Data Lineage: что это такое, зачем нужен и как внедрить
В эпоху, когда данные стали новой нефтью бизнеса, вопрос их происхождения и достоверности приобретает критическое значение.

Представьте ситуацию: ваш финансовый отчет показывает неожиданный скачок доходности, но никто не может объяснить, откуда взялись эти цифры и какие преобразования к ним применялись. Звучит как кошмар любого аудитора? Именно для решения подобных проблем и существует Data Lineage.
- Что такое Data Lineage простыми словами
- История и предпосылки появления
- Виды и уровни
- Как работает Data Lineage на практике
- Инструменты для DL
- Лучшие практики внедрения
- Кейсы применения
- Проблемы и вызовы внедрения
- Будущее Data Lineage
- Заключение
- Рекомендуем посмотреть курсы по бизнес аналитике
Что такое Data Lineage простыми словами
Если использовать простую метафору, то Data Lineage можно сравнить с системой кровообращения в организме — он показывает, как информация движется по «венам и артериям» корпоративной IT-инфраструктуры. Каждая «капля данных» имеет свою историю: откуда пришла, через какие «органы» (системы) прошла и какие «витамины» (преобразования) получила по пути.
В буквальном переводе Data Lineage означает «родословная данных» — полная история жизни информации от рождения до финального использования. Это процесс документирования и визуализации того, как данные перемещаются между системами, какие трансформации над ними выполняются и кто за это отвечает. Представьте детективное расследование, где нужно восстановить цепочку событий, только вместо преступления мы отслеживаем путь конкретного значения из исходной базы данных до итогового отчета.
Важно не путать Data Lineage с Data Mapping — это принципиально разные концепции. Data Mapping представляет собой статичную схему соответствий между полями различных систем (например, поле «Имя клиента» в CRM соответствует полю «customer_name» в хранилище данных). DL же — это динамический процесс, который показывает реальное движение данных в реальном времени, включая все промежуточные преобразования и бизнес-логику.
Если продолжить аналогию с детективным расследованием, то Data Mapping — это карта города с названиями улиц, а Data Lineage — это GPS-трекер, показывающий реальный маршрут движения от точки А до точки Б, включая все остановки, развороты и объезды. Именно эта динамичность делает DL незаменимым инструментом для понимания того, что действительно происходит с данными в современных сложных IT-ландшафтах.
История и предпосылки появления
Потребность в отслеживании происхождения данных возникла не на пустом месте — она стала закономерным ответом на вызовы эпохи больших данных. В начале 2000-х, когда корпоративные хранилища данных еще помещались на нескольких серверах, а ETL-процессы можно было пересчитать по пальцам, вопрос происхождения данных решался довольно просто — достаточно было спросить у разработчика или посмотреть в документацию.
Однако стремительный рост объемов данных кардинально изменил ситуацию. Появление концепций Data Lake, распределенных вычислений и облачных платформ привело к тому, что современная корпоративная экосистема может включать десятки источников данных, сотни ETL-процессов и тысячи таблиц. В таких условиях ручное отслеживание происхождения данных стало практически невозможным — как попытка проследить родословную в городе с миллионным населением без архивов и документов.
Критическим моментом стало ужесточение регулятивных требований. Законы о защите персональных данных (GDPR в Европе, 152-ФЗв России) потребовали от компаний не только знать, где хранятся персональные данные, но и документировать все их преобразования. Финансовые регуляторы стали требовать полной прозрачности в формировании отчетности, а аудиторы — детального обоснования каждой цифры в финансовых документах.
В российском контексте дополнительные стимулы для развития Data Lineage создали требования внутреннего аудита и необходимость соответствия отраслевым стандартам. Банковский сектор, например, должен обеспечивать полную прослеживаемость данных для отчетов в Центральный банк, а государственные компании — соответствовать стандартам информационной безопасности. Все это превратило Data Lineage из «приятной опции» в критически важную бизнес-потребность.
