Data Fabric (ткань данных): что это и какие задачи решает

В современном корпоративном мире данные давно перестали быть просто побочным продуктом бизнес-процессов — они превратились в один из ключевых активов компании. Мы наблюдаем, как организации накапливают информацию в невиданных ранее объёмах, превращая её в основу для принятия стратегических решений.
- Что такое Data Fabric простыми словами
- Зачем нужна ткань данных
- Почему традиционный подход устарел
- Основные задачи, которые решает
- Архитектура и ключевые компоненты
- Преимущества для бизнеса
- Отраслевые кейсы применения
- Как внедрить Data Fabric в компании
- Data Fabric и другие подходы
- Перспективы и будущее
- Заключение
- Рекомендуем посмотреть курсы по системной аналитике
Что такое Data Fabric простыми словами
Data Fabric (ткань данных) — это архитектурная концепция, которая позволяет создать единую «ткань» из разрозненных источников данных компании. Термин «fabric» в переводе с английского означает «ткань», что точно отражает суть подхода: подобно тому, как отдельные нити переплетаются в прочное полотно, различные массивы информации объединяются в цельную структуру.
Важно понимать, что ткань данных — это не программное обеспечение или конкретная технология, а именно архитектурный подход к организации информации. Мы можем сравнить его с городской инфраструктурой: так же, как дороги, мосты и транспортные узлы соединяют различные районы города в единую систему, DF связывает корпоративные хранилища, облачные платформы и внешние сервисы.
В русскоязычной среде встречаются различные переводы этого термина — «ткань данных». Оба варианта отражают ключевую идею: создание производственной среды, где информация обрабатывается, преобразуется и доставляется потребителям в нужном виде и в нужное время.
Ключевые характеристики включают:
- Распределённость — информация остается в своих источниках, но становится доступной через единый интерфейс.
- Единый слой доступа — пользователи работают с информацией через унифицированные API, не задумываясь о её физическом расположении.
- Работа с метаданными — система использует «данные о данных» для автоматического управления потоками информации.
- Интеллектуальная автоматизация — применение машинного обучения для оптимизации процессов обработки информации.
Такой подход позволяет превратить хаотичный набор информационных ресурсов в организованную экосистему, где каждый элемент взаимодействует с остальными по чётко определённым правилам.
Зачем нужна ткань данных
Однако вместе с ростом значимости информации растёт и сложность управления ими. Современные компании сталкиваются с рядом критических проблем:
- Разнородность источников — информация поступает из CRM-систем, корпоративных хранилищ, облачных сервисов, внешних API и IoT-устройств.
- Фрагментация хранения — информация разбросана по различным департаментам, системам и географическим локациям.
- Скорость поступления — современный бизнес требует обработки информации в режиме реального времени.
- Устаревшие подходы — классические методы централизованного хранения теряют эффективность при работе с Big Data.
Традиционные подходы к управлению информацией, основанные на простой централизации, больше не справляются с вызовами современной информационной экосистемы. Компании тратят недели на составление отчётов, которые устаревают ещё до их завершения, а руководители вынуждены принимать решения на основе неполной или противоречивой информации.
В такой ситуации возникает потребность в принципиально новой архитектурной концепции — ткань данных, которая способна объединить разрозненные фрагменты корпоративной информации в единое, управляемое полотно данных.
