Data Engineer с нуля: почему «строители данных» стали важнее модных ML-моделей
Когда компании говорят о внедрении AI, разговор обычно крутится вокруг моделей: какая точнее, какая дешевле, GPT или собственная разработка. Но в реальных проектах история чаще заканчивается иначе: модель обучена, деньги потрачены, дедлайн сорван — а бизнес-результата нет. Причина, как правило, не в алгоритме. Информация пришла с задержкой. Или оказалась грязной. Или лежит в трёх разных системах и никто не договорился, какая версия правильная.
На практике выходит так: ML-проект тормозит не там, где думают. Узкое место — не модель, а инфраструктура данных. Именно здесь появляется фигура, о которой до недавнего времени говорили меньше, чем о Data Scientist или ML Engineer. Data Engineer — специалист, который строит системы: собирает информацию из источников, очищает её, организует хранение, настраивает доставку туда, где она нужна — в аналитику, дашборды, ML-пайплайны, AI-сервисы.

Мы не будем доказывать, что Дата инженер «важнее» всех остальных. Это был бы удобный заголовок, но неточный тезис. Важнее другое: без надёжной инфраструктуры данных ML-проекты часто не доходят до результата — и именно это объясняет, почему спрос на инженеров растёт вместе с AI-бумом, а не вопреки ему.
В этой статье мы разберём, кто такой Data Engineer, чем его работа отличается от работы аналитика или ML-инженера, что нужно учить с нуля, как выбрать курс без ловушек хайпа и стоит ли новичку вообще идти в эту сторону.
- Кто такой Data Engineer и почему без него не работает AI
- Что должен знать Data Engineer с нуля
- Как стать Дата инженером с нуля: дорожная карта обучения
- Как выбрать курс Data Engineer и не попасть в ловушку хайпа
- Для кого подойдут короткие, длинные и карьерные программы
- Data Engineering vs ML: что выбрать новичку
- Зарплаты, спрос и карьерные перспективы Data Engineer
- Итог: кому подходит профессия Data Engineer
- FAQ. Частые вопросы о профессии Data Engineer
- Рекомендуем посмотреть курсы по Data Engineering
Кто такой Data Engineer и почему без него не работает AI
Если спросить десять человек, кто строит AI-продукты, девять назовут Data Scientist или ML Engineer. Это понятно: они работают с моделями, делают красивые демо, публикуют результаты. Дата инженер в этой картине остаётся за кадром — он не строит модели, не рисует графики точности и не презентует результаты бизнесу. Он строит то, без чего всё остальное не работает.
Чем занимается Data Engineer простыми словами
Если попробовать описать профессию одним абзацем без технического жаргона, получится примерно так: Дата инженер проектирует, строит и поддерживает системы, которые берут информацию из одного места и доставляют её в другое — в нужном виде, в нужное время, без потерь и ошибок.
На практике это выглядит как набор конкретных задач. Подключить источник информации — например, выгрузку из CRM, лог сервера или поток событий из мобильного приложения. Спроектировать базу или хранилище, где эта информация будет жить. Написать процесс загрузки и трансформации — ETL или ELT. Настроить расписание: чтобы обновления шли не когда вспомнят, а автоматически и по графику. Контролировать качество: проверять, что пришло нужное количество записей, нет дублей, форматы совпадают. Следить за тем, что пайплайн не упал — а если упал, быстро найти причину.
Это инженерная работа в полном смысле слова: много системного мышления, внимания к деталям, понимания, как сломается то, что ты построил.
Почему ML-модель бесполезна без данных, пайплайнов и инфраструктуры
Есть удобная аналогия, которая хорошо передаёт суть. Если ML-модель — это двигатель, то Дата инженер строит дороги, топливную систему и всю логистику вокруг. Двигатель может быть отличным. Но если топливо загрязнено, трубопровод течёт, а поставки нерегулярны — автомобиль не поедет.
Амит Дхармапурикар (эксперт по данным): «В любом серьезном enterprise AI-проекте есть три слоя. Первый — AI-инфраструктура (GPU, модели), он уже профинансирован. Второй — AI-governance (правила и ограничения), он активно развивается. Третий — AI data readiness (непрерывное обнаружение, очистка и подготовка данных на уровне всей компании). Это именно тот слой, которого отчаянно не хватает, и без которого первые два просто не работают. Вы не можете управлять тем, что не очищено и не структурировано».
ML-модель требует данных — регулярных, чистых, согласованных и доступных. Если они приходят с задержкой в несколько часов, модель рекомендательной системы работает на вчерашней картине мира. Если в потоке есть систематическая ошибка — например, часть транзакций теряется при выгрузке — модель обучается на неполной выборке и даёт смещённые предсказания. Если сведения из разных источников не согласованы между собой — бизнес получает цифры, которые невозможно сравнить.
Рост интереса к AI и LLM-продуктам эту проблему не устранил — он её усилил. Компании, которые раньше обходились простой аналитикой, теперь строят AI-пайплайны, векторные хранилища, системы RAG, потоковую обработку событий. Всё это требует не только алгоритмов, но и надёжной инфраструктуры: governance данных, мониторинга, контроля доступа, масштабируемости. Именно поэтому спрос на Data Engineer растёт вместе с AI-бумом, а не отдельно от него.
Data Engineer, Data Analyst, Data Scientist и ML Engineer: кто за что отвечает
Путаница между этими ролями — нормальная история для новичка. Названия похожи, задачи пересекаются, в разных компаниях границы проведены по-разному. Вот короткое разграничение, которое помогает не запутаться:
| Роль | Главная задача | С какими данными работает | Ключевые инструменты | Результат работы | Кому подходит |
| Data Engineer | Строит инфраструктуру данных | Сырые, любые источники | SQL, Python, Airflow, Spark, облака | Пайплайны, хранилища, витрины | Любит системы, автоматизацию, инженерные задачи |
| Data Analyst | Анализирует данные, строит отчёты | Подготовленные сведения | SQL, Excel, BI-инструменты | Дашборды, отчёты, выводы | Любит работу с числами, бизнес-контекст |
| Data Scientist | Ищет закономерности, строит модели | Чистые, размеченные выборки | Python, R, Jupyter, sklearn | Модели, прогнозы, инсайты | Любит статистику, эксперименты, математику |
| ML Engineer | Внедряет модели в продакшен | Данные из пайплайнов | Python, MLflow, Docker, облака | Рабочие ML-сервисы | Любит системное программирование и продуктовый результат |
Дата инженер в этой схеме — фундамент. Аналитик не построит отчёт без чистых данных в хранилище. Data Scientist не обучит модель без подготовленной выборки. ML Engineer не задеплоит сервис без стабильного потока информации.
Новичку здесь важно не выбрать «лучшую» роль, а понять, какой тип работы ближе. Анализ и бизнес-вопросы — аналитика. Модели и эксперименты — Data Science. Инфраструктура, системы и автоматизация — Data Engineering. Продуктовый ML — ML Engineering. Ответ на этот вопрос сэкономит несколько месяцев хаотичного обучения.
