SQL-индексы: что это и как правильно применять в базе данных
Вас раздражают медленные запросы к базе данных? Индексы в SQL помогают кардинально ускорить выборку и упорядочивание информации. Но не всё так просто: при неправильном использовании индексы могут навредить производительности.

Эта статья расскажет, как работают индексы, какие бывают их типы, как выбирать подходящий вариант — и где кроется опасность. Особенно полезно для разработчиков, аналитиков и администраторов, работающих с большими объёмами данных.
- Как работают индексы в базе данных?
- Основные типы
- Создание индексов в SQL
- Как выбрать подходящий тип?
- Анализ паттернов запросов
- Учет системных требований
- Рекомендации по выбору
- Плюсы и минусы использования индексов
- Заключение
Как работают индексы в базе данных?
В мире баз данных index играют роль высокоэффективных навигаторов, и их внутреннее устройство заслуживает особого внимания. Давайте разберем, как именно работает этот механизм, который делает наши запросы молниеносными.
Представьте, что индекс — это своеобразная древовидная карта данных. В основе большинства современных index лежит структура, которая называется B-дерево (сбалансированное дерево). Это не просто метафора — это реальная организация данных, где информация располагается иерархически, начиная с корневого узла и заканчивая листьями.
Скриншот из pgAdmin 4 — популярного инструмента управления PostgreSQL. На изображении видно главное окно мониторинга: графики активности сервера, количество транзакций в секунду, чтений и вставок (Tuples in/out), нагрузка по чтению с диска (Block I/O), а также активность сеансов и список подключённых клиентов. Слева — дерево объектов базы данных, включая таблицы и схемы.
Процесс работы индекса можно разделить на несколько ключевых этапов:
- Создание структуры: При создании index СУБД анализирует данные в указанных столбцах и строит древовидную структуру, где каждый узел содержит значения ключей и указатели на соответствующие записи в таблице.
- Поддержание баланса: Система постоянно следит за тем, чтобы дерево оставалось сбалансированным — это критически важно для обеспечения стабильной производительности. При добавлении или удалении данных происходит автоматическая перестройка структуры.
- Процесс поиска: Когда приходит запрос, СУБД начинает навигацию с корневого узла, последовательно спускаясь по веткам дерева к нужным данным. Благодаря этому время поиска сокращается логарифмически — вместо просмотра тысяч записей система делает всего несколько переходов.
Что особенно интересно — при изменении данных в таблице index автоматически обновляется. Это похоже на то, как современные навигационные системы перестраивают маршрут при появлении пробок: процесс происходит в реальном времени и практически незаметно для пользователя.
Однако важно понимать: каждый индекс требует дополнительного места для хранения и вычислительных ресурсов для поддержания в актуальном состоянии. Именно поэтому бездумное создание index может привести к обратному эффекту — снижению производительности базы данных.
Основные типы
В мире баз данных существует целый арсенал различных типов index , каждый из которых предназначен для решения специфических задач. Давайте разберем основные типы и их особенности — это поможет нам делать осознанный выбор при проектировании баз данных.
Кластеризованные и некластеризованные
Начнем с фундаментального различия. Представьте себе два разных подхода к организации библиотеки. В первом случае книги физически расставлены по алфавиту (кластеризованный индекс), во втором — есть отдельный каталог с карточками, указывающими на местоположение книг (некластеризованный).
Кластеризованный index:
- Определяет физический порядок данных в таблице
- Может быть только один на таблицу
- Обеспечивает более быстрый доступ к данным
- Занимает больше места на диске
Некластеризованный index:
- Хранит указатели на данные отдельно от самих данных
- Можно создать несколько для одной таблицы
- Требует дополнительный шаг для доступа к данным
- Более компактный
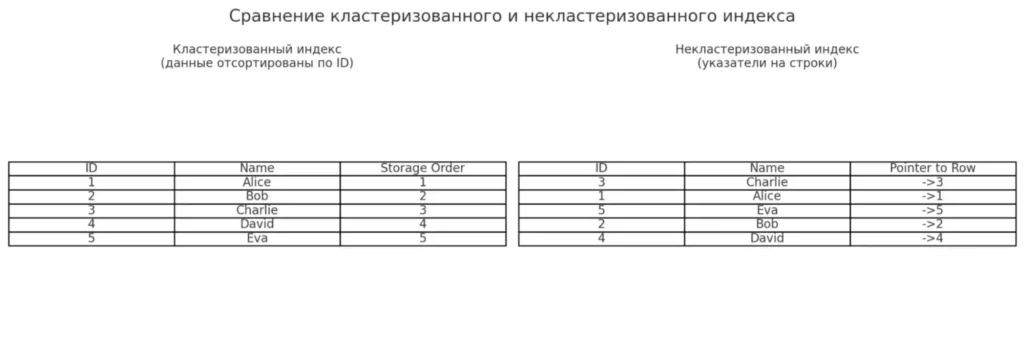
Левая таблица демонстрирует кластеризованный индекс, где строки физически упорядочены по значению ID. Правая — пример некластеризованного индекса: записи расположены в произвольном порядке, а индекс содержит указатели на строки. Такая наглядность помогает понять, почему кластеризованный индекс быстрее при последовательном доступе.
