Model Context Protocol: революция в интеграции AI с внешними сервисами
Model Context Protocol (MCP) — это новый открытый протокол от Anthropic, который стандартизирует взаимодействие между языковыми моделями и внешними системами. Представленный в конце 2024 года, MCP стал прорывом в области интеграции ИИ с реальным миром, позволяя моделям подключаться к базам данных, API, сервисам и даже умным устройствам.

Суть идеи Anthropic проста: создать «универсальный переходник» для AI-систем (своего рода USB-C в мире искусственного интеллекта), обеспечивающий стандартизированный формат обмена данными между LLM и внешними источниками. Благодаря этому протоколу модели получают доступ к актуальной информации и инструментам, что существенно повышает их точность и практическую ценность в решении реальных задач.
За несколько месяцев с момента появления Model Context Protocol уже получил широкое распространение в экосистеме AI-инструментов, включая популярные IDE и интерфейсы для работы с языковыми моделями. Это неудивительно, ведь протокол решает одну из ключевых проблем современных LLM — ограниченность предобученными данными.
- MCP: Что это и зачем нужно?
- Архитектура и основные компоненты MCP
- Три ключевых элемента MCP
- Как MCP взаимодействует с ИИ
- Стандартизированные форматы ввода/вывода и их роль в MCP
- Почему именно JSON?
- Структура обмена данными в MCP
- Практические преимущества стандартизации
- Преимущества MCP: Почему это важно?
- Сравнение MCP с альтернативными подходами (LangChain, REST API, GraphQL, Function Calling)
- MCP vs Function Calling
- MCP vs REST API
- MCP vs GraphQL
- MCP vs LangChain
- Когда какой подход выбирать?
- Как работает MCP? Пошаговый разбор
- Общий принцип работы MCP
- Примеры работы MCP в реальных сценариях
- Как создать собственный MCP-сервер?
- 1. Настройка базового сервера
- 2. Определение доступных инструментов
- 3. Реализация логики инструмента
- 4. Настройка транспорта и запуск сервера
- 5. Регистрация сервера в клиентском приложении
- Ограничения и потенциальные проблемы MCP
- Часто задаваемые вопросы
- Какие компании уже используют MCP?
- Поддерживают ли современные LLM (ChatGPT, Claude) этот стандарт?
- Можно ли MCP использовать для автономных систем без интернета?
- Насколько сложно интегрировать MCP в существующую инфраструктуру?
- Есть ли альтернативы MCP для схожих задач?
- Заключение
MCP: Что это и зачем нужно?
Итак, что же такое MCP, о котором все вдруг заговорили? Если совсем по-простому — это открытый протокол для стандартизации взаимодействия между языковыми моделями и внешними системами. Своего рода «цифровой переводчик», позволяющий LLM общаться с окружающим цифровым миром, не полагаясь исключительно на информацию, заложенную в них при обучении (которая, как мы знаем, имеет свойство устаревать быстрее, чем вы успеваете сказать «а вот еще одна версия ChatGPT»).
На практике это выглядит примерно так: вы общаетесь с нейросетью, просите ее найти какую-то информацию в вашей корпоративной базе знаний, а она — вместо того, чтобы честно признаться «извините, я не знаю, что у вас там в Confluence» или, что еще хуже, начать фантазировать — обращается через Model Context Protocol к этому самому Confluence и выдает актуальную информацию. Магия? Нет, просто грамотная стандартизация процесса.
Примеров применения — море разливанное:
- Чат-боты поддержки, подключенные к внутренним системам компании (CRM, базы знаний, тикетные системы)
- Автоматизация рутинных задач разработки (когда нейросеть не просто пишет код, но и тестирует его, обращаясь к базе данных или API)
- Бизнес-ассистенты, способные в человекочитаемом формате вытаскивать данные из SQL, составлять отчеты и даже принимать простые решения
Представьте, что вы сидите в своем любимом IDE и просите AI-ассистента не просто написать код, а «посмотреть, что там в логах, найти в документации решение проблемы и исправить ошибку в коде» — и он действительно это делает. А не просто генерирует оптимистичное «вот решение вашей проблемы» на основе того, что ему кажется, будто должно было бы сработать. В этом и есть фундаментальное отличие агентных систем с MCP от обычных языковых моделей.
Архитектура и основные компоненты MCP
Три ключевых элемента MCP
Если бы это была сказка, я бы начал с «жили-были три брата — Хост, Клиент и Сервер», но поскольку мы серьезные люди, занимающиеся серьезными технологиями, давайте рассмотрим эту троицу с должной степенью технической строгости (и щепоткой иронии, куда ж без нее).
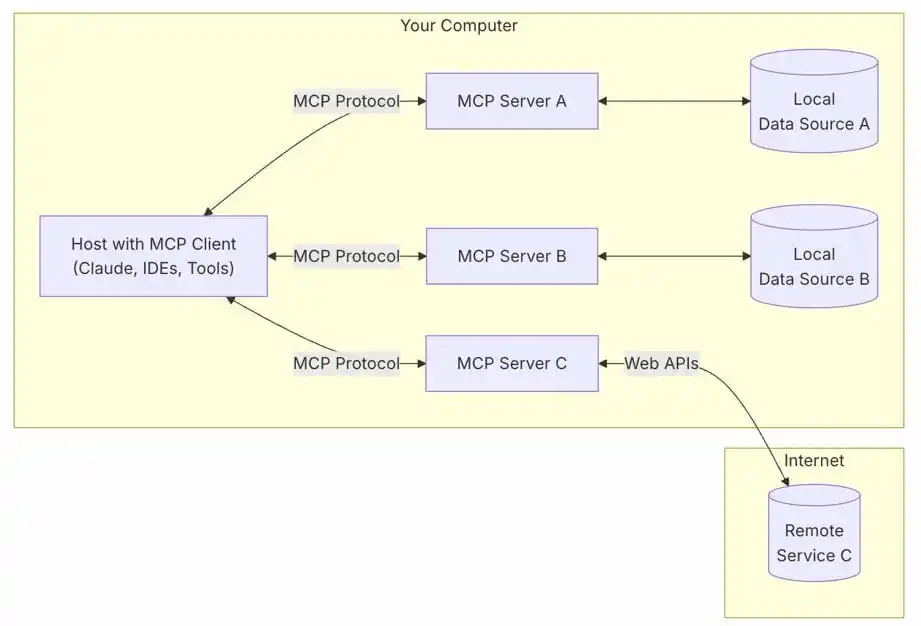
Схематическое изображение основной архитектуры
Host (Хост) — это своего рода «дирижер оркестра» в системе Model Context Protocol, который координирует всю симфонию взаимодействий. Обычно это приложение, с которым непосредственно общается пользователь в чате — такое как Claude Desktop, Cursor IDE или любой другой интерфейс к LLM. Хост управляет жизненным циклом клиент-сервер, принимает решения об авторизации, и, что самое главное, контролирует общение с самой языковой моделью. Другими словами, это тот, кто решает, когда и с кем «познакомить» нейросеть.
