Что такое распределённые транзакции и как они работают: протоколы, паттерны и практические решения
Распределённая транзакция представляет собой набор операций, выполняемых одновременно в нескольких независимых базах данных или системах, которые должны либо все успешно завершиться, либо все отменить свои изменения. Иными словами, это расширение классической концепции ACID-транзакций на распределённую среду, где данные хранятся не в одной, а в нескольких физически разделённых системах.

В традиционной ACID-транзакции (Atomicity, Consistency, Isolation, Durability — атомарность, согласованность, изоляция, надёжность) мы работаем с единой базой данных, которая самостоятельно гарантирует целостность операций. Однако современные микросервисные архитектуры, распределённые системы и облачные решения заставляют нас решать более сложную задачу: как обеспечить согласованность данных, когда каждый сервис владеет собственной базой данных и взаимодействует с другими через сеть?
Представьте классический сценарий электронной коммерции: клиент оформляет заказ. Эта, казалось бы, простая операция требует координации нескольких действий — списание средств со счёта покупателя, резервирование товара на складе, создание записи о заказе, начисление бонусных баллов. Если хотя бы один из этих шагов провалится (скажем, окажется, что средств недостаточно), все остальные операции должны быть отменены. В монолитной системе с единой базой данных это решается стандартной транзакцией. Но что делать, когда платёжный сервис, складской учёт и система лояльности — это три независимых микросервиса с собственными базами данных?
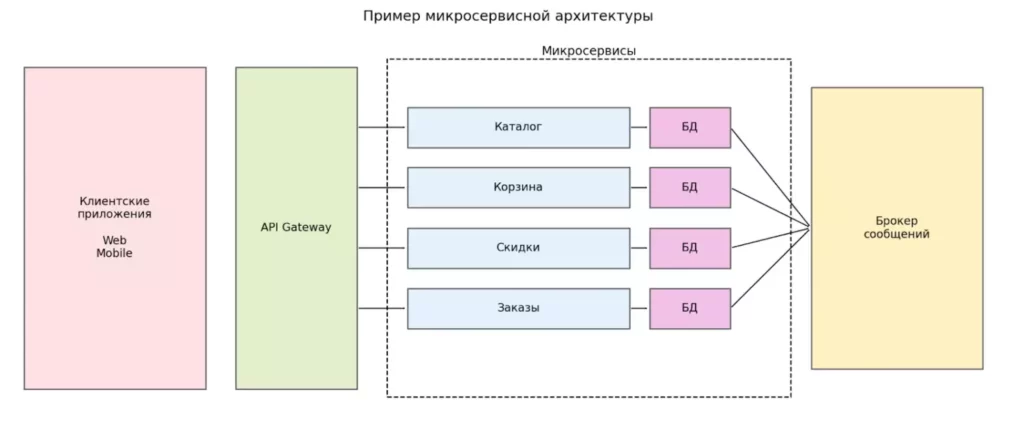
Схема показывает типичную микросервисную архитектуру с API Gateway и независимыми сервисами, каждый из которых владеет собственной базой данных.
Обмен событиями между сервисами осуществляется через брокер сообщений.
Именно такое разделение данных и ответственности приводит к необходимости распределённых транзакций и специальных паттернов согласованности.
Аналогичные проблемы возникают в банковских переводах между счетами в разных банках, бронировании авиабилетов (резервирование места, обработка платежа, начисление миль), системах здравоохранения, где данные пациента распределены между различными медицинскими учреждениями. Во всех этих случаях критически важно обеспечить консистентность данных — то самое состояние, когда вся система находится в логически корректном состоянии, и частичные обновления исключены.
- Почему распределённые транзакции сложны
- Классический подход: Two-Phase Commit (2PC)
- Улучшенный протокол: Three-Phase Commit (3PC)
- Архитектурные паттерны вместо распределённых транзакций
- Parallel Pipelines (параллельные пайплайны)
- Как выбрать подход к распределённым транзакциям
- Проблемы, подводные камни и best practices
- Заключение
- Рекомендуем посмотреть курсы по обучению DevOps
Почему распределённые транзакции сложны
Переход от монолитной архитектуры к распределённым системам кардинально меняет природу проблем, с которыми мы сталкиваемся. Если в рамках одной базы данных механизмы ACID-транзакций работают отлажено десятилетиями, то в распределённой среде каждый из этих принципов становится источником головной боли.
