Функция filter() в Python: как работает, зачем нужна и примеры использования

В процессе работы с данными мы постоянно сталкиваемся с необходимостью отбирать элементы по определённым критериям — будь то список пользователей с конкретным статусом, массив чисел, превышающих пороговое значение, или строки, соответствующие заданному паттерну. Именно для таких задач в Python существует встроенная функция filter(), которая элегантно решает проблему фильтрации данных.
Суть работы функции проста и логична: она последовательно проходит по каждому элементу коллекции, применяет к нему заданное условие и оставляет только те элементы, которые этому условию соответствуют. Можно представить это как своеобразное сито, которое пропускает только нужные данные, отсеивая всё остальное.
Формула работы выглядит следующим образом: коллекция → проверка условия → отфильтрованный результат. При этом исходная коллекция остаётся неизменной — filter() не модифицирует данные, а создаёт новую последовательность на основе результатов проверки.
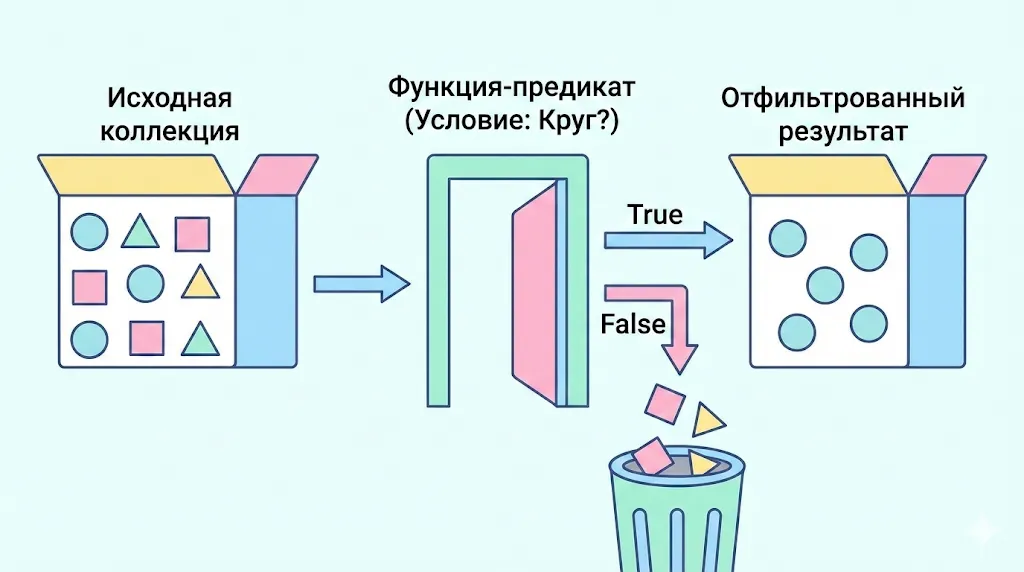
Эта схема наглядно демонстрирует процесс фильтрации как конвейер: элементы из исходной коллекции проходят через «ворота» с условием. Те, что соответствуют условию (True), попадают в результат, остальные отбрасываются.
Она относится к функциональному подходу программирования и особенно полезна в ситуациях, когда необходимо быстро обработать большой объём данных без написания циклов. Это делает код более компактным и читаемым, особенно когда критерии фильтрации относительно просты.
- Синтаксис и параметры функции
- Что возвращает filter(): разница между Python 2 и Python 3
- Как преобразовать результат filter() в список, кортеж, строку
- Использование с обычной функцией
- Использование с lambda: компактная и мощная фильтрация
- Фильтрация различных коллекций: список, кортеж, строка, словарь
- Использование filter() с None — фильтрация по истинности
- Продвинутые примеры использования
- Комбинирование filter() с другими функциями Python
- Ограничения и недостатки
- Где и когда стоит использовать функцию в реальных задачах
- Заключение
- Рекомендуем посмотреть курсы по Python
Синтаксис и параметры функции
Понимание синтаксиса — ключ к эффективному использованию этой функции. Базовая сигнатура выглядит предельно просто: filter(function, iterable). Однако за этой простотой скрывается гибкость, которая позволяет решать широкий спектр задач фильтрации данных.
Рассмотрим каждый из параметров подробнее, чтобы понять, как они взаимодействуют и какие возможности предоставляют.
function — функция-предикат
Первый параметр представляет собой функцию-предикат — то есть функцию, которая принимает один аргумент (элемент коллекции) и возвращает булево значение: True или False. Именно на основе этого значения она принимает решение — включать элемент в результат или отбросить его.
Важно понимать: функция-предикат должна возвращать именно булево значение или объект, который Python может интерпретировать как истину или ложь. Если функция возвращает True, элемент попадает в отфильтрованную последовательность; если False — отбрасывается.
В качестве функции-предиката можно использовать:
- Именованные функции — определённые через def.
- Lambda-функции — анонимные функции для простых условий.
- Встроенные функции Python — например, str.isdigit для проверки, является ли строка числом.
- None — специальный случай, который мы рассмотрим отдельно.
Интересная особенность: можно передавать встроенные функции напрямую, без вызова. Например, filter(str.isupper, [‘A’, ‘b’, ‘C’]) отфильтрует только заглавные буквы. Это работает потому, что мы передаём ссылку на функцию, а не результат её выполнения.
iterable — какие объекты можно передавать
Второй параметр — это любой итерируемый объект, то есть объект, по элементам которого можно пройти в цикле. Python предоставляет широкий набор таких структур данных:
- Списки (list) — изменяемые упорядоченные коллекции.
- Кортежи (tuple) — неизменяемые упорядоченные коллекции.
- Строки (str) — последовательности символов.
- Словари (dict) — при итерации по умолчанию проходят по ключам.
- Множества (set) — неупорядоченные коллекции уникальных элементов.
- Генераторы — объекты, создающие элементы «на лету».
- Файловые объекты — при чтении построчно.
Важная деталь: функция всегда обрабатывает элементы последовательно, в том порядке, в котором они представлены в исходной коллекции. Для словарей это означает, что фильтрация будет применяться к ключам (если не указано иное), для строк — к отдельным символам.
