Датасет: что это такое, зачем нужен и как его собрать
В эпоху искусственного интеллекта и машинного обучения мы постоянно слышим о том, насколько важны качественные данные для создания эффективных алгоритмов. ChatGPT, Stable Diffusion и другие нейросети достигли своих впечатляющих результатов благодаря одному критически важному компоненту — правильно подготовленным датасетам.

Но что же такое датасет на самом деле? Как его создать для собственных задач машинного обучения? И почему простое накопление информации еще не гарантирует успех в аналитике? В этой статье мы разберем все аспекты работы с датасетами — от базовых концепций до практических советов по их созданию и оптимизации.
- Что такое датасет: простое объяснение
- Из чего состоит датасет
- Какие бывают типы датасетов
- Популярные готовые датасеты для машинного обучения
- Как собрать свой датасет
- Практические советы по работе с датасетами
- Заключение
- Рекомендуем посмотреть курсы по машинному обучению
Что такое датасет: простое объяснение
Представьте, что у вас есть коллекция из тысячи фотографий животных, хранящаяся в папке на компьютере. Сама по себе эта коллекция — просто набор файлов, практически бесполезный для машинного обучения. Но стоит к каждой фотографии добавить подпись с указанием вида животного, его породы и других характеристик — и мы получаем датасет.
Датасет (от английского dataset) — это структурированный и обработанный массив данных, где каждому объекту присвоены конкретные свойства и характеристики. В отличие от «сырых данных», которые могут быть хаотичными и неопределенными, датасет представляет собой упорядоченную информацию, готовую для анализа и обучения алгоритмов.
Ключевое различие между обычными данными и датасетом заключается в структуре и назначении. Если обычные данные — это неструктурированная информация (текстовые файлы, изображения, аудиозаписи), то датасет — это организованная система, где каждый элемент имеет четко определенные признаки и связи с другими элементами.
В машинном обучении датасеты играют роль «учебника» для алгоритмов. Они делятся на три основные части: обучающую выборку (где модель изучает закономерности), валидационную (для настройки параметров) и тестовую (для финальной оценки качества). Этот принцип лежит в основе работы всех современных AI-систем — от рекомендательных алгоритмов в соцсетях до беспилотных автомобилей.
Из чего состоит датасет
Объекты и признаки
Любой датасет можно представить в виде таблицы, где каждая строка — это отдельный объект, а каждый столбец — признак этого объекта. Объект представляет собой единицу анализа: это может быть покупатель в интернет-магазине, медицинский снимок, финансовая транзакция или даже целое предложение в тексте.
Признаки (или фичи, от английского features) — это измеримые характеристики объекта. Для покупателя это могут быть возраст, пол, история покупок и географическое местоположение. Для медицинского снимка — размер, яркость, наличие определенных структур. Важно понимать разницу между признаками и целевой переменной (target): признаки описывают объект, а целевая переменная — это то, что мы хотим предсказать.
Интересная особенность современных датасетов заключается в том, что признаки часто кодируются цифрами. Например, пол покупателя может быть представлен как «0» для мужчин и «1» для женщин, а географическое положение — через систему бинарных признаков для каждого города.
Размерность, разреженность, разрешение
Размерность датасета определяется количеством признаков. Казалось бы, чем больше признаков, тем лучше — однако здесь кроется подводный камень, известный как «проклятие размерности». С ростом количества признаков сложность обработки увеличивается экспоненциально, а не линейно. Датасет с сотней признаков может потребовать в тысячи раз больше вычислительных ресурсов, чем датасет с десятью признаками.
Разреженность показывает, какая доля данных в датасете заполнена значимыми (ненулевыми) значениями. Многие реальные датасеты оказываются сильно разреженными. Например, в датасете покупок клиент может купить только 5 товаров из 10 000 доступных — получается, что 99,95% признаков будут равны нулю. Это нормальная ситуация, но она требует специальных методов обработки.
Разрешение характеризует детализацию данных. Для временных рядов это частота измерений (ежесекундно, ежечасно, ежедневно), для изображений — количество пикселей, для географических данных — точность координат. Правильное разрешение критически важно: слишком низкое может упустить важные закономерности, а слишком высокое — создать информационный шум и увеличить вычислительную нагрузку.