Client (Клиент) — это та часть системы, которая занимается коммуникацией между хостом и сервером. Представьте его как дипломатического посла, который говорит на двух языках и обеспечивает эффективный обмен сообщениями. Клиент обычно является частью хост-приложения и поддерживает соединения строго 1:1 с серверами. Он отслеживает возможности сервера, маршрутизирует сообщения и согласовывает версии протокола — словом, делает всю ту техническую работу, о которой пользователь даже не подозревает.
Server (Сервер) — это «мост в реальный мир» для LLM, предоставляющий доступ к внешним системам через их API. Сервер выставляет наружу специфичный для MCP интерфейс, с которым взаимодействует клиент. Обычно это небольшая программа на любом языке программирования (чаще всего Python или TypeScript), которая, по сути, просто связывает внешнюю систему и MCP-клиент.
| Компонент | Основные функции | Пример |
|---|---|---|
| Хост | • Управление жизненным циклом
• Авторизация пользователей • Агрегация контекста • Общение с LLM |
Claude Desktop, Cursor IDE |
| Клиент | • Поддержка соединений с серверами
• Маршрутизация сообщений • Управление возможностями • Согласование протокола |
Является частью хост-приложения |
| Сервер | • Предоставление Tools (инструментов)
• Предоставление Resources (ресурсов) • Предоставление Prompts (шаблонов) |
MCP-сервер для PostgreSQL, GitHub, Confluence |
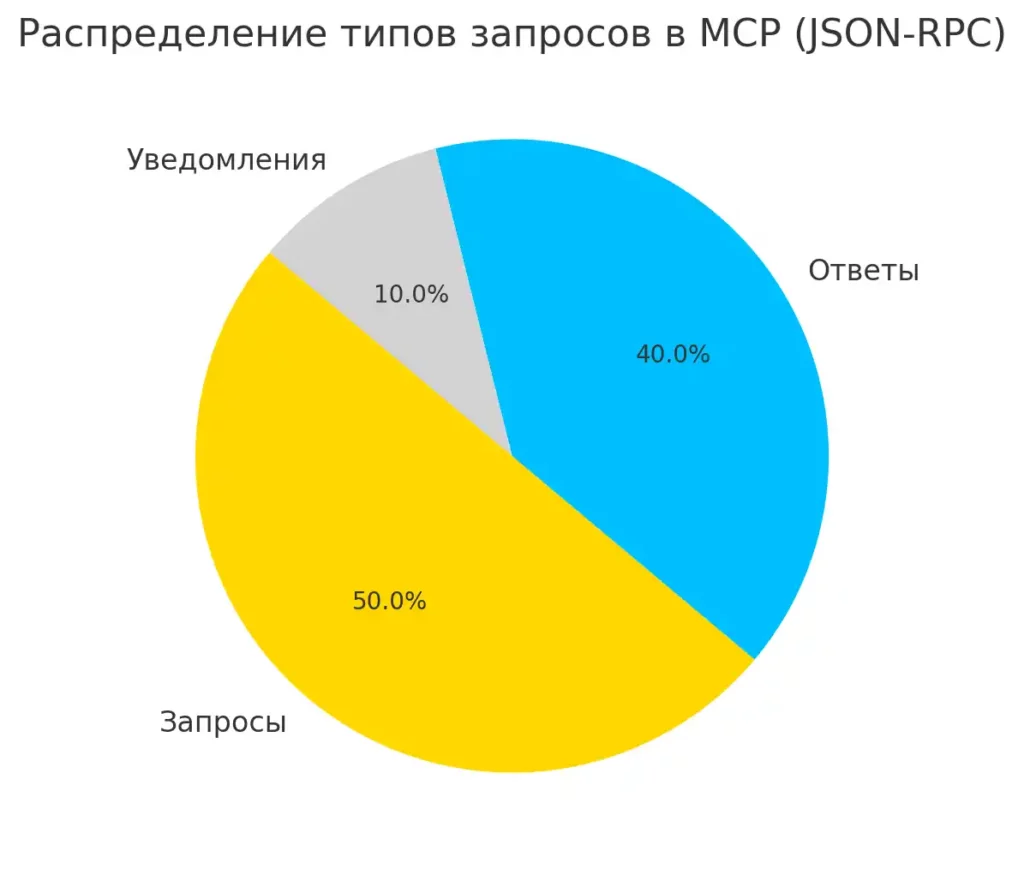
Круговая диаграмма распределения типов запросов в MCP (JSON-RPC)
Как MCP взаимодействует с ИИ
Теперь перейдем к самому интересному: как же эта система на самом деле работает? На базовом уровне Model Context Protocol использует JSON-RPC 2.0 как стандарт общения — технологию достаточно древнюю, чтобы быть надежной, и достаточно простую, чтобы не вызывать лишних сложностей (не то что эти модные GraphQL и gRPC со своими схемами и типами, которые, кажется, существуют только для того, чтобы усложнять жизнь честным разработчикам).
В основе протокола лежат три типа сообщений: запросы (для инициирования операций), ответы (собственно, чтобы на эти запросы отвечать) и уведомления (односторонние сообщения, не требующие ответа — что-то вроде «я просто оставлю это здесь»).
Когда пользователь что-то спрашивает у LLM, и модель понимает, что для ответа ей нужны дополнительные данные или выполнение каких-то действий, она может запросить у хоста вызов определенного инструмента. Хост, в свою очередь, передает этот запрос через клиент соответствующему серверу, который выполняет необходимые действия (например, запрос к API или поиск в базе данных) и возвращает результат обратно в том же направлении: сервер → клиент → хост → модель.
И вот тут-то начинается настоящая магия: модель получает актуальные данные из реального мира и может генерировать ответ на их основе, а не гадать на кофейной гуще предобученных данных. Это как разница между «я думаю, что в этой базе данных должно быть примерно вот это» и «я только что проверил, и там точно вот это».
Стандартизированные форматы ввода/вывода и их роль в MCP
Если вы когда-нибудь пытались договориться о чем-то со своим партнером по проекту без общего понимания терминов, то наверняка знаете, что такое «коммуникационный ад». Представьте, что один говорит на языке JSON, другой мыслит XML-структурами, а третий вообще предпочитает неструктурированный текст с эмодзи вместо ключевых слов. Примерно такая же какофония происходила (и часто до сих пор происходит) при взаимодействии различных систем с языковыми моделями.
Model Context Protocol решает эту проблему элегантно и бескомпромиссно — как Александр Македонский разрубил Гордиев узел, так и MCP разрубает узел интеграционных проблем, предлагая единый стандартизированный формат обмена данными. И этот формат, к счастью для всех разработчиков, страдавших от XML-теней прошлого, — наш старый добрый друг JSON.
Почему именно JSON?