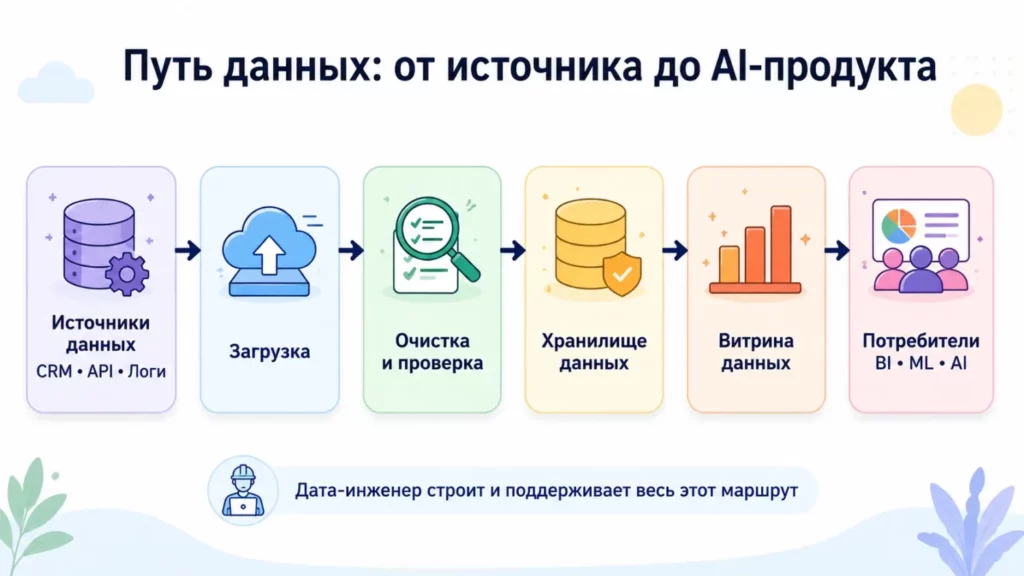
Схема показывает, как данные проходят путь от источников до BI, ML и AI-продуктов. Она помогает быстро понять, что Data Engineer отвечает не за один этап, а за надёжность всего маршрута.
Ниже — схема пути данных, которую можно использовать как врезку в этот раздел:
Схема 1. Как данные проходят путь от источника до AI-модели
Источник данных → Загрузка → Очистка → Хранилище → Витрина данных → Аналитика / BI / ML-модель / AI-продукт
Дата инженер отвечает не за каждый бизнес-вывод и не за каждую модель. Но именно он строит этот маршрут — и именно от его надёжности зависит, будут ли результаты на выходе соответствовать реальности.
Что должен знать Data Engineer с нуля
Один из самых частых запросов новичка, который заинтересовался профессией, звучит примерно так: «Хорошо, убедили. Что учить?» И здесь легко попасть в ловушку: открыть roadmap на GitHub, увидеть там Kafka, Spark, Flink, Kubernetes, Airflow, dbt, Redshift, Snowflake — и закрыть вкладку с ощущением, что это не для людей.
На практике выходит иначе. Стек Data Engineer большой, но осваивается последовательно. Есть фундамент, без которого ничего не работает. Есть инструменты второго уровня, которые нужны после первых проектов. И есть специализированные технологии, которые приходят с опытом. Разберём по уровням.
База: SQL, Python, БД и моделирование данных
SQL — это не опция и не «желательно». Это основной язык работы с данными, без которого в профессии делать нечего. Причём речь не о базовом SELECT: нужно уверенно писать JOIN между несколькими таблицами, GROUP BY с агрегациями, оконные функции для расчёта скользящих метрик, подзапросы и CTE. На практике именно SQL-задачи занимают значительную часть рабочего времени инженера данных — и на собеседованиях SQL проверяют в первую очередь.
Python нужен для всего, что SQL не умеет: написать скрипт загрузки информации из API, обработать CSV-файл нестандартного формата, добавить логику трансформации, которую в SQL описать неудобно, автоматизировать рутинную задачу. На старте достаточно уверенно понимать базовый синтаксис, работу с файлами, библиотеки pandas и requests, основы работы с исключениями.
Базы данных — это среда, в которой живут данные. Инженер должен понимать, как проектируются таблицы, что такое первичный и внешний ключ, зачем нужны индексы, чем реляционная база отличается от колоночного хранилища. Важно понимать разницу между OLTP (операционные базы, где записи постоянно пишутся и обновляются — например, база интернет-магазина) и OLAP (аналитические хранилища, откуда информация читается большими объёмами для отчётов и моделей). На старте достаточно PostgreSQL — это универсальная, хорошо документированная база, которая используется и в учебных проектах, и в боевых системах.
На старте минимально необходимый набор выглядит так: SQL на уверенном уровне, Python basics, PostgreSQL, работа с CSV и JSON, основы Git для версионирования кода, базовые навыки работы в Linux-терминале.
ETL/ELT, пайплайны, Airflow, dbt, Spark и Kafka
Когда фундамент есть, приходит время разобраться с тем, как данные движутся. Ключевые понятия здесь — ETL и ELT.
ETL (Extract, Transform, Load) — классическая схема: содержимое извлекается из источника, преобразуется в нужный формат и загружается в хранилище. ELT (Extract, Load, Transform) — современный подход: сначала всё загружается в хранилище как есть, а трансформации выполняются уже там, используя вычислительные мощности самого хранилища. ELT стал популярен с распространением облачных аналитических баз — BigQuery, Snowflake, Redshift, — где вычисления дешевле, чем их организация на отдельном сервере.
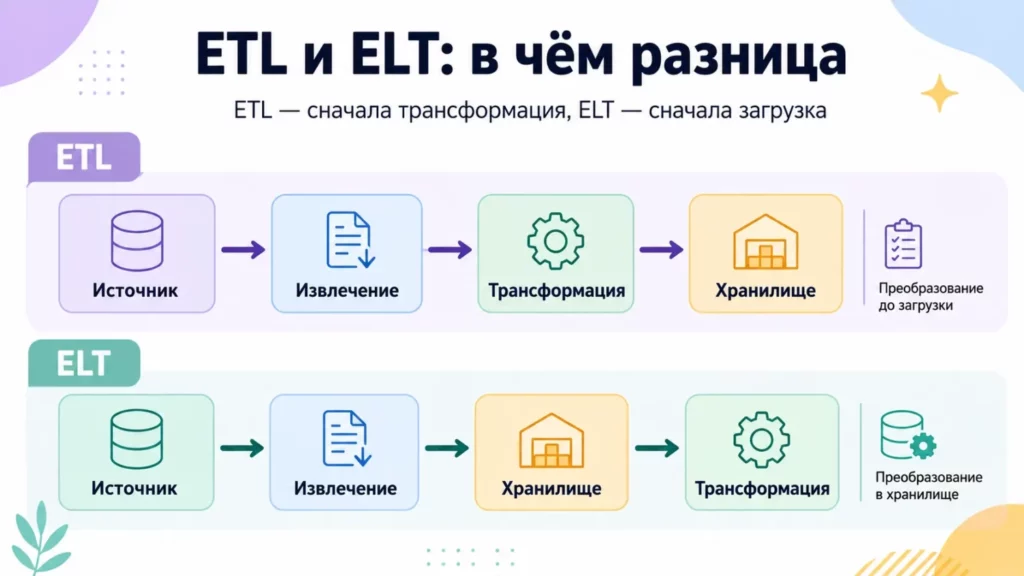
Диаграмма сравнивает два подхода к обработке данных: в ETL трансформация происходит до загрузки, а в ELT — уже внутри хранилища. Это упрощает восприятие разницы между классическим и современным подходом к пайплайнам.
