Автоскейлинг в Kubernetes: основы, сравнение и практика
Автоскейлинг — это механизм автоматического управления вычислительными ресурсами в зависимости от текущей нагрузки на систему. Проще говоря, когда спрос растет, система разворачивает дополнительные мощности. Когда трафик спадает — высвобождает их, оптимизируя затраты.

В экосистеме Kubernetes масштабирование работает на двух уровнях: на уровне подов (контейнеризированных приложений) и на уровне нод (физических или виртуальных машин). Это позволяет гибко реагировать как на краткосрочные всплески активности, так и на долгосрочные изменения в паттернах нагрузки.
Особенно критичным автоскейлинг становится для ресурсоемких приложений — например, ML-сервисов или систем обработки больших данных. Возьмем ChatGPT: для поддержки инфраструктуры OpenAI использует тысячи GPU-серверов, способных обслуживать от 100 до 500 миллионов активных пользователей в месяц. Без эффективного автоскейлинга подобная операция была бы экономически нецелесообразной.
В этой статье мы разберемся, как устроен автоскейлинг в Kubernetes, какие инструменты для этого предусмотрены и как применять их на практике.
- Что такое автоскейлинг в Kubernetes
- Основные типы автоскейлинга
- Сравнение способов управления масштабированием
- Автоскейлинг в реальных кейсах
- Советы по оптимизации и отладке
- Частые ошибки и как их избежать
- Заключение
- Рекомендуем посмотреть курсы по обучению DevOps
Что такое автоскейлинг в Kubernetes
Автоскейлинг в Kubernetes представляет собой процесс автоматического увеличения или уменьшения количества вычислительных ресурсов, выделенных для приложения, в ответ на изменение нагрузки. Звучит просто, но за этой простотой скрывается сложная система мониторинга, анализа метрик и принятия решений в режиме реального времени.
Давайте разберемся с базовыми принципами. В основе автоскейлинга лежит концепция реактивного управления ресурсами: система постоянно отслеживает ключевые показатели производительности — использование процессора, памяти, количество запросов в секунду или даже кастомные метрики, специфичные для вашего приложения. Когда эти показатели выходят за установленные пороговые значения, Kubernetes автоматически корректирует конфигурацию, добавляя или удаляя ресурсы.
Важно понимать, что автоскейлинг работает на нескольких уровнях архитектуры. Можно масштабировать горизонтально — увеличивая количество реплик приложения (подов), распределяя нагрузку между большим числом идентичных экземпляров. Можно масштабировать вертикально — изменяя объем ресурсов, выделенных каждому отдельному поду. А можно управлять самой инфраструктурой — добавляя или удаляя вычислительные ноды в кластере.
Зачем это нужно в современных приложениях? Ответ очевиден: непредсказуемость нагрузки стала нормой. Веб-сервисы сталкиваются с резкими всплесками трафика — будь то вирусная публикация в социальных сетях, сезонная распродажа или просто пиковые часы активности пользователей. Традиционный подход — держать инфраструктуру с запасом «на всякий случай» — экономически неэффективен. Вы либо переплачиваете за простаивающие ресурсы, либо рискуете оказаться не готовыми к неожиданному наплыву пользователей.
Возьмем реальный пример из мира машинного обучения. Инференс-сервисы, обрабатывающие запросы к нейросетям, демонстрируют крайне неравномерную нагрузку: пользователи активны днем, ночью трафик падает. Держать круглосуточно работающими десятки GPU-серверов, которые ночью загружены на 10%, — расточительство. Автоскейлинг позволяет автоматически сокращать количество активных подов в периоды низкой активности и разворачивать их снова, когда спрос возрастает.
Но автоскейлинг — это не серебряная пуля. Он требует тщательной настройки, понимания характеристик вашего приложения и правильного выбора метрик для мониторинга. Слишком агрессивное масштабирование может привести к нестабильности, слишком консервативное — к деградации производительности. Как найти баланс? Давайте разберемся с конкретными инструментами, которые предлагает Kubernetes.
Основные типы автоскейлинга
Горизонтальный автоскейлинг (HPA)
Horizontal Pod Autoscaler, или HPA, — это, пожалуй, наиболее широко используемый механизм автоскейлинга в Kubernetes. Его задача предельно конкретна: автоматически регулировать количество реплик приложения в зависимости от текущей нагрузки. Звучит просто, но именно эта простота делает HPA универсальным инструментом для большинства сценариев масштабирования.
Принцип работы HPA строится на постоянном мониторинге метрик производительности. Представьте контроллер, который каждые 30 секунд (по умолчанию) проверяет состояние ваших подов: насколько загружен процессор, сколько памяти используется, какова текущая пропускная способность. Эти данные собираются через Kubernetes Metrics API и сравниваются с целевыми значениями, которые вы задали в конфигурации. Если фактические показатели отклоняются от целевых — HPA принимает решение о масштабировании.