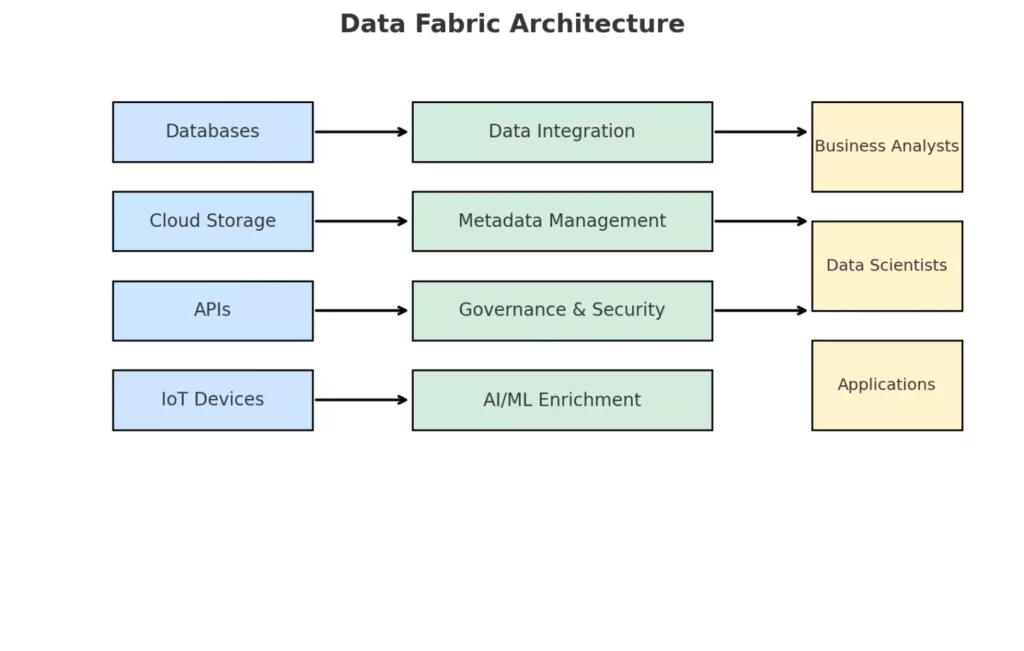
Архитектура Data Fabric: источники данных подключаются к слою Data Fabric, включающему интеграцию, управление метаданными, безопасность и AI/ML, после чего информация доступна аналитикам, дата-сайентистам и приложениям.
Почему традиционный подход устарел
Классические методы управления информацией, основанные на централизованном хранении и традиционных BI-системах, столкнулись с серьёзными ограничениями в условиях современного цифрового ландшафта. Мы наблюдаем, как подходы, эффективно работавшие ещё десятилетие назад, становятся препятствием для развития бизнеса.
Основные причины устаревания традиционных решений связаны с кардинальными изменениями в характере информации и требованиях к ее обработке.
Экспоненциальный рост объёмов информации сделал физически невозможным размещение всех данных в едином хранилище.
Облачная трансформация привела к тому, что критически важная информация теперь распределена между локальными серверами и различными облачными платформами.
API-экономика создала потребность в постоянном обмене информацией с внешними сервисами, а требования реального времени исключили возможность длительных ETL-процессов.
Сравнительная характеристика подходов наглядно демонстрирует ограничения традиционной модели:
| Критерий | Централизованный подход | Data Fabric |
|---|---|---|
| Размещение данных | Физическая централизация | Распределённое хранение |
| Время доступа | Часы/дни (ETL-процессы) | Реальное время |
| Масштабируемость | Ограничена размером хранилища | Практически неограничена |
| Облачная интеграция | Сложная миграция | Нативная поддержка |
| Стоимость инфраструктуры | Высокие капитальные затраты | Оптимизированные операционные расходы |
Традиционная модель требует предварительного перемещения и трансформации всей информации в центральное хранилище, что создаёт узкие места и увеличивает время получения инсайтов. В условиях, когда скорость принятия решений становится конкурентным преимуществом, такие задержки могут стоить компании рыночных возможностей и клиентов.
Основные задачи, которые решает
ТД представляет собой комплексное решение практических проблем, с которыми сталкиваются современные организации при работе с корпоративной информацией. Давайте рассмотрим ключевые задачи, которые эффективно решает эта архитектурная концепция.
Устранение разрозненности источников
Проблема информационных «силосов» знакома практически каждой крупной организации. Отделы маркетинга работают с одними системами, финансовая служба — с другими, а производственные подразделения используют третьи. DF создаёт единую точку доступа ко всем источникам информации, позволяя получить целостное представление о бизнесе без необходимости физического перемещения информации.
