Что такое модуль pickle в Python
Pickle — это встроенный модуль Python, который занимается сериализацией и десериализацией объектов. Звучит умно, но что это означает на практике? Сериализация — это процесс превращения любого Python-объекта (будь то список, словарь или ваш собственный класс) в последовательность байтов, которую можно сохранить в файл или отправить по сети. Десериализация — обратный процесс: берем эти байты и восстанавливаем из них оригинальный объект со всеми его свойствами и состоянием.

Простыми словами: представьте, что у вас есть сложная LEGO-конструкция (ваш объект), и вам нужно переехать. Pickle разбирает её на отдельные детальки, упаковывает в коробку (байты), а потом в новом доме собирает точно такую же конструкцию. Магия? Почти.
Иллюстрация показывает, как сериализация похожа на разборку LEGO-конструкции для последующей пересборки. Этот наглядный образ помогает интуитивно понять, как pickle превращает объект в байты.
- Зачем нужен pickle: основные сценарии использования
- Как работает сериализация и десериализация
- Протоколы сериализации: от 0 до 5
- Основные функции и классы pickle
- Обработка пользовательских объектов и нестандартных атрибутов
- Риски и безопасность при работе с pickle
- Расширенные возможности и лайфхаки
- Когда pickle — не лучший выбор: обзор альтернатив
- Часто задаваемые вопросы (FAQ)
- Заключение
- Рекомендуем посмотреть курсы по Python
Зачем нужен pickle: основные сценарии использования
В реальной разработке pickle появляется там, где нужно «заморозить» объекты для дальнейшего использования. Вот основные сценарии, где этот модуль становится незаменимым помощником:
- Кэширование вычислений — сохраняете результат долгих расчетов в файл, чтобы не пересчитывать их каждый раз при запуске программы.
- Сохранение состояния приложения — «замораживаете» текущее состояние игры, настройки пользователя или прогресс обработки данных.
- Передача объектов между процессами — отправляете сложные структуры данных между разными частями распределенной системы.
- Хранение моделей машинного обучения — сохраняете обученную нейросеть со всеми весами и параметрами для последующего использования.
- Архивирование структур данных — создаете бэкапы сложных объектов (графы, деревья, пользовательские классы) для восстановления в будущем.
- Обмен данными в кластерных вычислениях — передаете задачи и результаты между узлами при параллельной обработке.
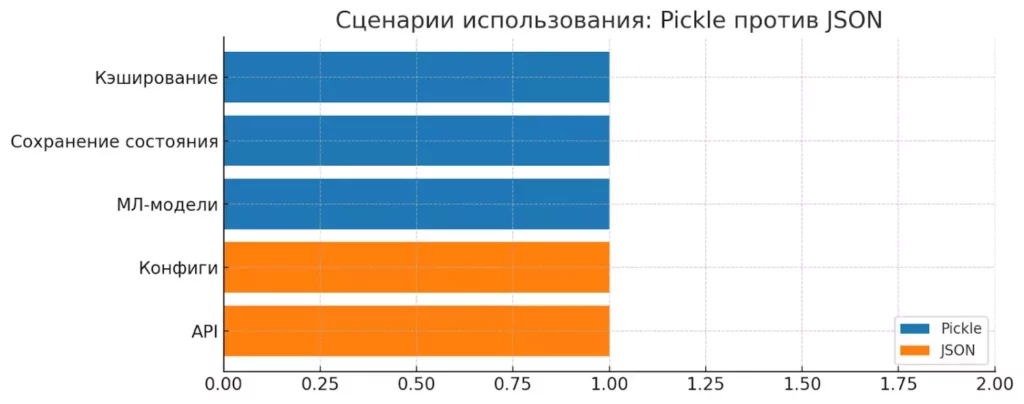
Горизонтальная диаграмма показывает, в каких сценариях лучше применять pickle, а где предпочтительнее json. Pickle полезен при кэшировании и сохранении сложных объектов, тогда как JSON — в API и конфигурациях.