Выбор JSON как основного формата для MCP не случаен и, признаться, довольно предсказуем — это всё равно что выбрать воду в качестве основы для чая (хотя, подозреваю, найдутся энтузиасты, предпочитающие заваривать чай на молоке или, не дай бог, на коле). JSON прост, лаконичен, человекочитаем, машиночитаем и, что немаловажно, не вызывает аллергической реакции у большинства современных разработчиков.
Но MCP идет дальше простого использования JSON — протокол определяет строгие схемы для различных типов сообщений:
json
{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "database_query",
"arguments": {
"query": "SELECT * FROM customers WHERE region = 'Europe'",
"limit": 10
}
},
"id": "request-12345"
}
Такая структуризация обеспечивает несколько ключевых преимуществ:
- Предсказуемость взаимодействия — и клиент, и сервер точно знают, какие поля ожидать и в каком формате. Это как в хорошем танце, где партнеры не наступают друг другу на ноги, потому что следуют одной и той же хореографии.
- Валидация на лету — благодаря JSON Schema, встроенной в протокол, каждое сообщение может быть проверено на корректность еще до его обработки. «Неправильные танцоры» отсеиваются на входе, не создавая проблем дальше по цепочке.
- Самодокументированность — структура сообщений MCP интуитивно понятна и несет в себе информацию о своем назначении. Даже если вы впервые сталкиваетесь с протоколом, взглянув на JSON, вы сразу поймете, что здесь происходит (в отличие, например, от SOAP, где без трехтомника спецификаций не разобраться даже в простейшем запросе).
- Расширяемость — формат позволяет легко добавлять новые поля и типы данных без нарушения обратной совместимости. Это как модульная мебель — хотите добавить еще одну секцию? Пожалуйста, и всё прекрасно состыкуется с уже имеющимися компонентами.
Структура обмена данными в MCP
В основе всех взаимодействий по протоколу лежит тройка базовых структур: запросы (requests), ответы (responses) и уведомления (notifications). Эта троица напоминает классическую схему «вопрос-ответ-реплика» из хорошей беседы, где каждый знает, когда ему говорить, а когда слушать.
Запросы содержат метод (что нужно сделать), параметры (с какими данными) и уникальный идентификатор (чтобы не путать разные разговоры). Примерно как если бы вы сказали коллеге: «Эй, Боб (id), не мог бы ты сделать кофе (метод) с двумя ложками сахара и без молока (параметры)?».
Ответы всегда соотносятся с конкретным запросом по id и содержат либо результат выполнения, либо информацию об ошибке. Это как если бы Боб ответил: «Вот твой кофе, как ты просил» или «Извини, кофемашина сломалась».
Уведомления — это односторонние сообщения, не требующие ответа. Представьте, что вы просто сообщаете всем: «Я ухожу на обед» — никто не обязан на это как-то реагировать, но информация доведена до сведения.
При этом, в отличие от многих других протоколов, MCP жестко определяет не только формат, но и «грамматику» общения между компонентами. Языковая модель не может просто так начать генерировать произвольные запросы — всё происходит в рамках чётко определенного процесса с проверкой возможностей, согласованием параметров и контролем потока данных.
Практические преимущества стандартизации
Все крупные игроки рынка ИИ-интеграций — от Composio до инженеров на DEV.to и аналитиков на Хабре — сходятся в одном: стандартизация форматов данных критически важна для успешного взаимодействия с языковыми моделями. И дело не только в удобстве разработки.
Представьте ситуацию: ваша LLM неправильно интерпретировала запрос пользователя «найти все заказы за май» и вместо этого удалила все записи за этот период. Кошмар, правда? Стандартизированный формат запросов и ответов с четкой типизацией данных делает такие сценарии практически невозможными.
Более того, стандартизация позволяет:
- Создавать универсальные инструменты для мониторинга — когда формат всех сообщений известен заранее, можно легко строить системы для отслеживания производительности, выявления узких мест и анализа использования ресурсов.
- Обеспечивать совместимость между различными версиями — даже если протокол эволюционирует (а он будет), базовая структура остается неизменной, что гарантирует работоспособность старых интеграций с новыми компонентами.
- Упрощать отладку — когда все сообщения имеют предсказуемую структуру, найти проблему становится значительно проще. Это как искать иголку не в стоге сена, а в аккуратно организованной коробке с отделениями.
В мире, где каждая технологическая компания стремится создать свой «уникальный» протокол интеграции (и заодно привязать вас к своей экосистеме крепче, чем суперклей), подход Anthropic с открытым и стандартизированным форматом обмена данными выглядит как глоток свежего воздуха. Это похоже на появление USB в мире компьютерных интерфейсов — внезапно всем стало гораздо проще жить, и только производители проприетарных кабелей остались недовольны.
Впрочем, не будем забывать, что любая, даже самая продуманная стандартизация — это компромисс между гибкостью и предсказуемостью. И хотя MCP нашел хороший баланс, в некоторых специфических сценариях жесткие рамки протокола могут потребовать дополнительных обходных решений. Но об этом мы поговорим позже, когда будем рассматривать практические примеры использования MCP в реальных проектах.
Преимущества MCP: Почему это важно?
Не знаю, как вы, а я уже достаточно устал от ситуаций, когда нейросеть уверенно рассказывает мне про содержимое документа, которого не существует, или о функциональности API, которая давно устарела. Это как спрашивать дорогу у человека, который был в этом городе пять лет назад и пытается вспомнить, было ли на том перекрестке кафе или все-таки аптека. Занимательно, но не особо полезно.
И вот тут на сцену выходит Model Context Protocol — как рыцарь на белом коне, готовый спасти нас от этой информационной неопределенности. Но чем же он так хорош? Давайте разберемся по пунктам (я люблю пункты — они создают иллюзию порядка в хаотичном мире технологий).
Во-первых, MCP унифицирует интеграцию внешних систем с LLM. Это может звучать несколько абстрактно, пока вы не столкнетесь с необходимостью подключить десяток разных сервисов к своему ИИ-решению. В мире без MCP каждая интеграция — это уникальный снежок, требующий индивидуального подхода (и, как правило, индивидуальных страданий). Model Context Protocol же предлагает единый стандарт: один протокол для связи с любым инструментом, будь то база данных, API или, не дай бог, ваша умная кофеварка.
Во-вторых, и это, пожалуй, самое важное: MCP обеспечивает доступ LLM к тем системам, которые могут быть чисто внутренними и даже не иметь доступа в интернет. Вся та корпоративная информация, которая никогда не попадала в обучающие датасеты — внутренние вики, документация, кодовая база, тикеты — теперь может быть доступна модели в режиме реального времени. Это как дать очки дальнозоркому — внезапно он видит то, что находится прямо перед ним.
