GeekBrains vs Karpov.Courses: аналитика — где проще вход, а где выше планка задач
Курсов по аналитике данных на рынке десятки. Сравнительных статей — ещё больше. Большинство из них заканчиваются примерно одинаково: «оба варианта хорошие, выбирайте под себя» — и никакой конкретики о том, что именно «под себя» означает.

В этом материале мы разбираем два конкретных вопроса: где реально проще войти, если за плечами нет технического бэкграунда, — и где выше планка задач, если база уже есть и хочется расти. Для этого мы прошли через программы, позиционирование и логику обеих платформ — GeekBrains и Karpov.Courses — и собрали структуру, которая помогает принять решение исходя из вашего уровня, времени и цели. Без «один лучше другого» и без голословных обещаний.
- GeekBrains или Karpov.Courses: где проще старт, а где выше планка?
- Где проще вход «с нуля»: как устроен онбординг и первые недели
- Сравнение практики и программы: где больше задач и глубже стек?
- Формат и поддержка: темп, дедлайны, проверка ДЗ
- Результат и окупаемость: портфолио, карьера, деньги
- FAQ: что выбрать под ваши ограничения
- Рекомендуем посмотреть курсы по системной аналитике
GeekBrains или Karpov.Courses: где проще старт, а где выше планка?
Если смотреть на позиционирование платформ честно, без маркетингового глянца, картина складывается примерно такая. GeekBrains последовательно строит образ «входной точки»: обучение без технического бэкграунда, объяснения «человеческим языком», поддержка на каждом шаге. Это не недостаток — это осознанная ставка на аудиторию, которой страшно начинать. Karpov.Courses, напротив, делает акцент на объёме и глубине практики: 830+ задач, выделенный трек «Hard» с элементами ML, упор на самостоятельную работу с реальными данными. Здесь меньше «держат за руку» — и это тоже осознанная позиция.
Проблема возникает тогда, когда человек с нулевой базой записывается туда, где «высокая планка» — и сливается на третьей неделе. Или когда специалист с опытом в Excel и базовым SQL платит за курс «с нуля» и скучает на вводных модулях. Обе ситуации — не вина платформ, а результат несовпадения ожиданий и реального уровня.
Ниже — быстрая сравнительная таблица по 12 критериям, которая даст ориентир до того, как мы разберём каждый пункт подробно.
GeekBrains vs Karpov.Courses: быстрое сравнение по 12 критериям
| Критерий | GeekBrains | Karpov.Courses |
|---|---|---|
| Порог входа | Низкий — позиционирование «с нуля», без технического бэкграунда | Средний — предполагается базовое понимание таблиц/логики |
| Темп обучения | Умеренный, с поддержкой | Интенсивный, акцент на самостоятельность |
| Объём практики | Достаточный для старта | Высокий — 830+ практических задач |
| Сложность ДЗ | Преимущественно L1–L2 (по образцу, шаблону) | L1–L4, включая «Hard»-уровень |
| Глубина SQL | Базовый–средний (SELECT, JOIN, агрегации) | Средний–продвинутый (оконные функции, оптимизация) |
| Глубина Python | Базовый (pandas, визуализация) | Средний (pandas, numpy, sklearn-минимум) |
| BI-инструменты | Есть в программе (Tableau/Power BI) | Есть, с акцентом на интерпретацию данных |
| Статистика / A/B | Базовый уровень | Средний — проверка гипотез, p-value, размер эффекта |
| ML-минимум | Ознакомительный | Присутствует в Hard-треке (регрессия, классификация) |
| Обратная связь | Кураторы, проверка ДЗ, чат | Ревью задач, комьюнити, наставники |
| Портфолио | Итоговый проект | Накопительное портфолио по задачам + финальный проект |
| Кому подходит | «Нулевой» старт, нужен наставник и структура | Есть база → хочу практики и роста |
Алгоритм выбора курса: три ключевых вопроса
Прежде чем идти дальше, ответьте себе честно на три вопроса — они задают «развилки» в логике выбора:
- Уровень: Вы можете написать SQL-запрос с JOIN и GROUP BY, не подглядывая? → Если нет — нужен мягкий вход. Если да — смотрите на глубину практики.