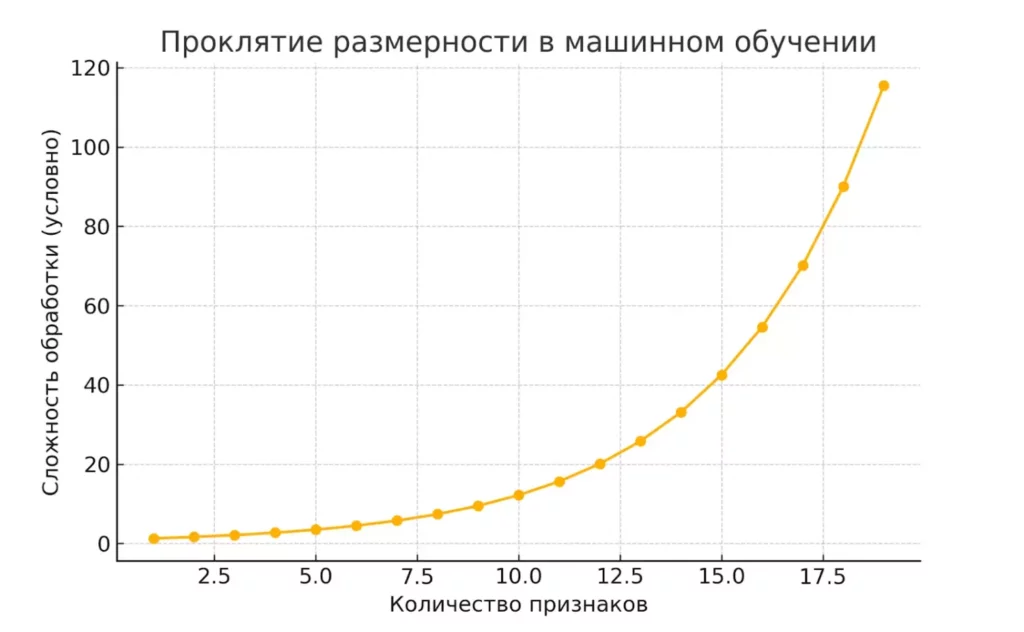
Экспоненциальный рост сложности обработки данных с увеличением количества признаков.
Какие бывают типы датасетов
Простые записи (таблицы)
Классический и наиболее распространенный тип датасетов представляет собой двумерную таблицу, где строки — это объекты наблюдения, а столбцы — их признаки. Такая структура интуитивно понятна и напоминает привычные Excel-таблицы или базы данных.
В этом формате нет явных связей между строками — каждая запись независима и содержит полный набор характеристик объекта. Примерами могут служить данные о клиентах банка (возраст, доходы, кредитная история), результаты медицинских анализов или статистика продаж по регионам. Такие датасеты обычно хранятся в форматах CSV, Excel или реляционных базах данных.
Внутри табличных данных выделяют несколько подвидов: транзакционные данные (где важен факт совершения действия), матрицы данных (с фиксированным набором числовых признаков) и разреженные матрицы (где большинство значений равно нулю).
Графы
Когда в данных важны не только характеристики объектов, но и связи между ними, используются графовые датасеты. Граф состоит из узлов (объектов) и ребер (связей между ними). Социальные сети — классический пример: пользователи являются узлами, а дружеские связи или подписки — ребрами.
Графы могут быть направленными (связь односторонняя) и ненаправленными (взаимная связь), взвешенными (где связи имеют различную силу) и невзвешенными. В логистике графы помогают оптимизировать маршруты доставки, в биоинформатике — анализировать взаимодействие белков, а в рекомендательных системах — находить похожих пользователей.
Упорядоченные записи
Этот тип датасетов характеризуется важностью последовательности или расположения данных в пространстве и времени. Здесь порядок следования элементов несет критически важную информацию.
Временные ряды представляют данные, изменяющиеся во времени: котировки акций, показания датчиков IoT, метеорологические наблюдения. Последовательности включают тексты (где важен порядок слов), ДНК-последовательности, логи системных событий. Пространственные данные содержат географические координаты: GPS-треки, карты, спутниковые снимки.
| Тип датасета | Пример | Где используется |
|---|---|---|
| Табличные данные | Покупки, Excel, CRM | Финансы, маркетинг |
| Графы | Связи между пользователями | Соцсети, логистика |
| Последовательности | Временные ряды, тексты | IoT, прогнозирование |
Каждый тип требует специфических методов обработки и анализа — то, что работает для табличных данных, может оказаться неэффективным для графов или временных рядов.
Популярные готовые датасеты для машинного обучения
Прежде чем создавать собственный датасет с нуля, стоит изучить уже существующие решения — это поможет понять стандарты качества и сэкономить значительное количество времени. Мы рассмотрим наиболее значимые датасеты, сгруппированные по областям применения.
