Обработка ошибок в Go: практическое руководство
Go занимает особое место среди современных языков программирования, предлагая принципиально иной подход к работе с ошибками. В отличие от Java, Python или C#, здесь нет привычных исключений — вместо этого они возвращаются как обычные значения.

На первый взгляд такой подход может показаться архаичным, однако именно он делает код более предсказуемым и явным.
- Что такое ошибка в Go
- Базовая обработка ошибок
- Создание ошибок
- Оборачивание ошибок
- Проверка и сравнение ошибок
- Лучшие практики работы с ошибками
- defer, panic и recover
- Сторонние библиотеки для обработки ошибок
- Заключение
- Рекомендуем посмотреть курсы по golang разработке
Что такое ошибка в Go
В основе системы обработки ошибок Go лежит элегантная простота — ошибка представляет собой интерфейс с единственным методом:
type error interface {
Error() string
}
Любой тип, который реализует этот метод, автоматически становится предупреждением error. Такой минималистичный подход отражает философию языка: простота важнее удобства. Разработчики Go сознательно отказались от механизма исключений, считая его источником скрытой сложности и непредсказуемого поведения программ.

Скриншот страницы официальной документации Go (pkg.go.dev), где описан интерфейс error.
Основная идея, которую можно сформулировать как «ошибка должна рассказывать историю», означает, что каждое сообщение об ней должно содержать достаточно контекста для понимания того, что именно пошло не так и где это произошло. В отличие от исключений в других языках, которые могут «всплывать» через множество уровней вызовов, ошибки в Go обрабатываются явно на каждом уровне.
Рассмотрим простейший пример:
package main
import (
"errors"
"fmt"
)
func divide(a, b float64) (float64, error) {
if b == 0 {
return 0, errors.New("деление на ноль невозможно")
}
return a / b, nil
}
func main() {
result, err := divide(10, 0)
if err != nil {
fmt.Printf("Ошибка: %s\n", err.Error())
return
}
fmt.Printf("Результат: %.2f\n", result)
}
Такой подход заставляет разработчика явно обрабатывать каждую потенциальную проблему, что на первый взгляд может показаться избыточным, но в долгосрочной перспективе делает код более надежным и предсказуемым.
Базовая обработка ошибок
Проверка err != nil
Краеугольным камнем работы с предупреждениями error в Go является проверка err != nil — конструкция, которая встречается практически в каждом Go-проекте. Стандартный паттерн выглядит следующим образом:
result, err := someFunction()
if err != nil {
// обработка ошибки
return err
}
// продолжаем работу с result
При обнаружении предупреждения разработчик может выбрать одну из нескольких стратегий: вернуть ошибку выше по стеку вызовов, залогировать её для последующего анализа, повторить операцию (особенно актуально для сетевых запросов) или преобразовать в другой тип ошибки, более подходящий для текущего контекста.
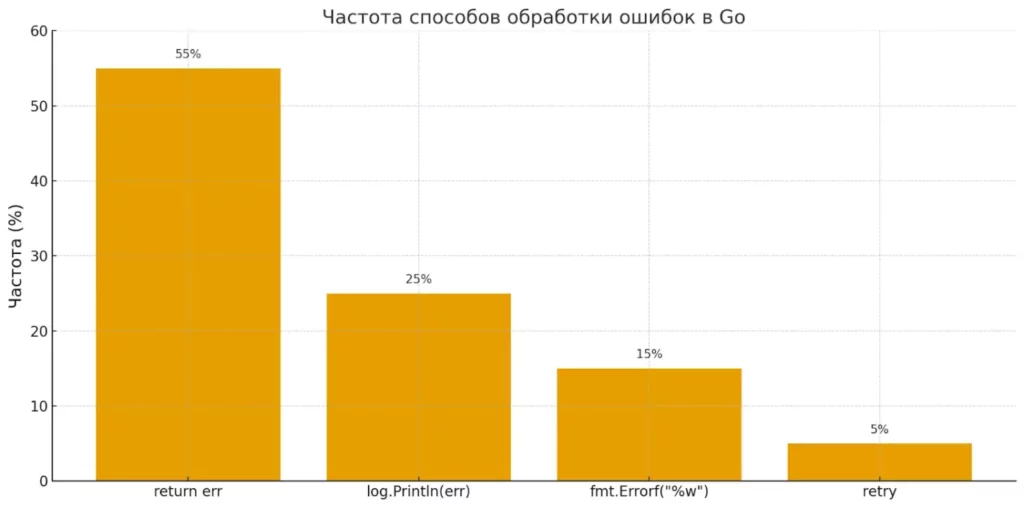
Столбчатая диаграмма показывает, что проверка err != nil и возврат ошибки — наиболее распространённый паттерн в Go-проектах. Остальные подходы используются реже, но дополняют общую стратегию.
