Что такое маппинг данных (Data Mapping)
Представим ситуацию: в одной корпоративной системе информация о семейном положении сотрудника записывается как «1» (есть дети) или «0» (нет детей). В другой системе те же данные хранятся в формате «True/False», а в третьей — просто словами «да» и «нет». Три разных способа записи одной и той же информации — именно такие противоречия решает маппинг данных.

Маппинг данных (от английского data mapping — сопоставление данных) — это процесс установления соответствий между элементами данных из разных источников или систем. В широком смысле мы говорим о создании «карты переводов», которая позволяет привести разрозненную информацию к единому формату и структуре.
Для IT-специалистов маппинг — это техническая процедура сопоставления полей, таблиц и структур информации между источником и приемником. Для бизнеса это инструмент, который делает возможным объединение информации из разных отделов, систем и даже компаний в единую картину для принятия решений.
В современной корпоративной среде МД становится неотъемлемой частью более широких процессов. Он тесно связан с концепцией data lineage — отслеживанием происхождения и движения информации по всей IT-инфраструктуре. Когда мы консолидируем информацию из множества источников в корпоративное хранилище или озеро данных, маппинг обеспечивает корректное преобразование и интеграцию разнородных форматов.
Суть процесса можно свести к трем ключевым задачам: идентификации соответствий между данными, определению правил их преобразования и автоматизации этих правил для регулярного применения. Без качественного маппинга любые попытки создать единую аналитическую систему или перенести информацию между платформами обречены на провал — мы получим либо хаос из несовместимых форматов, либо потерю критически важной информации.
- Зачем нужен: основные задачи и примеры
- Как устроен процесс: пошаговое руководство
- Какие сложности могут возникнуть при мапинге
- Инструменты для маппинга
- Кто занимается маппингом данных: распределение ролей
- Как научиться маппингу данных: советы для начинающих
- Заключение
- Рекомендуем посмотреть курсы по системной аналитике
Зачем нужен: основные задачи и примеры
В эпоху цифровой трансформации компании накапливают терабайты данных в десятках различных систем — от CRM и ERP до специализированных отраслевых решений. Каждая система создавалась в свое время, разными командами разработчиков, с собственными стандартами и логикой. Результат предсказуем: информационный хаос, где одни и те же бизнес-сущности представлены совершенно по-разному.
Представим аналитика, который пытается понять причины снижения конверсии в интернет-магазине. Ему нужна информация из системы веб-аналитики (где пользователи идентифицируются по cookie), CRM (где клиенты имеют внутренние ID), платежной системы (с собственной нумерацией транзакций) и службы поддержки (где обращения привязаны к email-адресам). Без маппинга это четыре изолированных массива информации, которые невозможно связать в единую картину.
МД решает фундаментальную проблему унификации. Мы создаем правила преобразования, которые позволяют «перевести» данные из одного формата в другой, сохраняя их смысловое содержание. Это особенно критично при работе с противоречивыми форматами — когда одна система хранит даты в формате DD.MM.YYYY, а другая использует американский стандарт MM/DD/YYYY.
Контроль качества информации — еще одна ключевая функция маппинга. В процессе сопоставления мы выявляем дубли, пропуски, логические противоречия и аномалии. Например, если в одной системе возраст клиента указан как 25 лет, а в другой — как 35, маппинг поможет обнаружить эту нестыковку и определить, какой источник более достоверен.
Основные сферы применения маппинга
Миграция данных — перенос информации при смене IT-платформы или объединении компаний. Здесь маппинг обеспечивает корректную трансформацию информации без потери критически важной информации.
Интеграция систем — создание регулярного обмена данными между различными приложениями. ETL-процессы используют маппинг для синхронизации информации в реальном времени.
Подготовка данных для аналитики — формирование единых датасетов для Business Intelligence и Data Science. Аналитики получают «чистую» информацию в унифицированном формате.
Загрузка в хранилища данных — консолидация информации в корпоративные DWH или Data Lake требует четкого маппинга схем и структур из различных источников.
Обогащение данных для ML/AI — современные алгоритмы машинного обучения требуют качественных, структурированных датасетов, что невозможно без профессионального маппинга разнородных источников.
Как устроен процесс: пошаговое руководство
Маппинг данных — это не разовая техническая операция, а комплексный процесс, который требует участия различных специалистов и четкого понимания бизнес-логики. В основе лежит классическая методология ETL (Extract, Transform, Load), где маппинг играет центральную роль на этапе трансформации информации.