Следует отметить, что filter() не изменяет исходный объект — это чистая функция в терминах функционального программирования. Она создаёт новую последовательность на основе результатов проверки, оставляя оригинал нетронутым. Это особенно важно при работе с данными, которые могут использоваться в других частях программы.
Что возвращает filter(): разница между Python 2 и Python 3
Одна из особенностей, которая часто вызывает недоумение у разработчиков, переходящих на Python 3, — это изменение поведения функции filter(). Понимание того, что именно возвращает эта функция, критически важно для эффективной работы с ней.
В Python 3 эта функция возвращает не список, как это было в Python 2, а специальный объект — filter object (объект-фильтр). Это итератор, который генерирует отфильтрованные элементы «лениво» — то есть по мере необходимости, а не все сразу. Если вывести результат напрямую, мы увидим нечто вроде <filter object at 0x7f8b8c0a3d00>, что не особенно информативно.
Ленивость итератора означает, что фильтрация не происходит в момент вызова filter(). Вместо этого создаётся объект, который будет выполнять фильтрацию только тогда, когда мы начнём запрашивать элементы — например, при преобразовании в список или при итерации в цикле. Это архитектурное решение имеет важные последствия для производительности и использования памяти.
Рассмотрим практическую разницу. В Python 2 код filter(lambda x: x > 5, [1, 6, 3, 8]) немедленно создавал список [6, 8] в памяти. В Python 3 тот же код создаёт объект-итератор, который хранит лишь ссылку на исходную последовательность и функцию-предикат, но не сами результаты.
Это различие становится особенно значимым при работе с большими объёмами данных. Представим, что мы фильтруем миллион элементов, а затем используем только первые десять результатов. В Python 2 все миллион элементов были бы обработаны и сохранены в памяти. В Python 3 обработаются только те элементы, которые действительно понадобятся.

Иллюстрация показывает колоссальную разницу в использовании памяти при фильтрации большого массива. В Python 2 создается полный список, занимающий много памяти, тогда как в Python 3 создается «ленивый» итератор, потребление памяти которым минимально.
Сравнение Python 2 и Python 3:
| Аспект | Python 2 | Python 3 |
|---|---|---|
| Тип результата | list | filter object (итератор) |
| Момент вычисления | Немедленно | Лениво (при запросе) |
| Использование памяти | Вся коллекция в памяти | Только текущий элемент |
| Повторное использование | Возможно | Итератор исчерпывается после одного прохода |
Важное следствие ленивости: объект-фильтр можно использовать только один раз. После того как мы пройдём по всем его элементам, он «исчерпается» и дальнейшие попытки итерации не дадут результатов. Если необходимо многократно обращаться к отфильтрованным данным, следует явно преобразовать результат в список или другую коллекцию.
Как преобразовать результат filter() в список, кортеж, строку
Как мы уже выяснили, функция в Python 3 возвращает итератор, что не всегда удобно для дальнейшей работы. К счастью, преобразование результата в привычные структуры данных выполняется простыми встроенными функциями. Рассмотрим основные варианты преобразования, которые пригодятся в повседневной практике.
Примеры преобразования результата
В список. Наиболее распространённый сценарий — преобразование в список с помощью функции list(). Это создаёт изменяемую коллекцию, с которой можно выполнять любые операции: добавлять элементы, удалять, сортировать.
numbers = [1, 2, 3, 4, 5, 6] even = list(filter(lambda x: x % 2 == 0, numbers)) # Результат: [2, 4, 6]
В кортеж. Если требуется неизменяемая последовательность — например, для использования в качестве ключа словаря или элемента множества — используем tuple(). Кортежи занимают меньше памяти и обрабатываются быстрее списков.
words = ['apple', 'banana', 'avocado', 'cherry']
a_words = tuple(filter(lambda w: w.startswith('a'), words))
# Результат: ('apple', 'avocado')
В множество. Преобразование в множество через set() автоматически удаляет дубликаты и создаёт неупорядоченную коллекцию уникальных элементов. Это полезно, когда важна только уникальность отфильтрованных значений.
numbers = [1, 2, 2, 3, 4, 4, 5]
unique_even = set(filter(lambda x: x % 2 == 0, numbers))
# Результат: {2, 4}
В строку. Для объединения отфильтрованных символов или строк в единую строку используется метод join(). Это особенно актуально при работе с текстовыми данными — например, при удалении определённых символов из строки.
text = "Hello, World! 123" letters_only = ''.join(filter(str.isalpha, text)) # Результат: 'HelloWorld'
Обратите внимание: при работе со строками join() требует, чтобы все элементы были строками. Если фильтруем не символы, а слова, разделитель можно указать явно: ‘ ‘.join(filter(…)) для объединения через пробел.
Выбор типа преобразования зависит от конкретной задачи: списки — для изменяемых данных, кортежи — для неизменяемых последовательностей, множества — для уникальных значений, строки — для текстовой обработки.
Использование с обычной функцией
Базовый и наиболее наглядный способ использования filter() — передача именованной функции в качестве предиката. Этот подход особенно оправдан, когда логика фильтрации достаточно сложна или используется в нескольких местах программы. Определение отдельной функции делает код более читаемым и упрощает его тестирование.
Основное преимущество именованных функций перед анонимными lambda — возможность включать сложную логику, состоящую из нескольких операций, и давать функции понятное, семантически значимое имя, которое объясняет её назначение.
Пример фильтрации списка чисел
Рассмотрим классический пример — отбор чисел по определённому критерию. Предположим, нам нужно выбрать все положительные числа, кратные трём:
def is_positive_multiple_of_three(num): return num > 0 and num % 3 == 0 numbers = [-9, -3, 0, 3, 5, 6, 9, 12, 15, 17] result = list(filter(is_positive_multiple_of_three, numbers)) # Результат: [3, 6, 9, 12, 15]
Преимущество такого подхода очевидно: название функции is_positive_multiple_of_three сразу объясняет, что именно мы фильтруем, без необходимости анализировать логику условия. Если позже потребуется изменить критерий отбора, достаточно модифицировать одну функцию.
