Что такое лог-файлы
Каждую минуту современные ИТ-системы генерируют терабайты данных о своей работе — от простых записей об обращениях пользователей до сложных трассировок выполнения микросервисов. Этот непрерывный поток информации, известный как логи, становится всё более критически важным для понимания того, что происходит в цифровой инфраструктуре компаний.

В этой статье мы разберёмся с современными подходами к работе с лог-файлами и покажем, как интеллектуальные технологии меняют привычные методы мониторинга ИТ-инфраструктуры.
- Лог-файлы: что это и зачем они нужны
- Какие бывают log-файлы
- Где хранятся и в каком виде
- Как читать и анализировать файлы вручную
- Основные проблемы при мониторинге
- Подходы к log-менеджменту и мониторингу
- Как ИИ и AIOps меняют подход к логированию
- Безопасность и ротация
- Выводы и практические рекомендации
- Заключение
- Рекомендуем посмотреть курсы по веб разработке
Лог-файлы: что это и зачем они нужны
Определение лог-файлов
В самом простом понимании лог (от английского log — «журнал») представляет собой хронологическую запись событий, происходящих в системе. Каждая такая запись содержит временную метку, указание на источник события и описание того, что именно произошло. Можно сказать, что log — это своеобразная «чёрная коробка» ИТ-системы, которая фиксирует всё происходящее внутри.
Типичная log-запись может выглядеть следующим образом: 2025-07-24 14:32:15 [INFO] User authentication successful for user_id=12345. Здесь мы видим время события, уровень важности, краткое описание и дополнительные параметры. Именно такая структурированность делает логи ценным источником информации для анализа.
Для чего нужны
Практическая ценность проявляется в нескольких ключевых областях. Во-первых, это отладка и устранение неполадок — когда система работает некорректно, log помогают понять, где именно произошёл сбой и что его вызвало. Во-вторых, логи критически важны для обеспечения информационной безопасности: они фиксируют попытки несанкционированного доступа, подозрительную активность и другие потенциальные угрозы.
Не менее важна их роль в аудите и соответствии нормативным требованиям. Многие отраслевые стандарты (например, PCI DSS для платёжных систем или GDPR для обработки персональных данных) прямо требуют ведения подробных журналов операций. Наконец, логи служат источником данных для аналитики производительности и понимания поведения пользователей.
Кто использует
Круг специалистов достаточно широк. Разработчики используют их для отладки кода и понимания того, как приложение ведёт себя в продакшене. Системные администраторы полагаются на log для мониторинга состояния серверов и сетевого оборудования. Службы технической поддержки обращаются к log для диагностики проблем пользователей, а специалисты по информационной безопасности анализируют их в поисках признаков вторжений и аномальной активности.
Какие бывают log-файлы
Системные
Записывают события операционной системы: запуск и остановку служб, ошибки драйверов, изменения в реестре. Пример: Jul 24 14:30:12 server01 systemd[1]: Started Apache HTTP Server. Эти логи критически важны для понимания общего состояния сервера.
Приложенческие
Содержат информацию о работе конкретных программ и сервисов. Разработчики настраивают их для отслеживания бизнес-логики, обработки запросов, ошибок выполнения. Типичная запись: 2025-07-24 14:32:18 [ERROR] Database connection failed: timeout after 30s.
Сетевые
Фиксируют трафик, подключения, работу маршрутизаторов и межсетевых экранов. Пример из файла доступа веб-сервера: 192.168.1.100 — — [24/Jul/2025:14:30:15 +0300] «GET /api/users HTTP/1.1» 200 1024. Особенно важны для диагностики проблем с подключением.
Безопасности
Записывают события аутентификации, авторизации, попытки доступа к защищённым ресурсам. Включают как успешные входы в систему, так и неудачные попытки, что позволяет выявлять атаки методом перебора паролей.
Баз данных
Содержат информацию о выполненных запросах, транзакциях, блокировках, ошибках целостности данных. Критически важны для оптимизации производительности СУБД и восстановления после сбоев.
Уровни важности событий
Современные системы логирования используют стандартизированную классификацию по критичности:
- INFO — обычные рабочие событи.
- WARNING — потенциальные проблемы, требующие внимания.
- ERROR — ошибки, влияющие на функциональность.
- FATAL — критические сбои, приводящие к остановке системы.
