Что такое SRE и как он влияет на бизнес
Site Reliability Engineering (SRE) — Это инженерный способ управлять IT-системами так, чтобы они работали стабильно и могли расти без сбоев. Проще говоря, SRE помогает уйти от постоянного «тушения пожаров»: вместо того чтобы каждый раз срочно чинить проблемы, команды заранее предотвращают их, автоматизируют рутинные задачи и могут больше времени уделять развитию и новым идеям.

Представьте себе инженеров стабильности — специалистов, которые не просто следят за тем, чтобы системы работали, но и проектируют их так, чтобы они автоматически справлялись с проблемами.
- Чем SRE отличается от классической эксплуатации
- Зачем бизнесу нужен SRE: влияние на деньги, стабильность и рост
- Как внедрить SRE: пошаговый план для компаний
- Метрики эффективности SRE: как понять, что всё работает
- Ключевые принципы: на чём стоит подход
- SLI, SLO, SLA: как измеряется надёжность
- Error Budget: как управлять рисками и скоростью разработки
- Методы и практики SRE
- Инструменты: что используют инженеры
- Заключение
- Рекомендуем посмотреть курсы по кибербезопасности
Чем SRE отличается от классической эксплуатации
Ключевое отличие от традиционного подхода к эксплуатации инфраструктур заключается в философии. Классические сисадмины реагируют на проблемы по мере их возникновения — система упала, нужно срочно её восстановить. SRE-инженеры, напротив, работают на опережение: они создают механизмы, которые либо предотвращают проблемы, либо позволяют инфраструктуре самостоятельно восстанавливаться.
Главная идея
Цель — обеспечить надёжность, масштабируемость и эффективность при сохранении скорости разработки и внедрения инноваций. Важно понимать: Site Reliability Engineering не стремится к идеальной стопроцентной безотказности — это дорого и невозможно. Вместо этого подход определяет разумный уровень надёжности, который удовлетворяет потребности бизнеса и пользователей.
Когда ваш бизнес теряет $10,000 за каждую минуту простоя, разница между 99% и 99,99% доступности становится критически важной. Site Reliability Engineering помогает найти баланс между стабильностью сервисов и необходимостью быстро выпускать новые функции, не задушив инновации избыточными требованиями к надёжности.
В современном мире 73% компаний из списка Fortune 500 имеют выделенные SRE-команды, а рынок инструментов для SRE оценивается в $35 миллиардов. Возникает закономерный вопрос: как этот подход может трансформировать вашу IT-инфраструктуру и какие практические выгоды он принесёт бизнесу?
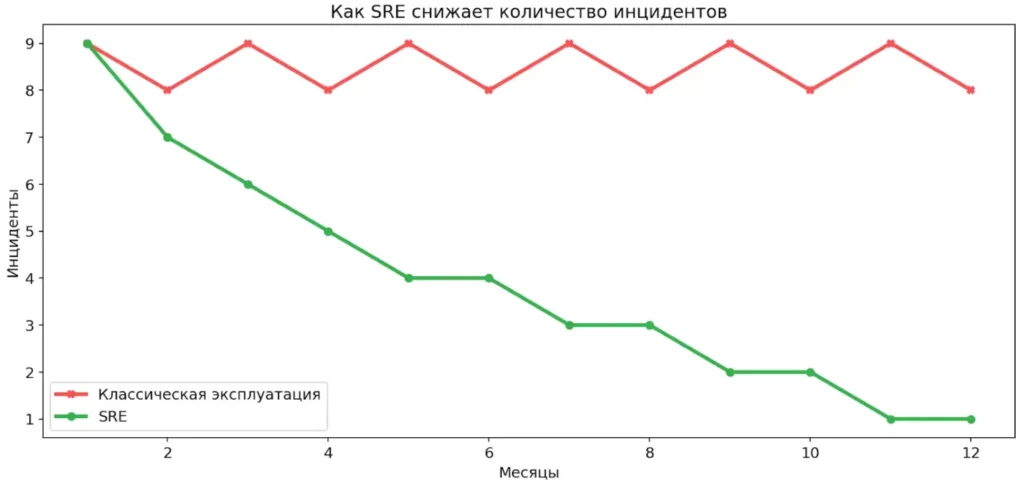
График показывает разницу в динамике инцидентов. При реактивной эксплуатации сбои повторяются из месяца в месяц. SRE позволяет системно снижать их количество со временем.
Зачем бизнесу нужен SRE: влияние на деньги, стабильность и рост
Когда речь заходит о внедрении новых подходов в IT, первый вопрос, который задают руководители — какую конкретную ценность это принесёт бизнесу? В случае с SRE ответ измеряется в деньгах, удовлетворённости клиентов и способности компании расти без технических ограничений.
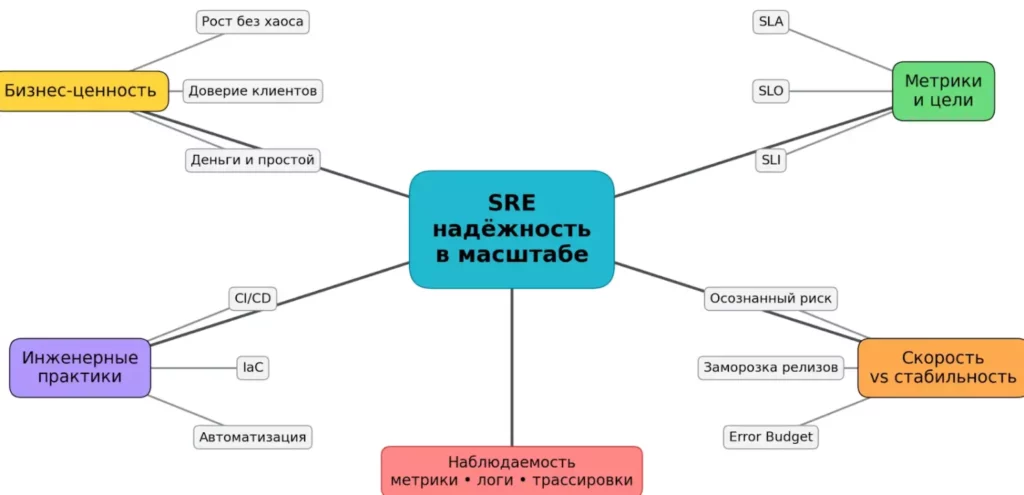
Эта майнд-карта показывает SRE как точку баланса между бизнес-целями и инженерными практиками. С одной стороны — деньги, рост и доверие клиентов, с другой — метрики, автоматизация и контроль рисков. Внизу объединяющим слоем выступает наблюдаемость, без которой SRE не работает.
