Балансировка нагрузки: что это, какие методы существуют и как работают алгоритмы распределения трафика
Балансировка нагрузки — это технология распределения входящего трафика между несколькими серверами в кластере. Если описать механику совсем просто: клиент отправляет запрос, тот попадает на специальное устройство или программу (балансировщик нагрузки), которое решает, какому именно узлу из доступного пула следует обработать это обращение. Сервер анализирует его и возвращает ответ пользователю. Казалось бы, ничего сложного — добавили промежуточное звено, и проблема решена.

Однако на практике всё несколько интереснее. Балансировка нагрузки решает целый комплекс критически важных задач, без которых современные высоконагруженные системы просто не смогли бы существовать. Во-первых, это горизонтальное масштабирование: вместо того чтобы бесконечно улучшать один узел, мы можем добавлять новые машины в кластер по мере роста нагрузки. Во-вторых, отказоустойчивость — если один из серверов выходит из строя (а это, как мы знаем, неизбежно происходит), балансировщик автоматически перенаправляет трафик на работающие хосты, обеспечивая непрерывность сервиса. В-третьих, стабильность времени отклика: правильно настроенная балансировка позволяет распределять нагрузку таким образом, чтобы ни один узел не оказывался перегруженным, пока другие простаивают.
Основные задачи балансировки нагрузки:
- Распределение трафика — равномерное или взвешенное распределение входящих обращений между доступными серверами.
- Обеспечение отказоустойчивости — автоматическое исключение неработающих узлов из пула и перенаправление трафика на здоровые хосты.
- Горизонтальное масштабирование — возможность наращивать производительность системы путём добавления новых машин, а не апгрейда существующих.
- Оптимизация производительности — минимизация времени отклика за счёт. интеллектуального выбора наименее загруженных или географически ближайших узлов.
- Резервирование серверов — создание копий, которые могут подхватить нагрузку в критической ситуации.
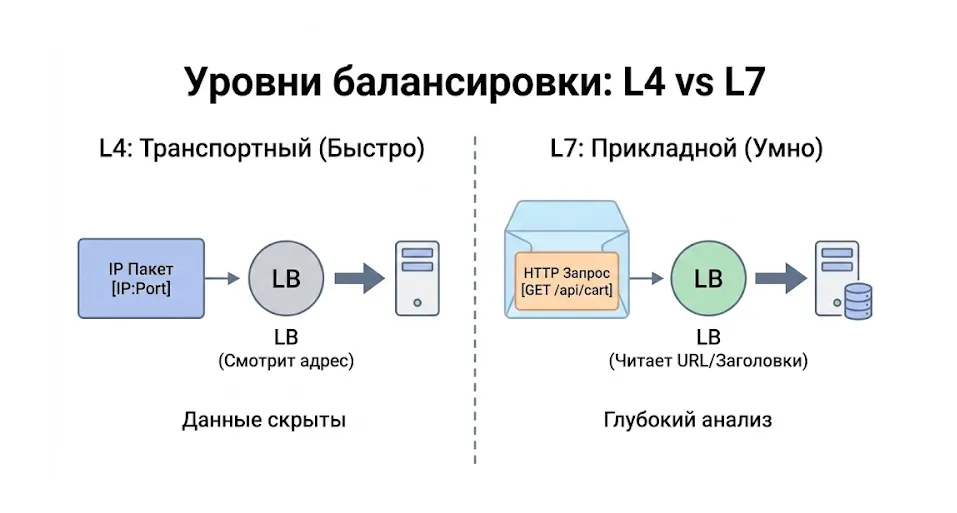
- Уровни балансировки нагрузки: сетевой, транспортный, прикладной
- Основные алгоритмы балансировки нагрузки
- Критерии выбора алгоритма балансировки нагрузки
- Практические проблемы и ограничения балансировки нагрузки
- Как выбрать подход и алгоритм: рекомендации
- Заключение
- Рекомендуем посмотреть курсы по обучению DevOps
Стоит отметить, что выбор конкретного подхода к балансировке — это всегда вопрос компромисса между сложностью реализации, эффективностью распределения нагрузки и требованиями к отказоустойчивости. Не существует универсального решения, которое подошло бы всем и всегда.
Уровни балансировки нагрузки: сетевой, транспортный, прикладной
Балансировка нагрузки — это не монолитная технология, а целый комплекс методов, работающих на различных уровнях сетевой модели OSI. Выбор конкретного уровня определяется не только техническими возможностями, но и требованиями к производительности, гибкости и степени контроля над трафиком. Давайте разберёмся, какие возможности открывает каждый из подходов и в каких ситуациях его стоит применять.
Сетевой уровень (IP, DNS, Anycast)
Балансировка на сетевом уровне — это самый «низкоуровневый» подход, работающий непосредственно с IP-адресами. Основная идея проста: сделать так, чтобы за одним публичным IP-адресом скрывалось несколько физических машин.
DNS Round Robin — один из классических методов. При обращении к доменному имени DNS-сервер возвращает несколько IP-адресов, чередуя их порядок для разных клиентов. Метод примитивен, но работает: клиенты автоматически распределяются между узлами. Проблема в том, что DNS не знает о реальном состоянии хостов — если один из них упал, DNS продолжит выдавать его адрес до тех пор, пока кто-то вручную не обновит записи.
Территориальная балансировка использует технологию Anycast DNS, позволяющую размещать идентичные сервисы с одинаковыми IP-адресами в территориально различных регионах интернета. Обращения автоматически маршрутизируются к ближайшему узлу на основе топологии сети. Этот подход активно используется в CDN и крупных распределённых системах.
NLB-кластеры (Network Load Balancing) — решение от Microsoft, объединяющее серверы в кластер с входными и вычислительными узлами. Балансировка осуществляется с помощью специального алгоритма, работающего на сетевом уровне.