Наряду с этими уровнями, часто используются DEBUG для детальной отладочной информации и TRACE для максимально подробного отслеживания выполнения кода.
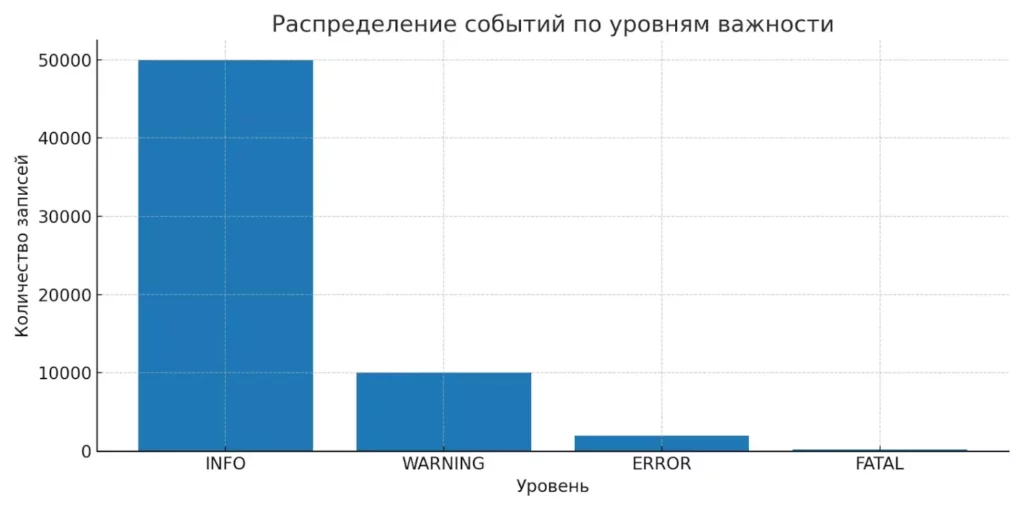
Гистограмма показывает, что основная масса записей приходится на события уровня INFO. Это визуально подчёркивает проблему информационного шума при логировании.
Правильная настройка уровней позволяет фильтровать информационный шум и концентрироваться на действительно важных событиях.
Где хранятся и в каком виде
Пути хранения
В Unix-подобных системах логи традиционно размещаются в директории /var/log/. Здесь можно найти системные журналы (/var/log/syslog), логи веб-сервера (/var/log/apache2/access.log), записи аутентификации (/var/log/auth.log). Windows использует иной подход: системные события попадают в журналы событий Windows (Event Logs), доступные через оснастку «Просмотр событий», а также могут храниться в текстовых файлах в папке C:\Windows\System32\LogFiles\.
Контейнерные решения добавляют свою специфику. Docker по умолчанию собирает log контейнеров в /var/lib/docker/containers/, а Kubernetes предоставляет команду kubectl logs для доступа к логам подов. Облачные платформы (AWS CloudWatch, Azure Monitor, Google Cloud Logging) предлагают централизованное хранение с возможностью долгосрочного архивирования.
Форматы
Текстовые остаются наиболее распространённым форматом благодаря простоте чтения и обработки стандартными утилитами. JSON-формат набирает популярность в микросервисных архитектурах, поскольку позволяет легко структурировать сложные данные: {«timestamp»: «2025-07-24T14:30:15Z», «level»: «ERROR», «service»: «user-auth», «message»: «Invalid token»}. Бинарные используются высоконагруженными системами для экономии места и скорости записи, но требуют специальных инструментов для чтения.
Пример log-записи
Рассмотрим типичную строку из access.log веб-сервера Apache:
192.168.1.100 — admin [24/Jul/2025:14:30:15 +0300] «GET /api/users?page=2 HTTP/1.1» 200 2048 «https://example.com/dashboard» «Mozilla/5.0…»
| Поле | Значение | Описание |
|---|---|---|
| IP-адрес | 192.168.1.100 | Адрес клиента |
| Пользователь | admin | Имя аутентифицированного пользователя |
| Время | 24/Jul/2025:14:30:15 +0300 | Временная метка с часовым поясом |
| Запрос | GET /api/users?page=2 | HTTP-метод и URL |
| Статус | 200 | Код ответа сервера |
| Размер | 2048 | Размер ответа в байтах |
Такая структуризация позволяет автоматически анализировать паттерны обращений, выявлять ошибки и оптимизировать производительность системы.