Более сложный пример — фильтрация чисел по составному критерию. Допустим, нам нужны числа из определённого диапазона, которые являются простыми:
def is_prime_in_range(num): if num < 10 or num > 100: return False if num < 2: return False for i in range(2, int(num ** 0.5) + 1): if num % i == 0: return False return True numbers = [5, 11, 23, 47, 50, 67, 89, 105, 150] primes = list(filter(is_prime_in_range, numbers)) # Результат: [11, 23, 47, 67, 89]
Пример фильтрации строк
При работе с текстовыми данными именованные функции также демонстрируют свою полезность. Представим задачу: отобрать из списка только те строки, которые представляют собой валидные email-адреса (упрощённая проверка):
def is_valid_email(email):
return '@' in email and '.' in email.split('@')[-1] and len(email) > 5
contacts = ['user@example.com', 'invalid', 'test@domain.co', 'bad@', '@test.com']
valid_emails = list(filter(is_valid_email, contacts))
# Результат: ['user@example.com', 'test@domain.co']
Другой распространённый сценарий — фильтрация строк по длине и содержимому. Например, выбор только тех строк, которые содержат цифры и имеют минимальную длину:
def has_digits_and_min_length(text): return len(text) >= 5 and any(char.isdigit() for char in text) data = ['abc', 'test123', 'hi', 'data2023', '12', 'python3.11'] filtered = list(filter(has_digits_and_min_length, data)) # Результат: ['test123', 'data2023', 'python3.11']
Стоит отметить: при использовании именованных функций важно следить за тем, чтобы они не имели побочных эффектов и зависели только от входных параметров. Это делает код предсказуемым и облегчает отладку. В функциональном программировании они называются «чистыми», и именно они идеально подходят для использования с filter().
Использование с lambda: компактная и мощная фильтрация
Lambda-функции — это анонимные функции, которые определяются непосредственно в месте использования и состоят из одного выражения. В сочетании с filter() они образуют мощный инструмент для компактной записи операций фильтрации. Давайте разберёмся, когда lambda действительно улучшает код, а когда лучше обойтись без неё.
Простая фильтрация с lambda
Основное преимущество lambda — возможность описать простое условие фильтрации в одной строке, без необходимости создавать отдельную именованную функцию. Это особенно удобно для одноразовых операций:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] even_numbers = list(filter(lambda x: x % 2 == 0, numbers)) # Результат: [2, 4, 6, 8, 10] words = ['apple', 'banana', 'kiwi', 'strawberry', 'plum'] short_words = list(filter(lambda w: len(w) <= 5, words)) # Результат: ['apple', 'kiwi', 'plum']
Синтаксис lambda предельно прост: lambda аргумент: выражение. Выражение автоматически возвращается как результат, поэтому ключевое слово return не используется.
Сложные условия в одной строке
Lambda-функции поддерживают логические операторы, что позволяет комбинировать несколько условий:
numbers = range(-10, 11)
filtered = list(filter(lambda x: x > 0 and x % 3 == 0, numbers))
# Результат: [3, 6, 9]
products = [
{'name': 'Laptop', 'price': 1200, 'stock': 5},
{'name': 'Mouse', 'price': 25, 'stock': 0},
{'name': 'Keyboard', 'price': 80, 'stock': 12}
]
available_affordable = list(filter(
lambda p: p['price'] < 100 and p['stock'] > 0,
products
))
# Результат: [{'name': 'Keyboard', 'price': 80, 'stock': 12}]
Можно использовать тернарные операторы, вызовы методов и даже доступ к элементам вложенных структур. Однако здесь кроется и опасность: слишком сложная lambda становится нечитаемой.
Сравнение filter + lambda vs list comprehension
Возникает закономерный вопрос: когда использовать filter() с lambda, а когда — генераторы списков (list comprehension)? Оба подхода решают одну задачу, но имеют разные области применения.
# Вариант с filter() и lambda numbers = range(20) evens_filter = list(filter(lambda x: x % 2 == 0, numbers)) # Вариант с list comprehension evens_comp = [x for x in numbers if x % 2 == 0]
Когда лучше использовать lambda с filter():
- Когда у вас уже есть готовая функция-предикат (встроенная или определённая ранее).
- Когда фильтрация — часть цепочки функциональных операций (filter → map → reduce).
- Когда критерий фильтрации выражается одним простым условием.
- Когда важна семантика: «отфильтровать элементы» звучит яснее, чем «собрать элементы с условием».
Когда предпочтительнее list comprehension:
- Когда после фильтрации нужно трансформировать элементы: [x**2 for x in nums if x > 0].
- Когда условие достаточно сложное и включает несколько проверок.
- Когда важна читаемость для разработчиков, не знакомых с функциональным программированием.
- Когда нужно создать словарь или множество: {x: x**2 for x in nums if x > 0}.
Исследования показывают, что для простых операций list comprehension может работать немного быстрее, так как это встроенная языковая конструкция, оптимизированная интерпретатором. Однако разница в производительности обычно незначительна и не должна быть решающим фактором при выборе подхода.
Важное ограничение lambda: она не может содержать операторы (например, if-else как оператор, а не выражение), присваивания или множественные выражения. Если логика фильтрации требует этого, следует использовать именованную функцию.
Фильтрация различных коллекций: список, кортеж, строка, словарь
Универсальность функции проявляется в способности работать с различными типами данных Python. Однако каждая коллекция имеет свои особенности, которые следует учитывать при фильтрации. Рассмотрим, как filter() взаимодействует с основными структурами данных и какие нюансы возникают в каждом случае.
Фильтрация списка (list)
Списки — самая распространённая структура для фильтрации. Они изменяемы, упорядочены и могут содержать элементы любого типа:
prices = [15.99, 299.00, 45.50, 1200.00, 89.99, 12.00] affordable = list(filter(lambda p: p < 100, prices)) # Результат: [15.99, 45.50, 89.99, 12.00] mixed_data = [1, 'text', None, 42, '', 0, 'hello'] non_empty = list(filter(None, mixed_data)) # Результат: [1, 'text', 42, 'hello']
Обратите внимание: при фильтрации списков порядок элементов сохраняется. Это важно, когда последовательность имеет значение — например, при работе с временными рядами или упорядоченными данными.
