Почему машинное обучение работает — и как оно меняет наш мир
В эпоху цифровой трансформации машинное обучение становится движущей силой инноваций, меняющей целые отрасли и повседневную жизнь каждого из нас. От персонализированных рекомендаций в стриминговых сервисах до беспилотных автомобилей и прорывов в медицинской диагностике — эта технология незаметно, но фундаментально изменила практически каждый аспект взаимодействия человека с цифровым миром.

Машинное обучение — это не просто модный технологический термин или абстрактная концепция, а мощный набор инструментов, позволяющий компьютерам учиться на основе данных, выявлять закономерности и принимать решения с минимальным вмешательством человека. Примечательно, что в отличие от традиционного программирования, где каждое действие системы должно быть явно запрограммировано, machine learning позволяет алгоритмам самостоятельно совершенствоваться по мере поступления новых данных.
Почему же важность ML так возросла именно сейчас? Ответ кроется в сочетании трех ключевых факторов: экспоненциальный рост доступных данных, значительное увеличение вычислительных мощностей и прорывы в алгоритмах. Давайте разберемся, что представляет собой эта технология, как она функционирует и где находит применение в современном мире.
- Что такое машинное обучение
- Определение и основные принципы работы
- Краткая история развития
- Виды машинного обучения и их особенности
- Обучение с учителем
- Обучение без учителя
- Обучение с подкреплением
- Основные задачи машинного обучения
- Классификация
- Регрессия
- Кластеризация
- Уменьшение размерности
- Популярные алгоритмы машинного обучения
- Базовые алгоритмы
- Продвинутые алгоритмы
- Когда использовать какой алгоритм
- Как работает процесс машинного обучения
- Сбор данных
- Очистка и подготовка данных
- Выбор модели
- Обучение модели
- Тестирование и оценка качества
- Деплой модели
- Где применяется машинное обучение
- Распознавание изображений и речи
- Рекомендательные системы
- Финансы
- Медицина
- Самоуправляемые автомобили
- Промышленность и автоматизация
- Инструменты и платформы для работы с машинным обучением
- Python и библиотеки для ML
- Облачные решения для машинного обучения
- No-code платформы для ML
- Будущее машинного обучения
- Развитие Explainable AI
- Нейросети и творческие профессии
- Этика в ML
Что такое машинное обучение
Определение и основные принципы работы
Машинное обучение (Machine Learning, ML) — это подраздел искусственного интеллекта, представляющий собой совокупность методов, которые позволяют компьютерным системам обучаться и совершенствоваться на основе опыта без явного программирования. В отличие от традиционного программирования, где разработчик прописывает четкую последовательность шагов для решения конкретной задачи, при machine learning специалист предоставляет системе данные и описывает критерии успешного решения, а алгоритм самостоятельно находит оптимальный способ достижения цели.
Представьте ситуацию, когда классический программист пишет код для распознавания кошек на фотографиях. Ему пришлось бы создать правила для определения ушей, усов, хвоста и других характеристик. Но что если кошка сфотографирована под необычным углом или частично скрыта? Учесть все возможные варианты практически невозможно. В ML мы показываем модели тысячи изображений кошек и не-кошек, и она самостоятельно выявляет признаки, позволяющие отличить одно от другого.
Важно отметить различие между терминами «машинное обучение» и «искусственный интеллект». Последний — более широкое понятие, охватывающее все способы, которыми компьютер может имитировать человеческий интеллект: рассуждение, планирование, творчество. Машинное обучение — это конкретное направление искусственного интеллекта, реализующее его способность учиться на данных и адаптироваться к новым сценариям.
Краткая история развития
| Год | Событие | Значение |
|---|---|---|
| 1958 | Создание перцептрона Френком Розенблаттом | Первая модель искусственной нейронной сети, способная распознавать образы |
| 1959 | Термин «машинное обучение» введен Артуром Самуэлем | Создание программы для игры в шашки, которая обучалась самостоятельно |
| 1980-е | Возрождение интереса к нейронным сетям | Разработка алгоритма обратного распространения ошибки |
| 1996 | Deep Blue побеждает Гарри Каспарова | IBM создает суперкомпьютер, обыгравший чемпиона мира по шахматам |
| 2011 | Основание Google Brain | Google создает подразделение для исследований в области ИИ и ML |
| 2014 | Появление платформ ML у Amazon и Microsoft | Массовое внедрение ML-технологий в бизнес |
| 2016 | AlphaGo побеждает чемпиона мира по го | Демонстрация возможностей глубокого обучения с подкреплением |
| 2020 | AlphaFold решает проблему сворачивания белка | Революционный прорыв в биологии и медицине благодаря ML |
Эволюция machine learning от академических исследований до технологии, меняющей целые отрасли, произошла за относительно короткий исторический период. Сегодня мы находимся на этапе, когда ML-технологии становятся доступными не только для крупных корпораций, но и для среднего и малого бизнеса, что значительно расширяет спектр их применения и влияние на общество.
