Что такое DOM, как он устроен и как с ним работать
Когда мы открываем веб-страницу в браузере, перед нами возникает визуальный интерфейс: текст, кнопки, изображения, формы. Однако за этой визуальной оболочкой скрывается сложная структура данных, которая делает возможным всё то интерактивное волшебство, к которому мы привыкли на современных сайтах. Эта структура называется DOM — Document Object Model, или объектная модель документа.
По своей сути Document Object Model представляет собой программный интерфейс, который трансформирует статичный HTML-код в древовидную структуру взаимосвязанных объектов. Можно сказать, что DOM — это своеобразный мост между разметкой страницы и языком программирования JavaScript. Без этого моста браузер просто отобразил бы набор тегов и текста, и страница оставалась бы полностью статичной, как обычный текстовый документ.
Важно понимать: DOM — это именно структура данных, а не визуальный интерфейс. Когда браузер считывает HTML-код, он преобразует каждый тег, абзац и изображение в отдельный объект. Они выстраиваются в иерархию — подобно файловой системе на компьютере, где есть корневая папка, вложенные директории и файлы внутри них. Так возникает DOM-дерево.
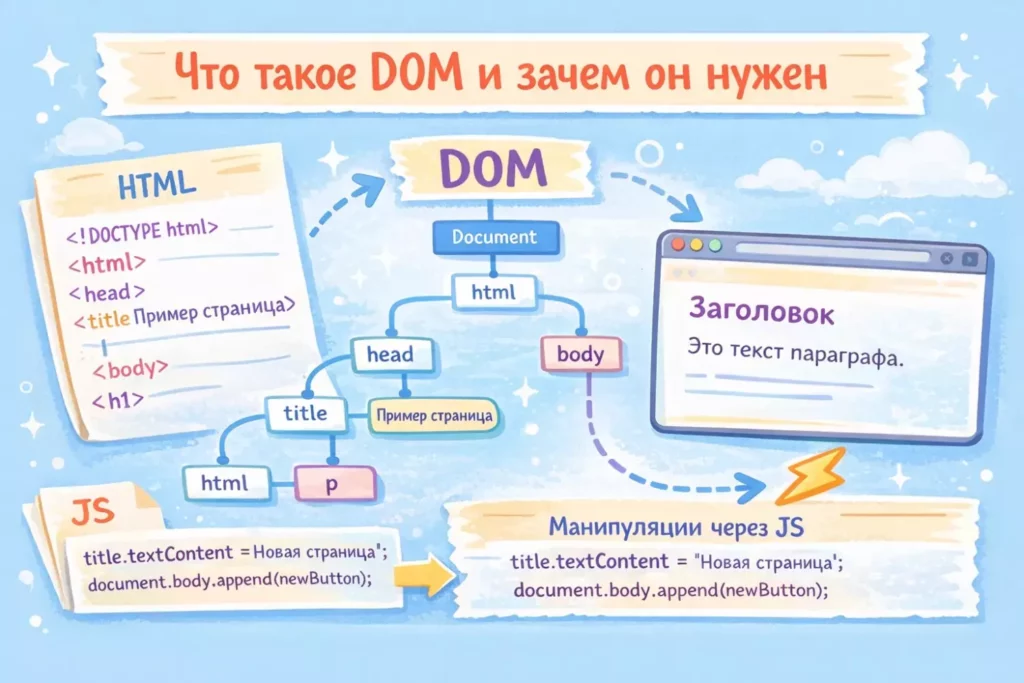
DOM преобразует HTML-разметку в древовидную структуру объектов, с которой может работать JavaScript. Изменяя узлы DOM, скрипты управляют содержимым страницы без её перезагрузки. Именно эта модель делает веб-интерфейсы интерактивными.
Именно благодаря Document Object Model веб-страницы становятся интерактивными. JavaScript получает возможность взаимодействовать с любым элементом страницы уже после её загрузки: изменять текст кнопки, скрывать блоки, добавлять новые компоненты или реагировать на действия пользователя. Без DOM-модели каждое изменение на странице требовало бы полной перезагрузки — и о современных одностраничных приложениях можно было бы забыть.
- Как браузер превращает HTML в DOM-дерево
- Из чего состоит DOM: типы узлов
- Доступ к DOM через JavaScript: базовые методы
- Как изменять DOM: полный разбор операций
- Работа с атрибутами и стилями
- Обработка событий: как DOM реагирует на действия пользователя
- Работа DOM с формами
- DOM и визуальное отображение: в чём разница
- Производительность: проблемы и решения
- Браузерные инструменты для работы
- Преимущества и недостатки
- Заключение
- Рекомендуем посмотреть курсы по веб разработке
Как браузер превращает HTML в DOM-дерево
Процесс превращения HTML-кода в интерактивную структуру данных происходит каждый раз, когда мы открываем веб-страницу. Давайте разберёмся, как именно браузер выполняет эту трансформацию и почему результат называют деревом.