Случаи применения сетевого уровня:
- Географически распределённые системы, где важна минимизация задержек.
- Простые сценарии с относительно статичной конфигурацией машин CDN и системы доставки контента.
- Ситуации, где требуется максимальная производительность без анализа содержимого обращений.
Ограничения:
- Отсутствие информации о реальной загрузке узлов.
- Невозможность анализа содержимого обращений для интеллектуальной маршрутизации Сложности с автоматическим исключением неработающих хостов.
- Ограниченная гибкость в настройке правил распределения.
Транспортный уровень
Балансировка на транспортном уровне — это наиболее простой и эффективный метод: клиент обращается к балансировщику, который перенаправляет вызов одному из серверов. Выбор узла может осуществляться в соответствии с различными алгоритмами — от простого циклического перебора до сложных адаптивных методов.
В качестве примера можно привести сетевой фильтр pf в BSD-системах, где балансировка трафика настраивается на конкретных портах и протоколах. Вот типичное правило для балансировки веб-трафика:
web_servers = "{ 10.0.0.10, 10.0.0.11, 10.0.0.13 }"
pass in on $ext_if proto tcp to port 80 rdr-to $web_servers round-robin
Транспортный уровень не анализирует содержимое пакетов глубже заголовков TCP/UDP, что делает его быстрым и эффективным. Балансировщик работает как прозрачный прокси, оперируя портами и протоколами.
Плюсы транспортного уровня:
- Высокая производительность за счёт минимальной обработки пакетов.
- Простота реализации и настройки.
- Универсальность — подходит для любых TCP/UDP-протоколов Низкие накладные расходы на обработку
Минусы:
- Невозможность маршрутизации на основе содержимого вызовов.
- Отсутствие специфичных для приложений оптимизаций.
- Ограниченная гибкость в сложных сценариях использования.
Прикладной уровень
Прикладной уровень — это самый «умный» и гибкий подход к балансировке. Здесь балансировщик работает как полноценный прокси-сервер, способный анализировать содержимое HTTP-запросов (или обращений других протоколов прикладного уровня) и принимать решения на основе этой информации.
Nginx с модулем upstream — классический пример балансировщика прикладного уровня. Он может маршрутизировать вызовы на основе URL, заголовков, cookies и других параметров HTTP-запроса. Другой пример — pgpool для PostgreSQL, который распределяет SQL-запросы между репликами базы данных, анализируя тип обращения (чтение или запись).
На прикладном уровне становятся доступны такие возможности, как sticky sessions (привязка клиента к конкретному узлу), маршрутизация на основе типа контента, SSL-терминация, кеширование и многое другое.
Когда выбирать прикладной уровень:
- Когда требуется маршрутизация на основе содержимого вызовов (URL, заголовки, cookies).
- Для реализации sticky sessions и сохранения состояния сессий пользователей.
- Когда нужны дополнительные функции: SSL-терминация, сжатие, кеширование.
- В микросервисных архитектурах, где важна гибкая маршрутизация между сервисами.
- Для логирования и детального мониторинга трафика на уровне приложения.
Возникает закономерный вопрос: если прикладной уровень настолько функционален, зачем вообще использовать более низкие уровни? Ответ прост — производительность и простота. Чем глубже балансировщик анализирует трафик, тем больше вычислительных ресурсов это требует. Для высоконагруженных систем с простыми требованиями балансировка на сетевом или транспортном уровне может оказаться более эффективным решением.
Комплексная иллюстрация архитектурных решений. Слева: на уровне L4 балансировщик оперирует только IP-адресами (закрытый пакет), тогда как на L7 он «видит» содержимое запроса (URL, куки). В центре: механизм Health Check автоматически исключает из трафика сервер со сбоем (красный крест). Справа: консистентное хеширование в виде кольца позволяет добавлять и удалять узлы с минимальным перемещением данных между серверами.
Основные алгоритмы балансировки нагрузки
Алгоритмы балансировки — это сердце всей системы распределения нагрузки. Именно от выбора алгоритма зависит, насколько эффективно будут использоваться ресурсы серверов, какой будет задержка ответов и как система справится с нестандартными ситуациями. Давайте детально разберём основные подходы — от простейших до продвинутых адаптивных решений.
Round Robin
Начнём с самого простого и распространённого метода. Round Robin (циклический перебор) отправляет каждое новое обращение следующему узлу по очереди. Первый вызов идёт на сервер A, второй на B, третий на C, четвёртый снова на A — и так по кругу.
Элегантность метода в его простоте. Представим, что у нас есть балансировщик, отправляющий узлу одно обращение в секунду. По мере обработки каждый вызов «уменьшается в размере» — условно говоря, становится менее ресурсоёмким. Для многих веб-сайтов с однотипными обращениями такая схема работает превосходно. Современные серверы способны обрабатывать множество операций параллельно, и циклическое распределение обеспечивает вполне приемлемую равномерность.
Однако у Round Robin есть фундаментальная слабость: он не учитывает реальную нагрузку на узлы. Алгоритм исходит из предположения, что все машины имеют одинаковую мощность, а все вызовы требуют одинаковых ресурсов для обработки. На практике же хосты редко бывают идентичными по производительности, а задачи могут различаться драматически — одни обрабатываются мгновенно, другие «висят» минутами.
Особенности работы Round Robin:
- Обеспечивает наилучшую медианную задержку среди простых алгоритмов.
- Демонстрирует плохие показатели на высоких перцентилях (95-й, 99-й) из-за возможных «очередей».
- Идеально работает только при одинаковой мощности узлов и «стоимости» вызовов.
- Остаётся стандартным методом балансировки HTTP-нагрузки в Nginx именно благодаря простоте и эффективности в типовых сценариях.