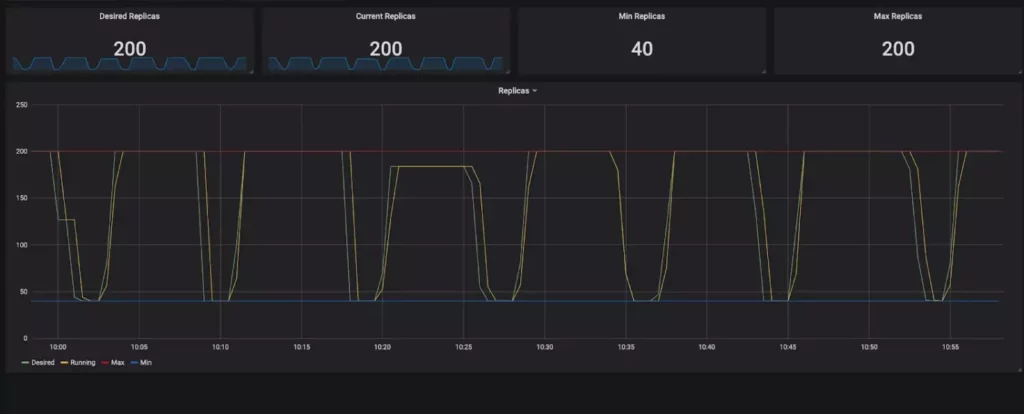
Дашборд демонстрирует реальное состояние HPA в кластере: графики метрик, реплик и событий масштабирования, помогая читателю связать YAML-конфиг с живым мониторингом и понять реакцию на нагрузку. Источник: grafana.com
Рассмотрим базовый пример. Допустим, мы установили целевое значение использования CPU на уровне 50%. Что происходит дальше? HPA вычисляет среднее использование процессора по всем репликам приложения. Если оно составляет 75% — система понимает, что подов недостаточно, и увеличивает их количество. Если использование падает до 30% — часть реплик может быть безопасно удалена. Kubernetes использует для этого специальную формулу, которая учитывает текущие и желаемые метрики, обеспечивая плавное и предсказуемое масштабирование.
Показывает реальное состояние HPA: текущие метрики, целевые значения и количество реплик. Помогает связать теорию с тем, как автоскейлинг выглядит в живом кластере.
Ключевой момент: HPA работает с контроллерами, такими как Deployment или ReplicaSet. Он не создает и не удаляет поды напрямую — вместо этого он изменяет параметр replicas в спецификации контроллера, а тот уже занимается фактическим разворачиванием или удалением подов.
Метрики для масштабирования
HPA может опираться на различные типы метрик. Стандартные метрики — CPU и память — покрывают большинство базовых сценариев. Однако для более сложных приложений этого может быть недостаточно. Представьте веб-сервис, где критичнее всего не загрузка процессора, а время отклика на запросы пользователей или длина очереди задач. Для таких случаев HPA поддерживает кастомные метрики, которые вы можете определить самостоятельно через системы мониторинга вроде Prometheus.
Работа с кастомными метриками открывает широкие возможности. Например, для ML-инференса критичной может быть метрика latency — задержка обработки запросов. Если пользователи начинают получать ответы с задержкой более секунды, это сигнал к масштабированию, даже если CPU загружен всего на 40%. Или возьмем систему обработки видео: здесь логичнее ориентироваться на количество задач в очереди, а не на утилизацию памяти.
Настройка HPA
При конфигурации HPA необходимо определить несколько ключевых параметров: минимальное и максимальное количество реплик, целевые значения метрик и период проверки. Минимальное количество реплик гарантирует базовый уровень доступности даже при нулевой нагрузке. Максимальное — защищает от неконтролируемого роста, который может исчерпать ресурсы кластера или выйти за рамки бюджета.
Рассмотрим практический пример конфигурации для приложения, использующего метрику CPU:
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: myapp-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: myapp minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50
В этом манифесте мы указываем, что HPA должен поддерживать среднее использование CPU на уровне 50%. Количество реплик будет варьироваться от 2 до 10 в зависимости от нагрузки. Если утилизация процессора превышает 50%, система добавит реплики. Если падает ниже — удалит лишние, но не менее двух, обеспечивая минимальную отказоустойчивость.
Стоит отметить: HPA превосходно справляется с нагрузкой на CPU и память, но для работы с кастомными метриками потребуется дополнительная настройка адаптеров и интеграция с системами мониторинга. Тем не менее, гибкость этого подхода оправдывает усилия, особенно когда речь идет о высоконагруженных production-системах.
Вертикальный автоскейлинг (VPA)
Если HPA отвечает на вопрос «сколько копий приложения нам нужно?», то Vertical Pod Autoscaler (VPA) задается другим вопросом: «сколько ресурсов требуется каждой отдельной копии?». Это принципиально иной подход к масштабированию, и понимание разницы критично для правильного выбора стратегии.
VPA автоматически регулирует запросы на ресурсы (requests) и лимиты (limits) для контейнеров внутри подов, основываясь на их фактическом и историческом использовании. Зачем это нужно? Дело в том, что разработчики часто либо недооценивают, либо переоценивают потребности своих приложений в ресурсах. В первом случае приложение рискует столкнуться с нехваткой памяти или процессорного времени, что приведет к деградации производительности или даже к аварийному завершению. Во втором — ресурсы резервируются избыточно, что означает неэффективное использование инфраструктуры и необоснованные расходы.
VPA решает эту проблему элегантно: он наблюдает за реальным поведением приложения и динамически корректирует выделенные ресурсы. Представьте сервис обработки изображений, нагрузка на который зависит от размера и сложности загружаемых файлов. В пиковые моменты ему может потребоваться 4 ГБ памяти, но в обычное время достаточно 1 ГБ. VPA позволяет оптимизировать использование ресурсов под текущие потребности, избегая как дефицита, так и излишков.
