AIOps: что это такое, как работает и зачем нужен бизнесу и IT-командам

Современные IT-инфраструктуры переживают беспрецедентную трансформацию. Компании переходят от монолитных приложений к микросервисной архитектуре, активно используют гибридные и мультиоблачные среды, внедряют контейнеризацию и оркестрацию. Каждый из этих элементов генерирует огромные объемы данных — логи, метрики, события, трассировки. В результате даже относительно небольшая инфраструктура может производить десятки тысяч событий ежедневно, что создает принципиально новые вызовы для IT-операций.
- Что такое AIOps — простое и формальное определение
- Как работает AIOps — архитектура и жизненный цикл
- Ключевые функции и возможности AIOps-платформ
- Преимущества AIOps для бизнеса и IT-команд
- Практические сценарии применения AIOps
- AIOps vs другие подходы: DevOps, Observability, MLOps
- Эволюция AIOps: Predictive → Agentic AIOps
- Как выбрать AIOps-платформу
- Ошибки при внедрении
- Кейсы внедрения AIOps (обзорные)
- Заключение
- Рекомендуем посмотреть курсы по обучению DevOps
Что такое AIOps — простое и формальное определение
Термин AIOps был введен аналитической компанией Gartner в 2016 году как сокращение от «Algorithmic IT Operations» и впоследствии трансформировался в «Artificial Intelligence for IT Operations». По определению Gartner, AIOps представляет собой подход к управлению IT-операциями, который объединяет технологии больших данных (Big Data) и машинного обучения (Machine Learning) для автоматизации и усовершенствования процессов мониторинга, управления событиями и реагирования на инциденты.
Концепция AIOps стала логическим продолжением более ранней практики IT Operations Analytics (ITOA), отражая следующий этап эволюции управления IT-инфраструктурой. Если ITOA фокусировалась на сборе и анализе операционных данных, то эта методология идет значительно дальше, применяя продвинутые алгоритмы искусственного интеллекта для автономного принятия решений и проактивного управления.
Согласно исследованиям Gartner, в 2018 году лишь 5% компаний отмечали, что AIOps является частью их IT-стратегии. Однако уже к 2023 году этот показатель вырос до 30%, а прогнозы BCC Research указывают на рост глобального рынка с $3 миллиардов в 2021 году до $9,4 миллиардов в 2026 при среднегодовых темпах роста 26%. Эти цифры красноречиво демонстрируют, что индустрия признала критическую важность интеллектуального подхода к управлению IT-операциями.
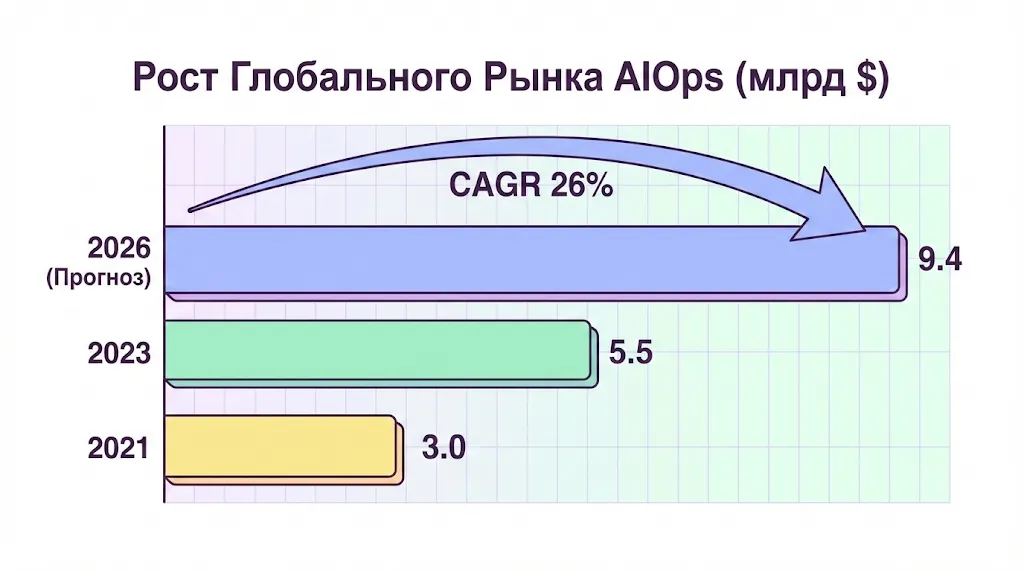
AIOps демонстрирует стремительный рост с прогнозируемым среднегодовым темпом (CAGR) в 26%, что подтверждает растущий интерес бизнеса к интеллектуальной автоматизации.
Простое объяснение для бизнеса
Представим ситуацию, с которой сталкивается любая современная компания: десятки, а то и сотни приложений и сервисов работают одновременно, каждый генерирует данные о своем состоянии. Традиционный подход можно сравнить с попыткой одновременно следить за сотней телевизоров, каждый из которых показывает свой канал — информационная перегрузка гарантирована.
Технология AIOps работает как интеллектуальный помощник, который не просто наблюдает за всеми этими «каналами», но и понимает, что происходит, выделяет действительно важное и даже предсказывает неполадки до их возникновения. Если выразиться проще: она превращает огромные массивы операционных данных в интеллектуальную систему, способную самостоятельно выявлять аномалии, находить корневые причины проблем и автоматически устранять инциденты — всё это с минимальным участием человека.
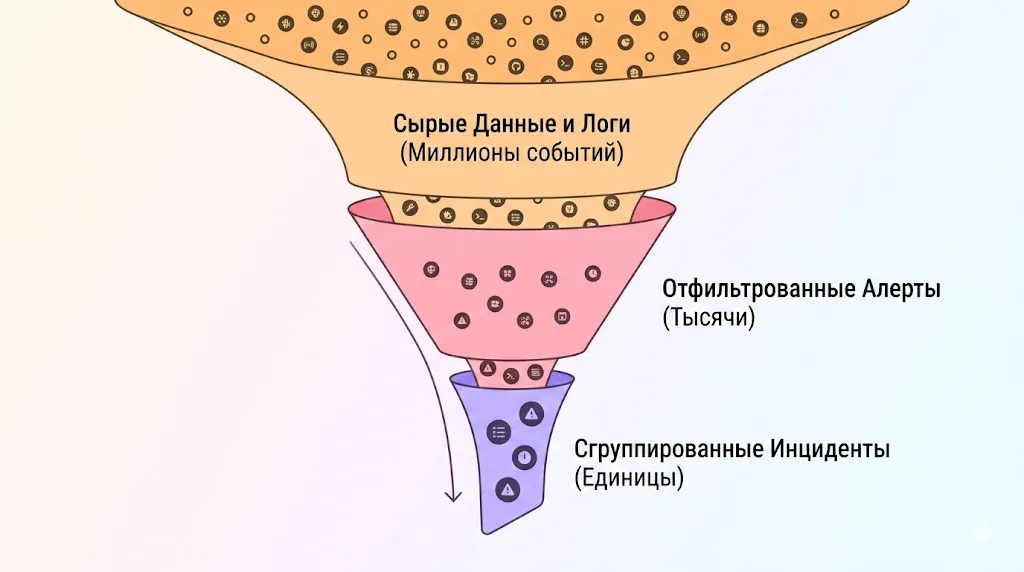
AIOps действует как интеллектуальный фильтр, превращая миллионы сырых событий и тысячи алертов в небольшое число значимых инцидентов, требующих внимания специалиста.