Виды машинного обучения и их особенности
В зависимости от методологии и степени вовлеченности человека в процесс Learning, machine learning подразделяется на несколько фундаментальных типов. Рассмотрим три основных подхода, каждый из которых имеет свои уникальные характеристики и области применения.
Обучение с учителем
Обучение с учителем (supervised learning) — наиболее распространенный и интуитивно понятный подход в машинном Learning. Здесь роль «учителя» играет размеченный набор данных, в котором для каждого входного примера уже известен правильный ответ. Модель анализирует эти примеры и учится устанавливать взаимосвязи между входными данными и ожидаемыми результатами.
Представьте это как Learning с наставником: специалист по ML предоставляет системе множество примеров с «правильными ответами», и система должна научиться давать корректные ответы на новые, ранее не встречавшиеся примеры. Эти «правильные ответы» в профессиональной терминологии называются метками или целевыми переменными.
Наиболее яркие примеры применения обучения с учителем включают:
- Фильтры спама в электронной почте (каждое письмо классифицируется как спам или не-спам)
- Распознавание лиц на фотографиях (система учится идентифицировать конкретного человека)
- Прогнозирование цен на недвижимость (на основе характеристик объекта и рыночных данных)
Обучение без учителя
При Learning без учителя (unsupervised learning) система работает с неразмеченными данными — то есть, ей не предоставляются «правильные ответы». Вместо этого, алгоритм самостоятельно ищет скрытые структуры и закономерности в данных, группируя похожие элементы или выявляя аномалии.
Это напоминает ситуацию, когда исследователь изучает новую территорию без карты — он должен самостоятельно определить ключевые ориентиры и закономерности. Такой подход особенно ценен в сценариях, где размечать данные вручную нецелесообразно из-за их объема или сложности.
Типичные применения Learning без учителя:
- Сегментация клиентов в маркетинге (выявление групп покупателей со схожим поведением)
- Обнаружение мошеннических транзакций (выявление аномальных финансовых операций)
- Рекомендательные системы (группировка пользователей по предпочтениям)
Обучение с подкреплением
Learning с подкреплением (reinforcement learning) представляет собой принципиально иной подход, основанный на взаимодействии с окружающей средой. Здесь алгоритм, называемый агентом, учится достигать своих целей через систему вознаграждений и штрафов.
Это похоже на то, как дрессировщик обучает животное: правильные действия поощряются, а неправильные — наказываются. С течением времени агент разрабатывает оптимальную стратегию, максимизирующую совокупное вознаграждение.
Области применения Learning с подкреплением включают:
- Создание ИИ для игр (от шахмат до сложных стратегий)
- Оптимизация маршрутов для беспилотных автомобилей
- Автоматизация промышленных процессов
- Роботы-манипуляторы, обучающиеся выполнять сложные физические задачи
| Тип ML | Данные | Ключевые особенности | Примеры применения |
|---|---|---|---|
| Обучение с учителем | Размеченные | Требует готовых примеров с ответами; подходит для задач классификации и регрессии | Распознавание текста, прогнозирование цен, медицинская диагностика |
| Обучение без учителя | Неразмеченные | Самостоятельно находит структуры в данных; применяется для кластеризации и снижения размерности | Сегментация рынка, обнаружение аномалий, сжатие данных |
| Обучение с подкреплением | Генерируемые в процессе взаимодействия | Обучается через систему наград и штрафов; оптимизирует стратегию действий | Игровые ИИ, робототехника, оптимизация процессов |
Выбор конкретного подхода зависит от характера решаемой задачи, доступности данных и требуемого уровня автономности системы. Часто на практике эти подходы комбинируются, создавая гибридные модели, способные решать еще более сложные задачи.
Основные задачи машинного обучения
Машинное обучение предлагает инструментарий для решения широкого спектра практических проблем. Независимо от выбранного подхода к Learning, все ML-системы в конечном счете решают одну или несколько фундаментальных задач. Рассмотрим ключевые типы задач и их практическое применение.
Классификация
Классификация — пожалуй, наиболее распространенная задача в machine learning. Здесь модель учится относить входные данные к одной из предопределенных категорий. Математически это можно представить как функцию, которая принимает признаки объекта и выдает его принадлежность к определенному классу.
На практике это выглядит следующим образом: система анализирует характеристики объекта (например, содержание электронного письма) и определяет, к какой категории он относится (спам или легитимное сообщение). Классификация может быть бинарной (два класса) или мультиклассовой (три и более классов).
В сфере компьютерного зрения классификация применяется для распознавания объектов на изображениях — от детекции лиц в системах безопасности до автоматического определения дорожных знаков в беспилотных автомобилях. В медицине модели классификации помогают диагностировать заболевания, анализируя медицинские снимки и результаты анализов.
Регрессия
Если классификация предсказывает категорию, то регрессия прогнозирует числовое значение. Задача регрессии заключается в построении модели, которая устанавливает зависимость между входными параметрами и непрерывной переменной на выходе.