Быстрый и безопасный доступ к информации
Современный бизнес требует мгновенного доступа к актуальной информации, но при этом не может пожертвовать безопасностью. DF обеспечивает централизованное управление правами доступа через унифицированные API, позволяя настроить гранулярные разрешения для различных пользователей и ролей. Это означает, что сотрудники получают именно те данные, которые им необходимы для работы, не больше и не меньше.
Ускорение аналитики и принятия решений
Вместо недель ожидания сводных отчётов руководители получают возможность анализировать информацию в режиме реального времени. Ткань данных автоматически агрегирует информацию из различных источников, применяет предустановленные бизнес-правила и представляет результаты в удобном для восприятия виде. Это кардинально сокращает время от возникновения вопроса до получения ответа.
Снижение рисков и ошибок
Ручная работа с разрозненными источниками информации неизбежно приводит к ошибкам сопоставления, дублированию информации и неточностям в расчётах. Data Fabric автоматизирует процессы валидации и очистки данных, применяет единые стандарты качества и обеспечивает аудируемость всех операций. Результат — минимизация человеческого фактора и повышение достоверности аналитических выводов.
Архитектура и ключевые компоненты
Понимание архитектурных принципов критически важно для успешного внедрения этой концепции. Мы рассмотрим основные технологические компоненты, которые превращают разрозненную информационную среду в единую управляемую экосистему.
Роль метаданных («нить», связывающая систему)
Метаданные в архитектуре ткани играют роль своеобразной «нервной системы» — они содержат информацию о структуре, местоположении, качестве и взаимосвязях информации. Именно метаданные позволяют системе автоматически определять, где искать нужную информацию, как её обрабатывать и в каком виде предоставлять пользователю. Без качественных метаданных DF превращается в обычное хранилище с красивым интерфейсом.
Каталоги и управление информацией
Современные каталоги данных выполняют функцию «карты» информационного ландшафта компании. Они автоматически сканируют доступные источники, классифицируют найденную информацию и поддерживают актуальный реестр всей информации организации. Это позволяет пользователям быстро находить нужные датасеты, понимать их содержание и оценивать пригодность для решения конкретных задач.
Интеграция через API и хранилища
Техническую основу ткани данных составляет сеть API-соединений, которые обеспечивают взаимодействие между различными компонентами системы. Современные решения поддерживают как REST, так и GraphQL интерфейсы, обеспечивая гибкость интеграции с существующими корпоративными системами. Промежуточные хранилища информации (data lakes, data warehouses) служат буферными зонами для оптимизации производительности.
Big Data, AI/ML и автоматизация
Искусственный интеллект и машинное обучение встроены в саму архитектуру Data Fabric. Алгоритмы ML автоматически выявляют паттерны использования информации, предсказывают потребности пользователей и оптимизируют маршруты доставки информации. Это превращает пассивную инфраструктуру в интеллектуальную систему, способную к самообучению и адаптации.
Гибридные облака и открытые стандарты
Современная DF должна работать в гибридной среде, где часть данных хранится локально, а часть — в различных облачных сервисах. Поддержка открытых стандартов (Apache Kafka, Apache Spark, Kubernetes) обеспечивает независимость от конкретных поставщиков и возможность эволюционного развития архитектуры без кардинальных переделок.