Фильтрация кортежа (tuple) + пример преобразования обратно
Кортежи неизменяемы, но filter() прекрасно с ними работает. Важный момент: результат нужно явно преобразовать обратно в кортеж, если требуется сохранить тип данных:
coordinates = (10, -5, 0, 15, -3, 8, 0, 12) positive_coords = tuple(filter(lambda x: x > 0, coordinates)) # Результат: (10, 15, 8, 12) rgb_colors = ((255, 0, 0), (128, 128, 128), (0, 255, 0), (200, 200, 200)) bright_colors = tuple(filter(lambda c: sum(c) > 400, rgb_colors)) # Результат: ((255, 0, 0), (0, 255, 0), (200, 200, 200))
Кортежи часто используются для представления неизменяемых данных — координат, RGB-значений, конфигурационных параметров. Преобразование обратно в кортеж гарантирует, что тип данных остаётся консистентным во всей программе.
Фильтрация строк (str) — посимвольная фильтрация
При фильтрации строки filter() обрабатывает её как последовательность символов. Это открывает интересные возможности для обработки текста:
text = "Hello, World! 2024" only_letters = ''.join(filter(str.isalpha, text)) # Результат: 'HelloWorld' only_digits = ''.join(filter(str.isdigit, text)) # Результат: '2024' uppercase_only = ''.join(filter(str.isupper, text)) # Результат: 'HW' # Удаление гласных vowels = 'aeiouAEIOU' no_vowels = ''.join(filter(lambda c: c not in vowels, text)) # Результат: 'Hll, Wrld! 2024'
Важная деталь: для получения строки на выходе необходимо использовать ».join(), иначе результатом будет итератор символов. Посимвольная фильтрация особенно полезна при очистке входных данных, валидации или подготовке текста для дальнейшей обработки.
Фильтрация словаря (dict): выбор ключей/значений
Словари требуют особого подхода, поскольку содержат пары ключ-значение. По умолчанию итерация проходит по ключам, но можно фильтровать и по значениям, и по обоим параметрам одновременно:
# Фильтрация по ключам
scores = {'Alice': 85, 'Bob': 72, 'Charlie': 95, 'Diana': 68}
high_performers = dict(filter(lambda item: item[1] > 80, scores.items()))
# Результат: {'Alice': 85, 'Charlie': 95}
# Фильтрация по значениям с условием на ключи
config = {'debug': True, 'timeout': 30, 'max_retries': 5, 'verbose': False}
numeric_params = dict(filter(lambda item: isinstance(item[1], int), config.items()))
# Результат: {'timeout': 30, 'max_retries': 5}
# Комплексная фильтрация
products = {
'laptop': {'price': 1200, 'stock': 5},
'mouse': {'price': 25, 'stock': 0},
'keyboard': {'price': 80, 'stock': 12}
}
available = dict(filter(lambda item: item[1]['stock'] > 0, products.items()))
# Результат: {'laptop': {...}, 'keyboard': {...}}
Ключевой момент: для фильтрации словаря используем метод .items(), который возвращает пары (ключ, значение). Функция-предикат получает кортеж (key, value) и может проверять любой из этих элементов или оба сразу.
Сравнение объекта-результата до и после преобразования:
| Тип коллекции | Исходный объект | Объект filter | После преобразования |
|---|---|---|---|
| Список | [1, 2, 3, 4, 5] | <filter object> | [2, 4] (list) |
| Кортеж | (1, 2, 3, 4, 5) | <filter object> | (2, 4) (tuple) |
| Строка | «Hello123» | <filter object> | «123» (str через join) |
| Словарь | {‘a’: 1, ‘b’: 2} | <filter object> | {‘b’: 2} (dict) |
Понимание этих различий позволяет эффективно применять filter() к любым структурам данных Python, адаптируя подход под специфику каждой коллекции.
Использование filter() с None — фильтрация по истинности
Одна из наиболее элегантных возможностей функции — использование None в качестве первого аргумента. Этот специальный случай позволяет отфильтровать элементы на основе их «истинности» в понимании Python, без необходимости писать явную функцию-предикат. Разберёмся, как это работает и когда может быть полезно.
Когда в filter() передаётся None вместо функции, Python применяет встроенную проверку на истинность к каждому элементу коллекции. Элементы, которые интерпретируются как «истинные» (truthy), попадают в результат, а «ложные» (falsy) отбрасываются.
mixed = [0, 1, False, True, '', 'text', None, [], [1, 2], {}, {'key': 'value'}]
truthy_values = list(filter(None, mixed))
# Результат: [1, True, 'text', [1, 2], {'key': 'value'}]
Python определяет следующие значения как «ложные»:
- None — специальное значение отсутствия.
- False — булево ложь.
- Числовой ноль — 0, 0.0, 0j (комплексный ноль).
- Пустые коллекции — » (пустая строка), [] (пустой список), () (пустой кортеж), {} (пустой словарь), set() (пустое множество).
- Пустые объекты — объекты классов, у которых методы __bool__() или __len__() возвращают False или 0.
Все остальные значения считаются «истинными». Это поведение делает filter(None, …) чрезвычайно полезным инструментом для очистки данных.