Наиболее наглядный пример — прогнозирование цен. Скажем, ML-система оценивает стоимость квартиры на основе таких параметров, как площадь, район, этаж, наличие парковки и других характеристик. В финансовой сфере регрессионные модели предсказывают котировки акций и другие показатели рынка, что критически важно для принятия инвестиционных решений.
В промышленности регрессия применяется для предсказания срока службы оборудования, что позволяет планировать профилактическое обслуживание и минимизировать простои производства.
Кластеризация
Кластеризация относится к задачам Learning без учителя и заключается в группировке объектов по их сходству. В отличие от классификации, здесь заранее неизвестно, сколько групп (кластеров) получится и какие именно характеристики определяют принадлежность к кластеру.
Один из классических примеров — сегментация клиентов в маркетинге. Система анализирует поведение пользователей (частоту покупок, средний чек, предпочитаемые категории товаров) и группирует их в сегменты со схожими паттернами поведения. Это позволяет компаниям разрабатывать таргетированные маркетинговые кампании для каждой группы.
В биоинформатике кластеризация используется для группировки генов со схожими функциями или для выявления подтипов заболеваний на основе генетических профилей пациентов.
Уменьшение размерности
С ростом объема данных растет и количество признаков, с которыми приходится работать. Это создает проблему «проклятия размерности» — чем больше признаков, тем больше данных требуется для обучения модели. Уменьшение размерности позволяет сократить количество переменных без существенной потери информации.
В компьютерном зрении это может быть преобразование миллионов пикселей изображения в компактный набор признаков, описывающих ключевые характеристики. В обработке естественного языка — представление текстов в виде векторов фиксированной длины, сохраняющих семантический смысл.
Уменьшение размерности не только повышает эффективность вычислений, но и помогает визуализировать данные, что критически важно для их исследования и интерпретации результатов.
| Задача ML | Описание | Примеры использования | Типичные алгоритмы |
|---|---|---|---|
| Классификация | Определение категории объекта | Фильтрация спама, распознавание объектов, диагностика заболеваний | Логистическая регрессия, деревья решений, SVM, нейронные сети |
| Регрессия | Предсказание числового значения | Прогноз цен, оценка срока службы оборудования, предсказание потребления ресурсов | Линейная регрессия, регрессионные деревья, нейронные сети |
| Кластеризация | Группировка похожих объектов | Сегментация клиентов, анализ социальных сетей, обнаружение аномалий | K-means, иерархическая кластеризация, DBSCAN |
| Уменьшение размерности | Сокращение числа признаков | Визуализация данных, сжатие информации, предобработка для других моделей | PCA, t-SNE, автоэнкодеры |
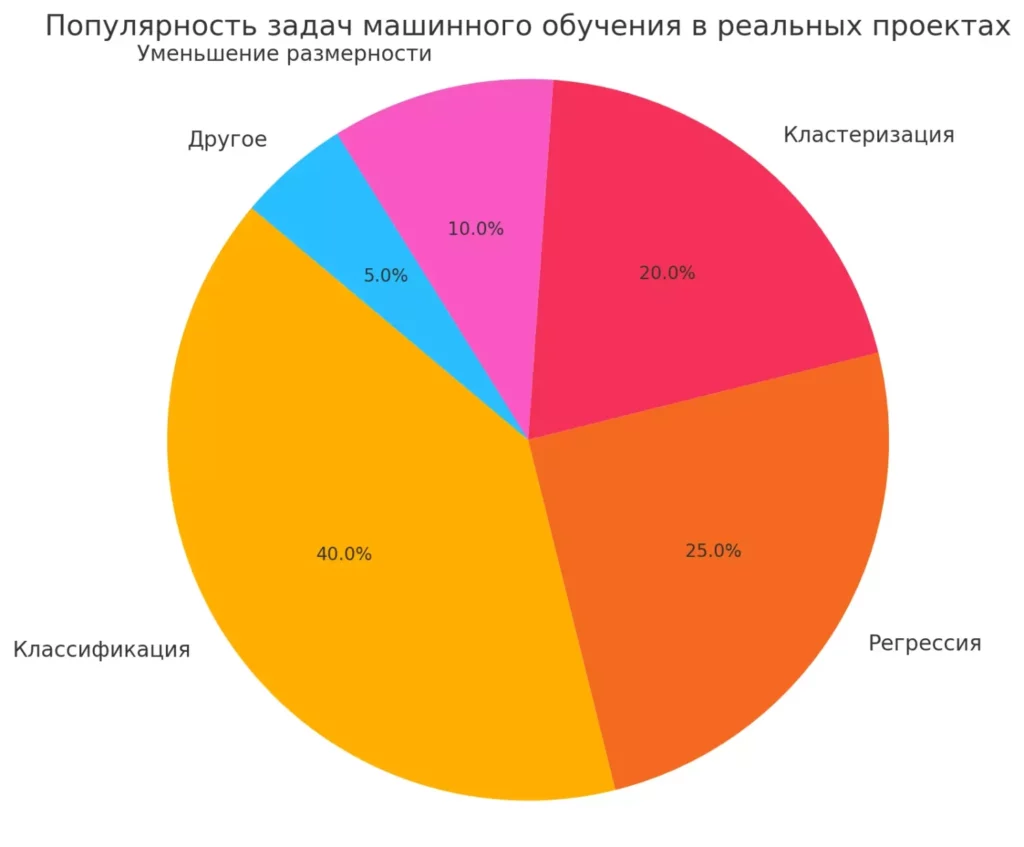
Круговая диаграмма, наглядно демонстрирующая популярность различных задач машинного обучения
Эффективное решение практических задач часто требует комбинирования различных подходов. Например, сначала может применяться уменьшение размерности для подготовки данных, затем кластеризация для выявления групп, и наконец, классификация для предсказания поведения новых объектов. Такой комплексный подход позволяет создавать сложные аналитические системы, способные решать многогранные бизнес-задачи.
