Что такое логгер в программировании и технике: полное объяснение простыми словами
Логгер — это инструмент, который фиксирует события и состояния системы в реальном времени. В программировании он представляет собой специальный модуль или библиотеку, записывающую информацию о работе приложения: от запуска функций до критических ошибок. В технической сфере таким инструментом называют также физические устройства, собирающие данные о температуре, влажности, давлении или местоположении объектов.

Несмотря на различия в реализации, суть остаётся неизменной: создаётся хронология событий, которая позволяет понять, что происходило с инфраструктурой в конкретный момент времени. Эти записи — логи — становятся незаменимым инструментом для диагностики проблем, анализа производительности и обеспечения безопасности.
- Зачем нужен логгер и какую задачу он решает
- Как работает логгер: принцип действия
- Виды логгеров: программные и аппаратные
- Уровни логирования: зачем их использовать
- Примеры использования логгеров в реальных задачах
- Как подключить и использовать логгер: шаг за шагом
- Преимущества логирования: зачем оно нужно бизнесу и разработчикам
- Как выбрать логгер: чек-лист
- Рекомендации по эффективному внедрению логгирования
- Заключение
- Рекомендуем посмотреть курсы по веб разработке
Зачем нужен логгер и какую задачу он решает
Логирование решает фундаментальную проблему любой сложной системы — потребность в прозрачности процессов. Когда приложение работает на продакшене или устройство функционирует в автономном режиме, мы не можем наблюдать за каждым его действием в реальном времени. Данный инструмент становится нашими глазами и ушами, фиксируя всё происходящее внутри.

Пример реального лога из официальной документации Python
Первая и наиболее очевидная задача — диагностика проблем. Когда приложение падает с ошибкой или устройство работает некорректно, логи позволяют восстановить последовательность событий, приведших к сбою. Вместо того чтобы гадать, что пошло не так, разработчик или инженер открывает лог-файл и видит точный момент возникновения проблемы, включая параметры, с которыми она произошла.
Вторая ключевая функция — контроль и мониторинг. Логи помогают отслеживать нагрузку на инфраструктуру, частоту обращений к определённым модулям, время отклика сервисов. Это особенно важно для высоконагруженных приложений, где даже небольшая задержка может привести к каскадному отказу.
Не менее важна роль в обеспечении безопасности. Записи о попытках подключения, изменениях конфигурации, доступе к критическим данным позволяют обнаружить подозрительную активность и провести расследование инцидентов. В корпоративных системах логи становятся основой для аудита и соответствия требованиям регуляторов.
Наконец, логирование служит инструментом сбора аналитических данных. Информация о поведении юзеров, частоте использования функций, показателях производительности — всё это помогает принимать обоснованные решения о развитии продукта.
Основные функции логгера
Данный инструмент выполняет несколько ключевых функций, каждая из которых критична для эффективной работы инфраструктуры:
- Запись событий — фиксация всех значимых действий: запуск и остановка сервисов, выполнение функций, обращения к базе данных, действия пользователей. Каждое событие сохраняется с временной меткой, что позволяет восстановить полную картину происходящего.
- Фиксация ошибок — автоматическая регистрация исключений, сбоев и нештатных ситуаций. Система захватывает не только сам факт ошибки, но и её контекст: стек вызовов, значения переменных, состояние в момент возникновения проблемы. Это существенно ускоряет процесс поиска и устранения багов.
- Диагностика — анализ работы отдельных компонентов. Механизм помогает выявить узкие места, замедляющие работу приложения, обнаружить утечки памяти, отследить неоптимальные запросы к базе данных. Без логирования такая диагностика превращается в слепой поиск.
- Мониторинг процессов — непрерывное отслеживание состояния системы и её компонентов. Логи позволяют настроить оповещения о критических событиях, контролировать доступность сервисов, отслеживать метрики производительности. В связке с системами мониторинга инструмент превращается в мощный механизм предотвращения проблем, а не только их решения.
Когда логирование критически необходимо
Существуют сферы и сценарии, где отсутствие логирования может привести к катастрофическим последствиям. Давайте рассмотрим ключевые области, где оно становится не просто полезным инструментом, а абсолютной необходимостью.
- Высоконагруженные инфраструктуры — когда приложение обрабатывает тысячи запросов в секунду, отследить проблему без логов практически невозможно. Интернет-магазины, финансовые платформы, социальные сети — все они полагаются на детальную фиксацию для выявления bottleneck’ов и предотвращения простоев. Здесь логи помогают понять, какой именно микросервис замедляет всю цепочку обработки запроса.
- Системы безопасности и аудита — в банковском секторе, здравоохранении, государственных информационных инфраструктурах логирование является обязательным требованием. Каждое действие пользователя, каждое изменение данных должно быть зафиксировано. Это не только вопрос безопасности, но и соответствия регуляторным требованиям вроде GDPR или ФЗ-152.
- IoT и встроенные системы — датчики, контроллеры, «умные» устройства часто работают автономно в труднодоступных местах. Механизм фиксации становится единственным способом узнать, что происходило с устройством между сеансами обслуживания.
- Промышленное производство — на заводах и фабриках специальные устройства фиксируют параметры технологических процессов: температуру, давление, скорость конвейера. Эти данные критичны для контроля качества и расследования инцидентов.
- Отладка сложного ПО — чем сложнее архитектура приложения, тем важнее понимать взаимодействие между его компонентами. Без логирования отладка распределённых инфраструктур превращается в гадание на кофейной гуще.