- Время: Сколько часов в неделю реально, а не «в идеале»? До 7 часов — нужна гибкость и щадящий темп. 10–15 часов — можно брать интенсив.
- Цель: «Войти в профессию за 6–9 месяцев» или «вырасти внутри текущей роли»? Первый сценарий требует дисциплины и портфолио, второй — глубины стека.
Эти три развилки и определяют, какая из платформ сработает именно для вас. В следующих разделах мы рассмотрим каждую из них подробно — с конкретными сценариями и инструментами.
Роман Бунин, эксперт по визуализации данных и системный аналитик (ex-Яндекс): «Аналитик сегодня — это не тот, кто рисует чарты, а тот, кто находит в данных аномалии и приносит деньги. Если курс учит только синтаксису SQL, вы выйдете оператором базы данных, а не аналитиком».
Для кого GeekBrains, а для кого Karpov.Courses: три портрета
Абстрактные описания аудитории вроде «подходит всем, кто хочет войти в IT» — это маркетинг, а не навигация. Давайте сделаем иначе: три реальных портрета, в каждом из которых можно узнать себя.
Портрет 1. «С нуля, страшно, нужен наставник»
- Бэкграунд: гуманитарное или нетехническое образование, Excel на уровне «сумма и фильтры», SQL не трогал, Python звучит угрожающе. Времени — около 7–8 часов в неделю, часть из которых неизбежно «съедается» бытом.
- Что важно: пошаговые объяснения, живой куратор, возможность задать «глупый» вопрос без осуждения, умеренный темп без ощущения, что отстаёшь от группы.
- Рекомендация: GeekBrains. Позиционирование «с нуля» здесь не просто слоган — это конкретная методическая логика: от Excel к SQL, от SQL к Python, без резких скачков сложности.
Портрет 2. «Есть база, хочу практики и роста»
- Бэкграунд: работает в смежной роли — маркетолог, продакт, финансист — и уже пишет простые SQL-запросы, строит сводные таблицы, понимает, что такое воронка и метрики. Хочет «сделать аналитику основной профессией» или существенно расширить инструментарий.
- Что важно: много задач на реальных данных, рост сложности, возможность дойти до A/B-тестов и базовой статистики, не тратя время на объяснение того, что уже знает.
- Рекомендация: Karpov.Courses. Высокий объём практики и наличие задач уровня L3–L4 дают именно тот «мышечный рост», который нужен человеку со средней базой.
Глеб Михайлов, известный Data Science евангелист: «Главная ошибка новичка — учить инструменты (Python, SQL) в отрыве от доменной области. Вы должны понимать, как работает бизнес-модель, прежде чем считать Retention«.
Портрет 3. «Цель — оффер, нужен проектный выход и дисциплина»
- Бэкграунд: может быть разным — от почти нуля до уверенного среднего уровня. Главное — чёткая цель: пройти собеседование на junior-аналитика в течение 6–9 месяцев. Готов к интенсивной нагрузке, если видит конкретный результат.
- Что важно: накопительное портфолио, финальный проект, который не стыдно показать на GitHub, и поддержка в подготовке к собесу.
- Рекомендация: Karpov.Courses — за счёт объёма задач и проектной логики. Но при условии, что база уже есть. Если базы нет — сначала 2–3 месяца на GeekBrains, затем переход или параллельная практика на Karpov.
Как видно, выбор платформы — это не вопрос «какая лучше», а вопрос соответствия вашему текущему уровню и цели. Именно поэтому следующий шаг — честная самодиагностика, без скидок на «ну я примерно понимаю».
Мини-самодиагностика: какой у вас порог входа по SQL/Python/матстату
Прежде чем выбирать курс, стоит потратить пять минут на честную самопроверку. Не «я в целом понимаю логику» — а конкретные ответы на конкретные вопросы. Ниже — семь пунктов. Отвечайте «да» только если можете сделать это прямо сейчас, без гугла.