Почему стабильность систем критична для бизнеса
Представим ситуацию: ваш интернет-магазин падает на час в пятницу вечером — в пик продаж. Каждая минута простоя означает потерянные заказы, разочарованных клиентов и репутационный ущерб, который не измерить простой арифметикой. Согласно исследованиям, средняя стоимость простоя для крупного e-commerce проекта составляет от $5,000 до $10,000 в минуту. Для финтех-сервисов эта цифра может быть ещё выше.
Но дело не только в прямых финансовых потерях. Когда инфраструктура нестабильна, команда разработки вынуждена постоянно тушить пожары вместо того, чтобы создавать новые функции. Это замедляет развитие продукта и снижает конкурентоспособность компании на рынке.
Разница между 99% и 99,99% доступности
На первый взгляд разница в 0,99% кажется незначительной. Однако давайте посмотрим, что это означает на практике:
- 99% доступности = 7,2 часа простоя в месяц (около 3,5 дней в год).
- 99,9% доступности = 43 минуты простоя в месяц (примерно 8,7 часов в год).
- 99,99% доступности = 4,3 минуты простоя в месяц (около 52 минут в год).
Для пользователя, который зашёл на сайт в момент недоступности, не имеет значения, что система работала 99% времени — он столкнулся со сбоем именно сейчас. Каждый дополнительный «девять» в показателе доступности требует значительных инвестиций, но для критичных сервисов эти вложения полностью оправданы.
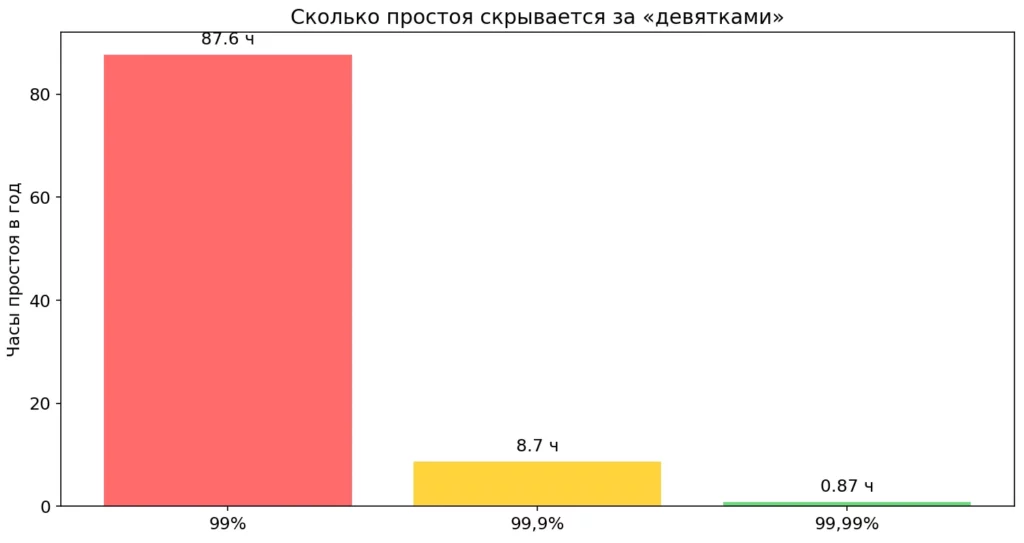
Каждый дополнительный «девять» радикально снижает простой сервиса. На диаграмме видно, что разница измеряется десятками часов в год. Для бизнеса это прямые деньги и доверие пользователей.
Влияние на удовлетворённость клиентов
Пользователи не прощают нестабильность. Если ваше приложение регулярно зависает или работает медленно, клиенты просто уйдут к конкурентам — особенно в условиях высококонкурентного рынка. Site Reliability Engineering обеспечивает предсказуемое качество сервиса, что напрямую влияет на user perceived quality — воспринимаемое пользователями качество.
Когда система стабильна, клиенты доверяют вашему продукту. Это особенно критично для финансовых сервисов, платформ электронной коммерции и SaaS-решений, где любой сбой может привести к оттоку пользователей.
Баланс между скоростью развития и стабильностью
Один из главных конфликтов в IT — противоречие между желанием быстро выпускать новые функции и необходимостью поддерживать стабильность. Разработчики хотят экспериментировать и внедрять инновации, операционные команды боятся, что каждое изменение может «что-то сломать».
SRE решает эту проблему через концепцию Error Budget (бюджет ошибок). Если инфраструктура работает лучше целевого показателя надёжности, у команды есть «запас прочности» для экспериментов и быстрых релизов. Если бюджет ошибок исчерпан — релизы замораживаются до тех пор, пока надёжность не будет восстановлена. Это создаёт прозрачный механизм принятия решений и улучшает взаимоотношения между командами разработки и эксплуатации.
Конкретные выгоды SRE для бизнеса:
- Снижение операционных расходов на 23% за счёт автоматизации.
- Уменьшение количества критических сбоев на 50%.
- Сокращение времени восстановления после инцидентов на 70%.
- Повышение производительности инженеров на 37%.
- Увеличение частоты релизов при сохранении стабильности.
Данные показывают, что компании, успешно внедрившие SRE-практики, получают конкурентное преимущество через повышенную надёжность при одновременном снижении операционных затрат. Вопрос уже не в том, стоит ли внедрять SRE, а в том, как сделать это максимально эффективно с учётом специфики вашей организации и бизнес-целей.
Как внедрить SRE: пошаговый план для компаний
Шаг 1. Оценить готовность и зрелость процессов
Прежде чем бросаться внедрять, необходимо честно оценить текущее состояние организации. SRE не работает в вакууме — он требует определённого фундамента.