Weighted Round Robin
Что делать, если серверы в кластере имеют разную производительность? Допустим, у нас есть два узла: один на мощном железе способен обрабатывать вдвое больше операций, чем второй. Round Robin будет отправлять им одинаковое количество задач, что приведёт к недоиспользованию мощного хоста и перегрузке слабого.
Weighted Round Robin (взвешенный циклический перебор) решает эту проблему введением весовых коэффициентов. Разработчик вручную задаёт вес каждой машины — например, 2 для мощной и 1 для слабой. Балансировщик будет отправлять мощному узлу в два раза больше вызовов. Если у нас три машины с весами 3, 2 и 1, то из каждых шести обращений первый получит три, второй — два, третий — один.
Метод решает проблему разной производительности узлов, но требует тщательной ручной настройки и тестирования. Веса нужно подбирать, измерять производительность, корректировать — процесс итеративный и трудоёмкий. Более того, если производительность хостов меняется со временем (а она меняется — из-за деградации оборудования, обновлений ПО, изменения характера задач), веса приходится пересматривать заново.
Ключевое ограничение: Weighted Round Robin не адаптируется к изменениям производительности автоматически. Он слеп к реальной текущей загрузке узлов.
Dynamic Weighted Round Robin
Логичное развитие идеи взвешивания — автоматическое определение весов на основе реальных метрик. Dynamic Weighted Round Robin самостоятельно вычисляет весовые коэффициенты машин, используя в качестве основной метрики задержку (latency) ответов.
Принцип работы элегантен: балансировщик отслеживает, как быстро каждый узел отвечает на обращения. Если хост начинает «тормозить» — его вес снижается, и он получает меньше новых вызовов. Если отвечает быстро — его вес растёт. Система адаптируется к изменениям производительности автоматически, без вмешательства администратора.
Этот подход особенно хорош в ситуациях, где серверы имеют разную мощность и где «стоимость» операций варьируется. Алгоритм понимает, что медленные машины или перегруженные хосты не должны получать столько же трафика, сколько быстрые и свободные.
Преимущества:
- Автоматическая адаптация к изменениям производительности узлов.
- Учёт реальной задержки ответов, а не абстрактных весов.
- Не требует ручной настройки и постоянного мониторинга.
- Справляется с колебаниями нагрузки и временными деградациями.
Недостатки:
- Более сложная реализация по сравнению с простым Round Robin.
- Возможна избыточная чувствительность к кратковременным всплескам задержки.
- Требует калибровки параметров алгоритма под конкретную систему.
Least Connections
А что, если отойти от циклического перебора и начать принимать решения на основе реальной загрузки узлов? Именно эту идею реализует алгоритм Least Connections (наименьшее количество соединений).
Каждое следующее обращение передаётся машине с наименьшим количеством активных подключений в текущий момент времени. Логика проста: если на узле A сейчас обрабатывается 10 задач, а на B — 5, то новая операция отправляется на B.
Метод простой и эффективный, особенно когда вызовы имеют разную «стоимость» обработки. Представим ситуацию: большинство операций обрабатывается успешно и быстро, но некоторые «теряются» — застревают в обработке на неопределённое время. При использовании Round Robin такие «потерянные» задачи будут накапливаться в очереди случайно выбранного хоста, создавая дисбаланс нагрузки. Least Connections автоматически перестаёт отправлять новые вызовы на проблемный узел, так как видит у него большое количество активных соединений.
Least Connections доступен как опция в продвинутых балансировщиках (например, AWS ALB или Nginx Plus), так как обеспечивает более справедливое распределение нагрузки при разнородных обращениях. Метод использует все доступные ресурсы кластера эффективнее, чем простой Round Robin.
Важная особенность: Least Connections справляется с перегрузками лучше всех простых алгоритмов, но ценой более высокой задержки на 95-м и 99-м перцентилях. Это компромисс между справедливостью распределения и стабильностью отклика.
Weighted Least Connections
Усовершенствованный вариант предыдущего метода, предназначенный для кластеров с машинами разной производительности. Weighted Least Connections учитывает при распределении нагрузки не только количество активных подключений, но и весовой коэффициент узла.
Формула проста: выбирается хост с наименьшим значением (количество активных соединений / вес). Если мощный узел с весом 2 обрабатывает 10 операций, а слабый с весом 1 обрабатывает 4, то соотношение составит 10/2 = 5 для первого и 4/1 = 4 для второго — новая задача пойдёт на слабый хост, хотя на нём уже больше половины нагрузки мощного.
Этот метод особенно актуален для гетерогенных кластеров, где серверы имеют существенно различающиеся технические характеристики. Он объединяет преимущества взвешивания и учёта реальной загрузки.
Среди усовершенствованных вариантов стоит выделить Locality-Based Least Connection Scheduling — метод, созданный специально для кеширующих прокси-серверов. Его суть: наибольшее количество обращений передаётся узлам с наименьшими активными подключениями, но для каждого клиентского IP закрепляется «родной» хост. Вызовы с этого IP направляются на закреплённый узел, если тот не перегружен полностью; в противном случае задача переправляется на другой, менее загруженный хост.
Hash-алгоритмы
Совершенно иной подход к балансировке — использование хеш-функций. Вместо анализа загрузки или циклического перебора, балансировщик вычисляет хеш от определённого параметра вызова и на основе этого хеша определяет целевой узел.
Source Hash использует IP-адрес отправителя. Все обращения с одного IP всегда попадают на один и тот же хост (если, конечно, конфигурация кластера не меняется). Метод полезен для обеспечения консистентности в системах, где важно, чтобы клиент всегда обращался к одной машине.
Destination Hash работает по тому же принципу, но использует IP-адрес получателя (или другие параметры вызова). Сервер, обрабатывающий задачу, выбирается из статической таблицы соответствия.