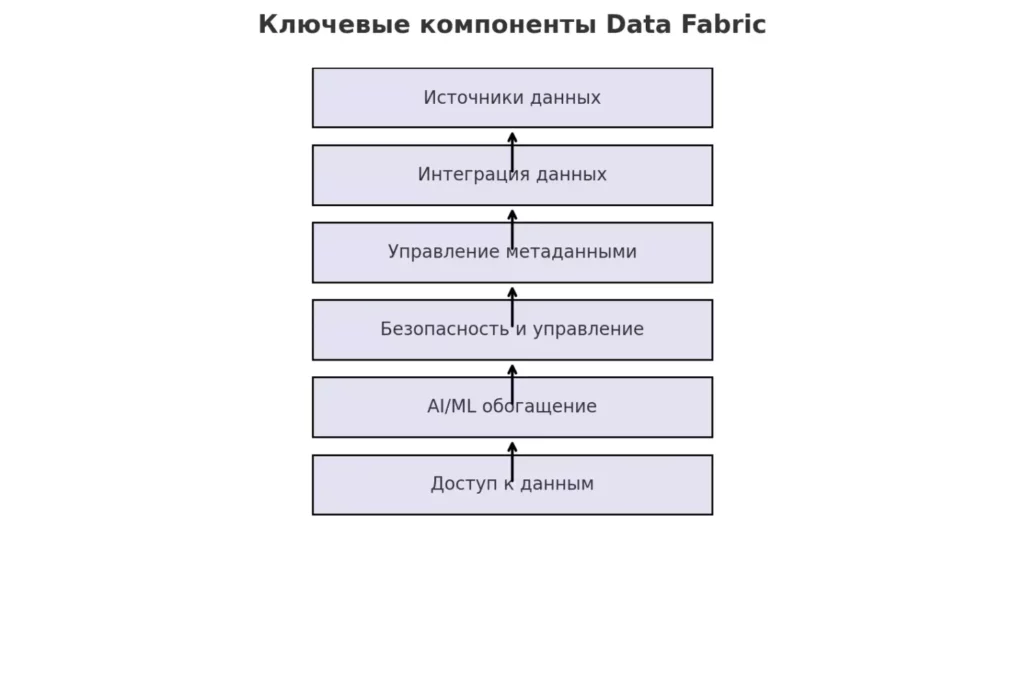
Ключевые компоненты Data Fabric: источники данных, интеграция, управление метаданными, безопасность, AI/ML и доступ
Преимущества для бизнеса
Внедрение DF приносит организациям измеримые преимущества, которые напрямую влияют на операционную эффективность и конкурентоспособность. Мы систематизировали ключевые выгоды, которые получают компании при переходе на эту архитектурную модель.
Автоматизация рутинных процессов становится одним из наиболее заметных эффектов внедрения. Задачи, которые раньше требовали ручного труда аналитиков — сбор информации из различных источников, их валидация и подготовка отчётов — теперь выполняются автоматически. Это высвобождает человеческие ресурсы для более стратегических задач и значительно сокращает время получения инсайтов.
Real-time аналитика перестаёт быть привилегией крупных технологических компаний. Ткань данных обеспечивает практически мгновенный доступ к актуальной информации, позволяя принимать решения на основе текущего состояния бизнеса, а не вчерашних отчётов. Это особенно критично для динамичных отраслей, где рыночные условия меняются ежечасно.
Снижение операционных издержек достигается за счёт оптимизации инфраструктуры и устранения дублирующих систем. Компании больше не нуждаются в содержании множества специализированных хранилищ и middleware-решений — единая архитектура DF покрывает все потребности в управлении данными при меньших затратах на поддержку.
Повышение безопасности и соответствие требованиям обеспечивается централизованным управлением доступом и единообразным применением политик безопасности. Это особенно важно в контексте GDPR, российского закона о персональных данных и отраслевых стандартов compliance.
Ускорение цифровой трансформации происходит благодаря готовой технологической платформе для внедрения новых цифровых сервисов. Вместо создания очередного изолированного решения компании могут интегрировать новые инициативы в существующую Data Fabric, получая синергетический эффект от взаимодействия различных систем.
Масштабируемость и гибкость архитектуры позволяют организациям адаптироваться к изменяющимся бизнес-требованиям без капитальных инвестиций в новую инфраструктуру. Добавление новых источников информации или изменение аналитических процессов происходит эволюционно, без нарушения работы существующих систем.
Сравнение традиционного подхода и Data Fabric: разрозненные системы против единой интеллектуальной среды.
Отраслевые кейсы применения
Ткань демонстрирует свою эффективность в самых различных отраслях экономики, решая специфические задачи каждой сферы деятельности. Мы проанализировали наиболее показательные примеры внедрения этой концепции в ключевых секторах.