Когда браузер получает HTML-документ от сервера, он не просто отображает код на экране. Вместо этого запускается специальный компонент — парсер HTML, который построчно читает разметку и начинает строить DOM-дерево. Парсер анализирует каждый тег, атрибут и фрагмент текста, преобразуя их в отдельные узлы — структурные единицы будущего дерева.
Процесс построения идёт последовательно, сверху вниз. Браузер видит открывающий тег <html> и создаёт корневой узел — самый главный элемент, от которого отрастают все ветви. Затем он встречает теги <head> и <body> и добавляет их как дочерние узлы корня. Внутри <body> обнаруживаются параграфы, ссылки, изображения — каждый из них становится отдельным узлом и занимает своё место в иерархии.
Ключевое понятие здесь — иерархия родителей и потомков. Каждый узел может иметь только одного родителя, но множество детей. Узлы, находящиеся на одном уровне вложенности, считаются siblings — «братьями» или «сёстрами». Узлы без потомков называются листьями дерева. Эта древовидная структура позволяет браузеру эффективно навигировать по документу и быстро находить нужные компоненты.

Визуализация того, как браузер разбирает HTML-код на вложенные объекты. Синие круги — это элементы-контейнеры, а желтые — текстовые узлы, содержащие контент.
Рассмотрим простой пример HTML-кода:
<!DOCTYPE html> <html> <head> <title>Пример страницы </head> <h1>Заголовок <p>Это текст параграфа. </body> </html>
Браузер преобразует его в следующую древовидную структуру:
Document └── html ├── head │ └── title │ └── "Пример страницы" └── body ├── h1 │ └── "Заголовок" └── p └── "Это текст параграфа."
Как видим, каждый тег становится узлом-элементом, а текст внутри. Именно с ними чаще всего работают девелоперы— отдельными текстовыми узлами. Важно отметить, что всё содержимое между открывающим и закрывающим тегами также становится частью Document Object Model — включая пробелы и переносы строк, хотя они часто игнорируются при отображении.
После того как парсер доходит до конца документа, DOM-дерево считается построенным. Теперь JavaScript может получить доступ к любому узлу этой структуры, изменить его свойства или добавить новые ветви. Браузер следит за изменениями в дереве и автоматически обновляет то, что мы видим на экране.
Из чего состоит DOM: типы узлов
DOM-дерево не является однородной структурой — оно состоит из узлов разных типов, каждый из которых выполняет свою специфическую роль. Понимание этих типов критически важно для эффективной работы с документом: именно знание того, с каким типом узла мы имеем дело, определяет, какие методы можно применить и какие изменения допустимы.
Рассмотрим основные типы узлов, из которых строится любой Document Object Model-документ:
- Document — корневой узел всей иерархии, представляющий документ целиком. Это точка входа в DOM-дерево, через которую JavaScript получает доступ ко всем остальным элементам. Именно объект document мы используем, когда пишем document.querySelector() или document.getElementById().
- Element — узлы-элементы, соответствующие HTML-тегам. Это самый распространённый тип: каждый <div>, <p>, <a> или <img> в разметке становится узлом типа Element. Именно с ними чаще всего работают разработчики, изменяя их содержимое, стили или структуру.
- Text — текстовые узлы, содержащие собственно текст документа. Важная деталь: текст внутри тега не является частью самого элемента, а представляет собой отдельный дочерний узел. Например, в конструкции <p>Привет</p> узел <p> содержит один дочерний текстовый узел со значением «Привет».
- Attr (атрибуты) — узлы, представляющие атрибуты HTML-компонентов, такие как id, class, href или src. Технически атрибуты также являются узлами Document Object Model, хотя современные API чаще работают с ними как со свойствами элементов, а не как с отдельными узлами дерева.
- Comment — узлы комментариев, соответствующие HTML, вида <!— комментарий —>. Они остаются в DOM-дереве даже после парсинга, хотя не отображаются визуально. Разработчики иногда используют их для специальных целей — например, как маркеры для динамической вставки контента.