Для компьютерного зрения
ImageNet остается золотым стандартом для задач классификации изображений. Этот датасет содержит более 14 миллионов изображений, разделенных на 20 000 категорий. Именно на ImageNet тестируются новые архитектуры нейросетей, и именно здесь впервые продемонстрировали свою эффективность сверточные нейронные сети.
MS COCO специализируется на задачах обнаружения и сегментации объектов. Помимо меток классов, здесь есть точные контуры объектов на изображениях, что делает его незаменимым для обучения моделей компьютерного зрения высокого уровня.
Labelled Faces in the Wild содержит более 13 000 размеченных изображений лиц и широко используется для разработки систем распознавания. Особенность датасета — разнообразие условий съемки: различное освещение, ракурсы, выражения лиц.
Для обработки естественного языка
Stanford Sentiment Treebank — классический датасет для анализа тональности текста, где каждое предложение размечено по шкале от крайне негативного до крайне позитивного. Его используют для обучения моделей, которые должны понимать эмоциональную окраску текста.
HotspotQA Dataset содержит пары «вопрос-ответ» и применяется для создания систем автоматических ответов. Особенность датасета в том, что для получения ответа часто требуется проанализировать несколько связанных фрагментов текста.
Amazon Reviews представляет собой массивную коллекцию отзывов покупателей за 18-летний период. Этот датасет позволяет анализировать потребительские предпочтения и строить рекомендательные системы.
Для автопилотов
Berkeley DeepDrive BDD100k — крупнейший открытый датасет для беспилотного вождения, содержащий 100 000 видеозаписей в различных условиях: день, ночь, дождь, разные типы дорог. Каждый кадр содержит разметку объектов: автомобили, пешеходы, дорожные знаки.
Baidu Apolloscapes фокусируется на семантической сегментации сцен с возможностью распознавания 26 различных типов объектов городской среды.
Cityscape Dataset предоставляет высококачественные изображения городских улиц из 50 городов с детальной пиксельной разметкой.
Для медицины
MIMIC-III — один из немногих открытых медицинских датасетов, содержащий обезличенную информацию о 40 000 пациентах отделений интенсивной терапии. Включает жизненные показатели, назначенные лекарства, результаты анализов и исходы лечения.
Работа с медицинскими данными требует особой осторожности из-за вопросов конфиденциальности и этических соображений — именно поэтому качественных открытых датасетов в этой области относительно мало.
Поиск готовых датасетов лучше всего начинать с Google Dataset Search — специализированной поисковой системы по наборам данных, а также изучить коллекции на платформе Kaggle, где регулярно проводятся соревнования по машинному обучению с использованием реальных датасетов.
Главная страница Google Dataset Search.
Как собрать свой датасет
1. Определите цель
Прежде чем приступать к сбору данных, необходимо четко сформулировать задачу. Что именно вы хотите предсказать или проанализировать? От этого зависит структура будущего датасета, объем необходимых данных и методы их сбора.
Определите тип задачи: классификация (отнести объект к одной из категорий), регрессия (предсказать числовое значение) или кластеризация (найти группы похожих объектов). Для классификации изображений кошек и собак нужны тысячи размеченных фотографий, для прогноза продаж — исторические данные о транзакциях и внешних факторах.
2. Сбор данных
Ручной сбор подразумевает личное участие в создании датасета. Это может быть фотографирование объектов, анкетирование, ручная обработка документов. Метод трудозатратный, но обеспечивает высокое качество и полный контроль над процессом.
Автоматизированный сбор использует программные решения: парсеры веб-сайтов, API социальных сетей, данные с IoT-датчиков, системы логирования. Современные инструменты позволяют собирать огромные объемы данных, но требуют последующей фильтрации и проверки качества.
3. Разметка данных
Это один из наиболее критических этапов. Разметка — процесс присвоения меток или аннотаций каждому объекту в датасете. Для изображений это может быть указание класса объекта или выделение контуров, для текстов — определение тональности или извлечение именованных сущностей.
Разметку можно выполнять самостоятельно (для небольших датасетов), привлекать специализированные платформы краудсорсинга (Amazon Mechanical Turk, Toloka) или передавать на аутсорс компаниям, специализирующимся на подготовке данных. Важно обеспечить согласованность разметки между разными исполнителями.