Airflow — инструмент оркестрации пайплайнов. Проще говоря, это планировщик, который запускает задачи по расписанию, следит за зависимостями между ними и сигнализирует, если что-то пошло не так. Пайплайн в Airflow описывается как DAG (направленный ациклический граф): сначала загрузка, потом очистка, трансформация, и запись в витрину. Airflow — один из самых распространённых инструментов в продакшен-системах, поэтому его понимание критично для перехода с учебных проектов на реальные задачи.
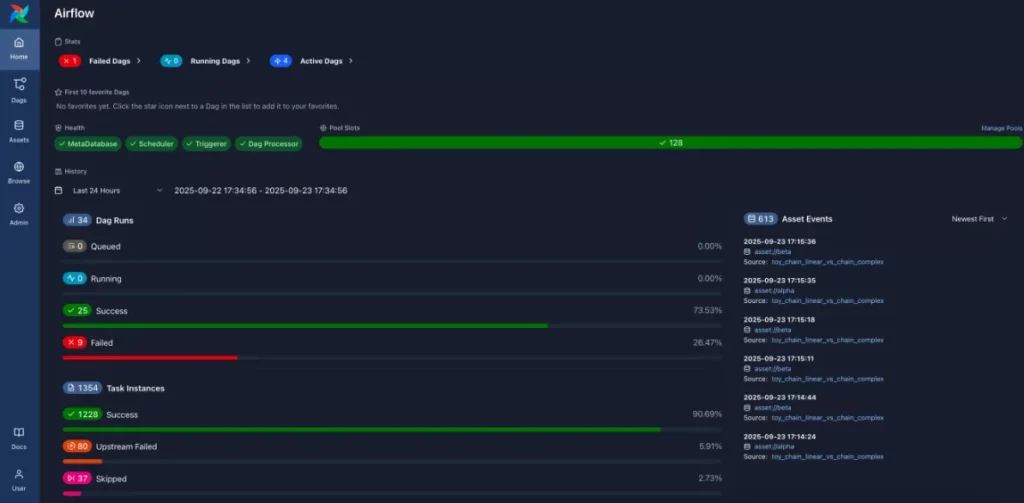
Скриншот Airflow UI с графом DAG: несколько связанных задач, статусы запусков, расписание, история выполнения.
dbt (data build tool) — инструмент для трансформаций в аналитических хранилищах. Он позволяет описывать преобразования на SQL, версионировать их через Git, тестировать качество данных и документировать модели. По сути, dbt привнёс в аналитику инженерные практики — тесты, версионирование, модульность.
Spark — фреймворк для обработки больших данных. Нужен там, где объёмы не помещаются в память одной машины. Kafka — платформа для надежной передачи и буферизации событий в реальном времени. А для обработки этого непрерывного потока данных используют такие инструменты, как Apache Flink или Spark Streaming
Новичку важно понять: всё это не нужно знать одновременно. На первом этапе достаточно SQL + Python + PostgreSQL + один простой ETL-проект. Airflow и dbt приходят после того, как появляется понимание, зачем они нужны. Spark и Kafka — это уже история про масштаб, которая становится актуальной позже.
Облака, Docker, Linux и мониторинг
Реальные данные редко живут на локальном компьютере. Большинство компаний хранят их в облаках — AWS, Google Cloud или Azure. Конкретный выбор платформы зависит от компании, но принципы везде одинаковые: есть хранилище объектов (S3, GCS, Azure Blob), есть управляемые базы данных, есть вычислительные ресурсы, есть инструменты для оркестрации и мониторинга. На старте не нужно становиться облачным архитектором — достаточно понимать базовые концепции: как устроено хранилище, как настраиваются доступы, из чего складывается стоимость, где могут быть проблемы с безопасностью.
- Docker нужен для воспроизводимости. Классическая проблема разработки звучит как «у меня работает». Docker решает её: окружение упаковывается в контейнер, который запускается одинаково на любой машине. Для Data Engineer это означает возможность развернуть Airflow, PostgreSQL или любой другой инструмент локально за несколько команд.
- Linux — рабочая среда большинства серверов и облачных систем. Базовые навыки командной строки обязательны: перемещение по файловой системе, работа с процессами, настройка прав доступа, просмотр логов, запуск скриптов по cron.
- Мониторинг — это ответ на вопрос «а вдруг всё сломалось, пока никто не смотрел». Пайплайны ломаются: источник поменял формат, база недоступна, задача зависла. Инженер данных должен понимать, как настроить алерты, где смотреть логи и как быстро локализовать проблему. Пайплайн без мониторинга — это система, об ошибках которой узнают от аналитика, который пришёл за информацией и ничего не нашёл.
Ниже — таблица и чек-лист, которые можно использовать как врезки в этот раздел.
Таблица 2. Стек Data Engineer: что учить сразу, что позже
| Навык / инструмент | Зачем нужен | Важность для новичка | Пример задачи | Когда изучать |
| SQL | Основной язык работы с данными | Критично | Написать запрос с JOIN, агрегацией и оконной функцией | Сразу |
| Python | Автоматизация, скрипты, API | Критично | Загрузить информацию из API и сохранить в CSV | Сразу |
| PostgreSQL | Реляционная БД для хранения данных | Критично | Спроектировать схему таблиц и наполнить её | Сразу |
| Git | Версионирование кода | Критично | Закоммитить проект, сделать ветку | Сразу |
| Linux / CLI | Работа с серверами и окружением | Важно | Запустить скрипт по расписанию через cron | Сразу |
| Airflow | Оркестрация пайплайнов | Важно | Настроить DAG с расписанием и зависимостями | После базы |
| dbt | Трансформации в хранилищах | Важно | Написать модели и тесты для аналитического слоя | После SQL и хранилищ |
| Docker | Воспроизводимые окружения | Важно | Запустить Airflow + PostgreSQL локально | После базы |
| Spark | Обработка больших данных | Средне | Обработать датасет, не помещающийся в память | После понимания пайплайнов |
| Kafka | Потоковая передача событий | Средне | Обработать поток кликов в реальном времени | Позже |
| AWS / GCP / Azure | Облачная инфраструктура | Важно | Загрузить файлы в S3, настроить доступ | После локальных проектов |
Чек-лист 1. Минимальный набор навыков Junior Data Engineer.