Для наглядности представим типы узлов в виде таблицы:
| Тип узла | Описание | Пример |
|---|---|---|
| Document | Корень документа | document |
| Element | HTML-теги | <div>, <p>, <span> |
| Text | Текстовое содержимое | Текст внутри тегов |
| Attr | Атрибуты элементов | class=»button», id=»header» |
| Comment | Комментарии в коде | <!— TODO: добавить валидацию —> |
Зачем нужно различать типы узлов? Дело в том, что разные типы поддерживают разные операции. Мы можем изменить текстовое содержимое текстового узла, но не можем добавить к нему дочерние компоненты. Мы можем установить атрибуты у элемента, но не у текстового узла. Понимание этой типологии позволяет избежать ошибок и писать более эффективный код при манипуляции документом.
Доступ к DOM через JavaScript: базовые методы
Построение DOM-дерева браузером — это только половина истории. Настоящая магия начинается, когда JavaScript получает возможность взаимодействовать с этой структурой. Для этого существует целый арсенал методов, позволяющих находить нужные компоненты на странице и работать с ними.
Исторически первыми появились методы, ориентированные на конкретные атрибуты элементов. getElementById() ищет элемент по его уникальному идентификатору — пожалуй, самый простой и быстрый способ получить доступ к конкретному узлу:
const header = document.getElementById('main-header');
// Возвращает один элемент или null, если элемент не найден
getElementsByClassName() и getElementsByTagName() работают шире — они возвращают коллекцию всех компонентов, соответствующих указанному классу или тегу. Важная деталь: результатом является не массив, а HTMLCollection — живая коллекция, которая автоматически обновляется при изменении DOM:
const buttons = document.getElementsByClassName('btn');
// Возвращает HTMLCollection всех элементов с классом 'btn'
const paragraphs = document.getElementsByTagName('p');
// Возвращает HTMLCollection всех параграфов
Однако современная веб-разработка тяготеет к более универсальным инструментам. querySelector() и querySelectorAll() произвели настоящую революцию в работе с DOM, позволив использовать любые CSS-селекторы для поиска элементов. Первый метод возвращает первый найденный компонент, второй — NodeList со всеми совпадениями:
// Поиск по классу
const button = document.querySelector('.submit-button');
// Поиск по сложному селектору
const firstLink = document.querySelector('nav > ul > li:first-child a');
// Получение всех элементов
const allImages = document.querySelectorAll('img[alt]');
// Возвращает NodeList -- статическую коллекцию
Почему querySelector стал фактическим стандартом? Причина проста: универсальность и читаемость кода. Вместо того чтобы запоминать множество специализированных методов, разработчик использует привычный синтаксис CSS-селекторов, который работает для любых случаев — от простейшего поиска по классу до сложных комбинаций псевдоклассов и атрибутов.
Для доступа к ключевым компонентам документа существуют прямые ссылки: document.body возвращает элемент <body>, а document.documentElement — корневой элемент <html>. Это удобные shortcut’ы, не требующие поиска:
document.body.style.backgroundColor = '#f0f0f0'; console.log(document.documentElement.lang); // Получаем атрибут lang у
Следует помнить о различиях между возвращаемыми значениями: getElementById() и querySelector() возвращают либо один элемент, либо null, тогда как методы с префиксом «getElements» и querySelectorAll() всегда возвращают коллекцию — даже если она пустая или содержит один элемент. Это влияет на то, как мы работаем с результатом: одиночный компонент можно сразу использовать, а с коллекцией придётся итерировать.
Как изменять DOM: полный разбор операций
Поиск компонентов — это только начало работы с DOM. Настоящая мощь JavaScript раскрывается, когда мы начинаем модифицировать структуру документа: изменять содержимое, добавлять новые элементы или удалять существующие. Давайте рассмотрим основные операции, которые составляют арсенал любого frontend-разработчика.
Изменение содержания элементов
Для изменения содержимого существуют два ключевых свойства: innerHTML и textContent. На первый взгляд они кажутся взаимозаменяемыми, но различия между ними принципиальны.
innerHTML работает с HTML-разметкой: он позволяет не только изменить текст, но и вставить целые структуры с тегами. Браузер парсит переданную строку и создаёт соответствующие узлы:
const container = document.querySelector('.content');
container.innerHTML = '<h2>Новый заголовок<p>И новый параграф';
textContent, напротив, работает исключительно с текстом. Даже если передать ему HTML-теги, они будут вставлены как обычный текст, а не интерпретированы как разметка:
const paragraph = document.querySelector('p');
paragraph.textContent = 'Простой текст без форматирования';
// Если вставить 'Текст', теги отобразятся как текст
Когда использовать каждый из них? textContent предпочтителен для работы с пользовательским вводом — он безопаснее, так как предотвращает XSS-атаки. innerHTML удобен, когда нужно вставить готовую разметку, но требует осторожности при работе с непроверенными данными.