Практические примеры использования:
# Удаление пустых строк из списка
lines = ['first line', '', 'second line', ' ', 'third line', '']
non_empty_lines = list(filter(None, [line.strip() for line in lines]))
# Результат: ['first line', 'second line', 'third line']
# Очистка данных от нулевых и пустых значений
data = [100, 0, 250, None, 0, 180, False, 320]
valid_data = list(filter(None, data))
# Результат: [100, 250, 180, 320]
# Удаление пустых словарей из списка результатов
results = [{'id': 1}, {}, {'id': 2}, None, {'id': 3}, {}]
valid_results = list(filter(None, results))
# Результат: [{'id': 1}, {'id': 2}, {'id': 3}]
Важное замечание: использование filter(None, …) требует осторожности, когда ноль или False являются валидными значениями в вашем контексте. Например, если вы работаете с температурами, где 0 градусов — это допустимое значение, filter(None, …) ошибочно отбросит его. В таких случаях следует использовать явную проверку:
temperatures = [25, 0, -5, None, 15, 0, 30] # Неправильно: удалит нули wrong = list(filter(None, temperatures)) # Результат: [25, -5, 15, 30] # Правильно: удалит только None correct = list(filter(lambda x: x is not None, temperatures)) # Результат: [25, 0, -5, 15, 0, 30]
Фильтрация по истинности особенно полезна при работе с данными, полученными из внешних источников — API, баз данных, пользовательского ввода — где могут встречаться пустые или отсутствующие значения, требующие удаления перед дальнейшей обработкой.
Продвинутые примеры использования
По мере роста сложности задач функция демонстрирует свою гибкость в нетривиальных сценариях. Рассмотрим несколько продвинутых техник, которые часто встречаются в реальных проектах — от работы с множественными коллекциями до обработки аномальных данных.
Пересечение двух списков через filter()
Задача нахождения общих элементов в двух коллекциях элегантно решается с помощью filter(). Этот подход особенно полезен, когда нужно сохранить порядок элементов из первого списка:
list1 = [1, 2, 3, 4, 5, 6, 7] list2 = [4, 5, 6, 7, 8, 9, 10] intersection = list(filter(lambda x: x in list2, list1)) # Результат: [4, 5, 6, 7] # Пересечение списков строк с учётом регистра tags1 = ['python', 'AI', 'MachineLearning', 'data'] tags2 = ['ai', 'Python', 'backend', 'data'] common_tags = list(filter(lambda t: t.lower() in [x.lower() for x in tags2], tags1)) # Результат: ['python', 'AI', 'data']
Следует отметить: при работе с большими коллекциями эффективнее преобразовать второй список во множество для ускорения проверки вхождения (x in set(list2)), так как проверка принадлежности к множеству выполняется за O(1) вместо O(n).
Фильтрация списков словарей (например: товары дороже X)
В современной разработке часто приходится работать со структурированными данными, представленными как списки словарей — например, результаты API-запросов или записи из баз данных:
products = [
{'name': 'Laptop', 'price': 1200, 'category': 'Electronics', 'rating': 4.5},
{'name': 'Mouse', 'price': 25, 'category': 'Electronics', 'rating': 4.0},
{'name': 'Desk', 'price': 350, 'category': 'Furniture', 'rating': 4.7},
{'name': 'Chair', 'price': 180, 'category': 'Furniture', 'rating': 4.3},
{'name': 'Monitor', 'price': 450, 'category': 'Electronics', 'rating': 4.8}
]
# Товары дороже 300 с высоким рейтингом
premium = list(filter(
lambda p: p['price'] > 300 and p['rating'] >= 4.5,
products
))
# Результат: [{'name': 'Laptop', ...}, {'name': 'Monitor', ...}]
# Электроника в среднем ценовом сегменте
mid_range_electronics = list(filter(
lambda p: p['category'] == 'Electronics' and 50 <= p['price'] <= 500,
products
))
# Результат: [{'name': 'Monitor', 'price': 450, ...}]
Комбинирование filter() с другими операциями позволяет строить сложные запросы к данным без использования внешних библиотек.
Фильтрация выбросов/аномалий в данных (пример со статистикой)
При анализе данных часто требуется удалить аномальные значения — выбросы, которые могут исказить статистику. Типичный подход — отбросить значения, лежащие за пределами определённого количества стандартных отклонений от среднего:
import statistics measurements = [10, 12, 11, 13, 10, 11, 95, 12, 10, 13, 11, 2, 12, 11] mean = statistics.mean(measurements) std_dev = statistics.stdev(measurements) # Удаляем значения, отклоняющиеся более чем на 2 стандартных отклонения filtered_data = list(filter( lambda x: abs(x - mean) <= 2 * std_dev, measurements )) # Результат: [10, 12, 11, 13, 10, 11, 12, 10, 13, 11, 12, 11] # Удалены выбросы: 95 и 2
Другой распространённый метод — межквартильный размах (IQR), который менее чувствителен к экстремальным значениям:
def remove_outliers_iqr(data): sorted_data = sorted(data) q1_idx = len(sorted_data) // 4 q3_idx = 3 * len(sorted_data) // 4 q1 = sorted_data[q1_idx] q3 = sorted_data[q3_idx] iqr = q3 - q1 lower_bound = q1 - 1.5 * iqr upper_bound = q3 + 1.5 * iqr return list(filter(lambda x: lower_bound <= x <= upper_bound, data)) clean_data = remove_outliers_iqr(measurements)
Пример данных с выбросами:
| Индекс | Значение | Статус |
|---|---|---|
| 0-5 | 10-13 | Норма |
| 6 | 95 | Выброс (слишком высокое) |
| 7-10 | 10-13 | Норма |
| 11 | 2 | Выброс (слишком низкое) |
| 12-13 | 11-12 | Норма |
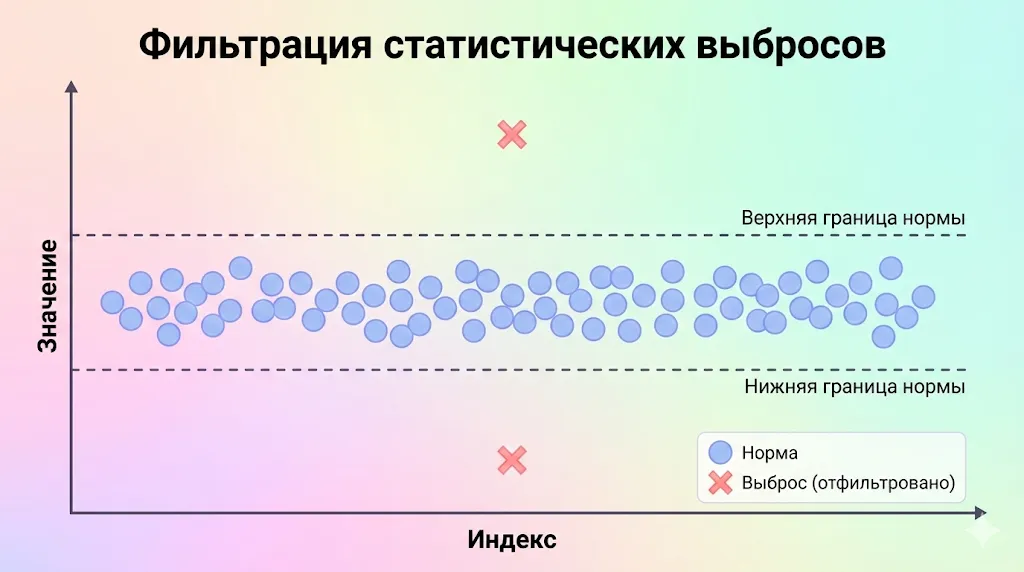
Иллюстрация демонстрирует применение filter() для очистки данных от статистических выбросов. Точки, выходящие за пределы установленных границ нормы (обозначены красными крестиками), отфильтровываются, оставляя только данные в пределах допустимого диапазона.