Как читать и анализировать файлы вручную
Инструменты чтения (базовые)
Для работы с log на Unix-системах традиционно используются консольные утилиты. less и more позволяют просматривать большие файлы постранично: less /var/log/syslog. tail показывает последние строки файла и может отслеживать новые записи в реальном времени: tail -f /var/log/apache2/access.log. grep — мощный инструмент поиска по шаблонам: grep «ERROR» /var/log/application.log найдёт все строки с ошибками.
В Windows-окружении популярны графические редакторы вроде Notepad++, который может работать с большими файлами и подсвечивать синтаксис. Для более серьёзного анализа используются специализированные инструменты типа Log Parser от Microsoft или LogExpert с возможностями фильтрации и поиска по регулярным выражениям.
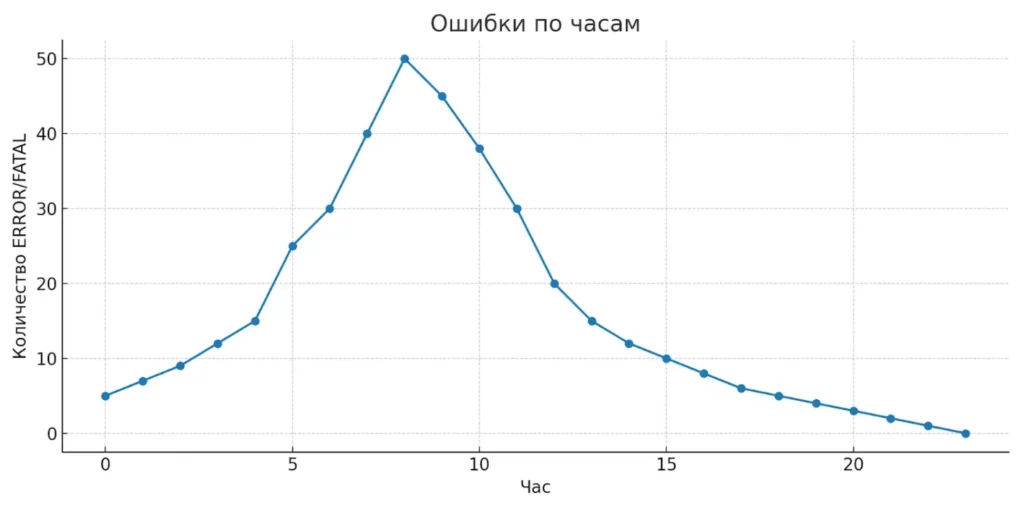
Линейный график отражает пики ошибок в течение дня. Это полезно для оперативного выявления проблемных интервалов и настройки фильтров.
Поиск нужной информации
Эффективная работа с логами требует понимания ключевых паттернов поиска. Фильтрация по времени позволяет сосредоточиться на конкретном периоде: grep «2025-07-24 14:» /var/log/app.log покажет события за 14-й час. Поиск по уровню ошибок помогает быстро выявить проблемы: grep -E «(ERROR|FATAL)» logfile.txt.
Комбинирование команд через пайпы открывает широкие возможности: grep «404» access.log | awk ‘{print $1}’ | sort | uniq -c | sort -nr покажет IP-адреса, генерирующие больше всего ошибок 404. Использование регулярных выражений позволяет находить сложные паттерны: grep -E «failed login.*user=\w+» auth.log найдёт неудачные попытки входа с указанием пользователя.
Таблица как способ визуализации
Структурирование log-данных в табличном виде значительно упрощает анализ. Например, события аутентификации можно представить следующим образом:
| Время | IP-адрес | Пользователь | Статус | Действие |
|---|---|---|---|---|
| 14:30:15 | 192.168.1.100 | admin | SUCCESS | login |
| 14:31:22 | 10.0.0.50 | guest | FAILED | login |
| 14:32:01 | 192.168.1.100 | admin | SUCCESS | logout |
Такое представление позволяет быстро выявить подозрительную активность, частоту обращений конкретных пользователей и временные паттерны нагрузки. Для автоматического создания подобных таблиц можно использовать awk: awk ‘{print $1, $2, $3, $4}’ auth.log | column -t создаст выровненные колонки из первых четырёх полей лога.