Создание и вставка элементов
Для программного создания новых компонентов используется метод createElement(), который принимает имя тега и возвращает новый узел:
const newDiv = document.createElement('div');
newDiv.className = 'card';
newDiv.textContent = 'Содержимое карточки';
Созданный элемент существует в памяти, но ещё не отображается на странице. Чтобы добавить его в документ, применяются методы вставки:
append() и appendChild() добавляют компонент в конец родительского контейнера. Разница в том, что append() — более современный метод, позволяющий вставлять сразу несколько элементов и даже текстовые строки:
const list = document.querySelector('ul');
const item = document.createElement('li');
item.textContent = 'Новый пункт';
list.appendChild(item);
// Или с append() - можно добавить несколько элементов
list.append(item, 'Ещё один пункт');
prepend() вставляет компонент в начало контейнера, а insertBefore() позволяет разместить новый узел перед указанным элементом, обеспечивая точный контроль над позицией.
Удаление элементов
Удаление из DOM стало значительно проще с появлением метода remove():
const elementToRemove = document.querySelector('.old-banner');
elementToRemove.remove();
Классический подход с removeChild() требует обращения к родительскому элементу, что делает код более громоздким:
const parent = element.parentNode; parent.removeChild(element);
Клонирование элементов
Когда нужно создать копию существующего элемента со всеми его атрибутами и стилями, на помощь приходит cloneNode(). Метод принимает булев параметр: true для глубокого копирования (со всеми потомками), false — для поверхностного:
const original = document.querySelector('.template');
const clone = original.cloneNode(true); // Копируем со всем содержимым
clone.id = 'new-element'; // Меняем ID, чтобы избежать дублирования
document.body.appendChild(clone);
Эти операции составляют фундамент динамического изменения веб-страниц. Комбинируя их, мы можем создавать сложные интерактивные интерфейсы, реагирующие на действия пользователя в режиме реального времени.
Работа с атрибутами и стилями
Манипуляция содержимым компонентов — это лишь часть возможностей Document Object Model. Не менее важной задачей является изменение атрибутов и визуального оформления элементов. JavaScript предоставляет для этого удобные инструменты, позволяющие динамически управлять практически любыми характеристиками элементов.
Для работы с атрибутами существует набор специализированных методов. getAttribute() читает значение указанного атрибута, возвращая строку или null, если атрибут отсутствует:
const link = document.querySelector('a');
const url = link.getAttribute('href');
console.log(url); // Выведет значение атрибута href
setAttribute() устанавливает новое значение атрибута или создаёт его, если он отсутствовал:
link.setAttribute('href', 'https://example.com');
link.setAttribute('target', '_blank'); // Откроется в новой вкладке
hasAttribute() проверяет наличие атрибута без получения его значения — полезно для условной логики, а removeAttribute() полностью удаляет атрибут из элемента.
Важно понимать различие между атрибутами и свойствами. Атрибуты — это то, что написано в HTML-разметке, свойства — это характеристики DOM-объекта в JavaScript. Для стандартных атрибутов браузер автоматически создаёт соответствующие свойства, и обращение через точку часто удобнее:
// Через свойство (для стандартных атрибутов)
link.href = 'https://example.com';
// Через метод (для любых атрибутов, включая кастомные)
link.setAttribute('data-id', '12345');
Для управления CSS-классами существует мощный интерфейс classList, предлагающий методы add(), remove(), toggle() и contains():
const button = document.querySelector('.btn');
button.classList.add('active'); // Добавить класс
button.classList.remove('disabled'); // Удалить класс
button.classList.toggle('hidden'); // Переключить класс
Изменение инлайн-стилей осуществляется через свойство style. Важная деталь: CSS-свойства с дефисами в JavaScript записываются в camelCase:
const header = document.querySelector('h1');
header.style.color = 'blue';
header.style.fontSize = '2em';
header.style.backgroundColor = '#f0f0f0'; // background-color → backgroundColor
Следует помнить, что изменение стилей через style создаёт инлайн-стили, которые имеют высокий приоритет. Для лучшей архитектуры кода предпочтительнее управлять оформлением через классы, а CSS держать в отдельных файлах — это обеспечивает разделение логики и представления.
Обработка событий: как DOM реагирует на действия пользователя
Статичная веб-страница, даже с самой сложной структурой Document Object Model, остаётся всего лишь документом. Настоящая интерактивность возникает тогда, когда страница начинает реагировать на действия пользователя — клики мышью, нажатия клавиш, скроллинг, наведение курсора. Механизм, связывающий эти действия с изменениями в DOM, называется системой событий.