Критические предпосылки для SRE:
- Культура. Организация должна быть готова к открытому обсуждению проблем без поиска виноватых. Если в компании принято наказывать за ошибки, постмортемы превратятся в формальность, а инженеры будут скрывать инциденты вместо того, чтобы учиться на них.
- CI/CD. Должны существовать автоматизированные процессы сборки и развёртывания. Если каждый релиз требует ручных действий дюжины людей, внедрение error budget и частых итераций будет невозможным.
- Базовый мониторинг. Необходим хотя бы минимальный мониторинг ключевых систем. Невозможно определить SLO, если вы не знаете, какова текущая доступность и производительность сервисов.
Если этих элементов нет — начните с них. Попытка внедрить SRE в хаотичную среду без базовых процессов обречена на провал.
Шаг 2. Определить критичные сервисы
Не пытайтесь внедрять везде одновременно — это гарантированный путь к выгоранию команды и разочарованию руководства. Вместо этого определите 2-3 критически важных сервиса, где внедрение даст максимальный эффект.
Критерии выбора:
- Высокая бизнес-важность (сервис напрямую влияет на выручку или репутацию).
- Частые инциденты или жалобы пользователей на нестабильность.
- Активное развитие (регулярные релизы новых функций).
- Достаточная техническая зрелость команды, работающей с сервисом.
Например, для e-commerce компании это может быть сервис корзины и оформления заказа. Для SaaS-платформы — API, через который работают клиентские приложения.
Шаг 3. Выбрать и настроить SLI/SLO
Определение правильных метрик — это искусство, требующее баланса между амбициозностью и реалистичностью.
Какие метрики лучше использовать:
- Ориентируйтесь на пользовательский опыт. SLI должны отражать то, что важно для пользователей, а не для инженеров. Загрузка CPU сервера — плохой SLI. Время ответа API с точки зрения клиента — хороший SLI.
- Начните консервативно. Лучше установить достижимый SLO и постепенно повышать планку, чем поставить недостижимую цель в 99,99% и постоянно её нарушать. Проанализируйте текущую производительность за последние 3-6 месяцев и установите SLO чуть лучше среднего показателя.
- Используйте перцентили, а не средние значения. 95-й или 99-й перцентиль времени отклика лучше отражает реальный опыт пользователей, чем среднее значение, которое скрывает проблемы с выбросами.
Примеры начальных SLO:
- 99,5% успешных запросов к API за месяц.
- 95-й перцентиль времени отклика < 500 мс.
- Доступность веб-интерфейса 99,9% времени.
Шаг 4. Внедрить мониторинг и наблюдаемость
Без качественного мониторинга вы не сможете ни измерить достижение SLO, ни быстро реагировать на инциденты.
Что нужно реализовать:
- Сбор метрик в реальном времени (Prometheus, VictoriaMetrics или аналоги).
- Централизованное хранение и анализ логов (ELK, Loki).
- Трассировка запросов в распределённых системах (Jaeger, Zipkin).
- Дашборды для визуализации ключевых метрик (Grafana).
- Настройка алертов для критических отклонений.
Важно: не создавайте алерты на всё подряд. Каждый должен требовать действия. Если он не приводит к немедленному реагированию, это не алерт, а информационное уведомление.
Шаг 5. Автоматизировать рутинные задачи
Составьте список операций, которые команда выполняет регулярно вручную, и начните методично их автоматизировать.
Примеры задач для автоматизации:
- Развёртывание приложений через CI/CD пайплайны.
- Автоматическое масштабирование при росте нагрузки.
- Ротация логов и очистка устаревших данных.
- Резервное копирование критичных данных.
- Обновление зависимостей и патчей безопасности.
Начните с наиболее часто повторяющихся и трудоёмких задач. Даже автоматизация одной операции, которая выполняется ежедневно и занимает час, высвободит 20+ часов в месяц.
Шаг 6. Ввести культуру постмортемов
Постмортемы — это не просто формальность, а ключевой механизм обучения организации.
Как проводить эффективные разборы:
- Назначьте ответственного за документирование инцидента сразу после его завершения.
- Проведите встречу всех причастных в течение 48 часов, пока детали свежи в памяти.
- Фокусируйтесь на системных проблемах, а не на людях..
- Определите конкретные action items с ответственными и дедлайнами.
- Сделайте постмортемы публично доступными внутри компании для распространения знаний.
Хороший постмортем отвечает на три вопроса: что произошло, почему это произошло, как мы предотвратим повторение.
Шаг 7. Масштабировать практики на другие сервисы
Когда первые пилотные сервисы демонстрируют успех — сокращение инцидентов, улучшение доступности, снижение времени восстановления — можно начинать расширение.
Когда можно расширять:
- Команда уверенно работает с SLO и error budget.
- Постмортемы стали регулярной практикой.
- Уровень автоматизации превышает 50%.
- Есть измеримые улучшения в метриках надёжности.
Не торопитесь. Лучше медленно, но качественно распространить практики на новые области, чем быстро и поверхностно «внедрить» SRE везде, получив формальное соблюдение без реальных результатов.
Чек-лист готовности к внедрению SRE:
- Поддержка руководства и выделенный бюджет.
- Базовая автоматизация CI/CD.
- Минимальный мониторинг критичных систем.
- Культура, допускающая открытое обсуждение ошибок.
- Выбраны 2-3 пилотных сервиса.
- Определены начальные SLI/SLO.
- Назначены ответственные за внедрение.
- Запланированы регулярные ретроспективы прогресса.
Метрики эффективности SRE: как понять, что всё работает
Давайте разберём ключевые метрики, которые позволяют объективно оценить эффективность SRE-подхода.
MTTR и MTBF: время — деньги
MTTR (Mean Time To Recovery) — среднее время восстановления после инцидента. Эта метрика показывает, насколько быстро команда способна вернуть инфраструктуру в рабочее состояние после сбоя.
- Что показывает: эффективность процессов реагирования на инциденты, качество мониторинга и наблюдаемости, зрелость команды в диагностике проблем.
- Желаемый тренд: снижение. Если год назад среднее время восстановления составляло 2 часа, а сейчас — 15 минут, это прямое свидетельство улучшения. Зрелые SRE-команды стремятся к MTTR в пределах минут, а не часов.
