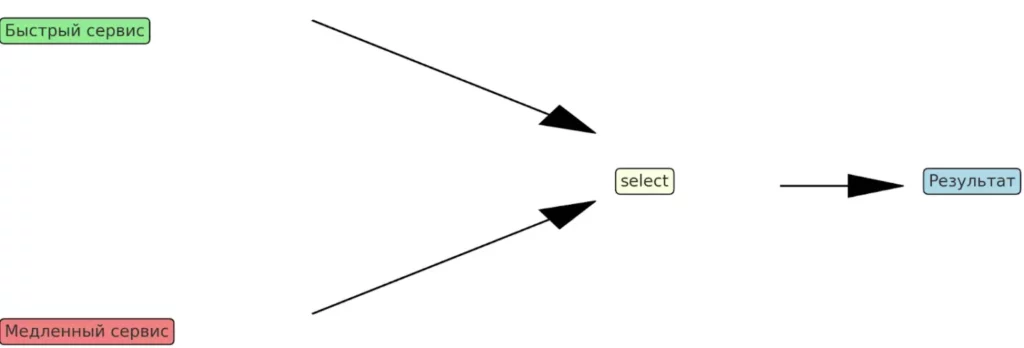
Конструкция select выбирает первый готовый результат из нескольких источников. Иллюстрация упрощает понимание работы с конкурентными запросами.
Использование select для нескольких каналов
Конструкция select представляет собой мощный инструмент для работы с множественными каналами, позволяя goroutine реагировать на события из разных источников:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan string)
ch2 := make(chan string)
// Горутина 1: быстрый ответ
go func() {
time.Sleep(1 * time.Second)
ch1 <- "Результат из быстрого сервиса"
}()
// Горутина 2: медленный ответ
go func() {
time.Sleep(3 * time.Second)
ch2 <- "Результат из медленного сервиса"
}()
// Ожидаем первый доступный результат
select {
case msg1 := <-ch1:
fmt.Println("Получен:", msg1)
case msg2 := <-ch2:
fmt.Println("Получен:", msg2)
case <-time.After(2 * time.Second): // таймаут
fmt.Println("Превышено время ожидания")
}
}
Конструкция select блокируется до тех пор, пока хотя бы один из каналов не станет готовым для операции. Это особенно полезно в сценариях, где мы хотим получить результат от самого быстрого источника данных или установить таймаут для операций.
Важная особенность select — если несколько каналов готовы одновременно, выбор между ними происходит случайным образом, что предотвращает «голодание» медленных каналов в пользу быстрых.
Такой подход находит применение в реализации балансировщиков нагрузки, системах с резервированием, а также при работе с внешними API, где важно получить ответ как можно быстрее, независимо от источника.
Частые ошибки и подводные камни
Многопоточное программирование в Go, несмотря на элегантность горутин и каналов, таит в себе ряд типичных ловушек, с которыми сталкиваются разработчики на практике.
Утечки памяти из-за неконтролируемых горутин
Одна из наиболее коварных проблем — goroutine, которые продолжают работать после того, как их результаты больше не нужны основной программе. Классический пример: горутина ожидает данные из канала, но никто больше не собирается в него писать. Такая goroutine будет существовать до завершения программы, потребляя память и ресурсы планировщика.
Особенно опасны бесконечные циклы в goroutine без механизмов остановки. В веб-приложениях это может привести к накоплению «мертвых» горутин с каждым новым запросом, что в итоге исчерпает память сервера.
Блокировки при неправильной работе с каналами
Небуферизованные каналы требуют наличия готового получателя в момент отправки данных. Попытка записи в канал, из которого никто не читает, приведет к permanent блокировке goroutine. Аналогично, чтение из пустого канала заблокирует горутину до появления данных.
Особую опасность представляют каналы в циклах — если логика неверна, можно легко создать ситуацию взаимной блокировки (deadlock), когда несколько goroutine ждут друг друга и программа полностью останавливается.
Состояние гонки при доступе к разделяемым данным
Хотя каналы решают многие проблемы синхронизации, разработчики иногда пытаются «оптимизировать» код, обращаясь к обычным переменным из нескольких goroutine одновременно. Результат предсказуем — непредсказуемое поведение программы, когда результаты зависят от случайного порядка выполнения операций.
Типичная ошибка: использование счетчиков или флагов без proper синхронизации. Go предоставляет пакет sync с мьютексами и атомарными операциями, но лучший подход — проектирование архитектуры таким образом, чтобы каждая горутина работала со своими данными, а обмен происходил через каналы.
Забытые каналы и goroutine leaks
Создание канала без последующего его закрытия может привести к накоплению ресурсов. Особенно важно закрывать каналы в producer-consumer сценариях — это сигнализирует получателям о том, что больше данных не будет.
Неправильная обработка паники (panic) в goroutine также создает проблемы. Паника в горутине завершает только эту горутину, но может оставить связанные каналы в неопределенном состоянии, что приведет к блокировкам других частей программы.
Неэффективное использование буферизации каналов
Чрезмерно большие буферы каналов маскируют проблемы архитектуры, создавая ложное ощущение производительности. Слишком маленькие буферы, наоборот, могут привести к частым блокировкам и снижению пропускной способности.
Критически важно понимать семантику закрытия каналов: отправка в закрытый канал вызывает панику, а чтение из закрытого канала возвращает нулевое значение типа. Многие ошибки возникают именно из-за неправильной обработки этих ситуаций.
Заключение
Многопоточность в Go представляет собой элегантное решение сложной проблемы параллельного выполнения задач. Горутины и каналы — это не просто синтаксический сахар, а фундаментальные инструменты, которые позволяют разработчикам создавать высокопроизводительные приложения без погружения в сложности низкоуровневого управления потоками.
- Многопоточность в Go упрощает работу. Горутины и каналы заменяют сложные механизмы потоков ОС.
- Горутины легковесны. Они потребляют минимум памяти и позволяют запускать тысячи параллельных задач.
- Каналы делают синхронизацию безопасной. Данные передаются без прямого доступа к памяти.
- Select повышает гибкость. С его помощью можно обрабатывать события из разных источников.
- Основные ошибки можно избежать. Достаточно контролировать количество горутин и корректно закрывать каналы.
Если вы только начинаете осваивать программирование и хотите глубже понять, как работают потоки в Go, рекомендуем обратить внимание на подборку курсов по Go-разработке. В них есть как теоретическая база, так и практические задания, которые помогут быстрее закрепить знания.
Рекомендуем посмотреть курсы по golang разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Искусство написания сервиса на Go
|
GOLANG NINJA
14 отзывов
|
Цена
38 565 ₽
92 096 ₽
|
|
Длительность
5 месяцев
|
Старт
в любое время
|
Подробнее |
|
Go-разработчик
|
Нетология
46 отзывов
|
Цена
87 900 ₽
195 360 ₽
с промокодом kursy-online
|
От
4 070 ₽/мес
0% на 36 месяцев
8 041 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
2 раз в неделю после 18:00 МСК
|
Подробнее |
|
Искусство работы с ошибками и безмолвной паники в Go
|
GOLANG NINJA
14 отзывов
|
Цена
26 545 ₽
39 620 ₽
|
|
Длительность
9 недель
|
Старт
в любое время
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.