Событие в контексте Document Object Model — это сигнал о том, что произошло что-то значимое. Пользователь кликнул по кнопке? Возникло событие click. Начал вводить текст в поле? Сработало событие input. Навёл курсор на элемент? Появилось событие mouseover. Браузер непрерывно отслеживает множество подобных действий и генерирует соответствующие события.
Для того чтобы наш код мог реагировать на эти события, используется метод addEventListener(). Он принимает два основных параметра: тип события (строка) и функцию-обработчик, которая будет выполнена при возникновении события:
const button = document.querySelector('.submit-btn');
button.addEventListener('click', function() {
console.log('Кнопка нажата!');
});
Рассмотрим практический пример: создадим простую интерактивность, где клик по кнопке изменяет текст на странице:
const button = document.querySelector('#changeTextBtn');
const heading = document.querySelector('h1');
button.addEventListener('click', function() {
heading.textContent = 'Текст изменён!';
heading.style.color = 'green';
});
Здесь отчётливо видна вся цепочка: пользователь выполняет действие (клик) → браузер генерирует событие → JavaScript получает уведомление через обработчик → код изменяет DOM → браузер обновляет визуальное отображение. Эта связка работает молниеносно, создавая ощущение мгновенной реакции интерфейса.
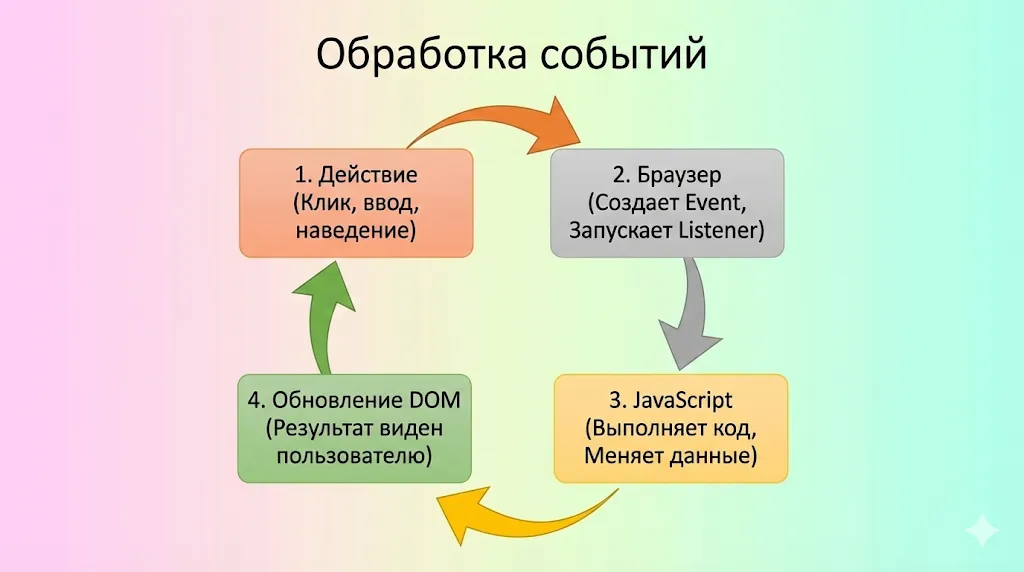
Механизм реакции на действия пользователя. JavaScript выступает посредником: он перехватывает событие от браузера, выполняет код и обновляет DOM, замыкая круг взаимодействия.
События не ограничиваются кликами. Для работы с формами используются input и change, для отслеживания клавиатуры — keydown и keyup, для работы с прокруткой — scroll. Современные веб-приложения могут обрабатывать десятки различных типов событий, создавая сложные интерактивные сценарии:
const input = document.querySelector('input');
input.addEventListener('input', function(event) {
console.log('Текущее значение:', event.target.value);
});
Возникает вопрос: можно ли обойтись без системы событий? Теоретически да, но на практике это означало бы постоянный опрос состояния элементов — неэффективный и ресурсозатратный подход. События работают по принципу уведомлений: код спокойно ожидает, пока не произойдёт что-то важное, и только тогда активируется. Именно это делает современные веб-приложения одновременно отзывчивыми и производительными.
Работа DOM с формами
Формы представляют собой особую категорию элементов в веб-разработке — именно через них пользователи отправляют данные, регистрируются, авторизуются, оставляют комментарии. Document Object Model предоставляет специализированные инструменты для работы с формами, делая процесс сбора и валидации данных максимально удобным.