- Уверенно писать SELECT, JOIN, GROUP BY, оконные функции.
- Понимать нормализацию и базовое моделирование данных.
- Писать Python-скрипты для загрузки и обработки.
- Работать с API и файлами CSV / JSON.
- Использовать Git: коммиты, ветки, pull request.
- Запускать проект локально, объяснить его структуру.
- Понимать разницу между ETL и ELT.
- Собрать простой пайплайн — от источника до таблицы в базе.
- Описать архитектуру своего проекта схемой или текстом.
- Объяснить, как проверяется качество данных в пайплайне.
Как стать Дата инженером с нуля: дорожная карта обучения
Главная ошибка новичка, который решил войти в Data Engineering, — начать сразу со всего. Открыть три курса параллельно, поставить Kafka, попробовать Spark, зарегистрироваться в AWS и через месяц обнаружить, что ни одна из этих вещей не освоена даже наполовину. Хаотичное обучение в этой профессии особенно болезненно: инструменты здесь связаны между собой, и без фундамента каждый следующий шаг ощущается как прыжок в пустоту.
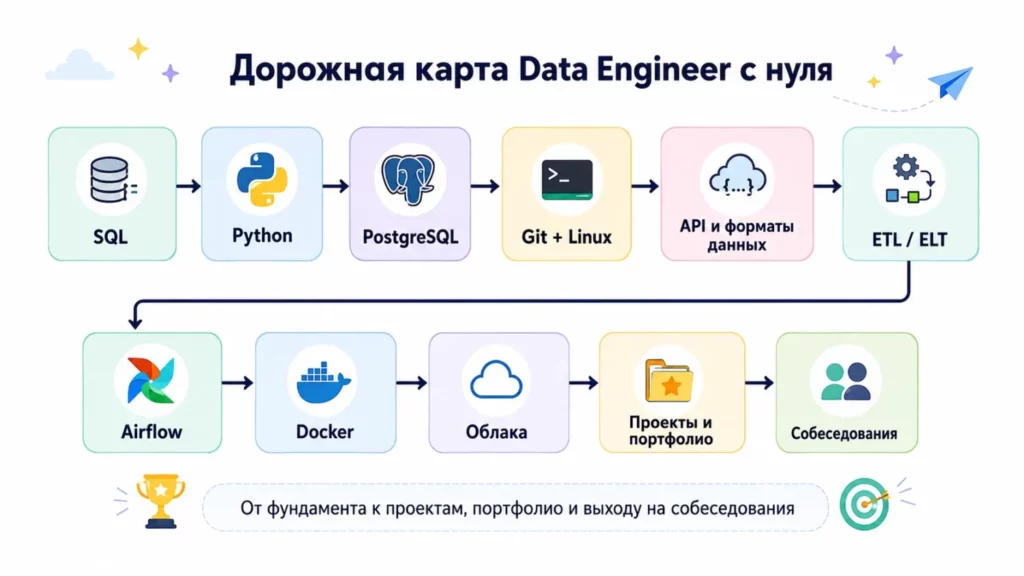
Roadmap показывает последовательность обучения: от SQL и Python до проектов, портфолио и собеседований. Такая визуализация снижает ощущение хаоса от большого стека и помогает читателю увидеть понятный маршрут
Дорожная карта ниже построена по принципу последовательного освоения: каждый этап даёт практический результат и открывает следующий уровень.
Схема 2. Roadmap Data Engineer с нуля
SQL → Python → Базы данных → Git + Linux → API и форматы данных → ETL/ELT → Airflow → Docker → Облака → Проекты и портфолио → Собеседования
Этап 1: фундамент для новичка
Начинать нужно не с Kafka и не со Spark. Начинать нужно с вопроса: понимаю ли я, как данные появляются, где хранятся, как передаются и как запрашиваются? Если ответ «не очень» — это и есть точка старта.
Фундамент состоит из нескольких блоков, которые осваиваются параллельно или последовательно — в зависимости от темпа.
- SQL — первый приоритет. Не потому что он «простой», а потому что он везде. Нужно дойти до уверенного уровня: JOIN нескольких таблиц, агрегации, GROUP BY, HAVING, оконные функции (ROW_NUMBER, LAG, SUM OVER), подзапросы, CTE. Хорошая проверка: можете ли вы написать запрос, который считает скользящее среднее продаж по неделям с разбивкой по категориям товаров? Если да — база есть.
- Python на этом этапе нужен не для машинного обучения и не для веб-разработки. Нужно освоить: базовый синтаксис, работу с файлами, библиотеки pandas (обработка таблиц) и requests (запросы к API), основы обработки исключений, запись содержимого в файл и базу данных. Этого достаточно для первых реальных задач.
- Базы данных — PostgreSQL как основная учебная среда. Нужно понять: как создать таблицу, как настроить первичные и внешние ключи, что такое индекс и зачем он нужен, как смотреть план запроса. Параллельно — базовое понимание разницы между OLTP и OLAP: операционные базы хранят текущее состояние системы, аналитические — историю событий для отчётности.
- Git и Linux — технический минимум для работы в любой команде. Git: инициализация репозитория, коммиты, ветки, push в GitHub. Linux: навигация по файловой системе, права доступа, просмотр логов, запуск скриптов, cron для расписания.
- Результат этапа — конкретный и измеримый. По его итогам вы умеете: написать SQL-запросы разной сложности, загрузить содержимое из CSV или API на Python, сохранить его в PostgreSQL, сделать простую обработку и закоммитить всё в Git. Это уже материал для первого учебного проекта.
Этап 2: первые пайплайны и проекты
После фундамента наступает момент, который многие откладывают: пора перестать проходить курсы и начать что-то строить. Первый end-to-end проект — это не идеальная архитектура и не продакшен-система. Это цепочка: взял данные из источника → очистил → сохранил в базу → сделал витрину → автоматизировал обновление.
Примеры проектов, которые реально можно собрать на этом этапе:
- Пайплайн информации о погоде из открытого API: загрузка каждые несколько часов, хранение в PostgreSQL, простая агрегация по дням.
- Загрузка содержимого интернет-магазина из CSV в базу с нормализацией: товары, заказы, клиенты — разные таблицы, связанные ключами.
- Витрина продаж: SQL-запрос, который из сырых записей строит аналитическую таблицу с метриками по категориям и периодам.
- Автоматизация ежедневной загрузки через Airflow: простой DAG с двумя-тремя задачами и расписанием.
- Мини-хранилище для аналитического дашборда: слой сырых данных, очищенных, слой витрин.
На этом этапе приходит понимание вещей, которые в теории звучат абстрактно. Что такое идемпотентность пайплайна — то есть почему важно, чтобы повторный запуск не создавал дубли. Как обрабатывать ошибки: что делать, если API не ответил или формат изменился. Зачем нужны логи и как их читать.