4. Очистка и предобработка
Сырые данные почти никогда не готовы к использованию. Необходимо удалить дубликаты, исправить ошибки, заполнить пропущенные значения. Категориальные признаки (например, названия городов) преобразуются в числовые через методы one-hot encoding или label encoding.
Нормализация приводит данные к единому масштабу — это критически важно для алгоритмов, чувствительных к разбросу значений. Доходы в миллионах рублей и возраст в годах должны быть приведены к сопоставимым диапазонам.
5. Деление на выборки
Финальный этап — разделение датасета на три независимых части:
- Обучающая выборка (60-80%) — для непосредственного обучения модели.
- Валидационная выборка (10-20%) — для настройки гиперпараметров и выбора лучшей модели.
- Тестовая выборка (10-20%) — для финальной оценки качества.
Важно обеспечить репрезентативность каждой выборки: распределение классов и основных характеристик должно быть примерно одинаковым во всех частях. Для временных рядов используется хронологическое разделение — более поздние данные идут в тестовую выборку.
Практические советы по работе с датасетами
Сколько данных действительно нужно?
Один из самых частых вопросов начинающих специалистов — определение минимально необходимого объема данных. Универсального ответа не существует, но есть практические ориентиры. Для простых задач классификации с небольшим количеством признаков может хватить нескольких сотен примеров на класс. Однако современные глубокие нейросети, подобные тем, что используются в GPT или Stable Diffusion, требуют миллионы, а иногда и миллиарды примеров.
Хотя универсального правила нет, для сложных задач требуются огромные объемы данных. При этом современные исследования (например, законы масштабирования для языковых моделей) показывают, что оптимальное соотношение между размером модели и объемом данных является сложной темой, и простое правило «10 к 1» не применяется
Борьба с несбалансированными классами
Реальные датасеты редко бывают идеально сбалансированными. В медицинской диагностике здоровых пациентов может быть в разы больше, чем больных; в задачах обнаружения мошенничества — подавляющее большинство транзакций оказываются легальными. Такой дисбаланс может привести к тому, что модель будет просто предсказывать наиболее частый класс.
Существует несколько стратегий решения: увеличение количества примеров редких классов (oversampling), уменьшение количества примеров частых классов (undersampling), или генерация синтетических данных с помощью алгоритмов типа SMOTE. Альтернативный подход — использование взвешенных функций потерь, которые штрафуют ошибки на редких классах сильнее.
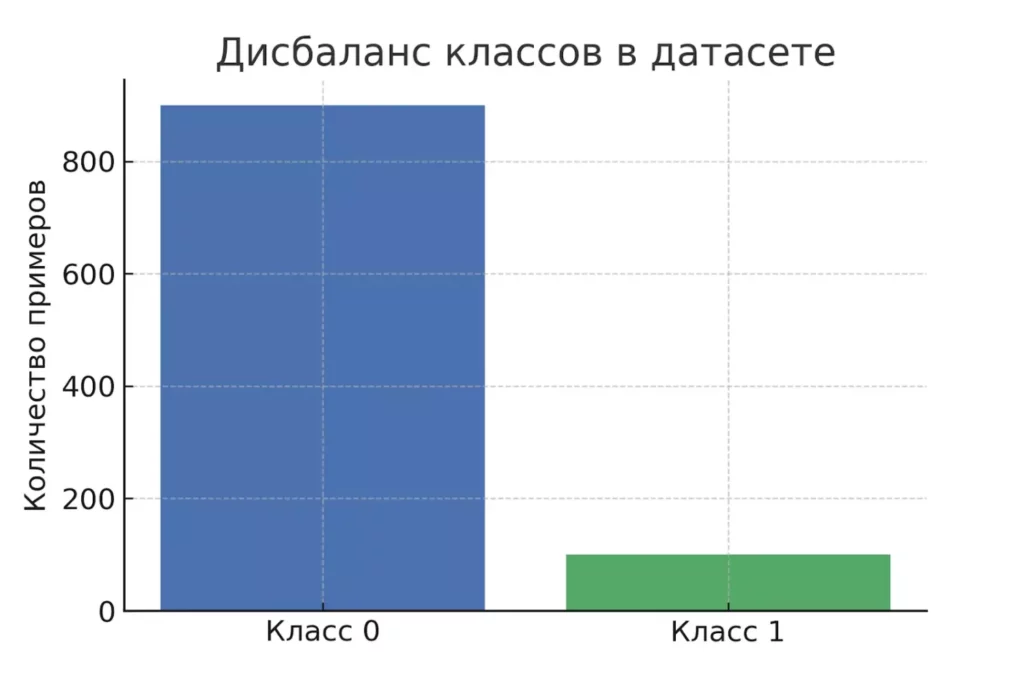
Гистограмма, демонстрирующая дисбаланс классов: 90% объектов одного класса и 10% другого.