Виды и уровни
DL работает на разных уровнях детализации — от высокоуровневого обзора потоков данных до отслеживания отдельных значений. Понимание этих уровней критически важно для выбора правильного подхода к внедрению системы отслеживания происхождения данных.
Table-level
Самый базовый уровень отслеживания показывает движение целых таблиц и наборов данных между системами. Например: данные о клиентах из CRM-системы попадают в корпоративное хранилище данных, затем агрегируются в витрину данных для отдела маркетинга. Этот уровень помогает понять общую архитектуру потоков данных и выявить зависимости между системами.
Column-level
Более детальный уровень отслеживает преобразования отдельных атрибутов и полей. Здесь мы видим, как поле «Дата рождения» клиента трансформируется в «Возрастную группу» через формулу расчета возраста. Или как несколько полей объединяются в одно — например, «Имя», «Фамилия» и «Отчество» превращаются в «Полное имя». Этот уровень критически важен для понимания бизнес-логики преобразований.
Report-level
Этот уровень связывает технические данные с бизнес-отчетами и KPI. Он показывает, какие источники данных влияют на конкретные метрики в панелях управления руководителей. Например, KPI «Средний чек» формируется из данных о продажах (таблица orders), информации о продуктах (таблица products) и курсах валют (внешний API).
Cross-system
Межсистемное отслеживание показывает движение данных через различные платформы, базы данных и облачные сервисы. Особенно актуально в гибридных средах, где данные могут перемещаться между on-premise решениями и облачными платформами, проходя через различные ETL-инструменты и API-интеграции.
Cell-level
Самый детальный уровень отслеживания конкретных значений — от исходной записи до финального использования. Этот подход иногда называют Data Provenance и применяют в критически важных сценариях, таких как медицинские исследования или финансовая отчетность, где необходимо проследить происхождение каждого числа в отчете до конкретной транзакции или измерения.
Диаграмма показывает пять уровней Data Lineage — от таблиц до отдельных значений. Она помогает визуально понять, как меняется детализация отслеживания данных.
Как работает Data Lineage на практике
На практике система функционирует как сложный механизм непрерывного мониторинга и документирования, который можно разделить на четыре ключевых этапа.
Этап 1: Выявление и каталогизация источников.
Система автоматически сканирует корпоративную инфраструктуру, выявляя все источники данных — от транзакционных баз данных и ERP-систем до внешних API и файловых хранилищ. На этом этапе собираются метаданные о структуре, форматах и владельцах данных. Современные инструменты используют коннекторы для интеграции с популярными системами — от Oracle и PostgreSQL до Snowflake и AWS S3.
Этап 2: Фиксация преобразований и трансформаций.
Здесь происходит магия — система отслеживает каждое преобразование данных. Это может быть простая фильтрация записей, сложные SQL-запросы с джоинами, алгоритмы машинного обучения или бизнес-правила в ETL-процессах. Ключевым элементом является создание направленного ациклического графа (DAG), который визуализирует зависимости между данными — от исходных таблиц до производных метрик.
Этап 3: Документирование результирующих активов.
Конечные точки данных — отчеты, дашборды, ML-модели — связываются с их источниками через цепочку преобразований. Система фиксирует не только технические аспекты (какие таблицы и поля использованы), но и бизнес-контекст (для каких решений используется отчет, кто его владелец).
Этап 4: Мониторинг в реальном времени.
Современные решения предоставляют возможность отслеживания изменений в режиме реального времени. Когда изменяется исходная схема данных или модифицируется ETL-процесс, система автоматически обновляет граф lineage и может предупреждать о потенциальных проблемах downstream-систем.этапы lineage
Подпись: Блок-схема иллюстрирует четыре ключевых этапа работы Data Lineage: от выявления источников данных до мониторинга изменений в реальном времени. Это помогает увидеть весь процесс как единый цикл.
Блок-схема иллюстрирует четыре ключевых этапа работы Data Lineage: от выявления источников данных до мониторинга изменений в реальном времени. Это помогает увидеть весь процесс как единый цикл.