Уникальные и неуникальные
Это разделение основано на требованиях к уникальности значений:
Уникальный:
- Гарантирует уникальность значений в столбце
- Часто используется для первичных ключей
- Автоматически предотвращает дубликаты
Неуникальный:
- Допускает повторяющиеся значения
- Подходит для столбцов с часто повторяющимися данными
- Обычно используется для оптимизации поиска
Специализированные типы индексов
В современных СУБД также представлен ряд специализированных индексов:
Bitmap:
- Эффективен для столбцов с небольшим количеством уникальных значений
- Использует битовые карты для представления данных
- Особенно полезен в хранилищах данных
Хеш:
- Оптимален для точного поиска по равенству
- Не подходит для поиска по диапазону значений
- Обеспечивает очень быстрый доступ к данным
Полнотекстовый:
- Специально разработан для поиска по текстовым данным
- Поддерживает сложные текстовые запросы
- Включает механизмы токенизации и морфологического анализа
Выбор типа индекса напрямую влияет на производительность базы данных и эффективность запросов. При этом важно помнить, что универсального решения не существует — каждый тип имеет свои сильные и слабые стороны, которые необходимо учитывать при проектировании системы.
Создание индексов в SQL
Теоретические знания об index важны, но без практического применения они остаются лишь абстрактными концепциями. Давайте рассмотрим, как создавать и управлять индексами в реальных условиях, используя SQL.
Базовый синтаксис создания индексов
Начнем с простейшего случая — создания обычного index. В большинстве современных СУБД синтаксис выглядит следующим образом:
CREATE INDEX index_name ON table_name (column_name);
Однако на практике часто требуются более сложные конструкции. Рассмотрим несколько практических примеров:
Создание составного индекса
Когда поиск часто осуществляется по нескольким столбцам одновременно, имеет смысл создать составной index:
CREATE INDEX client_search_idx ON orders (client_name, client_city, client_country);
Важно отметить, что порядок столбцов в составном индексе имеет значение — он влияет на эффективность различных типов запросов.
Создание уникального индекса
Для обеспечения уникальности значений используется следующий синтаксис:
CREATE UNIQUE INDEX unique_order_idx ON orders (order_id);
Управление существующими индексами
В процессе эксплуатации базы данных часто возникает необходимость в модификации или удалении индексов:
-- Удаление индекса DROP INDEX index_name; -- Переименование индекса ALTER INDEX old_index_name RENAME TO new_index_name;
Частичные индексы
Особый интерес представляют частичные index, которые создаются только для подмножества строк, удовлетворяющих определенному условию:
Это особенно полезно, когда нам нужно оптимизировать запросы, работающие только с определенной частью данных.
Специфика различных СУБД
CREATE INDEX active_clients_idx ON orders (client_id) WHERE client_status = 'active';
Важно понимать, что разные СУБД могут иметь свои особенности в синтаксисе и возможностях создания index. Например, в PostgreSQL есть возможность создания индексов с использованием различных методов доступа:
CREATE INDEX text_pattern_idx ON messages USING GiST (message_text);
При работе с индексами следует всегда консультироваться с документацией конкретной СУБД, чтобы использовать все доступные возможности оптимизации.
Как выбрать подходящий тип?
Выбор правильного типа index — это искусство балансирования между производительностью запросов и накладными расходами на поддержание индексов. Давайте разберем основные критерии, которые помогут принять взвешенное решение.
Анализ характера данных
Прежде всего, необходимо понять характеристики данных, с которыми мы работаем:
- Для уникальных идентификаторов (например, ID пользователей или номера заказов) оптимальным выбором будет уникальный индекс.
- Для столбцов с низкой кардинальностью (например, статус заказа или пол пользователя) bitmap-index могут быть более эффективны.
- Для текстовых данных с необходимостью полнотекстового поиска следует рассмотреть специализированные полнотекстовые индексы.
Анализ паттернов запросов
Не менее важно понимать, как данные будут использоваться:
- Если преобладают запросы точного соответствия (WHERE column = value), хеш-index могут обеспечить оптимальную производительность.
- При частых запросах по диапазону значений (WHERE column BETWEEN x AND y) лучше использовать B-tree индексы.