Основная сложность заключается в том, что между узлами системы существует сеть — ненадёжная, подверженная задержкам и разрывам связи среда передачи данных. Согласно знаменитой теореме CAP, в распределённой системе невозможно одновременно гарантировать консистентность (Consistency), доступность (Availability) и устойчивость к разделению сети (Partition tolerance) — приходится выбирать максимум два из трёх свойств. Это фундаментальное ограничение, которое невозможно обойти никакими техническими ухищрениями.
Проблема двойной записи (dual write problem)
Одной из ключевых проблем в микросервисной архитектуре является так называемая проблема двойной записи. Она возникает, когда один сервис должен атомарно выполнить две операции: обновить свою базу данных и уведомить другой сервис об этом изменении (например, через отправку сообщения в очередь или прямой вызов API).
Рассмотрим конкретный сценарий: микросервис А получает запрос от клиента, обновляет свою базу данных и должен уведомить микросервис Б о произошедших изменениях. Здесь возникает критическая дилемма:
- Если мы отправим сообщение сервису Б после записи в базу данных А, существует риск, что отправка прервётся из-за сетевого сбоя или падения приложения. В результате сервис Б останется в неконсистентном состоянии — он не узнает об изменениях.
- Если мы отправим сообщение перед записью в базу данных, возникает противоположная проблема: сообщение будет доставлено, но последующая запись в базу может провалиться, и сервис А окажется в неконсистентном состоянии.
Эта, казалось бы, простая задача не имеет тривиального решения в распределённой среде и требует применения специализированных паттернов.
Почему обычные ACID-транзакции не подходят в распределённой среде
ACID-транзакции прекрасно работают в рамках одной базы данных, но их механизмы не масштабируются на распределённую архитектуру. Вот основные причины:
- Блокировки и задержки. В классической транзакции база данных использует блокировки для обеспечения изоляции. В распределённой системе удержание блокировок на нескольких узлах во время выполнения сетевых запросов приводит к катастрофическому снижению производительности и пропускной способности.
- Координация и точки отказа. Для синхронизации распределённой транзакции требуется координатор— единая точка отказа, падение которой может заблокировать всю систему на неопределённое время.
- Сетевая ненадёжность. Каждый сетевой вызов может завершиться с ошибкой, зависнуть или вернуть результат с задержкой. В отличие от локальных операций в базе данных, где время выполнения предсказуемо, сетевые задержки могут варьироваться от миллисекунд до минут, что делает удержание транзакционных блокировок крайне проблематичным.
Классический подход: Two-Phase Commit (2PC)
Протокол двухфазной фиксации (Two-Phase Commit, 2PC) — это классическое решение для распределённых транзакций, разработанное ещё в 1970-х годах. Несмотря на почтенный возраст, этот протокол остаётся стандартом де-факто в системах, требующих строгой консистентности данных. Давайте разберёмся, как он работает и почему до сих пор применяется в критичных приложениях.
Как работает 2PC — фаза prepare и commit
Протокол двухфазной фиксации делит процесс выполнения распределённой транзакции на два последовательных этапа, что и отражено в его названии.
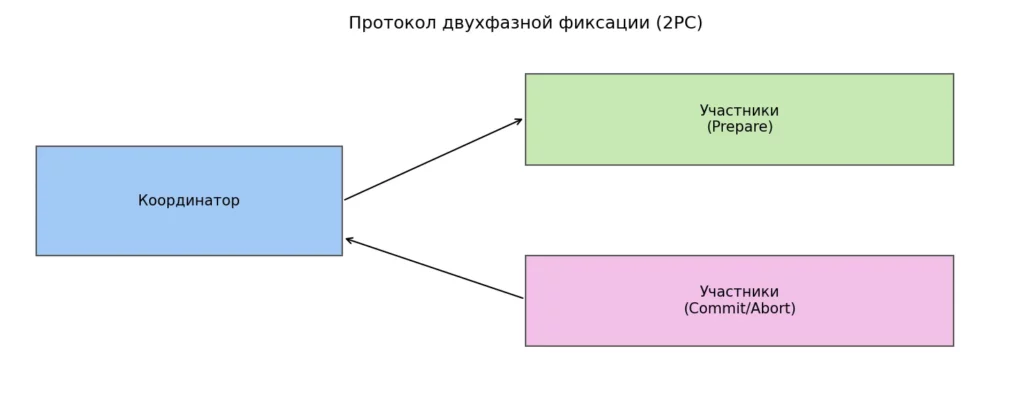
Иллюстрация показывает двухфазный процесс фиксации распределённой транзакции с участием координатора и нескольких узлов. Сначала выполняется фаза подготовки (prepare), затем — фиксация или откат (commit/abort). Центральная роль координатора делает протокол уязвимым к сбоям и блокировкам.