Как работает логгер: принцип действия
На первый взгляд механика кажется простой: программа записывает информацию в файл. Однако за этой простотой скрывается продуманная архитектура, которая делает инструмент эффективным, а не просто бесконечным потоком текста.
Система функционирует как посредник между приложением и хранилищем данных. Разработчик явно указывает в коде, какие события должны быть зафиксированы. Например, при подключении пользователя появляется команда вроде logger.info(‘Пользователь {username} подключился с IP {address}’). Модуль перехватывает эту команду, обрабатывает её и направляет результат в заранее определённое место хранения.
Важно понимать: работа не происходит сама по себе. Активация происходит только тогда, когда программист явно вызывает соответствующие методы. Это принципиально отличает логирование от автоматического мониторинга — мы сами решаем, что именно заслуживает внимания.
Современные решения поддерживают гибкую настройку: можно определить формат записей, выбрать уровень детализации, настроить фильтрацию по важности событий. Некоторые умеют автоматически ротировать файлы — например, создавать новый файл каждый день или при достижении определённого размера. Это предотвращает ситуацию, когда один лог-файл разрастается до нескольких гигабайт.
В распределённых инфраструктурах инструменты работают в связке: каждый микросервис пишет свои логи, а специализированные средства агрегируют их в единое хранилище. Это позволяет отследить путь запроса через всю инфраструктуру — от момента обращения пользователя до получения ответа от базы данных.
Стоит отметить, что производительность тоже имеет значение. Запись в файл — операция относительно медленная, поэтому часто используют буферизацию: накапливают несколько записей в памяти и записывают их одним блоком. Это снижает нагрузку на систему ввода-вывода.
Этапы работы логгера
Процесс представляет собой последовательность чётко определённых этапов, каждый из которых выполняет свою роль в формировании итоговой записи:
- Сбор данных — система получает информацию о событии в момент его возникновения. Это может быть вызов функции, появление ошибки, обращение к API или действие пользователя. На этом этапе фиксируются все релевантные параметры: временная метка, уровень важности события, текст сообщения, контекстные данные (идентификаторы пользователей, IP-адреса, значения переменных).
- Обработка информации — собранные данные преобразуются в определённый формат. Модуль может добавить дополнительные метаданные (имя модуля, номер строки кода, идентификатор потока), применить форматирование (например, структурировать вывод в JSON), выполнить фильтрацию согласно настроенным правилам. На этом же этапе происходит проверка уровня — если событие имеет низкий приоритет, а система настроена только на критические ошибки, запись может быть отброшена.
- Хранение данных — обработанная информация направляется в хранилище. Это может быть локальный текстовый файл, база данных, удалённый сервер или сразу несколько назначений одновременно. Современные решения поддерживают множественные обработчики (handlers), позволяя, например, отправлять обычные события в файл, а критические ошибки — одновременно в файл, базу данных и инфраструктуру оповещения администраторов.
- Анализ данных — финальный этап, который часто выходит за рамки работы самого инструмента. Накопленные логи анализируются для выявления закономерностей, поиска аномалий, построения отчётов. Для этого используются специализированные инструменты: grep для поиска по текстовым файлам, системы вроде ELK Stack (Elasticsearch, Logstash, Kibana) для визуализации и анализа больших объёмов данных, или собственные скрипты для извлечения специфичной информации.
Места хранения логов
Выбор места хранения существенно влияет на возможности их анализа, скорость доступа и общую надёжность инфраструктуры. Рассмотрим основные варианты и их особенности.
| Тип хранилища | Плюсы | Минусы |
|---|---|---|
| Текстовые файлы | Простота реализации и настройки; не требуют дополнительной инфраструктуры; легко читаются человеком; минимальные системные требования; работают на любой платформе | Медленный поиск по большим объёмам; сложность централизованного сбора с нескольких серверов; отсутствие структурированности данных; риск потери при сбое диска; необходимость ручной ротации |
| Базы данных | Быстрый поиск и фильтрация; структурированное хранение; возможность сложных запросов; централизация логов из множества источников; встроенные механизмы резервного копирования | Повышенная нагрузка на СУБД; необходимость администрирования базы; дополнительные расходы на инфраструктуру; может стать bottleneck при высокой интенсивности логирования |
| Облачные системы логирования | Масштабируемость без дополнительных усилий; встроенные инструменты анализа и визуализации; автоматическое резервное копирование; доступ из любой точки; интеграция с системами мониторинга | Зависимость от интернет-соединения; ежемесячные расходы; ограничения на объём данных в базовых тарифах; вопросы конфиденциальности для критичных данных; возможная задержка при передаче |
Выбор конкретного варианта зависит от масштаба проекта и требований. Для небольших приложений достаточно текстовых файлов, для корпоративных решений чаще используются базы данных или гибридные подходы, а современные облачные стартапы отдают предпочтение специализированным SaaS-решениям вроде Datadog, Splunk или CloudWatch.
Централизованные системы агрегации, такие как Kibana, превращают потоки текстовых данных в наглядные дашборды. Это позволяет быстро фильтровать события, строить графики активности и находить аномалии.
Централизованные системы агрегации, такие как Kibana, превращают потоки текстовых данных в наглядные дашборды. Это позволяет быстро фильтровать события, строить графики активности и находить аномалии.
Виды логгеров: программные и аппаратные
Термин «логгер» охватывает два принципиально разных класса инструментов, объединённых общей целью — фиксацией данных о состоянии системы. С одной стороны, мы имеем дело с программными решениями, встроенными в код приложений. С другой — с физическими устройствами, собирающими информацию об окружающей среде или технических процессах. Несмотря на очевидные различия в реализации, логика их работы остаётся схожей: непрерывная регистрация событий с возможностью последующего анализа.