Короче говоря, везде, где JSON уже не справляется с вашими Python-объектами, на сцену выходит pickle.
Как работает сериализация и десериализация
Под капотом pickle творит настоящую магию — он разбирает ваш объект на атомы, записывает инструкцию по его пересборке, а затем упаковывает всё это в байтовый поток. Этот процесс работает как универсальный 3D-принтер для Python-объектов: можете «распечатать» точную копию в любом месте и в любое время.
Сериализация (dump, dumps)
Когда вы вызываете pickle.dump() или pickle.dumps(), модуль начинает рекурсивно обходить ваш объект, превращая каждый его элемент в байтовое представление. dump() сразу записывает результат в файл (обязательно в режиме wb — binary write), а dumps() возвращает байтовую строку, которую можете использовать как угодно.
Особенность в том, что pickle сохраняет не только данные, но и метаинформацию о типах, связях между объектами и даже код пользовательских классов (что, кстати, создает определенные риски безопасности).
Десериализация (load, loads)
При восстановлении pickle.load() читает файл в режиме rb (binary read) и последовательно воссоздает все объекты, восстанавливая связи между ними. pickle.loads() делает то же самое, но работает с байтовой строкой в памяти. Магия в том, что восстановленный объект ведет себя точно так же, как оригинал — со всеми методами, атрибутами и внутренним состоянием.
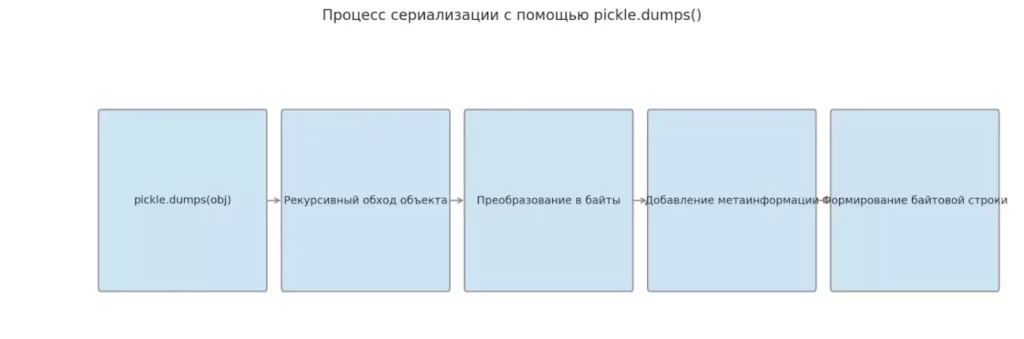
Горизонтальная схема показывает правильную последовательность шагов, происходящих при сериализации объекта через pickle.dumps(). Каждый этап — от обхода до упаковки в байты — представлен как отдельный шаг внутри процесса.
Протоколы сериализации: от 0 до 5
Pickle не стоит на месте и за годы развития Python обзавелся целой коллекцией протоколов сериализации. Каждый новый протокол — это попытка сделать процесс быстрее, эффективнее или просто менее болезненным для разработчиков.
| Протокол | Особенности | Совместимость | Когда использовать |
|---|---|---|---|
| 0 | ASCII-формат, человекочитаемый | Python 1.4+ | Только для отладки (медленный) |
| 1 | Первый бинарный формат | Python 1.5+ | Легаси-системы |
| 2 | Поддержка new-style классов | Python 2.3+ | Совместимость с Python 2 |
| 3 | Оптимизация для Python 3 | Python 3.0+ | Несовместим с Python 2 |
| 4 | Улучшения для больших объектов | Python 3.4+ | Крупные коллекции данных |
| 5 | Буферизация, shared memory | Python 3.8+ | Высокопроизводительные приложения |
В большинстве случаев используйте pickle.HIGHEST_PROTOCOL — это константа, которая автоматически выберет самый продвинутый протокол для вашей версии Python. Зачем заморачиваться выбором, когда можно делегировать это решение самому модулю? Он лучше знает, на что способен.