Чек-лист самодиагностики
- Вы можете написать SQL-запрос с JOIN двух таблиц и GROUP BY — и объяснить, что он делает?
- Вы понимаете разницу между WHERE и HAVING и знаете, когда использовать каждый?
- Вы работали с pandas: загружали датафрейм, фильтровали строки, считали агрегации?
- Вы знаете, что такое медиана, стандартное отклонение и в чём их практический смысл?
- Вы строили сводные таблицы в Excel или Google Sheets и понимаете логику агрегации?
- Вы слышали про p-value и можете объяснить, что значит «результат статистически значим»?
- Вы хотя бы раз самостоятельно строили дашборд — в Tableau, Power BI, Looker Studio или любом другом BI-инструменте?
Интерпретация результатов
- 0–2 «да» → Вход с нуля. Не в смысле «вы ничего не знаете» — в смысле «фундамент ещё не заложен». Здесь критически важен мягкий онбординг, объяснения базовых концепций и куратор, который не даст потеряться на старте. Выбор в пользу GeekBrains здесь логичен и обоснован.
- 3–5 «да» → Средняя база. Вы понимаете инструменты, но, возможно, не уверены в статистике или Python. Можно сразу идти на программу с высокой практической нагрузкой — Karpov.Courses закроет пробелы через задачи, а не через дополнительные объяснения. Главное — не бояться сложных ДЗ на старте.
- 6–7 «да» → Уверенная база. Курс «с нуля» будет скучным и неэффективным. Смотрите на глубину стека: есть ли задачи уровня L3–L4, покрывается ли A/B-методология, есть ли ML-минимум. Для вас важен не онбординг, а рост планки — и здесь выигрывает трек Hard на Karpov.Courses.
Результат этой диагностики — не приговор, а точка отсчёта. Базу можно подтянуть за 2–4 недели самостоятельно, если знать, что именно учить. Об этом — в следующем разделе.
Где проще вход «с нуля»: как устроен онбординг и первые недели
Один из самых распространённых страхов перед стартом звучит примерно так: «А вдруг я не потяну, и все вокруг окажутся умнее?». Это нормальная реакция — и именно поэтому качество онбординга часто решает больше, чем содержание всей программы. Человек, который не потерялся на первой неделе, доходит до конца. Тот, кто потерялся — уходит, даже если курс объективно хороший.
Давайте разберёмся, что реально происходит в первые недели обучения и что нужно знать до старта, чтобы не тратить первый месяц на ликвидацию пробелов в панике.
Что нужно знать до старта и где это закрывается
Хорошая новость: порог входа в аналитику данных ниже, чем кажется. Плохая: он всё же существует — и если прийти совсем без базы, первые недели превратятся в догонялки вместо обучения. Ниже — минимальный набор навыков, который стоит иметь до старта курса, и способы закрыть каждый пробел за 1–2 недели.
Таблица: Навык → зачем нужен в работе → как быстро подтянуть
| Навык | Зачем нужен аналитику | Как подтянуть за 1–2 недели |
|---|---|---|
| Excel / Google Sheets (базовый) | Быстрый анализ, сводные таблицы, первичная обработка данных | Бесплатные курсы на Stepik, официальные туториалы Google |
| Логика SQL (SELECT, WHERE, JOIN) | Основа работы с любой реляционной БД | SQLZoo, Mode SQL Tutorial, тренажёр на sql-ex.ru |
| Понятие таблицы, ключей, связей | Без этого JOIN превращается в магию | Любой вводный курс по базам данных — достаточно 3–4 часов |
| Базовый Python (переменные, циклы, функции) | Необходим для pandas и автоматизации | Python на Stepik («Поколение Python»), первые 5 модулей |
| Базовые метрики (среднее, медиана, процентили) | Без этого интерпретация данных невозможна | Khan Academy Statistics, любой вводный урок по описательной статистике |
Важный момент: большинство курсов — включая GeekBrains — декларируют старт «с нуля» и действительно закрывают часть этих пробелов в первых модулях. Но есть нюанс: «закрывает» не означает «даёт время освоить». Темп первых недель может быть достаточно высоким даже на «мягких» программах. Поэтому если вы знаете, что, например, SQL для вас — абсолютная terra incognita, потратьте одну неделю до старта на sql-ex.ru или SQLZoo. Это не подготовка к экзамену — это страховка от стресса в первый месяц.GeekBrains на странице курса “Аналитик данных” прямо говорит, что курс подойдет как новичку, так и человеку с минимальными знаниями.

