Что такое Big Data
В эпоху цифровизации мы ежедневно сталкиваемся с понятием «большие данные», которое давно вышло за пределы технического жаргона и прочно обосновалось в лексиконе современного бизнеса. Но что в действительности скрывается за этим модным термином?

Big Data, или большие данные — это массивы информации такого объёма, скорости поступления и сложности, что традиционные инструменты обработки данных становятся неэффективными. Концепция возникла в начале 2000-х годов, когда технологические компании столкнулись с экспоненциальным ростом объёмов информации. Ключевой вклад в формализацию понятия внёс аналитик Gartner Даг Лейни, который в 2001 году предложил определять большие данные через три характеристики: Volume (объём), Velocity (скорость) и Variety (разнообразие). Важно понимать, что «большой объём» — это не фиксированная цифра, а относительное понятие, означающее количество данных, превышающее возможности традиционных систем по их обработке и анализу.
- Признаки больших данных (модель 6V)
- Какие бывают типы данных
- Как работает Big Data: от сбора до анализа
- Где применяются большие данные
- Преимущества использования
- Риски и вызовы: безопасность, приватность и этика работы с Big Data
- Какие специалисты работают с Big Data
- Как начать работать с Big Data
- Заключение
- Рекомендуем посмотреть курсы по системной аналитике
Впрочем, дело не только в размере. Ключевая особенность больших данных — их применение для принятия обоснованных решений и построения прогнозных моделей высокой точности. Они помогают бизнесу понять поведение клиентов, оптимизировать операционные процессы и создавать инновационные продукты, а научному сообществу — совершать новые открытия.
BD — это не просто большие массивы информации, а комплексный подход к сбору, хранению и анализу data с использованием специализированных инструментов, позволяющий находить неочевидные закономерности и делать точные прогнозы.
Сегодня к большим data можно отнести информацию, генерируемую социальными сетями, IoT-устройствами, транзакционными системами и множеством других источников — словом, всё, что требует специальных инструментов для хранения, обработки и анализа.
Признаки больших данных (модель 6V)
Чтобы отличить настоящие большие данные от просто «много информации», в индустрии мы используем модель 6V — шесть ключевых характеристик, без которых о BD говорить не приходится. Эта модель — своеобразная лакмусовая бумажка, позволяющая точно идентифицировать явление в мире дата.
| Характеристика | Описание | Пример |
|---|---|---|
| Volume (объём) | Информации должно поступать более 150 Гб в сутки. | Социальная сеть VK, где ежедневно загружаются терабайты контента: фото, видео, сообщения. |
| Velocity (скорость) | Данные обновляются и обрабатываются практически в реальном времени. | Сервис FlightRadar24, отображающий все маршруты самолётов онлайн с минимальной задержкой. |
| Variety (разнообразие) | Информация имеет разные форматы, степень структурированности и источники. | Контент пользователей YouTube — видео разного качества, комментарии, метаданные. |
| Veracity (достоверность) | Источники данных должны быть надёжными для принятия стратегических решений. | Данные аналитических систем NASA, на основе которых моделируются космические миссии. |
| Variability (изменчивость) | Поток data непостоянен, на него влияют внешние факторы. | Данные о пассажиропотоке такси, меняющиеся в зависимости от времени суток, погоды, праздников. |
| Value (ценность) | Информация должна обладать потенциалом для извлечения практической пользы. | Данные о трафике, которые можно использовать для оптимизации транспортных маршрутов и сокращения пробок. |
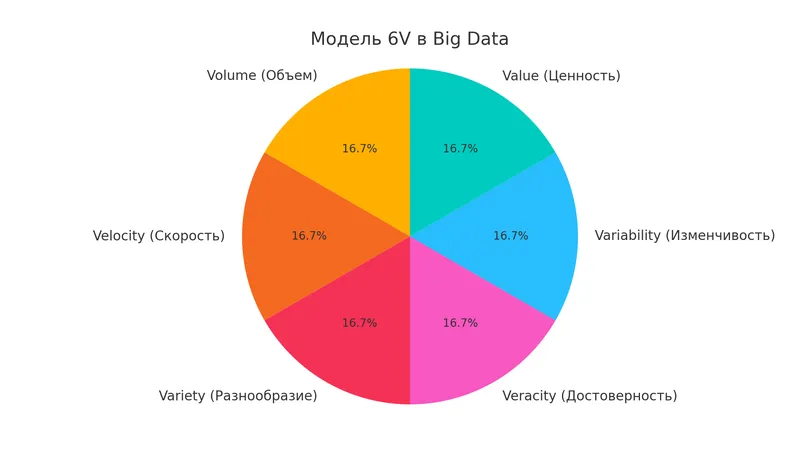
Модель 6V в Big Data — объём, скорость, разнообразие, достоверность, изменчивость и ценность. Все эти характеристики определяют, что данные действительно являются «большими».
