Что такое ETL и зачем он нужен
В эпоху данных каждая компания сталкивается с одной и той же проблемой: информация разбросана по десяткам систем, форматов и источников. CRM хранит клиентов в одном виде, аналитические системы требуют другого, а отчеты генерируются из третьего. ETL-процессы стали тем инструментом, который превращает хаос разрозненных данных в упорядоченную систему для принятия решений.
В этом курсе мы разберем, что такое ETL, как он работает на практике и почему без него не обходится ни одна современная компания, работающая с большими объемами информации.
- Простыми словами: что такое ETL
- Когда и зачем используется ETL?
- Как работает ETL: пошаговый разбор
- Чем ETL отличается от ELT?
- Какие существуют инструменты для ETL?
- Как ETL внедряют на практике: пошаговый план
- ETL и профессия дата-инженера: какие навыки нужны?
- Альтернативы ETL: виртуализация данных, стриминг и CDC
- Заключение
- Рекомендуем посмотреть курсы по системной аналитике
Простыми словами: что такое ETL
ETL расшифровывается как Extract, Transform, Load — «извлечение, преобразование, загрузка». По сути, это процесс, который можно сравнить с работой продавца в торговом центре перед праздниками: он берет товар с полки (извлекает), заворачивает в красивую упаковку (преобразовывает) и передает покупателю в пакете (загружает).
Точно так же ETL-системы забирают данные из различных источников — будь то CRM, файлы Excel, API или базы данных — приводят их к единому формату и структуре, а затем размещают в хранилище данных для дальнейшего анализа. Главная задача ETL — решить проблему разрозненности информации и создать единую точку доступа к данным компании, где аналитики смогут строить отчеты и принимать бизнес-решения на основе полной картины, а не отдельных фрагментов.
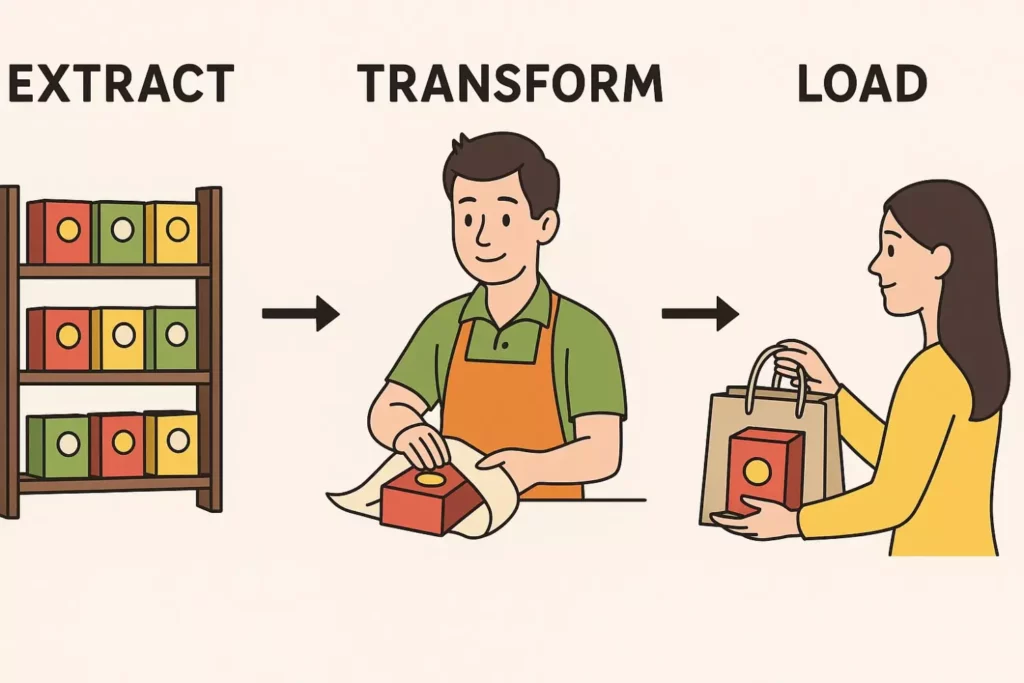
Ироничная визуализация: продавец берёт товар (Extract), упаковывает (Transform), передаёт клиенту (Load). Это помогает интуитивно понять суть ETL-процесса через бытовой образ.
Когда и зачем используется ETL?
ETL-процессы находят применение везде, где компании работают с множественными источниками данных. Рассмотрим основные сценарии использования:
Интернет-магазины и e-commerce: данные о покупателях поступают из онлайн-платформы, офлайн-магазинов, мобильного приложения и call-центра. ETL объединяет информацию о клиентах в единый профиль для персонализации предложений и анализа поведения.
Банковская сфера: транзакции, заявки на кредиты, данные анкет и история платежей хранятся в разных системах. ETL связывает эту информацию для скоринга клиентов и выявления мошеннических операций.