Проблема минимального контекста
Однако простое return err часто оказывается недостаточным для эффективной диагностики проблем. Представим ситуацию с базой данных:
func GetUser(id int) (*User, error) {
row, err := db.Query("SELECT * FROM users WHERE id = ?", id)
if err != nil {
return nil, err // потеряли контекст!
}
if err == sql.ErrNoRows {
// Как сообщить вызывающему коду, что пользователь не найден,
// сохранив при этом информацию о месте возникновения ошибки?
return nil, err
}
// остальная логика...
}
В данном примере мы сталкиваемся с классической дилеммой: с одной стороны, нужно сохранить первоначальную ошибку (sql.ErrNoRows), чтобы вызывающий код мог принять соответствующее решение, с другой — добавить контекст о том, где именно произошла ошибка. Простое возвращение оригинальной проблемы лишает нас информации о месте её возникновения, а создание новой может разорвать логическую связь с первопричиной.
Типичные действия при обработке ошибок:
- Немедленный возврат ошибки вызывающему коду.
- Логирование с дополнительным контекстом.
- Повторная попытка выполнения операции.
- Преобразование в предупреждение предметной области.
- Возврат значения по умолчанию с сопутствующей ошибкой.
Создание ошибок
Стандартная библиотека Go предоставляет два основных способа создания ошибок, каждый из которых подходит для определенных сценариев использования.
Функция errors.New() — это самый простой способ создать предупреждение со статическим сообщением:
import "errors"
var ErrUserNotFound = errors.New("пользователь не найден")
var ErrInvalidPassword = errors.New("неверный пароль")
func AuthenticateUser(username, password string) error {
if !userExists(username) {
return ErrUserNotFound
}
if !validatePassword(username, password) {
return ErrInvalidPassword
}
return nil
}
Определение ошибок как переменных уровня пакета позволяет другим частям кода легко их идентифицировать и обрабатывать соответствующим образом.
Функция fmt.Errorf() предоставляет более гибкие возможности для создания ошибок с динамическим содержимым:
import "fmt"
func ValidateAge(age int) error {
if age < 0 {
return fmt.Errorf("возраст не может быть отрицательным: получено %d", age)
}
if age > 150 {
return fmt.Errorf("возраст %d выглядит неправдоподобно", age)
}
return nil
}
Выбор между этими подходами зависит от конкретной ситуации: errors.New() идеален для создания константных ошибок, которые можно сравнивать и переиспользовать, тогда как fmt.Errorf() незаменим, когда сообщение должно содержать специфичную для ситуации информацию. В современных приложениях часто используется комбинированный подход — предопределенные ошибки для типовых ситуаций и динамические для уточнения контекста.
Оборачивание ошибок
Одной из наиболее важных возможностей Go, появившейся в версии 1.13, является механизм оборачивания ошибок с помощью специального глагола %w в функции fmt.Errorf(). Этот подход позволяет решить дилемму между сохранением оригинальной ошибки и добавлением контекстной информации.
func GetUserData(userID int) (*UserData, error) {
// Вызываем функцию низкого уровня
row := db.QueryRow("SELECT name, email FROM users WHERE id = ?", userID)
var userData UserData
err := row.Scan(&userData.Name, &userData.Email)
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
// Оборачиваем специфичную ошибку БД в ошибку предметной области
return nil, fmt.Errorf("пользователь с ID %d не найден: %w", userID, err)
}
// Добавляем контекст к любой другой ошибке
return nil, fmt.Errorf("ошибка получения данных пользователя %d: %w", userID, err)
}
return &userData, nil
}
Зачем необходим такой контекст? Представьте, что вы анализируете логи продакшн-системы и видите ошибку sql: no rows in result set. Без дополнительной информации практически невозможно понять, в какой именно части приложения возникла проблема — это может быть поиск пользователя, получение настроек, загрузка конфигурации или любая другая операция с базой данных.