Важно понимать, что все эти характеристики взаимосвязаны. Например, высокая скорость поступления (Velocity) часто сопровождается разнообразием форматов (Variety), что усложняет проверку достоверности (Veracity). Это создаёт определённый парадокс: чем больше данных мы собираем, тем сложнее из них извлечь реальную ценность (Value).
Для разных отраслей приоритетность этих характеристик может варьироваться. В финансовом секторе на первый план выходят достоверность и скорость, в то время как для маркетинговых исследований критичнее разнообразие и объём. Но лишь наличие всех шести признаков делает data по-настоящему «большими» в современном понимании.
Возникает резонный вопрос: не является ли модель 6V чрезмерно усложнённой? Практика показывает, что нет — эти критерии помогают отделить действительно масштабные аналитические задачи от рутинной обработки информации, требующей иных подходов и инструментов.
Какие бывают типы данных
В мире больших данных не все массивы информации создаются равными. Мы можем разделить все дата на три основных типа, каждый из которых требует особого подхода к хранению и обработке. Эта классификация играет ключевую роль при проектировании архитектуры BD решений.
Структурированные данные
- Организованы в строгом формате с чётко определёнными полями.
- Легко поддаются индексации, поиску и анализу.
- Хранятся в традиционных реляционных базах данных.
Примеры:
- Банковские транзакции с фиксированными полями (дата, сумма, отправитель, получатель).
- Медицинские показатели пациентов (температура, давление, уровень глюкозы).
- Таблицы Excel с данными о продажах по стандартизированной форме.
Полуструктурированные данные
- Имеют определённую организацию, но без строгой схемы.
- Содержат теги или маркеры для разделения элементов.
- Хранятся с использованием специальных форматов (JSON, XML, YAML).
Примеры:
- Электронные письма (заголовок структурирован, но содержимое — нет).
- Данные о погоде из разных источников с различающимися параметрами.
- Логи веб-серверов с частично стандартизированной информацией.
Неструктурированные данные
- Не имеют предопределённой модели или организации.
- Составляют до 80% всех корпоративных data.
- Требуют специальных инструментов для обработки и анализа.
Примеры:
- Фотографии и видео пользователей социальных сетей.
- Аудиозаписи разговоров в колл-центрах.
- Тексты научных статей и сообщения в мессенджерах.
| Критерий | Структурированные | Полуструктурированные | Неструктурированные |
|---|---|---|---|
| Формат | Фиксированный | Гибкий с элементами структуры | Произвольный |
| Сложность хранения | Низкая | Средняя | Высокая |
| Скорость обработки | Высокая | Средняя | Низкая |
| Масштабируемость | Ограниченная | Хорошая | Отличная |
| Типичные хранилища | Реляционные СУБД | NoSQL, XML-базы | Озёра данных (Data Lakes) |
Интересно отметить, что с развитием технологий границы между этими типами становятся всё более размытыми. Современные системы управления базами данных (СУБД) эволюционируют в сторону гибридных решений, способных эффективно работать с разными типами дата. А распределённая архитектура больших данных позволяет параллельно обрабатывать структурированную и неструктурированную информацию в рамках единой аналитической платформы.
