DevOps и SRE: что это, в чём разница и как выбрать подход
В последние годы термины DevOps и SRE (Site Reliability Engineering) стали настолько популярными в IT-индустрии, что их часто используют как взаимозаменяемые — и это создаёт немало путаницы. Работодатели ищут специалистов с этими компетенциями, конференции посвящают им целые секции, а вакансии с пометками «DevOps Engineer» и «SRE Engineer» множатся с каждым днём. Но действительно ли это одно и то же, или мы имеем дело с принципиально разными подходами к разработке и эксплуатации систем?

В этой статье мы детально разберём, что представляют собой DevOps и SRE, в чём заключаются их ключевые сходства и различия, какие метрики они используют для измерения успеха, и какие роли играют специалисты этих направлений в современных технологических компаниях. Наша цель — помочь вам понять не только теоретические основы, но и практическое применение каждого подхода, чтобы вы могли осознанно выбрать направление для своей карьеры или определить оптимальную стратегию для своей организации.
- Что такое DevOps: подход, культура, цели
- Что такое SRE: инженерный подход к надёжности
- Общие черты DevOps и SRE: что их объединяет
- Главное отличие DevOps и SRE: сравнение подходов
- Подход к инцидентам: DevOps против SRE
- Организационные различия: как DevOps и SRE существуют в компании
- Профессии DevOps и SRE: навыки, карьерный путь, зарплаты
- Полная таблица сравнения DevOps и SRE (расширенная)
- Заключение
- Рекомендуем посмотреть курсы по обучению DevOps
Что такое DevOps: подход, культура, цели
Начнём с того, что девопс — это не просто набор инструментов или должность в штатном расписании. В первую очередь, это философия организационной культуры разработки программного обеспечения, которая фундаментально меняет подход к созданию и поддержке продуктов. Если попытаться сформулировать суть максимально просто, DevOps — это методология, основанная на принципах гибкости, автоматизации и, что особенно важно, совместной работы команд, которые традиционно существовали изолированно друг от друга.
Исторически девопс вырос из методологий Lean и Agile, переняв их философию итеративной разработки и непрерывного совершенствования. Однако DevOps идёт дальше: его главная миссия — разрушить те самые «стены», которые десятилетиями разделяли отделы разработки (Development) и эксплуатации (Operations). Разработчики писали код, «перебрасывали его через забор» операционной команде, и дальше начиналось взаимное перекладывание ответственности, когда что-то неизбежно ломалось в продакшене. Знакомая картина, не правда ли?
Основные принципы
DevOps строится на нескольких фундаментальных принципах, которые определяют его практическое применение:
- Коллаборация — пожалуй, краеугольный камень всей методологии. Речь идёт не просто о вежливом общении между командами, а о совместной ответственности за продукт на всех этапах его жизненного цикла.
- Автоматизация — всего, что можно автоматизировать. От сборки и тестирования до развёртывания и мониторинга. Автоматизация не только экономит время, но и критически важна для устранения человеческого фактора — ведь всё, что делается вручную, неизбежно подвержено ошибкам.
- Непрерывность — continuous everything, как любят говорить на Западе. Непрерывная интеграция, доставка, мониторинг. Суть в том, чтобы превратить разработку из серии дискретных событий в плавный, постоянный поток улучшений.
- Измеримость — невозможно улучшить то, что не измеряешь. DevOps требует постоянного сбора метрик и обратной связи для принятия обоснованных решений о дальнейшем развитии продукта.
7C цикла DevOps
На практике девопс реализуется через так называемый цикл 7C — семь последовательных (и одновременно непрерывных) этапов, через которые проходит разработка:
- Continuous Development (непрерывная разработка) — планирование и кодирование новой функциональности.
- Continuous Integration (непрерывная интеграция) — регулярное объединение изменений от разных разработчиков.
- Continuous Testing (непрерывное тестирование) — автоматизированная проверка кода на каждом этапе.
- Continuous Feedback (непрерывная обратная связь) — сбор данных о работе приложения и пользовательском опыте.
- Continuous Monitoring (непрерывный мониторинг) — отслеживание производительности и доступности в реальном времени.
- Continuous Deployment (непрерывное развёртывание) — автоматическая доставка изменений в продакшен.
- Continuous Operations (непрерывная работа) — обеспечение бесперебойного функционирования системы.
Важно понимать, что это не линейный процесс с чётким началом и концом, а скорее замкнутый цикл, где каждый этап плавно перетекает в следующий, создавая эффект непрерывного совершенствования продукта.