Airflow стоит ввести именно здесь — не раньше. Когда уже есть скрипт загрузки, который работает вручную, становится понятно, зачем нужен инструмент, который запускает его автоматически, следит за результатом и сигнализирует об ошибке. До этого момента Airflow — просто набор незнакомых концепций.
Этап 3: портфолио, GitHub и подготовка к собеседованиям
Портфолио Дата инженера — это не просто папка с кодом на GitHub. Это демонстрация инженерного мышления: как вы ставили задачу, какую архитектуру выбрали, почему именно так, что может сломаться и как вы это предусмотрели.
Хороший проект в портфолио отличается от учебного упражнения несколькими вещами. В нём есть README — понятное описание проекта, его цели и того, что внутри. Есть схема архитектуры: даже простая диаграмма, показывающая источник данных, этапы обработки и место хранения. Есть инструкция запуска: клонировал репозиторий, выполнил три команды — и всё работает. Есть описание бизнес-задачи: зачем вообще нужен этот пайплайн, что он даёт. Есть обработка ошибок и хотя бы базовое логирование.
Страница репозитория на GitHub: README, структура файлов, коммиты, папки проекта. Показывает, как должен выглядеть проект, который не просто «лежит кодом», а оформлен как портфолио.
Чек-лист 2. Каким должен быть проект в портфолио Data Engineer
- Есть понятный источник данных.
- Информация загружается автоматически (по расписанию или триггеру).
- Есть база или хранилище.
- Есть слой очистки и трансформации.
- Есть итоговая витрина или аналитический слой.
- Есть README с описанием проекта и бизнес-задачи.
- Есть схема архитектуры.
- Есть инструкция запуска.
- Есть обработка ошибок и логирование.
- Код опубликован на GitHub в читаемом виде.
Для собеседований на Junior-позицию нужно быть готовым к нескольким типам вопросов. SQL-задачи — почти всегда: написать запрос на месте, объяснить, как он работает, предложить оптимизацию. Вопросы по базам данных: что такое индекс, когда он помогает, а когда нет. Вопросы по ETL: чем отличается ETL от ELT, что такое идемпотентность, как проверять качество данных. Вопросы по Airflow: что такое DAG, как работают зависимости между задачами. И — что особенно важно — вопросы по вашим проектам. «Расскажите, что вы сделали» — это не светская беседа. Это проверка того, понимаете ли вы, что построили.
Один хорошо объяснённый собственный проект стоит больше, чем десять пройденных курсов без практики.
Как выбрать курс Data Engineer и не попасть в ловушку хайпа
Рынок курсов по Data Engineering за последние два года вырос заметно — вместе со спросом на профессию. Это означает не только больше выбора, но и больше программ, которые эксплуатируют интерес к теме, не давая реального результата. Красивый лендинг, упоминание AI и больших данных в первом абзаце, обещание трудоустройства — и курс продаётся. Что внутри, выясняется позже.
Мы не будем называть конкретные программы и расставлять оценки. Задача этого раздела другая: дать инструменты, которые позволяют оценить курс самостоятельно — до покупки, а не после.
Какие критерии важнее бренда: проекты, стек, длительность, поддержка
Бренд школы — не лучший критерий выбора. Известное название не гарантирует ни актуального стека, ни качественной обратной связи, ни реальных проектов. На практике выходит, что небольшая программа с сильным наставником и живыми проектами даёт больше, чем массовый курс с известным логотипом и автоматической проверкой заданий.
Что реально важно при выборе курса:
- Стек. Программа должна включать SQL, Python, базы данных, ETL/ELT, хотя бы один инструмент оркестрации (Airflow), основы облаков и Docker. Если стек устарел или в нём нет ничего из этого списка — курс не готовит к реальной работе.
- Проекты. Не учебные упражнения в формате «повтори за преподавателем», а самостоятельные end-to-end проекты с реальными источниками данных. Хороший признак — когда в программе описано, что именно студент построит к концу обучения и как это выглядит.
- Обратная связь. Проверка домашних заданий живым наставником, а не автотестами. Код-ревью — когда преподаватель или ментор смотрит на ваш код и объясняет, что можно улучшить. Это принципиально отличается от «тест пройден / тест не пройден».
- Длительность. Слишком короткий курс для новичка — тревожный сигнал. Data Engineering — инженерная дисциплина, которая требует времени на практику. Программа, которая обещает подготовить специалиста за четыре недели с нуля, либо сильно сокращает фундамент, либо работает с людьми, у которых уже есть IT-база.
- Карьерная поддержка. Помощь с резюме, портфолио, подготовка к собеседованиям — это не бонус, а часть полноценной программы для тех, кто входит в профессию. Важно понимать, что именно предлагается: живые консультации или шаблон резюме в PDF.
Таблица 3. Как выбрать курс
| Критерий | Хороший признак | Плохой признак | Вопрос перед покупкой |
| Уровень входа | Чётко указан, есть вводный модуль | «Для всех» без уточнений | С какого уровня подготовки рассчитана программа? |
| Программа | Подробная, с темами и проектами | Общие слова без конкретики | Что именно я изучу и в каком порядке? |
| Практика | Много заданий, самостоятельные проекты | Только лекции и тесты | Сколько часов практики на каждый модуль? |
| Проекты | End-to-end, с реальными данными | Повторение за преподавателем | Какие проекты я добавлю в портфолио? |
| Наставники | Практикующие специалисты, есть биографии | Нет информации о преподавателях | Кто ведёт курс и какой у них опыт? |
| Обратная связь | Код-ревью, живая проверка заданий | Автотесты, боты | Кто и как проверяет домашние задания? |
| Карьерная поддержка | Консультации, помощь с резюме и портфолио | Шаблон резюме в подарок | Что конкретно включает карьерный блок? |
| Длительность | Соответствует заявленной глубине | Слишком коротко для заявленного уровня | Сколько времени в неделю нужно уделять учёбе? |
| Стек | Актуальный: SQL, Python, Airflow, облака | Устаревший или без инженерной базы | Какие именно инструменты я освою? |
| Прозрачность обещаний | Честные условия, без гарантий без оговорок | «Гарантируем трудоустройство» без деталей | Что именно подразумевается под гарантией? |
Для кого подойдут короткие, длинные и карьерные программы
Выбор формата зависит не от бюджета и не от популярности курса — а от стартовой точки и цели.
Короткие курсы (1–3 месяца) подходят тем, у кого уже есть IT-база: разработчики, аналитики, администраторы баз данных. Такой человек не тратит время на объяснение, что такое переменная или как работает сеть. Ему нужен конкретный инструментальный блок: научиться Airflow, разобраться с dbt, освоить облачную инфраструктуру. Короткий курс с практикой — рабочий вариант.
Длинные программы (4–12 месяцев) подходят новичкам, которым нужен фундамент с нуля. Здесь важна последовательность: SQL → Python → базы данных → пайплайны → проекты. Торопиться не стоит — попытка пройти годовую программу за три месяца обычно заканчивается поверхностным пониманием и отсутствием реальных навыков.