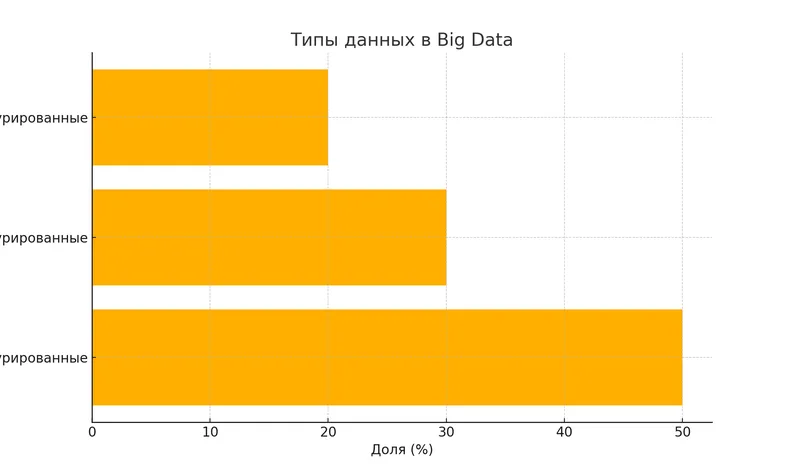
Типы данных в Big Data — неструктурированные данные занимают наибольшую долю (50%), полуструктурированные составляют 30%, а структурированные — 20%.
Возникает закономерный вопрос: какой тип дата наиболее ценен? Ответ неоднозначен и зависит от конкретных бизнес-задач. Иногда наибольшую ценность представляют именно неструктурированные data, содержащие скрытые закономерности, которые невозможно обнаружить в рамках жёстких структур.
Как работает Big Data: от сбора до анализа
Работа с большими данными представляет собой комплексный процесс, напоминающий производственный конвейер, где каждый этап критически важен для получения конечного результата. Давайте разберёмся, как сырые данные превращаются в ценные бизнес-инсайты, проходя через четыре ключевых стадии.
Сбор данных
На этом этапе происходит агрегация информации из множества источников:
- Социальные источники — всё, что генерируется пользователями в цифровой среде: посты, комментарии, фотографии, видеоролики и геолокационные метки из социальных сетей и приложений.
- Статистические источники — data от государственных органов, исследовательских институтов и организаций, охватывающие демографию, экономические показатели и другие формы структурированной информации.
- Медицинские источники — электронные медицинские карты, результаты диагностики, данные носимых устройств, отслеживающих показатели здоровья.
- Машинные источники — информация, генерируемая устройствами без прямого участия человека: дата с датчиков IoT, записи камер наблюдения, показания промышленного оборудования.
- Транзакционные источники — сведения о финансовых операциях, включая платежи, переводы и другие формы монетарного взаимодействия.
На этапе сбора данные также проходят первичную очистку — отсеиваются дубликаты, удаляются явно ошибочные значения и исправляются форматы.
Хранение
Для Биг Дата традиционные хранилища неэффективны, поэтому используются специализированные системы:
- Data Warehouse (DWH) — единое корпоративное хранилище, где дата структурированы по принципу ETL (Extract, Transform, Load): сначала извлекаются из источников, затем трансформируются в единый формат и только потом загружаются в хранилище.
- Data Lake — «озёра данных», работающие по принципу ELT (Extract, Load, Transform): информация сначала сохраняется в исходном виде, и лишь при необходимости преобразуется под конкретную задачу.
- Системы управления базами данных (СУБД) — как реляционные (PostgreSQL, MySQL), так и нереляционные (MongoDB, Cassandra). Для больших data часто используются колоночные СУБД (ClickHouse, Vertica), оптимизированные для аналитических запросов.
- Распределённые файловые системы — например, Hadoop Distributed File System (HDFS), позволяющая хранить огромные массивы данных на кластерах из обычных серверов.
Обработка и анализ
Здесь происходит самое интересное — превращение «сырых» дата в информацию, пригодную для принятия решений:
- MapReduce и его современные аналоги — парадигма распределённых вычислений, когда задача разбивается на множество мелких, которые решаются параллельно на разных узлах.
- Apache Spark — фреймворк для распределённой обработки данных, выполняющий вычисления в оперативной памяти, что существенно ускоряет процесс относительно традиционного Hadoop.