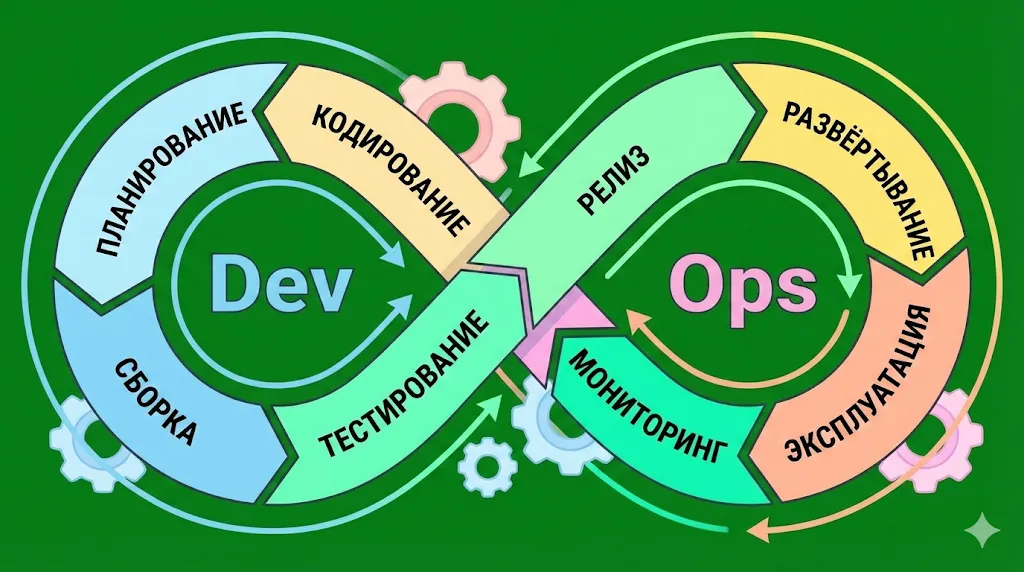
Иллюстрация демонстрирует непрерывный цикл DevOps, где каждый этап плавно перетекает в следующий, создавая постоянный поток улучшений продукта.
Цели DevOps
Что же в конечном итоге пытается достичь девопс? Если отбросить красивые формулировки, цели вполне прагматичны и измеримы. Во-первых, это увеличение скорости релизов — способность быстро доставлять новые функции и исправления пользователям. Компании, успешно внедрившие DevOps, могут выпускать обновления не раз в квартал, а десятки или даже сотни раз в день.
Во-вторых, сокращение time-to-market — времени от идеи до её реализации в продакшене. В современном мире конкурентных преимуществ скорость реакции на рыночные изменения часто важнее совершенства исполнения.
И наконец, устранение разрыва между разработкой и эксплуатацией — создание единой команды с общими целями и разделяемой ответственностью за успех продукта. DevOps фокусируется на создании ядра продукта, работая исходя из требований клиентов и применяя гибкий подход с непрерывным процессом сборки, тестирования и развертывания. Звучит амбициозно? Безусловно. Но практика таких гигантов, как Amazon, Netflix и Google, показывает, что это работает.
Что такое SRE: инженерный подход к надёжности
Site Reliability Engineering, или сокращённо SRE, представляет собой более специализированный и, если угодно, более инженерный подход к обеспечению надёжности систем. Если девопс можно назвать философией и культурой, то SRE — это конкретная инженерная дисциплина, которая применяет принципы разработки программного обеспечения к операционным задачам. Проще говоря, концепция Site Reliability Engineering подразумевает максимальную автоматизацию операционной работы, превращая традиционные задачи системного администрирования в программные, решаемые через код.
В чём ключевое отличие от классического подхода к эксплуатации? SRE-инженеры не просто «держат систему на плаву» — они пишут код для автоматизации этого процесса. Вместо того чтобы вручную перезагружать упавший сервис в три часа ночи, Site Reliability Engineering создаёт систему, которая сделает это автоматически. Вместо того чтобы реагировать на проблемы постфактум, SRE проектирует системы с учётом отказоустойчивости изначально.
История появления SRE
Любопытно, что она, в отличие от многих IT-трендов, имеет вполне конкретную точку происхождения. Методология была создана в Google в 2003 году — задолго до того, как DevOps стал массовым явлением. Столкнувшись с необходимостью обеспечить надёжность и отказоустойчивость растущей инфраструктуры, которая должна была поддерживать такие продукты, как Gmail и Google Search, компания поняла, что традиционный подход к эксплуатации просто не масштабируется.