Основные преимущества такого подхода очевидны: быстрая локализация проблем (если отчет показывает неожиданные результаты, можно быстро найти источник ошибки), анализ влияния изменений (перед модификацией базы данных можно оценить, какие отчеты это затронет) и обеспечение прозрачности для аудиторов и регуляторов. В результате DL превращается из технического инструмента в стратегический актив для управления данными.
Инструменты для DL
Ландшафт инструментов для реализации Data Lineage весьма разнообразен — от open-source решений до корпоративных платформ с широким функционалом. Выбор конкретного инструмента зависит от технической зрелости организации, бюджета и специфических требований к интеграции.
Open-source решения
Apache Atlas представляет собой комплексную платформу управления метаданными для экосистемы Hadoop, включающую мощные возможности lineage. Особенно эффективен в средах с активным использованием Spark, Hive и других компонентов Big Data стека. Marquez от WeWork предлагает более легковесный подход, фокусируясь на отслеживании metadata через OpenLineage API. Amundsen от Lyft сочетает каталог данных с базовыми функциями lineage, предоставляя user-friendly интерфейс для data discovery.
BI-платформы с интегрированным lineage
Российские решения активно развивают функционал отслеживания данных. 1С:Аналитика включает модули для визуализации потоков данных и интеграции с корпоративными системами на базе 1С. Яндекс DataLens предоставляет базовые возможности lineage для источников данных и создаваемых в системе отчетов, что особенно удобно для небольших и средних проектов.
Платформы управления метаданными
Collibra, Alation и Informatica представляют enterprise-класс решений с продвинутыми возможностями automated lineage discovery, business glossary и data governance workflows. Эти платформы могут автоматически сканировать десятки различных источников данных и строить комплексные карты lineage на всех уровнях детализации.
Специализированные Data Quality системы
Инструменты вроде Octopai и MANTA фокусируются именно на lineage как основной функции, предлагая глубокую аналитику потоков данных и impact analysis. Они особенно эффективны в сложных средах с множественными ETL-процессами и legacy-системами.
OpenLineage стандарт
Особого внимания заслуживает OpenLineage — открытый стандарт для обмена metadata о lineage между различными системами. Разработанный под эгидой Linux Foundation, он позволяет создавать vendor-agnostic решения и обеспечивает совместимость между различными инструментами в data pipeline.
| Инструмент | Особенности | Для кого подходит |
|---|---|---|
| Apache Atlas | Hadoop-ориентированный, open-source | Big Data команды |
| Alation | Enterprise каталог + lineage | Крупные корпорации |
| 1С:Аналитика | Российская разработка, интеграция с 1С | Компании на 1С-стеке |
| DataLens | Простота внедрения, облачность | Малый и средний бизнес |
| OpenLineage | Стандартизация и совместимость | Технически зрелые команды |
Лучшие практики внедрения
Успешное внедрение системы отслеживания происхождения данных требует системного подхода, который учитывает как технические, так и организационные аспекты. Наш опыт показывает, что большинство неудач связано не с выбором неправильного инструмента, а с недостаточным планированием и игнорированием человеческого фактора.
Майнд-карта наглядно собирает ключевые факторы успешного внедрения Data Lineage: постановка целей, распределение ролей, сочетание автоматизации и ручного контроля, итеративность, регулярный аудит и обучение пользователей. Визуализация помогает запомнить все шаги как единую систему.
Определение четких целей и приоритетов
Первый шаг — понимание того, зачем именно вашей организации нужен DL. Различные цели требуют разных подходов к реализации. Если приоритет — соответствие регулятивным требованиям (compliance), начинайте с column-level lineage для персональных данных и финансовой информации. Для оптимизации процессов фокусируйтесь на наиболее часто используемых наборах данных и выявлении избыточных трансформаций. В случае улучшения качества аналитики акцент делается на отслеживании источников для ключевых бизнес-метрик.
Назначение ролей и ответственности
Создание эффективной системы DL невозможно без четкого распределения ролей. Data Stewards отвечают за бизнес-контекст и качество метаданных в своих доменах. Data Engineers обеспечивают техническую реализацию отслеживания в ETL-процессах. Data Analysts валидируют корректность lineage и дополняют его бизнес-логикой. Критически важно назначить координатора проекта, который будет синхронизировать усилия всех участников и следить за полнотой покрытия.