- Аналитика и визуализация — использование BI-инструментов (Power BI, Tableau) для создания интерактивных дашбордов, диаграмм и отчётов, делающих данные понятными для конечных пользователей.
- Машинное обучение — применение алгоритмов, способных находить закономерности в data и делать прогнозы без явного программирования правил.
Весь этот процесс напоминает воронку: на входе — гигантские объёмы разнородной информации, а на выходе — концентрированные инсайты, готовые для трансформации в бизнес-решения. Ключевое отличие BD архитектуры от традиционных систем обработки дата — возможность работать с информацией параллельно на множестве узлов, обеспечивая как горизонтальную масштабируемость, так и отказоустойчивость.
Интересная особенность современных Big Data-систем — смещение акцента от пакетной обработки к потоковой (stream processing), позволяющей анализировать данные практически в реальном времени, что критично для ряда бизнес-сценариев, таких как выявление мошенничества или динамическое ценообразование.
Где применяются большие данные
Поразительно, как быстро Биг Дата из узкоспециализированной технологии превратилась в ключевой драйвер инноваций практически во всех сферах человеческой деятельности. Мы наблюдаем, как большие data трансформируют отрасли, создавая конкурентные преимущества для тех, кто освоил их потенциал.

Big Data в реальной жизни — аналитики работают за компьютерами, обрабатывая массивы данных. На экранах отображаются графики, диаграммы и дашборды, а на заднем плане — серверы и потоки данных.
Медицина и здравоохранение
- Прогнозирование вспышек заболеваний на основе поисковых запросов и активности в социальных сетях.
- Персонализированная медицина с учётом генетических особенностей пациента.
- Оптимизация операционной деятельности медицинских учреждений, сокращение времени ожидания.
Кейс: Компания IBM Watson Health анализирует медицинские карты, научные публикации и клинические испытания для поддержки врачебных решений, повышая точность диагностики редких заболеваний на 30%.
Финансы и банковский сектор
- Алгоритмическая торговля на фондовых рынках с учётом микротрендов.
- Выявление мошеннических транзакций в режиме реального времени.
- Оценка кредитоспособности клиентов на основе цифрового следа.
Кейс: Сбербанк использует Big Data для определения кредитного скоринга, что снизило уровень невозвратов на 15% и ускорило принятие решений по кредитам с нескольких дней до нескольких минут.
Маркетинг и ритейл
- Гиперперсонализация предложений на основе поведенческих паттернов.
- Динамическое ценообразование в зависимости от спроса и действий конкурентов.
- Оптимизация ассортимента для конкретных локаций.
Кейс: Amazon генерирует до 35% выручки благодаря системе рекомендаций, построенной на анализе поведения миллионов пользователей.
Наука и исследования
- Моделирование климатических изменений на основе дата тысяч метеостанций.
- Секвенирование генома и поиск новых лекарств.
- Физика высоких энергий и анализ данных с коллайдеров.
Кейс: ЦЕРН ежедневно обрабатывает петабайты data с экспериментов на Большом адронном коллайдере, что привело к открытию бозона Хиггса.
Транспорт и логистика
- Оптимизация маршрутов доставки с учётом дорожной ситуации.
- Предиктивное обслуживание транспортных средств.
- Динамическое определение цен на поездки в зависимости от спроса.
Кейс: Яндекс.Такси использует алгоритмы обработки больших data для прогнозирования спроса, распределения водителей и оптимизации цен, сокращая среднее время ожидания такси с 7 до 4 минут.
| Отрасль | Задачи | Результаты |
|---|---|---|
| Медицина | Диагностика, исследования, оптимизация лечения. | Повышение точности диагностики, сокращение расходов. |
| Финансы | Скоринг, противодействие мошенничеству, алгоритмическая торговля. | Снижение рисков, увеличение маржинальности операций. |
| Ритейл | Персонализация, управление запасами, ценообразование. | Рост среднего чека, оптимизация логистики. |
| Транспорт | Маршрутизация, техобслуживание, управление трафиком. | Сокращение времени доставки, уменьшение простоев. |
Примечательно, что границы между применением больших данных в разных отраслях постепенно стираются. Например, технологии, первоначально разработанные для финансового сектора, находят применение в здравоохранении, а алгоритмы рекомендаций из e-commerce внедряются в государственные сервисы. Это свидетельствует о формировании универсальных подходов к решению сложных аналитических задач.