Бен Трейнор Слосс (Ben Treynor Sloss), которого считают основателем SRE в Google, сформулировал это так: «SRE — это то, что получается, когда инженер-программист проектирует операционную функцию». Google в своей книге о Site Reliability Engineering описала, насколько совместные усилия инженеров DevOps, SRE и других специалистов жизненно важны для поддержки глобальных сервисов. С тех пор методология распространилась далеко за пределы Google, став стандартом де-факто для компаний, работающих с высоконагруженными распределёнными системами.

Скриншот главной страницы сайта sre.google. На скриншоте видны обложки книг. Это первоисточник знаний. Скриншот подтверждает авторитетность методологии, показывает, что это открытая база знаний от Google, и визуально знакомит с книгами, которые часто называют «библией» направления.
Зоны ответственности SRE-инженера
Что же конкретно делает SRE-инженер? Его роль существенно шире, чем может показаться на первый взгляд. Команды сосредоточивают своё внимание на полноценной реализации продукта и соответствии его ожиданиям пользователей по нескольким ключевым направлениям:
- Обеспечение доступности — системы должны быть доступны пользователям согласно заявленным показателям. Звучит очевидно, но на практике это означает проектирование архитектуры с учётом отказоустойчивости на каждом уровне.
- Отказоустойчивость — создание механизмов, позволяющих системе продолжать работу даже при частичных сбоях. Это включает резервирование критичных компонентов, graceful degradation и автоматическое восстановление.
- Управление инцидентами — не просто реагирование на проблемы, а создание системы их предотвращения, обнаружения и разрешения. Site Reliability Engineering команды проводят анализ каждого инцидента, чтобы увидеть его первопричину и найти способы автоматизации повторяющихся операций.
- Автоматизация операционных задач — преобразование ручных процессов в программный код. Цель — свести к минимуму так называемый toil (рутинную операционную работу) и высвободить время для улучшения системы.
Метрики SRE: SLA, SLO, SLI
Одна из отличительных особенностей SRE — чёткая система измерения надёжности через три взаимосвязанных концепции. Давайте разберёмся, что они означают на практике:
- SLA (Service Level Agreement) — соглашение об уровне обслуживания. Это формальный договор с пользователями (внутренними или внешними) о том, какую надёжность и производительность гарантирует сервис. Например: «API будет доступен 99.9% времени». SLA — это обещание, за нарушение которого часто предусмотрены штрафные санкции.
- SLO (Service Level Objective) — цели уровня обслуживания. Это внутренние целевые показатели, которые команда Site Reliability Engineering устанавливает для себя, чтобы гарантированно выполнить SLA. Если SLA обещает 99.9%, SLO может быть установлен на уровне 99.95% — с запасом на непредвиденные обстоятельства.
- SLI (Service Level Indicator) — индикаторы уровня обслуживания. Это конкретные метрики, которые измеряются в реальном времени. Например: задержка ответа API (latency), процент успешных запросов (availability), пропускная способность системы (throughput), среднее время восстановления после сбоя (MTTR).
Можно представить эту связь так: SLI показывают текущее состояние системы, SLO определяют целевые значения, а SLA — обязательства перед пользователями. Например, если SLI показывает, что доступность упала до 99.8%, а SLO установлен на 99.95%, команда SRE знает, что находится в опасной близости к нарушению SLA и должна действовать.
Общие черты DevOps и SRE: что их объединяет
Несмотря на различия в акцентах и подходах, девопс и SRE имеют гораздо больше общего, чем может показаться на первый взгляд. Можно сказать, что обе методологии родились из одной и той же боли — необходимости преодолеть организационные барьеры, которые десятилетиями мешали эффективной разработке и эксплуатации программных систем.
В первую очередь, обе дисциплины направлены на устранение разрыва между разработкой и эксплуатацией. Это не просто декларация о намерениях — речь идёт о фундаментальном изменении подхода к разделению ответственности. И DevOps, и SRE отвергают классическую модель, где разработчики «перебрасывают код через стену» операционной команде. Вместо этого обе методологии продвигают концепцию shared ownership — разделяемой ответственности, когда все участники процесса несут ее за конечный результат.