Обновлённая горизонтальная диаграмма показывает, как менялись протоколы Pickle с 1995 года. Каждый новый шаг улучшал производительность, добавлял новые возможности или решал ограничения предыдущих версий.
Единственное исключение — когда нужна совместимость со старыми версиями Python или вы планируете обмениваться данными между разными версиями интерпретатора.
Основные функции и классы pickle
API модуля pickle можно освоить за пять минут — он намеренно сделан простым и интуитивным. Но за этой простотой скрывается мощный функционал, который покрывает практически все сценарии работы с сериализацией.
dump и dumps — различия
import pickle
data = {'name': 'Alice', 'age': 30}
# dump() -- сразу в файл
with open('data.pkl', 'wb') as f:
pickle.dump(data, f)
# dumps() -- в байтовую строку
serialized = pickle.dumps(data)
print(type(serialized)) # <class 'bytes'>
dump() удобен для прямого сохранения в файл, а dumps() — когда нужно поработать с байтами в памяти (например, отправить по сети или сжать данные).
load и loads
# load() -- из файла
with open('data.pkl', 'rb') as f:
restored_data = pickle.load(f)
# loads() -- из байтов
restored_data = pickle.loads(serialized)
Принцип тот же: load() для файлов, loads() для байтовых строк.
Pickler и Unpickler — кастомная сериализация
Когда стандартного поведения недостаточно, на сцену выходят классы Pickler и Unpickler. Они позволяют тонко настроить процесс сериализации — от выбора протокола до контроля того, какие классы можно десериализовать:
import io
# Кастомный сериализатор с дополнительными проверками
class SafePickler(pickle.Pickler):
def save_global(self, obj, name=None):
# Разрешаем только встроенные типы
if obj.__module__ == "builtins":
return super().save_global(obj, name)
raise pickle.PicklingError(f"Запрещено: {obj}")
Обработка пользовательских объектов и нестандартных атрибутов
Когда дело доходит до сериализации собственных классов, pickle иногда ведет себя как капризный ребенок — то работает идеально, то внезапно выдает ошибки типа «cannot pickle file object». Проблема в том, что не все объекты можно превратить в байты: файловые дескрипторы, сетевые соединения, потоки — всё это pickle переварить не может.
Методы __getstate__, __setstate__, __reduce__, __reduce_ex__
Для таких случаев Python предоставляет специальные методы, которые позволяют явно указать, как именно сериализовать и восстанавливать объект:
class CatLogger: def __init__(self, filename): self.filename = filename self.file = open(filename, 'a') def __getstate__(self): # Исключаем несериализуемый файловый дескриптор state = self.__dict__.copy() del state['file'] return state def __setstate__(self, state): # Восстанавливаем состояние и пересоздаем файл self.__dict__.update(state) self.file = open(self.filename, 'a')
Метод __reduce__ дает еще больше контроля — он должен вернуть кортеж с информацией о том, как воссоздать объект. Для продвинутых случаев есть __reduce_ex__, который учитывает версию протокола.
Модуль copyreg и регистрация обработчиков
Когда даже кастомные методы не спасают, на помощь приходит copyreg — модуль для регистрации внешних обработчиков сериализации:
import copyreg def pickle_cat_logger(obj): return CatLogger, (obj.filename,) copyreg.pickle(CatLogger, pickle_cat_logger)
Теперь все объекты CatLogger будут сериализоваться через вашу функцию, даже если в самом классе нет специальных методов. Удобно, когда нужно «научить» pickle работать с чужими классами, которые вы изменить не можете.