Фаза подготовки (Prepare Phase). На этом этапе координатор обращается к каждому участнику транзакции с вопросом: «Готов ли ты зафиксировать эти изменения?» Участники выполняют все необходимые проверки, захватывают блокировки на своих ресурсах, записывают изменения во временное хранилище (но ещё не применяют их окончательно) и отвечают координатору либо «Да, готов» (vote-commit), либо «Нет, не могу» (vote-abort).
Критически важный момент: если участник ответил «Да», он даёт гарантию, что сможет зафиксировать транзакцию независимо от последующих обстоятельств. По сути, участник берёт на себя обязательство и не может от него отказаться.
Фаза фиксации (Commit Phase). После получения ответов от всех участников координатор принимает окончательное решение. Если все участники проголосовали за фиксацию, координатор отправляет всем команду commit, и каждый участник применяет изменения окончательно. Если хотя бы один участник ответил отрицательно или не ответил вовремя, координатор отправляет команду abort, и все участники откатывают свои изменения.
Роль координатора и участников
В архитектуре 2PC центральная роль отводится координатору транзакций — специальному компоненту, который управляет всем процессом. Координатор ведёт надёжный журнал транзакций (transaction log), в который записывает каждое изменение состояния. Этот журнал критически важен для восстановления после сбоев.
Участники (ресурсные менеджеры) — это отдельные системы или базы данных, которые владеют частью данных транзакции. Каждый участник должен поддерживать протокол 2PC и уметь сохранять промежуточное состояние транзакции, чтобы в случае падения системы можно было корректно завершить или откатить операцию.
Проблемы 2PC: блокировки, зависания, отказ координатора
При всех достоинствах протокол 2PC обладает рядом существенных недостатков, которые делают его малопригодным для высоконагруженных и географически распределённых систем.
- Проблема блокировок. После голосования на фазе prepare участники захватывают блокировки и удерживают их до получения окончательного решения от координатора. Если координатор работает медленно или недоступен из-за сетевых проблем, участники могут оставаться заблокированными на неопределённое время, что катастрофически снижает пропускную способность системы.
- Единая точка отказа. Координатор — это узкое место всей архитектуры. Если координатор падает между фазами prepare и commit, участники оказываются в подвешенном состоянии: они проголосовали за фиксацию, захватили блокировки, но не знают, какое решение принял координатор. Для восстановления требуется либо дождаться возвращения координатора к жизни, либо применять ручное вмешательство.
- Низкая производительность. Протокол требует как минимум двух раундов сетевого взаимодействия между координатором и каждым участником, что приводит к высокой латентности, особенно в географически распределённых системах.
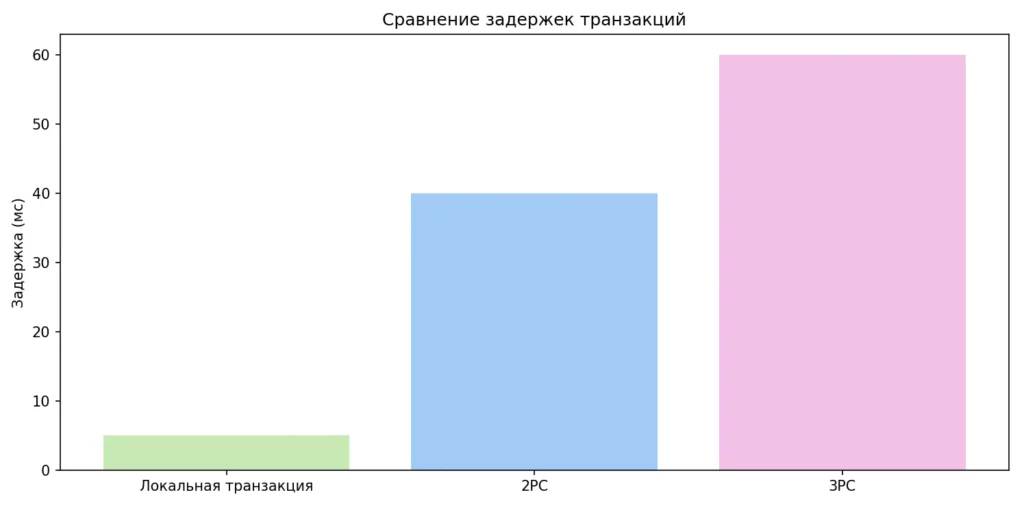
Диаграмма показывает разницу в задержках между локальной транзакцией, двухфазной (2PC) и трёхфазной фиксацией (3PC). Чем больше сетевых раундов требуется протоколу, тем выше общая латентность. Это наглядно объясняет, почему 2PC и 3PC плохо подходят для высоконагруженных систем.