Архитектура и компоненты VPA
VPA состоит из трех ключевых компонентов, каждый из которых выполняет специфическую функцию:
Recommender — аналитический модуль, который собирает и анализирует данные об использовании ресурсов подами. Он изучает как текущие метрики, так и исторические паттерны потребления, и на основе этого анализа формирует рекомендации по оптимальным значениям requests и limits для контейнеров. Можно сказать, что Recommender играет роль эксперта, который постоянно следит за вашим приложением и советует, как лучше распределить ресурсы.
Updater — исполнительный компонент, отвечающий за применение рекомендаций на практике. Когда Recommender определяет, что текущие настройки ресурсов неоптимальны, Updater инициирует перезапуск подов с новыми значениями. Именно здесь кроется одна из ключевых особенностей VPA: для изменения ресурсных параметров работающего пода его необходимо пересоздать. Это принципиальное ограничение Kubernetes, которое невозможно обойти.
Admission Plugin — механизм, который перехватывает запросы на создание новых подов и автоматически применяет к ним рекомендованные значения ресурсов. Благодаря этому компоненту даже только что развернутые поды сразу получают оптимальные настройки, основанные на накопленных данных.
Когда применять VPA? Он особенно эффективен для приложений с изменяющимися требованиями к ресурсам, которые сложно предсказать на этапе разработки. Типичные сценарии включают:
- Приложения с переменной нагрузкой, где объем обрабатываемых данных значительно различается во времени
- Системы машинного обучения, где размер модели или сложность инференса могут варьироваться
- Долгоживущие сервисы, чьи требования к ресурсам эволюционируют по мере развития функциональности
Рассмотрим практическую конфигурацию:
apiVersion: autoscaling.k8s.io/v1 kind: VerticalPodAutoscaler metadata: name: myapp-vpa spec: targetRef: apiVersion: "apps/v1" kind: Deployment name: myapp updatePolicy: updateMode: "Auto" resourcePolicy: containerPolicies: - containerName: "myapp-container" minAllowed: cpu: "200m" memory: "256Mi" maxAllowed: cpu: "2" memory: "4Gi"
В этом примере VPA настроен для Deployment с именем myapp. Политика обновления установлена в режим Auto, что означает автоматическую корректировку ресурсов. Мы также определили границы: минимум 200 милликор процессора и 256 МБ памяти, максимум — 2 ядра и 4 ГБ памяти. Эти ограничения защищают от экстремальных значений, которые могут возникнуть из-за аномалий в данных.
Критическое ограничение: перезапуск подов
Необходимо четко понимать: применение новых ресурсных параметров требует перезапуска подов. Это может временно снизить доступность приложения, особенно если у вас недостаточное количество реплик или отсутствуют правильно настроенные PodDisruptionBudgets. Для минимизации влияния на production-среду можно использовать режим updateMode: «Off», при котором VPA только выдает рекомендации, но не применяет их автоматически. Это позволяет DevOps-инженерам контролировать процесс и проводить изменения в подходящее время, например, при плановом обслуживании.
Еще один важный момент: VPA и HPA не рекомендуется использовать одновременно на одних и тех же подах с метриками CPU или памяти, поскольку они могут конфликтовать друг с другом, создавая непредсказуемое поведение системы.
Масштабирование нод (Cluster Autoscaler)
Если HPA и VPA работают на уровне приложений, то Cluster Autoscaler (CA) управляет самой инфраструктурой кластера — добавляет или удаляет вычислительные ноды в зависимости от потребностей. Это следующий логический уровень автоматизации, который замыкает цепочку масштабирования.
Представьте ситуацию: HPA определил, что вашему приложению нужно больше реплик для обработки возросшей нагрузки. Kubernetes пытается запланировать новые поды, но обнаруживает, что в кластере недостаточно свободных ресурсов — все существующие ноды уже загружены. Без Cluster Autoscaler поды остались бы в состоянии Pending, ожидая появления ресурсов. С CA же система автоматически добавит новые ноды в кластер, предоставив необходимое пространство для развертывания приложений.
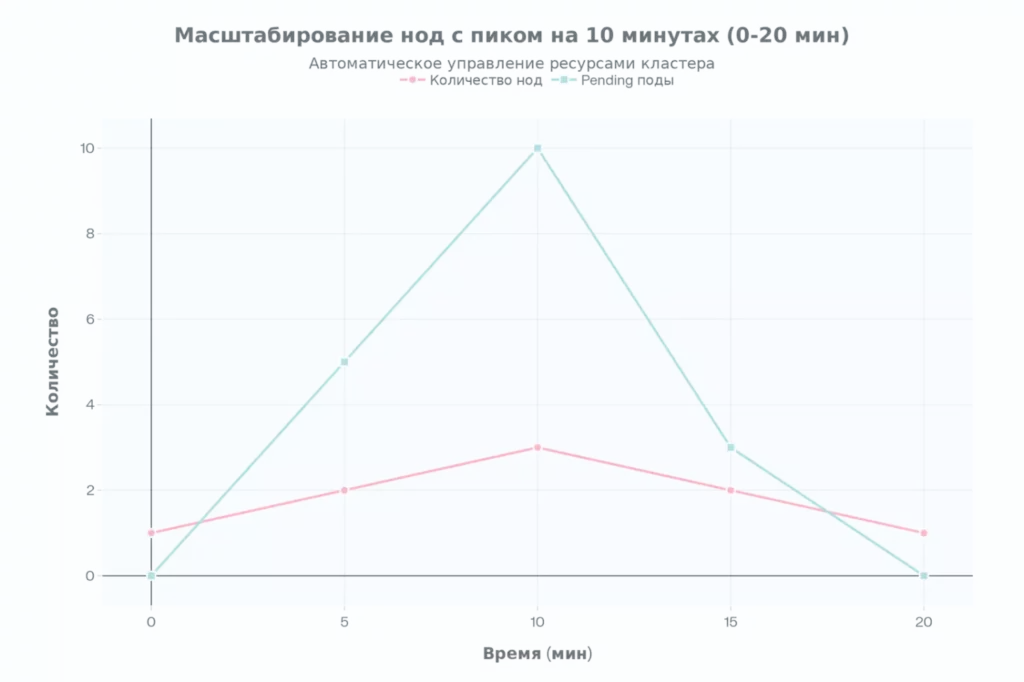
: График динамики нод и pending подов при нагрузке. Показывает scale-up/down за 20 мин. Полезно для понимания задержек CA.