В-третьих, Model Context Protocol позволяет модели оставаться в пределах единого контекста при решении многоэтапной задачи. Для тех, кто не погружен в кухню работы с LLM: это значительное преимущество, поскольку модели часто теряют нить разговора, когда решают сложные задачи, требующие множества шагов. С MCP модель может выполнять последовательные действия, не теряя контекста — как хороший шеф-повар, который готовит пять блюд одновременно и помнит, на каком этапе находится каждое.
| Аспект | Традиционный подход | С использованием MCP |
|---|---|---|
| Актуальность данных | Зависит от даты обучения модели | Данные в реальном времени из подключенных источников |
| Доступ к внутренним ресурсам | Отсутствует или требует сложной интеграции | Унифицированный доступ через стандартный протокол |
| Последовательное выполнение задач | Ограничено объемом контекста | Возможность выполнять многоэтапные задачи без потери контекста |
| Безопасность данных | Данные должны быть предоставлены в промпте | Данные могут оставаться внутри корпоративной сети |
| Масштабируемость | Требует индивидуальных интеграций для каждой системы | Единый стандарт для всех интеграций |
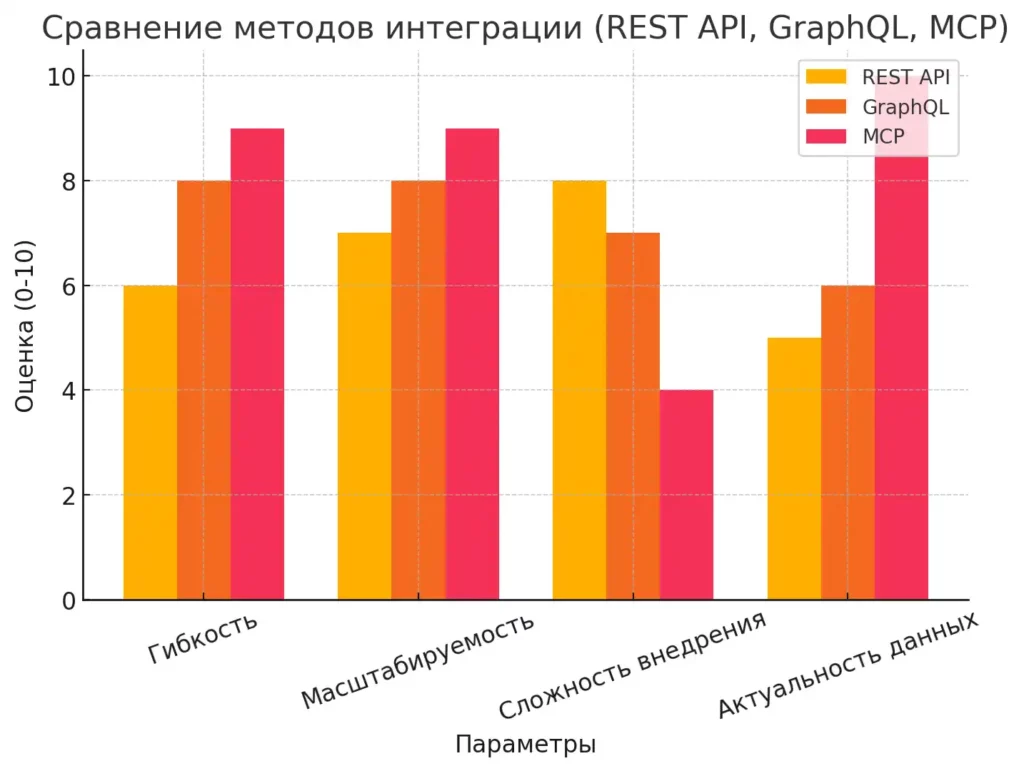
Столбчатая диаграмма сравнения методов интеграции показывает, как REST API, GraphQL и MCP оцениваются по 4 ключевым параметрам
К тому же, если сравнивать Model Context Protocol с традиционными подходами к интеграции, такими как REST API или GraphQL, он выигрывает за счет своей ориентированности именно на работу с LLM. Это не просто «еще один способ связи систем» — это протокол, созданный с учетом специфики работы языковых моделей, их контекстной природы и потребностей в структурированных данных.
В итоге, MCP — это не революция, но значительная эволюция в мире ИИ-интеграций. Это тот случай, когда стандартизация действительно упрощает жизнь вместо того, чтобы создавать новые проблемы (что, надо признать, случается с технологическими стандартами чаще, чем хотелось бы).
Сравнение MCP с альтернативными подходами (LangChain, REST API, GraphQL, Function Calling)
Если вы похожи на меня, то наверняка знаете, что в мире технологий редко бывает «единственно верный путь». Обычно существует как минимум полдюжины способов решить одну и ту же задачу, и каждый из них будет яростно отстаиваться своими адептами (порой с религиозным пылом, который заставил бы покраснеть средневековых инквизиторов). Интеграция языковых моделей с внешними системами — не исключение. Так давайте же посмотрим, как Model Context Protocol соотносится с другими популярными подходами, и выясним, когда стоит выбирать именно его, а когда, возможно, лучше обратить внимание на альтернативы.
MCP vs Function Calling
Начнем с самого близкого родственника — механизма Function Calling, который используется в API OpenAI (и не только). По сути, это возможность для языковой модели «вызывать функции», описанные разработчиком, получая от них данные и принимая решения на их основе.
Сходства:
- Обе технологии позволяют LLM взаимодействовать с внешними системами
- Обе используют JSON для структурирования данных
- Обе требуют описания доступных функций/инструментов
Различия:
- Function Calling — это скорее возможность модели, чем протокол взаимодействия
- MCP предоставляет стандартизированный жизненный цикл взаимодействия (инициализация, операции, завершение)
- В MCP есть четкое разделение ролей между хостом, клиентом и сервером
- MCP ориентирован на длительные, многоэтапные взаимодействия, а не на отдельные вызовы функций
Если Function Calling — это как звонок другу с конкретным вопросом, то MCP — это приглашение специалиста к себе домой, где он может не только ответить на вопрос, но и изучить ситуацию, задать уточняющие вопросы и предложить комплексное решение.
MCP vs REST API
REST API — это ветеран интеграционных решений, проверенный временем и миллионами разработчиков. Это как классический костюм — может быть не самый модный, но точно уместный в большинстве случаев.
Сходства:
- Оба подхода используют HTTP для коммуникации (в случае MCP — при использовании SSE-транспорта)
- Оба структурируют данные в формате JSON
- Оба могут работать как с публичными, так и с приватными системами
Различия:
- REST API не специализирован для работы с LLM и не учитывает их особенности
- MCP включает механизмы для сохранения контекста между запросами, что критично для LLM
- REST требует от разработчика создания отдельных эндпоинтов для каждой операции, MCP же предоставляет унифицированный интерфейс
- REST не имеет встроенных механизмов для описания возможностей API, тогда как в MCP это часть протокола
Если REST API — это разговор на разных языках через переводчика (где разработчик должен создать «словарь» для каждого взаимодействия), то MCP — это разговор на едином языке, где все стороны изначально знают правила коммуникации.
MCP vs GraphQL
GraphQL — это «новая школа» в мире API, которая решает многие ограничения REST и позволяет клиентам получать именно те данные, которые им нужны, и ничего лишнего. Своего рода шведский стол вместо комплексного обеда.