Где применяется 2PC
Несмотря на ограничения, 2PC остаётся стандартным решением в корпоративных системах, где требуется строгая консистентность данных. Наиболее известная реализация — это XA-транзакции (eXtended Architecture), стандарт, разработанный консорциумом The Open Group.
XA-транзакции используются в системах планирования ресурсов предприятия (ERP), финансовых приложениях, системах обработки платежей — везде, где цена ошибки или несогласованности данных слишком высока. Для работы с XA требуются специализированные менеджеры транзакций (например, Narayana, Atomikos) и базы данных с поддержкой XA-драйверов. Важно отметить, что многие современные решения, такие как NoSQL-базы данных, не поддерживают XA-спецификацию, что ограничивает применимость 2PC в современных микросервисных архитектурах.
Улучшенный протокол: Three-Phase Commit (3PC)
Протокол трёхфазной фиксации (Three-Phase Commit, 3PC) был разработан как попытка решить проблему блокировок, присущую двухфазному коммиту. Основная идея заключается в добавлении промежуточной фазы между подготовкой и окончательной фиксацией, что позволяет участникам принимать решения даже в случае отказа координатора.
Три фазы 3PC: prepare → pre-commit → commit
В отличие от 2PC, трёхфазный протокол вводит дополнительный этап, разделяя процесс на три последовательные фазы.
- Фаза подготовки (Prepare Phase). Эта фаза идентична соответствующему этапу в 2PC — координатор опрашивает всех участников о готовности зафиксировать транзакцию. Участники выполняют проверки, захватывают необходимые ресурсы и отправляют свои голоса координатору.
- Фаза предварительной фиксации (Pre-Commit Phase). Здесь кроется ключевое отличие 3PC от 2PC. Если все участники проголосовали за фиксацию, координатор отправляет им команду pre-commit. Получив эту команду, участники переходят в специальное состояние готовности к фиксации, но ещё не применяют изменения окончательно. Важно: если участник не получает команду pre-commit в течение установленного таймаута, он автоматически прерывает транзакцию.
- Фаза фиксации (Commit Phase). После получения подтверждений о переходе в состояние pre-commit от всех участников, координатор отправляет окончательную команду commit, и участники применяют изменения.
Как pre-commit снижает вероятность блокировок
Фаза предварительной фиксации вносит критически важное изменение в логику протокола: она гарантирует, что если хотя бы один участник находится в состоянии pre-commit, значит, все остальные участники успешно завершили фазу подготовки.
Эта гарантия позволяет участникам принимать решения о завершении транзакции даже при отказе координатора. Если участник находится в состоянии pre-commit и не получает команду commit в течение таймаута, он знает, что все остальные участники тоже готовы к фиксации, и может безопасно применить изменения самостоятельно. Аналогично, если участник не получил команду pre-commit в установленное время, он может безопасно прервать транзакцию, зная, что другие участники либо тоже не получили эту команду, либо ещё не перешли в состояние готовности.
Введение таймаутов для каждой фазы позволяет избежать бесконечного ожидания и снижает риск долговременных блокировок ресурсов.
Ограничения 3PC
Несмотря на теоретические улучшения, трёхфазный коммит не получил широкого распространения в промышленной разработке. Основная причина — протокол делает сильное предположение об ограниченности задержек в сети и отсутствии разделений сети (network partitions). В реальных распределённых системах эти условия не всегда выполняются.