GeekBrains на странице курса “Аналитик данных” прямо говорит, что курс подойдет как новичку, так и человеку с минимальными знаниями.
Что касается инструментов: Excel или Google Sheets — это не «устаревший навык», а рабочая реальность большинства аналитиков. Умение быстро собрать сводную таблицу и построить простой график ценится на практике не меньше, чем знание pandas. BI-инструменты (Tableau, Power BI, Looker Studio) появятся в программе позже — их не нужно учить до старта, достаточно понимать, что это «визуализация данных для бизнеса».
Схематично путь новичка от нуля до портфолио выглядит так:
База (Excel/SQL/Python-основы) → Практика на реальных данных → Проект с интерпретацией результатов → Упаковка и подготовка к собеседованию
Каждый этап строится на предыдущем — и именно поэтому пропускать базу, даже если «хочется быстрее к интересному», не стоит.
Типовые ошибки новичков и как не слиться на 2–3 неделе
Статистика онлайн-образования неутешительна: по различным оценкам, до финала доходят от 10 до 15% записавшихся на курс. Причём большинство отсева происходит не в конце, когда становится по-настоящему сложно, — а на второй-третьей неделе, когда первоначальный энтузиазм заканчивается, а навык ещё не сформировался. Давайте разберём пять основных причин, по которым люди уходят именно в этот момент — и как каждую из них нейтрализовать.
- Ошибка 1. Недооценка реального времени. «Буду учиться по вечерам» — звучит разумно. На практике это означает: усталость после работы, одно пропущенное занятие, затем второе, затем ощущение, что «всё равно отстал». Курс не бросают потому, что стало сложно — его бросают потому, что накопился долг и непонятно, с чего начать возврат. Как избежать: до старта честно посчитайте не «сколько хотите учиться», а «сколько реально останется после всего остального». Если получается 5–7 часов в неделю — это нормально, просто выбирайте темп, который этому соответствует.
- Ошибка 2. Просмотр лекций без практики. Лекция создаёт иллюзию понимания. Человек смотрит объяснение SQL-запроса, кивает, думает «понял» — и не открывает тренажёр. Через три дня запрос не пишется. Через неделю кажется, что «ничего не усваивается». Как избежать: правило простое — ни одна лекция не считается пройденной, пока не написан хотя бы один запрос/скрипт руками. Без исключений.
- Ошибка 3. Попытка «выучить всё» перед следующим шагом. Перфекционизм в обучении — один из главных врагов прогресса. «Я перейду к следующей теме, когда полностью разберусь с текущей» — звучит ответственно, но на практике означает зависание на одной теме неделями. Как избежать: принять, что понимание приходит итерациями. Первый раз — «примерно понял». После практики — «начинаю чувствовать логику». После трёх-пяти задач — «это уже рефлекс». Двигайтесь вперёд, даже если что-то кажется недоусвоенным.
- Ошибка 4. Отсутствие конспекта или репозитория. Обучение без фиксации — это вода, которую льют в дырявое ведро. Через месяц человек не может вспомнить, что проходил две недели назад, и тратит время на повторение вместо продвижения вперёд. Как избежать: завести GitHub-репозиторий с первого дня. Пусть там будут даже самые простые учебные скрипты — это формирует привычку и попутно начинает собирать портфолио.
- Ошибка 5. Страх задавать вопросы. «Не хочу выглядеть глупо в чате» — классика. В результате человек застревает на одном месте на несколько дней, теряет темп и мотивацию.