Популярные алгоритмы машинного обучения
Эффективность решения задач с помощью machine learning напрямую зависит от выбора подходящего алгоритма. За несколько десятилетий развития этой области сформировался обширный инструментарий методов — от простых линейных моделей до сложных нейронных сетей. Рассмотрим ключевые алгоритмы, которые формируют основу современного ML-ландшафта.
Базовые алгоритмы
Линейная и логистическая регрессия
Эти алгоритмы остаются фундаментом машинного обучения несмотря на свою математическую простоту. Линейная регрессия моделирует зависимость между входными переменными и непрерывной выходной переменной с помощью линейной функции. Её эффективность объясняется интерпретируемостью: коэффициенты модели напрямую показывают влияние соответствующих признаков на результат.
Логистическая регрессия, несмотря на название, решает задачи классификации. Она преобразует линейную комбинацию входных признаков в вероятность принадлежности к определенному классу с помощью логистической функции. Данный алгоритм широко применяется в медицинской диагностике, кредитном скоринге и маркетинговых моделях с бинарным исходом (конверсия произошла/не произошла).
Деревья решений
Деревья решений представляют собой наглядную модель, где каждый узел дерева соответствует проверке значения определенного атрибута, а каждая ветвь — возможному исходу этой проверки. Путь от корня до листа формирует последовательность правил принятия решения.
Этот подход особенно ценится за наглядность результатов и способность работать с данными разных типов без предварительной обработки. Деревья решений лежат в основе многих продвинутых ансамблевых методов, таких как случайный лес (Random Forest) и градиентный бустинг.
Метод опорных векторов (SVM)
Support Vector Machine — мощный алгоритм классификации, который находит оптимальную гиперплоскость, разделяющую классы с максимальным зазором. Ключевая идея SVM — преобразование исходного пространства признаков в пространство более высокой размерности, где разделение классов становится возможным с помощью линейной границы.
SVM демонстрирует высокую эффективность в задачах классификации текстов, изображений и биологических последовательностей, особенно в случаях с небольшими и средними наборами данных.
Продвинутые алгоритмы
Нейросети и глубокое обучение
Искусственные нейронные сети, вдохновленные структурой биологического мозга, представляют собой сложные архитектуры из взаимосвязанных нейронов, организованных в слои. Глубокие нейронные сети (содержащие множество скрытых слоев) произвели революцию в machine learning, демонстрируя беспрецедентную эффективность в задачах компьютерного зрения, обработки естественного языка и распознавания речи.
Архитектуры, такие как свёрточные нейронные сети (CNN) для работы с изображениями, рекуррентные нейронные сети (RNN) и трансформеры для обработки последовательных данных, лежат в основе современных систем ИИ, включая ChatGPT и диффузионные модели генерации изображений.
Градиентный бустинг
Градиентный бустинг представляет собой ансамблевый метод, последовательно комбинирующий слабые модели (обычно деревья решений) в сильную. Каждая новая модель в ансамбле обучается таким образом, чтобы минимизировать ошибки предыдущих моделей.
Реализации градиентного бустинга, такие как XGBoost, CatBoost и LightGBM, регулярно занимают лидирующие позиции в соревнованиях по machine learning и широко применяются в промышленных системах, где требуется высокая точность предсказаний на структурированных данных.
Генеративно-состязательные сети (GANs)
GANs представляют собой архитектуру из двух конкурирующих нейронных сетей: генератора, создающего синтетические образцы, и дискриминатора, пытающегося отличить их от реальных данных. В процессе Learning обе сети совершенствуются, что приводит к созданию генератором всё более реалистичного контента.
Эта технология произвела революцию в области генеративного ИИ, позволив создавать фотореалистичные изображения, реалистичные 3D-модели и даже музыкальные композиции. Практические применения включают создание синтетических данных для Learning других моделей, дизайн продуктов и генерацию медиаконтента.