Ритейл (прогноз спроса, ценообразование)
Розничная торговля стала одной из первых отраслей, где DF продемонстрировала свою эффективность. Ритейлеры используют эту архитектуру для объединения информации о продажах, складских остатках, поведении покупателей и внешних факторах (погода, праздники, конкуренты). Результат — точные прогнозы спроса, динамическое ценообразование и оптимизация ассортимента в режиме реального времени.
Банки (онлайн-кредитование, фрод-мониторинг)
Финансовый сектор использует Data Fabric для создания комплексного профиля клиентов, объединяя транзакционные данные, кредитную историю, социальные медиа и внешние источники информации. Это позволяет принимать решения о выдаче кредитов за минуты, а не дни, одновременно повышая качество скоринга и эффективность систем предотвращения мошенничества.
Телеком (качество услуг, автоматизация процессов)
Телекоммуникационные компании применяют DF для мониторинга качества сетей, анализа пользовательского опыта и персонализации тарифных предложений. Интеграция данных сетевого оборудования, биллинговых систем и пользовательской аналитики обеспечивает проактивное управление инфраструктурой и повышение удовлетворённости клиентов.
Промышленность (снижение издержек, IoT)
Производственные компании используют ткань данных для создания «цифровых двойников» заводов, интегрируя информацию IoT-датчиков, систем планирования производства и цепочек поставок. Это обеспечивает предиктивное обслуживание оборудования, оптимизацию энергопотребления и сквозную прозрачность производственных процессов.
Государственный сектор (Госуслуги, открытые данные)
Государственные структуры применяют принципы Data Fabric для создания единых цифровых платформ взаимодействия с гражданами. Интеграция информации различных ведомств позволяет предоставлять комплексные услуги без необходимости многократного обращения граждан в разные инстанции, что значительно повышает качество государственных сервисов.
| Отрасль | Ключевая задача | Достигаемый эффект |
|---|---|---|
| Ритейл | Прогнозирование и ценообразование | Сокращение неликвидов на 15-25% |
| Банки | Скоринг и фрод-мониторинг | Ускорение решений в 10-50 раз |
| Телеком | Качество сервиса | Снижение churn rate на 20-30% |
| Промышленность | Предиктивная аналитика | Сокращение простоев на 25-40% |
| Госсектор | Цифровизация услуг | Повышение удовлетворённости на 35-50% |
Как внедрить Data Fabric в компании
Успешное внедрение ткани данных требует систематического подхода и чёткого понимания последовательности действий. Мы рассмотрим практические шаги, которые позволяют организациям эффективно перейти от разрозненной информационной среды к единой архитектуре информации.
Определение стратегии и архитектуры
Первый этап внедрения начинается с формулирования цифровой стратегии и определения целевой архитектуры. Компании необходимо провести аудит существующих информационных активов, выявить ключевые источники информации и определить приоритетные бизнес-сценарии использования. Важно сразу определить, будет ли ткань данных развиваться эволюционно поверх существующих систем или потребует частичной замены legacy-инфраструктуры.
Работа с метаданными и классификация данных
Создание качественного слоя метаданных становится фундаментом всей будущей архитектуры. Необходимо классифицировать информацию по уровням конфиденциальности, актуальности и бизнес-ценности. Этот этап включает инвентаризацию всех источников информации, анализ их взаимосвязей и создание единого каталога информации компании. Особое внимание следует уделить выявлению персональных данных для обеспечения соответствия требованиям защиты информации.
Перемещение нагрузок и оптимизация
На этом этапе определяются критерии размещения различных типов информации — что остаётся в локальных хранилищах, что переносится в облако, а что требует гибридного подхода. Решения принимаются на основе анализа стоимости, производительности, требований безопасности и нормативных ограничений. Важно предусмотреть постепенную миграцию без нарушения работы критически важных бизнес-процессов.