Как избежать: понять, что «глупых вопросов» в обучении не существует — существуют только неправильно сформулированные. Вопрос с контекстом («я пишу такой запрос, ожидаю такой результат, получаю вот это — где ошибка?») всегда получает ответ быстрее и качественнее, чем «почему не работает».
Чек-лист «Как не слиться на 2–3 неделе»
- Зафиксировать реальное время на обучение в календаре — как встречу, которую нельзя перенести.
- Завести GitHub-репозиторий в первый день и коммитить каждое практическое задание.
- Не считать лекцию пройденной без практики — минимум одна задача на каждую тему.
- Двигаться вперёд даже при неполном понимании — возвращаться после практики.
- Задавать вопросы в чате с контекстом: что делаю → что ожидаю → что получаю.
- Не сравнивать свой темп с чужим — у всех разная база и разное время.
- Раз в неделю делать «ревью недели»: что усвоил, где застрял, что повторить.
- Не пропускать более двух дней подряд — возобновить проще, чем перезапустить.
- Первые две недели — режим «малых побед»: лучше сделать меньше, но каждый день.
- Найти одного «учебного партнёра» в потоке — взаимный контроль работает лучше силы воли.
Онбординг — это не про то, насколько умный или подготовленный вы. Это про то, насколько правильно выстроен первый месяц. Если первые две недели пройдены без накопленного долга и с живой практикой — дальше становится значительно проще. Именно на этом фундаменте строится всё остальное: глубина задач, сложность стека, реальный рост.
Сравнение практики и программы: где больше задач и глубже стек?
Если онбординг — это про то, как войти, то практика и программа — это про то, куда вы в итоге придёте. Именно здесь разница между платформами становится наиболее ощутимой. И именно здесь чаще всего возникает главное заблуждение: «много практики» и «высокая планка задач» — это не одно и то же.
Можно решить 500 однотипных задач уровня «повтори по образцу» и остаться на том же месте. А можно разобрать 50 задач, где нужно самостоятельно выбрать метод, обосновать решение и интерпретировать результат для бизнеса — и сделать качественный скачок. Давайте разберёмся, как устроена практика на каждой из платформ и что это означает на выходе.
Практика и сложность ДЗ: объём задач, критерии, «hard»-планка
Чтобы говорить о сложности предметно, нужна общая шкала. Введём четыре уровня — они достаточно универсальны для оценки любого курса по аналитике.
Таблица: Шкала сложности задач L1–L4
| Уровень | Описание | Пример задачи |
|---|---|---|
| L1 — По образцу | Повторить действие из лекции на тех же или аналогичных данных | Написать SELECT с GROUP BY по шаблону из урока |
| L2 — По шаблону, новые данные | Применить известный паттерн к незнакомому датасету | Посчитать retention по новой таблице событий |
| L3 — Выбор метода / гипотеза | Самостоятельно выбрать подход, проверить гипотезу, обосновать результат | Определить, значимо ли падение конверсии, и объяснить почему |
| L4 — Неопределённость / бизнес-интерпретация | Работать с неполными данными, принимать компромиссные решения, формулировать вывод для стейкхолдера | Проанализировать аномалию в метриках и предложить гипотезы причин с рекомендациями |
Большинство курсов для начинающих работают в диапазоне L1–L2 — и это оправдано: без уверенного владения базовыми паттернами переходить к L3 бессмысленно. Вопрос в том, есть ли в программе путь к L3–L4 — или курс заканчивается там, где начинается настоящая работа.
Karpov.Courses заявляет 830+ практических задач — и важно понимать, что это не просто количество. Наличие выделенного трека «Hard» с задачами на регрессию, классификацию, кластеризацию и временные ряды означает, что платформа осознанно закрывает диапазон L3–L4. Это именно та зона, где аналитик перестаёт быть «человеком с дашбордом» и начинает работать с неопределённостью и бизнес-контекстом.