Принцип работы
Cluster Autoscaler постоянно мониторит состояние подов и нод в кластере. Его логика работы основана на двух ключевых сценариях:
Добавление нод происходит, когда в кластере появляются поды в состоянии Pending из-за нехватки ресурсов. CA анализирует требования этих подов (requests для CPU, памяти и других ресурсов) и запрашивает у облачного провайдера создание новых виртуальных машин подходящей конфигурации. Время развертывания новой ноды зависит от провайдера и может занимать от нескольких до десяти минут с учетом установки необходимых системных сервисов Kubernetes.
Удаление нод осуществляется, когда ресурсы используются неэффективно. Если на ноде длительное время работают поды, которые в совокупности потребляют незначительную часть её мощности, и при этом все эти поды можно безопасно перенести на другие ноды, CA помечает такую ноду как кандидата на удаление. Система корректно эвакуирует поды на другие машины и затем удаляет освободившуюся ноду, оптимизируя расходы на инфраструктуру.
Интеграция с облачными провайдерами
Ключевая особенность Cluster Autoscaler — его тесная интеграция с облачными платформами. CA не может самостоятельно создавать физические серверы, поэтому он взаимодействует с API облачных провайдеров для управления виртуальными машинами. Поддерживаются все основные платформы: AWS, Google Cloud Platform, Microsoft Azure, а также приватные облака и on-premise решения через соответствующие адаптеры.
Для AWS, например, CA использует Auto Scaling Groups — механизм автоматического масштабирования EC2-инстансов. Необходимо предварительно настроить IAM-роли с соответствующими правами, определить типы инстансов и регионы их развертывания. В GCP работа строится на базе Instance Groups, где аналогичным образом задаются параметры машинных типов, зон доступности и проектов. Azure предлагает Virtual Machine Scale Sets для управления группами виртуальных машин.
Важный нюанс: CA работает с группами нод, а не с отдельными машинами. Вы определяете минимальное и максимальное количество нод в группе, а также характеристики этих нод (количество CPU, памяти, наличие GPU). Когда CA решает добавить ноду, он выбирает подходящую группу на основе требований pending-подов и запрашивает создание инстанса с соответствующими параметрами.
Особенности работы с GPU-ресурсами
Отдельного внимания заслуживает масштабирование для ML-нагрузок, требующих GPU. Когда новая реплика ML-сервиса запрашивает ресурс nvidia.com/gpu=1, но свободных GPU-нод в кластере нет, CA инициирует создание новой ноды из соответствующей группы. После запуска на ноде должен установиться GPU Operator, который настроит драйверы и плагины для работы с видеокартами — этот процесс может занять дополнительные 2-3 минуты.
Следует учитывать, что GPU-ноды значительно дороже обычных вычислительных машин, поэтому агрессивное масштабирование может привести к существенным расходам. Рекомендуется тщательно настраивать пороговые значения и таймауты для удаления нод, чтобы найти баланс между доступностью сервиса и стоимостью инфраструктуры.
Cluster Autoscaler замыкает экосистему автоскейлинга в Kubernetes, обеспечивая полную автоматизацию управления ресурсами — от отдельных контейнеров до инфраструктуры кластера. В связке с HPA и VPA он создает самодостаточную систему, способную адаптироваться к любым изменениям нагрузки.
Сравнение способов управления масштабированием
Разобравшись с каждым типом автоскейлинга по отдельности, логично задаться вопросом: когда какой инструмент применять? Давайте систематизируем ключевые различия между HPA, VPA и Cluster Autoscaler в виде сравнительной таблицы.
| Критерий | HPA | VPA | Cluster Autoscaler |
|---|---|---|---|
| Основное назначение | Масштабирование подов горизонтально | Регулировка ресурсов подов | Масштабирование нод в кластере |
| Тип масштабирования | Горизонтальное (добавление/удаление подов) | Вертикальное (изменение запросов ресурсов подов) | Масштабирование нод (добавление/удаление нод) |
| Метрики для принятия решений | CPU, память, кастомные метрики | CPU, память | Состояние подов и нод, используемые ресурсы |
| Периодичность проверки | 30 секунд (по умолчанию) | 10 секунд (по умолчанию) | Каждые 10 секунд |
| Примеры использования | Веб-приложения с переменной нагрузкой, обработка данных | Приложения с изменяющимися требованиями к ресурсам | Облачные кластеры с динамическими нагрузками |
| Ограничения | Конфликты с VPA, задержки в реакциях | Необходимость перезапуска подов, несовместимость с HPA | Задержки в масштабировании, зависимость от облака |
Интерпретация различий
Из таблицы видно, что каждый инструмент решает специфическую задачу, и их комбинация позволяет создать комплексную стратегию масштабирования. HPA идеально подходит для приложений, где нагрузка меняется предсказуемо и главная задача — распределить её между несколькими экземплярами. Типичный пример — веб-сервис, обрабатывающий HTTP-запросы: чем больше пользователей, тем больше реплик.