Если сеть разделяется на несколько изолированных сегментов, участники в разных сегментах могут принять противоречащие решения о судьбе транзакции, что приведёт к нарушению консистентности. Кроме того, 3PC добавляет ещё один раунд сетевого взаимодействия, что увеличивает латентность по сравнению с 2PC.
На практике, если требуется строгая консистентность данных, разработчики предпочитают использовать проверенный временем 2PC, а для более гибких сценариев обращаются к альтернативным паттернам, которые мы рассмотрим далее.
Архитектурные паттерны вместо распределённых транзакций
Строгие протоколы вроде 2PC и 3PC обеспечивают надёжную консистентность, но платой за это становится низкая производительность, сложность реализации и ограниченная масштабируемость. Современные микросервисные архитектуры всё чаще отказываются от распределённых транзакций в пользу альтернативных подходов, которые меняют саму постановку задачи. Вместо того чтобы гарантировать мгновенную консистентность, эти паттерны обеспечивают согласованность в конечном счёте (eventual consistency), что оказывается приемлемым компромиссом для многих бизнес-сценариев.
Модульный монолит
Прежде чем погружаться в сложные паттерны, стоит рассмотреть решение, которое формально не является микросервисным, но прекрасно работает на практике — модульный монолит. Этот подход предполагает, что несколько логически независимых сервисов развёртываются как отдельные модули в рамках единого приложения с доступом к общей базе данных.
Ключевое преимущество: поскольку оба сервиса работают в одном процессе и используют одну базу данных, они могут выполнять операции в рамках единой локальной транзакции, полностью избегая проблемы двойной записи. При этом модули остаются логически разделёнными — они могут использовать разные схемы данных, находиться в отдельных пакетах и поддерживаться разными командами.
Важная деталь реализации: создаётся сервис-обёртка, который координирует вызовы обоих модулей в рамках единой транзакции. Этот подход увеличивает связность между сервисами, но взамен даёт простую семантику транзакций и гарантированную консистентность данных.
Минусы: единый рантайм не позволяет независимо развёртывать и масштабировать модули, логическое разделение таблиц в базе данных может быть нарушено, отсутствует отказоустойчивость на уровне отдельных сервисов.
Модульный монолит подходит для случаев, когда строгая связь между компонентами важнее масштабируемости и независимости развёртывания.
SAGA — базовая идея
Паттерн SAGA радикально меняет подход к распределённым транзакциям. Вместо того чтобы пытаться выполнить все операции атомарно, SAGA разбивает долгоживущую транзакцию на последовательность локальных транзакций в каждом сервисе. Каждая локальная транзакция фиксируется независимо, а в случае сбоя на каком-либо этапе запускается цепочка компенсирующих транзакций, которые отменяют ранее выполненные действия.
Представьте процесс оформления заказа: создание заказа → резервирование товара → списание оплаты → начисление бонусов. В SAGA каждый из этих шагов выполняется и фиксируется отдельно. Если на этапе списания оплаты происходит ошибка, запускаются компенсации: отмена резервирования товара, удаление заказа. Критически важно, чтобы каждая операция имела соответствующую компенсирующую транзакцию.
SAGA Orchestration (оркестрация)
При оркестрации существует централизованный координатор (оркестратор), который управляет всем процессом. Оркестратор знает последовательность шагов транзакции, вызывает соответствующие сервисы, отслеживает их ответы и в случае ошибки запускает компенсирующие действия. Оркестратор хранит состояние всей транзакции в своей базе данных, что позволяет восстановиться после любых сбоев.
Популярные реализации включают BPMN-движки (Camunda, jBPM), специализированные фреймворки (Conductor от Netflix, Cadence от Uber, Temporal), serverless решения (AWS Step Functions, Azure Durable Functions) и библиотеки (Apache Camel Saga, NServiceBus Saga).
- Плюсы: централизованное управление состоянием, всегда можно узнать текущий статус транзакции, не требуются XA-транзакции.
- Минусы: сложная модель разработки, необходимость идемпотентных операций, согласованность в конечном счёте, возможны невосстанавливаемые ошибки при выполнении компенсаций.
SAGA Choreography (хореография)
Альтернативный подход — хореография, где отсутствует центральный координатор. Каждый сервис выполняет свою локальную транзакцию и публикует событие, которое запускает следующий шаг в других сервисах. Исторически это реализуется через асинхронный обмен сообщениями.