Карьерные программы — это не просто обучение, а подготовка к выходу на рынок труда. Они включают портфолио, помощь с резюме, mock-интервью, нетворкинг с работодателями. Подходят тем, кто уже понимает профессию и хочет системно подготовиться к поиску первой работы. Важная оговорка: карьерная программа не заменяет практику — она её дополняет. Результат всё равно зависит от того, сколько реального кода написал студент.
Какие обещания курса должны насторожить
Есть формулировки, которые встречаются на лендингах курсов и при ближайшем рассмотрении оказываются либо преувеличением, либо прямым введением в заблуждение. Перечислим те, на которые стоит обращать внимание.
- «Станете Дата инженером за две недели с нуля» — физически невозможно для человека без IT-базы. Data Engineering — это инженерная дисциплина с достаточно широким стеком. Две недели можно потратить на введение в SQL. Не более.
- «Гарантируем зарплату» или «гарантируем трудоустройство» без условий — это маркетинговая формулировка, а не юридическое обязательство. Результат трудоустройства зависит от рынка, портфолио, усилий студента и региона. Честный курс объясняет условия гарантии, а не прячет их в сноску.
- Нет программы или она написана общими словами — если школа не готова показать, что именно изучается и в каком порядке, это повод насторожиться.
- Нет SQL и Python в программе — без этих двух инструментов невозможно работать Data Engineer. Их отсутствие означает либо очень узкую специализацию, либо поверхностный подход.
- Программа состоит только из видео — без заданий, без проверки, без проектов. Можно смотреть лекции бесконечно и не научиться ничему практическому.
Чек-лист 3. Красные флаги курса
- Обещают профессию за слишком короткий срок без оговорок об уровне входа.
- Нет самостоятельных проектов — только повторение за преподавателем.
- Нет проверки домашних заданий живым наставником.
- SQL или Python отсутствуют в программе.
- Много AI-обещаний, но нет инженерной базы.
- Нет информации о преподавателях и их реальном опыте.
- Программа состоит только из видеолекций.
- Нет карьерного блока или он сведён к шаблону резюме.
- Нет требований к самостоятельной практике.
- Обещают гарантированное трудоустройство без прозрачных условий.
Разумный подход при выборе курса — взять этот чек-лист, открыть программу интересующей школы и пройтись по каждому пункту. Если три и более флага совпадают, стоит поискать альтернативу или как минимум задать менеджеру прямые вопросы перед оплатой.
Data Engineering vs ML: что выбрать новичку
Этот вопрос звучит регулярно — и обычно формулируется как выбор между двумя конкурирующими путями. На самом деле никакой конкуренции здесь нет. Data Engineering и Machine Learning — разные профессии с разными задачами, типом мышления и набором инструментов. Вопрос не в том, что лучше в абсолютном смысле, а в том, что ближе конкретному человеку и с какой стартовой точки он начинает.
Когда лучше начинать с Data Engineering
DE — хороший выбор для тех, кому нравится системность и инженерное мышление. Если человек получает удовольствие от того, что настроил процесс, который работает надёжно и предсказуемо, — это сигнал в сторону инженерии данных. Если интересно, как устроены базы, как информация перемещается между системами, как сделать так, чтобы пайплайн не падал в три часа ночи, — тоже сюда.
На практике Data Engineering хорошо подходит нескольким типам людей. Разработчикам, которые хотят работать с данными, но не стремятся в сторону математики и статистики. Администраторам баз данных, которые хотят расширить стек и перейти в более инженерную роль. Аналитикам, которых раздражает, что входящая информация всегда грязная и приходит с задержкой — и которые хотят решить эту проблему на уровне инфраструктуры. Людям без IT-опыта, которым ближе логика, системы и автоматизация, чем эксперименты и исследования.
Ещё один аргумент в его пользу как точки входа: математика здесь нужна на базовом уровне. Не линейная алгебра, не теория вероятностей, не оптимизация функций потерь. Достаточно понимать базовую статистику и уметь работать с числами. Это снижает порог входа для людей с гуманитарным или нетехническим бэкграундом, которые при этом готовы освоить инженерный инструментарий.
Когда логичнее идти в ML или аналитику
Machine Learning — правильный выбор для тех, кому интересны не системы, а закономерности. Если человека увлекает вопрос «почему модель ошибается» больше, чем «почему пайплайн упал» — это сигнал в сторону ML. Здесь нужна математика: линейная алгебра, теория вероятностей, статистика, основы оптимизации. Без этого фундамента работа с моделями будет поверхностной — инструменты можно использовать, но понять, что происходит внутри, не получится.
ML подходит тем, кому нравятся эксперименты: обучил модель, получил метрику, изменил параметр, сравнил результаты. Это итеративная исследовательская работа, которая требует терпения и готовности к неопределённости.
Аналитика — третий вариант, который часто недооценивают. Data Analyst работает ближе к бизнесу: переводит вопросы компании в SQL-запросы, строит дашборды, интерпретирует метрики, помогает принимать решения на основе данных. Математика здесь нужна меньше, чем в ML, зато важно понимание бизнес-контекста и умение доносить выводы до нетехнической аудитории. Аналитика — хорошая точка входа для людей, которым интересны цифры, но которые хотят работать с бизнес-задачами, а не с инфраструктурой.
Таблица 4. Data Engineering, ML или аналитика: что выбрать
| Направление | Кому подходит | Что нужно учить | Тип задач | Сложность входа | Куда можно развиваться |
| Data Engineering | Любит системы, автоматизацию, инфраструктуру | SQL, Python, базы данных, ETL, Airflow, облака | Пайплайны, хранилища, автоматизация | Средняя (математика не обязательна) | MLOps, Data Architect, Analytics Engineer |
| Machine Learning | Любит модели, эксперименты, математику | Python, математика, sklearn, PyTorch/TF, статистика | Обучение моделей, эксперименты, метрики | Высокая (нужна математика) | ML Engineer, Research, LLM-инженерия |
| Аналитика | Любит бизнес-вопросы, метрики, дашборды | SQL, Excel/BI-инструменты, базовая статистика | Отчёты, дашборды, продуктовая аналитика | Низкая / средняя | Data Scientist, Product Analyst, BI Engineer |
Как Data Engineering помогает перейти в AI/ML позже
Есть распространённое заблуждение: если начать с DE, дорога в ML закрыта. На практике выходит ровно наоборот.
Инженер данных, который хочет перейти в ML или AI-инженерию, приходит туда с серьёзным преимуществом. Он понимает, откуда берётся информация, как она очищается, почему в ней появляются ошибки и как это влияет на качество обучения. Он умеет строить пайплайны — а значит, может не просто обучить модель в ноутбуке, но и обеспечить ей регулярное переобучение на свежих выборках. Он понимает продакшен-инфраструктуру, что критично для MLOps — направления, которое как раз отвечает за надёжную эксплуатацию ML-систем.