Например, если сетевой коммутатор выходит из строя, традиционная система может сгенерировать 500 оповещений от всех подключенных серверов. Платформа AIOps распознает, что коммутатор является единственной первопричиной, подавит 499 избыточных оповещений и отправит одно четкое уведомление сетевой команде с контекстом проблемы и предлагаемыми действиями.
Ключевые технологии в основе AIOps:
- Machine Learning (ML) — алгоритмы обучаются на исторических данных и выявляют паттерны нормального поведения систем.
- Natural Language Processing (NLP) — обработка неструктурированных данных, таких как логи и тикеты.
- Корреляция событий — установление причинно-следственных связей между разрозненными событиями.
- Анализ аномалий — автоматическое обнаружение отклонений от базовой линии производительности.
- Предиктивная аналитика — прогнозирование потенциальных проблем на основе трендов.
Стоит отметить, что AIOps — это не отдельный инструмент, а комплексная платформа, которая интегрируется с существующей экосистемой мониторинга и управления, обогащая ее интеллектуальными возможностями.
Традиционный подход к мониторингу, основанный на ручном анализе и реагировании постфактум, больше не справляется с этой сложностью. Классические решения мониторинга работают по принципу «обнаружил проблему — создай алерт», что приводит к нескольким критическим неполадкам.
Типичные проблемы IT-операций без AIOps:
- Информационный шум и усталость от алертов. Когда механизмы генерируют сотни оповещений в день, IT-специалисты теряют способность различать действительно критические инциденты. По некоторым оценкам, до 90% алертов в традиционных решениях являются ложными срабатываниями или дубликатами связанных событий.
- Задержки в обнаружении реальных проблем. Важные инциденты теряются в потоке незначительных уведомлений. К тому моменту, когда неполадка становится очевидной, она уже успевает повлиять на конечных пользователей и бизнес-процессы.
- Высокое время восстановления (MTTR). Инженеры тратят до 80% времени на поиск первопричины проблемы и только 20% — на ее устранение. В условиях сложной распределенной инфраструктуры выявление взаимосвязей между компонентами превращается в детективное расследование.
- Реактивный подход вместо проактивного. Традиционный мониторинг сообщает о неполадках, когда они уже произошли. Предсказать деградацию сервиса или потенциальный сбой на основе паттернов данных он не способен.
- Человеческий фактор и дефицит кадров. Согласно исследованиям, в России не хватает миллиона IT-специалистов, а в США вакансии заполняются выпускниками с соответствующей квалификацией менее чем на 30%. При этом рутинные операции отнимают колоссальное количество времени специалистов, которое могло бы быть направлено на стратегические задачи.
Традиционный мониторинг vs AIOps:
| Аспект | Традиционный мониторинг | AIOps |
| Обработка данных | Анализ отдельных метрик и логов | Корреляция всех источников данных |
| Обнаружение проблем | Статические пороговые значения | Динамическое выявление аномалий на основе ML |
| Алерты | Множество дублирующих оповещений | Интеллектуальная фильтрация и группировка |
| Анализ причин | Ручное исследование | Автоматический анализ первопричин (RCA) |
| Реагирование | Реактивное, постфактум | Проактивное, с предсказанием инцидентов |
| Автоматизация | Ограниченная, скриптовая | Полная, с самообучением |
Возникает резонный вопрос: как IT-команды могут эффективно управлять инфраструктурой, которая постоянно усложняется, при ограниченных ресурсах и нехватке специалистов? Именно здесь на помощь приходит рассматриваемая технология, которая применяет искусственный интеллект и машинное обучение для автоматизации и оптимизации IT-операций, превращая хаос данных в структурированную, действенную информацию.
Как работает AIOps — архитектура и жизненный цикл
Для понимания того, как эта методология решает задачи управления IT-инфраструктурой, важно разобраться в его архитектуре и жизненном цикле обработки данных. В отличие от традиционных средств мониторинга, которые работают изолированно в своих «силосах», AIOps представляет собой многоуровневую платформу, где каждый этап обработки данных добавляет новый уровень интеллекта. Давайте рассмотрим, как данные проходят через платформу — от первичного сбора до автоматического исправления проблем.
Слой данных (Data Layer / Observation)
Всё начинается со сбора данных — фундамента, на котором строится вся интеллектуальная аналитика. Платформы AIOps агрегируют информацию из множества разнородных источников: журналы событий (logs), метрики производительности (CPU, память, сеть), данные трассировки микросервисов, события изменений конфигурации, пользовательские обращения и тикеты.
Критическое отличие от традиционных инструментов заключается в способности разрушать барьеры между системами. Сетевые инструменты отслеживают сеть, инструменты для приложений — приложения; данный подход же собирает информацию со всех уровней одновременно. Современные платформы интегрируются с облачными провайдерами (AWS, Azure, Google Cloud), решениями контейнерной оркестрации (Kubernetes), инструментами мониторинга (Prometheus, Grafana, Datadog) и создают единый поток телеметрии в реальном времени.
Дашборды мониторинга с метриками CPU, памяти, сети, контейнеров. Скриншот показывает, как выглядят реальные источники телеметрии: метрики, графики, состояние контейнеров.
Важно понимать, что «сырые» данные часто бывают хаотичными и неполными. На этом этапе происходит нормализация информации — приведение данных из различных источников к единому формату, что позволяет применять к ним универсальные алгоритмы анализа на следующих этапах.
Выделение сигналов из шума (Signal Discovery)
Представьте, что вы пытаетесь услышать важный разговор на переполненном стадионе. Именно такую задачу решает этап фильтрации — выделение действительно значимых событий из океана информационного шума. Здесь алгоритмы машинного обучения анализируют входящий поток данных и определяют, какие события заслуживают внимания, а какие являются фоновым шумом.