Гибридный подход: автоматизация плюс ручная аннотация
Полностью автоматическое построение lineage работает далеко не всегда — особенно в случае сложных бизнес-правил, legacy-систем или нестандартных интеграций. Эффективная стратегия сочетает automated discovery для стандартных случаев (SQL-запросы, популярные ETL-инструменты) с ручным документированием для уникальной бизнес-логики. Важно создать процессы регулярной валидации автоматически обнаруженных связей и дополнения их бизнес-контекстом.
Итеративный подход к внедрению
Не пытайтесь охватить всю корпоративную экосистему данных сразу. Начните с пилотного проекта на критически важном для бизнеса домене данных — например, customer analytics или financial reporting. Это позволит отработать процессы, обучить команду и продемонстрировать ценность решения заинтересованным сторонам. После успешного пилота постепенно расширяйте покрытие на другие области.
Ключевые принципы для успешного внедрения: регулярный аудит полноты и актуальности lineage (рекомендуется ежемесячно), интеграция с существующими процессами разработки и развертывания, обучение пользователей работе с системой и создание культуры ответственности за качество метаданных.
Кейсы применения
Практическое применение Data Lineage существенно различается в зависимости от отрасли и специфики бизнес-процессов. Рассмотрим наиболее характерные сценарии использования, которые демонстрируют реальную ценность систем отслеживания происхождения данных.
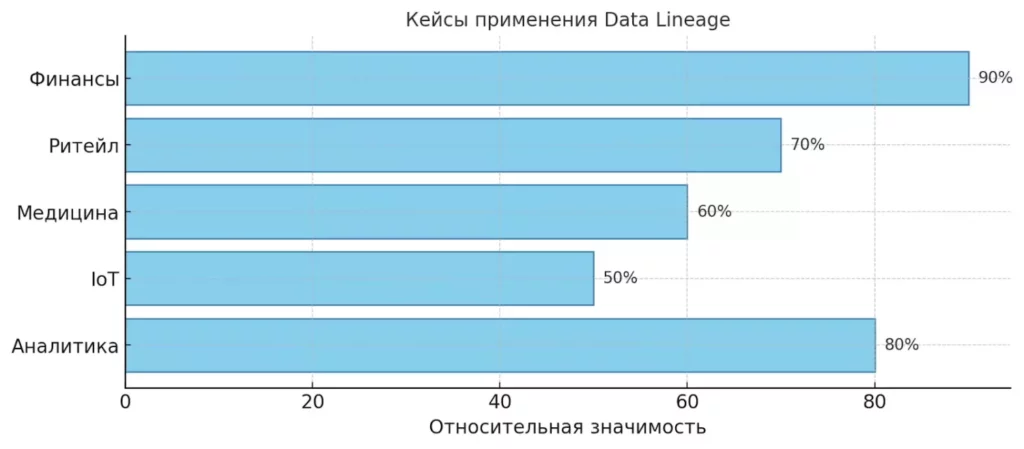
Горизонтальная диаграмма показывает, в каких отраслях Data Lineage наиболее значим: финансовый сектор, корпоративная аналитика и ритейл лидируют, медицина и IoT тоже играют важную роль. Такой визуальный акцент помогает быстро сравнить области применения.
Финансовый сектор: прозрачность отчетности и аудит
В банковской сфере DL становится критически важным инструментом для подготовки регулятивной отчетности. Например, при формировании отчета о достаточности капитала система отслеживает каждый показатель от исходных транзакций в core-banking системе через промежуточные расчеты рисков до итоговых коэффициентов. Когда аудитор Центрального банка запрашивает обоснование конкретной цифры, банк может предоставить полную цепочку преобразований с указанием всех использованных алгоритмов и бизнес-правил.