Сходства:
- Оба подхода позволяют четко определить структуру запрашиваемых/возвращаемых данных
- Оба поддерживают интроспекцию (возможность узнать о доступных возможностях)
- Оба могут работать через HTTP
Различия:
- GraphQL ориентирован на запрос данных, MCP — на взаимодействие с инструментами и системами
- GraphQL имеет более зрелую экосистему с инструментами для генерации кода, визуализации и т.д.
- MCP специально создан для работы с контекстно-зависимыми LLM, GraphQL же универсален
- GraphQL требует определения схемы для всех типов данных, MCP более гибок в этом отношении
Если представить GraphQL как высокоточный скальпель для хирургически точного извлечения данных, то MCP — это скорее универсальный мультитул, который может не только «доставать данные», но и взаимодействовать с системами более комплексно.
MCP vs LangChain
А вот это интересное сравнение, поскольку LangChain — это не столько альтернатива MCP, сколько фреймворк, который может использовать MCP как один из своих компонентов.
Сходства:
- Оба решения ориентированы на улучшение возможностей LLM через доступ к внешним системам
- Оба поддерживают концепцию инструментов/агентов
- Оба могут работать с разными языковыми моделями
Различия:
- LangChain — это высокоуровневый фреймворк, MCP — низкоуровневый протокол
- LangChain включает готовые интеграции с множеством сервисов, для MCP их нужно создавать
- LangChain может использовать MCP как «транспортный слой» для своих агентов
- MCP более стандартизирован и ограничен в функциональности, но и более предсказуем
На практике наметился интересный тренд: разработчики LangChain начали добавлять поддержку MCP в свой фреймворк, позволяя создавать агентов, которые могут общаться с внешним миром через этот протокол. Это как если бы швейцарская армия решила стандартизировать крепление для всех инструментов в своих знаменитых ножах — базовый механизм один, но возможности для расширения практически безграничны.
Когда какой подход выбирать?
После всех этих сравнений закономерно возникает вопрос: «Ок, а что же мне использовать для моего проекта?». Как обычно в таких случаях, ответ начинается с «Это зависит…»:
- Выбирайте MCP, если: вам нужна стандартизированная интеграция языковых моделей с внутренними системами, особенно если эти системы не имеют доступа в интернет, а также если вы ориентируетесь на долгосрочную перспективу развития решения.
- Предпочтите Function Calling, если: вам нужно быстро интегрировать отдельные функции с моделями от OpenAI или аналогичными, и вы не планируете сложных многоэтапных взаимодействий.
- Остановитесь на REST API, если: у вас уже есть зрелая REST-инфраструктура, вам не требуется специфическая интеграция с LLM, и вы предпочитаете проверенные временем подходы.
- Обратите внимание на GraphQL, если: важна точность и эффективность получения данных, особенно для мобильных приложений или других клиентов с ограниченными ресурсами.
- Исследуйте LangChain, если: вам нужны готовые компоненты для быстрой разработки AI-решений, и вы не хотите погружаться в детали низкоуровневых протоколов.
В реальных проектах, особенно крупных, часто используется комбинация подходов. Например, LangChain для быстрого прототипирования с постепенным переходом на более стандартизированные решения на базе MCP для критически важных компонентов. Или MCP для взаимодействия с внутренними системами в сочетании с REST/GraphQL для публичных API.
Мир интеграционных технологий редко бывает черно-белым, и MCP не стремится заменить собой все существующие подходы. Скорее, это еще один инструмент в арсенале разработчика — специализированный, но оттого не менее ценный. И как показывает практика, именно специализированные инструменты часто оказываются решающими в сложных проектах, подобно тому как хирург выбирает конкретный скальпель для конкретной операции, а не пытается провести всю процедуру универсальным ножом для бумаги.
Как работает MCP? Пошаговый разбор
Общий принцип работы MCP
Давайте погрузимся в прекрасный мир протоколов и увидим, как же это чудо инженерной мысли работает на практике. Если вы когда-нибудь пытались объяснить своей бабушке, как работает интернет («ну, бабуль, там такие трубы с информацией…»), то поймёте, что я чувствую, пытаясь просто описать процесс обмена JSON-RPC сообщениями между компонентами системы. Но я постараюсь.
Всё начинается с фазы инициализации — своеобразного «знакомства» клиента и сервера. Как на неловком первом свидании, они обмениваются информацией о себе: какие версии протокола поддерживают, какими возможностями обладают, не любят ли случайно одни и те же фильмы. Клиент отправляет серверу запрос initialize, сервер отвечает списком своих возможностей (доступные инструменты, ресурсы и подсказки), а клиент оценивает, достаточно ли они совместимы для продолжения отношений.
После успешного «знакомства» наступает фаза операций — та самая рабочая рутина, ради которой всё и затевалось. Здесь происходит обмен запросами и ответами между клиентом и сервером. Например, когда пользователь просит языковую модель найти что-то в базе данных, модель может решить использовать инструмент «sql-запрос». Клиент отправляет запрос tools/call серверу, тот выполняет запрос к базе данных и возвращает результат обратно. Модель получает эти данные и использует их для формирования ответа пользователю.
Периодически (как в любых здоровых отношениях) происходит проверка связи — клиент отправляет серверу сообщения типа «ты ещё тут?», а сервер отвечает «да, я никуда не делся». Это нужно для поддержания соединения и своевременного обнаружения проблем.
Наконец, когда всё уже сказано и сделано (или пользователь просто закрыл приложение), наступает фаза завершения. Клиент вежливо сообщает серверу, что их пути расходятся (отправляет запрос shutdown), сервер подтверждает получение этой печальной новости, и клиент отправляет последнее уведомление exit. На этом жизненный цикл соединения заканчивается — до следующего запуска.
Примеры работы MCP в реальных сценариях
Теперь, когда мы разобрались с теорией, давайте посмотрим, как это работает в реальной жизни — где проблемы обычно не имеют идеальных решений, а кофе всегда заканчивается в самый неподходящий момент.
- Интеграция с Confluence и Jira для автоматизации задач
Представьте: вы работаете над новой функциональностью в проекте и не уверены, как она должна выглядеть. Вместо того, чтобы перерывать всю документацию или беспокоить коллег, вы просто спрашиваете у ассистента в вашей IDE: «Какие требования к функции авторизации в нашем проекте?». Благодаря Model Context Protocol, ассистент не гадает на кофейной гуще, а обращается к вашему корпоративному Confluence, находит соответствующие спецификации, может проверить связанные тикеты в Jira и даёт вам точный ответ со ссылками на документы. А всё потому, что к IDE подключены соответствующие MCP-серверы, и модель знает, как с ними общаться.