Решение применяет техники подавления дублирующихся алертов и корреляции связанных событий. Если один сбойный компонент вызывает каскад оповещений от зависимых механизмов, платформа распознает паттерн и группирует все связанные события в единый инцидент. Это радикально снижает количество алертов — вместо 500 оповещений IT-команда получает одно консолидированное уведомление с полным контекстом.
Экран с большим количеством алертов / инцидентов в системе управления инцидентами. Иллюстрирует «шум» традиционного мониторинга: десятки и сотни алертов. Источник: atlassian
Более того, решение учится различать «нормальный шум» от аномальных паттернов. Например, еженедельный бэкап может создавать временный всплеск нагрузки на диски — платформа распознает это как ожидаемое поведение и не создает алерт, тогда как внезапный аналогичный всплеск в нетипичное время будет расценен как потенциальная проблема.
Аналитика и ML-модели
На этом этапе происходит настоящая магия искусственного интеллекта. ML-модели анализируют отфильтрованные данные, выявляя паттерны и аномалии, которые невозможно обнаружить вручную. Платформы применяют различные типы детекторов аномалий: анализ временных рядов для метрик, обнаружение аномальной плотности событий, выявление нетипичных последовательностей действий.
Ключевое преимущество машинного обучения — способность адаптироваться к изменяющимся условиям. Решение устанавливает базовую линию нормального поведения для каждого компонента инфраструктуры, учитывая сезонность, циклы нагрузки и естественные колебания. Когда метрики отклоняются от ожидаемых значений, это фиксируется как потенциальная неполадка.
Но технология идет дальше простого обнаружения — она начинает предсказывать будущие инциденты. Анализируя тренды деградации производительности, заполнения дискового пространства или роста числа ошибок, платформа может предупредить о приближающейся проблеме за часы или даже дни до ее возникновения. Такой проактивный подход позволяет предотвращать инциденты, а не реагировать на них постфактум.
Contextualization и RCA (анализ первопричин)
Обнаружить неполадку — это лишь половина дела. Гораздо важнее понять, что именно пошло не так и почему. Здесь в игру вступает контекстуализация и анализ первопричин (Root Cause Analysis, RCA).
Платформы AIOps строят граф зависимостей между компонентами инфраструктуры — своеобразную карту причинно-следственных связей. Когда возникает инцидент, решение анализирует этот граф, чтобы определить, какой именно компонент является источником проблемы, а какие страдают от каскадного эффекта. Например, если база данных испытывает высокую нагрузку, это может проявляться как замедление работы веб-приложения, увеличение времени ответа API и рост количества таймаутов. Традиционный мониторинг зафиксирует все эти симптомы как отдельные неполадки, тогда как AIOps проследит связи и укажет на базу данных как на корневую причину.
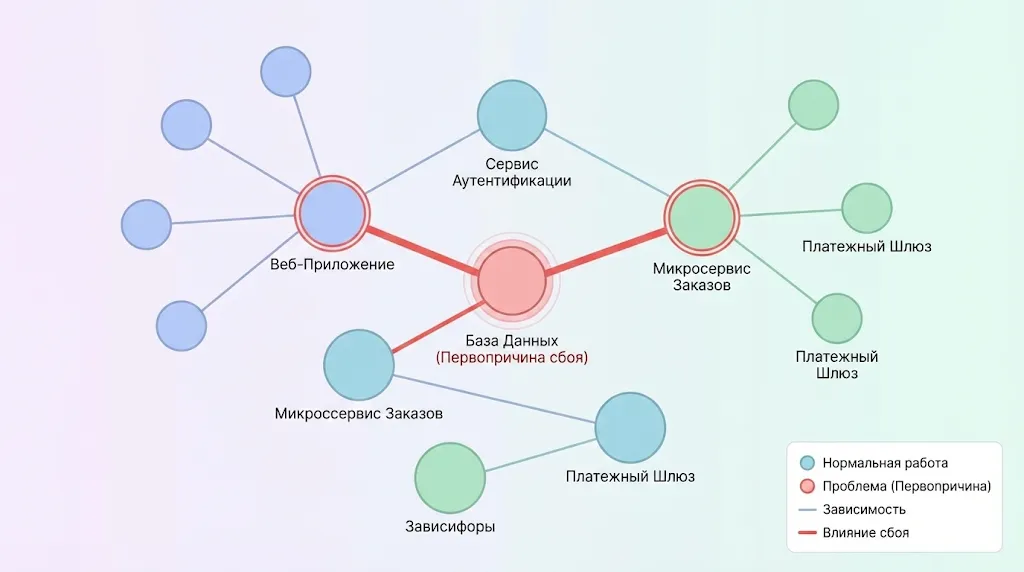
Платформа AIOps автоматически строит граф зависимостей, что позволяет быстро выявить корневую причину сбоя (например, в базе данных) и определить все затронутые ею сервисы
Платформа обогащает инциденты дополнительным контекстом: историей предыдущих похожих проблем, информацией о недавних изменениях конфигурации, данными о затронутых бизнес-сервисах. Это позволяет IT-командам мгновенно понимать масштаб и критичность неполадки, а также получать подсказки о возможных путях решения.
Auto-Remediation — автоматическое исправление
Завершающий этап жизненного цикла — автоматическое устранение проблем. Технология выявляет первопричины и на основе накопленных знаний устраняет неисправность.
Это может быть перезапуск зависшего сервиса, масштабирование ресурсов при росте нагрузки, переключение трафика на резервные инстансы или выполнение заранее определенных скриптов (runbooks). Современные платформы поддерживают интеграцию с механизмами оркестрации и автоматизации, что позволяет не только диагностировать ошибку, но и мгновенно применять исправления без участия человека.
Важно отметить, что автоматизация происходит с учетом оценки рисков. Критические действия могут требовать подтверждения человека, тогда как рутинные операции выполняются автономно. Решение постоянно обучается на результатах своих действий, совершенствуя стратегии реагирования.
Визуализация жизненного цикла:
Сбор данных → Фильтрация шума → ML-анализ → Определение первопричины → Автоисправление ↓ ↓ ↓ ↓ ↓ Интеграции Корреляция Аномалии Граф связей Runbooks Логи/метрики Группировка Предсказание Контекст Оркестрация
Таким образом, технология превращает хаотичный поток операционных данных в организованный, самоуправляемый процесс, где каждый этап добавляет уровень интеллекта и приближает платформу к автономности управления IT-инфраструктурой.
Ключевые функции и возможности AIOps-платформ
Понимание архитектуры дает нам общую картину, но что конкретно получает бизнес от внедрения таких решений? Давайте детально рассмотрим ключевые функции, которые отличают современные продукты от традиционных инструментов мониторинга и делают их незаменимыми для управления сложными IT-средами.