Основные проблемы при мониторинге
При всей важности log для поддержания работоспособности ИТ-систем, их эффективное использование сопряжено с рядом серьёзных вызовов, которые становятся всё более острыми по мере роста сложности инфраструктуры.
Избыточность и информационный шум — пожалуй, самая распространённая проблема современных систем логирования. Высоконагруженные приложения могут генерировать миллионы записей в день, большинство из которых представляют собой рутинные события типа «запрос обработан успешно». В этом море информации критически важные сигналы об ошибках легко теряются. Попытки снизить уровень детализации логирования чреваты упущением важных данных — классическая дилемма между полнотой и управляемостью.
Распределённость современных систем кардинально усложняет задачу мониторинга. Если раньше веб-приложение работало на одном сервере, то сегодня типичный сервис может состоять из десятков микросервисов, развёрнутых в контейнерах на разных хостах. Отследить путь одного пользовательского запроса через такую архитектуру, опираясь только на разрозненные log-файлы, становится чрезвычайно сложной задачей.
Скорость генерации данных в высоконагруженных системах может достигать сотен тысяч записей в секунду. Традиционные методы анализа логов — от ручного просмотра до простых скриптов — просто не справляются с такими объёмами. Время, необходимое для поиска причины инцидента, может растянуться на часы, что неприемлемо для критически важных систем.
Сложность корреляции событий проявляется особенно остро при расследовании инцидентов. Одна проблема может проявляться в логах нескольких компонентов с разной временной задержкой и в разных форматах. Связать эти разрозненные события в единую причинно-следственную цепочку вручную крайне затруднительно, особенно когда счёт идёт на минуты.
Подходы к log-менеджменту и мониторингу
Централизация и агрегация log
Решением проблемы распределённости стала централизация — сбор всех логов в едином хранилище для последующего анализа. Наиболее популярным решением остаётся ELK Stack (Elasticsearch, Logstash, Kibana), где Logstash собирает и обрабатывает данные, Elasticsearch индексирует их для быстрого поиска, а Kibana предоставляет интерфейс визуализации. Альтернативой выступает Grafana Loki — более лёгкое решение, оптимизированное для работы с контейнерными средами.
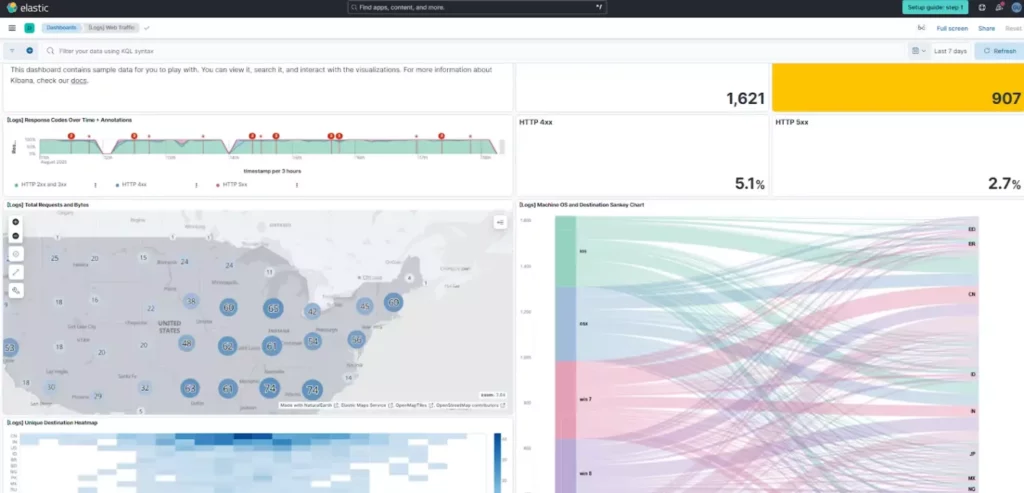
Скриншот интерфейса Kibana с примером дашборда логов. Скриншот наглядно показывает, как централизованные системы визуализируют логи: графики ошибок, фильтры, временные диапазоны. Это помогает читателю понять, зачем нужна Kibana/Grafana и как они выглядят.
Fluentd и его облегчённая версия Fluent Bit решают задачу унификации сбора данных из различных источников. Эти инструменты могут работать как с традиционными log-файлами, так и со специфичными форматами баз данных, веб-серверов и приложений, приводя всё к единому структурированному виду.