- Использование MCP для SQL-запросов на естественном языке
«Покажи мне продажи за последний квартал в разрезе регионов, отсортированные по прибыльности» — говорите вы, и (о чудо!) получаете именно эти данные. Магия? Нет, просто MCP-сервер для вашей базы данных. Модель, получив ваш запрос, определяет, что нужно составить SQL-запрос, вызывает соответствующий инструмент, передавая ему параметры запроса. Сервер переводит это в SQL, выполняет запрос к базе, получает данные и возвращает их обратно. Модель упаковывает результат в удобочитаемый формат и показывает вам. И всё это без необходимости помнить синтаксис SQL или структуру вашей базы данных (которая, давайте будем честны, обычно документирована хуже, чем маршруты миграции птиц в Антарктиде).
- Создание чат-ботов поддержки, подключенных к внутренним базам данных
Ваш отдел поддержки устал отвечать на одни и те же вопросы? Звучит знакомо. Model Context Protocol позволяет создать чат-бота, который не просто отвечает заготовленными фразами, а имеет доступ к вашей базе знаний, тикетной системе, CRM и любым другим внутренним системам. «Какой статус моего заказа #12345?» — спрашивает клиент, и бот через MCP-сервер проверяет статус в CRM, может посмотреть связанные тикеты в системе поддержки, найти информацию о доставке в логистической системе и даже проверить историю взаимодействия с клиентом. И всё это в рамках одного запроса, без необходимости писать тонны кода для интеграции или обучать модель на вашей корпоративной информации.
- Дебаг кода с доступом к различным источникам данных
Пожалуй, одно из самых захватывающих применений — возможность для языковой модели не просто анализировать код, но и запускать его, проверять результаты, обращаться к базам данных или кешам (например, Redis), анализировать логи и итеративно исправлять ошибки. Представьте: вы показываете модели проблемный код, она его анализирует, запускает, видит ошибку, проверяет данные в базе, находит несоответствие, предлагает исправление, снова запускает код для проверки — и всё это в рамках одной сессии, без необходимости вам самим переключаться между разными инструментами и интерфейсами.
В каждом из этих сценариев Model Context Protocol решает одну ключевую проблему: обеспечивает доступ языковой модели к актуальным данным и инструментам в реальном времени, позволяя ей действовать не как изолированная система, а как интегрированный компонент вашей технологической экосистемы. И это, на мой взгляд, открывает дверь в новую эру использования ИИ — ту, где он не просто генерирует текст на основе предобученных данных, а взаимодействует с миром почти как человек. Почти.
// src/index.ts import { Server, StdioServerTransport, ErrorCode, McpError, ListToolsRequestSchema, CallToolRequestSchema } from '@anthropic-ai/mcp';
// Инициализация MCP-сервера const server = new Server({ name: "simple-facts-server", version: "1.0.0", });
// Регистрация инструментов (tools) server.setRequestHandler(ListToolsRequestSchema, async () => { return { tools: [{ name: "random_facts", description: "Получает случайный факт из API", inputSchema: { type: "object", properties: { category: { type: "string", description: "Категория факта (опционально)" } } } }] }; });
// Обработчик вызова инструмента server.setRequestHandler(CallToolRequestSchema, async (request) => { if (request.params.name === "random_facts") { const args = request.params.arguments; console.log("Запрошена категория:", args?.category || "любая");
try {
const response = await fetch('https://uselessfacts.jsph.pl/api/v2/facts/random', {
method: 'GET',
headers: {
"Content-Type": "application/json"
}
});
const data = await response.json();
return {
toolResult: {
fact: data.text,
source: data.source,
language: data.language
},
};
} catch (error) {
console.error("Ошибка при получении случайного факта:", error);
throw new McpError(ErrorCode.InternalError, "Не удалось получить случайный факт");
}
}
throw new McpError(ErrorCode.MethodNotFound, "Инструмент не найден"); });
// Запуск сервера с транспортом stdio const transport = new StdioServerTransport();
// Подключение транспорта к серверу server.connect(transport) .then(() => { console.log("MCP-сервер запущен и ожидает запросы"); }) .catch((error) => { console.error("Ошибка при запуске сервера:", error); process.exit(1); });
Как создать собственный MCP-сервер?
Любая достаточно продвинутая технология неотличима от магии, говорил Артур Кларк. Но я предпочитаю другую формулировку: любая достаточно запутанная технология неотличима от боли в одном месте — особенно когда пытаешься её реализовать. Однако с MCP всё неожиданно просто (настолько, что это даже подозрительно).
MCP-сервер можно написать практически на любом языке программирования — Python, TypeScript, Go, Ruby. Выбор зависит от того, с какими внешними системами вы планируете интегрироваться, и на каком языке вам комфортнее писать. Лично я для примера выбрал TypeScript — язык, который умудряется одновременно раздражать и радовать меня уже несколько лет (сложные отношения, знаете ли).
Давайте разберём базовые шаги создания MCP-сервера, который будет выдавать случайные факты по запросу (бесполезно, но наглядно — прямо как большинство демонстрационных проектов в IT):
1. Настройка базового сервера
Первым делом нужно инициализировать сервер, указав его имя и версию. Это как паспортные данные — без них никуда:
const server = new Server({
name: "simple-facts-server",
version: "1.0.0",
});
2. Определение доступных инструментов
Далее нужно сообщить клиентам, какие инструменты предоставляет наш сервер. Это делается через обработчик запросов типа ListTools:
server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [{
name: "random_facts",
description: "Получает случайный факт из API",
inputSchema: {
type: "object",
properties: {
category: {
type: "string",
description: "Категория факта (опционально)"
}
}
}
}]
};
});
Обратите внимание на inputSchema — это схема для параметров инструмента. LLM будет использовать эту информацию для правильного формирования запросов к вашему инструменту. И да, это JSON Schema — тот самый формат, который заставляет вас гуглить синтаксис каждый раз, когда вы с ним сталкиваетесь (или это только у меня так?).
3. Реализация логики инструмента
Здесь мы определяем, что именно должен делать наш инструмент при вызове. В данном случае — запрашивать случайный факт из внешнего API:
server.setRequestHandler(CallToolRequestSchema, async (request) => {
if (request.params.name === "random_facts") {
// Получаем параметры запроса
const args = request.params.arguments;
try {
// Запрашиваем факт из внешнего API
const response = await fetch('https://uselessfacts.jsph.pl/api/v2/facts/random');
const data = await response.json();
// Возвращаем результат
return {
toolResult: {
fact: data.text,
source: data.source
},
};
} catch (error) {
throw new McpError(ErrorCode.InternalError, "Не удалось получить случайный факт");
}
}
throw new McpError(ErrorCode.MethodNotFound, "Инструмент не найден");
});
4. Настройка транспорта и запуск сервера
Финальный аккорд — выбор транспорта (способа коммуникации) и запуск сервера:
const transport = new StdioServerTransport();
server.connect(transport)
.then(() => {
console.log("MCP-сервер запущен и ожидает запросы");
})
.catch((error) => {
console.error("Ошибка при запуске сервера:", error);
process.exit(1);
});
Здесь мы используем StdioServerTransport — транспорт, работающий через стандартные потоки ввода-вывода. Это самый простой вариант, подходящий для локального использования. Для удалённых серверов обычно используется SSE (Server-Sent Events) транспорт.