Когда использовать какой алгоритм
- Для небольших наборов данных с хорошо структурированными признаками: линейная/логистическая регрессия, SVM
- Когда важна интерпретируемость результатов: деревья решений, линейные модели
- Для работы с изображениями: свёрточные нейронные сети, GANs
- Для обработки текста и последовательностей: рекуррентные нейронные сети, трансформеры
- Для высокоточных предсказаний на табличных данных: градиентный бустинг (XGBoost, CatBoost, LightGBM)
- Для выявления сложных нелинейных закономерностей при наличии больших объемов данных: глубокие нейронные сети
- Для генерации нового контента: GANs, диффузионные модели
- Для работы с временными рядами: ARIMA, LSTM, трансформеры
Выбор алгоритма — это искусство балансирования между точностью, интерпретируемостью, скоростью обучения и вычислительными ресурсами. Опытные специалисты по machine learning обычно тестируют несколько подходов, выбирая оптимальный для конкретной задачи и доступных данных. Не существует универсального алгоритма, идеального для всех сценариев, что подчеркивает важность экспериментального подхода в разработке ML-систем.
Как работает процесс машинного обучения
Создание эффективных ML-моделей — это итеративный процесс, включающий несколько взаимосвязанных этапов. Понимание полного цикла разработки моделей машинного Learning критически важно для успешной реализации проектов в этой области. Рассмотрим каждый из этапов этого сложного, но увлекательного процесса.
Сбор данных
Основа любого проекта machine learning — качественные данные. Как гласит известный в ML-сообществе принцип: «Мусор на входе — мусор на выходе». Данные могут поступать из различных источников: внутренних баз данных компании, открытых датасетов, API, результатов опросов, сенсоров IoT-устройств и т.д.
На этом этапе важно не просто накопить максимальный объем информации, но и убедиться в её репрезентативности — то есть, в том, что собранные данные адекватно отражают реальную среду, в которой будет применяться модель. Недостаточное разнообразие данных может привести к созданию модели, работающей корректно только в ограниченном наборе сценариев.
Очистка и подготовка данных
Этот этап часто называют «черновой работой» machine learning, но именно здесь закладывается фундамент успеха модели. По оценкам экспертов, до 80% времени в ML-проектах тратится именно на подготовку данных, которая включает:
- Обработку пропущенных значений (заполнение средними, медианами или прогнозными значениями)
- Удаление выбросов и дубликатов
- Нормализацию данных (приведение к единому масштабу)
- Кодирование категориальных переменных
- Извлечение новых признаков (feature engineering)
Качественно выполненная подготовка данных существенно улучшает производительность моделей и упрощает последующие этапы разработки.
Выбор модели
Выбор подходящего алгоритма основывается на характере решаемой задачи, особенностях данных и требованиях к конечному результату. Здесь необходимо учитывать такие аспекты, как:
- Объем доступных данных (некоторые модели, особенно нейронные сети, требуют больших датасетов)
- Линейность взаимосвязей между переменными
- Требования к интерпретируемости результатов
- Вычислительные ресурсы и ограничения по времени Learning/инференса
- Требования к точности и допустимый уровень ошибок
Как правило, эффективнее начинать с простых моделей (например, линейной регрессии), постепенно переходя к более сложным алгоритмам по мере необходимости.
Обучение модели
На этом этапе алгоритм «учится» на предоставленных данных, корректируя свои внутренние параметры для минимизации ошибки предсказания. Процесс Learning включает:
- Разделение данных на обучающую, валидационную и тестовую выборки
- Настройку гиперпараметров модели (параметров, которые не меняются в процессе обучения)
- Собственно Learning на тренировочных данных
- Регуляризацию для предотвращения переобучения
Современные фреймворки машинного обучения, такие как scikit-learn, TensorFlow и PyTorch, значительно упрощают этот процесс, предоставляя готовые инструменты для Learning различных типов моделей.
Тестирование и оценка качества
Обученная модель проверяется на данных, которые не использовались при обучении, чтобы оценить её способность к обобщению. В зависимости от типа задачи применяются различные метрики:
- Для классификации: точность (accuracy), полнота (recall), F1-мера
- Для регрессии: среднеквадратичная ошибка (MSE), коэффициент детерминации (R²)
- Для ранжирования: NDCG, MAP
На этом этапе также проводится анализ ошибок модели, что может привести к пересмотру выбранного алгоритма или дополнительной обработке данных.
Деплой модели
Завершающий этап — внедрение модели в производственную среду. Это включает:
- Интеграцию с существующими системами и API
- Оптимизацию для эффективного выполнения (например, квантизацию параметров)
- Настройку мониторинга производительности
- Разработку механизмов для периодического переобучения модели на новых данных
Важно отметить, что процесс ML редко бывает линейным. Часто приходится возвращаться к предыдущим этапам, корректировать подходы, собирать дополнительные данные или менять алгоритмы на основе полученных результатов. Такая итеративность — не недостаток, а естественная часть процесса, отражающая его экспериментальную природу.