Интеллектуальный мониторинг и обнаружение аномалий
В отличие от статических пороговых значений, которые использует традиционный мониторинг, данная методология применяет динамические, самообучающиеся модели. Решение анализирует исторические данные, выявляет паттерны нормального поведения для каждого компонента инфраструктуры и автоматически адаптируется к изменениям. Если производительность приложения обычно падает в пятницу вечером из-за еженедельного обслуживания, платформа учтет это и не будет генерировать ложные тревоги. Однако аналогичное падение в понедельник утро будет немедленно зафиксировано как аномалия.
Современные детекторы аномалий работают с различными типами данных: временными рядами метрик, плотностью событий, последовательностями действий. Это позволяет выявлять как явные неполадки (резкий скачок ошибок), так и скрытые деградации (постепенное замедление отклика сервиса).
Умная фильтрация и подавление шума
Одна из наиболее ценных возможностей — радикальное сокращение информационного шума. Платформы применяют алгоритмы корреляции событий, которые автоматически группируют связанные алерты в единый инцидент. Вместо того чтобы получать сотни дублирующих оповещений от зависимых компонентов, IT-команда видит один консолидированный инцидент с полным контекстом проблемы.
Более того, решение различает повторяющиеся «известные» события от действительно новых неполадок. Если определенный тип алерта регулярно возникает и автоматически устраняется, платформа может подавить его или понизить приоритет, фокусируя внимание специалистов на критических и нестандартных ситуациях.
Анализ первопричин (RCA)
Возможно, самая трудоемкая задача в управлении инцидентами — поиск корневой причины проблемы. Методология автоматизирует этот процесс, используя граф зависимостей между компонентами инфраструктуры и алгоритмы машинного обучения для установления причинно-следственных связей.
Решение анализирует временную последовательность событий, топологию сервисов и исторические данные о предыдущих инцидентах. В результате вместо того чтобы тратить часы на ручное расследование, инженеры получают готовую карту первопричин с указанием на конкретный компонент, вызвавший неполадку. Например, платформа может определить, что замедление работы приложения вызвано не самим приложением, а исчерпанием пула подключений к базе данных, которое в свою очередь связано с аномально долгими запросами от конкретного микросервиса.
Предсказание инцидентов
Проактивность — то, что радикально отличает данный подход от реактивных механизмов мониторинга. Анализируя тренды и паттерны, платформа может предсказывать будущие проблемы задолго до их возникновения. Она фиксирует постепенное заполнение дискового пространства, деградацию производительности, рост числа медленных запросов или увеличение частоты ошибок — все те «слабые сигналы», которые предвещают грядущий инцидент.
Такое раннее предупреждение дает IT-командам возможность предотвратить неполадку, а не тушить пожар после того, как сервис уже недоступен для пользователей. Предиктивная аналитика оценивает вероятность развития инцидента и его потенциальное влияние на критические бизнес-сервисы, что позволяет расставлять правильные приоритеты в работе.
Проактивная автоматизация и авто-ремедиация
Технология не просто информирует о проблемах — она способна самостоятельно их устранять. На основе заранее определенных runbook’ов, скриптов и интеграций с механизмами оркестрации платформа выполняет корректирующие действия: перезапускает сервисы, масштабирует ресурсы, переключает трафик на здоровые инстансы, откатывает проблемные изменения.
Важно, что автоматизация происходит интеллектуально, с учетом контекста и оценкой рисков. Решение может автономно устранять типовые неполадки, а критические действия эскалировать человеку с предоставлением всей необходимой информации для принятия решения. Каждое автоматическое действие фиксируется, а его результаты анализируются для дальнейшего совершенствования стратегий реагирования.
Дашборды и визуализация зависимостей
Современные платформы предоставляют мощные инструменты визуализации, которые превращают сложные данные в понятные графические представления. Интерактивные дашборды показывают состояние всей инфраструктуры в едином окне, карты зависимостей визуализируют связи между компонентами, а временные графики демонстрируют корреляции между событиями.
Эти возможности observability позволяют не только оперативно реагировать на текущие проблемы, но и проводить ретроспективный анализ инцидентов, выявлять узкие места в архитектуре и принимать обоснованные решения об оптимизации инфраструктуры. Визуализация делает сложные системные взаимодействия прозрачными даже для новых сотрудников команды, что значительно ускоряет адаптацию и снижает зависимость от экспертных знаний отдельных специалистов.
Преимущества AIOps для бизнеса и IT-команд
Теория и архитектура — это, безусловно, важно, но давайте поговорим о том, что действительно волнует руководителей и специалистов: какую конкретную пользу приносит эта технология и как это отражается на ключевых показателях эффективности? Рассмотрим основные преимущества, которые получают организации при внедрении.
Снижение MTTR и ускорение обнаружения инцидентов
Наиболее прямое и измеримое влияние — это радикальное сокращение среднего времени восстановления (Mean Time To Resolution, MTTR). В традиционном процессе инженеры тратят до 80% времени на поиск проблемы и лишь 20% — на ее устранение. Данный подход полностью меняет это соотношение.
Автоматизация этапов обнаружения и анализа первопричин позволяет IT-командам избегать утомительной работы по расследованию и сразу переходить к решению неполадки. Платформа предоставляет готовый ответ, а не просто оповещение. Это означает, что мелкие технические неполадки устраняются за считанные минуты, а не перерастают в длительные простои продолжительностью несколько часов. По некоторым оценкам экспертов, затраты на критические сбои могут достигать $5600 долларов в минуту — предотвращая такие сбои, решение напрямую защищает потоки доходов.
Стабильность сервисов и повышение SLA
В 2025 году пользователи абсолютно нетерпимы к простоям. Если приложение работает медленно или не отвечает, они просто переходят к конкуренту. Время безотказной работы — это уже не единственный важный показатель; производительность имеет не меньшее значение.
Технология помогает поддерживать бесперебойную работу, прогнозируя замедления еще до того, как пользователи их заметят. Заблаговременно выявляя задержки на бэкенде или узкие места в базе данных, платформа позволяет командам устранять проблемы в фоновом режиме. В результате фронтенд остается быстрым и надежным, защищая репутацию бренда и поддерживая высокий уровень удовлетворенности клиентов. Для компаний, работающих с жесткими SLA, это превращается в конкурентное преимущество — способность гарантировать стабильность даже в условиях растущей сложности инфраструктуры.
Оптимизация затрат и ресурсов
Экономия выходит за рамки простоя. Данный подход отлично справляется с оптимизацией ресурсов. Решение может выявлять «зомби-серверы» — неиспользуемые тома хранения или избыточно выделенные облачные ресурсы, которые приводят к ежемесячным потерям средств. Платформа обнаруживает эти неэффективности, позволяя IT-руководителям вернуть бюджет, который в настоящее время тратится на ненужную инфраструктуру.