Чтение значений из полей формы осуществляется через свойство value. Для текстовых полей, текстовых областей и селектов это свойство возвращает текущее содержимое:
const emailInput = document.querySelector('#email');
const userEmail = emailInput.value;
console.log('Введённый email:', userEmail);
Для чекбоксов и радиокнопок используется свойство checked, возвращающее булево значение — отмечен элемент или нет.
Валидация данных перед отправкой — критически важный аспект работы с формами. DOM позволяет проверять введённые значения и предотвращать отправку некорректных данных:
const form = document.querySelector('#registrationForm');
const passwordInput = document.querySelector('#password');
form.addEventListener('submit', function(event) {
if (passwordInput.value.length < 8) {
event.preventDefault(); // Останавливаем отправку формы
alert('Пароль должен содержать минимум 8 символов');
}
});
Метод preventDefault() играет ключевую роль — он отменяет стандартное поведение браузера, которое заключается в перезагрузке страницы при отправке формы. Это позволяет обработать данные на стороне клиента, отправить их через AJAX или выполнить дополнительные проверки без потери состояния страницы.
Современные веб-приложения часто используют такой подход для создания бесшовного пользовательского опыта, где отправка формы происходит асинхронно, без видимой перезагрузки. DOM делает это возможным, предоставляя полный контроль над процессом обработки форм.
DOM и визуальное отображение: в чём разница
Распространённое заблуждение среди начинающих разработчиков заключается в отождествлении Document Object Model с тем, что мы видим на экране. Действительно, когда мы изменяем DOM, страница обновляется — кажется, что это одно и то же. Однако на самом деле Document Object Model — это всего лишь структура данных, абстрактная модель документа, которая сама по себе ничего не рисует.
Чтобы превратить дерево в видимое изображение на экране, браузер проходит через несколько дополнительных этапов. После построения DOM он создаёт CSSOM (CSS Object Model) — аналогичную древовидную структуру, но для стилей. CSSOM содержит информацию обо всех правилах оформления: цветах, размерах, позиционировании и прочих визуальных характеристиках.
Далее браузер объединяет DOM и CSSOM, формируя Render Tree — дерево рендеринга. Это уже не полная копия Document Object Model: в него не попадают элементы с display: none, скрипты, мета-теги и другие невидимые узлы. Render Tree содержит только то, что действительно должно отображаться на странице.
После построения дерева рендеринга запускается этап Layout (или Reflow) — браузер рассчитывает геометрию каждого элемента: где именно он должен располагаться, какого размера будет, как соотносится с соседними элементами. Это вычислительно сложная операция, особенно для страниц со тяжелой структурой.
Наконец происходит Painting — браузер фактически отрисовывает пиксели на экране: заливает фоны, рендерит текст, накладывает тени, отображает картинки. Весь этот конвейер можно представить следующим образом:
HTML → DOM CSS → CSSOM DOM + CSSOM → Render Tree → Layout → Painting → Экран
Почему это важно понимать? Потому что изменения в DOM не всегда одинаково «дороги» с точки зрения производительности. Если мы меняем цвет текста, браузер может обойтись простой перерисовкой (repaint). Но если изменяем размеры элемента или его позицию, запускается полный пересчёт layout — операция, которая может затронуть множество компонентов на странице и серьёзно замедлить работу.

Путь от кода до пикселей на экране. Обратите внимание: DOM и CSSOM объединяются, чтобы создать дерево рендеринга, и только после этого происходит компоновка и отрисовка.
Например, элемент может присутствовать в DOM, но быть скрытым через CSS. С точки зрения JavaScript он доступен, его можно найти и модифицировать, но визуально он отсутствует. Или наоборот: CSS-анимация может создавать визуальное движение без изменения DOM-дерева — сама структура остаётся неизменной, меняется только визуальное представление.
Это разделение между данными и представлением — ключевой архитектурный принцип, позволяющий браузерам эффективно обрабатывать сложные веб-приложения.
Производительность: проблемы и решения
Работа с DOM удобна и интуитивна, однако она имеет свою цену. Каждое изменение в дереве потенциально запускает пересчёт layout и перерисовку страницы — процессы, которые при частом повторении способны существенно замедлить работу веб-приложения. Особенно остро эта проблема проявляется на мобильных устройствах с ограниченными вычислительными ресурсами.