Эффективное управление этим сложным процессом требует не только технических навыков, но и глубокого понимания предметной области, что делает междисциплинарный подход ключевым фактором успеха в проектах machine learning.
Где применяется машинное обучение
ML уже давно вышло за пределы исследовательских лабораторий и стало неотъемлемой частью множества отраслей. Сегодня эта технология трансформирует бизнес-процессы, научные исследования и повседневную жизнь, зачастую оставаясь невидимой для конечного пользователя. Рассмотрим ключевые сферы применения ML-технологий и конкретные примеры их использования.
Распознавание изображений и речи
Область компьютерного зрения и распознавания речи — одна из наиболее динамично развивающихся в контексте machine learning. Алгоритмы CV (Computer Vision) и ASR (Automatic Speech Recognition) позволили создать продукты, которые стали частью повседневной жизни миллионов людей:
- Биометрическая аутентификация (Face ID, сканеры отпечатков пальцев) — технологии, превратившие смартфон в персонального помощника, распознающего своего владельца
- Голосовые помощники (Алиса, Siri, Google Assistant) — системы, способные понимать естественную речь и отвечать на вопросы, управлять устройствами и взаимодействовать с пользователем
- Системы видеонаблюдения с функцией распознавания лиц, используемые для обеспечения безопасности в общественных местах и на предприятиях
- Автоматическая модерация контента на платформах социальных медиа, позволяющая выявлять нежелательный и запрещенный материал
Интересно отметить, что алгоритмы распознавания изображений достигли такого уровня развития, что в некоторых задачах (например, в классификации рентгеновских снимков) превосходят специалистов-людей по точности и скорости обработки.
Рекомендательные системы
Рекомендательные алгоритмы изменили способ потребления контента и совершения покупок. Они анализируют прошлое поведение пользователя и поведение похожих пользователей для формирования персонализированных предложений:
- Стриминговые сервисы (Netflix, YouTube, Яндекс Музыка) используют ML для предложения контента, соответствующего вкусам конкретного пользователя
- Интернет-магазины (Amazon, Ozon) анализируют историю покупок и просмотров для формирования персонализированных товарных рекомендаций
- Новостные агрегаторы формируют ленту на основе интересов пользователя, увеличивая вовлеченность и время, проведенное на платформе
По данным Netflix, более 80% контента, который смотрят пользователи сервиса, они находят благодаря рекомендательной системе, что подчеркивает экономическую значимость этих алгоритмов.
Финансы
Финансовый сектор — один из пионеров в области внедрения ML-технологий, использующий их для минимизации рисков и оптимизации операций:
- Антифрод-системы анализируют транзакции в режиме реального времени, выявляя подозрительные операции и предотвращая мошенничество
- Кредитный скоринг — автоматизированная оценка кредитоспособности заемщиков на основе множества параметров, включая кредитную историю, доходы и даже поведенческие факторы
- Алгоритмическая торговля — использование ML для прогнозирования движения рынка и автоматического совершения сделок
- Персонализированные финансовые советы — анализ финансового поведения пользователя для предоставления рекомендаций по сбережениям, инвестициям и расходам
Медицина
Здравоохранение — сфера, где машинное Learning имеет потенциал не просто оптимизировать процессы, но и спасать жизни:
- Диагностика заболеваний по медицинским изображениям (рентген, МРТ, КТ) с точностью, сопоставимой или превосходящей человеческую
- Прогнозирование вспышек заболеваний на основе анализа больших данных о распространении инфекций
- Разработка лекарств — ML ускоряет процесс скрининга потенциальных лекарственных соединений и моделирования их взаимодействия с биологическими мишенями
- Персонализированная медицина — подбор оптимальных методов лечения на основе генетического профиля пациента и истории болезни
Примечательно достижение DeepMind (AlphaFold) в предсказании структуры белков, что может революционизировать понимание многих заболеваний и создание новых методов лечения.
Самоуправляемые автомобили
Автономные транспортные средства — одно из наиболее амбициозных применений машинного Learning:
- Распознавание дорожной обстановки — идентификация других участников движения, дорожных знаков, разметки и препятствий
- Прогнозирование поведения других участников дорожного движения
- Планирование маршрута и принятие решений в сложных дорожных ситуациях
- Адаптация к различным условиям движения, включая плохую видимость и неблагоприятные погодные условия
Промышленность и автоматизация
Производственный сектор активно внедряет ML для оптимизации процессов и повышения эффективности:
- Предиктивное техобслуживание — прогнозирование выхода из строя оборудования для планирования своевременного ремонта
- Контроль качества — автоматизированное выявление дефектов продукции с использованием компьютерного зрения
- Оптимизация цепочек поставок — прогнозирование спроса и оптимизация логистических процессов
- Автоматизация производственных процессов с использованием роботов, обученных с помощью ML выполнять сложные операции
Внедрение ML-технологий в промышленности часто ассоциируется с концепцией «Индустрии 4.0» — новой парадигмой организации производства, основанной на автоматизации, обмене данными и использовании киберфизических систем.