Снижение размерности: когда признаков слишком много
Проклятие размерности — реальная проблема современного машинного обучения. Датасеты с тысячами признаков могут содержать много избыточной или шумной информации. Методы снижения размерности помогают выделить наиболее важные закономерности.
Отбор признаков включает статистические методы (корреляционный анализ, хи-квадрат тесты) и алгоритмические подходы (важность признаков в случайном лесе). Метод главных компонент (PCA) создает новые признаки как линейные комбинации исходных, сохраняя максимум информации при меньшем количестве измерений.Результат применения PCA: многомерные данные сведены к двум главным компонентам.
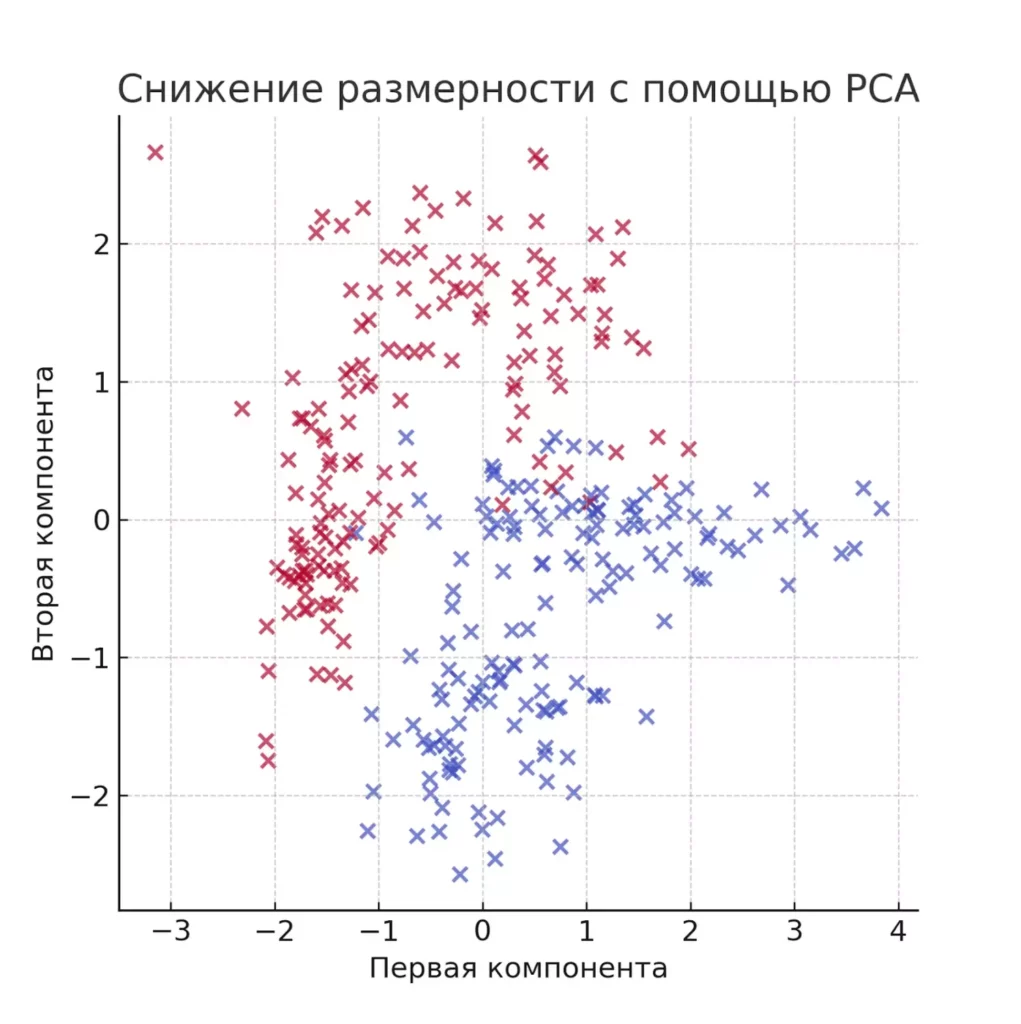
Результат применения PCA: многомерные данные сведены к двум главным компонентам.