Хеш-алгоритмы отлично подходят для маршрутизации трафика в кластерах кеширующих прокси-серверов — гарантируя, что обращения к одному и тому же ресурсу попадут на один и тот же узел, они повышают эффективность кеширования. Однако при изменении количества машин в пуле возникает проблема: хеш-функция начинает возвращать другие значения, и привязка клиент-сервер нарушается.
Sticky Sessions (привязка клиентов к серверам)
Sticky Sessions — это не столько самостоятельный алгоритм балансировки, сколько механизм, обеспечивающий привязку сессий пользователей к конкретным узлам. Зачем это нужно? Многие веб-приложения хранят состояние сессии пользователя в памяти хоста — авторизационные данные, содержимое корзины, пользовательские настройки. Если каждое обращение будет обрабатываться разными машинами, сессия постоянно «теряется», и пользователь вынужден заново авторизовываться.
Существуют два основных варианта реализации sticky sessions:
IP Hash — самый простой метод. В Nginx он реализуется директивой ip_hash в блоке upstream. Как указано в официальной документации, «метод гарантирует, что запросы одного и того же клиента будут передаваться на один и тот же сервер». Если закреплённый за конкретным адресом узел недоступен, обращение перенаправляется на другой хост.
Cookie-based — более надёжный, но и более сложный подход. Балансировщик устанавливает специальный cookie, идентифицирующий машину, которая обработала первый вызов пользователя. Все последующие операции с этим cookie направляются на тот же узел. В коммерческой версии Nginx есть модуль sticky, реализующий этот механизм; существуют и бесплатные аналоги вроде nginx-sticky-module. Такая функциональность доступна и в HAProxy.
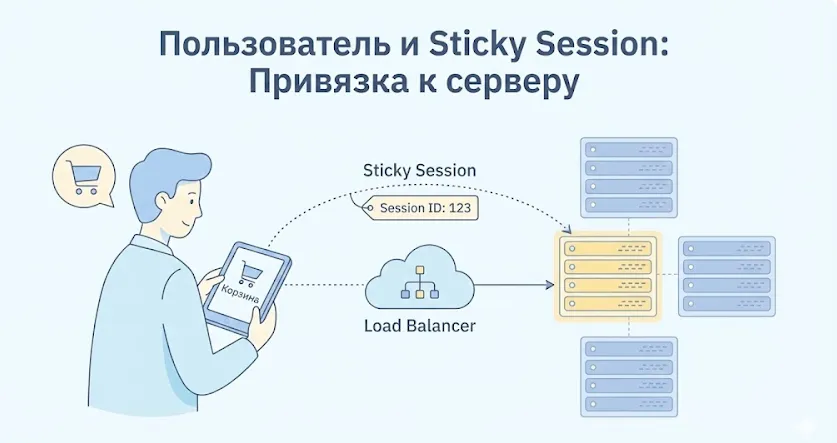
Наглядная демонстрация механизма «липких сессий». Балансировщик идентифицирует конкретного человека (User A) и направляет все его запросы строго на «красный» сервер, чтобы сохранить данные сессии. Если перенаправить пользователя на «синий» сервер, его корзина или авторизация могут потеряться.
Проблемы и риски sticky sessions:
- При использовании IP Hash возникают сложности с динамическими IP-адресами — пользователи мобильных сетей могут постоянно менять адреса.
- В ситуации, когда большое количество обращений проходит через один прокси-сервер, балансировку вряд ли можно назвать эффективной и справедливой — все эти операции пойдут на один backend-узел.
- Sticky sessions снижают гибкость системы — если нужно вывести хост из эксплуатации, приходится либо разрывать все активные сессии, либо ждать их естественного завершения.
- Усложняется масштабирование — добавление новой машины не сразу даёт эффект, так как существующие пользователи остаются привязанными к старым узлам.
PEWMA (Peak Exponentially Weighted Moving Average)
Завершим обзор алгоритмов самым продвинутым и сложным методом — PEWMA (пиковое экспоненциально взвешенное скользящее среднее). Название длинное и пугающее, но принцип вполне понятен.
PEWMA объединяет лучшие идеи из Dynamic Weighted Round Robin и Least Connections, добавляя сверху щепотку собственной «магии». Алгоритм отслеживает задержку последних N вызовов для каждого узла. Вместо того чтобы считать среднее арифметическое, он суммирует значения с экспоненциально убывающим коэффициентом: свежие операции влияют на сумму сильнее, чем старые. Полученное значение умножается на количество открытых подключений к машине. Результат используется для выбора хоста, на который следует отправить следующую задачу: меньше значение — лучше узел.
Алгоритм чувствителен к задержкам и стремится минимизировать их, при этом понимая, что остальные машины быстрее. Он не создаёт необходимости повышать задержку, работая с маломощным узлом, как это иногда случается с обычным Least Connections. PEWMA может «оставить хост недогруженным», если видит, что тот медленнее остальных.
В симуляциях PEWMA демонстрирует замечательные результаты: заметное улучшение по всем метрикам, особенно выраженное на верхних перцентилях (95-й, 99-й). Медиана также стабильно присутствует и улучшается. Однако со временем алгоритм начинает уступать Least Connections — это логично, ведь PEWMA стремится к наименьшим задержкам и иногда оставляет машину недогруженной, что при определённых условиях может привести к сбоям.
Преимущества PEWMA:
- Наилучшие показатели задержки во всех перцентилях среди рассмотренных алгоритмов.
- Адаптивность к изменениям производительности в реальном времени.
- Учёт как текущей загрузки, так и истории производительности узлов.
- Эффективная работа при разнородных обращениях и неоднородных машинах.
Ограничения PEWMA:
- Самая высокая сложность реализации и настройки среди всех методов.
- Множество настраиваемых параметров, требующих тщательной калибровки.
- При некорректной настройке может быть хуже, чем простой Least Connections.