Для IT-специалистов программные решения становятся повседневным инструментом, в то время как аппаратные варианты чаще встречаются в промышленности, логистике и инженерных инфраструктурах. Однако граница между этими мирами постепенно размывается: IoT-устройства объединяют физические датчики с программными компонентами, создавая гибридные системы.
Давайте рассмотрим каждый тип детальнее, чтобы понять их специфику и области применения.
Программные логгеры (основной фокус для IT)
Программные решения представляют собой библиотеки или модули, интегрируемые в код приложения. Их задача — предоставить разработчику удобный API для записи событий без необходимости вручную работать с файлами или другими системами хранения.
Ключевые особенности:
- Уровни детализации — возможность разделять события по важности (debug, info, warning, error), что упрощает фильтрацию при анализе.
- Форматирование вывода — автоматическое добавление временных меток, имён модулей, идентификаторов потоков выполнения.
- Множественные обработчики — одновременная отправка логов в файл, консоль, базу данных или внешний сервис.
- Ротация файлов — автоматическое создание новых лог-файлов при достижении размера или по расписанию.
- Асинхронность — возможность неблокирующей записи, критичная для высоконагруженных систем.
Примеры программных решений:
- JavaScript (Node.js) — Winston, Bunyan, Pino. Простейший встроенный вариант — console.log(), хотя для продакшена используются более продвинутые решения с поддержкой структурированных логов в JSON-формате.
- Python — встроенный модуль logging, предоставляющий полный набор функций для большинства задач. Альтернативы: Loguru (упрощённый синтаксис), structlog (структурированное логирование).
- Java — Log4j, SLF4J, Logback. Отличаются гибкими настройками и enterprise-ориентированностью.
- Go — zap, logrus. Оптимизированы для высокой производительности.
- PHP — Monolog, интегрируется с популярными фреймворками вроде Laravel и Symfony.
Каждое из этих решений адаптировано под особенности языка и экосистемы, но базовые принципы остаются неизменными.
Аппаратные логгеры (физические устройства)
Аппаратные устройства — это автономные электронные приборы, оснащённые датчиками и памятью для записи физических параметров окружающей среды. В отличие от программных решений, они существуют как самостоятельные гаджеты, способные работать без постоянного подключения к компьютеру или сети.

Аппаратные логгеры — это компактные автономные устройства, фиксирующие параметры окружающей среды. На иллюстрации показан логгер с датчиком температуры и USB-интерфейсом, используемый для контроля холодовой цепи.
Основные типы по специализации:
- Температурные — фиксируют изменения температуры с заданной периодичностью. Используются при транспортировке лекарств, продуктов питания, в медицинских холодильниках. Диапазон измерений обычно от -40°C до +85°C, память позволяет хранить от нескольких тысяч до миллионов замеров.
- Геолокационные (GPS-трекеры) — записывают координаты объекта и траекторию его перемещения. Применяются в логистике для отслеживания грузов, в автопарках для контроля транспорта, в научных исследованиях для изучения миграции животных. Современные модели дополнительно фиксируют скорость, высоту, время стоянок.
- Датчики влажности — измеряют относительную влажность воздуха, критичны для хранения электроники, музейных экспонатов, архивных документов. Часто комбинируются с температурными датчиками, поскольку эти параметры взаимосвязаны.
- Многофункциональные — объединяют несколько типов датчиков в одном корпусе. Могут одновременно фиксировать температуру, влажность, освещённость, атмосферное давление, вибрацию, удары. Такие устройства востребованы в промышленности и научных экспериментах.
Применение аппаратных устройств по отраслям:
| Отрасль | Тип логгера | Задача |
|---|---|---|
| Фармацевтика | Температурные | Контроль условий хранения и транспортировки вакцин, инсулина, биоматериалов |
| Пищевая промышленность | Температурные, влажности | Соблюдение холодовой цепи при доставке скоропортящихся продуктов |
| Логистика | GPS-логгеры | Отслеживание маршрутов грузов, контроль времени доставки, защита от кражи |
| Серверные помещения | Температурные, влажности | Мониторинг микроклимата для предотвращения перегрева оборудования |
| Музеи и архивы | Влажности, температурные | Обеспечение оптимальных условий хранения экспонатов и документов |
| Сельское хозяйство | Многофункциональные | Контроль условий в теплицах, зернохранилищах, животноводческих комплексах |
| «Умный дом» | Многофункциональные | Автоматизация климат-контроля, анализ энергопотребления, мониторинг безопасности |
Аппаратные устройства обычно имеют автономное питание (батарейки на несколько месяцев или лет работы), защищённый корпус и интерфейс для выгрузки данных — USB, Bluetooth или Wi-Fi. Некоторые модели поддерживают облачную синхронизацию, превращаясь в полноценные IoT-устройства.
Уровни логирования: зачем их использовать
Представьте ситуацию: приложение пишет в лог абсолютно всё — каждый вызов функции, изменение переменной и каждый запрос к базе данных. Через час работы вы получаете файл на несколько гигабайт, в котором невозможно найти критическую ошибку среди тысяч рутинных сообщений. Именно для решения этой проблемы были придуманы уровни детализации.
Уровни — это система классификации событий по степени важности. Каждое сообщение получает определённый уровень, который отражает его критичность для работы инфраструктуры. Это позволяет разработчику гибко управлять детализацией в зависимости от контекста: на этапе разработки записывать всё подряд для отладки, в продакшене — только значимые события и ошибки.