- Для сложных условий поиска с множеством столбцов стоит рассмотреть составные index.
Учет системных требований
Важно принимать во внимание технические ограничения:
- Доступное дисковое пространство
- Нагрузка на систему во время обновления данных
- Требования к скорости выполнения запросов
Рекомендации по выбору
Для таблиц с частыми операциями чтения и редкими изменениями:
- Можно создавать больше index
- Рассмотреть возможность использования составных индексов
- Не бояться специализированных типов индексов
Для таблиц с частыми изменениями:
- Минимизировать количество index
- Использовать только самые необходимые индексы
- Избегать составных index, если это возможно
Для критически важных запросов:
- Провести тестирование производительности с различными типами индексов
- Рассмотреть возможность денормализации данных
- Использовать частичные index для оптимизации конкретных сценариев
Помните, что выбор типа индекса — это не окончательное решение. Важно регулярно анализировать производительность и быть готовым к изменениям по мере эволюции вашей системы.
Плюсы и минусы использования индексов
В мире баз данных, как и в реальной жизни, любое решение имеет свои последствия. Использование index не является исключением — это мощный инструмент оптимизации, который при неправильном применении может создать больше проблем, чем решить. Давайте рассмотрим основные преимущества и недостатки индексирования.
Преимущества использования индексов
Ускорение поиска данных
- Значительное сокращение времени выполнения запросов
- Эффективная обработка сложных условий поиска
- Оптимизация сортировки и группировки данных
Обеспечение целостности данных
- Гарантия уникальности значений через уникальные index
- Поддержка ссылочной целостности в отношениях между таблицами
- Предотвращение дублирования критически важных данных
Оптимизация производительности
- Снижение нагрузки на процессор при выполнении запросов
- Уменьшение количества операций ввода-вывода
- Повышение скорости агрегационных функций
Недостатки использования индексов
Дополнительные ресурсы
- Увеличение размера базы данных
- Дополнительная нагрузка на систему при обновлении данных
- Потребление оперативной памяти для кэширования индексов
Замедление операций модификации
- Увеличение времени выполнения INSERT-запросов
- Снижение производительности при массовых UPDATE-операциях
- Дополнительные затраты на реорганизацию index
Сложность администрирования
- Необходимость регулярного обслуживания индексов
- Потребность в мониторинге и анализе использования
- Риск фрагментации index при длительной эксплуатации
Как мы видим, индексы — это палка о двух концах, и их использование требует взвешенного подхода.
Заключение
В современном мире, где скорость доступа к данным играет критическую роль, правильное использование индексов становится не просто преимуществом, а необходимостью. В ходе нашего обзора мы рассмотрели различные аспекты работы с индексами — от базовых концепций до практических рекомендаций по их применению.
Ключевой вывод, который мы можем сделать: индексы — это мощный инструмент оптимизации, но их эффективное использование требует глубокого понимания как теоретических основ, так и практических аспектов работы с базами данных. Важно помнить, что нет универсальных решений — каждый случай требует индивидуального подхода и тщательного анализа.
При работе с индексами следует придерживаться золотой середины: создавать достаточное количество индексов для оптимизации производительности, но не настолько много, чтобы это начало негативно влиять на работу системы. Регулярный мониторинг, анализ и обслуживание индексов должны стать неотъемлемой частью процесса администрирования базы данных.
Мир баз данных продолжает развиваться, появляются новые типы индексов и методы оптимизации. Следите за новыми возможностями, которые предоставляют современные СУБД, но не забывайте о фундаментальных принципах, которые мы обсудили в этой статье.
Чтобы закрепить полученные знания и научиться эффективно применять индексы в реальных проектах, рекомендуем обратить внимание на специализированные курсы по SQL. Практические занятия под руководством опытных преподавателей помогут быстрее освоить не только работу с индексами, но и другие аспекты оптимизации запросов, проектирования баз данных и администрирования СУБД. Такой подход позволит превратить теоретические знания в практические навыки, которые высоко ценятся в IT-индустрии.

GitOps: революция в управлении инфраструктурой
GitOps превращает Git в центр управления инфраструктурой. Как этот подход упрощает развертывание и делает его безопасным? Разбираем ключевые принципы.

Нейросети для фриланса: на каких навыках сейчас можно заработать быстрее всего?
Нейросети для фриланса уже перестали быть экспериментом — но какие навыки действительно приносят первые деньги? Какие услуги покупают бизнесы и как выйти на стабильный доход без опыта? Разбираем реальные сценарии заработка, риски и быстрые стратегии старта.

Как провести аттестацию сотрудников без рисков и ошибок
Аттестация персонала помогает бизнесу выявлять сильных специалистов и мотивировать сотрудников. Но что делать, чтобы избежать распространённых ошибок?