Диаграмма иллюстрирует, как ошибка проходит через уровни приложения: от первичной sql.ErrNoRows до верхнего уровня, где добавляется контекст и выполняется проверка через errors.Is.
Оборачивание решает эту проблему элегантно:
// Где-то в коде верхнего уровня
userData, err := GetUserData(123)
if err != nil {
// Получаем: "пользователь с ID 123 не найден: sql: no rows in result set"
log.Printf("Ошибка: %v", err)
// При этом можем проверить первоначальную ошибку
if errors.Is(err, sql.ErrNoRows) {
// Обрабатываем как отсутствие пользователя
return handleUserNotFound()
}
return fmt.Errorf("критическая ошибка работы с БД: %w", err)
}
Такой подход позволяет создавать цепочки ошибок, где каждый уровень добавляет свой контекст, не теряя при этом информацию о первопричине. Это особенно важно в больших приложениях, где вызовы функций могут проходить через множество слоев абстракции.
Проверка и сравнение ошибок
С появлением механизма оборачивания ошибок возникла потребность в более совершенных методах их анализа. Go 1.13 представил две ключевые функции в пакете errors, которые кардинально упростили работу с обернутыми ошибками.
errors.Is
Функция errors.Is определяет, содержится ли в цепочке ошибок определенное значение. Это особенно полезно, когда нужно проверить первопричину ошибки, независимо от того, сколько раз она была обернута:
func ProcessFile(filename string) error {
data, err := os.ReadFile(filename)
if err != nil {
return fmt.Errorf("не удалось прочитать файл %s: %w", filename, err)
}
// обработка данных...
return nil
}
// В вызывающем коде
err := ProcessFile("config.json")
if err != nil {
// Проверяем первопричину, даже если ошибка была обернута
if errors.Is(err, fs.ErrNotExist) {
// Файл не существует - создаем конфигурацию по умолчанию
return createDefaultConfig()
}
if errors.Is(err, fs.ErrPermission) {
// Нет прав доступа - уведомляем пользователя
return fmt.Errorf("недостаточно прав для чтения файла: %w", err)
}
// Другая ошибка - прерываем выполнение
return err
}
errors.As
Функция errors.As позволяет проверить, можно ли привести ошибку к определенному типу, и извлечь её для дальнейшего анализа:
type ValidationError struct {
Field string
Message string
}
func (e ValidationError) Error() string {
return fmt.Sprintf("ошибка валидации поля %s: %s", e.Field, e.Message)
}
func ValidateUser(user *User) error {
if user.Email == "" {
return fmt.Errorf("проверка пользователя не пройдена: %w",
ValidationError{Field: "email", Message: "не может быть пустым"})
}
return nil
}
// В коде обработки
err := ValidateUser(user)
if err != nil {
var validationErr ValidationError
if errors.As(err, &validationErr) {
// Получили конкретный тип ошибки - можем работать с её полями
log.Printf("Проблема с полем %s: %s", validationErr.Field, validationErr.Message)
return handleValidationError(validationErr)
}
// Это не ошибка валидации - обрабатываем по-другому
return handleGenericError(err)
}
Типичные кейсы использования:
- Проверка ошибок файловой системы (fs.ErrNotExist, fs.ErrPermission).
- Анализ сетевых ошибок для реализации повторных попыток.
- Обработка ошибок валидации с извлечением деталей.
- Различение временных и постоянных ошибок в распределенных системах.
Лучшие практики работы с ошибками
Эффективная работа с error в Go требует следования определенным принципам, которые сформировались в сообществе за годы использования языка. Эти практики помогают создавать код, который легко отлаживать и поддерживать.
Ключевые правила формирования сообщений об ошибках:
- Информативность превыше краткости. Сообщение должно содержать достаточно деталей для понимания проблемы без необходимости изучения кода. Вместо «invalid input» лучше написать «недопустимое значение возраста: ожидается число от 0 до 150, получено -5».
- Контекст как путеводная нить. Каждый уровень должен добавлять информацию о том, что он пытался сделать. Это создает логическую цепочку от места возникновения ошибки до верхнего уровня приложения.