Основная причина снижения производительности заключается в том, что браузер стремится отображать актуальное состояние страницы. Добавили новый элемент? Браузер пересчитывает позиции. Изменили размер? Запускается reflow, который может затронуть родительские и соседние элементы. Изменили цвет? Требуется repaint. Если такие операции происходят в цикле, создавая десятки или сотни изменений, производительность падает катастрофически.
Минимизация перерисовок достигается группировкой изменений. Вместо множества отдельных операций лучше накопить изменения в памяти и применить их за один раз. Классический инструмент для этого — DocumentFragment, лёгковесный контейнер, который не является частью основного дерева:
const fragment = document.createDocumentFragment();
for (let i = 0; i < 100; i++) {
const item = document.createElement('li');
item.textContent = `Элемент ${i}`;
fragment.appendChild(item); // Добавляем в память, не в DOM
}
document.querySelector('ul').appendChild(fragment); // Один reflow вместо 100
Другой подход — изменение классов вместо прямой манипуляции стилями. Это позволяет браузеру оптимизировать применение CSS-правил.
Осознание этих проблем привело к появлению концепции Virtual DOM в современных фреймворках вроде React. Virtual DOM — это лёгкая копия реального Document Object Model в памяти JavaScript. Фреймворк сначала вносит все изменения в виртуальное дерево, затем сравнивает его с предыдущим состоянием и вычисляет минимальный набор операций для обновления реального DOM. Это радикально сокращает количество дорогостоящих манипуляций.
Впрочем, для большинства задач прямая работа с Document Object Model остаётся вполне приемлемой — важно лишь понимать её особенности и избегать очевидных антипаттернов.
Браузерные инструменты для работы
Теоретическое понимание DOM — это важно, но настоящее мастерство приходит через практику и эксперименты. К счастью, современные браузеры предоставляют мощные инструменты разработчика, позволяющие исследовать и модифицировать DOM в режиме реального времени.
Ключевой инструмент для работы с DOM — панель Elements (или Inspector в Firefox) в DevTools. Открыть её можно нажатием F12 или через контекстное меню «Inspect Element». Здесь перед нами предстаёт живое DOM-дерево текущей страницы — не исходный HTML-код, который прислал сервер, а именно актуальная структура после всех JavaScript-манипуляций.
Панель Elements позволяет раскрывать и сворачивать узлы дерева, исследуя вложенность элементов. При наведении на узел в инспекторе соответствующий компонент подсвечивается на странице — удобный способ понять, какой код отвечает за какую визуальную часть интерфейса.
Но самое интересное — возможность редактирования DOM прямо в браузере. Можно двойным кликом изменить текст, добавить или удалить атрибуты, переместить элементы перетаскиванием, даже удалить целые ветви дерева. Все изменения мгновенно отражаются на странице, позволяя экспериментировать без необходимости редактировать исходный код и перезагружать страницу.
Это незаменимый инструмент для отладки: можно проверить, правильно ли JavaScript создал элемент, присвоил ли нужные классы, корректно ли вставил содержимое. Особенно полезна панель при работе со сложными динамическими интерфейсами, где структура DOM формируется на лету.
Стоит помнить, что все изменения, внесённые через DevTools, временны — они исчезнут при перезагрузке страницы. Это песочница для экспериментов, а не способ редактирования сайта.
Преимущества и недостатки
Как и любая технология, DOM имеет свои сильные и слабые стороны. Понимание этих аспектов помогает принимать обоснованные архитектурные решения и выбирать правильные инструменты для конкретных задач.
Преимущества DOM:
- Интерактивность — Document Object Model превращает статичные HTML-документы в живые приложения, способные реагировать на действия пользователя в режиме реального времени. Без DOM веб был бы коллекцией неизменных страниц, требующих перезагрузки при каждом взаимодействии.
- Гибкость — структура данных в виде дерева обеспечивает универсальный доступ к любому элементу документа. Мы можем изменить что угодно и где угодно: добавить элемент в середину списка, изменить атрибут глубоко вложенного узла, переместить целые блоки страницы. Document Object Model не накладывает ограничений на характер манипуляций.
- Стандартизация — DOM является универсальным стандартом, поддерживаемым всеми современными браузерами. Код, написанный для работы с DOM, будет функционировать одинаково в Chrome, Firefox, Safari и Edge.
Недостатки DOM:
- Производительность — как мы уже обсуждали, частые манипуляции с Document Object Model могут серьёзно замедлить работу приложения. Каждое изменение потенциально запускает пересчёты и перерисовки, что особенно критично для страниц со сложной структурой и большим количеством элементов.