Более того, предиктивные возможности позволяют планировать масштабирование ресурсов заранее, избегая как избыточных мощностей, так и дефицита производительности в моменты пиковой нагрузки. Вместо того чтобы содержать постоянный избыток «на всякий случай», организации могут динамически управлять ресурсами на основе реальных потребностей и прогнозов.
Снижение нагрузки на сотрудников
Разрыв между потребностью в кадрах и их наличием давно и широко известен. Дефицит квалифицированных IT-специалистов — это глобальная проблема, и она только усугубляется. При этом основные мотиваторы для трудоустройства — зарплата и рабочий график, но многие специалисты мечтают заниматься чем-то более интересным, чем рутинные процессы.
Технология освобождает инженеров от множества ручных операций и повторяющихся задач. Более высокий уровень автоматизации позволяет сосредоточить усилия команды на стратегических инициативах — разработке новых сервисов, внедрении инноваций, улучшении архитектуры. Это не только повышает эффективность, но и улучшает моральный дух команды. Фреймворки уже содержат процессы автоматизации workflow, например, управление сервисными тикетами и уязвимостями, что дополнительно снижает когнитивную нагрузку на специалистов.
Кроме того, наличие единого интерфейса управления всеми процессами значительно ускоряет адаптацию новых сотрудников. Вместо постепенного освоения сложного и запутанного IT-окружения новички могут быстро войти в курс дела, независимо от уровня их начальной подготовки.
Улучшение качества сервиса и опыта клиентов
В конечном счете, все технические улучшения должны транслироваться в бизнес-ценность. Данная методология напрямую влияет на пользовательский опыт, обеспечивая стабильную, быструю и надежную работу приложений и сервисов. Когда платформа предотвращает инциденты до их возникновения, пользователи даже не подозревают о потенциальных проблемах — а это и есть идеальный сервис.
Для сервис-провайдеров и MSP компаний технология создает особые возможности: снижение затрат, увеличение качества доставки сервисов, рост киберзащищенности. Все это можно либо обратить в дополнительную прибыль, либо использовать для снижения стоимости сервисов, что в любом случае создает конкурентное преимущество. При этом возможность предложить клиентам решение как дополнительную услугу открывает новые источники дохода.
Практические сценарии применения AIOps
Теория становится особенно убедительной, когда мы видим, как она работает на практике. Давайте рассмотрим конкретные сценарии применения в различных областях IT-операций, чтобы понять, какие именно задачи решает эта технология для разных команд и бизнес-подразделений.
Для IT-операций
IT-операционные команды — это первая линия обороны в борьбе за стабильность инфраструктуры. Их ежедневная реальность — это поток инцидентов, алертов и запросов на обслуживание. Рассматриваемая технология трансформирует этот хаос в упорядоченный процесс.
Управление инцидентами становится проактивным, а не реактивным. Вместо того чтобы ждать жалоб пользователей или критических алертов, решение заранее предупреждает о потенциальных проблемах. Интеллектуальное шумоподавление избавляет операторов от необходимости просеивать сотни дублирующих оповещений — они видят только консолидированные инциденты с четким контекстом. Автоматический анализ первопричин (RCA) устраняет необходимость в многочасовых расследованиях, позволяя сразу переходить к устранению проблемы.
Особенно ценной оказывается способность отслеживать зависимости между компонентами. Когда возникает неполадка в базе данных, платформа сразу показывает, какие приложения и сервисы пострадают, позволяя оценить бизнес-влияние и правильно расставить приоритеты.
Для DevOps-команд
DevOps-практики построены на принципе непрерывной доставки, но каждый релиз несет потенциальный риск деградации сервиса. Данная методология служит своеобразной страховкой, обеспечивая стабильность в условиях постоянных изменений.
Платформа отслеживает влияние каждого развертывания на производительность и доступность сервисов. Если новая версия приложения вызывает рост числа ошибок, увеличение времени отклика или аномальное потребление ресурсов, решение немедленно это фиксирует. Это позволяет DevOps-командам либо быстро откатить изменения, либо применить hotfix до того, как проблема повлияет на значительную часть пользователей.
Более того, технология помогает в оптимизации CI/CD-пайплайнов, выявляя узкие места и неэффективные этапы сборки и тестирования. Анализ исторических данных позволяет предсказать, какие изменения в коде с высокой вероятностью приведут к проблемам в продакшене, основываясь на паттернах прошлых инцидентов.
Для безопасности (SecOps)
Киберзащита — это область, где способности к обнаружению аномалий проявляются особенно ярко. Злоумышленники становятся все изощреннее, а традиционные механизмы безопасности, основанные на сигнатурах известных угроз, часто оказываются бессильны против новых атак.
Платформа классифицирует данные и ресурсы, позволяя применять политики безопасности согласно уровню критичности. Она устанавливает базовую линию нормальной активности пользователей и механизмов, что дает возможность обнаруживать вредоносную активность по косвенным признакам — аномальные паттерны доступа, необычное время входа в устройство, нетипичные объемы передаваемых данных.
Критически важна способность работать с угрозами в контексте. Подозрительные сигналы сопоставляются с данными из внешних сервисов threat intelligence и собственной базы знаний компании. Это позволяет обнаружить угрозы, которые создают реальные риски, и сосредоточить усилия команды безопасности на отработке наиболее критичных уязвимостей, избегая перегрузки ложными срабатываниями.
Автоматизированные процессы уведомляют правильных сотрудников о подозрении на угрозы, предоставляя полный контекст — серьезность инцидента, затронутые сегменты инфраструктуры, зависимые элементы и даже рекомендации по действиям. Решение продолжает контролировать работу с каждым инцидентом до полного устранения последствий.
Для бизнеса
На уровне бизнеса преимущества выражаются в конкретных метриках, понятных руководителям. Снижение времени простоя напрямую влияет на выручку — по оценкам экспертов, каждая минута недоступности критических элементов может стоить тысячи долларов. Предотвращая инциденты или минимизируя их влияние, технология защищает финансовые показатели.
Рост удовлетворенности пользователей — еще один критический фактор. В эпоху, когда потребители мгновенно переключаются на конкурентов при малейших проблемах с сервисом, стабильность и производительность становятся конкурентным преимуществом. Методология обеспечивает тот уровень надежности, который современные пользователи воспринимают как данность, но который невероятно трудно поддерживать в условиях растущей технологической сложности.