Корреляция с метриками и трассировками
Современный подход к наблюдаемости (observability) предполагает объединение трёх типов данных: логов, метрик и трассировок. Метрики показывают количественные показатели (CPU, память, количество запросов), трассировки отслеживают путь запроса через распределённую систему, а логи предоставляют детальный контекст происходящего.
Такая интеграция позволяет, например, заметив аномальный рост времени ответа в метриках, быстро перейти к соответствующим логам и трассировкам для понимания первопричины. Инструменты вроде Jaeger для трассировки и Prometheus для метрик всё чаще интегрируются с системами управления логами.
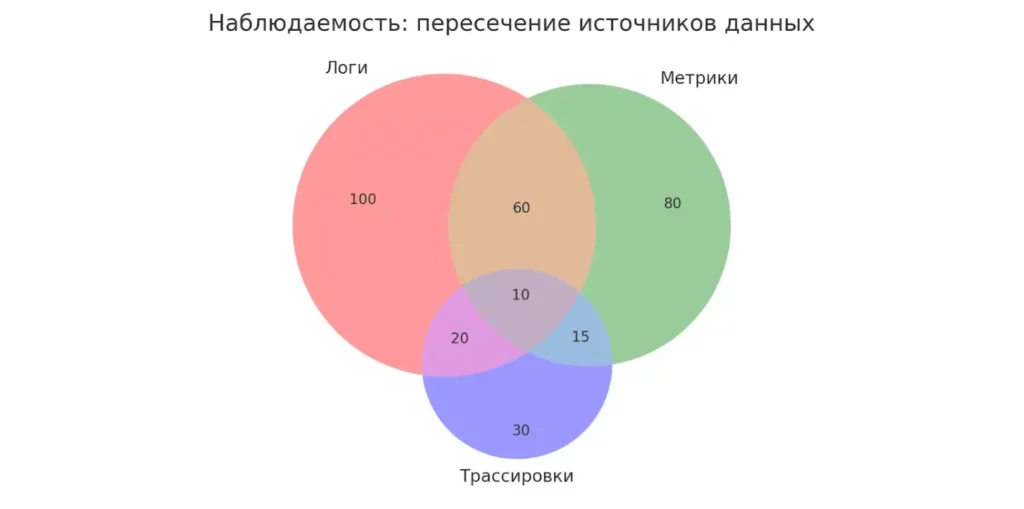
Диаграмма Венна наглядно показывает, как пересекаются логи, метрики и трассировки. Такой подход позволяет увидеть общую картину происходящего в системе.
Примеры архитектуры log-менеджмента
Типичная современная архитектура выглядит следующим образом:
Источники → Агрегаторы → Обработка → Хранилище → Визуализация
На уровне источников логи генерируются приложениями, операционными системами, сетевым оборудованием. Агрегаторы (Filebeat, Fluent Bit) собирают данные и передают их для обработки. На этапе обработки происходит парсинг, нормализация, обогащение данных дополнительными метаданными. Хранилище (Elasticsearch, ClickHouse) обеспечивает быстрый поиск и долгосрочное архивирование. Визуализация (Kibana, Grafana) предоставляет дашборды и инструменты анализа.
Ключевое преимущество такой архитектуры — возможность масштабирования каждого компонента независимо и замены отдельных элементов без перестройки всей системы.
Как ИИ и AIOps меняют подход к логированию
Что такое AIOps в log-менеджменте
AIOps (Artificial Intelligence for IT Operations) представляет собой применение технологий машинного обучения и искусственного интеллекта для автоматизации ИТ-операций. В контексте работы с логами это означает переход от реактивного подхода — когда проблемы выявляются после их возникновения — к проактивному, где системы самостоятельно обнаруживают аномалии и предсказывают потенциальные сбои.
Практические примеры применения включают автоматическую классификацию инцидентов по степени критичности, выявление повторяющихся паттернов ошибок, корреляцию событий из различных источников для построения причинно-следственных связей. Например, AIOps-система может автоматически связать рост времени отклика базы данных с увеличением количества медленных запросов в log приложения и предупредить о потенциальной проблеме до того, как она повлияет на пользователей.
Преимущества автоматизации
Традиционные пороговые алерты часто страдают от высокого уровня ложных срабатываний — система может генерировать сотни уведомлений о «проблемах», большинство из которых оказываются ложными тревогами. Детектирование аномалий на основе машинного обучения позволяет системе понимать нормальное поведение инфраструктуры и выявлять действительно подозрительные отклонения.