VPA, напротив, работает с приложениями, где важнее оптимизировать ресурсы каждого отдельного пода. Это особенно актуально для сервисов с непредсказуемыми паттернами потребления ресурсов или для долгоживущих процессов, требования которых эволюционируют со временем. Классический кейс — batch-обработка данных переменного объема, где одна задача может потребовать 500 МБ памяти, а другая — 3 ГБ.
Cluster Autoscaler дополняет картину, обеспечивая инфраструктурный уровень масштабирования. Без него даже самый продуманный HPA не сможет развернуть новые поды, если в кластере банально закончились свободные ресурсы. CA критичен для облачных сред, где стоимость простаивающей инфраструктуры может быть значительной.
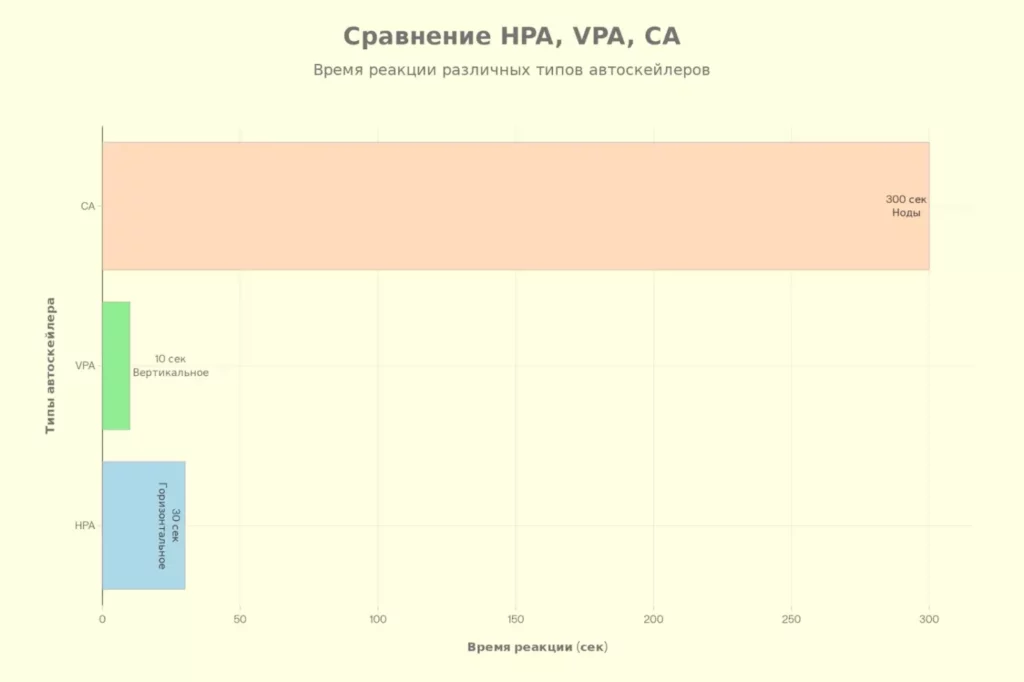
Столбцы сравнивают HPA/VPA/CA по скорости. HPA быстрый, CA медленный. Усиливает таблицу различий.
Важно понимать, что HPA и VPA не следует использовать одновременно на одних и тех же метриках (CPU, память), так как они могут принимать противоречивые решения. Однако HPA и CA прекрасно работают в тандеме: первый увеличивает количество подов, второй обеспечивает необходимые для них ресурсы на уровне нод. Аналогично, VPA и CA также совместимы, позволяя оптимизировать как индивидуальные ресурсные запросы подов, так и общую емкость кластера.
Автоскейлинг в реальных кейсах
Инференс ML-сервисов (пример ChatGPT)
Теория — это прекрасно, но давайте посмотрим, как автоскейлинг работает в реальных high-load системах. Лучше всего это демонстрирует пример ChatGPT — сервиса, который за короткое время стал одним из самых нагруженных ML-приложений в мире.
Чтобы поддерживать свою инфраструктуру, OpenAI использует порядка 3,617 серверов с GPU NVIDIA A100. Эта армада железа обслуживает от 100 до 500 миллионов активных пользователей ежемесячно. Впечатляющие цифры, не правда ли? Но что еще более впечатляет — это неравномерность нагрузки на систему.
Если взглянуть на статистику последних 90 дней работы ChatGPT, становится очевидным: даже такой IT-мастодонт не всегда справляется с входящим трафиком. Красные черты на графиках доступности сервиса наглядно демонстрируют периоды, когда система захлебывалась под наплывом запросов. И здесь мы подходим к ключевому вопросу: почему ML-нагрузка настолько критична для автоскейлинга?
Специфика ML-инференса
По своей сути, инференс почти не отличается от обычного веб-сервиса. Пользователь отправляет запрос на endpoint, модель обрабатывает его и возвращает ответ — например, в формате JSON. Казалось бы, стандартная схема. Однако дьявол кроется в деталях: вычислительная сложность обработки каждого запроса в ML-системах на порядки выше, чем в традиционных CRUD-приложениях.