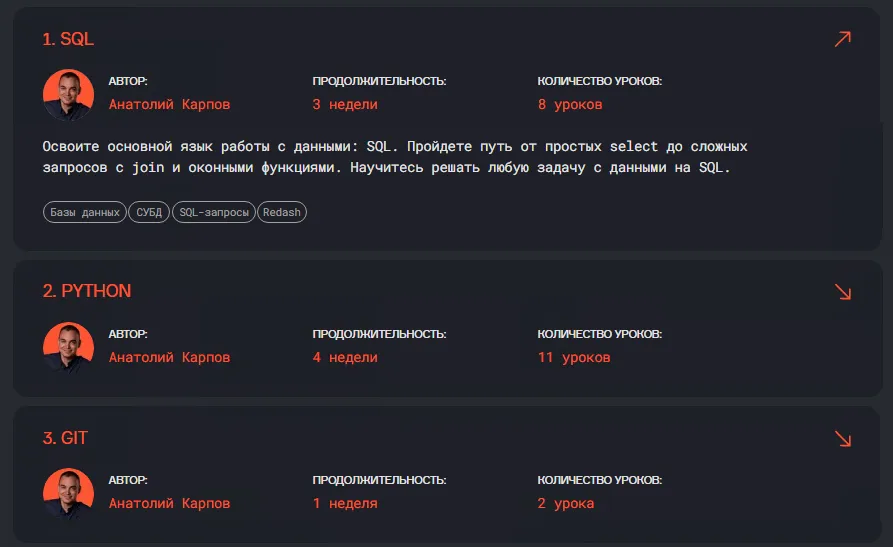
Часть программы курса “Аналитик данных” у Karpov.Courses.
GeekBrains строит практику иначе: упор на уверенное освоение L1–L2 с постепенным переходом к L3 в рамках итогового проекта. Это не слабость — это другая методическая логика, рассчитанная на человека, которому важнее сначала почувствовать почву под ногами, чем сразу прыгнуть в глубину.
У GeekBrains можно выбрать конкретную профессию, связанную с аналитикой и идти дальше по ней.
Практический вывод: если ваша цель — войти в профессию с базовым стеком и получить первый оффер, диапазона L1–L3 достаточно. Если цель — работать в продуктовых командах, взаимодействовать с DS/ML-инженерами и расти до middle — нужен выход на L4, и здесь важно выбирать программу с явным «hard»-углублением.
Программа и инструменты: SQL, Python, BI, статистика, A/B, ML-минимум
Стек аналитика данных — это не список технологий для резюме. Это набор инструментов, каждый из которых решает конкретную рабочую задачу. Рассмотрим каждый элемент через призму «зачем это нужно на практике» — и соотнесём с тем, как он представлен в программах.
Матрица стека аналитика данных
| Инструмент / навык | Зачем нужен на работе | Уровень в GeekBrains | Уровень в Karpov.Courses |
|---|---|---|---|
| SQL | Основа 80% задач: извлечение, агрегация, джойны, оконные функции | Базовый–средний | Средний–продвинутый |
| Python (pandas, numpy) | Обработка данных, автоматизация, EDA | Базовый | Средний |
| BI (Tableau / Power BI) | Визуализация для бизнеса, дашборды для стейкхолдеров | Есть в программе | Есть, акцент на интерпретацию |
| Статистика (описательная) | Без неё любой анализ — это «примерно так» | Базовый | Средний |
| A/B-тестирование | Ключевой инструмент продуктовой аналитики | Базовый | Средний — p-value, размер эффекта, мощность теста |
| Продуктовые метрики | DAU/MAU, retention, LTV, воронки — язык общения с бизнесом | Есть | Есть |
| ML-минимум | Взаимодействие с DS-командой, базовые прогнозы | Ознакомительный | Есть в Hard-треке |
Отдельно остановимся на блоке, который вызывает больше всего вопросов — ML-минимум для аналитика.
Здесь важно расставить акценты честно. Аналитик данных — это не data scientist, и требовать от него построения production-моделей никто не будет. Но в реальной работе аналитик регулярно оказывается на стыке с ML-командой: нужно понять, что делает модель, оценить качество её предсказаний, сформулировать задачу для DS-инженера или интерпретировать результат для бизнеса.