- Более требователен к вычислительным ресурсам балансировщика.
Реализация, приведённая в оригинальных исследованиях, использует конфигурацию, хорошо показавшую себя в протестированных сценариях. Дополнительная тонкая настройка может дать результаты ещё лучше, но это уже минус PEWMA по сравнению с Least Connections — большая сложность.
Сравнение алгоритмов балансировки нагрузки
Мы рассмотрели целый спектр алгоритмов балансировки — от простейших до весьма изощрённых. Теперь пришло время свести всё воедино и понять, в каких ситуациях какой метод окажется наиболее эффективным. Выбор алгоритма всегда представляет собой компромисс между несколькими факторами: эффективностью использования ресурсов, справедливостью распределения, устойчивостью к отказам, способностью адаптироваться к изменениям и сложностью настройки.
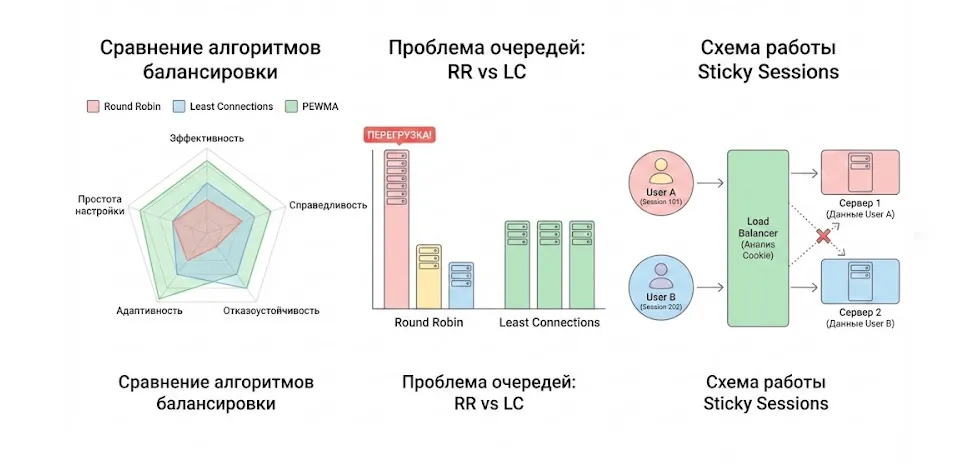
Эта иллюстрация объединяет ключевые концепции балансировки нагрузки. Слева лепестковая диаграмма демонстрирует компромисс между простотой Round Robin и высокой эффективностью (но сложностью) алгоритма PEWMA. В центре наглядно показано, как простой перебор может привести к перегрузке сервера «тяжелыми» задачами, и как Least Connections решает эту проблему. Справа изображена схема работы Sticky Sessions, где балансировщик обеспечивает «прилипание» сессии пользователя к конкретному серверу.
Для начала взглянем на сводную таблицу, обобщающую характеристики всех рассмотренных методов:
| Алгоритм | Эффективность использования | Справедливость распределения | Отказоустойчивость | Динамичность / Адаптивность | Сложность настройки |
|---|---|---|---|---|---|
| Round Robin | Средняя | Высокая (при одинаковых серверах) | Базовая | Отсутствует | Минимальная |
| Weighted Round Robin | Средняя–Высокая | Высокая (при правильных весах) | Базовая | Отсутствует | Средняя (нужен ручной подбор весов) |
| Dynamic Weighted RR | Высокая | Высокая | Средняя | Высокая (автоматическая адаптация) | Средняя |
| Least Connections | Высокая | Очень высокая | Высокая | Средняя (реагирует на текущую нагрузку) | Минимальная |
| Weighted Least Connections | Очень высокая | Очень высокая | Высокая | Средняя | Средняя |
| Source/Destination Hash | Низкая–Средняя | Низкая | Низкая (ломается при изменении пула) | Отсутствует | Минимальная |
| Sticky Sessions (IP Hash) | Низкая–Средняя | Низкая | Низкая–Средняя | Отсутствует | Минимальная |
| Sticky Sessions (Cookie) | Средняя | Средняя | Средняя | Отсутствует | Средняя–Высокая (зависит от реализации) |
| PEWMA | Очень высокая | Высокая | Средняя–Высокая | Очень высокая | Высокая (много параметров и тонкая настройка) |
Несколько наблюдений из этой таблицы помогут нам сформулировать практические рекомендации.
- Во-первых, простейший Round Robin остаётся вполне жизнеспособным решением для систем с однородными машинами и предсказуемыми обращениями. Его основное преимущество — минимальная сложность реализации и отладки. Для многих веб-приложений с относительно стабильной нагрузкой этого более чем достаточно.
- Во-вторых, Least Connections демонстрирует впечатляющий баланс между эффективностью и простотой. Не случайно этот метод стал стандартом в AWS — он автоматически справляется с разнородными вызовами без необходимости тонкой настройки. Единственная плата — несколько более высокие показатели на верхних перцентилях задержки, но для большинства приложений это приемлемый компромисс.
- В-третьих, методы, основанные на хешировании (Hash и Sticky Sessions), стоит использовать только когда это действительно необходимо для функционирования приложения. Они жертвуют эффективностью распределения нагрузки ради других целей: кеширования в случае Hash-методов или сохранения состояния сессий в случае Sticky Sessions. Если архитектура приложения позволяет, лучше отказаться от этих подходов в пользу stateless-серверов и централизованного хранения сессий.
Наконец, адаптивные алгоритмы вроде Dynamic Weighted Round Robin и особенно PEWMA показывают наилучшие результаты в сложных сценариях с гетерогенными машинами и переменной нагрузкой. Однако они требуют значительных усилий на этапе внедрения и настройки. PEWMA, например, может превзойти все остальные методы, но только при правильной калибровке параметров под конкретную систему.