Системный аналитик выступает архитектором процесса — он анализирует бизнес-требования, документирует связи между информацией и создает техническое задание для разработчиков. Инженер данных (Data Engineer) реализует эти требования в виде программного кода, настраивает ETL-процессы и обеспечивает их стабильную работу в production-среде.
Этап 1: Анализ источников
Первый шаг — детальная инвентаризация всех источников информации. Мы составляем реестр систем, выявляем форматы данных, изучаем структуры таблиц и документируем бизнес-логику каждого поля. Критически важно понимать не только техническую структуру, но и семантику — что означает каждое поле, как оно заполняется, есть ли ограничения или зависимости.
Например, для поля «Статус заказа» в разных системах может использоваться разная кодировка: числовые коды (1, 2, 3), текстовые значения («новый», «в работе», «завершен») или даже цветовые маркеры. Системный аналитик должен зафиксировать все эти варианты и определить единый стандарт для целевой системы.
Этап 2: Сопоставление и трансформация
На этом этапе создаются правила преобразования. Мы определяем, какие поля из источника соответствуют полям в приемнике, какие требуют преобразования формата, а какие нужно вычислить на основе нескольких исходных значений.
Особое внимание уделяется обработке дублей и конфликтов. Если один клиент присутствует в нескольких системах под разными идентификаторами, нужно создать логику их объединения. Например, сопоставление может происходить по email-адресу или номеру телефона, а в случае противоречий — выбираться наиболее актуальная версия данных.
Этап 3: Автоматизация и генерация правил
Современные ETL-инструменты позволяют создавать маппинг в графическом режиме — мы буквально рисуем связи между полями источника и приемника. Система автоматически генерирует код на SQL, Java, Python или других языках программирования.
Однако автоматизация не означает полное отсутствие ручной работы. Сложные преобразования, бизнес-логика и обработка исключений часто требуют написания custom-скриптов. Например, для преобразования адресов из свободной текстовой формы в структурированные поля (страна, город, улица, дом) может потребоваться алгоритм с использованием регулярных выражений и справочников.
Этап 4: Загрузка и проверка
Финальный этап включает не только техническую загрузку данных, но и комплексную проверку результатов. Мы сравниваем количество записей до и после преобразования, проверяем корректность ключевых метрик, анализируем качество информации в целевой системе.
Критически важно настроить систему мониторинга и логирования. ETL-процессы должны автоматически фиксировать ошибки, предупреждения и статистику обработки. Это позволяет оперативно реагировать на проблемы и постоянно улучшать качество маппинга.
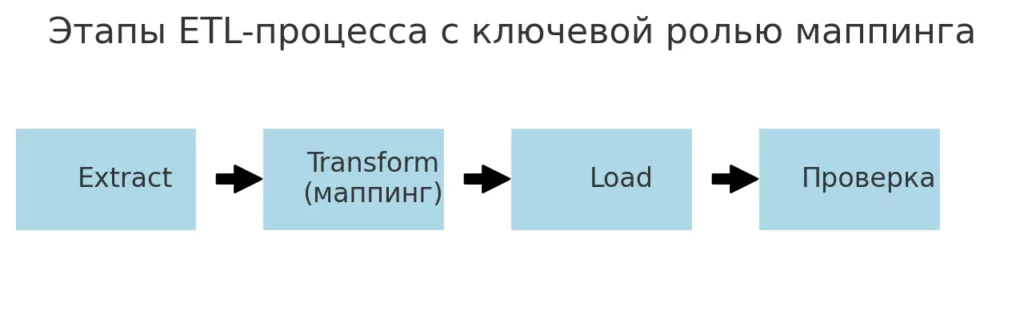
Линейная блок-схема с этапами Extract, Transform (маппинг), Load и Проверка.
Какие сложности могут возникнуть при мапинге
Даже самый продуманный процесс маппинга может столкнуться с серьезными препятствиями, которые способны превратить, казалось бы, рутинную задачу в настоящий технический вызов. Понимание этих сложностей помогает правильно планировать проекты и избегать критических ошибок.
- Объем и производительность — когда речь идет о терабайтах информации, стандартные подходы к маппингу могут оказаться неэффективными. Обработка миллионов записей в реальном времени требует оптимизированных алгоритмов, параллелизации процессов и специализированных инструментов для работы с большими данными.
- Несовместимость форматов и структур — различия в типах данных между системами могут создать неожиданные проблемы. Например, текстовое поле длиной 255 символов в одной системе может не поместиться в поле длиной 100 символов в другой. Или числовое поле может иметь разную точность после запятой, что критично для финансовых расчетов.