Риски и безопасность при работе с pickle
Вот мы и добрались до самой мрачной главы этой истории. Pickle — это как швейцарский нож: невероятно полезен, но может серьезно поранить, если обращаться с ним неосторожно. Основная проблема в том, что при десериализации pickle может выполнить произвольный код — а это открывает ворота для всевозможных атак.
Пример атаки (запуск команды через os.system)
Представьте, что вам прислали «безобидный» pickle-файл с данными. Вы, ничего не подозревая, загружаете его:
import pickle
import os
class MaliciousPayload:
def __reduce__(self):
# При десериализации выполнится команда
return os.system, ("echo 'Ваш компьютер взломан!'",)
# Злоумышленник сериализует вредоносный объект
malicious_data = pickle.dumps(MaliciousPayload())
# Вы невинно загружаете данные...
pickle.loads(malicious_data) # И тут же выполняется команда!
В реальности вместо безобидного echo может быть что угодно — от удаления файлов до установки бэкдоров. Метод __reduce__ позволяет указать любую функцию и аргументы для неё, превращая pickle в универсальный инструмент для Remote Code Execution.
Как обезопаситься: Unpickler.find_class, ограничение классов, использование токенов/подписей
К счастью, есть несколько способов укротить этого зверя:
import io
import builtins
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
# Разрешаем только безопасные встроенные типы
if module == "builtins" and name in {"list", "dict", "str", "int"}:
return getattr(builtins, name)
raise pickle.UnpicklingError(f"Запрещено: {module}.{name}")
def safe_loads(data):
return RestrictedUnpickler(io.BytesIO(data)).load()
Еще один подход — цифровая подпись данных с помощью HMAC. Если данные изменены злоумышленником, подпись не сойдется, и вы поймете, что что-то не так.
Золотое правило: никогда не загружайте pickle-данные из ненадежных источников. Для обмена данными с внешним миром используйте JSON, XML или другие безопасные форматы.
Расширенные возможности и лайфхаки
Когда базовый функционал pickle освоен, самое время заглянуть под капот и изучить несколько продвинутых трюков. Эти техники превращают обычную сериализацию в мощный инструмент для решения нетривиальных задач.
- Миграция версий классов с __version__ — добавьте в класс атрибут версии и обрабатывайте старые форматы в __setstate__:
class DataModel:
__version__ = 2
def __setstate__(self, state):
version = state.pop('__version__', 1)
if version == 1:
# Миграция со старой версии
state['new_field'] = 'default_value'
self.__dict__.update(state)
- Использование сжатия (модуль zlib) — большие объекты можно сжать для экономии места:
import zlib compressed = zlib.compress(pickle.dumps(huge_object)) restored = pickle.loads(zlib.decompress(compressed))
- pickletools для анализа байтов — этот модуль позволяет заглянуть внутрь сериализованных данных и понять, что именно происходит:
import pickletools
pickletools.dis(pickle.dumps({'key': 'value'}))
- Цифровая подпись (HMAC + hashlib) — защитите данные от подделки:
import hmac, hashlib
def sign_data(data, secret_key):
signature = hmac.new(secret_key, data, hashlib.sha256).digest()
return data + signature
def verify_and_load(signed_data, secret_key):
data, signature = signed_data[:-32], signed_data[-32:]
expected = hmac.new(secret_key, data, hashlib.sha256).digest()
if hmac.compare_digest(signature, expected):
return pickle.loads(data)
raise ValueError("Подпись не совпадает!")
Эти техники особенно полезны в продакшене, где нужна надежность, безопасность и совместимость между версиями приложения.