Преимущества использования
В эпоху информационного взрыва большие дата становятся не просто технологическим трендом, но и критическим фактором конкурентоспособности. Мы видим, как организации, освоившие инструменты Big Data, получают существенные преимущества в своих отраслях. Но в чем конкретно заключается эта выгода?
Повышение качества принимаемых решений
- Переход от интуитивного менеджмента к data-driven подходу.
- Возможность учитывать множество факторов одновременно.
- Снижение влияния когнитивных искажений на стратегические решения.
Прогнозирование с высокой точностью
- Выявление неочевидных закономерностей в исторических дата.
- Моделирование различных сценариев развития событий.
- Предсказание поведения пользователей и рыночных трендов.
Оптимизация операционной деятельности
- Сокращение издержек за счет автоматизации аналитики.
- Выявление неэффективных бизнес-процессов.
- Оперативное реагирование на аномалии и инциденты.
Персонализация клиентского опыта
- Точное таргетирование маркетинговых кампаний.
- Создание индивидуальных предложений для каждого клиента.
- Повышение уровня удовлетворенности и лояльности потребителей.
Инновации и новые бизнес-модели
- Создание продуктов, основанных на данных.
- Монетизация аналитических инсайтов.
- Трансформация традиционных отраслей через цифровизацию.
Важно отметить, что ценность больших дата экспоненциально возрастает при их комбинировании из различных источников. Например, сочетание транзакционных данных с поведенческими метриками и информацией из социальных сетей создает многомерную картину предпочтений потребителя, недоступную при использовании лишь одного источника информации.
Однако не стоит воспринимать BD как панацею — реализация потенциала больших data требует не только технологических инвестиций, но и культурных изменений в организации, готовности к экспериментам и принятию решений на основе информации, а не только опыта и интуиции.
Риски и вызовы: безопасность, приватность и этика работы с Big Data
Чем больше данных мы собираем, тем острее встают вопросы их защиты. Большие данные — это не только новые возможности, но и серьёзные риски, особенно когда речь заходит о приватности, безопасности и юридических аспектах.
Почему это важно?
Обработка больших массивов информации зачастую затрагивает персональные данные миллионов людей:
— историю покупок,
— передвижения,
— медицинские показатели,
— активность в социальных сетях.
Ошибки в работе с такими данными могут привести к утечкам, дискриминации, нарушениям закона или просто подрыву доверия к компании.
Основные риски:
- Утечка данных. Чем больше информации хранится, тем выше риск её компрометации.
- Нарушение конфиденциальности. Даже обезличенные данные можно деанонимизировать, сопоставив разные источники.
- Неэтичное использование. Например, манипуляция поведением пользователей на основе предсказаний их слабых мест — граница между маркетингом и манипуляцией размыта.
- Юридические последствия. Нарушение законов о защите данных может обойтись в миллионы долларов штрафов. Например, за несоблюдение GDPR в Европе или российского закона о локализации персональных данных.
Как компании решают эти проблемы?
- Используют методы обезличивания данных — удаляют или маскируют идентифицирующую информацию.
- Применяют сквозное шифрование при передаче и хранении данных.
- Внедряют политику минимизации: собирают только то, что действительно нужно.
- Назначают DPO (Data Protection Officer) — специалиста, отвечающего за соблюдение норм безопасности данных.
- Проходят регулярные аудиты безопасности.
Где грань между инновациями и этикой?
Сбор и анализ больших данных — это не только про технологии, но и про ответственность. В эпоху цифровизации важно задавать себе неудобные вопросы:
- Нужно ли нам действительно собирать все эти данные?
- Как мы обеспечим их сохранность?
- Какое влияние наша аналитика окажет на реальных людей?
Только те компании, которые смогут честно ответить на эти вопросы, смогут использовать потенциал Big Data, не переходя границы допустимого.