Механика работы проста: при инициализации указывается минимальный уровень, который нас интересует. Все события ниже этого порога игнорируются. Например, если установлен уровень WARNING, система зафиксирует предупреждения и ошибки, но проигнорирует отладочные данные и обычные информационные сообщения. Это радикально сокращает объём логов без потери критически важной информации.
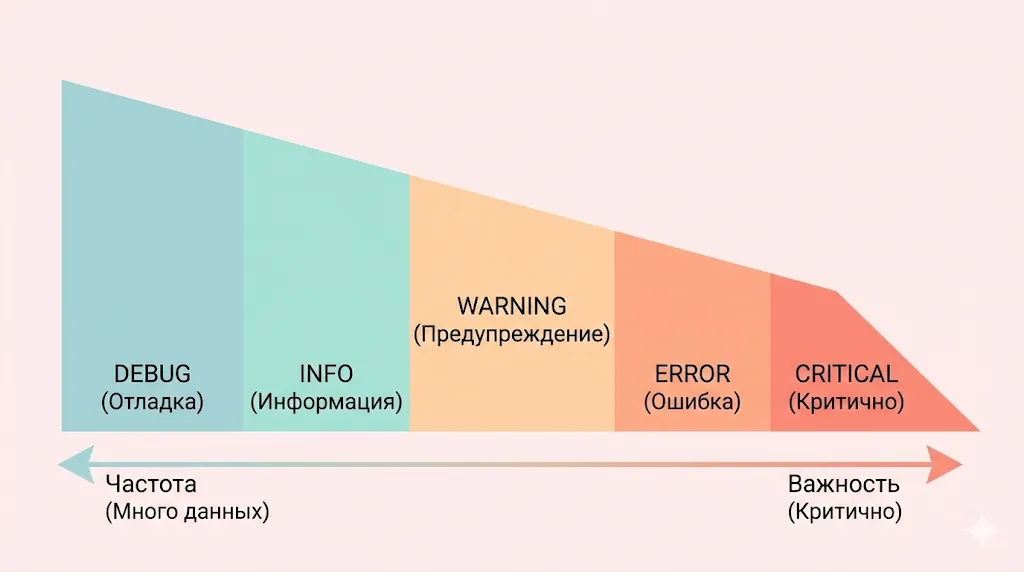
Диаграмма иллюстрирует обратную зависимость: чем критичнее уровень события (CRITICAL), тем реже оно должно возникать. Напротив, служебных сообщений (DEBUG) генерируется больше всего, но они имеют наименьшую важность.
Более того, уровни упрощают анализ: вместо того чтобы читать весь файл построчно, можно сразу отфильтровать только ошибки или предупреждения. Многие инструменты визуализации автоматически подсвечивают сообщения разных уровней разными цветами, превращая монотонный текст в структурированную картину состояния.
Грамотное использование отражает зрелость команды разработки. Начинающие программисты часто пишут все сообщения на одном уровне или используют только INFO и ERROR. Опытные разработчики тщательно подбирают уровень для каждого типа событий, создавая логи, которые действительно помогают, а не создают информационный шум.
Основные уровни логов
Большинство современных решений используют иерархию уровней, которая стала де-факто индустриальным стандартом. Рассмотрим их подробнее.
| Уровень | Что фиксирует | Пример события |
|---|---|---|
| DEBUG | Детальная информация для отладки, пошаговое выполнение кода, значения переменных на каждом этапе. Используется только в процессе разработки. | «Функция calculate_discount вызвана с параметрами: user_id=12345, cart_total=5000, promo_code=’SUMMER2025′» |
| INFO | Штатные события в работе системы, подтверждающие нормальное функционирование. Ключевые точки бизнес-логики, успешное завершение операций. | «Пользователь admin@company.com успешно авторизовался. Сессия создана с ID: a7f3c2e9» или «База данных инициализирована, загружено 15 таблиц» |
| WARNING | Потенциальные проблемы, которые пока не нарушают работу, но требуют внимания. Нештатные, но обрабатываемые ситуации. | «API внешнего сервиса не ответил за 3 секунды, используем кешированные данные» или «Диск заполнен на 85%, рекомендуется очистка» |
| ERROR | Ошибки, нарушающие выполнение конкретной операции, но не останавливающие приложение целиком. Исключения, которые были отловлены и обработаны. | «Не удалось отправить email пользователю user@example.com: SMTP сервер недоступен» или «Ошибка валидации платежа: недостаточно средств на счёте клиента ID 9876» |
| CRITICAL/FATAL | Критические ошибки, приводящие к аварийному завершению приложения или полной потере функциональности системы. | «Невозможно подключиться к основной базе данных. Приложение остановлено» или «Исчерпана вся доступная память. Принудительное завершение процесса» |
Стоит отметить, что некоторые системы добавляют промежуточные уровни (например, NOTICE между INFO и WARNING) или используют альтернативную терминологию, но базовая логика остаётся неизменной: от максимальной детализации к критическим событиям.
Важный нюанс: уровни образуют строгую иерархию. Если система настроена на WARNING, она зафиксирует также ERROR и CRITICAL, но проигнорирует INFO и DEBUG. Это позволяет одной настройкой контролировать объём генерируемых данных.
Как выбрать уровень для конкретной задачи
Выбор правильного уровня — это искусство, которое приходит с опытом. Однако существуют проверенные практики, упрощающие это решение в зависимости от контекста разработки.