Вторая общая черта — фанатичная приверженность автоматизации. Обе дисциплины исходят из принципа, что любая повторяющаяся задача должна быть автоматизирована. Это не просто вопрос эффективности — она критически важна для устранения человеческого фактора и обеспечения консистентности. Когда речь идёт об автоматизации в девопс, это означает прежде всего автоматизацию развёртывания задач и новых функций. В Site Reliability Engineering она направлена на поддержание резервов мощности и преобразование ручных операционных задач в программные, чтобы обеспечивать работоспособность технологических стеков.
Наконец, обе методологии полагаются на одни и те же фундаментальные практики: continuous integration и continuous delivery (CI/CD), инфраструктура как код (Infrastructure as Code, IaC), комплексный мониторинг и логирование. Это не случайное совпадение — эти практики образуют базовый инструментарий современной разработки и эксплуатации высоконагруженных систем.
Инструменты, которые используют обе роли
На практическом уровне сходство DevOps и SRE ещё более очевидно, если взглянуть на технологический стек. Специалисты обоих направлений работают с практически идентичным набором инструментов, хотя и могут использовать их с несколько разными акцентами.
- Контейнеризация и оркестрация. Docker для упаковки приложений, Kubernetes для управления контейнерами в продакшене. Эти технологии стали де-факто стандартом для обеспечения консистентности между окружениями и эффективного использования ресурсов.
- Infrastructure as Code. Terraform, Ansible, CloudFormation — инструменты для декларативного описания инфраструктуры. Вместо ручной настройки серверов через SSH, современные команды описывают желаемое состояние инфраструктуры в коде, который можно версионировать, тестировать и воспроизводить.
- Мониторинг и наблюдаемость. Prometheus для сбора метрик, Grafana для визуализации, стек ELK (Elasticsearch, Logstash, Kibana) для централизованного логирования. Без этих инструментов невозможно понять, что происходит в распределённой системе.
- Облачные платформы. AWS, Google Cloud Platform, Azure — провайдеры, которые предоставляют управляемые сервисы для всего спектра задач от хранения данных до машинного обучения. Работа с облаками требует понимания их специфики, но избавляет от необходимости управлять физическим железом.
Это сходство в инструментарии не случайно — оно отражает общность проблем, которые решают обе дисциплины: как быстро и надёжно доставлять изменения в продакшен, как масштабировать системы, как обеспечить их наблюдаемость и отказоустойчивость.
Главное отличие DevOps и SRE: сравнение подходов
Философские различия
Теперь, когда мы разобрались с общими чертами, пришло время обратиться к ключевым различиям — и они начинаются на самом фундаментальном, философском уровне. DevOps — это прежде всего культура и набор практик, направленных на трансформацию организационных процессов. Можно сказать, что девопс отвечает на вопрос «как нам работать вместе?» и предлагает философию коллаборации, но не предписывает конкретных технических решений.
SRE, напротив, представляет собой конкретную инженерную реализацию многих принципов DevOps. Это не абстрактная культура, а чётко определённая роль с конкретными обязанностями, метриками и инструментами. Один из руководителей Google удачно сформулировал это так: «class SRE implements DevOps» — Site Reliability Engineering можно рассматривать как класс, который имплементирует интерфейс девопс в терминах объектно-ориентированного программирования.
Ещё одно философское различие касается того, на чём фокусируется каждый подход. DevOps имеет более экспериментальный характер — команды пишут код, постоянно проверяют его на наличие ошибок, добавляют новые функции, разрабатывают дизайн продукта и запускают его в производство. DevOps фокусируется на создании ядра проекта — того, ради чего вообще затевается разработка.
SRE же носит скорее исследовательский характер. Команды SRE постоянно отслеживают соответствующие показатели, анализируют паттерны отказов, ищут узкие места в системе. Их больше волнует не скорость добавления новых функций, а опыт конечного пользователя и надёжность того, что уже работает. Они проводят глубокий анализ каждой проблемы, чтобы понять её первопричину и предотвратить повторение в будущем.
Как каждая роль измеряет успех
Различия в философии прямо отражаются в том, как каждая дисциплина измеряет свой успех. Давайте структурируем это в виде сравнительной таблицы:
| Показатель | DevOps | SRE |
|---|---|---|
| Фокус | Скорость доставки | Надёжность системы |
| Метрики | Deployment Frequency, Lead Time, MTTR | SLO/SLA/SLI, Error Budget |
| Подход | Автоматизация поставки | Автоматизация эксплуатации |
| Приоритет | Быстрые релизы | Стабильность продакшена |
Эта таблица показывает фундаментальное различие в приоритетах. DevOps задаётся вопросом: «Как быстро мы можем доставить новую функциональность?» SRE спрашивает: «Насколько надёжна наша система, и можем ли мы позволить себе ещё один релиз?»