Логистика и ритейл: интеграция множественных источников
Крупные торговые сети работают с десятками ERP-систем, WMS, системами прогнозирования спроса и внешними поставщиками данных о погоде или экономических индикаторах. Data Lineage помогает отследить, как изменение прогноза погоды влияет на планы закупок сезонных товаров, или выяснить, почему система рекомендаций предлагает неожиданные товары. Когда прогноз оказывается неточным, lineage позволяет быстро определить, какой из источников данных дал сбой.
Медицина и фармацевтика: контроль научных исследований
В клинических исследованиях DL обеспечивает прослеживаемость от первичных измерений (анализы пациентов, показания приборов) до публикуемых результатов. Это критически важно для peer review процесса и соответствия стандартам FDA или EMA. Например, если в статье утверждается, что препарат снижает давление на 15%, lineage позволяет проследить этот результат до конкретных измерений у конкретных пациентов с учетом всех исключений и корректировок.
Big Data и IoT: автоматизация мониторинга аномалий
В промышленных IoT-системах Data Lineage помогает быстро локализовать источники аномалий. Когда система предиктивного обслуживания выдает предупреждение о возможной поломке турбины, lineage показывает, какие именно датчики и алгоритмы привели к этому выводу. Это позволяет инженерам сфокусироваться на проверке конкретных компонентов, а не проводить общую диагностику всего оборудования.
Корпоративная аналитика: согласованность между департаментами
Часто возникают ситуации, когда отдел продаж и финансовый департамент представляют разные цифры выручки за один период. Data Lineage помогает выяснить причины расхождений: возможно, отдел продаж считает по дате заключения сделки, а финансисты — по дате поступления средств на счет. Или применяются разные правила обработки возвратов и отмененных заказов. Понимание этих различий позволяет либо унифицировать подходы, либо корректно интерпретировать различия в контексте бизнес-процессов.
Проблемы и вызовы внедрения
Несмотря на очевидные преимущества, внедрение Data Lineage сталкивается с рядом серьезных технических и организационных вызовов. Понимание этих сложностей поможет избежать типичных ошибок и выстроить реалистичные ожидания от проекта.
Сложные трансформации и черные ящики.
Современные системы часто включают компоненты, которые сложно поддаются автоматическому анализу — алгоритмы машинного обучения, stored procedures с комплексной бизнес-логикой, real-time stream processing с динамическими правилами маршрутизации. Нейросетевые модели, например, могут использовать сотни признаков для генерации предсказаний, но проследить вклад каждого исходного поля в финальный результат технически крайне сложно. В таких случаях приходится полагаться на ручное документирование и доверие к экспертизе data scientists.
Баланс автоматизации и человеческого контроля.
Полностью автоматизированные системы часто пропускают важные бизнес-контексты или неправильно интерпретируют сложную логику. С другой стороны, избыточная зависимость от ручного документирования приводит к устареванию метаданных и снижению доверия к системе. Оптимальный подход требует создания гибридных workflow, где автоматическое обнаружение дополняется человеческой экспертизой, но при этом сохраняется культура регулярного обновления документации.
Многоуровневый контекст и семантика.
Техническое отслеживание движения данных — это только половина задачи. Полноценный Data Lineage должен включать бизнес-контекст: почему выполняется конкретное преобразование, какую бизнес-логику оно реализует, кто принимал решение об изменении алгоритма. Без этого контекста система превращается в техническую схему, полезную для разработчиков, но бесполезную для бизнес-пользователей и аудиторов.
Дополнительные сложности возникают при работе с legacy-системами, где документация может отсутствовать, а логика преобразований скрыта в устаревшем коде. Интеграция с cloud-native решениями также требует особого внимания — данные могут обрабатываться serverless-функциями, которые создаются и уничтожаются динамически, что затрудняет построение стабильного графа зависимостей.
Будущее Data Lineage
Развитие технологий Data Lineage происходит в контексте более широких трендов цифровой трансформации, где искусственный интеллект и автоматизация играют все более важную роль. Мы наблюдаем качественные изменения в подходах к управлению данными, которые формируют новую парадигму корпоративной аналитики.