Именно поэтому ML-минимум аналитику нужен не для того, чтобы «тоже уметь строить модели» — а для того, чтобы говорить на одном языке с командой и не быть слепым пятном в процессе. Конкретно это означает:
- понимание логики линейной регрессии и классификации (не формулы — а что модель делает и зачем);
- умение читать метрики качества модели (precision/recall, RMSE — хотя бы на уровне «это хорошо или плохо»);
- базовое понимание кластеризации — когда это применяется и что даёт бизнесу;
- понимание временных рядов на уровне «тренд, сезонность, аномалия».
Когда ML-минимум лучше не трогать до формирования базы: если вы ещё не уверены в SQL и pandas — ML будет просто набором магических функций без понимания. Сначала база, потом углубление.
Итог раздела можно сформулировать коротко: глубина стека определяет не то, сколько строк в вашем резюме, а то, какие задачи вы сможете закрывать самостоятельно через полгода после старта. Выбирайте программу исходя из того, где вы хотите оказаться — а не из того, какой список технологий выглядит внушительнее.
Формат и поддержка: темп, дедлайны, проверка ДЗ
Содержание программы — это только половина уравнения. Вторая половина — как именно выстроен процесс обучения: можно ли совмещать с работой, что происходит, если пропустил неделю, и насколько полезна обратная связь, которую вы получаете на домашние задания. Именно эти факторы часто становятся решающими — не потому что «программа плохая», а потому что формат не совпал с реальностью жизни.
Давайте разберём два ключевых вопроса: как выбрать темп, который не сломается через месяц, и как выжать максимум из обратной связи — ресурса, который большинство студентов используют в лучшем случае наполовину.
Запись/живые занятия/гибкость темпа: что выбрать работающему
Работающий человек, который идёт на курс по аналитике — это не студент дневного отделения. У него есть дедлайны на основной работе, семья, усталость и непредсказуемые «горящие» недели. Формат обучения должен это учитывать — иначе первый же аврал на работе сломает весь ритм.
Рассмотрим три реальных сценария и что они означают на практике.
Сценарий 1. Времени 5–7 часов в неделю
Это самый распространённый режим — и самый уязвимый. При таком бюджете времени критически важны два параметра: возможность учиться в записи (чтобы не зависеть от расписания живых занятий) и отсутствие жёстких еженедельных дедлайнов, которые создают стресс при любом сбое.
Рекомендации: выбирайте асинхронный формат с мягкими дедлайнами. Планируйте два-три фиксированных слота в неделю — лучше короткие и регулярные, чем один длинный «марафон» в выходные. Живые занятия смотрите в записи, но не откладывайте дольше чем на три дня — иначе долг накапливается быстрее, чем кажется.
Сценарий 2. Времени 10–15 часов в неделю
Комфортный режим для большинства программ. При таком бюджете можно совмещать просмотр лекций с активной практикой, участвовать в живых занятиях и успевать разбирать сложные ДЗ без спешки. Здесь уже имеет смысл смотреть на программы с более высокой интенсивностью — в том числе на треки с углублённой практикой.
Рекомендации: используйте живые занятия как точку синхронизации, а не как основной формат получения знаний. Лекции — самостоятельно в удобное время, живые сессии — для вопросов и разбора сложных мест.
Сценарий 3. «Рывками» — две недели активно, потом пауза
Наименее предсказуемый режим, но вполне рабочий при правильной стратегии. Главный риск — потеря контекста после паузы: возвращаешься и не помнишь, на чём остановился.
Рекомендации: фиксируйте в конце каждой активной сессии «точку возврата» — три предложения о том, что сделано и что следующий шаг. GitHub-коммиты с комментариями здесь работают лучше любого конспекта. И принципиально важно: не пытайтесь «догнать программу» после паузы — продолжайте с того места, где остановились.