Игровая индустрия: поведение игроков в игре, покупки внутриигровых предметов, данные из социальных сетей — все это нужно объединить для анализа метрик удержания и монетизации.
Логистика и доставка: GPS-трекеры, системы складского учета, CRM с заказами — ETL помогает оптимизировать маршруты и прогнозировать загрузку.
Основные профессионалы, работающие с ETL: дата-инженеры (проектируют и поддерживают процессы), бизнес-аналитики (используют подготовленные данные для отчетов), BI-специалисты (строят дашборды на основе обработанной информации). ETL решает критически важные задачи: ускоряет создание отчетов, обеспечивает единое видение бизнес-процессов и избавляет аналитиков от ручного сбора данных из десятков источников.
Как работает ETL: пошаговый разбор
Extract (Извлечение данных)
Первый этап ETL начинается с подключения к источникам данных и их выгрузки в промежуточную область — так называемую staging-зону. На практике это выглядит как создание сервисных учетных записей с ограниченными правами доступа для автоматизированных процессов.
Источники данных могут быть самыми разнообразными: структурированные базы данных (PostgreSQL, MySQL, Oracle), файлы различных форматов (CSV, JSON, Excel), API внешних сервисов (CRM, маркетинговые платформы), неструктурированные данные (логи серверов, документы, изображения) и даже потоковые источники в реальном времени.
Критически важный момент — контроль объема выгружаемых данных. Если система-приемник не сможет обработать весь объем информации, процесс завершится ошибкой. Поэтому на этапе извлечения происходит первичная фильтрация: удаляются тестовые записи, очевидные дубликаты и данные, не относящиеся к анализируемому периоду. В staging-области данные сохраняются в промежуточных форматах (чаще всего JSON, Parquet или CSV), что позволяет при необходимости повторить их обработку без повторного обращения к источникам.
Transform (Преобразование данных)
Этап трансформации — сердце всего ETL-процесса, где «сырые» данные превращаются в структурированную информацию, готовую для анализа. Здесь происходят самые разнообразные операции преобразования.
Очистка данных включает удаление дубликатов, обработку пустых значений (замена на значения по умолчанию или удаление записей), исправление форматов дат и приведение текстовых полей к единому регистру. Например, если в одном источнике пол указан как «М/Ж», а в другом — «Мужской/Женский», система приводит все к единому формату.
Маппинг и нормализация решают задачу унификации структуры данных. Поле «client_id» из CRM может соответствовать полю «customer_number» из системы заказов — маппинг связывает эти поля воедино. Составные значения разделяются на отдельные поля: адрес разбивается на улицу, дом и квартиру.
Расчет новых показателей и агрегация позволяют создавать производные метрики. Из даты рождения вычисляется возраст, из истории заказов — средний чек, из логов активности — время сессии. При необходимости происходит обезличивание персональных данных — замена реальных имен на псевдонимы, хеширование контактной информации для соблюдения требований GDPR и других регулирующих норм.
Load (Загрузка данных)
Финальный этап ETL — размещение преобразованных данных в целевом хранилище. Здесь критически важно выбрать правильную стратегию загрузки в зависимости от специфики бизнес-задач.
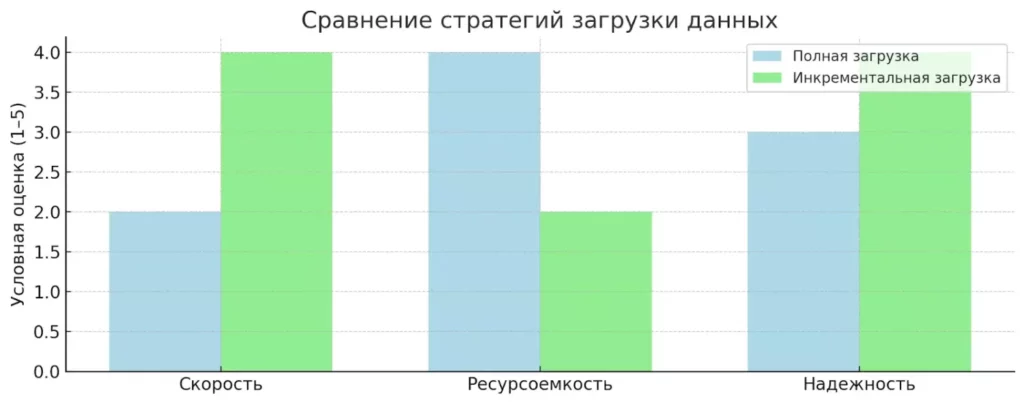
Сравнение полной и инкрементальной загрузки по ключевым метрикам: скорости, ресурсоёмкости и надёжности. Диаграмма подчёркивает преимущества инкрементального подхода при работе с большими объёмами данных.