Для backend-разработки:
В продакшене устанавливайте базовый уровень INFO — это обеспечит фиксацию всех значимых бизнес-событий без избыточной детализации. DEBUG активируйте только при расследовании конкретной ошибки и только для проблемного модуля, иначе рискуете затопить систему логами.
Используйте WARNING для ситуаций, которые требуют мониторинга, но не моментальной реакции: медленные запросы к базе (более 1 секунды), повторные попытки подключения к внешним сервисам, приближение к лимитам ресурсов. ERROR резервируйте для ситуаций, когда конкретный запрос пользователя не может быть выполнен: ошибки валидации, проблемы с платежами, недоступность критических зависимостей.
Для frontend-разработки:
В браузере объём логов ограничен, поэтому подход должен быть более избирательным. В production используйте уровень ERROR для отправки информации о JavaScript-исключениях в систему мониторинга (Sentry, Rollbar). WARNING применяйте для фиксации проблем с производительностью: медленная загрузка компонентов, долгий рендеринг, API-запросы с высокой задержкой.
INFO в браузере имеет смысл только для критических бизнес-событий: завершение оформления заказа, успешная оплата, отправка важной формы. DEBUG оставляйте исключительно для локальной разработки — в продакшене он создаёт лишний шум в консоли разработчика.
Для DevOps и инфраструктуры:
При настройке на серверах и в контейнерах ориентируйтесь на WARNING как базовый уровень. Это позволит отслеживать потенциальные проблемы (высокая загрузка CPU, заполнение дисков, сетевые таймауты), не захлёбываясь в деталях каждого HTTP-запроса.
Для систем оркестрации (Kubernetes, Docker Swarm) фиксируйте на уровне INFO события lifecycle: запуск и остановка контейнеров, масштабирование сервисов, обновление конфигураций. ERROR используйте для падений контейнеров, недоступности нод кластера, проблем с persistent volumes.
В CI/CD пайплайнах придерживайтесь INFO для успешных этапов и ERROR для провалов, добавляя DEBUG только при настройке новых стадий деплоя.
Общее правило: если сомневаетесь между двумя уровнями — выбирайте более высокий (менее детальный). Всегда проще временно увеличить детализацию для конкретного компонента, чем разбираться в гигабайтах избыточных данных.
Примеры использования логгеров в реальных задачах
Теория обретает смысл только в контексте реальных сценариев применения. Давайте рассмотрим, как инструменты решают конкретные задачи в программировании и инженерных системах.
В программировании
- Отладка сложной бизнес-логики — разработчик интернет-магазина сталкивается с проблемой: некоторые пользователи жалуются, что промокод не применяется. Логи показывают полную цепочку: получен промокод → проверка в базе данных → код действителен → применён к корзине → пересчитана итоговая сумма. Оказывается, проблема возникает только при комбинации двух акций, что выявляется благодаря детальной DEBUG-фиксации параметров на каждом этапе.
- Мониторинг производительности — финтех-стартап фиксирует время выполнения критических операций: авторизация пользователя, проверка баланса, проведение транзакции. Когда среднее время обработки платежа вырастает с 200 до 800 миллисекунд, логи указывают на конкретный SQL-запрос, который начал выполняться медленно из-за роста объёма данных. Проблема решается добавлением индекса.
- Расследование инцидентов безопасности — система обнаруживает подозрительную активность: множественные неудачные попытки входа с разных IP-адресов на один аккаунт в течение минуты. Логи фиксируют паттерн brute-force атаки, автоматически блокируют аккаунт и отправляют уведомление владельцу. Детальная хронология событий позволяет понять, была ли атака успешной и какие данные могли быть скомпрометированы.
- Аудит операций с данными — в медицинской информационной системе каждое обращение к карте пациента фиксируется: кто, когда и какую информацию просматривал или изменял. Это не только соответствие требованиям HIPAA, но и механизм выявления несанкционированного доступа или случайных ошибок персонала.
- Отслеживание пользовательских сценариев — продуктовая команда анализирует логи, чтобы понять, как пользователи взаимодействуют с новой функцией. Выясняется, что 60% отказываются от регистрации на третьем шаге формы — это сигнал к упрощению процесса.
В инженерных системах
- Термоконтроль в дата-центрах — температурные устройства непрерывно фиксируют климат в серверной. Когда температура в одной из зон поднимается выше 28°C, система выявляет тренд по данным за последний час и автоматически увеличивает мощность кондиционирования, предотвращая перегрев оборудования.
- Контроль холодовой цепи в логистике — фармацевтическая компания транспортирует вакцины при температуре +2…+8°C. GPS-трекер с температурным датчиком фиксирует каждое отклонение. По прибытии груза данные выгружаются, и заказчик получает полный отчёт, подтверждающий соблюдение условий на всех этапах доставки. Однажды устройство зафиксировало превышение температуры на 15 минут — партия была забракована, что предотвратило использование испорченных препаратов.
- Мониторинг микроклимата в музеях — датчики влажности и температуры защищают бесценные экспонаты от разрушения. Данные за годы позволяют выявить сезонные колебания и скорректировать работу климатических систем. В одном случае анализ показал, что резкие перепады влажности происходят при открытии служебных дверей — проблема была решена установкой воздушной завесы.
- Оптимизация «умного дома» — многофункциональные устройства собирают данные об освещённости, температуре, присутствии людей в разных комнатах. Система анализирует паттерны и автоматически подстраивает отопление: снижает температуру в спальне днём, повышает вечером за час до обычного времени возвращения жильцов.