Какие специалисты работают с Big Data
Мир больших данных требует специалистов с уникальным набором навыков, балансирующих на стыке математики, программирования и бизнес-аналитики. Мы наблюдаем формирование целой экосистемы профессий, каждая из которых играет свою незаменимую роль в превращении сырых data в ценные бизнес-решения.
Data Engineer
- Ключевые обязанности: проектирование и поддержка инфраструктуры для хранения и обработки дата, разработка ETL-процессов.
- Необходимые навыки: программирование на Python, Java или Scala, опыт работы с распределенными системами (Hadoop, Spark), знание SQL и NoSQL СУБД.
- Подходит для: разработчиков, системных администраторов, DevOps-инженеров с интересом к данным.
Data Scientist
- Ключевые обязанности: построение прогностических моделей, выявление закономерностей в дата, проведение экспериментов.
- Необходимые навыки: математическая статистика, машинное обучение, программирование на Python/R, визуализация данных.
- Подходит для: аналитиков, математиков, исследователей, программистов с сильной математической подготовкой.
Data Analyst
- Ключевые обязанности: анализ data для решения конкретных бизнес-задач, создание дашбордов и отчетов, формирование рекомендаций.
- Необходимые навыки: SQL, Excel, инструменты визуализации (Tableau, Power BI), статистический анализ.
- Подходит для: бизнес-аналитиков, маркетологов, экономистов с аналитическим складом ума.
ML Engineer
- Ключевые обязанности: внедрение моделей машинного обучения в производственные системы, оптимизация алгоритмов.
- Необходимые навыки: глубокие знания в области ML/DL, навыки программирования, понимание MLOps-процессов.
- Подходит для: специалистов по данным с сильными инженерными навыками, программистов с опытом в ML.
DWH-аналитик
- Ключевые обязанности: проектирование и оптимизация структуры хранилищ данных, создание и поддержка ETL-процессов.
- Необходимые навыки: глубокие знания SQL, понимание принципов хранилищ данных, опыт работы с ETL-инструментами.
- Подходит для: SQL-разработчиков, аналитиков баз данных с опытом работы с большими массивами информации.
BI-разработчик
- Ключевые обязанности: создание аналитических дашбордов, внедрение инструментов для самостоятельной аналитики бизнес-пользователями
- Необходимые навыки: SQL, инструменты BI (Tableau, Power BI, QlikView), понимание принципов визуализации data.
- Подходит для: аналитиков с творческим подходом к представлению информации и пониманием потребностей бизнеса.
Интересно отметить, что границы между этими специальностями становятся всё более размытыми, а требования к универсальности навыков возрастают. Например, успешный Data Scientist сегодня должен не только разбираться в алгоритмах машинного обучения, но и обладать навыками инженерной работы с данными, а также уметь доносить результаты своей работы до бизнес-пользователей — т.е. частично выполнять функции инженера данных и BI-разработчика.
При этом в экосистеме больших данных находится место специалистам с самым разным бэкграундом — от чистых математиков до отраслевых экспертов. Ключевым объединяющим фактором становится аналитический склад ума и готовность постоянно осваивать новые инструменты и подходы в этой стремительно развивающейся области.
Как начать работать с Big Data
Путь в мир больших данных может показаться извилистым и труднопроходимым, особенно для тех, кто не имеет технического бэкграунда. Однако мы видим, что при структурированном подходе войти в эту динамично развивающуюся область вполне реально. Рассмотрим пошаговую стратегию входа в профессию, которая зарекомендовала себя как эффективная.
Что учить
- Освоение фундаментальных знаний
- Математическая база: линейная алгебра, теория вероятностей, математическая статистика.
- Алгоритмы и структуры data: понимание сложности алгоритмов, основных методов сортировки и поиска.
- Основы баз данных: реляционные модели, нормализация, базовый SQL.
- Изучение языков программирования и инструментов
- Python — универсальный язык для анализа данных с обширной экосистемой библиотек (pandas, NumPy, scikit-learn).
- SQL — обязательный навык для работы с хранилищами данных.
- R — специализированный язык для статистического анализа (опционально).
- Scala — для работы с Apache Spark и другими инструментами экосистемы JVM (опционально).