Различия в обязанностях DevOps и SRE инженера
На практическом уровне различия проявляются в повседневных задачах специалистов:
DevOps-инженер сосредоточен на:
- Разработке и оптимизации CI/CD пайплайнов для ускорения релизов.
- Автоматизации процессов сборки, тестирования и развёртывания.
- Настройке инфраструктуры через IaC (Infrastructure as Code).
- Интеграции различных инструментов в единую экосистему разработки.
- Оптимизации процессов взаимодействия между командами разработки и эксплуатации.
SRE-инженер концентрируется на:
- Определении и мониторинге SLO/SLI для критичных сервисов.
- Управлении error budget и принятии решений о возможности новых релизов.
- Настройке систем алертинга с фокусом на действительно критичные проблемы.
- Проведении постмортемов (post-mortem анализа инцидентов) без поиска виновных.
- Проактивном проектировании отказоустойчивости на архитектурном уровне.
- Автоматизации реагирования на типовые инциденты.
Обратите внимание: девопс отслеживает показатели производительности и даёт обратную связь команде в случае необходимости внедрения изменений, в то время как SRE использует собранные метрики для принятия конкретных решений о допустимости рисков.
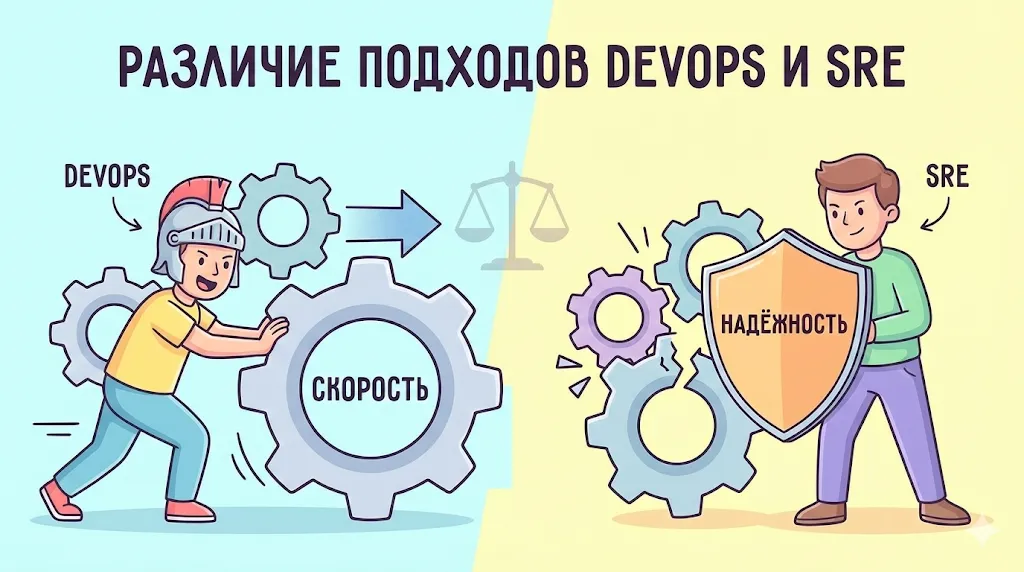
В то время как DevOps фокусируется на скорости доставки изменений, SRE ставит во главу угла защиту и обеспечение надежности системы.
Error Budget — ключевой инструмент SRE
Одна из самых элегантных концепций Site Reliability Engineering— это error budget (бюджет ошибок), инструмент, которого нет в классическом DevOps. Что это такое и почему это важно?
Представьте, что ваш SLO определяет доступность сервиса на уровне 99.9%. Это означает, что в течение месяца (примерно 730 часов) система может быть недоступна не более 43.8 минут. Эти 43.8 минуты и есть ваш error budget — разрешённое время простоя.
Вот как это выполняется на практике: если система работает слишком надёжно и error budget не расходуется, команда может позволить себе более агрессивные релизы, эксперименты, рефакторинг. Если же budget исчерпывается быстро, это сигнал замедлиться и сфокусироваться на стабильности. Появляется замораживание новых функций до тех пор, пока надёжность не будет восстановлена.
Эта концепция решает вечный конфликт между скоростью разработки и стабильностью системы, переводя его из плоскости субъективных оценок в область измеримых показателей. Error budget превращает надёжность из абстрактной ценности в конкретный ресурс, которым можно управлять.