Сценарии применения AIOps:
| Сценарий | Что делает платформа | Результат |
| Управление инцидентами (IT Ops) | Корреляция событий, подавление шума, автоматический RCA | Снижение MTTR на 60-80%, уменьшение числа алертов на 90% |
| Стабильность релизов (DevOps) | Мониторинг влияния изменений, раннее обнаружение деградации | Быстрые откаты проблемных версий, повышение качества релизов |
| Обнаружение угроз (SecOps) | Анализ аномалий поведения, корреляция с threat intelligence | Выявление атак по косвенным признакам, сокращение времени реагирования |
| Оптимизация ресурсов (FinOps) | Выявление неиспользуемых ресурсов, прогнозирование потребностей | Экономия до 30% облачных расходов |
| Пользовательский опыт (Business) | Предсказание проблем до их возникновения, проактивное масштабирование | Повышение NPS, снижение оттока клиентов |
AIOps vs другие подходы: DevOps, Observability, MLOps
В современной IT-индустрии существует множество подходов и методологий, каждая из которых обещает решить определенные проблемы. Рассматриваемая технология часто упоминается в одном ряду с DevOps, Observability и MLOps, что порой создает путаницу. Давайте разберемся, в чем фундаментальные различия между этими концепциями и как они соотносятся друг с другом.
AIOps vs DevOps
DevOps — это прежде всего культура и набор практик, направленных на устранение барьеров между разработкой и операциями. Его фокус — на скорости доставки изменений, автоматизации CI/CD-пайплайнов и совместной ответственности за качество продукта. DevOps отвечает на вопрос «как быстрее и эффективнее создавать и развертывать программное обеспечение».
Данная методология же решает задачу интеллектуального управления уже работающей инфраструктурой. Это не философия, а конкретная технологическая платформа, которая применяет машинное обучение для автоматизации операционных процессов. Если DevOps ускоряет доставку изменений, то эта технология обеспечивает стабильность и надежность этих изменений в продакшене.
Важно понимать, что эти подходы не конкурируют, а дополняют друг друга. DevOps-команды получают огромную пользу от решений, которые помогают отслеживать влияние релизов, выявлять проблемы производительности и автоматизировать реагирование на инциденты. По сути, данный подход делает DevOps более зрелым и устойчивым.
AIOps vs Observability
Observability (наблюдаемость) — это свойство, которое определяет, насколько хорошо мы можем понять внутреннее состояние по внешним сигналам. Она включает три столпа: логи, метрики и трассировки (traces). Observability отвечает на вопрос «что происходит в инфраструктуре и почему».
Рассматриваемая методология использует данные observability в качестве исходного материала, но идет значительно дальше простого наблюдения. Если observability предоставляет видимость, то данная технология добавляет интеллект — автоматический анализ, корреляцию событий, предсказание проблем и самостоятельное исправление. Можно сказать, что observability — это глаза, а эта платформа — мозг, который анализирует увиденное и принимает решения.
На практике платформы интегрируются с инструментами observability (Prometheus, Grafana, Jaeger), агрегируя их данные и применяя к ним машинное обучение для извлечения инсайтов, которые невозможно получить простым наблюдением.
AIOps vs MLOps
MLOps (Machine Learning Operations) — это практика управления жизненным циклом моделей машинного обучения, включая разработку, развертывание и мониторинг. MLOps фокусируется на операционализации ML-моделей как продукта.
Рассматриваемая технология использует машинное обучение как инструмент для повышения эффективности IT-операций. Разница в том, что MLOps управляет ML-моделями, тогда как данный подход управляет инфраструктурой и приложениями с помощью ML. Обе практики используют автоматизацию, но в разных областях.
Интересно, что организации, внедряющие MLOps, часто становятся пользователями этих решений — им нужно управлять сложной инфраструктурой, на которой работают их ML-пайплайны.
Сравнение подходов:
| Аспект | AIOps | DevOps | Observability | MLOps |
| Основная цель | Интеллектуальное управление IT-операциями | Ускорение доставки ПО | Понимание состояния | Управление ML-моделями |
| Фокус | Автоматизация операций через AI/ML | Культура и практики разработки | Видимость и мониторинг | Жизненный цикл ML-моделей |
| Основные технологии | ML, Big Data, автоматизация | CI/CD, IaC, контейнеры | Логи, метрики, трассировки | ML frameworks, версионирование моделей |
| Кто использует | IT Ops, SRE, NOC | Разработчики + Ops | Все технические команды | Data Scientists + ML Engineers |
| Результат | Снижение MTTR, предсказание проблем | Быстрые релизы | Прозрачность | Надежные ML-модели в продакшене |
Эволюция AIOps: Predictive → Agentic AIOps
Технологии не стоят на месте, и данная методология — не исключение. За последние годы мы наблюдаем значительную эволюцию этого подхода, которая отражает общие тренды развития искусственного интеллекта. Давайте рассмотрим, как решение трансформировалось от предсказательных механизмов к агентным платформам, способным к автономным действиям.
Predictive AIOps (первое поколение)
Первое поколение платформ фокусировалось преимущественно на аналитике и предсказании. Эти решения собирали данные, выявляли паттерны, обнаруживали аномалии и предупреждали о потенциальных проблемах. Их главная ценность заключалась в способности прогнозировать инциденты до их возникновения, что само по себе было революционным шагом вперед по сравнению с реактивным мониторингом.
Однако у предсказательного подхода был существенный недостаток: он оставался в значительной степени зависимым от человеческих действий. Решение могло сказать «произойдет проблема с базой данных через два часа», но для устранения этой проблемы требовалось участие инженера. По сути, Predictive был интеллектуальным советником, но не исполнителем.
Эти платформы использовали алгоритмы машинного обучения для анализа временных рядов, выявления трендов и расчета вероятностей будущих событий. Они значительно сокращали время на диагностику, но финальное решение и действие всегда оставались за человеком.
Agentic AIOps (современный подход)
Следующая эволюционная ступень — Agentic — представляет собой качественно иной уровень автономности. Здесь на сцену выходят AI-агенты, которые не просто анализируют и предсказывают, но и самостоятельно выполняют действия по устранению проблем.
Ключевое отличие агентного подхода — в способности принимать решения и действовать без постоянного надзора человека. AI-агенты могут оценивать ситуацию, выбирать оптимальную стратегию реагирования из набора возможных вариантов, выполнять корректирующие действия и затем верифицировать результаты. Это создает замкнутый цикл автономного управления.
Революционным катализатором этой трансформации стало появление Generative AI и больших языковых моделей (LLM). Интеграция GenAI в платформы открыла принципиально новые возможности. Теперь решение может не только выполнять заранее запрограммированные runbook’и, но и генерировать новые скрипты на основе контекста, использовать естественный язык для взаимодействия с инженерами, автоматически создавать документацию по инцидентам и даже обучаться на описаниях решений, зафиксированных в тикетах.