- Знакомство с технологиями Big Data
- Hadoop-экосистема: HDFS, MapReduce, Hive, HBase.
- Apache Spark — для распределённой обработки data.
- NoSQL базы данных: MongoDB, Cassandra, Redis.
- Инструменты визуализации: Tableau, Power BI, Matplotlib, Seaborn.
- Специализация в выбранном направлении
- Для инженера данных: углубление в ETL-процессы, системы распределённого хранения.
- Для аналитика: статистические методы, A/B-тестирование, инструменты визуализации.
- Для специалиста по данным: алгоритмы машинного обучения, нейронные сети, NLP.
Где применять на практике
- Работа с открытыми данными
- Использование публичных датасетов с Kaggle, Google Dataset Search, Data.gov.
- Участие в соревнованиях по анализу данных для применения теоретических знаний.
- Анализ открытых API (Reddit, GitHub) для сбора и обработки реальных данных.
- Портфолио проектов
- Создание репозитория на GitHub с примерами работ по анализу и визуализации данных.
- Разработка dashboard’а на основе открытых данных, демонстрирующего навыки визуализации.
- Реализация end-to-end проекта с элементами сбора, обработки, анализа и представления результатов.
- Профессиональное развитие
- Прохождение специализированных курсов: Coursera, Udacity, Яндекс.Практикум, курс «Специалист по Data Science».
- Участие в профессиональных сообществах.
- Чтение технической литературы и мониторинг блогов ведущих компаний в области данных.
- Стажировки и первая работа
- Поиск начальных позиций: Junior Data Analyst, Data Engineer Assistant.
- Рассмотрение возможностей перехода из смежных областей: программирование, аналитика, статистика.
- Участие в хакатонах и отраслевых мероприятиях для нетворкинга.
Интересно отметить, что путь в BD не всегда начинается с нуля. Многие успешные специалисты приходят в эту область из смежных профессий, привнося ценную отраслевую экспертизу. Например, маркетолог с аналитическим складом ума может стать отличным аналитиком данных в е-commerce, а инженер из производственного сектора — найти себя в области предиктивного обслуживания оборудования.
Важно понимать, что в сфере больших данных, как ни в какой другой, критически важно непрерывное обучение. Технологии и методы здесь обновляются с такой скоростью, что даже опытные специалисты вынуждены постоянно осваивать новые инструменты и подходы. Поэтому готовность к непрерывному самообразованию — пожалуй, самое важное качество для всех, кто планирует связать свою карьеру с Big Data.
Заключение
Подводя итоги нашего погружения в мир больших данных, мы видим, что Big Data — это не просто технологический тренд, а фундаментальный сдвиг в подходах к работе с информацией. Это явление, трансформирующее бизнес-модели, научные исследования и даже повседневную жизнь.
- Big Data — это не просто большие объёмы информации. Это комплексный процесс сбора, хранения, обработки и анализа разнородных данных.
- Основная цель работы с большими данными — превращать информацию в полезные бизнес-решения. Это помогает прогнозировать поведение клиентов, оптимизировать процессы и создавать новые продукты.
- Модель 6V — это основа понимания Big Data. Объём, скорость, разнообразие, достоверность, изменчивость и ценность — все эти параметры важны для работы с данными.
- Большие данные используются в разных сферах: от медицины до ритейла и финансов. Это уже не теория, а рабочий инструмент бизнеса.
- Работать с Big Data могут специалисты разных профилей. Инженеры, аналитики, дата-сайентисты и BI-разработчики создают инфраструктуру, анализируют данные и строят прогнозы.
- Начать работать с Big Data можно с изучения основ аналитики и практических курсов. Это доступно даже тем, кто раньше не сталкивался с анализом данных.
Хотите разобраться глубже? Посмотрите подборку курсов по системной аналитике — это поможет освоить инструменты работы с Big Data на практике. Там собраны актуальные обучающие программы, которые помогут вам освоить работу с Big Data — от сбора информации до построения аналитических моделей.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 апреля
|
Подробнее |
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
257 760 ₽
Ещё -12% по промокоду
|
От
4 579 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.