Подход к инцидентам: DevOps против SRE
Одна из областей, где различия между DevOps и SRE проявляются особенно отчётливо — это подход к инцидентам и сбоям. Обе дисциплины признают неизбежность проблем в сложных распределённых системах, но философия работы с этими проблемами у них существенно отличается.
Как DevOps предотвращает сбои
Девопс подходит к предотвращению сбоев через призму ускорения процессов и оптимизации потока работы. Основная идея заключается в том, что чем быстрее мы можем доставлять изменения, тем быстрее можем исправлять проблемы. Парадоксально, но частые небольшие релизы оказываются безопаснее редких крупных обновлений — проще найти причину проблемы в небольшом изменении, чем в массивном релизе с сотнями модификаций.
Ключевые механизмы предотвращения сбоев в DevOps включают автоматизированное тестирование на всех этапах пайплайна. Юнит-тесты отлавливают ошибки на уровне отдельных компонентов, интеграционные тесты проверяют взаимодействие модулей, а end-to-end тесты симулируют реальное поведение пользователей. Чем раньше в процессе обнаруживается проблема, тем дешевле её исправить.
Также девопс активно использует практики вроде feature flags (флагов функциональности), позволяющих включать и выключать новые возможности без повторного развёртывания, и canary deployments (канареечных развёртываний), когда изменения сначала раскатываются на небольшую часть пользователей для проверки.
Как SRE управляет сбоями
Методология, в свою очередь, рассматривает сбои не как нечто, чего нужно избежать любой ценой, а как предсказуемый и измеримый аспект работы системы. Помните концепцию error budget? Она исходит из признания, что стопроцентная надёжность не только недостижима, но и экономически нецелесообразна. Важно не устранить все сбои, а управлять их частотой и влиянием в рамках установленных границ.
Политика алертов в SRE выстраивается особенно тщательно. Здесь действует принцип: алерт должен требовать немедленных действий человека. Если на оповещение можно не реагировать сразу — это не алерт, а информация для дашборда. Это критически важно для предотвращения «усталости от алертов», когда операторы начинают игнорировать шум бесконечных уведомлений и пропускают действительно важные проблемы.
Когда инцидент всё же происходит, Site Reliability Engineering использует управление бюджетом ошибок для принятия решений. Если error budget исчерпан, это автоматически триггерит замедление релизов и фокус на улучшении надёжности. Решение о приостановке новых функций принимается не на эмоциях («опять всё сломалось!»), а на основе объективных метрик.
Особое место в практике SRE занимают постмортемы без обвинений (blameless post-mortems). После каждого значимого инцидента команда проводит детальный разбор, но цель — не найти виновного, а выявить системные проблемы, которые позволили инциденту произойти. Документ постмортема обычно включает хронологию событий, первопричину (root cause), воздействие на пользователей и, самое важное, конкретные action items для предотвращения повторения. Культура обучения на ошибках, а не наказания за них — один из столпов SRE.
Организационные различия: как DevOps и SRE существуют в компании
Помимо философских и технических различий, DevOps и Site Reliability Engineering по-разному встраиваются в организационную структуру компаний — и эти различия могут существенно влиять на эффективность их применения.
Место DevOps в компании
DevOps в организационном смысле — это скорее распределённая функция, чем отдельная команда. Да, у вас может быть должность «DevOps-инженер», но суть методологии заключается именно во внедрении культуры совместной работы во всей организации. В идеальном мире девопс инженеры работают встроенными в продуктовые команды, помогая разработчикам, тестировщикам и всем остальным участникам процесса создавать и поддерживать эффективные пайплайны доставки.
На практике это может выглядеть по-разному: где-то создают централизованную Platform Team, которая предоставляет инструменты и практики для всех продуктовых команд; где-то DevOps-инженеры распределены по feature teams; где-то используют матричную структуру. Важно понимать, что девопс не работает как изолированное подразделение — его задача именно в том, чтобы разрушить изоляцию и создать единый поток ценности от идеи до продакшена.
Место SRE
Site Reliability Engineering, напротив, чаще существует как отдельная, чётко выделенная команда со своими специфическими обязанностями. Это не случайно — SRE требует глубокой специализации в области проектирования надёжных систем, понимания статистики, теории вероятностей и способности мыслить на уровне распределённых систем.