Обработка NaN и спецзначений
При работе с числовыми данными, особенно полученными из внешних источников, часто встречаются специальные значения — NaN (Not a Number), бесконечности. Python предоставляет инструменты для их обработки:
import math
data = [1.5, float('nan'), 2.3, float('inf'), 3.7, float('-inf'), 4.2, None]
# Удаление NaN и бесконечностей
clean_numbers = list(filter(
lambda x: x is not None and not math.isnan(x) and not math.isinf(x),
[x for x in data if isinstance(x, (int, float))]
))
# Результат: [1.5, 2.3, 3.7, 4.2]
# Альтернативный подход с использованием math.isfinite
clean_alt = list(filter(
lambda x: isinstance(x, (int, float)) and math.isfinite(x),
data
))
# Результат: [1.5, 2.3, 3.7, 4.2]
Функция math.isfinite() проверяет, является ли число конечным (не NaN и не бесконечность), что делает код более компактным. Это особенно актуально при подготовке данных для машинного обучения, где такие значения могут вызвать ошибки в алгоритмах.
Комбинирование filter() с другими функциями Python
Истинная мощь filter() раскрывается при использовании в связке с другими функциями высшего порядка. Функциональный подход программирования предполагает создание конвейеров обработки данных, где результат одной операции становится входом для следующей. Рассмотрим наиболее распространённые комбинации, которые помогают решать сложные задачи элегантно и компактно.
filter() + map()
Комбинация фильтрации и трансформации данных — один из самых частых паттернов. Сначала отбираем нужные элементы, затем преобразуем их:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Возводим в квадрат только чётные числа
result = list(map(lambda x: x**2, filter(lambda x: x % 2 == 0, numbers)))
# Результат: [4, 16, 36, 64, 100]
# Извлекаем и форматируем цены товаров, которые в наличии
products = [
{'name': 'Laptop', 'price': 1200, 'in_stock': True},
{'name': 'Mouse', 'price': 25, 'in_stock': False},
{'name': 'Monitor', 'price': 450, 'in_stock': True}
]
prices = list(map(
lambda p: f"${p['price']:.2f}",
filter(lambda p: p['in_stock'], products)
))
# Результат: ['$1200.00', '$450.00']
Важное отличие: map() преобразует каждый элемент, а filter() отбирает их без изменения. Когда нужно и отобрать, и преобразовать, их комбинация оказывается наиболее выразительной.
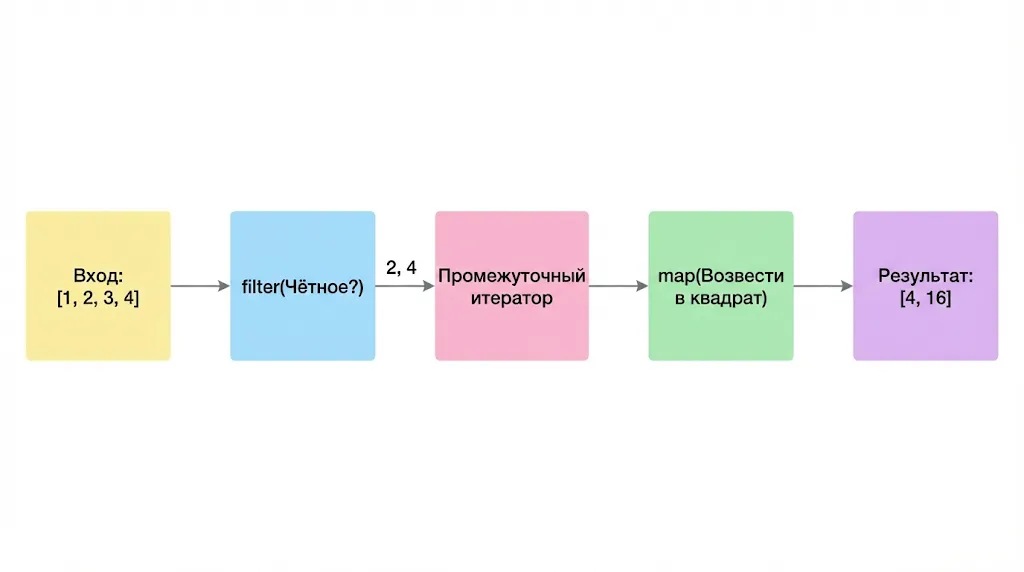
Эта схема показывает, как функции filter() и map() могут быть объединены в конвейер обработки данных. Сначала filter() отбирает нужные элементы (в данном случае, четные числа), а затем map() преобразует их (возводит в квадрат), формируя конечный результат.
Основные различия:
- filter() — уменьшает количество элементов, не изменяя их значения.
- map() — сохраняет количество элементов, трансформируя каждый из них.