Автоматическая корреляция событий решает проблему связывания разрозненных записей в единую картину инцидента. Алгоритмы могут обнаружить, что ошибка в одном микросервисе предшествует сбою в другом с определённой временной задержкой, и автоматически группировать такие события. Это кардинально сокращает время на локализацию проблем — с часов до минут.
Предиктивная аналитика позволяет выявлять проблемы на ранних стадиях. Система может заметить, что определённый паттерн в логах исторически предшествовал серьёзным сбоям, и заблаговременно предупредить операционную команду.
Рынок и тренды
Стремительный рост рынка AIOps отражает острую потребность индустрии в интеллектуальных решениях. По данным Mordor Intelligence, рынок оценивался в $2,62 млрд в 2023 году и прогнозируется его рост до $5,46 млрд к 2029 году со среднегодовым темпом роста около 13%. Драйверами роста выступают массовый переход к облачным архитектурам, внедрение контейнеризации и микросервисов, а также растущая сложность ИТ-инфраструктур.
Ведущие облачные провайдеры активно развивают собственные AIOps-решения: AWS предлагает CloudWatch Insights с возможностями машинного обучения, Microsoft интегрирует ИИ в Azure Monitor, Google Cloud внедряет интеллектуальную аналитику в Cloud Logging. Параллельно развиваются независимые платформы вроде Splunk, Datadog, которые делают ставку на продвинутую аналитику и автоматизацию.
Интересный тренд — демократизация AIOps-технологий. Если раньше подобные решения были доступны только крупным корпорациям, то сегодня облачные сервисы делают интеллектуальный анализ логов доступным для средних и даже небольших компаний.
Безопасность и ротация
Управление логами требует не только технических навыков, но и понимания принципов информационной безопасности и рационального использования ресурсов.
Контроль доступа — первоочередная задача при работе с log. Журналы часто содержат конфиденциальную информацию: IP-адреса пользователей, фрагменты запросов с параметрами, иногда даже пароли, случайно попавшие в URL. Доступ к логам должен предоставляться по принципу минимальных привилегий — каждый сотрудник видит только те данные, которые необходимы для выполнения его обязанностей. Разработчики получают доступ к логам своих приложений, системные администраторы — к системным журналам, специалисты по безопасности — к логам аудита.
Сроки хранения данных определяются балансом между требованиями бизнеса, нормативными актами и стоимостью хранения. Многие отраслевые стандарты предписывают хранить логи аудита не менее года, но высокодетализированные логи приложений редко имеют ценность спустя несколько недель. Типичная стратегия предполагает хранение «горячих» данных (с быстрым доступом) в течение 30-90 дней, после чего они архивируются в более дешёвые хранилища.
Процедуры удаления и архивирования должны быть автоматизированы во избежание переполнения дисков. Ротация логов — это не просто удаление старых файлов, а сложный процесс, включающий сжатие, перенос в архивные хранилища, обновление индексов поиска. Утилиты вроде logrotate в Linux позволяют настроить гибкие правила ротации с учётом размера файлов, их возраста и доступного дискового пространства.
Шифрование и защита от несанкционированного доступа становятся критически важными при работе с чувствительными данными. Логи должны шифроваться как при передаче (TLS для сетевых соединений), так и при хранении. Современные системы управления логами поддерживают интеграцию с системами управления ключами (KMS), обеспечивая автоматическое шифрование без участия администраторов.
Немаловажный аспект — защита от модификации. Логи должны быть неизменяемыми после записи, что достигается использованием специальных файловых систем или блокчейн-подобных механизмов контроля целостности. Это особенно важно для соответствия требованиям аудита и расследования инцидентов безопасности.
Выводы и практические рекомендации
Мониторинг log-файлов превратился из простой задачи «посмотреть, что пишет сервер» в сложную дисциплину, требующую системного подхода и современных инструментов. Подводя итоги нашего обзора, сформулируем практические рекомендации для разных этапов зрелости ИТ-инфраструктуры.
Определите свои потребности в логировании.
Начните с аудита существующих источников данных — какие системы генерируют log, в каких форматах, с какой интенсивностью. Не пытайтесь сразу собирать всё подряд: сосредоточьтесь на критически важных компонентах и постепенно расширяйте охват. Для большинства организаций приоритетными будут логи безопасности, основных бизнес-приложений и сетевой инфраструктуры.