SRE-команды обычно работают с наиболее критичными и сложными системами на продакшене — теми, где цена сбоя измеряется не просто в неудобстве пользователей, но в серьёзных финансовых или репутационных потерях. Они активно взаимодействуют с командами разработки, предоставляя им обратную связь о надёжности их сервисов, с операционными командами, совершенствуя инфраструктуру, и с QA, внедряя практики chaos engineering и resilience testing.
Интересно, что в крупных компаниях, таких как Google, SRE-команды имеют право отказаться от поддержки сервиса, если команда разработки не выполняет требования по надёжности — своеобразная встроенная система контроля качества на организационном уровне.
Профессии DevOps и SRE: навыки, карьерный путь, зарплаты
Разобравшись с концептуальными различиями, давайте обратимся к практическому вопросу, который волнует многих: какие конкретные навыки требуются для каждой из этих ролей, и как выбрать между ними, если вы планируете карьеру в этой области?
Навыки DevOps-инженера
DevOps-инженер — это, по сути, мультиинструменталист современной разработки. Набор требуемых компетенций широк и продолжает расширяться, но есть несколько базовых областей, без которых не обойтись.
- CI/CD системы — это хлеб девопс-инженера. GitLab CI/CD, Jenkins, GitHub Actions, CircleCI — умение выстраивать и оптимизировать пайплайны непрерывной интеграции и доставки критически важно. Речь не просто о том, чтобы запустить готовую конфигурацию, а о способности спроектировать эффективный workflow от коммита до продакшена.
- Контейнеризация и оркестрация — Docker уже стал базовым навыком, без которого в современной разработке делать нечего. Kubernetes же превратился из модного фреймворка в индустриальный стандарт, хотя и сохраняет репутацию технологии с крутой кривой обучения.
- Infrastructure as Code — Terraform для управления облачной инфраструктурой, Ansible для конфигурационного менеджмента. Способность описать всю инфраструктуру в коде, который можно версионировать и воспроизводить, отличает современного DevOps-инженера от системного администратора старой школы.
- Scripting и автоматизация — Bash для быстрых скриптов, Python для более сложной логики. Умение автоматизировать рутинные задачи — это не просто полезный навык, это философия DevOps в действии.
- Мониторинг и логирование — Prometheus, Grafana, ELK stack. Невозможно улучшить то, что не измеряешь, — и девопс-инженеру нужно понимать, как собирать, хранить и визуализировать метрики и логи.

Пример задач и навыков для девопс-инженера из реальной вакансии.
Навыки SRE-инженера
SRE-инженер должен обладать многими из перечисленных выше навыков, но с более глубоким погружением в определённые области и дополнительными специфическими компетенциями.
- Глубокое понимание SLO/SLI/SLA — способность не просто настроить мониторинг, а спроектировать систему измерения надёжности с нуля. Какие метрики действительно важны для бизнеса? Как установить реалистичные SLO? Как сбалансировать надёжность и скорость разработки через error budget?
- Продвинутый алертинг — искусство настройки оповещений, которые действительно требуют внимания. SRE должен уметь отличить сигнал от шума и спроектировать систему алертов, которая не приведёт к выгоранию дежурной команды.
- Культура постмортемов — способность проводить глубокий анализ инцидентов, выявлять первопричины (root cause analysis) и формулировать действенные рекомендации. Это требует не только технических навыков, но и определённой психологической подготовки для создания атмосферы обучения без обвинений.
- Проектирование отказоустойчивости — понимание паттернов надёжности на архитектурном уровне: circuit breakers, bulkheads, graceful degradation, retry logic. SRE должен мыслить категориями распределённых систем и понимать, как отказ одного компонента влияет на систему в целом.
- Системное мышление — пожалуй, самая сложная для формализации компетенция. Способность видеть систему целиком, понимать взаимосвязи и прогнозировать последствия изменений.

Пример задач и навыков для SRE-инженера из реальной вакансии.
Как выбрать — DevOps или SRE?
Итак, перед нами два привлекательных направления. Как же выбрать? Наш опыт показывает, что решение стоит принимать, исходя из нескольких факторов.
Если вас больше привлекает скорость, эксперименты и создание нового, если вы любите оптимизировать процессы и видеть, как ваши улучшения позволяют командам работать быстрее — девопс может быть вашим путём. Эта роль больше про движение вперёд, про непрерывное улучшение workflow, про то, чтобы сделать релизы частыми и безболезненными.