Переход из Data Engineering в ML или AI-инженерию — это вопрос доучивания математики и освоения фреймворков, а не смены профессии с нуля. Фундамент, который дала инженерия данных, остаётся и работает.
Зарплаты, спрос и карьерные перспективы Data Engineer
Разговор о зарплатах требует аккуратности. Цифры сильно зависят от региона, компании, стека и того, что именно понимается под конкретным уровнем. Поэтому вместо того чтобы называть точные суммы, которые устареют раньше, чем дочитает читатель, мы разберём факторы, которые реально влияют на доход — и которые не меняются от квартала к кварталу.
Junior, Middle, Senior: чем отличаются ожидания
Разница между уровнями — это не просто количество лет опыта. Это разница в зоне ответственности, в типе задач и в том, насколько самостоятельно человек принимает решения.
Таблица 5. Junior, Middle, Senior Data Engineer
| Уровень | Типовые задачи | Инструменты | Зона ответственности | Что должно быть в портфолио | Вопросы на собеседовании |
| Junior | Поддержка пайплайнов, написание SQL-запросов, загрузка данных, базовые ETL-скрипты | SQL, Python, PostgreSQL, Git, основы Airflow | Отдельные задачи под руководством | 1–2 end-to-end проекта с описанием и схемой | SQL на джойны и агрегации, базы данных, ETL-концепции, объяснение своих проектов |
| Middle | Проектирование отдельных решений, оптимизация запросов, настройка хранилищ, работа с облаками | Airflow, dbt, облака (AWS/GCP/Azure), Docker, Spark | Полный цикл задачи: от постановки до запуска | 2–4 проекта с реальными данными, облачная инфраструктура, мониторинг | Архитектурные вопросы, оптимизация, работа с Airflow, облачные сервисы |
| Senior | Архитектура систем данных, governance, масштабирование, взаимодействие с бизнесом, техлидерство | Весь стек + специализированные инструменты под задачи | Архитектурные решения, надёжность, стоимость | Кейсы масштабирования, описание архитектурных решений и их обоснование | Системный дизайн, трейдоффы, стоимость решений, работа с требованиями бизнеса |
Джуниор Дата инженер — это человек, который умеет выполнять конкретные инженерные задачи под руководством: написать SQL-запрос, поддержать существующий пайплайн, добавить новый источник по шаблону. От него не ждут архитектурных решений, но ждут аккуратности, понимания базовых концепций и умения объяснить, что он сделал и почему.
Middle уже проектирует отдельные решения самостоятельно. Он понимает, как выбрать инструмент под задачу, умеет оптимизировать медленные запросы, работает с облачной инфраструктурой и знает, как настроить мониторинг. На этом уровне инженер начинает влиять на архитектурные решения — пусть и не принимает их единолично.
Senior отвечает за архитектуру целиком: надёжность системы, стоимость инфраструктуры, масштабируемость, governance данных — то есть правила работы с информацией, доступы, качество, документирование. Кроме инженерной стороны, Senior взаимодействует с бизнесом: переводит требования компании в технические решения и обратно — объясняет ограничения системы стейкхолдерам без простым языком.
Какие отрасли нанимают Data Engineer
DE — не нишевая специализация для технологических компаний. Данные есть везде, где есть бизнес-процессы, и инфраструктура для работы с ними нужна в самых разных отраслях.
Наиболее активно нанимают финтех и банки — там объёмы транзакционных потоков огромны, требования к надёжности и безопасности высоки, а аналитика напрямую влияет на продуктовые решения. E-commerce и маркетплейсы — сведения о поведении пользователей, заказах, логистике и рекомендациях требуют постоянно работающих пайплайнов. Телеком, медтех, логистика, промышленность — везде, где есть потоки событий и необходимость их обрабатывать в реальном времени или близко к нему. AI-продукты и SaaS-компании — здесь Data Engineer часто работает на стыке с MLOps: обеспечивает материал для обучения и переобучения моделей. Ритейл, консалтинг, государственный сектор — менее очевидные, но реальные источники спроса.
На практике выходит так: если компания работает с данными в каком-либо масштабе и хочет принимать решения на их основе, рано или поздно ей понадобится инженер данных. Это делает профессию менее зависимой от конъюнктуры конкретной отрасли.
Почему спрос связан с AI, BI и автоматизацией бизнеса
Три тренда одновременно создают устойчивый спрос на Data Engineer — и все три никуда не денутся в ближайшие годы.
- Первый — AI-продукты. Компании хотят внедрять AI: рекомендации, прогнозы, чат-боты на основе LLM, автоматизацию процессов. Все эти системы требуют данных — актуальных, чистых, доступных. Без инженера данных AI-проект либо не стартует, либо деградирует по качеству по мере того, как информация устаревает.
- Второй — BI и аналитика. Бизнес хочет дашборды, отчёты, метрики в реальном времени. За красивым интерфейсом BI-инструмента всегда стоит инфраструктура данных — хранилище, витрины, пайплайны обновления. Кто-то должен её строить и поддерживать.
- Третий — автоматизация. Компании переходят от ручных процессов к автоматическим: отчетность, мониторинг метрик, алерты при отклонениях. Это инженерные задачи, которые решает Дата инженер.
Возникает вопрос: не вытеснят ли эти функции AI-инструменты и no-code платформы? Частично — уже вытесняют рутинные задачи. Но проектирование архитектуры, принятие решений о трейдоффах, обеспечение надёжности и governance — это задачи, которые требуют инженерного суждения. Инструменты меняются, но потребность в людях, которые умеют думать системно над данными, остаётся.
Можно ли стать Data Engineer без опыта в IT? Можно, но нужно быть готовым к тому, что фундамент придётся строить с нуля — и это займёт время. SQL, Python, базы данных, Git, Linux — всё это осваивается, если подходить последовательно. На практике выходит, что люди без IT-бэкграунда успешно входят в профессию через 12–18 месяцев целенаправленного обучения с практикой. Ключевое слово здесь — практика: курсов без реальных проектов недостаточно. Нужно строить, ломать и чинить собственный код.
- Что учить первым — SQL или Python? SQL. Это основной язык работы с данными в профессии, и без него невозможно двигаться дальше. Python на старте нужен для автоматизации и скриптов, но большинство задач первого уровня решаются именно через SQL. Разумная последовательность: SQL до уверенного уровня → Python basics параллельно или сразу после → PostgreSQL как среда для практики обоих.
- Нужна ли математика? На базовом уровне — да. Нужно понимать агрегации, основы статистики, уметь работать с числами и интерпретировать метрики. Глубокая математика — линейная алгебра, теория вероятностей, матанализ — не обязательна. Это одно из отличий Data Engineering от Machine Learning: порог входа по математике здесь существенно ниже, что делает профессию доступной для людей с нетехническим образованием.