MTBF (Mean Time Between Failures) — среднее время между сбоями. Показывает, как часто происходят инциденты.
- Что показывает: общую стабильность системы, эффективность превентивных мер, качество архитектурных решений.
- Желаемый тренд: увеличение. Если инциденты происходят всё реже, инфраструктура становится более надёжной. Хороший показатель — когда MTBF измеряется неделями или месяцами, а не днями.
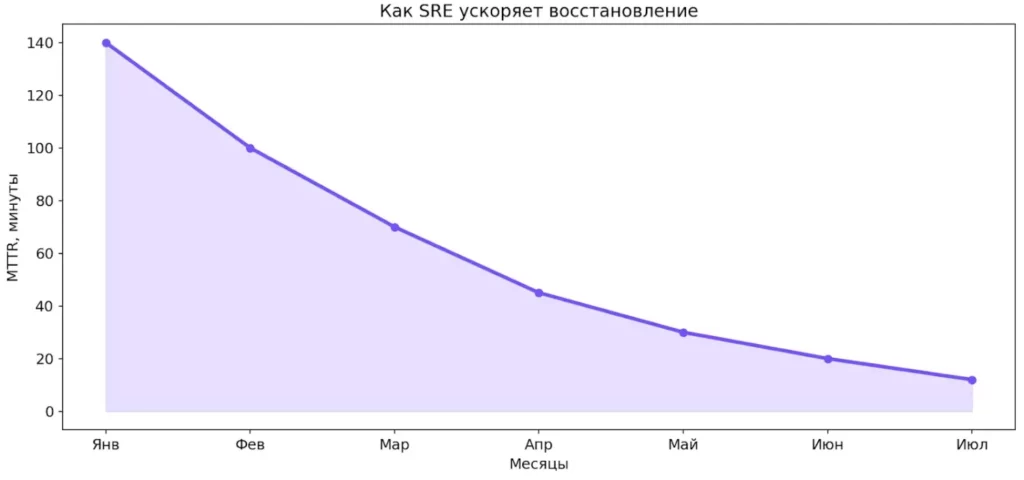
Диаграмма показывает устойчивое снижение MTTR по мере зрелости SRE-практик. Инциденты остаются неизбежными, но время восстановления сокращается в разы. Это снижает финансовые и репутационные потери.
Количество и серьёзность инцидентов
Простой, но важный показатель: сколько инцидентов происходит и насколько они критичны.
Что отслеживать:
- Общее количество инцидентов за период.
- Распределение по уровням опасности (критические, высокие, средние).
- Процент инцидентов, которые повторяются (recurring incidents).
Желаемый тренд: снижение общего количества и особенно критических инцидентов. Если количество повторяющихся инцидентов уменьшается — это означает, что постмортемы работают и команда действительно учится на ошибках.
Процент автоматизации и доля Toil
SRE-философия предполагает постоянное сокращение рутинной работы через автоматизацию.
- Процент автоматизации: доля задач, которые выполняются без участия человека. Например, если из 100 деплоев в месяц 95 происходят автоматически через CI/CD, процент автоматизации — 95%.
- Доля Toil: процент рабочего времени инженера, затрачиваемый на рутинные, повторяющиеся операции.
- Что показывает: насколько эффективно команда использует своё время. Если инженеры тратят 80% времени на ручные операции, они не занимаются улучшением системы — они просто поддерживают status quo.
- Желаемый тренд: процент автоматизации растёт, доля Toil снижается. Целевой показатель по Toil — не более 50%, а в идеале — 30% или меньше.
Частота релизов при сохранении стабильности
Один из парадоксов: правильное внедрение не замедляет разработку, а ускоряет её.
Что измеряется:
- Количество релизов в производственную среду за период.
- Процент успешных релизов (без rollback).
- Среднее время от коммита до продакшена (lead time).
Что показывает: баланс между скоростью инноваций и стабильностью. Если частота релизов растёт, но доступность не падает (или даже растёт) — SRE работает правильно.
Желаемый тренд: увеличение частоты релизов при стабильной или улучшающейся надёржности. Это прямое доказательство того, что error budget и SLO помогают находить правильный баланс.
Удовлетворённость пользователей (User Perceived Quality)
В конечном счёте, вся работа SRE должна улучшать опыт пользователей.
Как измерять:
- NPS (Net Promoter Score) — готовность пользователей рекомендовать продукт.
- CSAT (Customer Satisfaction Score) — удовлетворённость конкретными взаимодействиями.
- Количество жалоб на производительность или недоступность.
- Процент успешных пользовательских сессий.
Что показывает: реальное влияние технической надёжности на бизнес-результаты. Можно иметь идеальные внутренние метрики, но если пользователи недовольны — что-то работает неправильно.
Желаемый тренд: рост удовлетворённости и снижение жалоб, связанных с техническими проблемами.
Сводная таблица метрик
| Метрика | Что показывает | Желаемый тренд |
|---|---|---|
| MTTR | Скорость восстановления после инцидентов | ↓ Снижение (минуты вместо часов) |
| MTBF | Частота возникновения инцидентов | ↑ Увеличение (недели/месяцы между сбоями) |
| Количество инцидентов | Общая стабильность систем | ↓ Снижение, особенно критических |
| Процент автоматизации | Доля автоматизированных операций | ↑ Увеличение (стремление к 90%+) |
| Доля Toil | Время на рутинные задачи | ↓ Снижение (целевое значение <50%) |
| Частота релизов | Скорость доставки изменений | ↑ Увеличение при сохранении надёжности |
| Процент успешных релизов | Качество процесса деплоя | ↑ Увеличение (стремление к 95%+) |
| User Perceived Quality | Удовлетворённость пользователей | ↑ Рост NPS/CSAT, снижение жалоб |
Как часто измерять и анализировать
Метрики бессмысленны без регулярного анализа. Рекомендуемая практика:
- Оперативные метрики (MTTR, текущие инциденты) — отслеживаются в реальном времени.
- Тактические метрики (доля Toil, процент автоматизации) — анализируются еженедельно или ежемесячно.