Представьте ситуацию: платформа обнаруживает аномальное поведение микросервиса. Вместо того чтобы просто создать алерт, Agentic анализирует контекст, определяет, что проблема связана с исчерпанием пула подключений, автоматически масштабирует ресурсы, верифицирует, что проблема решена, и генерирует отчет для команды на естественном языке, объясняя, что произошло и какие действия были предприняты.
Современные агентные платформы способны обучаться на результатах своих действий, постоянно совершенствуя стратегии реагирования. Они понимают контекст бизнеса и могут приоритизировать действия на основе влияния на критические сервисы. Это уже не просто инструмент — это интеллектуальный партнер IT-команды, берущий на себя значительную часть операционной нагрузки.
Как выбрать AIOps-платформу
Рынок решений стремительно растет, и организации сталкиваются с непростым выбором среди множества предложений. Согласно прогнозам аналитиков, компании, у которых не хватает собственных ресурсов для создания фреймворка, будут применять готовые сторонние платформы. Давайте разберемся, на что следует обращать внимание при выборе, какие метрики использовать для оценки и каких ошибок избегать.
На что смотреть в функционале
Первый и главный критерий — совместимость с вашей текущей экосистемой. Платформа должна интегрироваться с облачными провайдерами, которые вы используете (AWS, Azure, Google Cloud), механизмами мониторинга (Prometheus, Datadog, Zabbix), инструментами оркестрации (Kubernetes, Terraform) и сервисными решениями (ServiceNow, Jira). Универсальный low-code коннектор, позволяющий подключить практически любую систему, — это серьезное преимущество, так как он избавляет от зависимости только от готовых интеграций.
Критически важны возможности машинного обучения. Обратите внимание на наличие различных типов детекторов аномалий: для временных рядов, плотности событий, последовательностей действий. Решение должно поддерживать как supervised, так и unsupervised learning, чтобы обучаться не только на размеченных данных, но и самостоятельно выявлять новые паттерны.
Функциональность корреляции и RCA — еще один ключевой аспект. Платформа должна автоматически строить карты причинно-следственных связей, использовать графы зависимостей и предоставлять визуализацию инцидентов с полным контекстом. Возможность работы с неструктурированными данными через NLP позволяет извлекать ценную информацию из логов и тикетов.
Не менее важна гибкость автоматизации. Ищите платформы, которые поддерживают не только предустановленные runbook’и, но и позволяют создавать собственные сценарии реагирования через low-code конструкторы или скрипты. Интеграция с Generative AI для автоматической генерации решений — признак современной, перспективной платформы.
Какие метрики оценивать
При оценке эффективности фокусируйтесь на конкретных, измеримых показателях.
- Снижение MTTR (Mean Time To Resolution) — главная метрика операционной эффективности. Ожидаемое улучшение после внедрения — сокращение на 60-80%. Фиксируйте базовую линию до внедрения и отслеживайте динамику.
- Коэффициент шумоподавления показывает, насколько решение эффективно фильтрует алерты. Хорошая платформа должна снижать количество алертов на 85-95%, при этом не пропуская критические события. Метрика «соотношение событий к инцидентам» демонстрирует качество корреляции.
- MTTD (Mean Time To Detect) и MTTA (Mean Time To Acknowledge) отражают скорость обнаружения и реагирования. Данная методология должна сократить эти показатели в разы благодаря проактивному мониторингу и автоматическому оповещению правильных людей с полным контекстом.
- ROI (Return on Investment) рассчитывается с учетом нескольких факторов: стоимость предотвращенных простоев, экономия времени инженеров, снижение облачных расходов за счет оптимизации ресурсов. Типичный срок окупаемости для таких проектов — 6-12 месяцев.
- Показатель доступности сервисов и соответствие SLA — бизнес-метрики, которые особенно важны для руководства. Решение должно обеспечить измеримое улучшение uptime и снижение количества нарушений соглашений об уровне обслуживания.
Ошибки при внедрении
Типичные ошибки, которых следует избегать:
- Недооценка важности качества данных. Платформа работает настолько хорошо, насколько хороши данные, которые она получает. Неполные, несогласованные или низкокачественные данные приведут к ложным срабатываниям и снижению доверия к решению.
- Попытка автоматизировать всё и сразу. Начинайте с ограниченной области применения — например, с одного критического сервиса или типа инцидентов. Постепенно расширяйте охват, накапливая опыт и доверие команды.
- Игнорирование человеческого фактора. IT-команды могут сопротивляться внедрению, опасаясь потери контроля или сокращения рабочих мест. Важно вовлекать специалистов в процесс, демонстрируя, что технология освобождает их от рутины для более интересной работы.
- Отсутствие четких метрик успеха. Определите KPI до начала внедрения и регулярно отслеживайте прогресс. Без измеримых целей сложно доказать ценность проекта.
- Недостаточное обучение. ML-модели требуют времени для обучения на ваших данных. Не ожидайте идеальных результатов с первого дня — дайте решению 2-4 недели на адаптацию к вашей специфике.
Критерии выбора платформы:
| Критерий | Что оценивать | Почему важно |
| Интеграции | Поддержка вашего tech stack, универсальные коннекторы | Платформа должна работать с существующими инструментами |
| ML-возможности | Типы детекторов, обучение моделей, точность предсказаний | Определяет качество анализа и прогнозирования |
| Автоматизация | Runbooks, скрипты, low-code, GenAI | Влияет на степень автономности |
| Масштабируемость | Объемы данных, количество источников, производительность | Важно для роста инфраструктуры |
| Простота внедрения | Time-to-value, требования к настройке | Определяет скорость получения результатов |
| Поддержка | Документация, community, SLA вендора | Критично для успешной эксплуатации |
Кейсы внедрения AIOps (обзорные)
Теория обретает убедительность, когда подкрепляется реальными результатами. Давайте рассмотрим несколько обобщенных сценариев внедрения в различных индустриях, чтобы увидеть, какие конкретные улучшения получают организации и с какими вызовами они сталкиваются на пути трансформации.
Пример 1: E-commerce платформа с пиковыми нагрузками
Крупная e-commerce компания столкнулась с классической проблемой современного онлайн-бизнеса: их микросервисная архитектура из более чем 200 сервисов генерировала около 50 000 алертов ежедневно. IT-команда из 25 инженеров физически не могла обработать этот поток информации, в результате чего критические проблемы терялись в шуме, а среднее время восстановления сервиса составляло 4,5 часа. Особенно остро проблема проявлялась во время распродаж и праздничных периодов, когда трафик возрастал в 10-15 раз.