Когда pickle — не лучший выбор: обзор альтернатив
Pickle хорош, но не универсален. Иногда его специфичность для Python становится не преимуществом, а ограничением. Вот сравнение основных альтернатив — каждая со своими плюсами и подводными камнями:
| Формат | Преимущества | Недостатки | Поддержка объектов | Кросс-язычность |
|---|---|---|---|---|
| JSON | Человекочитаемый, быстрый, безопасный | Только базовые типы | dict, list, str, int, float, bool | Отличная |
| YAML | Читаемый, поддержка комментариев | Медленный, сложный парсинг | Расширяемая через теги | Хорошая |
| MessagePack | Компактный, быстрый | Бинарный формат | Базовые типы + расширения | Отличная |
| shelve | Персистентный словарь | Только dict-интерфейс | Любые pickle-совместимые | Только Python |
| pickle | Любые Python-объекты | Небезопасный, только Python | Максимальная | Никакая |
JSON стоит выбирать для API и конфигов — он безопасен и читается везде. MessagePack отлично подходит для высокопроизводительных приложений, где важен размер данных. YAML хорош для конфигурационных файлов, которые должны редактировать люди.
А pickle оставьте для внутренних нужд Python-приложений — кэширования, межпроцессного взаимодействия или сохранения состояния программы. Там, где безопасность под контролем, а совместимость с другими языками не требуется, он незаменим.
Правило простое: если данные покидают границы вашего Python-приложения — используйте что-то другое. Если остаются внутри — pickle справится отлично.
Часто задаваемые вопросы (FAQ)
Время разобраться с самыми популярными вопросами, которые возникают у разработчиков при работе с pickle. Некоторые ответы могут вас удивить (а некоторые — разочаровать).
Поддерживает ли pickle numpy/pandas?
Да, отлично работает с массивами NumPy и DataFrame из pandas. Но есть нюанс — для больших массивов лучше использовать специализированные форматы типа HDF5 или собственные методы сохранения этих библиотек.
Работает ли между версиями Python?
С оговорками. Файлы, созданные в Python 3.8+, могут не загрузиться в Python 3.7 из-за новых протоколов. Обратная совместимость обычно есть, но лучше тестировать. Используйте конкретный протокол вместо HIGHEST_PROTOCOL, если совместимость критична.
Какой формат весит меньше?
Зависит от данных. Pickle часто компактнее JSON для сложных структур, но проигрывает MessagePack. Для текстовых данных JSON может быть эффективнее. Хотите точности — измеряйте на ваших данных.
Как обезопасить load()?
Никак полностью. Можно ограничить доступные классы через кастомный Unpickler.find_class(), но стопроцентной защиты нет. Лучшая защита — не загружать pickle из ненадежных источников.
Можно ли сериализовать функции?
Локальные функции и лямбды — нет. Функции верхнего уровня — да, но восстановятся только если модуль доступен при загрузке. Для сериализации произвольного кода лучше использовать специализированные библиотеки типа dill.
Заключение
Pickle — это мощный, но коварный инструмент в арсенале Python-разработчика. Он отлично справляется с задачами кэширования, сохранения состояния и передачи сложных объектов внутри Python-экосистемы. Но помните: с большой силой приходит большая ответственность. Подведем итоги:
- Pickle сериализует любые Python-объекты. Это делает модуль универсальным для сохранения сложных структур данных.
- Поддерживает несколько протоколов сериализации. Используйте HIGHEST_PROTOCOL, если не требуется совместимость со старыми версиями Python.
- Загрузка pickle-файлов может быть небезопасна. Pickle способен выполнять произвольный код при десериализации.
- Существует защита от уязвимостей. Используйте кастомные Unpickler, ограничение классов и цифровые подписи.
- Не все объекты можно сериализовать напрямую. Для нестандартных объектов применяйте __getstate__, __reduce__ и copyreg.
- Есть альтернативы для других задач. JSON и MessagePack лучше подходят для обмена данными между системами.
- Pickle эффективен в пределах Python-приложений. Особенно полезен для кэширования, сохранения состояния и передачи данных между процессами.
Только начинаете осваивать профессию Python-разработчика? Рекомендуем обратить внимание на подборку курсов по Python-разработке. В них есть как теоретические блоки, так и практические задания — вы научитесь использовать pickle и альтернативы на практике.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.