Важно понимать, что выбор алгоритма — это не теоретическое упражнение, а практическая задача, требующая тестирования на реальных данных. Симуляции дают общее представление о поведении алгоритмов, но реальная нагрузка всегда преподносит сюрпризы: сетевые задержки, медленные запуски машин, реальные ограничения железа. Возникает резонный вопрос: можно ли вообще выбрать «правильный» алгоритм без полномасштабного тестирования?
Критерии выбора алгоритма балансировки нагрузки
Выбор алгоритма балансировки — это многофакторная задача, требующая анализа специфики конкретного приложения и инфраструктуры. Не существует универсального «лучшего» алгоритма, который подходил бы для всех случаев. Вместо этого нам следует рассматривать набор критериев, определяющих, насколько хорошо тот или иной метод справится с задачами вашей системы.
- Справедливость распределения — первый и наиболее очевидный критерий. Насколько равномерно алгоритм распределяет нагрузку между узлами? Идеальная справедливость означает, что каждый хост получает ровно столько операций, сколько может обработать, не больше и не меньше. Round Robin обеспечивает математически идеальное распределение — при условии, что все машины одинаковы и все вызовы требуют одинаковых ресурсов. Как только эти условия нарушаются (а они нарушаются практически всегда), справедливость страдает. Least Connections в этом плане гораздо более устойчив: он автоматически учитывает разницу в обработке задач, направляя меньше трафика на перегруженные хосты.
- Эффективность использования ресурсов тесно связана со справедливостью, но не тождественна ей. Мы можем правильно распределить нагрузку, но при этом недоиспользовать доступные мощности. Представим ситуацию: у нас есть три узла, один из которых вдвое мощнее остальных. Round Robin отправит каждому по трети вызовов, но мощный хост будет простаивать, а слабые — задыхаться. Weighted алгоритмы решают эту проблему, но требуют правильной настройки весов. Адаптивные методы вроде Dynamic Weighted Round Robin или PEWMA идут дальше, автоматически определяя, какая машина может взять больше нагрузки.
- Время отклика — критичный параметр для большинства интерактивных приложений. Здесь важно смотреть не только на среднее значение или медиану, но и на верхние перцентили — 95-й, 99-й. Именно они определяют опыт пользователей в худших случаях. Round Robin демонстрирует отличную медиану, но плохо справляется с высокими перцентилями из-за возможности накопления «тяжёлых» задач в очереди одного хоста. PEWMA, напротив, показывает наилучшие результаты именно на верхних перцентилях, активно избегая перегруженных узлов.
- Предсказуемость поведения — часто недооценённый критерий. Простые алгоритмы вроде Round Robin ведут себя предсказуемо: мы точно знаем, что каждый узел получит примерно одинаковое количество операций. Адаптивные алгоритмы сложнее в этом плане — их поведение зависит от множества факторов, и предсказать заранее, как система поведёт себя под новым типом нагрузки, непросто. Это не всегда плохо, но требует более тщательного мониторинга и понимания работы алгоритма.
- Устойчивость под нагрузкой и при отказах — способность системы продолжать работать при росте трафика или выходе из строя части машин. Least Connections автоматически исключает из ротации узлы, которые не справляются — просто перестаёт отправлять им новые задачи, видя большое количество активных соединений. Hash-методы, напротив, могут продолжать направлять обращения на упавший хост до тех пор, пока кто-то не обновит конфигурацию вручную.
- Масштабируемость — насколько легко система адаптируется к изменению количества узлов. Добавление новой машины в пул при использовании Round Robin даёт немедленный эффект. При использовании Sticky Sessions он будет отложенным — новый узел начнёт получать нагрузку только по мере появления новых пользователей. Hash-методы вообще могут потребовать полной реконфигурации при изменении пула машин.
Факторы, которые необходимо измерять при выборе алгоритма:
- Однородность узлов в кластере (идентичное или различное оборудование).
- Характер обращений (одинаковая или различная «стоимость» обработки).
- Динамика нагрузки (стабильная или с резкими всплесками).
- Требования к задержкам (важна медиана или верхние перцентили).
- Необходимость сохранения состояния сессий.
- Частота изменения конфигурации кластера.
- Доступные ресурсы для настройки и мониторинга системы.
Ключевой вывод: критерии не существуют в вакууме, они взаимосвязаны и часто конфликтуют друг с другом. Оптимизация времени отклика может снизить справедливость распределения. Повышение предсказуемости может уменьшить адаптивность. Выбор алгоритма — это всегда поиск баланса между противоречивыми требованиями.
Практические проблемы и ограничения балансировки нагрузки
Теория балансировки нагрузки выглядит убедительно: выбираем алгоритм, настраиваем параметры, запускаем систему — и она работает как швейцарские часы. На практике же реальность оказывается значительно сложнее, и многие проблемы проявляются только под настоящей нагрузкой, а не в аккуратных симуляциях.
- Начнём с фундаментальной проблемы: машины в кластере практически никогда не бывают идентичными. Даже если изначально вы закупили одинаковое оборудование, со временем производительность начинает различаться. Один узел деградирует быстрее из-за износа дисков, другой получил обновление прошивки контроллера RAID, третий физически расположен в более холодной части дата-центра и работает эффективнее. Weighted-алгоритмы должны были бы решить эту проблему, но как определить правильные веса? Тестированием? А что, если производительность меняется в зависимости от времени суток, типа нагрузки или фазы луны?
- Следующая проблема — обращения тоже не одинаковы. Веб-приложение может обрабатывать простой GET за миллисекунды, а сложный поисковый вызов с агрегацией данных — секундами. При скорости обработки в 3 операции в секунду часть вызовов неизбежно будет отбрасываться. Если новое обращение приходит на узел в момент, когда тот уже обрабатывает другое, машина его отклонит — пользователь получит ошибку. Добавление ещё одного хоста в пул решает проблему… до следующего пика нагрузки.