Избегайте утечки данных
Одна из самых коварных ошибок — использование информации из будущего для предсказания прошлого, или случайное попадание тестовых данных в обучающую выборку. Классический пример: включение в признаки информации, которая появляется одновременно с целевой переменной или после нее.
Для временных рядов критически важно соблюдать хронологический порядок — модель должна обучаться только на данных, предшествующих моменту прогноза. Для остальных задач необходимо тщательно проверять независимость обучающей и тестовой выборок.
Валидация качества данных
Даже самые аккуратные процессы сбора данных могут содержать ошибки. Регулярная проверка включает поиск выбросов (аномально больших или малых значений), анализ распределений признаков, проверку логической согласованности данных.
Полезно визуализировать данные перед началом работы — графики распределений, корреляционные матрицы, scatter plots помогают выявить неочевидные проблемы. Автоматические инструменты профилирования данных могут существенно ускорить этот процесс.
Заключение
Качественный датасет — это фундамент любого успешного проекта в области машинного обучения и аналитики данных. Мы рассмотрели путь от понимания базовых концепций до практических аспектов создания и оптимизации наборов данных.
Ключевые принципы, которые стоит запомнить:
- Датасет — это не просто коллекция информации, а основа для обучения моделей машинного обучения. Он структурирован и подготовлен по правилам.
- Существуют разные форматы датасетов: табличные, графовые, последовательные. Каждый решает свои задачи.
- Процесс создания датасета включает сбор, разметку, очистку и деление на выборки. Это стандарт в ML-проектах.
- Важно учитывать баланс классов, избегать утечки данных и следить за размерностью признаков. Это влияет на точность модели.
- Можно использовать готовые датасеты, но часто выгоднее собрать собственный набор данных — это даёт лучшие результаты.
Если вы только начинаете осваивать машинное обучение, рекомендуем обратить внимание на подборку курсов по Machine learning. В них есть теоретическая база и практическая работа с реальными данными.
Рекомендуем посмотреть курсы по машинному обучению
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Специалист Data Scientist с нуля
|
Eduson Academy
110 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
|
Длительность
9 месяцев
|
Старт
26 февраля
|
Подробнее |
|
Онлайн-курс по машинному обучению для начинающих
|
Karpov.Courses
75 отзывов
|
Цена
129 000 ₽
181 100 ₽
|
От
7 546 ₽/мес
|
Длительность
7 месяцев
|
Старт
8 марта
|
Подробнее |
|
Машинное обучение
|
Нетология
46 отзывов
|
Цена
53 600 ₽
99 268 ₽
с промокодом kursy-online
|
От
2 481 ₽/мес
Без переплат на 18 месяцев.
|
Длительность
10 месяцев
|
Старт
26 февраля
|
Подробнее |
|
Пакет курсов Data Scientist: Python + SQL + Машинное обучение
|
Stepik
33 отзыва
|
Цена
3 900 ₽
|
От
975 ₽/мес
|
Длительность
3 месяца
|
Старт
в любое время
|
Подробнее |
|
Профессия Machine Learning Engineer
|
Skillbox
226 отзывов
|
Цена
182 297 ₽
364 594 ₽
Ещё -20% по промокоду
|
От
5 881 ₽/мес
Это минимальный ежемесячный платеж за курс.
|
Длительность
13 месяцев
|
Старт
27 февраля
|
Подробнее |

Мотивация руководителя отдела продаж: полное руководство
Мотивация руководителя отдела продаж напрямую влияет на результаты команды и устойчивость бизнеса. Какие элементы должны быть в системе, как считать бонусы и почему универсальные схемы не работают? В статье — структурированные ответы и практические рекомендации.

Триггер в маркетинге: что это, как работает и зачем нужен бизнесу
Вы слышали о триггерах в маркетинге, но не уверены, как это работает? Мы покажем, как с их помощью выстроить воронку продаж — без крика «КУПИ СРОЧНО» и с уважением к уму клиента.

Микросервисы на Java: Почему крупные компании выбирают этот подход?
Узнайте, как микросервисы на Java помогут вашему бизнесу справиться с нагрузками и стать гибче, с примерами и советами.

Тестирование в Go: что это, зачем нужно и как начать
Хотите разобраться, как устроено тестирование в Go, какие инструменты используют разработчики и как повысить качество кода без лишних усилий? В статье вы найдёте понятные объяснения, практические советы и реальные примеры, которые помогут внедрить тестирование в ежедневную работу.