Роль AI в эволюции систем отслеживания.
Современные решения активно интегрируют машинное обучение для автоматического обнаружения неявных связей между данными, которые традиционные методы парсинга SQL или анализа метаданных не могут выявить. ИИ-системы начинают анализировать семантическое сходство полей данных, предлагать потенциальные связи на основе паттернов использования и даже предсказывать влияние изменений в upstream-системах на downstream-процессы. Это особенно актуально в эпоху, когда ChatGPT и аналогичные модели демонстрируют способности к пониманию контекста и выявлению скрытых закономерностей.
Data Governance как фундамент доверия.
Data Lineage превращается из технического инструмента в основу для комплексных Data Governance frameworks. Организации начинают строить политики управления данными, автоматически применяя правила классификации, контроля доступа и retention на основе lineage-информации. Если система знает, что конкретное поле содержит персональные данные и отслеживает все его производные, она может автоматически применять соответствующие политики GDPR ко всей цепочке трансформаций.
Культурный сдвиг: от недоверия к прозрачности.
Возможно, самое важное изменение происходит на уровне корпоративной культуры. Data Lineage способствует формированию среды, где прозрачность происхождения данных становится нормой, а не исключением. Это фундаментально меняет отношение к принятию решений на основе данных — от «мы верим этим цифрам, потому что их предоставил эксперт» к «мы понимаем, откуда взялись эти цифры и какие допущения в них заложены». Такой подход особенно важен в эпоху, когда ошибки в данных могут приводить к миллиардным потерям или неправильным стратегическим решениям.
В перспективе Data Lineage станет неотъемлемой частью современной data-driven организации — такой же базовой потребностью, как система контроля версий для разработчиков программного обеспечения.
Заключение
Data Lineage представляет собой не просто техническое решение, а стратегический подход к построению доверия в эпоху data-driven бизнеса. В мире, где данные становятся основой для принятия критически важных решений, способность проследить происхождение каждой цифры от источника до финального отчета превращается из «nice to have» в абсолютную необходимость.
- Data Lineage помогает понять происхождение и путь данных. Это повышает прозрачность и доверие к информации.
- Инструменты lineage автоматизируют отслеживание потоков. Это сокращает время на поиск ошибок и упрощает аудит.
- Разные уровни детализации дают контроль от таблиц до отдельных значений. Это позволяет выбирать подходящий масштаб анализа.
- Реализация DL требует целей, ролей и гибридного подхода. Такой метод снижает риски провала проекта.
- Системы lineage полезны для финансов, медицины, ритейла и IoT. Они помогают компаниям обеспечивать точность и согласованность данных.
- Будущее Data Lineage связано с AI и Data Governance. Это делает его стратегическим инструментом для бизнеса.
Если вы только начинаете осваивать профессию в области анализа и управления данными, рекомендуем обратить внимание на подборку курсов по бизнес-аналитике. В них есть и теоретическая, и практическая часть, что поможет быстрее понять основы и научиться применять их в работе.
Рекомендуем посмотреть курсы по бизнес аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Бизнес-аналитик
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
|
От
4 579 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Бизнес-аналитик
|
Нетология
46 отзывов
|
Цена
125 500 ₽
253 600 ₽
с промокодом kursy-online
|
От
3 874 ₽/мес
Без переплат на 2 года.
5 897 ₽/мес
|
Длительность
6 месяцев
|
Старт
24 марта
|
Подробнее |
|
Профессия Бизнес-аналитик
|
Skillbox
232 отзыва
|
Цена
105 680 ₽
264 200 ₽
с промокодом KURSHUB
|
От
3 409 ₽/мес
Без переплат на 31 месяц с отсрочкой платежа 6 месяцев.
9 212 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Бизнес-аналитик с нуля
|
Eduson Academy
114 отзывов
|
Цена
149 900 ₽
|
От
12 492 ₽/мес
|
Длительность
6 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Бизнес-аналитик
|
Академия Синергия
38 отзывов
|
Цена
84 900 ₽
|
От
3 538 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.