Разнообразие и масштаб применения machine learning продолжают расширяться, проникая в новые отрасли и трансформируя существующие бизнес-модели. Эта тенденция, подкрепленная непрерывным совершенствованием алгоритмов и увеличением доступных вычислительных мощностей, создает беспрецедентные возможности для организаций, готовых инвестировать в ML-технологии и адаптировать их к своим специфическим потребностям.
Инструменты и платформы для работы с машинным обучением
Современный ландшафт инструментов для machine learning поражает своим разнообразием — от библиотек с открытым исходным кодом до полноценных облачных платформ. Выбор подходящего инструментария критически важен для успешной реализации ML-проектов, поскольку он определяет не только скорость разработки, но и возможности масштабирования решений. Рассмотрим ключевые категории инструментов, доступных специалистам по машинному Learning.
Python и библиотеки для ML
Python стал де-факто стандартным языком для machine learning благодаря своей читаемости, гибкости и обширной экосистеме библиотек. Наиболее важные из них:
- scikit-learn — универсальная библиотека для классического машинного Learning с понятным API и обширной документацией. Предоставляет реализации большинства популярных алгоритмов, инструменты для предобработки данных и оценки моделей.
- TensorFlow — мощный фреймворк от Google, ориентированный на глубокое обучение. Поддерживает распределенные вычисления на GPU и TPU, что критически важно для Learning сложных нейронных сетей. TensorFlow включает высокоуровневый API Keras, существенно упрощающий создание и обучение нейронных сетей.
- PyTorch — гибкий фреймворк для глубокого обучения, разработанный Facebook. Отличается динамическим построением вычислительного графа, что делает его особенно удобным для исследовательской работы и экспериментов. Многие современные научные публикации в области ИИ основаны на PyTorch.
- Pandas — незаменимый инструмент для обработки табличных данных, предоставляющий структуры данных и функции для эффективной работы с ними.
- NumPy — библиотека для эффективных вычислений с многомерными массивами, которая лежит в основе большинства других ML-библиотек.
Эти и другие Python-библиотеки (Matplotlib, Seaborn для визуализации; NLTK, spaCy для обработки естественного языка; OpenCV для компьютерного зрения) формируют комплексную экосистему, позволяющую решать широкий спектр задач machine learning.
Облачные решения для машинного обучения
Облачные платформы демократизировали доступ к вычислительным ресурсам, необходимым для сложных ML-задач, и предоставили инструменты для масштабирования решений:
- Yandex.Cloud предлагает интегрированную платформу DataSphere для полного цикла разработки ML-моделей. Особенно ценным является возможность бесшовного переключения между разными типами вычислительных ресурсов (CPU и GPU) без остановки процесса Learning. Платформа также упрощает интеграцию с другими сервисами Яндекса.
- Google AI Platform (ранее Google Cloud ML) предоставляет инструменты для всех этапов ML-проекта: от обработки данных (BigQuery) до обучения моделей и их развертывания. Платформа тесно интегрирована с TensorFlow и позволяет использовать специализированные ускорители (TPU).
- Amazon SageMaker — комплексное решение от AWS, упрощающее построение, обучение и деплой ML-моделей. Включает инструменты для автоматизации подготовки данных, выбора алгоритмов и оптимизации гиперпараметров.
- Microsoft Azure Machine Learning предлагает визуальный интерфейс для создания моделей и автоматизации ML-процессов, что делает его доступным даже для специалистов с ограниченным опытом в программировании.
Облачные решения особенно актуальны для компаний, которые не хотят инвестировать в собственную инфраструктуру или нуждаются в гибком масштабировании ресурсов в зависимости от текущих потребностей.
No-code платформы для ML
Наряду с развитием профессиональных инструментов, появляются платформы, позволяющие создавать ML-модели без написания кода:
- Google AutoML предоставляет интуитивно понятный интерфейс для Learning моделей компьютерного зрения, обработки естественного языка и структурированных данных без необходимости углубляться в технические детали.
- Obviously AI позволяет создавать прогностические модели на основе CSV-файлов, автоматизируя предобработку данных и выбор алгоритмов.
- Create ML от Apple упрощает создание ML-моделей для iOS-приложений, позволяя разработчикам с минимальными знаниями в области ML интегрировать интеллектуальные функции в свои продукты.
Эти платформы делают технологии machine learning доступными для малого и среднего бизнеса, а также для отраслевых специалистов без глубоких технических знаний.
Выбор инструментов для конкретного ML-проекта должен основываться на таких факторах, как характер решаемой задачи, доступные вычислительные ресурсы, требования к масштабированию и уровень технической экспертизы команды. Зачастую наиболее эффективным подходом является комбинирование различных инструментов — например, разработка и прототипирование с использованием Python-библиотек с последующим развертыванием и масштабированием в облачной среде.