- Плюсы: отсутствие единой точки отказа, лучшая масштабируемость и независимость сервисов.
- Минусы: глобальное состояние транзакции распределено по участникам (сложно понять текущий статус), риск циклических зависимостей между сервисами.
Продвинутые варианты хореографии
- Хореография с двойной записью. Самый простой, но проблемный подход: сервис выполняет локальную транзакцию и отправляет сообщение в очередь. Возникает классическая проблема двойной записи — либо сообщение отправляется до коммита (и транзакция может откатиться), либо после (и отправка может провалиться).
- Хореография без двойной записи. Сервис А записывает данные в свою базу, а сервис Б периодически опрашивает базу данных А (или специальную таблицу-outbox) и забирает изменения. Недостаток: постоянное опрашивание создаёт нагрузку, повышается связность между сервисами.
- Хореография через Debezium / CDC. Более элегантное решение: инструмент Change Data Capture (например, Debezium) отслеживает транзакционный лог базы данных и автоматически публикует изменения в брокер сообщений (Apache Kafka). Сервисы-потребители подписываются на соответствующие топики. Это паттерн Transactional Outbox в действии.
- Хореография через Event Sourcing. При Event Sourcing состояние сущности хранится как последовательность событий. Запись события в append-only хранилище выполняется атомарно в рамках локальной транзакции, а само хранилище выступает как шина сообщений для других сервисов. Подход добавляет сложность, но решает проблему двойной записи элегантно.
Parallel Pipelines (параллельные пайплайны)
Все рассмотренные выше паттерны предполагают последовательную обработку запроса — один сервис завершает свою работу, затем управление передаётся следующему. Однако в реальных системах нередко возникает ситуация, когда один и тот же запрос должен обрабатываться несколькими независимыми сервисами параллельно, без прямой зависимости между ними.
Представьте систему аналитики, где входящее событие должно одновременно записаться в хранилище для долгосрочного анализа, попасть в поток реального времени для дашбордов и быть обработано системой рекомендаций. Эти три операции логически независимы и могут выполняться параллельно, что значительно снижает общую латентность обработки.
Router-based pipelines
В этом варианте между исходным сервисом и сервисами-получателями добавляется специальный компонент — роутер (router), который принимает запрос и распределяет его копии нескольким сервисам в рамках одной транзакции. Роутер гарантирует, что сообщение будет доставлено всем получателям, но не контролирует успешность их обработки — каждый сервис работает со своей локальной транзакцией независимо.
Этот подход обеспечивает простую масштабируемую архитектуру для параллельной обработки, особенно когда между целевыми сервисами нет связей и не требуется координация их результатов.
Listen-to-yourself pattern
Альтернативный вариант — один из сервисов сам выступает в роли роутера. Получив запрос, сервис А публикует событие в брокер сообщений, откуда это событие считывается как самим сервисом А, так и остальными заинтересованными сервисами. Такой подход устраняет необходимость в отдельном компоненте-роутере и упрощает архитектуру.
Паттерн получил название «слушай себя» (listen-to-yourself), поскольку сервис подписывается на собственные события. Это решение особенно удобно при использовании систем обмена сообщениями с гарантией доставки, таких как Apache Kafka.
- Плюсы: простота реализации, естественная масштабируемость, отсутствие координационных накладных расходов.
- Минусы: сложно определить текущее состояние системы в конкретный момент времени, отсутствие гарантий согласованности между параллельными потоками обработки.
Parallel Pipelines подходят для сценариев, где важнее пропускная способность и скорость обработки, чем строгая согласованность, а также когда между обрабатывающими сервисами отсутствуют взаимные зависимости.
Как выбрать подход к распределённым транзакциям
Разнообразие паттернов, которые мы рассмотрели, может вызвать вполне закономерный вопрос: как определить, какой подход подходит для конкретной задачи? К сожалению, универсального ответа не существует — выбор зависит от множества факторов, включая требования бизнеса, архитектурные ограничения и готовность команды мириться с определённым уровнем сложности.
Требования к консистентности
Первый и наиболее важный критерий — насколько критична мгновенная консистентность данных для вашего бизнеса. Если речь идёт о финансовых транзакциях, где недопустимы даже временные расхождения в балансах счетов, или о системах бронирования, где двойная продажа одного и того же ресурса недопустима, — строгая консистентность обязательна. В таких случаях стоит рассматривать 2PC или модульный монолит.