- Здесь возникает коварная ситуация с Round Robin: из-за различий в «стоимости» задач в работе узла происходит дисбаланс — накапливаются очереди на тех хостах, которым «не повезло» получить подряд несколько тяжёлых операций. Эти машины перегружаются, на них растут очереди, а другие при этом могут простаивать. Если наблюдать за симуляцией, обращения меняют цвет по мере обработки: чем дольше они не обрабатываются, тем темнее становятся. При использовании Round Robin картина получается неоднородной — тёмные пятна концентрируются на определённых узлах.
- Проблема с Sticky Sessions заслуживает особого внимания. Казалось бы, решение элегантное — привязываем пользователя к хосту, и вопрос закрыт. Но в реальности возникают сложности. Пользователи мобильных сетей постоянно меняют IP-адреса, что разрывает привязку. В ситуации, когда большое количество вызовов проходит через один корпоративный прокси или NAT, все эти пользователи получают один внешний IP — и все они направляются на один backend-узел, создавая чудовищный дисбаланс. Cookie-based методы решают проблему с IP, но усложняют инфраструктуру и требуют дополнительной обработки на уровне приложения.
- Динамика нагрузки — ещё один источник головной боли. Трафик редко бывает стабильным: утренние пики, обеденные спады, вечерние всплески активности. А ещё маркетинговые кампании, выход новых продуктов, вирусные посты в соцсетях. Статические алгоритмы не справляются с резкими изменениями. Адаптивные алгоритмы лучше, но и они имеют инерцию — им нужно время, чтобы «понять», что нагрузка изменилась, и скорректировать распределение.
- Отдельная проблема — невозможность полагаться исключительно на симуляции. Они игнорируют реальные ограничения: сетевые задержки, медленный запуск машин после перезагрузки, особенности работы операционной системы под высокой нагрузкой, влияние других процессов на том же железе. Симуляции полезны для демонстрации свойств каждого алгоритма, но они не могут предсказать, как система поведёт себя в production с реальными пользователями и реальными проблемами.
Именно поэтому тестирование на реальной нагрузке критически важно. Всегда стоит измерять ее на конкретном проекте, в конкретных условиях. Не воспринимайте советы из интернета как панацею — они демонстрируют лишь свойства алгоритмов в контролируемых условиях. Реальная production-среда преподнесёт сюрпризы, о которых не написано ни в одной статье.
Реальные проблемы при применении классических алгоритмов:
- Накопление медленных операций в очереди одного узла при использовании Round Robin.
- Невозможность быстро адаптироваться к отказу хоста при Hash-методах без пересчёта всех привязок.
- Колебания производительности машин из-за внешних факторов (температура, параллельные процессы, состояние сети).
- Проблемы с масштабированием при использовании Sticky Sessions — новые узлы получают мало трафика.
- Сложность определения оптимальных весов для Weighted-алгоритмов в гетерогенных кластерах.
- Избыточная чувствительность адаптивных алгоритмов к кратковременным всплескам задержки.
- Необходимость постоянного мониторинга и корректировки параметров в меняющихся условиях Увеличение сложности отладки при использовании продвинутых алгоритмов вроде PEWMA.
Возникает резонный вопрос: стоит ли вообще связываться со сложными алгоритмами, если простой Round Robin работает «достаточно хорошо»? Ответ зависит от масштаба и требований вашей системы. Для небольших проектов с предсказуемой нагрузкой простота может перевесить теоретические преимущества адаптивных методов. Для высоконагруженных систем с жёсткими SLA по задержкам — наоборот.
Как выбрать подход и алгоритм: рекомендации
После детального разбора алгоритмов и их ограничений пришло время сформулировать практические рекомендации. Как же выбрать правильный метод балансировки для конкретной системы? Простое правило: всегда начинайте с наиболее простого решения, которое справляется с задачей.
Для большинства веб-приложений с относительно однородными машинами и обращениями Round Robin остаётся разумным выбором по умолчанию. Не случайно он является стандартным методом в Nginx — простота реализации, предсказуемость поведения и отличная медиана задержки делают его оптимальным для типовых сценариев. Если ваши узлы идентичны, вызовы примерно одинаковы по «стоимости», и вас устраивают показатели на высоких перцентилях — не усложняйте систему без необходимости.
Когда же стоит переходить к более сложным методам? Least Connections становится предпочтительным, если обращения имеют сильно различающееся время обработки или если в кластере периодически возникают «тяжёлые» задачи, блокирующие хост надолго. Метод автоматически перестаёт отправлять новые вызовы на перегруженные машины, обеспечивая более справедливое распределение. Именно поэтому он стал стандартом в AWS — работает из коробки, не требует настройки, справляется с большинством реальных сценариев.
Если серверы в кластере имеют различную производительность, обратите внимание на Weighted-варианты алгоритмов. Weighted Round Robin подходит для относительно стабильных конфигураций, где соотношение мощностей узлов известно и не меняется. Dynamic Weighted Round Robin — для систем, где производительность машин может варьироваться, но вы готовы потратить время на настройку параметров автоматической адаптации.
Hash-алгоритмы имеют узкую специализацию — они нужны в кластерах кеширующих прокси или там, где критически важно, чтобы обращения от одного клиента (или к одному ресурсу) всегда обрабатывались одним узлом. Во всех остальных случаях они ухудшают балансировку и снижают отказоустойчивость системы.
Sticky Sessions следует использовать только когда это абсолютно необходимо для работы приложения — например, если сессии хранятся в памяти хоста и нет возможности быстро перенести их в централизованное хранилище. Помните, что sticky sessions усложняют масштабирование и снижают гибкость системы. Если архитектура позволяет, лучше сделать серверы stateless и хранить сессии в Redis, Memcached или аналогичных решениях.