Если же вас увлекает надёжность, глубокий анализ и предотвращение проблем, если вам нравится разбираться в причинах сбоев и проектировать системы, которые продолжают работать даже когда что-то идёт не так — SRE может оказаться ближе. Эта роль требует терпения, аналитического склада ума и готовности погружаться в технические детали на уровне, который может показаться избыточным тем, кто сфокусирован на скорости доставки.
Стоит также учитывать стадию вашей карьеры. DevOps часто является более доступной точкой входа — навыки можно развивать постепенно, работая с CI/CD и со временем расширяя зону компетенции. SRE обычно требует более глубокого технического бэкграунда и часто рассматривается как естественная эволюция для опытных DevOps-инженеров или системных программистов.
Полная таблица сравнения DevOps и SRE (расширенная)
После детального разбора различных аспектов DevOps и SRE, давайте систематизируем всё в единой таблице, которая позволит увидеть полную картину различий и сходств этих подходов. Эта таблица может служить своеобразной «шпаргалкой» для понимания ключевых отличий на практическом уровне.
| Критерий | DevOps | SRE |
|---|---|---|
| Основная цель | Ускорение цикла разработки и доставки | Обеспечение надёжности и доступности систем |
| Точка фокуса | Процесс разработки и релизный цикл | Эксплуатация и производственная среда |
| Метрики успеха | Deployment Frequency, Lead Time for Changes, MTTR | SLO/SLA/SLI, Error Budget, MTBF, доступность |
| Ключевые инструменты | CI/CD платформы, пайплайны автоматизации | Системы мониторинга, алертинга, управления инцидентами |
| Организация команды | Культура, часто распределённая функция | Отдельная специализированная команда |
| Отношение к ошибкам | Исправляют быстро через частые релизы | Управляют заранее через error budget и проактивное проектирование |
| Автоматизация | Фокус на автоматизации развёртывания | Фокус на автоматизации операционных задач |
| Приоритет | Скорость и гибкость | Стабильность и предсказуемость |
| Взаимодействие | Объединяет Dev и Ops | Работает на стыке Dev, Ops и пользователей |
| Измерение производительности | Частота и успешность деплоев | Соблюдение SLO и расход error budget |
Эта таблица наглядно демонстрирует, что девопс и SRE не являются взаимоисключающими подходами — скорее, они решают разные, но дополняющие друг друга задачи в жизненном цикле программного обеспечения. DevOps отвечает на вопрос «как быстро доставлять изменения», в то время как SRE задаётся вопросом «как сохранить надёжность при этих изменениях».
Важно понимать, что в реальных организациях граница между этими ролями часто размыта. В небольших компаниях один специалист может совмещать обязанности обоих направлений, в то время как крупные технологические гиганты вроде Google имеют чётко разделённые команды с детально проработанными зонами ответственности. Выбор конкретной модели зависит от масштаба системы, зрелости организации и бизнес-приоритетов.
Заключение
Пройдя путь от определений до практических различий, мы можем теперь с уверенностью сказать: противопоставление DevOps и SRE — это ложная дихотомия. Эти подходы не конкурируют друг с другом, а скорее представляют собой две стороны одной медали современной разработки программного обеспечения. Подведем итоги:
- DevOps — это культура и набор практик. Он помогает ускорить разработку и наладить совместную работу команд.
- SRE — это инженерная дисциплина. Она фокусируется на надежности, отказоустойчивости и измеримых показателях работы системы.
- DevOps ориентирован на скорость релизов. SRE делает приоритетом стабильность и соблюдение SLO.
- Обе роли используют схожие инструменты. Различия проявляются в целях, метриках и подходе к инцидентам.
- Выбор между направлениями зависит от интересов специалиста. Одним ближе автоматизация процессов, другим — аналитика надежности.
Если вы только начинаете осваивать профессию sre-инженера или devops-специалиста, рекомендуем обратить внимание на курсы DevOps-инженера. В них есть теоретическая и практическая часть, которые помогают разобраться в инструментах, метриках и реальных рабочих задачах.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
114 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 мая
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
DevOps-инженер
|
Нетология
46 отзывов
|
Цена
101 800 ₽
226 321 ₽
с промокодом kursy-online
|
От
3 143 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 апреля
|
Подробнее |
|
Профессия DevOps-инженер
|
Skillbox
232 отзыва
|
Цена
161 751 ₽
323 502 ₽
Ещё -20% по промокоду
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
23 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
102 отзыва
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Профессия DevOps-инженер PRO
|
Skillbox
232 отзыва
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
6 месяцев
|
Старт
23 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.