Если же временная несогласованность допустима (например, в системах аналитики, рекомендаций или уведомлений), можно использовать SAGA с её согласованностью в конечном счёте. Многие современные приложения прекрасно функционируют с eventual consistency, особенно если компенсирующие транзакции могут исправить любые временные аномалии.
Масштабируемость
Протоколы строгой консистентности (2PC, 3PC) плохо масштабируются из-за необходимости координации и удержания блокировок. Если ваша система должна обрабатывать тысячи транзакций в секунду или работать в географически распределённой инфраструктуре, эти подходы создадут узкие места.
Для высоконагруженных систем предпочтительны хореография или Parallel Pipelines, которые позволяют сервисам работать независимо и масштабироваться горизонтально. Оркестрация занимает промежуточное положение — она масштабируется лучше 2PC, но требует наличия достаточно производительного координатора.
Независимость сервисов
Если одна из ключевых целей архитектуры — обеспечить независимое развёртывание и эволюцию сервисов, модульный монолит и 2PC будут плохим выбором. Эти подходы тесно связывают сервисы, затрудняя их независимую разработку и развёртывание.
SAGA (особенно хореография) и Parallel Pipelines обеспечивают слабую связность: сервисы взаимодействуют через события и не знают о деталях реализации друг друга. Это даёт командам свободу выбора технологий и темпа развития.
Задержки и доступность
Согласно теореме CAP, в условиях разделения сети приходится выбирать между консистентностью и доступностью. Протоколы 2PC и 3PC жертвуют доступностью в пользу консистентности — при сетевых проблемах система может стать недоступной.
Паттерны eventual consistency (SAGA, Event Sourcing) предпочитают доступность: система продолжает принимать запросы даже при частичных сбоях, хотя временная несогласованность возможна.
Где лучше 2PC, где — SAGA, где — Event Sourcing
- 2PC и модульный монолит: финансовые системы, платёжные процессоры, системы управления критичными ресурсами (бронирование билетов, медицинские записи), корпоративные ERP-системы, где цена ошибки высока, а нагрузка умеренная.
- Оркестрация SAGA: системы электронной коммерции, процессы обработки заказов, долгоживущие бизнес-процессы с участием пользователя, сценарии, где нужна видимость состояния транзакции.
- Хореография SAGA: событийно-ориентированные архитектуры, высоконагруженные системы с множеством слабо связанных сервисов, потоковая обработка данных.
- Event Sourcing: системы аудита, где критична история изменений, финансовый учёт, аналитические платформы, сценарии с необходимостью воспроизведения состояния.
- Parallel Pipelines: системы аналитики реального времени, обработка событий IoT, логирование и мониторинг, сценарии с независимыми потребителями данных.
| Подход | Консистентность | Масштабируемость | Сложность | Независимость сервисов | Применение |
|---|---|---|---|---|---|
| Модульный монолит | Строгая | Низкая | Низкая | Низкая | Малые системы, строгая консистентность |
| 2PC/XA | Строгая | Низкая | Высокая | Низкая | Финансы, критичные транзакции |
| 3PC | Строгая | Низкая | Очень высокая | Низкая | Редко используется |
| Оркестрация SAGA | Eventual | Средняя | Средняя | Средняя | E-commerce, бизнес-процессы |
| Хореография SAGA | Eventual | Высокая | Высокая | Высокая | Событийные системы, высокая нагрузка |
| Parallel Pipelines | Eventual | Высокая | Низкая | Высокая | Аналитика, независимые потребители |
Проблемы, подводные камни и best practices
Теоретическое понимание паттернов распределённых транзакций — лишь половина успеха. На практике разработчики сталкиваются с целым рядом неочевидных проблем, которые могут превратить элегантную архитектуру в источник бесконечных багов и инцидентов.
- Отладка SAGA. Пожалуй, самая болезненная проблема — это отладка распределённых транзакций, особенно в паттернах хореографии. Когда состояние транзакции распределено между множеством сервисов, а каждый сервис знает только о своей части процесса, понять, что пошло не так и на каком именно этапе, становится нетривиальной задачей. Представьте ситуацию: клиент жалуется, что заказ не оформился, деньги списались, но товар не зарезервирован. Где искать проблему? В каком сервисе произошёл сбой? Был ли запущен процесс компенсации?