Полная загрузка предполагает полную перезапись данных в хранилище при каждом запуске процесса. Этот подход используется для небольших объемов данных или когда требуется гарантированная консистентность информации. Недостаток очевиден — высокие временные и вычислительные затраты, особенно при работе с большими массивами данных.
Инкрементальная (добавочная) загрузка работает значительно эффективнее — система сравнивает новые данные с уже существующими и обновляет только изменившиеся записи. Для этого используются временные метки, версионирование записей или технология Change Data Capture (CDC).
На этапе загрузки происходит подключение к различным типам хранилищ: традиционным реляционным базам данных, облачным data warehouse (Snowflake, BigQuery), современным lakehouse-решениям или NoSQL-системам. Обязательный элемент — контроль качества загрузки: проверка количества загруженных записей, валидация ключевых метрик и мониторинг производительности процесса.

Эта диаграмма наглядно показывает три основных этапа процесса ETL — извлечение, преобразование и загрузка данных. Она помогает сразу понять, как организован поток обработки информации в любой ETL-системе.
Чем ETL отличается от ELT?
С развитием облачных технологий и увеличением вычислительных мощностей появился альтернативный подход — ELT (Extract, Load, Transform). Разница кажется незначительной — всего лишь перестановка букв, однако на практике это принципиально разные философии работы с данными.
| Характеристика | ETL | ELT |
|---|---|---|
| Порядок операций | Преобразование до загрузки | Загрузка «как есть», затем преобразование |
| Место обработки | Промежуточные серверы | Целевое хранилище |
| Скорость загрузки | Медленнее из-за обработки | Быстрее — сырые данные |
| Риск потери данных | Высокий при ошибках трансформации | Минимальный — все сохраняется |
| Требования к хранилищу | Меньше места, структурированные данные | Больше места, включая «мусор» |
| Стоимость хранения | Ниже | Выше из-за объема |
| Гибкость анализа | Ограничена предустановленными схемами | Высокая — можно обрабатывать по-разному |
ELT особенно популярен в эпоху больших данных и машинного обучения, где важно сохранить всю информацию без потерь для последующего анализа различными способами. ETL остается предпочтительным выбором для регулярной отчетности и бизнес-аналитики, где важна скорость получения готовых результатов.
Какие существуют инструменты для ETL?
Рынок ETL-решений предлагает широкий спектр инструментов — от корпоративных платформ до open-source проектов. Выбор зависит от бюджета, сложности задач и технической экспертизы команды.
Платные ETL-системы
IBM DataStage — флагманское решение для крупных корпораций с высокими требованиями к производительности. Особенно сильно в интеграции с существующими IBM-системами и обработке больших объемов данных в реальном времени.
Informatica PowerCenter — один из лидеров рынка, известный своим графическим интерфейсом и мощными возможностями трансформации данных. Включает готовые коннекторы к сотням источников данных и продвинутые функции качества данных.
SAP Data Services — идеальный выбор для компаний, использующих экосистему SAP. Обеспечивает глубокую интеграцию с ERP-системами и бизнес-приложениями SAP, включая специализированные инструменты для миграции данных.
Бесплатные и open-source ETL
Apache Airflow — это ведущая open-source платформа для оркестрации (управления, автоматизации и мониторинга) ETL-процессов. Сами задачи по обработке данных выполняются другими инструментами (например, скриптами на Python или заданиями Spark), а Airflow выступает в роли «дирижера», который запускает их в нужной последовательности и по расписанию.
Apache NiFi — мощный инструмент для потоковой обработки данных с графическим интерфейсом. Особенно хорош для работы с IoT-данными и системами реального времени.
Scriptella ETL — легковесное решение для простых задач интеграции, поддерживает множество источников данных и может запускаться как обычное Java-приложение.
ETL в облаке
Yandex Data Transfer — российское решение для миграции и репликации данных между различными СУБД и облачными сервисами.
VK Cloud Big Data — платформа для работы с большими данными, включающая ETL-инструменты и аналитические возможности.
AWS Glue — полностью управляемый ETL-сервис от Amazon, автоматически определяющий схему данных и генерирующий код для их преобразования.
Как ETL внедряют на практике: пошаговый план
Внедрение ETL-процессов в компании требует системного подхода и четкого понимания бизнес-задач. Представим пошаговую инструкцию, которая поможет избежать типичных ошибок.
- Анализ и постановка задачи. Определите, какие данные нужно объединить, откуда они поступают и для каких целей будут использоваться. Выясните требования к частоте обновления (ежедневно, ежечасно, в реальном времени), формату выходных данных и допустимому времени обработки.
- Инвентаризация источников данных. Составьте полный перечень систем-источников: CRM, базы данных, файловые хранилища, внешние API. Определите ответственных за каждую систему и согласуйте доступы для ETL-процессов.