Полный код MCP-сервера получается удивительно компактным (см. артефакт выше) — всего около 70 строк кода для функционального сервера. Для сравнения, написание полноценного REST API обычно требует в разы больше кода, особенно если вы заботитесь о таких мелочах, как валидация, обработка ошибок и документация.
5. Регистрация сервера в клиентском приложении
После запуска сервера нужно зарегистрировать его в клиентском приложении (например, в Claude Desktop). Для этого обычно используется конфигурационный файл вида
{
"mcpServers": {
"simple-facts-server": {
"command": "node",
"args": ["path/to/dist/index.js"]
}
}
}
И всё! Теперь, когда пользователь спросит у модели что-то вроде «дай мне случайный факт», она сможет использовать ваш инструмент для получения актуальной информации.
В реальных проектах, конечно, всё несколько сложнее — нужно добавить аутентификацию, обработку различных ошибок, логирование, возможно, кеширование. Но базовый принцип остаётся тем же: вы создаёте сервер, регистрируете инструменты, реализуете их логику и подключаете транспорт. Всё остальное — детали реализации, которые зависят от конкретной задачи.
И, что самое приятное, благодаря стандартизации протокола, ваш сервер будет работать с любым клиентом, поддерживающим MCP, будь то Claude Desktop, Cursor IDE или любой другой инструмент в экосистеме.
Ограничения и потенциальные проблемы MCP
Как и любая технология (особенно новая и быстро развивающаяся), Model Context Protocol не лишен недостатков и ограничений. И, будучи человеком, который предпочитает смотреть на мир через слегка тонированные скептицизмом очки, я просто обязан их перечислить — чтобы вы не подумали, что я пытаюсь продать вам очередную технологическую панацею.
Первое и, пожалуй, самое существенное ограничение — отсутствие стандартизированного механизма аутентификации. Да-да, в 2025 году у нас есть протокол, который позволяет языковым моделям обращаться к внешним системам, но при этом не имеет встроенного способа убедиться, что этот доступ должен быть предоставлен. Разработчики должны реализовывать аутентификацию самостоятельно, что приводит к пестрой мозаике решений — от простейших API-ключей в переменных окружения до сложных OAuth-потоков. В будущих версиях протокола это обещают исправить (как же без этого), но пока приходится изобретать велосипед. Или, что чаще, заимствовать чужой велосипед и надеяться, что он не развалится на полпути.
Другая интересная проблема — отсутствие единого реестра и стандарта установки MCP-серверов. Представьте ситуацию: вы нашли отличный сервер для GitHub, скачали его… и что дальше? Как его установить? Как настроить? Как запустить? Каждый разработчик решает эти вопросы по-своему: одни используют Docker, другие — npm или pip, третьи предоставляют бинарники (которым я доверяю примерно так же, как незнакомцу, предлагающему конфеты на улице). Это создает немалый хаос, особенно для неподготовленных пользователей. Некоторые энтузиасты даже создали MCP-серверы для установки других серверов — если это не определение иронии, то я не знаю, что это такое.
Серьезную проблему представляет и управление контекстом. Хотя Model Context Protocol позволяет модели обращаться к внешним данным, эти данные все равно нужно как-то передать в контекст модели — а он ограничен как по объему, так и по стоимости. Если ваш MCP-сервер возвращает многомегабайтные JSON-ы или многостраничные тексты, модель просто не сможет их обработать или это будет стоить целое состояние. Решения типа суммаризации, кеширования или использования скользящего окна пока реализуются на стороне MCP-хоста, что снова приводит к разнобою в реализациях.
Нельзя не упомянуть и вопросы безопасности. Подключая MCP-сервер, вы фактически даете языковой модели доступ к вашим данным и системам. И хотя большинство моделей обучены на соблюдение этических норм и безопасности, риск всегда остается — особенно если учесть, что модели могут быть подвержены манипуляциям через промпт-инжекцию или другие атаки. Поэтому крайне важно запускать MCP-серверы с минимально необходимыми правами и в изолированной среде, а также тщательно проверять код сторонних серверов. В конце концов, доверять — хорошо, а не доверять — еще лучше, особенно когда речь идет о доступе к вашим внутренним системам.
Наконец, есть и чисто практические ограничения, связанные с зрелостью экосистемы. MCP — относительно новый протокол, и многие приложения еще не имеют официальных MCP-серверов. Это значит, что либо вам придется писать их самостоятельно (что, как мы выяснили, не так уж сложно, но всё же требует времени и усилий), либо использовать сторонние решения сомнительного качества. Кроме того, даже клиенты Model Context Protocol реализуют разные подмножества протокола — например, в одной версии Cursor поддержка ресурсов была попросту выпилена, что потребовало переработки некоторых серверов.
Если сравнивать Model Context Protocol с альтернативными подходами, такими как REST API или GraphQL, он проигрывает в зрелости, документированности и количестве доступных инструментов. Однако выигрывает в специализации именно на работу с языковыми моделями — позволяя им не просто получать данные, но и выполнять действия в контексте решаемой задачи. Это делает его уникальным инструментом для определенного класса задач, но вряд ли стоит ожидать, что он заменит собой традиционные подходы к интеграции.
В целом, Model Context Protocol — это многообещающая технология, которая решает реальные проблемы интеграции языковых моделей с внешними системами. Но как и любая молодая технология, она требует осторожного подхода, понимания ограничений и готовности к определенным компромиссам. И, разумеется, чем больше людей будет её использовать и развивать, тем быстрее эти ограничения будут преодолены — по крайней мере, я на это искренне надеюсь, иначе нам придется изобретать еще один протокол. А кому это надо?
Часто задаваемые вопросы
Какие компании уже используют MCP?
На данный момент Model Context Protocol активно используется в экосистеме Anthropic и в ряде популярных IDE и инструментов разработки. Среди них: Claude Desktop (естественно), Cursor IDE, Cline, Windsurf IDE и другие редакторы кода с AI-возможностями. К протоколу также проявляют интерес крупные компании, использующие языковые модели в своих продуктах, хотя многие находятся на стадии тестирования и оценки технологии. В сообществе разработчиков уже выпущены тысячи MCP-серверов для различных сервисов и инструментов — от баз данных и API до систем контроля версий и менеджеров задач.
Интересно, что за первые три месяца после релиза протокола его поддержка появилась практически во всех популярных AI-вайб-IDE, что говорит о высоком спросе на подобное решение в индустрии. Как любят говорить в Кремниевой долине, «продукт нашел свою проблему».
Поддерживают ли современные LLM (ChatGPT, Claude) этот стандарт?
Тут ситуация немного сложнее. Сам протокол разработан Anthropic, и модели Claude имеют нативную поддержку Model Context Protocol — фактически, они оптимизированы для работы с ним. Другие LLM, такие как модели OpenAI (GPT-4 и новее), Llama и Gemini, могут работать с MCP, но требуют дополнительной настройки на стороне хоста.