Начните с базовой централизации.
Даже простое решение на основе ELK Stack или Grafana Loki кардинально упростит работу по сравнению с просмотром десятков разрозненных файлов. Настройте автоматический сбор log с ключевых серверов, создайте базовые дашборды для мониторинга основных метрик — количества ошибок, времени отклика, активности пользователей.
Стандартизируйте форматы и практики.
Договоритесь о едином подходе к структуре log-записей в разработке, внедрите correlation ID для отслеживания запросов в распределённых системах, определите единые уровни логирования. Это существенно упростит последующий анализ и автоматизацию.
Рассмотрите переход на AIOps-решения когда традиционные методы перестают справляться с нагрузкой. Характерные признаки: время поиска причин инцидентов превышает несколько часов, количество ложных алертов мешает работе команды, объём данных требует значительных ресурсов для обработки. Современные платформы с поддержкой машинного обучения могут окупиться уже через несколько месяцев за счёт сокращения времени восстановления сервисов.
Не забывайте о безопасности и compliance.
Регулярно пересматривайте права доступа к log, настройте автоматическую ротацию и архивирование, убедитесь в соответствии отраслевым требованиям. Логи — это не только инструмент диагностики, но и потенциальный источник утечки конфиденциальной информации.
Заключение
Помните: идеальной системы мониторинга не существует. Главное — начать с простого решения и постепенно развивать его по мере роста потребностей организации. В мире, где цифровые сервисы становятся основой бизнеса, качественный мониторинг логов — это не техническое излишество, а конкурентное преимущество. Подведем итоги:
- Лог-файлы фиксируют все события в ИТ-системе. Это позволяет отслеживать работу компонентов, поведение пользователей и возникновение ошибок.
- Существует несколько типов логов. Ключевые из них — системные, приложенческие, сетевые, логи безопасности и баз данных.
- Ручной анализ логов возможен с помощью базовых инструментов. Утилиты вроде grep, tail, awk позволяют фильтровать и искать нужную информацию.
- Централизация логов упрощает мониторинг. Стек ELK и Grafana Loki позволяют собирать, визуализировать и анализировать логи в едином интерфейсе.
- Интеграция логов с метриками и трассировками усиливает наблюдаемость. Такой подход помогает быстрее локализовать и устранить сбои.
- ИИ и AIOps позволяют предсказывать инциденты. Они анализируют паттерны в логах и выявляют аномалии ещё до появления сбоев.
- Безопасность логов критически важна. Необходимо ограничивать доступ, шифровать данные, автоматизировать ротацию и обеспечивать неизменность логов.
- Лог-файлы — это не только технический инструмент. Они помогают соблюдать нормативные требования и могут использоваться как юридические доказательства.
Если вы только начинаете осваивать профессию разработчика, рекомендуем обратить внимание на подборку курсов по веб-разработке. В них вы найдёте как теоретические основы, так и практические задания с реальными логами и инструментами.
Рекомендуем посмотреть курсы по веб разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Веб-разработчик
|
Eduson Academy
114 отзывов
|
Цена
119 000 ₽
|
От
9 917 ₽/мес
|
Длительность
12 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Веб-разработчик с нуля до PRO
|
Skillbox
232 отзыва
|
Цена
294 783 ₽
589 565 ₽
Ещё -20% по промокоду
|
От
8 670 ₽/мес
Без переплат на 1 год.
|
Длительность
10 месяцев
|
Старт
23 марта
|
Подробнее |
|
Веб-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
163 300 ₽
302 470 ₽
с промокодом kursy-online
|
От
5 041 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 апреля
|
Подробнее |
|
Fullstack-разработчик на python (с нуля)
|
Eduson Academy
114 отзывов
|
Цена
158 760 ₽
|
От
13 230 ₽/мес
20 642 ₽/мес
|
Длительность
7 месяцев
|
Старт
24 марта
|
Подробнее |
|
Профессия Веб-разработчик
|
Skillbox
232 отзыва
|
Цена
152 538 ₽
305 075 ₽
Ещё -20% по промокоду
|
От
4 486 ₽/мес
Без переплат на 34 месяца с отсрочкой платежа 3 месяца.
|
Длительность
24 месяца
|
Старт
23 марта
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.