После внедрения платформы ситуация изменилась кардинально. Решение начало с агрегации данных из всех источников мониторинга, построения карты зависимостей между сервисами и обучения на исторических инцидентах. В течение первого месяца ML-модели установили базовую линию нормального поведения для каждого компонента инфраструктуры, учитывая сезонность и паттерны нагрузки.
Результаты оказались впечатляющими: количество алертов сократилось на 92% за счет интеллектуальной корреляции и подавления дубликатов. Вместо 50 000 ежедневных оповещений команда стала получать около 400 консолидированных инцидентов, каждый из которых содержал полный контекст и рекомендации по устранению. MTTR снизилось с 4,5 часов до 45 минут — десятикратное улучшение, которое напрямую отразилось на бизнес-показателях.
Особенно ценной оказалась предиктивная способность. За две недели до крупной сезонной распродажи решение предсказало, что три микросервиса платежной инфраструктуры не справятся с ожидаемой нагрузкой, основываясь на анализе трендов и проекциях трафика. Команда успела провести оптимизацию и масштабирование, что позволило избежать потенциальных потерь, которые эксперты оценили в $2,3 миллиона за период распродажи. Доступность критических сервисов выросла с 99,2% до 99,87%, что в пересчете означало сокращение времени простоя с 70 часов до 11 часов в год.
Пример 2: Телекоммуникационная компания с распределенной инфраструктурой
Крупный телеком-оператор управлял гибридной инфраструктурой, включающей legacy-системы биллинга, облачные сервисы для клиентского портала и распределенную сетевую инфраструктуру в сотнях локаций. Основная проблема заключалась не столько в количестве алертов, сколько в сложности диагностики: когда абоненты жаловались на качество связи, инженерам требовалось в среднем 6-8 часов, чтобы определить, где именно в этой сложной цепочке возникла проблема — в сетевом оборудовании, центрах обработки данных или в программных решениях.
Внедрение началось с построения топологической модели всей инфраструктуры и установления зависимостей между компонентами. Платформа интегрировалась с инструментами мониторинга сети, облачными сервисами, механизмами биллинга и CRM, создавая единое представление о состоянии всех элементов. Особое внимание уделялось корреляции технических метрик с жалобами пользователей.
Трансформация произошла через четыре месяца после запуска. Решение научилось автоматически выявлять первопричины проблем, используя граф зависимостей и анализ временных последовательностей событий. Когда в одном из региональных датацентров начинались проблемы с сетевым оборудованием, платформа не только фиксировала локальные симптомы, но и мгновенно показывала, какие клиентские сервисы будут затронуты, сколько абонентов пострадает и какова критичность для бизнеса.
Наиболее впечатляющим достижением стало сокращение времени диагностики с 6-8 часов до 15-20 минут. Решение автоматически генерировало отчеты о первопричинах с рекомендациями по устранению, что позволило даже менее опытным инженерам быстро решать сложные проблемы. Автоматизация рутинных операций — таких как перезапуск сервисов, переключение трафика на резервные каналы, масштабирование ресурсов — освободила около 40% времени команды NOC для работы над стратегическими проектами модернизации. Количество эскалаций к старшим специалистам сократилось на 65%, что позволило перераспределить экспертизу более эффективно.
Заключение
Современные IT-инфраструктуры достигли уровня сложности, при котором традиционные методы управления перестали работать эффективно. Тот факт, что децентрализованная модель предоставления услуг, гибридные облачные среды и микросервисная архитектура создают беспрецедентные объемы операционных данных, уже не вызывает сомнения. Вопрос заключается в другом: как организации могут справляться с этой сложностью, имея ограниченные ресурсы и дефицит квалифицированных специалистов?
Данная методология представляет собой один из ключевых ответов на этот вызов. Это не просто очередной инструмент мониторинга, а фундаментальная смена парадигмы — переход от реактивного управления к проактивному, от ручных операций к интеллектуальной автоматизации, от хаоса алертов к структурированной методике принятия решений. Применяя машинное обучение, большие данные и, всё чаще, генеративный искусственный интеллект, платформы превращают IT-операции из узкого места в конкурентное преимущество. Подведем итоги:
- AIOps объединяет большие данные и машинное обучение для управления IT-операциями. Это позволяет автоматизировать анализ событий и повысить точность обнаружения инцидентов.
- Платформы AIOps снижают информационный шум за счёт корреляции и группировки алертов. В результате команды получают меньше уведомлений, но с большим количеством полезного контекста.
- Технология ускоряет поиск первопричин сбоев благодаря анализу зависимостей между компонентами. Это напрямую сокращает время восстановления сервисов.
- Предиктивные возможности помогают выявлять потенциальные проблемы до их влияния на пользователей. Такой подход переводит IT-операции из реактивной модели в проактивную.
- Автоматическое устранение типовых инцидентов снижает нагрузку на специалистов. Инженеры могут сосредоточиться на развитии инфраструктуры, а не на рутинных задачах.
- Для бизнеса внедрение AIOps означает более стабильные сервисы и снижение простоев. Это повышает удовлетворённость клиентов и защищает выручку компании.
Если вы только начинаете осваивать профессию девопс-инженера или хотите глубже разобраться в автоматизации IT-операций, рекомендуем обратить внимание на подборку курсов по DevOps. В них обычно есть теоретическая и практическая часть, что помогает не только понять принципы AIOps, но и научиться применять их в реальных задачах.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
100 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 марта
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
Девопс-инженер. Интенсив
|
Level UP
36 отзывов
|
Цена
78 990 ₽
|
От
26 330 ₽/мес
|
Длительность
4 месяца
|
Старт
20 февраля
|
Подробнее |
|
DevOps-инженер
|
Нетология
46 отзывов
|
Цена
96 400 ₽
178 600 ₽
с промокодом kursy-online
|
От
2 976 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 февраля
|
Подробнее |
|
Профессия DevOps-инженер
|
Skillbox
219 отзывов
|
Цена
161 751 ₽
323 502 ₽
Ещё -20% по промокоду
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
15 февраля
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
98 отзывов
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 марта
|
Подробнее |

SQL и NoSQL: различия, преимущества и выбор
Чем отличаются SQL и NoSQL? Мы разберем основные различия, преимущества и случаи использования, чтобы помочь вам выбрать лучшее решение для вашего приложения.

Аналоги Miro: 10 альтернативных сервисов с онлайн-досками
В этой статье разберёмся, какие есть достойные аналоги Miro, как выбрать лучший сервис и на что обратить внимание, чтобы не пожалеть о миграции. Простым языком — без маркетингового шума.