Как подключить и использовать логгер: шаг за шагом
Теоретическое понимание обретает практическую ценность только тогда, когда мы начинаем использовать его в реальных проектах. Процесс интеграции состоит из нескольких последовательных этапов: подключение библиотеки, базовая настройка и непосредственное использование в коде. Давайте рассмотрим, как это работает на примере двух наиболее популярных языков программирования.
Важно понимать: это не магический инструмент, который начинает работать сам по себе после установки. Разработчик должен явно указать, какие события заслуживают внимания и на каком уровне их следует фиксировать. Чем продуманнее подход на этапе разработки, тем проще будет поддерживать и отлаживать приложение в будущем.
Подключение логгера в разных языках (JS / Python)
JavaScript (Node.js) с использованием встроенного console:
// Простейший вариант - встроенные методы console
console.log('Приложение запущено');
console.info('Пользователь подключился:', userId);
console.warn('Медленный запрос к API:', apiEndpoint);
console.error('Ошибка подключения к базе данных:', error);
// Более продвинутый вариант с библиотекой Winston
const winston = require('winston');
const logger = winston.createLogger({
level: 'info',
format: winston.format.json(),
transports: [
new winston.transports.File({ filename: 'error.log', level: 'error' }),
new winston.transports.File({ filename: 'combined.log' })
]
});
// Использование
logger.info('Сервер запущен на порту 3000');
// Имитируем возникновение ошибки для примера const err = new Error('Connection timeout'); logger.error('Не удалось обработать запрос', { userId: 123, error: err.message });
Python с встроенным модулем logging:
import logging
# Базовая настройка
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('app.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(_ _name_ _)
# Использование
logger.debug('Детальная информация для отладки')
logger.info('Пользователь авторизован: user_id=%s', user_id)
logger.warning('Диск заполнен на 85%%')
logger.error('Ошибка при обработке платежа', exc_info=True)
Обратите внимание: в обоих примерах мы настраиваем не только уровень, но и формат сообщений, а также указываем, куда именно должны записываться логи — в файл, консоль или оба варианта одновременно.
Настройка логгера
После подключения необходимо настроить инструмент под требования конкретного проекта. Ключевые параметры конфигурации:
Формат сообщений — определяет структуру каждой записи в логе. Стандартный формат обычно включает временную метку, уровень важности, имя модуля и текст сообщения. Для машинной обработки удобен JSON-формат:
format='{"time": "%(asctime)s", "level": "%(levelname)s", "message": "%(message)s"}'
Путь хранения — указывает, куда физически записываются логи. Можно настроить отдельные файлы для разных уровней (например, error.log только для ошибок, app.log для всего остального) или использовать единый файл с последующей фильтрацией.
Уровни — базовый определяет минимальную важность событий, которые будут записаны. В разработке обычно используют DEBUG, в продакшене — INFO или WARNING. Это позволяет контролировать объём генерируемых данных.
Ротация логов — механизм автоматического создания новых файлов, предотвращающий бесконтрольный рост одного файла. Ротация может происходить по размеру (создать новый файл при достижении 10 МБ), по времени (новый файл каждый день) или по их комбинации. Старые файлы обычно автоматически архивируются или удаляются.
Грамотная настройка этих параметров превращает инструмент из простого механизма записи текста в полноценную систему мониторинга состояния приложения.
Создавать свой логгер или использовать готовый?
Этот вопрос неизбежно возникает у разработчиков, столкнувшихся с необходимостью логирования впервые. Сначала задача кажется тривиальной: открыть файл, записать строку, закрыть файл. Однако за этой простотой скрывается множество нюансов, которые превращают примитивную запись в файл в полноценную систему.
Мы наблюдаем два противоположных подхода: одни разработчики немедленно тянутся к сторонним библиотекам, другие считают их избыточными и пишут собственное решение. Истина, как обычно, находится где-то посередине — выбор зависит от специфики проекта и требований.
Когда создание собственного логгера оправдано
Существуют сценарии, в которых разработка собственного инструмента становится не прихотью, а необходимостью:
Специфичный формат данных— если ваш проект требует уникальной структуры логов, несовместимой со стандартными решениями. Например, встраивание в проприетарный протокол обмена данными или необходимость шифрования каждой записи по кастомному алгоритму. В таких случаях адаптация готовой библиотеки может оказаться сложнее написания собственной.
Ограниченная среда выполнения — встроенные системы, микроконтроллеры, legacy-платформы с жёсткими ограничениями по памяти и вычислительным ресурсам. Стандартные решения могут оказаться слишком «тяжёлыми» для таких условий. Минималистичное решение на 50 строк кода, записывающее данные напрямую в EEPROM или UART, выигрывает у универсальной библиотеки.
Образовательные цели — понимание внутреннего устройства приходит только через собственную реализацию. Для обучения создание простого инструмента — отличное упражнение, раскрывающее концепции буферизации, форматирования, управления файлами. Главное — не использовать такие учебные проекты в продакшене.
Интеграция в экзотические окружения — редкие языки программирования, для которых не существует готовых решений, или необходимость записи в нестандартные системы хранения (например, запись непосредственно в аппаратные регистры специализированного контроллера).
Почему чаще используют готовые решения
Подавляющее большинство проектов выигрывает от использования зрелых библиотек, и на то есть веские причины:
- Устойчивость к ошибкам — готовые решения прошли проверку тысячами разработчиков и миллионами часов работы в продакшене. Они корректно обрабатывают edge cases: переполнение диска, одновременную запись из нескольких потоков, внезапное завершение процесса. Ваш собственный инструмент потребует месяцев отладки для достижения того же уровня надёжности.