Генерация текста большой языковой моделью требует выполнения триллионов математических операций. Для ускорения этих вычислений используются GPU — графические процессоры, изначально разработанные для рендеринга 3D-графики, но оказавшиеся идеальными для параллельных вычислений в нейросетях. И вот здесь начинаются интересные особенности масштабирования.
Особенности GPU-ресурсов
GPU — это дорогой и дефицитный ресурс. В отличие от обычных CPU-нод, которые можно относительно легко масштабировать в облаке, GPU-инстансы стоят в разы дороже и их доступность может быть ограничена. Более того, GPU невозможно «разделить» между подами так же легко, как CPU: если под запрашивает ресурс nvidia.com/gpu=1, ему нужна целая видеокарта (или её выделенная часть при использовании технологий вроде MIG или MPS).
Это создает уникальные вызовы для автоскейлинга. Когда HPA решает развернуть дополнительную реплику ML-сервиса, система должна найти ноду со свободным GPU. Если таких нод нет, в игру вступает Cluster Autoscaler, который запрашивает создание новой GPU-ноды у облачного провайдера. Но тут начинается ожидание: сама нода разворачивается за 3-5 минут, затем требуется время на установку GPU Operator (драйверы, плагины) — еще 2-3 минуты, и только после этого на ноду можно аллоцировать реплику.
Получается замкнутый круг: пользователи уже испытывают задержки в ответах (как те самые красные черты на графике доступности ChatGPT), но новые мощности появятся только через 5-8 минут. За это время часть пользователей может уйти, получив timeout или ошибку. Именно поэтому облачная инфраструктура хорошо подходит под такие системы — наличие свободных ресурсов позволяет быстрее реагировать на дополнительные входящие нагрузки, хотя и не мгновенно.
Паттерны нагрузки
Еще одна особенность ML-инференса — крайне неравномерное распределение нагрузки во времени. Пользователи активны в рабочие часы, ночью трафик падает. Держать круглосуточно работающими десятки GPU-серверов, загруженных ночью на 10-15%, экономически абсурдно. Автоскейлинг позволяет автоматически сокращать количество активных подов в периоды низкой активности и разворачивать их снова на рассвете, когда начинается новая волна запросов.
Однако здесь важен баланс: слишком агрессивное сокращение реплик может привести к тому, что утренний всплеск активности застанет систему врасплох. Необходимо учитывать не только текущую нагрузку, но и прогнозируемые паттерны, настраивая минимальное количество реплик и параметры масштабирования с запасом. В production-среде для ChatGPT-подобных систем это искусство тонкой настройки, основанное на анализе исторических данных и постоянном мониторинге.
Практика настройки на Kubernetes
Теория без практики — это как GPS без карты: знаешь направление, но не видишь дороги. Давайте разберемся, как на практике настроить автоскейлинг для ML-инференса в Kubernetes. В качестве примера рассмотрим развертывание inference-сервиса на базе vLLM — фреймворка для эффективного запуска больших языковых моделей.
Начальная конфигурация. Предположим, мы развернули Managed Kubernetes кластер с одной нодой, оснащенной GPU. На ноде крутится inference-сервис, к которому можно отправлять HTTP-запросы, например, для модели gpt2. Базовая архитектура выглядит следующим образом: Pod с инференсом → Inference сервис → Node с GPU → GPU Operator.
Первым делом определяем Deployment для нашего ML-сервиса:
apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference spec: replicas: 1 selector: matchLabels: app: vllm template: metadata: labels: app: vllm spec: containers: - name: vllm-container image: vllm/vllm-openai:latest resources: requests: nvidia.com/gpu: 1 cpu: "2" memory: "8Gi" limits: nvidia.com/gpu: 1 cpu: "4" memory: "16Gi" ports: - containerPort: 8000
Ключевой момент здесь — запрос ресурса nvidia.com/gpu: 1, который сообщает Kubernetes, что поду требуется целая видеокарта. Без доступной GPU-ноды под останется в состоянии Pending.
Настройка мониторинга с Prometheus. Для эффективного автоскейлинга нам нужны точные метрики. Стандартные метрики CPU и памяти не отражают реальную нагрузку на ML-сервис — гораздо важнее отслеживать задержку обработки запросов (latency). Для этого интегрируем Prometheus и настраиваем сбор кастомных метрик.
vLLM экспортирует метрику vllm_request_latency_seconds, которая показывает время обработки каждого запроса. Именно по ней мы будем масштабировать систему. Если латентность превышает секунду, пользовательский опыт деградирует, и нужно добавлять реплики.
Устанавливаем Prometheus Adapter, который преобразует метрики из Prometheus в формат, понятный HPA:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-adapter-config
data:
config.yaml: |
rules:
- seriesQuery: 'vllm_request_latency_seconds'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "^(.*)_seconds$"
as: "vllm_request_latency"
metricsQuery: 'avg(<<.Series>>{<<.LabelMatchers>>})'
Затем разворачиваем adapter с помощью Helm:
helm upgrade --install prometheus-adapter \ prometheus-community/prometheus-adapter \ -f prometheus-adapter-config.yaml
Конфигурация HPA с кастомными метриками. Теперь настраиваем HPA для масштабирования на основе латентности:
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: vllm-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: vllm-inference minReplicas: 1 maxReplicas: 5 metrics: - type: Pods pods: metric: name: vllm_request_latency target: type: AverageValue averageValue: "1000m" # 1 секунда в миллисекундах
В этой конфигурации мы указываем, что если средняя задержка запросов превышает 1 секунду, HPA должен увеличить количество реплик. Минимум — одна реплика, максимум — пять.