Для высоконагруженных систем с жёсткими требованиями к задержкам на верхних перцентилях стоит рассмотреть PEWMA или другие адаптивные алгоритмы. Но будьте готовы к тому, что потребуется серьёзная работа по настройке и тестированию. PEWMA может дать значительный выигрыш в производительности, но только при правильной калибровке параметров под вашу конкретную нагрузку.
Практические рекомендации по выбору алгоритма:
- Начинайте с Round Robin для простых систем с однородными узлами и обращениями.
- Переходите на Least Connections, если видите проблемы с накоплением очередей или если вызовы сильно различаются по времени обработки.
- Используйте Weighted-варианты только для гетерогенных кластеров, где различия в производительности машин существенны и стабильны.
- Применяйте Hash-методы исключительно для кеширующих систем или специфических сценариев с требованиями к консистентности.
- Избегайте Sticky Sessions везде, где это возможно — они создают больше проблем, чем решают.
- Рассматривайте адаптивные алгоритмы вроде PEWMA только для высоконагруженных систем, где выигрыш в задержках оправдывает сложность настройки.
- И самое главное — всегда тестируйте выбранный алгоритм на реальной нагрузке перед внедрением в production, симуляции не заменят практического опыта.
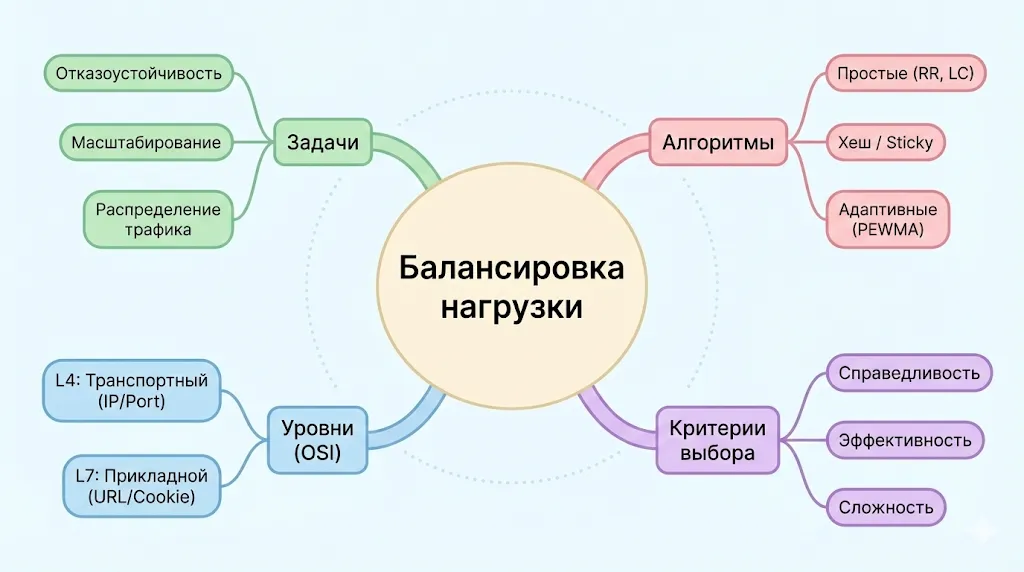
Эта схема позволяет одним взглядом охватить всю тему. От центрального понятия «Балансировка нагрузки» расходятся ветви: ключевые задачи (отказоустойчивость, масштабирование), уровни (L4 и L7), основные алгоритмы и критерии их выбора. Помогает систематизировать полученные знания.
Заключение
Балансировка нагрузки — это не просто технический трюк для распределения обращений между серверами, а фундаментальный элемент архитектуры современных высоконагруженных систем. Мы рассмотрели широкий спектр алгоритмов — от простейшего Round Robin, отправляющего вызовы по очереди каждому узлу, до сложного PEWMA, использующего экспоненциально взвешенное скользящее среднее для минимизации задержек. Подведем итоги:
- Балансировка нагрузки серверов распределяет входящий трафик между узлами кластера. Это помогает избежать перегрузок и держать стабильное время отклика.
- Балансировка решает задачи масштабирования и отказоустойчивости. При добавлении новых серверов система растёт горизонтально, а при сбоях трафик уходит на здоровые хосты.
- Уровень балансировки определяет возможности и стоимость обработки трафика. На L4 решения быстрее, а на L7 доступны маршрутизация по содержимому запросов и дополнительные функции.
- Алгоритм балансировки напрямую влияет на задержки и равномерность нагрузки. Round Robin прост, Least Connections лучше при разной «стоимости» запросов, а адаптивные методы учитывают реальную динамику.
- Sticky sessions и hash-подходы нужны для специальных сценариев. Они помогают сохранять привязку клиента или улучшать кеширование, но усложняют масштабирование и гибкость.
- Выбор подхода требует измерений и тестирования на реальной нагрузке. Симуляции полезны для понимания принципов, но production всегда добавляет сетевые задержки и нестабильность узлов.
Если вы только начинаете осваивать профессию DevOps-инженера или специалиста по серверной инфраструктуре, рекомендуем обратить внимание на подборку курсов по DevOps. Такие курсы обычно включают как теорию, так и практические задания с реальными инструментами и конфигурациями.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
114 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 мая
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
DevOps-инженер
|
Нетология
46 отзывов
|
Цена
101 800 ₽
226 321 ₽
с промокодом kursy-online
|
От
3 143 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 апреля
|
Подробнее |
|
Профессия DevOps-инженер
|
Skillbox
232 отзыва
|
Цена
161 751 ₽
323 502 ₽
Ещё -20% по промокоду
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
23 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
102 отзыва
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Профессия DevOps-инженер PRO
|
Skillbox
232 отзыва
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
6 месяцев
|
Старт
23 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.