- Стандартизация — использование популярных библиотек означает, что любой новый разработчик в команде мгновенно понимает, как работает логирование в проекте. Документация, примеры, ответы на Stack Overflow — всё это уже существует и доступно.
- Богатый функционал — современные решения предоставляют множество возможностей из коробки: ротация файлов, отправка в Syslog или облачные сервисы, асинхронная запись, контекстные переменные, структурированное логирование в JSON. Реализация даже части этого функционала самостоятельно займёт недели разработки.
- Производительность и оптимизация — разработчики популярных библиотек вложили огромные усилия в оптимизацию производительности. Буферизация, пулы объектов, минимизация аллокаций памяти — всё это уже реализовано и протестировано на высоконагруженных системах.
- Поддержка и обновления — готовые решения развиваются вместе с экосистемой языка, получают патчи безопасности, адаптируются под новые версии платформ. Ваш собственный код потребует постоянного сопровождения.
Вывод прост: если нет объективных технических причин для разработки собственного решения, используйте проверенные библиотеки и сосредоточьтесь на бизнес-логике вашего приложения.
Преимущества логирования: зачем оно нужно бизнесу и разработчикам
Логирование часто воспринимается как техническая необходимость, обязательный элемент инфраструктуры, о котором вспоминают только при возникновении проблем. Однако грамотно организованная система логов приносит измеримую бизнес-ценность, выходящую далеко за рамки простой отладки кода.
Инвестиции окупаются многократно: сокращается время поиска и устранения ошибок, повышается безопасность системы, появляется возможность для data-driven решений. Компании, внедрившие комплексное логирование на ранних этапах, получают конкурентное преимущество в скорости реакции на инциденты и понимании поведения пользователей.
Рассмотрим конкретные преимущества, которые даёт систематическая фиксация событий:
- Диагностика и устранение проблем — логи превращают поиск ошибок из гадания в точную науку. Вместо часов или дней на воспроизведение бага в тестовом окружении разработчик за минуты находит причину проблемы в продакшене. Это напрямую влияет на uptime сервиса и удовлетворённость пользователей.
- Безопасность и предотвращение инцидентов — логи служат первой линией обороны против атак. Анализ паттернов доступа выявляет попытки несанкционированного проникновения, brute-force атаки, эксплуатацию уязвимостей. В случае успешной атаки детальные логи становятся основой для forensics-анализа и понимания масштаба ущерба.
- Бизнес-аналитика и понимание пользователей — логи содержат богатейшую информацию о том, как клиенты взаимодействуют с продуктом. Какие функции используются чаще всего? На каком этапе пользователи отказываются от регистрации? Сколько времени занимает типичная сессия? Ответы на эти вопросы лежат в логах.
- Исторический контроль и аудит — возможность восстановить последовательность событий за любой период времени критична для финансовых систем, медицинских приложений, государственных информационных систем. Логи становятся юридически значимым доказательством при разрешении споров.
- Оптимизация производительности — анализ выявляет медленные запросы, неоптимальные алгоритмы, утечки памяти. Мониторинг времени выполнения операций позволяет заметить деградацию производительности до того, как она станет критичной для пользователей.
- Ускорение цикла разработки — детальное логирование на этом этапе сокращает время отладки новых функций. Разработчик видит, как код ведёт себя в реальных условиях, без необходимости подключать отладчик или добавлять временные print-операторы.
Как выбрать логгер: чек-лист
Выбор системы — это стратегическое решение, которое будет влиять на проект на протяжении всего его жизненного цикла. Неудачный выбор может привести к техническому долгу, сложностям с масштабированием или невозможности эффективно анализировать данные. Грамотный подход предполагает оценку текущих и будущих потребностей проекта.
Перед выбором конкретного решения ответьте на следующие вопросы:
- Какие данные нужно фиксировать? — определите scope. Только критические ошибки или полная трассировка запросов? Нужна ли информация о производительности? Требуется ли фиксировать действия пользователей для аналитики? От ответов зависит выбор между минималистичным решением и полноценной observability-платформой.
- Какой формат логов предпочтителен? — текстовые логи просты для чтения человеком, но сложны для автоматического анализа. Структурированные форматы (JSON, XML) упрощают парсинг и интеграцию с аналитическими системами, но менее читабельны. Для современных приложений мы рекомендуем JSON как баланс между человеко- и машинопонятностью.
- Где хранить логи? — локальные файлы подходят для небольших проектов, но создают проблемы в распределённых системах. Централизованные решения (ELK Stack, Graylog, Loki) упрощают агрегацию с множеством серверов. Облачные сервисы (CloudWatch, Datadog) снимают операционную нагрузку, но требуют бюджета.
- Как быстро нужно анализировать данные? — если требуется real-time мониторинг для оперативного реагирования на инциденты, выбирайте решения с встроенным стримингом и алертингом. Для post-mortem анализа достаточно batch-обработки раз в сутки.
- Требуется ли визуализация? — графики, дашборды, heat maps превращают сырые логи в понятную картину состояния системы. Если визуализация критична, обратите внимание на решения с встроенными возможностями (Kibana для ELK, Grafana для Loki) или лёгкой интеграцией с BI-инструментами.
- Интеграция с CI/CD и DevOps-процессами — инструмент должен органично вписываться в вашу инфраструктуру. Проверьте наличие плагинов для используемых инструментов: Docker, Kubernetes, Jenkins, GitLab CI. Поддержка стандартов вроде OpenTelemetry упростит будущие миграции.
Этот чек-лист поможет сформулировать требования и сузить круг подходящих решений, избежав импульсивного выбора на основе популярности или рекомендаций без учёта специфики вашего проекта.