- Вместе — сначала отбор, потом трансформация: максимальная гибкость.
filter() + reduce()
Функция reduce() из модуля functools позволяет свернуть коллекцию к одному значению. В сочетании с filter() это даёт возможность вычислять агрегированные показатели по отфильтрованным данным:
from functools import reduce
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Сумма только чётных чисел
sum_even = reduce(
lambda acc, x: acc + x,
filter(lambda x: x % 2 == 0, numbers),
0
)
# Результат: 30
# Произведение чисел больше 5
product = reduce(
lambda acc, x: acc * x,
filter(lambda x: x > 5, numbers),
1
)
# Результат: 30240 (6 * 7 * 8 * 9 * 10)
# Подсчёт общей стоимости доступных товаров
orders = [
{'item': 'Book', 'price': 15, 'available': True},
{'item': 'Pen', 'price': 2, 'available': False},
{'item': 'Notebook', 'price': 8, 'available': True}
]
total = reduce(
lambda acc, order: acc + order['price'],
filter(lambda o: o['available'], orders),
0
)
# Результат: 23
Стоит отметить, что для простых агрегаций (сумма, произведение) существуют встроенные функции sum() и math.prod(), которые более читаемы. Однако reduce() незаменим для сложных операций сворачивания, где логика аккумуляции нетривиальна.
filter() + enumerate()
Функция enumerate() добавляет к элементам коллекции их индексы, что полезно, когда нужно фильтровать на основе позиции элемента или сохранить информацию об исходном индексе:
words = ['apple', 'banana', 'cherry', 'date', 'elderberry'] # Отбираем элементы на чётных позициях even_position = list(filter(lambda item: item[0] % 2 == 0, enumerate(words))) # Результат: [(0, 'apple'), (2, 'cherry'), (4, 'elderberry')] # Извлекаем только значения values = [item[1] for item in even_position] # Результат: ['apple', 'cherry', 'elderberry'] # Фильтруем данные, где индекс соответствует условию на значение data = [10, 25, 30, 45, 50, 65, 70] # Оставляем элементы, где индекс меньше значения, делённого на 10 filtered = list(filter(lambda item: item[0] < item[1] // 10, enumerate(data))) # Результат: [(0, 10), (1, 25), (2, 30), (3, 45), (4, 50)]
Комбинация filter() с enumerate() особенно полезна при работе с данными, где позиция элемента несёт смысловую нагрузку — временные ряды, последовательности измерений, логи событий.
# Практический пример: фильтрация логов по времени и уровню logs = [ 'INFO: System started', 'DEBUG: Loading config', 'ERROR: Connection failed', 'INFO: Retrying...', 'ERROR: Timeout' ] # Находим все ERROR после определённой позиции errors_after_start = list(filter( lambda item: item[0] > 1 and 'ERROR' in item[1], enumerate(logs) )) # Результат: [(2, 'ERROR: Connection failed'), (4, 'ERROR: Timeout')]
Эти комбинации демонстрируют, как функциональный подход позволяет строить сложные конвейеры обработки данных, сохраняя при этом читаемость и декларативность кода. Каждая функция выполняет одну чётко определённую задачу, а их композиция решает комплексные проблемы.
Ограничения и недостатки
Несмотря на универсальность и элегантность, эта функция не является идеальным решением для всех задач фильтрации. Понимание ограничений помогает принимать взвешенные решения о том, когда использовать ее, а когда выбрать альтернативные подходы. Давайте рассмотрим основные недостатки и ситуации, где другие инструменты могут оказаться предпочтительнее.
Когда лучше использовать list comprehension:
Генераторы списков часто превосходят filter() по читаемости, особенно для разработчиков, не знакомых с функциональным программированием. Рассмотрим сравнение:
numbers = range(20) # С filter() и lambda evens_filter = list(filter(lambda x: x % 2 == 0 and x > 10, numbers)) # С list comprehension evens_comp = [x for x in numbers if x % 2 == 0 and x > 10]
Второй вариант читается практически как естественный язык: «возьми x из numbers, если x чётное и больше 10». List comprehension также позволяет одновременно фильтровать и трансформировать данные в одной конструкции, что с filter() требует дополнительного использования map().
Когда код становится нечитаемым:
Сложные условия в lambda-функциях быстро превращаются в нечитаемый код. Например:
# Плохо: сложная логика в lambda result = list(filter( lambda x: x['status'] == 'active' and x['score'] > 80 and (x['premium'] or x['verified']) and x['age'] >= 18, users )) # Лучше: именованная функция или list comprehension def is_eligible_user(user): return (user['status'] == 'active' and user['score'] > 80 and (user['premium'] or user['verified']) and user['age'] >= 18) result = list(filter(is_eligible_user, users)) # Или list comprehension result = [u for u in users if is_eligible_user(u)]
Когда логика фильтрации требует нескольких строк или условных конструкций, которые невозможно записать в одном выражении, lambda становится неподходящим инструментом. В таких случаях именованная функция с понятным названием значительно улучшает читаемость кода.
Ленивость результата может неожиданно влиять на логику:
Объект-итератор, возвращаемый filter(), «исчерпывается» после одного прохода, что может привести к неожиданным результатам:
numbers = [1, 2, 3, 4, 5] filtered = filter(lambda x: x > 2, numbers) # Первый проход работает нормально first_pass = list(filtered) print(first_pass) # [3, 4, 5] # Второй проход вернёт пустой список! second_pass = list(filtered) print(second_pass) # []
Эта особенность может вызвать трудноуловимые баги, если один и тот же результат фильтрации используется в нескольких местах программы. Решение — явное преобразование в список при первом использовании.
Ещё одна проблема ленивости связана с изменяемыми объектами:
data = [{'value': 1}, {'value': 2}, {'value': 3}]
filtered = filter(lambda x: x['value'] > 1, data)
# Изменяем исходные данные до материализации результата
data[1]['value'] = 0
# Результат фильтрации будет учитывать изменения!
result = list(filtered)
# Результат: [{'value': 3}] -- второй элемент отфильтрован, т.к. его значение стало 0
Дополнительные ограничения:
- Производительность. Для очень простых операций list comprehension может работать немного быстрее из-за оптимизаций интерпретатора.