- Стратегические метрики (MTBF, пользовательская удовлетворённость) — оцениваются ежемесячно или ежеквартально.
Важно не просто собирать цифры, а использовать их для принятия решений. Если MTTR растёт — пора инвестировать в улучшение мониторинга. Если доля Toil не снижается — нужно выделить время на автоматизацию. Данные без действий — это просто красивые графики.
Ключевые принципы: на чём стоит подход
Site Reliability Engineering представляет собой не просто набор инструментов или методик, а фундаментальный сдвиг в подходе к управлению надёжностью систем. В основе этой дисциплины лежат несколько ключевых принципов, которые определяют философию и практику работы SRE-инженеров. Давайте разберёмся, на чём именно стоит этот подход.
Принцип 1. Надёжность как продукт
Первый и, пожалуй, главный принцип SRE звучит парадоксально: не нужно стремиться к идеальной надёжности. Стопроцентная доступность — это не только дорого, но и невозможно. Более того, она может быть даже вредна для бизнеса.
Ключевая мысль здесь в том, что надёжность — это не абстрактная цель, а конкретная характеристика продукта, которая должна соответствовать бизнес-требованиям. Если система стабильна и ошибок меньше допустимого, можно добавлять новые функции. Если сбоев слишком много — сначала чинят их, потом добавляют функции. Это превращает надёжность в измеримую и управляемую величину.
Принцип 2. Автоматизация рутинных задач (борьба с Toil)
В терминологии SRE существует понятие Toil — рутинная работа, которая обладает несколькими характеристиками: она повторяющаяся, не требует интеллектуального анализа, может быть автоматизирована и растёт линейно с развитием сервиса.
Почему рутина — враг масштабирования? Потому что если для поддержки десяти серверов нужен один инженер, то для ста серверов потребуется десять человек — при условии, что вся работа выполняется вручную. Это линейное масштабирование операционных затрат делает рост дорогим и неустойчивым.
SRE-подход предполагает автоматизацию всего, что делается чаще двух раз. Машины лучше справляются с монотонной работой, где человеку проще ошибиться. Инженер должен писать инструментарий и скрипты для освобождения головы и рук для других, более интересных и полезных задач. Всё время «тушить пожар» руками из ведра — не лучшая стратегия.
Принцип 3. Инженерный подход к эксплуатации
Site Reliability Engineering возводит эксплуатацию инфраструктур в ранг инженерной дисциплины, применяя к ней те же стандарты, что и к разработке программного обеспечения. Это означает концепцию «эксплуатация как код» (Operations as Code) — когда конфигурация инфраструктуры, процессы развёртывания и управления описываются в виде кода, хранящегося в системе контроля версий.
Построение процессов с той же строгостью, что и разработка, предполагает: код-ревью для изменений в инфраструктуре, тестирование конфигураций перед применением, версионирование всех изменений и возможность быстрого отката. Если раньше системный администратор мог зайти на сервер и «подкрутить что-то руками», то в SRE-культуре любое изменение должно быть воспроизводимым, документированным и контролируемым.
Этот принцип устраняет «человеческий фактор» и делает инфраструктуру предсказуемой и управляемой, превращая операционную деятельность из искусства в науку.
Принцип 4. Непрерывный мониторинг и наблюдаемость (Observability)
Невозможно управлять тем, что не можешь измерить. Site Reliability Engineering базируется на трёх столпах наблюдаемости: логи, метрики и трассировки.
- Логи предоставляют детальную информацию о событиях в инфраструктуре — что произошло, когда и в каком контексте.
- Метрики дают количественные показатели состояния системы: загрузка CPU, время отклика, количество ошибок.
- Трассировки позволяют отследить путь конкретного запроса через распределённую систему, выявляя узкие места и проблемные компоненты.
Наблюдаемость играет критическую роль в быстром восстановлении после инцидентов. Когда инфраструктура падает, каждая секунда на счету. Если у вас нет чёткой картины того, что происходит внутри системы, вы будете тратить драгоценное время на поиск причины проблемы. Хорошо настроенный мониторинг позволяет не сидеть сутками у монитора в ожидании проблем, а получать автоматические уведомления и быстро локализовать инциденты.
Принцип 5. Анализ инцидентов и постмортемы
Инциденты неизбежны — это факт. Важно не то, что они случаются, а то, как организация на них реагирует и какие уроки извлекает.
Извлечение уроков и их документирование создают базу знаний, которая помогает предотвращать повторение аналогичных проблем. В правильно выстроенной культуре постмортемы становятся ценным источником обучения для всей команды, способствуя постоянному совершенствованию процессов и систем.
Эти пять принципов формируют фундамент Site Reliability Engineering-подхода, превращая операционную деятельность из хаотичной борьбы с проблемами в организованный, измеримый и постоянно совершенствующийся процесс инженерного управления надёжностью.
SLI, SLO, SLA: как измеряется надёжность
Если SRE — это инженерный подход к надёжности, то ему необходим точный язык для описания того, что именно считается «надёжным». Здесь на сцену выходят три ключевые аббревиатуры: SLI, SLO и SLA. Они формируют иерархию метрик, которая позволяет объективно измерять и управлять надёжностью систем.
Что такое SLI — конкретные метрики
Service Level Indicator (SLI) — это конкретная метрика, которая измеряет определённый аспект уровня обслуживания. Простыми словами, SLI отвечает на вопрос: «Что именно мы измеряем, чтобы понять, насколько хорошо работает наш сервис?»
Примеры хороших SLI:
- Доля успешных HTTP-запросов (например, с кодом ответа 200-299 vs все запросы).
- Время отклика API (например, 95-й перцентиль времени ответа должен быть меньше 200 мс).
- Доступность системы (процент времени, когда она отвечает на запросы).
Важно, что SLI должны быть измеримыми, объективными и напрямую связанными с пользовательским опытом. Бессмысленно измерять загрузку CPU сервера, если это не влияет на то, как быстро пользователи получают ответы от системы.
Что такое SLO — целевые уровни доступности
Service Level Objective (SLO) — это целевое значение или диапазон значений для SLI, которого команда обязуется достичь. Если SLI — это то, что мы измеряем, то SLO — это цель, к которой мы стремимся.