- Создание сервисных учетных записей. Создайте отдельные технические аккаунты с минимально необходимыми правами для автоматизированных процессов. Это обеспечит безопасность и позволит отслеживать действия ETL-системы.
- Исследование и валидация данных. Проанализируйте качество исходных данных: выявите пропуски, дубликаты, аномалии, несоответствия форматов. Определите правила очистки и трансформации для каждого источника.
- Разработка ETL-кода. Напишите скрипты извлечения (SQL-запросы, API-вызовы), трансформации (Python, SQL, PySpark) и загрузки данных. Обязательно предусмотрите обработку ошибок и логирование процессов.
- Настройка автоматизации. Внедрите систему оркестрации (Apache Airflow, Luigi) для автоматического запуска ETL-процессов по расписанию. Настройте мониторинг, алерты при ошибках и систему уведомлений.
- Тестирование и мониторинг. Проведите тестирование на исторических данных, проверьте корректность трансформаций и производительность процессов. Настройте дашборды для отслеживания ключевых метрик: время выполнения, количество обработанных записей, частота ошибок.
ETL и профессия дата-инженера: какие навыки нужны?
ETL-процессы составляют значительную часть работы дата-инженера — специалиста, который проектирует и поддерживает инфраструктуру данных в компании. Понимание принципов ETL критически важно для успешной карьеры в этой области.
Технические навыки: SQL остается фундаментальным инструментом — без глубокого знания языка запросов невозможно эффективно извлекать и трансформировать данные. Python стал де-факто стандартом для написания ETL-скриптов благодаря богатой экосистеме библиотек (pandas, SQLAlchemy, requests). Для работы с большими данными необходимо освоить PySpark — фреймворк распределенной обработки данных.
Apache Airflow — must-have инструмент для оркестрации ETL-процессов. Знание его возможностей позволяет создавать сложные пайплайны с зависимостями, мониторингом и автоматическим восстановлением после сбоев.
Архитектурное мышление: дата-инженер должен понимать принципы проектирования хранилищ данных, различия между OLTP и OLAP системами, концепции Data Lake и Data Warehouse. Важно знать паттерны ETL-архитектур: lambda, kappa, medallion.
Обучение и развитие: начать изучение ETL можно с онлайн-курсов по дата-инженерии и SQL. Практические навыки лучше всего развивать на проектах с открытыми данными — например, анализ данных Википедии или правительственных порталов открытых данных. Полезно изучить документацию популярных ETL-инструментов и попробовать их на простых задачах.
Альтернативы ETL: виртуализация данных, стриминг и CDC
Хотя ETL остается основным подходом к интеграции данных, современные технологии предлагают альтернативные решения для специфических задач. Каждая из них решает определенные ограничения традиционного ETL.
Data Virtualization (виртуализация данных) позволяет создавать единое представление данных без физического копирования и перемещения. Системы вроде Denodo или IBM Cloud Pak создают виртуальный слой, который объединяет данные из разных источников «на лету». Это особенно полезно для задач, где требуется актуальная информация в реальном времени, но полная репликация данных избыточна.
Change Data Capture (CDC) отслеживает изменения в базах данных и передает только дельты — измененные записи. Инструменты вроде Debezium или Oracle GoldenGate позволяют практически мгновенно синхронизировать данные между системами без необходимости полной перезагрузки.
Real-time ETL и стриминговая обработка решают задачи, где данные должны обрабатываться немедленно при поступлении. Apache Kafka в связке с Apache Flink или Apache Spark Streaming позволяют обрабатывать миллионы событий в секунду — критично для финтеха, IoT или систем мониторинга.
Выбор между традиционным ETL и альтернативными подходами зависит от требований к латентности, объемов данных и архитектурных ограничений конкретной компании.
Заключение
ETL остается краеугольным камнем современной экосистемы данных, решая фундаментальную проблему интеграции разрозненной информации. Мы рассмотрели основные аспекты этой технологии:
- ETL — это извлечение, преобразование и загрузка данных. Это помогает унифицировать данные из разных источников.
- Процесс состоит из трёх этапов: extract, transform, load. Каждый требует своей настройки и контроля качества.
- Существуют десятки инструментов: от open-source решений до облачных сервисов. Выбор зависит от задач и инфраструктуры.
- ETL — альтернатива, при которой преобразование происходит уже в хранилище. Подходит для анализа больших объёмов данных.
- Помимо классического подхода, существуют виртуализация, CDC и стриминговая обработка. Они решают задачи реального времени.
Если вы только начинаете осваивать новую профессию, рекомендуем обратить внимание на подборку курсов по системной аналитике. В них собраны как теоретические основы, так и практические задания, которые помогут быстрее разобраться в процессе и начать применять знания на реальных задачах.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 апреля
|
Подробнее |
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
257 760 ₽
Ещё -12% по промокоду
|
От
4 579 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.