- Однозначная идентификация места. Сообщение должно позволять быстро найти проблемное место в коде. Используйте имена функций, модулей или уникальные идентификаторы операций.
- Строчные буквы в начале. Согласно соглашениям Go, сообщения об ошибках начинаются со строчной буквы и не заканчиваются точкой, поскольку они могут быть частью более крупного сообщения.
- Избегание избыточности. Не дублируйте информацию, которая уже содержится в обернутой ошибке. Вместо «database error: sql: database connection failed» достаточно «не удалось получить данные пользователя: %w».
Правильно составленное сообщение о error должно читаться как связный рассказ о том, что происходило в момент сбоя. Это особенно важно при работе в команде, где один разработчик может отлаживать код, написанный другим. Инвестиции времени в качественные сообщения об ошибках многократно окупаются при поддержке проекта.
defer, panic и recover
Помимо стандартного механизма ошибок, Go предоставляет систему обработки критических ситуаций через триаду defer, panic и recover. Важно понимать, что это не замена обычным ошибкам, а инструмент для работы с исключительными ситуациями, когда программа не может продолжить нормальное выполнение.
panic представляет собой механизм аварийного завершения выполнения функции. В отличие от исключений в других языках, panic в Go используется крайне редко и только в критических ситуациях:
func safeDivide(a, b float64) float64 {
defer func() {
if r := recover(); r != nil {
fmt.Printf("Перехвачена паника: %v\n", r)
// Логирование, очистка ресурсов, уведомления...
}
}()
if b == 0 {
panic("деление на ноль в критическом участке кода")
}
return a / b
}
func processData() {
defer fmt.Println("Очистка ресурсов выполнена")
defer func() {
if err := recover(); err != nil {
log.Printf("Критическая ошибка: %v", err)
// Возможность корректно завершить работу
}
}()
// Потенциально опасные операции
result := safeDivide(10, 0)
fmt.Printf("Результат: %f\n", result)
}
Ключевая особенность defer заключается в том, что отложенные функции выполняются в обратном порядке независимо от того, как завершается функция — нормально или через панику. Это делает их идеальными для освобождения ресурсов.
recover может остановить распространение паники и вернуть контроль программе, но его следует использовать осторожно. В отличие от механизма исключений в Java или Python, где try-catch является нормальной частью потока управления, panic-recover в Go предназначен исключительно для экстренных ситуаций.
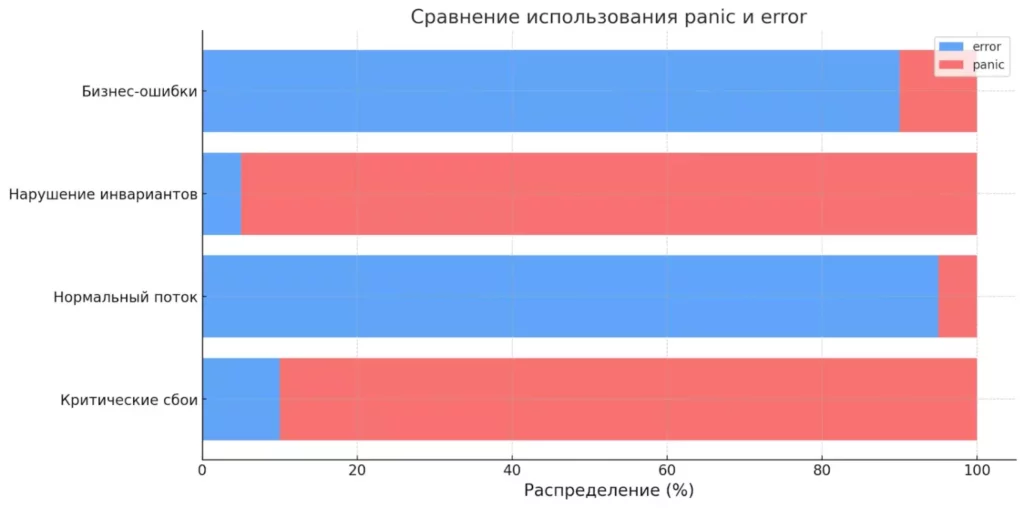
Горизонтальная диаграмма сравнивает области применения panic и error. Panic используется в исключительных, критических случаях, тогда как ошибки — основной инструмент работы с бизнес-логикой и нормальными потоками исполнения.