Например:
- «99,9% HTTP-запросов должны завершаться успешно за месяц».
- «95% запросов должны обрабатываться за время менее 200 мс».
- «Система должна быть доступна 99,95% времени в квартал».
SLO определяет «достаточную» надёжность, о которой мы говорили ранее. Это договорённость между командой разработки, Site Reliability Engineering и бизнесом о том, какой уровень качества сервиса приемлем. Если инфраструктура работает лучше SLO — отлично, у команды есть запас для экспериментов. Если хуже — нужно срочно заняться стабилизацией.
SLA — договорной уровень для клиентов
Service Level Agreement (SLA) — это формальное соглашение с клиентами о гарантированном уровне обслуживания, которое обычно включает последствия за его нарушение. SLA — это юридический документ с финансовыми обязательствами.
Критически важно понимать: SLA всегда должно быть менее строгим, чем внутренний SLO. Если ваш SLO — 99,9%, то SLA может быть 99,5%. Этот запас даёт команде возможность отреагировать на проблемы до того, как они приведут к нарушению обязательств перед клиентами и финансовым штрафам.
Разница между тремя аббревиатурами
| Аббревиатура | Что означает | Зачем нужна |
|---|---|---|
| SLI | Конкретная метрика, измеряющая аспект качества сервиса | Объективное измерение фактического состояния системы |
| SLO | Целевое значение SLI, внутренняя цель команды | Определение приемлемого уровня надёжности и границ для принятия решений |
| SLA | Договорное обязательство перед клиентами с санкциями за нарушение | Юридическая гарантия уровня обслуживания для внешних потребителей |
Примеры хороших и плохих SLI/SLO
Хорошие SLI/SLO:
- «95-й перцентиль времени ответа API должен быть ≤ 300 мс» — конкретно, измеримо, связано с пользовательским опытом.
- «99,9% запросов на вход в систему должны завершаться успешно» — чётко определено, что считается успехом.
- «Система доступна 99,95% времени, измеренная через синтетический мониторинг каждые 60 секунд» — ясный способ измерения.
Плохие SLI/SLO:
- «Система должна работать быстро» — субъективно, неизмеримо.
- «Стремимся к минимуму ошибок» — нет конкретной цели.
- «100% доступность» — нереалистично и контрпродуктивно.
- «Среднее время отклика < 100 мс» — использование среднего значения скрывает проблемы с выбросами.
Правильно выбранные SLI и SLO становятся основой для принятия инженерных решений: когда можно выкатывать новые функции, когда нужно сосредоточиться на стабильности, какие компоненты инфраструктуры требуют оптимизации. Они превращают абстрактное понятие «надёжности» в конкретные, измеримые цели, достижение которых можно отслеживать и улучшать.
Error Budget: как управлять рисками и скоростью разработки
Одна из самых элегантных концепций Site Reliability Engineering — это Error Budget, или бюджет ошибок. Именно этот механизм разрешает вечный конфликт между командами разработки, стремящимися к быстрым релизам и инновациям, и операционными командами, озабоченными стабильностью систем.

Site Reliability Engineering — это совместная работа людей из разных ролей: разработки, эксплуатации, бизнеса и SRE. Команда вокруг сервиса обеспечивает стабильность, контролирует риски и помогает системе расти без сбоев. Надёжность становится результатом согласованных решений, а не работы одного отдела.
Что такое бюджет ошибок
Бюджет ошибок — это «лимит сбоев», который можно потратить за определённый период времени без нарушения SLO. Математически он вычисляется просто: это разница между идеальной доступностью (100%) и целевым показателем SLO.
Допустим, ваш SLO — 99,9% доступности в месяц. Это означает, что у вас есть 0,1% времени, когда система может быть недоступна — примерно 43 минуты в месяц. Эти 43 минуты и есть ваш error budget. Вы можете «потратить» их на эксперименты, быстрые релизы новых функций или рискованные изменения в инфраструктуре.
Как бюджет помогает не «задушить инновации» ради надёжности
Традиционный подход к эксплуатации часто превращается в бесконечное «нет». Хотите выкатить новую функцию? Нет, это рискованно. Хотите провести эксперимент с новой технологией? Нет, инфраструктура и так работает стабильно, зачем рисковать?
Error budget переворачивает эту логику. Пока бюджет не исчерпан — команда имеет полную свободу экспериментировать и быстро выпускать изменения. Если система работает стабильнее, чем требует SLO, значит, мы слишком консервативны и теряем возможности для инноваций.
Этот подход создаёт объективный критерий для принятия решений: не «кажется, это рискованно», а «у нас есть 20 минут error budget на этот месяц, можем себе позволить этот релиз».
Когда замораживают релизы
Механизм работает и в обратную сторону. Если бюджет ошибок исчерпан — все новые релизы приостанавливаются до тех пор, пока надёжность не будет восстановлена. В этот период команда сосредотачивается исключительно на стабилизации: устранении багов, оптимизации узких мест, улучшении мониторинга.
Правила использования error budget:
- Измеряется объективно — на основе реальных метрик, а не субъективных ощущений.
- Обновляется регулярно — обычно помесячно или поквартально.
- Распространяется на всех — и разработчиков, и SRE-инженеров.
- Запускает автоматические действия — при исчерпании бюджета вступают в силу заранее определённые правила.
Как механизм улучшает отношения Dev–Ops–SRE
Error budget превращает конфликт между скоростью и стабильностью в совместную работу над общей целью. Разработчики понимают: если они выпускают недостаточно протестированный код, который приводит к сбоям, это съедает общий бюджет и замедляет всех. Site Reliability Engineering-инженеры, в свою очередь, понимают: если они чрезмерно консервативны и система работает слишком стабильно, команда упускает возможности для роста.
Мини-пример использования:
Компания установила SLO в 99,95% доступности для своего API. В начале месяца error budget составлял 21 минуту. После первого релиза произошёл инцидент длительностью 8 минут — осталось 13 минут бюджета. Команда выпустила ещё два релиза без проблем. К концу третьей недели случился ещё один сбой на 15 минут — бюджет исчерпан с отрицательным балансом.