- Неполные и противоречивые данные — реальные корпоративные системы редко содержат идеально чистую информацию. Пропущенные значения, дубли, устаревшие записи, логические противоречия — все это требует создания сложных правил валидации и очистки в процессе маппинга.
- Отсутствие единых метаданных — когда разные системы используют собственные стандарты описания данных, создание корректного маппинга становится почти детективной работой. Аналитику приходится изучать техническую документацию, интервьюировать пользователей систем и проводить статистический анализ информации для понимания ее смысла.
- Эволюция систем — структуры данных постоянно изменяются. Новые поля, измененные типы, переименованные таблицы — все это требует регулярного обновления правил маппинга. Отсутствие версионирования и документирования изменений может привести к внезапным сбоям ETL-процессов.
- Временные зависимости — данные в разных системах могут обновляться с разной периодичностью. Например, финансовая информация обновляется ежедневно, а справочники клиентов — раз в неделю. Синхронизация такой информации требует учета временных меток и создания логики обработки несоответствий.
- Производительность и масштабируемость — маппинг, который отлично работает с тестовыми данными, может показать неприемлемую производительность в production-среде. Особенно это касается сложных преобразований, требующих множественных соединений таблиц или вычислений.
Инструменты для маппинга
Современный рынок предлагает широкий спектр решений для МД — от enterprise-платформ стоимостью в сотни тысяч долларов до open-source инструментов, доступных любому разработчику. Выбор конкретного решения зависит от масштаба задач, бюджета проекта и технической экспертизы команды.
Enterprise ETL-платформы — такие решения, как Informatica PowerCenter, IBM DataStage, предоставляют комплексный функционал для маппинга корпоративного уровня. Они включают графические интерфейсы для создания маппингов, богатые библиотеки готовых коннекторов, системы мониторинга и управления метаданными. Основной недостаток — высокая стоимость лицензий и сложность внедрения.
Скриншот главной страницы Informatica PowerCenter.
Open-source решения — инструменты вроде Apache NiFi, Pentaho предлагают значительную часть функционала коммерческих аналогов без лицензионных затрат. Для средних компаний и стартапов это оптимальный выбор, позволяющий создавать профессиональные ETL-процессы с ограниченным бюджетом.
Скриншот главной страницы Pentaho.
Облачные сервисы — платформы типа AWS Glue, Azure Data Factory революционизируют подход к маппингу данных. Они предоставляют serverless-архитектуру, автоматическое масштабирование и интеграцию с облачными хранилищами данных. Особенно привлекательны для компаний, активно использующих облачные технологии.
Скриншот главной страницы Azure Data Factory.
Графические инструменты моделирования — BPMN-диаграммы и ER-модели помогают визуализировать процессы маппинга и создавать техническую документацию. Инструменты типа Lucidchart, Draw.io или Microsoft Visio незаменимы на этапе планирования и согласования требований с бизнес-пользователями.
Программирование вручную — для сложных сценариев часто оптимальным решением становится создание custom-скриптов на Python, Java или SQL. Этот подход обеспечивает максимальную гибкость и производительность, но требует высокой квалификации разработчиков.
Пример автоматизации маппинга
Рассмотрим практический пример автоматизации процесса маппинга с использованием Python. Предположим, нам нужно объединить данные о клиентах из двух систем с разными форматами представления статуса:
import pandas as pd
from datetime import datetime
# Словари маппинга для унификации данных
status_mapping = {
'system_a': {1: 'active', 2: 'inactive', 3: 'pending'},
'system_b': {'A': 'active', 'I': 'inactive', 'P': 'pending'}
}
region_mapping = {
'SPb': 'Saint Petersburg', 'MSK': 'Moscow', 'EKB': 'Ekaterinburg'
}
def standardize_customer_data(df, source_system):
"""Унификация данных клиентов из разных систем"""
df_clean = df.copy()
# Маппинг статуса в зависимости от источника
if source_system in status_mapping:
df_clean['status'] = df_clean['status'].map(status_mapping[source_system])
# Унификация названий регионов
df_clean['region'] = df_clean['region'].map(region_mapping).fillna(df_clean['region'])
# Стандартизация формата телефона
df_clean['phone'] = df_clean['phone'].str.replace(r'[^\d]', '', regex=True)
# Добавление метаданных о процессе
df_clean['source_system'] = source_system
df_clean['processed_at'] = datetime.now()
return df_clean
# Обработка данных из разных источников
customers_a = standardize_customer_data(system_a_data, 'system_a')
customers_b = standardize_customer_data(system_b_data, 'system_b')
# Объединение и дедупликация
unified_customers = pd.concat([customers_a, customers_b])
unified_customers = unified_customers.drop_duplicates(subset=['email'], keep='last')
Такой подход позволяет создать гибкую систему преобразования данных, которую легко адаптировать под новые источники и требования.