- Отладка. Отлаживать lambda-функции сложнее, чем именованные — невозможно установить точку останова внутри lambda.
- Повторное использование. Lambda-функции, написанные для filter(), нельзя переиспользовать в других частях программы без дублирования кода.
- Ограничения lambda. Невозможность использовать операторы присваивания, множественные выражения или сложную логику с ветвлениями.
Возникает вопрос: означает ли это, что функцию следует избегать? Отнюдь нет. Она остаётся ценным инструментом, особенно при работе с готовыми предикатами, в функциональных конвейерах обработки данных и когда требуется подчеркнуть намерение фильтрации. Ключ к успеху — понимание контекста применения и выбор подходящего инструмента для конкретной задачи.
Где и когда стоит использовать функцию в реальных задачах
Теоретическое понимание приобретает практическую ценность, когда мы видим, как эта функция применяется в реальных проектах. Давайте рассмотрим типичные сценарии использования, с которыми сталкиваются специалисты в повседневной работе, и оценим, почему именно filter() оказывается оптимальным выбором в этих ситуациях.
Очистка данных
Одна из наиболее распространённых задач — удаление некорректных, неполных или нерелевантных данных перед дальнейшей обработкой. Это критически важно при работе с пользовательским вводом, данными из внешних API или результатами парсинга:
# Очистка списка email-адресов от невалидных записей
emails = ['user@example.com', '', 'invalid', 'test@domain.co', None, 'admin@site.org']
valid_emails = list(filter(lambda e: e and '@' in e and '.' in e, emails))
# Удаление дубликатов и пустых значений из пользовательского ввода
user_tags = ['python', '', 'Python', 'ai', '', 'AI', 'python']
clean_tags = list(dict.fromkeys(filter(None, [t.strip().lower() for t in user_tags])))
# Фильтрация строк лога от служебных сообщений
log_lines = ['DEBUG: init', 'INFO: started', 'DEBUG: config', 'ERROR: timeout']
important = list(filter(lambda line: not line.startswith('DEBUG'), log_lines))
Подготовка данных для анализа
При работе с аналитикой и машинным обучением часто требуется отобрать подмножество данных, соответствующих определённым критериям, прежде чем применять статистические методы или алгоритмы:
# Отбор транзакций в определённом диапазоне для анализа
transactions = [
{'amount': 15.99, 'date': '2024-01-15', 'status': 'completed'},
{'amount': 1250.00, 'date': '2024-01-16', 'status': 'pending'},
{'amount': 45.50, 'date': '2024-01-17', 'status': 'completed'}
]
completed = list(filter(lambda t: t['status'] == 'completed', transactions))
# Выборка данных для обучающей выборки
samples = [{'features': [...], 'label': 1, 'quality': 0.95}, ...]
high_quality = list(filter(lambda s: s['quality'] > 0.9, samples)
Быстрые проверки условий
В процессе разработки часто возникает необходимость быстро проверить, удовлетворяет ли хотя бы один элемент коллекции определённому условию, или подсчитать количество элементов с нужными свойствами:
# Проверка наличия непрочитанных сообщений
messages = [{'id': 1, 'read': True}, {'id': 2, 'read': False}, ...]
has_unread = any(filter(lambda m: not m['read'], messages))
# Подсчёт активных пользователей
users = [{'name': 'Alice', 'active': True}, {'name': 'Bob', 'active': False}, ...]
active_count = len(list(filter(lambda u: u['active'], users)))
# Валидация конфигурации: все обязательные поля заполнены
config = {'api_key': 'xxx', 'timeout': 30, 'endpoint': '', 'retries': 3}
required_fields = ['api_key', 'endpoint']
all_filled = all(filter(lambda k: config.get(k), required_fields))
Работа с потоками данных
Ленивая природа функции делает её идеальным инструментом при работе с большими объёмами данных, которые нельзя полностью загрузить в память, или при обработке данных в реальном времени:
# Обработка больших файлов построчно
with open('huge_log.txt', 'r') as f:
error_lines = filter(lambda line: 'ERROR' in line, f)
for line in error_lines:
process_error(line) # Обрабатываем только строки с ошибками
# Фильтрация данных из генератора
def sensor_readings():
while True:
yield get_sensor_value()
valid_readings = filter(lambda v: 0 <= v <= 100, sensor_readings())
# Обработка API-ответов с пагинацией
def fetch_all_pages():
page = 1
while True:
data = api.get(f'/items?page={page}')
if not data:
break
yield from data
page += 1
active_items = filter(lambda item: item['status'] == 'active', fetch_all_pages())
Дополнительные практические сценарии включают:
- Фильтрацию результатов поиска по множественным критериям.
- Отбор релевантных записей для экспорта или отчётов.
- Выделение подмножества данных для A/B-тестирования.
- Удаление устаревших или неактуальных записей из кэша.
- Валидацию входных данных перед сохранением в базу.
filter() особенно ценна в ситуациях, где критерий фильтрации может динамически меняться — например, когда функция-предикат передаётся как параметр или формируется на основе пользовательских настроек. Это делает код гибким и легко расширяемым, что критически важно в долгосрочной перспективе развития проекта.
Заключение
Функция filter() представляет собой мощный инструмент, который элегантно решает задачу отбора элементов из коллекций по заданным критериям. Подведем итоги:
- Функция filter позволяет отбирать элементы по условию. Она применяет предикат к каждому объекту коллекции.
- В Python 3 результатом работы является итератор. Это снижает расход памяти при обработке больших данных.
- Filter можно использовать с именованными функциями и lambda. Выбор зависит от сложности логики фильтрации.
- Результат работы функции легко преобразовать в список, кортеж, множество или строку. Это делает инструмент универсальным.
- Функция особенно полезна при очистке данных и подготовке информации к анализу. Она упрощает обработку потоков и структурированных данных.
Если вы только начинаете осваивать профессию python-разработчика, рекомендуем обратить внимание на подборку курсов по Python. В них есть теоретическая и практическая часть, которые помогут уверенно применять фильтрацию данных в реальных задачах.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.