Решение: все запланированные релизы заморожены. Команда проводит ретроспективу инцидентов, выявляет общие паттерны проблем, улучшает автоматизированное тестирование и мониторинг. Только после того, как в следующем месяце система демонстрирует стабильность и бюджет восстанавливается, возобновляются активные релизы.
Такой подход устраняет взаимные обвинения и создаёт культуру совместной ответственности за качество продукта. Вопрос больше не стоит как «кто виноват», а как «что мы можем улучшить в системе, чтобы подобное не повторилось».
Методы и практики SRE
Принципы Site Reliability Engineering выглядят убедительно на бумаге, но как они реализуются в повседневной работе? Давайте разберём конкретные методы и практики, которые SRE-инженеры применяют для обеспечения надёжности инфраструктур.
Автоматизация рутинных процессов
Автоматизация — это не просто удобство, а необходимость для масштабирования. Site Reliability Engineering-инженеры систематически выявляют задачи, которые выполняются вручную, и заменяют их автоматизированными решениями.
Что автоматизируют в первую очередь:
- Развёртывание приложений и обновлений инфраструктуры.
- Масштабирование ресурсов в зависимости от нагрузки.
- Резервное копирование и восстановление данных.
- Обработку типовых инцидентов и алертов.
- Ротацию сертификатов и учётных данных.
Чем измеряется уровень Toil:
SRE-команды отслеживают, какой процент рабочего времени тратится на рутинные операции. Целевой показатель — не более 50% времени на Toil, а в идеале — значительно меньше. Если инженер тратит 80% времени на ручные операции, это сигнал о необходимости срочной автоматизации.
Наблюдаемость: метрики, логи, трассировки
Невозможно обеспечить надёжность того, что не видишь. Наблюдаемость — это способность понимать внутреннее состояние системы на основе её внешних выходных данных.
Метрики предоставляют количественные показатели в реальном времени: загрузку CPU, использование памяти, количество запросов в секунду, время отклика, процент ошибок. Они позволяют быстро оценить общее состояние инфраструктуры и выявить аномалии.
Логи дают детальный контекст о событиях: что произошло, когда, в какой последовательности, с какими параметрами. Они незаменимы при расследовании инцидентов, когда нужно восстановить полную картину произошедшего.
Трассировки показывают путь конкретного запроса через распределённую систему, позволяя понять, где именно возникает задержка или ошибка. Это особенно критично в микросервисных архитектурах, где один пользовательский запрос может проходить через десятки различных сервисов.
Подход к алертам: не всё, что можно измерить, должно вызывать алерты. SRE-практика предполагает настройку уведомлений только для ситуаций, требующих немедленного реагирования и влияющих на пользователей. Избыточные алерты приводят к «усталости от уведомлений», когда инженеры начинают игнорировать сигналы даже о реальных проблемах.
Инфраструктура как код (IaC)
Инфраструктура как код означает описание всех компонентов — серверов, сетей, баз данных, балансировщиков нагрузки — в виде конфигурационных файлов, которые хранятся в системе контроля версий.
Это даёт несколько критически важных преимуществ:
- Репликация окружений. Можно автоматически создать идентичную копию production-среды для тестирования или разработки. Больше никаких ситуаций «у меня на машине работало».
- Управляемость. Все изменения в инфраструктуре проходят через процесс код-ревью, так же как и изменения в коде приложения. Это предотвращает случайные ошибки и создаёт audit trail — след всех модификаций.
- Быстрое восстановление. Если что-то сломалось, можно откатиться к предыдущей рабочей версии конфигурации буквально одной командой.
Хаос-инжиниринг и стресс-тестирование
Зрелые Site Reliability Engineering-команды не ждут, пока система сломается в продакшене. Они намеренно вводят сбои в контролируемых условиях, чтобы проверить устойчивость системы и готовность команды к реагированию.
Зачем вводят искусственные сбои:
- Проверить, что механизмы отказоустойчивости действительно работают.
- Выявить узкие места и слабые звенья в архитектуре до того, как они проявятся в реальном инциденте.
- Тренировать команду реагировать на нестандартные ситуации.
- Убедиться, что мониторинг обнаруживает проблемы достаточно быстро.
Популярные практики: случайное отключение серверов в продакшене (принцип Chaos Monkey от Netflix), симуляция перегрузки сети, искусственное увеличение задержек между сервисами, имитация отказа целых дата-центров. Звучит страшно? Возможно. Но лучше обнаружить проблему в контролируемом эксперименте, чем в три часа ночи во время реального инцидента.
Управление инцидентами
Когда, несмотря на все меры предосторожности, происходит инцидент, критически важна организованная система реагирования.
- On-call дежурства. SRE-инженеры работают по графику on-call, когда они доступны для реагирования на критические инциденты в любое время суток. Правильно организованная система on-call включает чёткую эскалацию, справедливую ротацию и компенсацию за дежурства.
- Эскалация. Не все инциденты одинаковы. Простые проблемы решает дежурный инженер самостоятельно. Сложные требуют привлечения экспертов по конкретным системам. Критические могут потребовать созыва всей команды и уведомления руководства.
- MTTR (Mean Time To Recovery) — среднее время восстановления — ключевая метрика эффективности управления инцидентами. Зрелые Site Reliability Engineering-команды стремятся не к полному отсутствию инцидентов (что нереалистично), а к минимизации времени их устранения. Разница между восстановлением за 5 минут и за 2 часа может означать миллионы потерянной выручки.
Эти методы и практики превращают SRE из абстрактной философии в конкретный набор действий, которые ежедневно обеспечивают надёжность современных IT-систем.