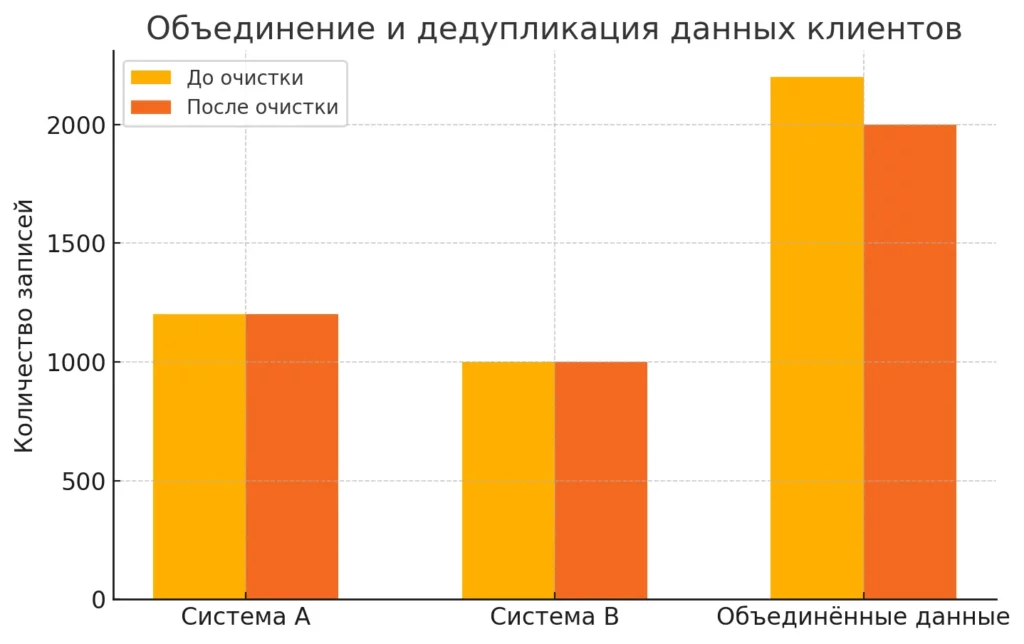
Диаграмма показывает, как после объединения и очистки данных из систем A и B количество записей уменьшилось за счёт удаления дубликатов.
Кто занимается маппингом данных: распределение ролей
Успешный маппинг данных — это результат слаженной работы команды специалистов с разными компетенциями. Понимание ролей и зон ответственности критически важно для эффективной организации проекта.
Системный аналитик выступает главным архитектором процесса маппинга. Он анализирует бизнес-требования, изучает существующие системы и создает техническое задание для разработчиков. В его обязанности входит документирование связей между данными, создание диаграмм потоков информации и определение правил валидации. Системный аналитик должен обладать глубоким пониманием предметной области и способностью переводить бизнес-логику в технические требования.
Data Engineer (инженер данных) реализует концепцию аналитика в виде работающих ETL-процессов. Он пишет код для извлечения, преобразования и загрузки данных, настраивает системы мониторинга и обеспечивает производительность решения. Инженер данных должен владеть SQL, Python/Java, понимать архитектуру баз данных и иметь опыт работы с ETL-инструментами.
DevOps/ML-инженер играет особую роль в проектах, связанных с машинным обучением и искусственным интеллектом. Современные ML-модели требуют качественных, структурированных данных в специфических форматах. Такой специалист обеспечивает интеграцию процессов маппинга с ML-pipeline, настраивает автоматизированную подготовку данных для обучения моделей и мониторинг качества входных данных.
Data Steward (управляющий данными) — роль, которая становится все более важной в крупных организациях. Этот специалист отвечает за качество данных, их соответствие корпоративным стандартам и регулятивным требованиям. В контексте маппинга он утверждает правила преобразования, контролирует соблюдение политик конфиденциальности и обеспечивает трассируемость данных.