Настройка Cluster Autoscaler. Для автоматического добавления GPU-нод настраиваем Cluster Autoscaler. В облаке Selectel (или любом другом) это делается через спецификацию Auto Scaling Group:
apiVersion: v1 kind: ConfigMap metadata: name: cluster-autoscaler-config data: autoscaler-config: | nodes: - name: gpu-pool minSize: 1 maxSize: 5 machineType: gpu-flavor resources: nvidia.com/gpu: "1"
Принцип работы следующий: когда HPA создает новую реплику, требующую GPU, но свободных ресурсов нет, Cluster Autoscaler запрашивает новую ноду из группы gpu-pool. Облачный провайдер разворачивает виртуальную машину (3-5 минут), на ней устанавливаются драйверы через GPU Operator (2-3 минуты), и только после этого реплика может быть аллоцирована.
Проверка работы системы. После развертывания всех компонентов можно протестировать автоскейлинг, подав нагрузку на сервис. Для этого используем инструмент genai-perf от NVIDIA:
docker run --net host -it \ nvcr.io/nvidia/tritonserver:24.05-py3-sdk \ genai-perf -m gpt2 \ --service-kind openai \ --endpoint v1/completions \ --concurrency 50 \ --url :8000 \ --num-prompts 100
Этот скрипт генерирует 50 конкурентных запросов к модели gpt2. По мере роста нагрузки мы увидим в Grafana, как растет латентность, как HPA принимает решение о масштабировании, и как в итоге появляется новая нода с GPU. Весь процесс занимает 5-8 минут, но результат впечатляет: система автоматически адаптируется к нагрузке, обеспечивая стабильную производительность.
Советы по оптимизации и отладке
Развернуть автоскейлинг — это половина дела. Настроить его так, чтобы он работал стабильно и эффективно в production, — задача куда более сложная. Давайте рассмотрим ключевые аспекты, которые помогут избежать типичных проблем и оптимизировать работу системы.
- Тестирование перед production. Прежде чем выкатывать автоскейлинг в боевую среду, необходимо провести тщательное тестирование. Создайте staging-окружение, максимально приближенное к production, и смоделируйте различные сценарии нагрузки. Используйте инструменты нагрузочного тестирования вроде Apache JMeter, Locust или специализированные решения для ML-инференса, такие как genai-perf от NVIDIA. Убедитесь, что система корректно масштабируется как при плавном росте нагрузки, так и при резких всплесках.
- Настройка правильных метрик. Выбор метрик для автоскейлинга — критически важное решение. CPU и память — это базовые показатели, но они не всегда отражают реальное состояние приложения. Для веб-сервисов имеет смысл мониторить время отклика (response time) и количество запросов в секунду (RPS). Для ML-систем — латентность инференса и размер очереди запросов. Не бойтесь использовать кастомные метрики, даже если их настройка требует дополнительных усилий — окупаемость будет значительной.
- Определение оптимальных пороговых значений. Слишком низкие пороги приведут к избыточному масштабированию и неоправданным расходам. Слишком высокие — к деградации производительности и плохому пользовательскому опыту. Найти золотую середину можно только эмпирически, анализируя реальные паттерны нагрузки. Начните с консервативных значений (например, 70% для CPU) и постепенно корректируйте их на основе наблюдений.
- Настройка cooldown-периодов. Kubernetes позволяет настроить время между последовательными операциями масштабирования. Это защищает от «дрожания» системы, когда она постоянно добавляет и удаляет реплики в ответ на краткосрочные колебания нагрузки. Для scale-up обычно используются более короткие интервалы (3-5 минут), для scale-down — более длинные (10-15 минут), чтобы не торопиться с удалением ресурсов.
- Использование PodDisruptionBudgets. Чтобы VPA или Cluster Autoscaler не нарушали доступность сервиса при перезапуске подов или удалении нод, настройте PodDisruptionBudgets. Это гарантирует, что в любой момент времени работает минимально необходимое количество реплик.
- Мониторинг и алертинг. Настройте дашборды в Grafana для визуализации метрик автоскейлинга: количество реплик, использование ресурсов, латентность, события масштабирования. Создайте алерты на критические моменты — например, когда HPA достигает максимального количества реплик или когда Cluster Autoscaler не может добавить новую ноду из-за квот или недоступности ресурсов.
- Учет стоимости инфраструктуры. Автоскейлинг может привести к неожиданным расходам, особенно в облачных средах. Установите жесткие лимиты на максимальное количество нод и реплик. Регулярно анализируйте паттерны использования ресурсов — возможно, для вашей нагрузки выгоднее выбрать reserved instances или spot instances вместо on-demand.
- Документирование конфигурации. Задокументируйте логику принятия решений о масштабировании, пороговые значения метрик и причины их выбора. Это поможет новым членам команды быстрее разобраться в системе и избежать повторения ошибок при внесении изменений.
Частые ошибки и как их избежать
Даже опытные DevOps-инженеры совершают ошибки при настройке автоскейлинга. Давайте рассмотрим наиболее распространенные проблемы и способы их предотвращения.
- Отсутствие или некорректные requests и limits. Одна из самых частых ошибок — не указывать resource requests для подов или устанавливать их произвольно, «на глаз». HPA берет эти значения для расчета метрик использования ресурсов. Если requests не заданы, HPA не сможет корректно определить загрузку, что приведет к непредсказуемому поведению. Решение простое: всегда явно указывайте requests на основе реального потребления ресурсов вашим приложением.