По мере развития отрасли ML мы наблюдаем тенденцию к упрощению инструментов, что делает эту технологию доступной для всё более широкого круга специалистов и организаций, не обладающих глубокой технической экспертизой в области ИИ и анализа данных.
Будущее машинного обучения
ML находится на перекрестке стремительного технологического развития и растущих общественных ожиданий. Потенциал этой технологии далеко не исчерпан, и в ближайшие годы мы, вероятно, станем свидетелями ее дальнейшей эволюции в нескольких ключевых направлениях.
Развитие Explainable AI
Одна из существенных проблем современных ML-систем, особенно сложных нейронных сетей, — их непрозрачность. Эти «черные ящики» могут давать точные предсказания, но зачастую невозможно понять, почему система пришла к тому или иному решению. Это создает серьезные ограничения для применения ML в областях с высокими требованиями к объяснимости, таких как медицина, финансы или юриспруденция.
Explainable AI (XAI) — направление, нацеленное на создание моделей, способных не только давать ответы, но и объяснять свою логику понятным для человека образом. Успехи в этой области могут значительно расширить сферу применения ML-технологий, открывая доступ к отраслям, где доверие к алгоритмам критически важно.
Как отметил один из ведущих исследователей в области XAI: «Недостаточно просто получить правильный ответ — мы должны понимать, как и почему этот ответ был получен. Только тогда мы сможем по-настоящему доверять машинному интеллекту».
Нейросети и творческие профессии
Генеративные модели, такие как GPT и Stable Diffusion, демонстрируют впечатляющие результаты в создании текстов, изображений и даже музыки. Эти технологии не столько заменяют творческих профессионалов, сколько трансформируют характер их работы, предоставляя новые инструменты и возможности.
В ближайшие годы мы, вероятно, увидим более глубокую интеграцию ML-инструментов в творческие процессы. Дизайнеры будут использовать генеративные модели для быстрого прототипирования, писатели — для поиска новых идей и расширения своих возможностей, а композиторы — для экспериментов с новыми музыкальными формами.
Интересно отметить, что этот процесс создает не только технологические, но и философские вопросы о природе творчества, авторстве и интеллектуальной собственности. Кому принадлежат права на произведение, созданное человеком с помощью ИИ? Можно ли считать такое произведение оригинальным? Эти вопросы потребуют новых правовых и этических рамок.
Этика в ML
По мере того как ML-системы становятся все более влиятельными в обществе, вопросы этики и ответственности выходят на первый план. Проблемы предвзятости алгоритмов, конфиденциальности данных и социальных последствий автоматизации требуют комплексного подхода.
Формирующееся направление «этичного ИИ» стремится разработать принципы и практики, обеспечивающие справедливое, прозрачное и ответственное использование ML-технологий. Это включает методы выявления и устранения предвзятости в данных, механизмы защиты персональной информации и инструменты для оценки социальных последствий внедрения ИИ-систем.
Многие технологические компании и исследовательские институты создают комитеты по этике ИИ, разрабатывают принципы ответственного использования технологий и инвестируют в исследования, направленные на минимизацию негативных последствий автоматизации.
В конечном счете, будущее machine learning зависит не только от технических достижений, но и от того, насколько успешно общество сможет интегрировать эти технологии в существующие социальные, экономические и правовые структуры. Баланс между инновациями и ответственностью, между эффективностью и справедливостью будет определять траекторию развития ML в предстоящие годы.
Какой бы ни была эта траектория, одно можно сказать с уверенностью: ML останется одной из ключевых трансформирующих технологий нашего времени, продолжая менять способы, которыми мы работаем, учимся, взаимодействуем и решаем сложные проблемы глобального масштаба.

«Слишком опытный» — теперь снова минус: как рынок труда развернулся против сильных кандидатов
В 2026 году каждый пятый работодатель принципиально не рассматривает кандидатов с избыточной квалификацией — год назад таких компаний было вдвое меньше. Рынок стал конкурентнее: вакансий меньше, резюме больше, а сильное прошлое уже не гарантирует оффер. Разбираемся, кого это касается и что с этим делать.

Чек-лист для маркетинга: 9 признаков курса, который даст вам практику, а не красивую теорию
Чек-лист курса по маркетингу поможет понять, где вас действительно научат работать руками, а где предложат только лекции и красивые обещания. Разберем, какие вопросы задать до оплаты, как оценить практику, фидбэк и программу, чтобы выбрать обучение без лишнего риска.

Devman vs Яндекс Практикум: где лучше изучать Python, если нет свободного времени
Devman vs Яндекс Практикум — разберём, где проще учиться взрослому новичку с работой, семьёй и ограниченным временем: в свободном темпе или по расписанию с дедлайнами?

Что проверить перед покупкой обучения, если цель — выйти на новую работу за 6 месяцев
Обучение для трудоустройства может помочь сменить профессию, но как понять, что курс действительно ведёт к работе, а не только обещает результат? Разбираем, какие вопросы задать школе, как проверить программу по вакансиям и на что смотреть в договоре до оплаты.