Технически любая модель с поддержкой function calling может работать через MCP, так как протокол абстрагирует детали взаимодействия и предоставляет стандартизированный интерфейс. Однако модели Anthropic, как создателя протокола, показывают лучшие результаты — они лучше понимают, когда и какие инструменты вызывать, и как интерпретировать полученные данные.
Если вы планируете использовать Model Context Protocol с другими моделями, стоит быть готовым к некоторым дополнительным настройкам и, возможно, менее оптимальным результатам.
Можно ли MCP использовать для автономных систем без интернета?
Да, и это одно из ключевых преимуществ протокола! Model Context Protocol специально разработан для обеспечения доступа LLM к системам, которые могут быть полностью внутренними и не иметь доступа в интернет.
Вы можете развернуть всю инфраструктуру — хост, сервер и подключенные системы — в изолированной среде. Это особенно ценно для компаний с высокими требованиями к безопасности и конфиденциальности данных, таких как финансовые организации, медицинские учреждения или государственные структуры.
Единственное условие — вам понадобится либо локально развернутая языковая модель, либо безопасный канал для взаимодействия с облачной моделью. В первом случае вы получаете полностью автономную систему, во втором — только данные остаются внутри вашей сети, а запросы к модели уходят наружу.
Насколько сложно интегрировать MCP в существующую инфраструктуру?
Сложность интеграции зависит от нескольких факторов: насколько хорошо документированы API ваших внутренних систем, какие клиенты Model Context Protocol вы планируете использовать, и какой уровень безопасности вам необходим.
В простейшем случае — если у вас есть хорошо документированные API и вы используете популярные клиенты типа Claude Desktop или Cursor — интеграция может занять буквально часы. Вы либо находите готовый MCP-сервер для вашей системы, либо пишете простой сервер-адаптер (как мы видели выше, это не так сложно).
В более сложных сценариях, особенно когда речь идет о корпоративных системах с комплексной аутентификацией или нестандартными API, процесс может занять дни или недели. Особенно если вам приходится разбираться с устаревшими системами, документация к которым утеряна, а разработчики давно покинули компанию (классическая ситуация, знакомая до боли).
В любом случае, сама концепция Model Context Protocol делает интеграцию значительно проще, чем если бы вам пришлось разрабатывать собственное решение с нуля.
Есть ли альтернативы MCP для схожих задач?
До появления MCP разработчики использовали различные подходы для интеграции LLM с внешними системами: от прямых вызовов API через function calling до специализированных фреймворков типа LangChain или AutoGPT.
Однако у этих решений были существенные недостатки: отсутствие стандартизации (каждая интеграция — уникальный снежинка), сложность масштабирования и ограниченная совместимость между различными LLM и инструментами.
MCP не заменяет эти подходы полностью, а скорее дополняет их, предоставляя стандартизированный протокол для коммуникации. Фактически, те же LangChain или другие фреймворки могут использовать MCP как транспортный слой для своих агентов.
На данный момент MCP остается наиболее продвинутым открытым протоколом для интеграции LLM с внешними системами, хотя в будущем, безусловно, появятся и другие стандарты. Возможно, мы увидим конвергенцию различных подходов или новые протоколы, решающие те проблемы, которые сейчас есть у MCP.
А пока что это, пожалуй, лучший инструмент для задачи интеграции языковых моделей с внешним миром — не идеальный, но вполне работоспособный и постоянно развивающийся.
Заключение
Model Context Protocol, при всей своей технической простоте, стал настоящим прорывом в области интеграции языковых моделей с внешними системами. Это тот редкий случай, когда новая технология не усложняет жизнь, а действительно решает насущные проблемы — стандартизирует интеграцию, упрощает доступ к данным и инструментам, делает LLM более полезными в реальных, практических сценариях.
Главные преимущества MCP очевидны: унифицированный подход к интеграции, возможность работы с внутренними системами, сохранение контекста для многоэтапных задач. Но не менее важно и то, что протокол открыт, относительно прост в реализации и активно развивается сообществом.
Кому стоит присмотреться к MCP в первую очередь? Я бы выделил несколько групп:
- Разработчикам IDE и инструментов для программистов — MCP открывает богатые возможности для создания «умных» ассистентов, способных работать с кодом, документацией и другими инструментами разработки.
- Компаниям, использующим внутренние базы знаний и корпоративные системы — MCP позволит создать интеллектуальных ассистентов, способных извлекать и анализировать данные из этих систем.
- Разработчикам чат-ботов и систем поддержки — протокол даёт возможность создавать бота, который не просто отвечает заготовленными фразами, а реально работает с актуальными данными.
- Энтузиастам и исследователям ИИ — MCP открывает дверь в мир агентных систем, способных взаимодействовать с окружающим миром, а не просто генерировать текст.
Но не будем забывать и о недостатках: молодость технологии, нерешенные вопросы безопасности и аутентификации, отсутствие единых стандартов установки и настройки. Всё это требует внимания и осторожного подхода, особенно в производственных сценариях.
В целом, MCP — это шаг в правильном направлении, к миру, где языковые модели не ограничены предобученными данными, а могут активно взаимодействовать с окружающими системами, получая актуальную информацию и выполняя реальные действия. И хотя до полноценных ИИ-агентов, о которых мечтают фантасты, ещё далеко, MCP определенно приближает нас к этому будущему — шаг за шагом, строчка кода за строчкой, один запрос за другим.
А для тех, кто хочет быть на переднем крае технологий, сейчас самое время погрузиться в эту экосистему — создавать свои серверы, экспериментировать с интеграциями и, возможно, внести свой вклад в развитие протокола. Потому что лучший способ предсказать будущее — это создать его самому. Или, по крайней мере, написать для него MCP-сервер.

HTML Academy vs Яндекс Практикум: где сильнее «с нуля» по вёрстке и фронтенду
Ищете курсы по фронтенду и не понимаете, с чего начать? Где проще освоить HTML и CSS, а где быстрее выйти в профессию? Разбираем ключевые отличия и помогаем выбрать подходящий формат обучения.

Moscow Digital Academy vs Нетология: где лучше учат под работу, а где — под диплом
Moscow Digital Academy или Нетология — что лучше выбрать, если вы хотите выйти в профессию или получить диплом? Разбираем ключевые различия, формат обучения и реальные сценарии выбора без лишнего шума.

Слёрм vs Яндекс Практикум: где полезнее, если цель — инженерная практика, а не «мягкий старт»
Слёрм или Яндекс Практикум DevOps — что выбрать, если уже есть опыт и нужна реальная практика? Разбираем форматы обучения, стек технологий и сценарии, где каждый вариант даёт максимум пользы.

LoftSchool vs Яндекс Практикум: где быстрее собрать портфолио и не застрять на теории
LoftSchool или Яндекс Практикум — что выбрать, если хочется быстрее получить проекты и не утонуть в теории? Разбираем формат обучения, портфолио и реальные сценарии выбора.