- Нужно ли знать ML, чтобы работать Дата инженером? Понимать, как ML-системы устроены и что им нужно от данных — полезно. Знать, как обучать модели и настраивать гиперпараметры — не обязательно. Data Engineer обеспечивает инфраструктуру, которую используют ML-специалисты: чистые выборки, надёжные пайплайны, доступные хранилища. Чем лучше инженер понимает потребности ML-команды, тем эффективнее взаимодействие — но это вопрос коммуникации и общего понимания, а не глубокой экспертизы в моделях.
- Сколько времени нужно, чтобы стать джуном? Зависит от стартовой точки и интенсивности обучения. Человеку с базой в программировании или работе с данными — от шести до девяти месяцев при регулярной практике. Новичку без IT-опыта — от двенадцати до восемнадцати месяцев. Важно понимать: «стать Junior» означает не пройти курс, а иметь портфолио с реальными проектами и уверенно отвечать на технические вопросы собеседования. Сертификат сам по себе не открывает дверь — открывает её демонстрация навыков.
- Какие проекты добавить в портфолио? Лучший вариант — те, которые решают реальную задачу, пусть и учебную. Пайплайн загрузки информации из открытого API с автоматическим обновлением и хранением в PostgreSQL. Хранилище с несколькими слоями: сырые данные, очищенные, витрина. Дашборд на основе собственного пайплайна. Проект с Airflow, где видна оркестрация и обработка ошибок. Главное требование: каждый проект должен быть описан в README, иметь схему архитектуры и инструкцию запуска. Код без контекста — это просто набор файлов, а не демонстрация инженерного мышления.
- Можно ли перейти из аналитики? Это один из самых естественных переходов в сфере данных. Аналитик уже умеет писать SQL, работать с цифрами и понимает бизнес-контекст. Для перехода нужно добавить инженерную составляющую: научиться строить пайплайны, работать с Python на уровне скриптов и автоматизации, освоить Airflow и основы облачной инфраструктуры. На практике аналитики, которые переходят в Data Engineering, нередко делают это органично — начинают замечать проблемы с качеством входящего материала, хотят решить их на уровне инфраструктуры и постепенно берут на себя инженерные задачи ещё до формальной смены роли.
- Чем Data Engineer отличается от Backend Developer? Оба пишут код, работают с базами данных и строят системы — отсюда и путаница. Но ориентация разная. Backend Developer строит сервисы и API: обрабатывает запросы пользователей, управляет бизнес-логикой приложения, отвечает за производительность и надёжность продукта. Дата инженер строит инфраструктуру данных: пайплайны, хранилища, витрины, системы доставки информации для аналитики и ML. Backend думает о том, как работает продукт. Data Engineer думает о том, как данные движутся внутри организации и как сделать их доступными и надёжными для всех, кто с ними работает.
Приянка Шелар (Senior Data Professional с 14-летним опытом) и эксперты аналитического агентства Revefi: «Традиционная инженерия данных мертва. Заменит ли ИИ инженеров данных? ИИ заменит тех инженеров, которые отказываются эволюционировать. Генеративные сети и no-code платформы (которые ускоряют сборку пайплайнов на 90%) заберут всю рутину: генерацию базового SQL, шаблоны ETL и тесты. Роль специалиста навсегда смещается от «водопроводчика данных», перекладывающего таблицы, к системному архитектору, отвечающему за надежность, governance и бизнес-логику».
Итог: кому подходит профессия Data Engineer
Data Engineering — не профессия для всех, кто хочет работать с данными. И это нормально: у аналитики, Data Science и ML есть своя аудитория, свои задачи и свои точки входа. Вопрос не в том, какая профессия престижнее или лучше оплачивается, а в том, какой тип работы даёт ощущение осмысленности и профессионального роста.
DE подходит тем, кому нравится строить системы, а не только использовать их. Кому важно, что процесс работает надёжно, предсказуемо и не требует ручного вмешательства каждый раз. Кто получает удовольствие от того, что разобрался, почему пайплайн падал, и починил это раз и навсегда. Кому интересна не столько математика моделей, сколько инфраструктура, которая делает эти модели возможными.
Профессия хорошо подходит людям с разным бэкграундом: разработчикам, которые хотят работать ближе к данным; аналитикам, которых раздражает качество входящего материала и которые хотят решить эту проблему на уровне архитектуры; специалистам из смежных областей — администраторам баз данных, системным администраторам, — которые хотят перейти в более инженерную роль. И даже людям без IT-опыта — если они готовы последовательно пройти фундамент и не торопиться с результатом.
Главная мысль, с которой мы начали, остаётся в силе: Data Engineer стал одной из ключевых профессий не потому что ML или AI потеряли ценность. А потому что компании на практике столкнулись с тем, что модели без данных — это красивые презентации. Работающий AI-продукт начинается не с алгоритма, а с надёжного потока информации. Именно это и строит Дата инженер.
FAQ. Частые вопросы о профессии Data Engineer
Если вы только начинаете осваивать профессию Data Engineer, рекомендуем обратить внимание на подборку курсов по Data Engineering. В таких программах обычно есть теоретическая часть для понимания базы и практическая часть с пайплайнами, SQL, Python, хранилищами данных и проектами для портфолио.
Рекомендуем посмотреть курсы по Data Engineering
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Дата-инженер с нуля до middle
|
Нетология
47 отзывов
|
Цена
111 400 ₽
225 070 ₽
с промокодом kursy-online
|
От
3 438 ₽/мес
Без переплат на 2 года.
|
Длительность
11 месяцев
|
Старт
15 июля
|
|
|
Deep Learning Engineer
|
Karpov.Courses
80 отзывов
|
Цена
89 000 ₽
124 900 ₽
|
От
5 204 ₽/мес
|
Длительность
4 месяца
|
Старт
в любое время
|
Сколько зарабатывают новички в IT в Москве и регионах и где обучение окупится быстрее
Зарплаты junior-разработчиков по регионам отличаются не только суммами в оффере: важно понять, где после аренды, расходов и поиска работы курс окупится быстрее. Разберём реальные сценарии, конкуренцию и формат удалёнки, чтобы выбрать старт без лишних финансовых рисков.
Специалист по автоматизации в бизнесе: кто это и почему компании готовы платить за экономию часов
Курсы по автоматизации бизнеса помогают понять, как убрать ручные операции, настроить CRM, интеграции и отчётность. Но как отличить полезную программу от набора уроков по сервисам? Разбираем, какие навыки, проекты и кейсы действительно нужны для старта.

Как выбирать курс, если вы живёте не в Москве: удалёнка, локальные вакансии или фриланс
Как выбрать курс, если вы живёте не в Москве и хотите выйти на реальный доход? Разберём, как проверить вакансии, оценить программу обучения и понять, что подойдёт именно вам: удалёнка, локальная работа или фриланс.

Что происходит с удаленкой в 2026 году: какие профессии после курсов еще реально дают работу из дома
Удалёнка после курсов уже не выглядит как лёгкая гарантия, но шанс на работу из дома всё ещё есть. Разбираемся, какие профессии подходят новичкам, где потребуется опыт и как не ошибиться с выбором обучения.