Инструменты: что используют инженеры
Современная экосистема SRE включает десятки специализированных решений для мониторинга, автоматизации, управления инцидентами и анализа систем. Давайте разберёмся, какие инструменты составляют арсенал инженера.
| Категория | Инструмент | Что делает |
|---|---|---|
| Мониторинг метрик | Prometheus | Сбор и хранение метрик в формате временных рядов, гибкий язык запросов PromQL |
| VictoriaMetrics | Высокопроизводительная альтернатива Prometheus с меньшими требованиями к ресурсам | |
| Zabbix | Комплексная система мониторинга инфраструктуры и приложений | |
| Datadog | Облачная платформа для мониторинга с развитой аналитикой | |
| Визуализация | Grafana | Создание дашбордов и визуализация метрик из различных источников |
| Grafana Mimir | Долгосрочное хранилище метрик, совместимое с Prometheus | |
| Сбор и анализ логов | Elasticsearch | Поисковый движок для хранения и анализа больших объёмов логов |
| Logstash | Сбор, обработка и передача логов в различные системы хранения | |
| Fluentd | Унифицированный сборщик логов с гибкой маршрутизацией | |
| Grafana Loki | Система логирования, оптимизированная для работы с метриками | |
| Splunk | Коммерческая платформа для анализа машинных данных и логов | |
| APM и Observability | Dynatrace | Автоматический мониторинг производительности приложений с AI-аналитикой |
| New Relic | Платформа для наблюдения за полным стеком приложений | |
| OpenTelemetry | Открытый стандарт для сбора телеметрии (метрики, логи, трассировки) | |
| Jaeger | Распределённая трассировка запросов в микросервисных архитектурах | |
| Zipkin | Система трассировки для выявления проблем с задержками | |
| Incident Response | PagerDuty | Управление инцидентами, алертинг и эскалация on-call дежурств |
| OpsGenie | Платформа для управления алертами и координации команды при инцидентах | |
| Grafana OnCall | Открытое решение для on-call дежурств и управления инцидентами | |
| Infrastructure as Code | Terraform | Декларативное описание и управление инфраструктурой в различных облаках |
| Pulumi | IaC с возможностью использования обычных языков программирования | |
| Ansible | Автоматизация конфигурирования и управления серверами | |
| Puppet | Система управления конфигурациями для больших инфраструктур | |
| Kubernetes | Оркестрация контейнеризированных приложений | |
| Контроль версий | Git | Стандарт для версионирования кода и конфигураций |
| Chaos Engineering | Chaos Monkey | Случайное отключение экземпляров сервисов для проверки устойчивости |
| Gremlin | Платформа для контролируемого внедрения сбоев в системы | |
| Alerting | Alertmanager | Обработка и маршрутизация алертов из Prometheus |
Как выбирать инструменты
Важно понимать: не существует универсального набора инструментов, подходящего для всех. Выбор зависит от множества факторов — размера инфраструктуры, бюджета, технической экспертизы команды, требований к масштабируемости.
Небольшой стартап может начать с бесплатного стека: Prometheus для метрик, Grafana для визуализации, ELK (Elasticsearch, Logstash, Kibana) для логов. Крупная корпорация с критически важными сервисами может инвестировать в коммерческие решения вроде Datadog или Dynatrace, которые предлагают готовую интеграцию, поддержку и расширенную аналитику.
Заключение
Мы прошли длинный путь — от базовых концепций до конкретных практик внедрения и метрик эффективности. Пришло время подвести итоги и ответить на главный вопрос: какое место занимает SRE в современной IT-индустрии и стоит ли вашей компании двигаться в этом направлении?
- SRE — это инженерный подход к надёжности. Он позволяет управлять стабильностью систем через метрики, автоматизацию и измеримые цели.
- Надёжность в SRE рассматривается как часть продукта. Команды заранее определяют допустимый уровень сбоев и принимают решения на основе данных.
- SRE помогает бизнесу снижать простои и потери. За счёт сокращения инцидентов и ускорения восстановления сервисы работают предсказуемо.
- Ключевую роль в подходе играют SLI, SLO и error budget. Эти инструменты помогают находить баланс между скоростью развития и стабильностью.
- Эффективное внедрение SRE требует культуры, автоматизации и мониторинга. Без базовых процессов подход не даёт ожидаемого результата.
Если вы только начинаете осваивать профессию SRE-инженера, рекомендуем обратить внимание на подборку курсов по кибербезопасности. В них есть теоретическая и практическая часть, которые помогут разобраться в метриках, надёжности и реальных сценариях работы.
Рекомендуем посмотреть курсы по кибербезопасности
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Специалист по кибербезопасности
|
Eduson Academy
110 отзывов
|
Цена
145 900 ₽
|
От
12 158 ₽/мес
0% на 24 месяца
19 047 ₽/мес
|
Длительность
6 месяцев
|
Старт
26 марта
Вт, Чт, 19:00-22:00 по МСК
|
Подробнее |
|
Кибербезопасность
|
Нетология
46 отзывов
|
Цена
245 000 ₽
|
От
300 ₽/мес
|
Длительность
22 месяца
|
Старт
1 марта
|
Подробнее |
|
Профессия Специалист по кибербезопасности
|
Skillbox
226 отзывов
|
Цена
178 274 ₽
356 547 ₽
Ещё -20% по промокоду
|
От
5 751 ₽/мес
Без переплат на 31 месяц с отсрочкой платежа 6 месяцев.
|
Длительность
12 месяцев
|
Старт
27 февраля
|
Подробнее |
|
Кибербезопасность
|
ЕШКО
19 отзывов
|
Цена
4 352 ₽
5 800 ₽
|
От
1 088 ₽/мес
1 450 ₽/мес
|
Длительность
4 месяца
|
Старт
26 февраля
|
Подробнее |

SQL-индексы: что это и как правильно применять в базе данных
Зачем нужны индексы в SQL и почему они могут как ускорить, так и замедлить работу базы? В статье — разбор всех видов индексов, практические советы и примеры кода.

Ntopng — что это, зачем нужен и как установить: полный гид
Хотите понять, как работает ntopng и почему его выбирают администраторы? Мы покажем, как этот инструмент помогает контролировать сеть, выявлять угрозы и строить аналитику без лишней сложности.

Как составить контент-стратегию: пошаговый план и практические советы
Что нужно, чтобы ваша контент-стратегия работала? В этой статье мы рассмотрим ключевые этапы: от постановки целей до постоянного анализа результатов.

Формулы для расчета дней в Excel — от простого к продвинутому
Формулы для Excel могут сбивать с толку: то выходные не учтены, то даты читаются как текст. Разбираемся, как рассчитать количество дней в экселе без ошибок — и с пользой.