Постоянное совершенствование архитектуры
Data Fabric — это живая система, которая должна адаптироваться к изменяющимся потребностям бизнеса. Необходимо внедрить процессы мониторинга использования данных, анализа производительности и выявления новых требований. Регулярная оптимизация включает пересмотр размещения информации, обновление метаданных и настройку алгоритмов машинного обучения для повышения автоматизации управления.
Ключевые этапы внедрения можно представить в виде последовательности:
- Стратегическое планирование (2-4 месяца) — определение целей и архитектуры.
- Подготовка метаданных (3-6 месяцев) — инвентаризация и классификация.
- Пилотный проект (4-8 месяцев) — внедрение на ограниченном периметре.
- Масштабирование (6-12 месяцев) — распространение на всю организацию.
- Оптимизация (постоянно) — непрерывное совершенствование системы.
Успешность внедрения во многом зависит от поддержки руководства, готовности сотрудников к изменениям и правильного выбора технологических партнёров, способных обеспечить долгосрочное развитие платформы.
Data Fabric и другие подходы
В современном ландшафте управления информацией ткань данных существует не в вакууме — компании часто выбирают между несколькими архитектурными концепциями. Мы проанализируем ключевые различия между Data Fabric и альтернативными подходами, чтобы помочь организациям принять обоснованное решение.
Fabric vs Mesh
Data Mesh представляет собой децентрализованную архитектуру, где каждый домен (подразделение) компании самостоятельно управляет своими данными как продуктом. В отличие от DF, которая создаёт единый слой абстракции над всеми источниками информации, Mesh делегирует ответственность за качество и доступность данных непосредственно их владельцам.
Основное различие заключается в философии управления: ткань данных стремится к централизованному контролю через единую платформу, в то время как Data Mesh продвигает федеративное управление с общими стандартами. Выбор между этими подходами зависит от организационной культуры компании — централизованные структуры тяготеют к DF, а компании с сильной доменной экспертизой предпочитают Data Mesh.
Fabric vs Lakehouse
Data Lakehouse представляет собой гибридную архитектуру, объединяющую преимущества data lake (гибкость хранения) и data warehouse (производительность аналитики). Это скорее технологическое решение для хранения и обработки данных, чем комплексная архитектурная концепция.
Ткань данных может использовать Data Lakehouse как один из компонентов своей архитектуры, но не ограничивается им. Lakehouse фокусируется на оптимизации хранения и обработки больших объёмов данных, в то время как Data Fabric решает более широкую задачу создания единой экосистемы управления всеми информационными активами организации.
| Критерий | Data Fabric | Data Mesh | Data Lakehouse |
|---|---|---|---|
| Управление | Централизованное | Федеративное | Централизованное |
| Область применения | Вся организация | Доменно-ориентированное | Аналитические нагрузки |
| Сложность внедрения | Высокая | Очень высокая | Средняя |
| Организационные изменения | Умеренные | Кардинальные | Минимальные |
| Время до результата | 6-18 месяцев | 12-36 месяцев | 3-12 месяцев |
Практика показывает, что многие организации начинают с внедрения Data Lakehouse для решения конкретных аналитических задач, а затем эволюционируют в сторону Data Fabric или Data Mesh в зависимости от корпоративной культуры и стратегических целей.
Перспективы и будущее
Data Fabric уверенно закрепляется как один из ведущих трендов 2020-х годов в области управления корпоративными данными. Мы наблюдаем стремительную эволюцию этой концепции от базовой интеграции источников данных к созданию полностью автономных интеллектуальных систем.
Ближайшие перспективы развития связаны с глубокой интеграцией искусственного интеллекта во все компоненты архитектуры. Современные решения уже используют машинное обучение для автоматического обнаружения данных, их классификации и оптимизации маршрутов доставки. Следующий этап — создание самообучающихся систем, способных предсказывать потребности пользователей и автоматически адаптировать архитектуру под изменяющиеся требования бизнеса.