Когда уместно использовать panic:
- При обнаружении невосстановимых ошибок программирования
- В инициализации критически важных ресурсов
- При нарушении инвариантов, которые никогда не должны произойти
Злоупотребление panic может сделать код непредсказуемым и затруднить отладку, поэтому в подавляющем большинстве случаев предпочтительнее использовать стандартные ошибки.
Сторонние библиотеки для обработки ошибок
Хотя стандартная библиотека Go предоставляет солидный фундамент для работы с ошибками, экосистема языка предлагает несколько специализированных пакетов, которые могут значительно упростить разработку в определенных сценариях.
pkg/errors — одна из наиболее популярных библиотек, которая расширяет возможности стандартного пакета:
- Автоматический сбор stack trace при создании ошибки.
- Более удобные функции для оборачивания ошибок.
- Совместимость со стандартными errors.Is и errors.As.
import "github.com/pkg/errors"
func loadConfig() error {
data, err := ioutil.ReadFile("config.json")
if err != nil {
// Автоматически добавляется информация о стеке вызовов
return errors.Wrap(err, "не удалось загрузить конфигурацию")
}
return nil
}
xerrors — экспериментальная библиотека от команды Go, многие идеи которой в итоге попали в стандартную библиотеку. Сейчас она менее актуальна, поскольку Go 1.13+ включает большинство её возможностей.
errorx — предоставляет расширенные возможности для категоризации ошибок и их обработки:
- Типизированные ошибки с дополнительными свойствами.
- Более гибкая система создания иерархий ошибок.
- Встроенная поддержка retry-механизмов.
Выбор сторонней библиотеки должен основываться на конкретных потребностях проекта. Для большинства приложений возможностей стандартной библиотеки вполне достаточно, особенно после улучшений в Go 1.13. Дополнительные инструменты стоит рассматривать, когда требуется детальная диагностика (stack trace), сложная категоризация ошибок или специфичные паттерны их обработки. Важно помнить, что любая зависимость усложняет проект и может повлиять на производительность.
Заключение
Система обработки ошибок в Go, несмотря на кажущуюся простоту, представляет собой мощный инструмент для создания надежных приложений. Философия явной обработки ошибок может показаться громоздкой разработчикам, пришедшим из других языков, но именно она делает код более предсказуемым и упрощает диагностику проблем в продакшн-среде.
Подведем итоги:
- В Go используется интерфейс error вместо исключений. Это делает обработку ошибок явной и предсказуемой.
- Проверка err != nil лежит в основе всех паттернов. Такой подход помогает быстро реагировать на сбои.
- Функции errors.New и fmt.Errorf упрощают создание сообщений. Они позволяют точно передавать контекст проблемы.
- Оборачивание ошибок с помощью %w сохраняет первопричину. Это облегчает диагностику и анализ цепочек.
- Методы errors.Is и errors.As дают гибкость при проверке ошибок. С их помощью можно точно определить тип и источник сбоя.
- panic и recover предназначены только для экстренных ситуаций. Они не заменяют стандартные error-механизмы.
- Сторонние библиотеки расширяют возможности обработки ошибок. Их стоит использовать осознанно в сложных проектах.
Если вы только начинаете осваивать профессию Go-разработчика, рекомендуем обратить внимание на подборку курсов по Go. В них есть как теоретические модули, так и практические задания, которые помогут глубже понять принципы обработки ошибок и применять их в реальных проектах.
Рекомендуем посмотреть курсы по golang разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Искусство написания сервиса на Go
|
GOLANG NINJA
14 отзывов
|
Цена
38 565 ₽
92 096 ₽
|
|
Длительность
5 месяцев
|
Старт
в любое время
|
Подробнее |
|
Go-разработчик
|
Нетология
46 отзывов
|
Цена
87 900 ₽
195 360 ₽
с промокодом kursy-online
|
От
4 070 ₽/мес
0% на 36 месяцев
8 041 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
2 раз в неделю после 18:00 МСК
|
Подробнее |
|
Искусство работы с ошибками и безмолвной паники в Go
|
GOLANG NINJA
14 отзывов
|
Цена
26 545 ₽
39 620 ₽
|
|
Длительность
9 недель
|
Старт
в любое время
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.