В небольших командах один специалист может совмещать несколько ролей, но по мере роста сложности проектов разделение обязанностей становится необходимостью. Эффективная коммуникация между участниками команды — ключевой фактор успеха любого проекта маппинга данных.
Как научиться маппингу данных: советы для начинающих
Маппинг данных — это междисциплинарный навык, который требует сочетания технических знаний, понимания бизнес-процессов и аналитического мышления. Для начинающих специалистов мы рекомендуем поэтапный подход к изучению этой области.
Фундаментальные навыки начинаются с глубокого изучения SQL — языка, который остается основой работы с данными во всех современных системах. Понимание принципов нормализации баз данных, создания связей между таблицами и оптимизации запросов критически важно для эффективного маппинга.
Освоение нотаций и стандартов — изучите BPMN для моделирования бизнес-процессов, UML для описания структур данных и основы проектирования баз данных. Эти инструменты помогут вам документировать и визуализировать процессы маппинга.
Практические навыки лучше всего развивать через работу с реальными данными. Начните с простых задач: загрузите открытые датасеты, попробуйте объединить данные из разных CSV-файлов, создайте простые ETL-процессы с использованием Python и pandas.
Рекомендуемые ресурсы для изучения:
- Курсы по системному анализу и управлению данными.
- Специализированные программы по Data Engineering.
- Практические руководства по ETL-инструментам (Talend, Pentaho).
- Сертификационные программы от вендоров (AWS, Microsoft, Google).
Чек-лист ключевых компетенций:
- SQL и реляционные базы данных.
- Основы Python/Java для обработки данных.
- Понимание форматов данных (JSON, XML, CSV).
- Навыки работы с ETL-инструментами.
- Знание принципов Data Quality и Data Governance.
Начните с малого, постепенно усложняя задачи, и помните: маппинг данных — это не только техническая процедура, но и искусство понимания бизнес-логики и потребностей пользователей.
Заключение
В эпоху, когда каждая компания становится технологической, а данные превращаются в основной актив бизнеса, маппинг данных перестал быть узкоспециализированной IT-задачей. Сегодня это фундаментальный навык, который определяет способность организации эффективно использовать накопленную информацию для принятия стратегических решений. Подведем итоги:
- Маппинг данных помогает привести разрозненные форматы к единому стандарту. Это упрощает работу с информацией, снижает ошибки и повышает качество аналитики.
- Процесс маппинга включает этапы анализа, сопоставления, трансформации и автоматизации. Это обеспечивает точность и повторяемость операций с данными.
- Без качественного маппинга возможно появление дублирующейся и противоречивой информации. Это приводит к потере данных и неправильным бизнес-решениям.
- Современные инструменты и скрипты на Python и других языках позволяют упростить и ускорить процесс маппинга. Они делают его более прозрачным и управляемым.
- Маппинг также необходим для миграции данных и построения аналитики без хаоса. Без него возможно возникновение ошибок и потерь информации.
Если вы только начинаете осваивать работу с данными, рекомендуем обратить внимание на подборку курсов по системной аналитике. В них есть как теоретическая, так и практическая часть, которая поможет быстро освоить ключевые навыки.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
107 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
17 февраля
|
Подробнее |
|
Системный и бизнес-анализ в разработке ПО. Интенсив
|
Level UP
36 отзывов
|
Цена
75 000 ₽
|
От
18 750 ₽/мес
|
Длительность
1 месяц
|
Старт
20 февраля
|
Подробнее |
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 марта
|
Подробнее |
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
107 отзывов
|
Цена
129 900 ₽
257 760 ₽
Ещё -10% по промокоду
|
От
10 825 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |

Apache Cassandra — что это, преимущества и недостатки
Что скрывается за популярной NoSQL системой Apache Cassandra и когда её стоит выбрать для проекта? В статье вы найдёте простое объяснение, реальные примеры и советы по использованию.

Kanban — что это такое и как работает метод визуального управления
Ключ к пониманию методологии — в её простоте. Kanban что это, как он помогает избавиться от хаоса и стоит ли внедрять его в команде? Всё по делу — внутри статьи.

Как ИИ меняет мир кибербезопасности – защита или угроза?
ИИ способен обнаруживать атаки быстрее человека, но и хакеры используют его в своих целях. Может ли он защитить данные или создаёт новые угрозы?

Нейросети для маркетплейсов: как автоматизировать работу и повысить продажи
Как ускорить работу на маркетплейсе и избавиться от рутины? Разбираем лучшие нейросети для продавцов — от генерации описаний и фото до анализа отзывов и трендов.