- Решение требует инвестиций в инфраструктуру наблюдаемости. Необходимо внедрить correlation ID — уникальный идентификатор, который передаётся через все сервисы и позволяет связать логи разных компонентов в единую цепочку. Distributed tracing (OpenTelemetry, Jaeger, Zipkin) становится не роскошью, а необходимостью — без него отследить путь транзакции через десятки микросервисов практически невозможно.
- Идемпотентность операций. В распределённых системах сообщения могут доставляться повторно из-за сетевых проблем или перезапусков сервисов. Если операция не идемпотентна, повторная обработка одного и того же сообщения приведёт к ошибкам — деньги спишутся дважды, товар зарезервируется в двойном количестве. Каждая операция в SAGA должна быть спроектирована так, чтобы её повторное выполнение с теми же параметрами не меняло конечный результат. Это требует хранения информации об уже обработанных запросах (паттерн idempotency key) и тщательной проработки логики каждого шага.
- Циклы событий. При использовании хореографии легко создать ситуацию, когда событие от сервиса А запускает обработку в сервисе Б, который публикует событие, снова попадающее в сервис А, и так по кругу. Такие циклические зависимости не только усложняют понимание системы, но и могут привести к бесконечным циклам обработки. Предотвращение требует тщательного проектирования событийной модели и явного контроля за направлением потоков данных.
- Тестирование распределённых процессов. Как протестировать SAGA, которая затрагивает пять различных микросервисов? Поднять все сервисы в тестовом окружении? Использовать моки? Ни один из подходов не является идеальным. Contract testing (Pact, Spring Cloud Contract) помогает проверить совместимость интерфейсов между сервисами, но не гарантирует корректность сквозного процесса. Chaos engineering — намеренное введение сбоев в тестовой среде — становится важным инструментом для проверки устойчивости системы к частичным отказам.
- Мониторинг и трассировка. Без надлежащего мониторинга распределённые транзакции превращаются в чёрный ящик. Необходимо отслеживать не только технические метрики (латентность, количество ошибок), но и бизнес-метрики — сколько транзакций находятся в процессе выполнения, сколько завершились с компенсацией, каков средний путь успешной транзакции. Дашборды должны показывать не просто «что сломалось», а «где именно в цепочке произошёл сбой и какие действия были предприняты».
Заключение
Мы рассмотрели широкий спектр подходов к решению проблемы распределённых транзакций — от классических протоколов вроде 2PC до современных архитектурных паттернов SAGA и Event Sourcing. Подведем итоги:
- Распределенные транзакции это способ обеспечить согласованность данных между несколькими сервисами. Они позволяют избежать частичных обновлений при сбоях в сложных системах.
- Классические ACID-транзакции не подходят для распределённой среды. Сетевые задержки, блокировки и точки отказа делают их плохо масштабируемыми.
- Протоколы 2PC и 3PC обеспечивают строгую консистентность. Однако они снижают доступность и производительность системы.
- Паттерн SAGA предлагает альтернативный подход через локальные транзакции и компенсации. Он лучше подходит для микросервисной архитектуры.
- Event Sourcing, CDC и Parallel Pipelines помогают решать проблему двойной записи. Эти подходы делают систему более устойчивой и масштабируемой.
- Выбор подхода зависит от требований к консистентности, масштабируемости и доступности. Универсального решения для всех сценариев не существует.
Если вы только начинаете осваивать профессию backend-разработчика, рекомендуем обратить внимание на подборку курсов по Devops. В них есть теоретическая и практическая часть, которая помогает разобраться в распределённых транзакциях и архитектурных паттернах на реальных примерах.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
114 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 мая
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
DevOps-инженер
|
Нетология
46 отзывов
|
Цена
101 800 ₽
226 321 ₽
с промокодом kursy-online
|
От
3 143 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 апреля
|
Подробнее |
|
Профессия DevOps-инженер
|
Skillbox
232 отзыва
|
Цена
161 751 ₽
323 502 ₽
Ещё -20% по промокоду
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
23 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
102 отзыва
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Профессия DevOps-инженер PRO
|
Skillbox
232 отзыва
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
6 месяцев
|
Старт
23 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.