- Управляемость в крупных проектах — при росте масштаба приложения императивная работа с DOM становится трудноконтролируемой. Код превращается в запутанную сеть манипуляций, где сложно отследить, какая часть приложения отвечает за какие изменения на странице. Именно поэтому появились фреймворки с декларативным подходом, абстрагирующие прямую работу с Document Object Model.
Эти особенности не делают DOM плохим или хорошим инструментом — они просто определяют контекст его применения. Для небольших скриптов и средних проектов прямая работа с Document Object Model остаётся простым и эффективным решением.
Заключение
Мы прошли путь от базового понимания DOM до практических аспектов работы с ним. Давайте зафиксируем ключевые моменты, которые составляют фундамент для эффективной веб-разработки:
- DOM — это структура данных, а не визуальный интерфейс. Она представляет HTML-документ в виде иерархического дерева объектов, с которым работает JavaScript.
- Браузер автоматически строит DOM-дерево при загрузке страницы. Каждый тег, текст и атрибут становятся отдельными узлами, связанными отношениями родителя и потомка.
- Работа с DOM лежит в основе интерактивности веб-приложений. Изменение текста, структуры, стилей и реакции на действия пользователя происходит через манипуляции DOM.
- Существуют разные типы DOM-узлов, и у каждого свои возможности. Понимание различий между Element, Text, Document и другими узлами помогает писать корректный и предсказуемый код.
- Частые изменения DOM влияют на производительность. Грамотная оптимизация и понимание процессов reflow и repaint позволяют избежать замедления интерфейса.
Если вы только начинаете осваивать frontend-разработку, рекомендуем обратить внимание на подборку курсов по веб-разработке. В таких курсах обычно есть как теоретическая часть, так и практические задания, которые помогают закрепить навыки работы с интерфейсами.
Рекомендуем посмотреть курсы по веб разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Веб-разработчик
|
Eduson Academy
112 отзывов
|
Цена
119 000 ₽
|
От
9 917 ₽/мес
|
Длительность
12 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Веб-разработчик с нуля до PRO
|
Skillbox
226 отзывов
|
Цена
294 783 ₽
589 565 ₽
Ещё -20% по промокоду
|
От
8 670 ₽/мес
Без переплат на 1 год.
|
Длительность
10 месяцев
|
Старт
15 марта
|
Подробнее |
|
Веб-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
163 300 ₽
302 470 ₽
с промокодом kursy-online
|
От
5 041 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 апреля
|
Подробнее |
|
Fullstack-разработчик на python (с нуля)
|
Eduson Academy
112 отзывов
|
Цена
158 760 ₽
|
От
13 230 ₽/мес
20 642 ₽/мес
|
Длительность
7 месяцев
|
Старт
24 марта
|
Подробнее |
|
Профессия Веб-разработчик
|
Skillbox
226 отзывов
|
Цена
152 538 ₽
305 075 ₽
Ещё -20% по промокоду
|
От
4 486 ₽/мес
Без переплат на 34 месяца с отсрочкой платежа 3 месяца.
|
Длительность
24 месяца
|
Старт
15 марта
|
Подробнее |

Skypro vs ProductStar: куда идти аналитику, чтобы стать продактом — траектория и кейсы
Если вы аналитик и хотите перейти в продакт-менеджмент, но не знаете, с чего начать, эта статья для вас. Мы расскажем, какие шаги и курсы помогут вам освоить нужные навыки, чтобы успешно перейти в продуктовую роль. Задайтесь вопросом: готовы ли вы на решение проблем, а не просто на анализ данных?

Собеседование Devops Junior и Middle: актуальные вопросы и темы 2026 года
Вопросы на собеседовании DevOps могут сильно различаться в зависимости от уровня кандидата. Какие навыки и знания проверяют у Junior и Middle в 2026 году? Мы расскажем, как подготовиться к собеседованию и что важно знать для успешного прохождения интервью.

Собеседование по Python: частые вопросы и как на них отвечать
Готовитесь к техническому интервью и хотите понять, какие вопросы на собеседование Python разработчик слышит чаще всего? Разбираем реальные примеры задач, вопросы для junior, middle и senior, а также типичные ошибки кандидатов и стратегию подготовки.

Skypro vs Contented: Web/UX дизайн — где сильнее разборы работ и быстрее растёт качество
В этой статье мы расскажем, как выбрать лучший курс по веб-дизайну. Если вы только начинаете изучать эту профессию, то вам наверняка будет полезно узнать, что важно учитывать при выборе курса и какие именно аспекты обучения могут ускорить ваш профессиональный рост. Откроем основные моменты, которые помогут вам сделать правильный выбор и избежать распространенных ошибок.