- Конфликт HPA и VPA. Использование HPA и VPA одновременно на одних и тех же метриках (CPU, память) создает ситуацию, когда два контроллера пытаются управлять одним и тем же ресурсом. HPA увеличивает количество реплик, видя высокую загрузку CPU, а VPA в это же время уменьшает выделяемые ресурсы, считая их избыточными. Результат — хаотичное поведение системы. Если необходимо использовать оба механизма, применяйте HPA для масштабирования по CPU, а VPA настройте только на память или используйте режим «Off» для VPA, чтобы получать только рекомендации.
- Неправильный выбор метрик. Масштабирование веб-приложения по использованию памяти вместо RPS или латентности может привести к тому, что система будет добавлять реплики, когда это не нужно, или наоборот — не масштабироваться при реальной необходимости. Память часто растет постепенно из-за кэширования или утечек, что не коррелирует с актуальной нагрузкой. Выбирайте метрики, которые действительно отражают состояние вашего приложения.
- Слишком агрессивное или консервативное масштабирование. Установка слишком низких порогов для масштабирования (например, 30% CPU) приведет к избыточному количеству реплик и переплате за инфраструктуру. Слишком высокие пороги (90% CPU) означают, что приложение будет работать на пределе возможностей, рискуя упасть при малейшем всплеске нагрузки. Золотое правило — начинайте с 60-70% и корректируйте на основе мониторинга реального поведения.
- Игнорирование времени запуска приложения. Если ваше приложение инициализируется 2-3 минуты, а HPA настроен на агрессивное масштабирование с коротким периодом проверки, система может добавлять новые реплики быстрее, чем они успевают стать готовыми к обработке запросов. Это создает эффект «снежного кома»: все больше подов запускается, но ни один еще не работает. Учитывайте время старта приложения при настройке параметров масштабирования и используйте readiness probes.
- Отсутствие ограничений на максимальное количество ресурсов. Не установив maxReplicas для HPA или максимальное количество нод для Cluster Autoscaler, вы рискуете столкнуться с неконтролируемым ростом инфраструктуры. DDoS-атака или баг в коде может привести к тому, что система попытается развернуть сотни подов и нод, исчерпав бюджет за считанные часы. Всегда устанавливайте разумные верхние границы.
Заключение
Мы прошли путь от базовых принципов автоскейлинга до практических примеров настройки ML-инференса. Теперь самое время систематизировать полученные знания и подвести итоги:
- Автоскейлинг регулирует ресурсы приложений в ответ на нагрузку. Это помогает поддерживать стабильную производительность.
- HPA масштабирует поды, ориентируясь на метрики. Он обеспечивает реактивное управление числом реплик.
- VPA корректирует requests и limits. Это повышает эффективность использования ресурсов каждого пода.
- Cluster Autoscaler управляет нодами кластера. Он добавляет или удаляет виртуальные машины при необходимости.
- Кастомные метрики делают масштабирование точнее. Они учитывают специфику приложения, например задержку.
- GPU-нагрузки требуют особого подхода. Время подготовки ноды влияет на скорость реакции системы.
- Ошибки в настройке автоскейлинга приводят к перерасходу или просадкам. Чёткие пороги и мониторинг решают проблему.
- Тестирование и корректировка параметров обязательны. Это позволяет адаптировать поведение системы под реальные сценарии.
Если вы только начинаете осваивать профессию DevOps и хотите глубже разобраться в теме масштабирования, рекомендуем обратить внимание на подборку курсов по Devops. В программах есть теоретическая и практическая часть, которые помогут быстрее перейти от понимания концепций к уверенной работе на практике.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
114 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 мая
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
DevOps-инженер
|
Нетология
46 отзывов
|
Цена
101 800 ₽
226 321 ₽
с промокодом kursy-online
|
От
3 143 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 апреля
|
Подробнее |
|
Профессия DevOps-инженер
|
Skillbox
232 отзыва
|
Цена
161 751 ₽
323 502 ₽
Ещё -20% по промокоду
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
19 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
102 отзыва
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Профессия DevOps-инженер PRO
|
Skillbox
232 отзыва
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
6 месяцев
|
Старт
19 марта
|
Подробнее |

Яндекс Практикум vs Bang Bang Education: сравниваем методологию и упаковку кейсов для UX-исследователей
UX-исследования — с чего начать и какой курс выбрать? Разбираем методологию, формат обучения и портфолио, чтобы вы не ошиблись с выбором.

Яндекс Практикум vs Stepik: SQL с нуля — что быстрее даёт навык «решать задачи», а не «знать команды»
Stepik или Яндекс Практикум — где быстрее освоить SQL-аналитику и научиться решать реальные задачи? Разбираем формат обучения, типы практики и ключевые различия платформ, которые влияют на скорость роста навыка.

Яндекс Практикум vs Karpov.Courses: A/B — где понятнее, а где глубже и строже
Выбор между курсами по A/B тестированию от Яндекс Практикум и Karpov может быть непростым. Узнайте, какой из них лучше соответствует вашим целям и ожиданиям. В статье мы детально разберем их особенности, включая теоретическую и практическую части курсов, чтобы помочь вам сделать правильный выбор!

Яндекс Практикум vs GeekBrains: фронтенд — где лучше база и где быстрее выход на первые проекты
Ищете лучший курс по фронтенду, но не знаете, какой выбрать? В нашей статье вы найдете подробное сравнение программ Яндекс Практикума и GeekBrains — прочитайте и выберите подходящий курс для своего старта!