Автономные Data Fabric представляют собой конечную цель эволюции концепции. В такой системе искусственный интеллект не просто помогает управлять данными, а полностью берёт на себя функции администрирования: автоматически обнаруживает новые источники информации, интегрирует их в общую архитектуру, обеспечивает качество данных и оптимизирует производительность. Человеческое вмешательство требуется только для определения бизнес-политик высокого уровня.
Развитие технологий квантовых вычислений открывает новые горизонты для обработки сверхбольших массивов данных в режиме реального времени. Хотя практическое применение квантовых технологий в корпоративной среде пока ограничено, их потенциал для решения задач оптимизации и машинного обучения в рамках Data Fabric огромен.
Интеграция с Web3 и блокчейн-технологиями создаёт предпосылки для формирования децентрализованных экосистем данных, где организации могут безопасно обмениваться информацией, сохраняя полный контроль над своими активами. Это особенно актуально для создания отраслевых консорциумов и межкорпоративной аналитики.
Сценарии развития ткани данных варьируются от эволюционного совершенствования существующих решений до революционного пересмотра принципов управления данными. Наиболее вероятным представляется постепенный переход к полностью автоматизированным системам, где человек выступает в роли стратега, а не оператора.
Заключение
Data Fabric представляет собой архитектурную концепцию нового поколения, которая превращает разрозненные фрагменты корпоративной информации в единую управляемую экосистему. Мы рассмотрели, как эта «ткань данных» решает критические проблемы современных организаций — от устранения информационных «силосов» до обеспечения анализа в режиме реального времени. Подведем итоги:
- Data Fabric создает единую среду для работы с данными. Это устраняет разрозненность и дублирование информации.
- Ускоряет обработку и анализ данных. Решения принимаются быстрее благодаря интеграции и централизованной структуре.
- Гарантирует безопасность данных. Управление доступом позволяет контролировать, кто и какие данные может использовать.
- Поддерживает гибкость и масштабируемость. Технология легко адаптируется к росту объема данных и новых источников.
- Снижает сложность IT-инфраструктуры. Организации получают удобный инструмент для оптимизации работы с информацией.
Если вы только начинаете осваивать управление данными, рекомендуем обратить внимание на подборку курсов по системной-аналитике. В программах предусмотрена как теоретическая, так и практическая часть, что поможет вам быстро понять ключевые принципы технологии.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
112 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
17 марта
|
Подробнее |
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 марта
|
Подробнее |
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
112 отзывов
|
Цена
129 900 ₽
257 760 ₽
Ещё -10% по промокоду
|
От
10 825 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |

Skypro vs ProductStar: куда идти аналитику, чтобы стать продактом — траектория и кейсы
Если вы аналитик и хотите перейти в продакт-менеджмент, но не знаете, с чего начать, эта статья для вас. Мы расскажем, какие шаги и курсы помогут вам освоить нужные навыки, чтобы успешно перейти в продуктовую роль. Задайтесь вопросом: готовы ли вы на решение проблем, а не просто на анализ данных?

Собеседование Devops Junior и Middle: актуальные вопросы и темы 2026 года
Вопросы на собеседовании DevOps могут сильно различаться в зависимости от уровня кандидата. Какие навыки и знания проверяют у Junior и Middle в 2026 году? Мы расскажем, как подготовиться к собеседованию и что важно знать для успешного прохождения интервью.

Собеседование по Python: частые вопросы и как на них отвечать
Готовитесь к техническому интервью и хотите понять, какие вопросы на собеседование Python разработчик слышит чаще всего? Разбираем реальные примеры задач, вопросы для junior, middle и senior, а также типичные ошибки кандидатов и стратегию подготовки.

Skypro vs Contented: Web/UX дизайн — где сильнее разборы работ и быстрее растёт качество
В этой статье мы расскажем, как выбрать лучший курс по веб-дизайну. Если вы только начинаете изучать эту профессию, то вам наверняка будет полезно узнать, что важно учитывать при выборе курса и какие именно аспекты обучения могут ускорить ваш профессиональный рост. Откроем основные моменты, которые помогут вам сделать правильный выбор и избежать распространенных ошибок.