Рекомендации по эффективному внедрению логгирования
Наличие в проекте не гарантирует автоматически пользу от его использования. Мы неоднократно наблюдали ситуации, когда команды внедряли логирование формально, без продуманной стратегии, что приводило либо к информационному шуму (гигабайты бесполезных записей), либо к отсутствию критически важной информации в момент инцидента.
Эффективное логирование требует систематического подхода и следования проверенным практикам:
- Определить цели на этапе проектирования — перед написанием первой строки кода сформулируйте, зачем нужны логи конкретно в вашем проекте. Отладка во время разработки? Мониторинг производительности? Аудит действий пользователей? Разные цели требуют разных подходов. Документируйте эти цели и делитесь ими с командой.
- Настроить уровни осознанно — не используйте один уровень для всех событий. Критические ошибки должны быть ERROR или CRITICAL, штатная работа — INFO, детали отладки — DEBUG. В продакшене базовый уровень обычно INFO или WARNING. Избегайте соблазна фиксировать всё на уровне DEBUG «на всякий случай» — это убивает производительность и засоряет хранилище.
- Регулярно проверять и анализировать логи — логи, которые никто не читает, бесполезны. Выделите время в спринте на ревью: какие паттерны повторяются? Есть ли warnings, игнорируемые месяцами? Не превращаются ли INFO-сообщения в шум? Периодический аудит выявляет проблемы до того, как они станут критическими.
- Настроить проактивный мониторинг — не ждите, пока пользователи сообщат о проблеме. Настройте алерты на критические события: рост числа ошибок, превышение времени отклика, недоступность зависимостей. Интегрируйте систему с нотификациями (Slack, PagerDuty, email) для немедленного реагирования.
- Применять автоматическую ротацию логов — файлы растут быстро. Без ротации один файл может достичь десятков гигабайт, что усложняет анализ и потребляет дисковое пространство. Настройте ротацию по размеру (например, новый файл каждые 100 МБ) или по времени (ежедневно). Старые логи архивируйте или удаляйте согласно retention policy.
- Избегать избыточности — каждая запись стоит ресурсов: CPU для форматирования, I/O для записи, дисковое пространство для хранения. Фиксация внутри tight loops, высокочастотных колбэков или на каждую итерацию алгоритма создаёт bottleneck. Используйте sampling: фиксируйте каждый 100-й запрос вместо всех, или агрегируйте однотипные события.
Следование этим рекомендациям превращает логирование из технической формальности в реальный инструмент повышения качества и надёжности вашего продукта.
Заключение
Логгер — это больше, чем просто инструмент для записи событий. Это фундаментальный механизм прозрачности, превращающий непрозрачную «чёрную коробку» приложения или системы в понятный, контролируемый процесс. Мы рассмотрели данные инструменты с разных сторон: от программных библиотек, интегрируемых в код, до физических устройств, собирающих данные об окружающей среде. Подведем итоги:
- Логгер в программировании — это инструмент фиксации событий и состояний системы. Он позволяет восстановить точную хронологию работы приложения и понять, что происходило в момент сбоя или нестабильной работы.
- Логирование решает задачи диагностики, мониторинга и безопасности. Благодаря логам разработчики быстрее находят ошибки, отслеживают производительность и выявляют подозрительную активность.
- Эффективное логирование строится на уровнях важности. Использование DEBUG, INFO, WARNING, ERROR и CRITICAL помогает контролировать объём данных и фокусироваться на действительно значимых событиях.
- Логи проходят несколько этапов обработки — от сбора данных до анализа. Это делает логирование частью полноценного пайплайна, а не простой записью текста в файл.
- Логгеры применяются как в программных, так и в инженерных системах. Они используются в веб-приложениях, DevOps-инфраструктуре, IoT-устройствах и промышленном оборудовании.
- Грамотно настроенная система логирования приносит бизнес-ценность. Она снижает время простоя сервисов, повышает надёжность продуктов и помогает принимать решения на основе данных.
Если вы только начинаете осваивать backend-разработку или DevOps-практики, рекомендуем обратить внимание на подборку курсов по backend-разработке. В таких программах есть теоретическая и практическая часть, что особенно важно, если вы только начинаете осваивать профессию разработчика или инженера по эксплуатации.
Рекомендуем посмотреть курсы по веб разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Веб-разработчик
|
Eduson Academy
114 отзывов
|
Цена
119 000 ₽
|
От
9 917 ₽/мес
|
Длительность
12 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Веб-разработчик с нуля до PRO
|
Skillbox
232 отзыва
|
Цена
294 783 ₽
589 565 ₽
Ещё -20% по промокоду
|
От
8 670 ₽/мес
Без переплат на 1 год.
|
Длительность
10 месяцев
|
Старт
23 марта
|
Подробнее |
|
Веб-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
163 300 ₽
302 470 ₽
с промокодом kursy-online
|
От
5 041 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 апреля
|
Подробнее |
|
Fullstack-разработчик на python (с нуля)
|
Eduson Academy
114 отзывов
|
Цена
158 760 ₽
|
От
13 230 ₽/мес
20 642 ₽/мес
|
Длительность
7 месяцев
|
Старт
24 марта
|
Подробнее |
|
Профессия Веб-разработчик
|
Skillbox
232 отзыва
|
Цена
152 538 ₽
305 075 ₽
Ещё -20% по промокоду
|
От
4 486 ₽/мес
Без переплат на 34 месяца с отсрочкой платежа 3 месяца.
|
Длительность
24 месяца
|
Старт
23 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.