Отдельно стоит сказать о дедлайнах. Жёсткие дедлайны — это не наказание, а инструмент дисциплины. Но для работающего человека они нужны только тогда, когда встроены в реальный ритм жизни. Если курс предполагает сдачу ДЗ каждую неделю в пятницу — убедитесь, что ваши рабочие пятницы это позволяют. Если нет — ищите программу с более гибким графиком сдачи или договаривайтесь с куратором на берегу.
Обратная связь: кураторы, чаты, ревью — как извлечь максимум
Обратная связь — это, пожалуй, самый недооценённый ресурс онлайн-обучения. Большинство студентов используют её реактивно: что-то не получилось — написал вопрос. Получил ответ — пошёл дальше. Между тем грамотно выстроенная работа с обратной связью ускоряет обучение в разы — и вот почему.

На курсах Karpov.Courses есть различные помощники – сами преподаватели, кураторы и ревьюеры, к которым можно обратиться с возникшими вопросами.
Ревью домашнего задания — это не просто «правильно/неправильно». Это информация о том, какой паттерн мышления вы используете при решении задачи — и где именно он даёт сбой. Если не фиксировать эту информацию, она теряется, и вы наступаете на те же грабли в следующем ДЗ.

У GeekBrains ситуация аналогичная — есть кураторы, служба заботы и HR-консультант, которому можно задать вопросы по составлению резюме и поиску работы.
Чек-лист «Как задавать вопрос ментору/в чате»
Хороший вопрос — это не «у меня не работает, помогите». Это структурированный запрос, который даёт ментору всё необходимое для быстрого и точного ответа:
- Контекст: что я делаю и в рамках какой задачи («пишу запрос для подсчёта retention по когортам»).
- Что пробовал: какой подход использовал и почему («написал оконную функцию с LAG, потому что нужно сравнить соседние периоды»).
- Что получаю: конкретный результат или ошибка — скриншот или код («получаю NULL в половине строк, вот запрос: …»).
- Что ожидал: какой результат считаю правильным и почему («ожидаю процент пользователей, вернувшихся на второй месяц»).
- Что уже проверил: какие гипотезы об ошибке уже исключил («проверил типы данных, они совпадают»).
Такой вопрос решается за один обмен сообщениями вместо трёх-пяти. И — что важнее — он заставляет вас самостоятельно структурировать проблему, что само по себе часто приводит к решению ещё до отправки вопроса.
Как превращать ревью в прогресс: журнал ошибок
Заведите простой документ — можно прямо в Notion или даже в текстовом файле — со следующей структурой:
Дата → Тема → В чём была ошибка → Правильный паттерн → Где ещё применимо
Раз в две недели перечитывайте этот журнал. Практика показывает: большинство ошибок в обучении аналитике — не случайные, а системные. Один и тот же человек раз за разом путает логику оконных функций, или забывает про NULL при агрегациях, или неправильно интерпретирует p-value. Журнал ошибок делает эти паттерны видимыми — и позволяет целенаправленно их закрывать, а не бороться с симптомами.
Формат и поддержка — это не «приятный бонус» к программе. Это инфраструктура, которая либо помогает вам учиться в реальных условиях, либо создаёт дополнительное трение. Правильно выстроенная работа с форматом и обратной связью может компенсировать даже не идеально подобранный темп — и наоборот, игнорирование этих инструментов сведёт на нет даже самую сильную программу.
Результат и окупаемость: портфолио, карьера, деньги
Вопрос «окупится ли курс» — один из самых честных вопросов, которые можно задать перед покупкой обучения. И один из самых сложных для ответа, потому что правильный ответ звучит так: «зависит не только от курса». Платформа может дать инструменты, задачи, обратную связь и структуру — но не может гарантировать оффер вместо вас. Давайте разберёмся, что реально находится в зоне вашего контроля, и как выстроить путь от старта до трудоустройства осознанно, без иллюзий и без лишнего пессимизма.
Портфолио аналитика: что показать
Портфолио аналитика данных — это не «папка с сертификатами». Это набор артефактов, который отвечает на вопрос рекрутера и нанимающего менеджера: «умеет ли этот человек решать реальные задачи?». Сертификат об окончании курса на этот вопрос не отвечает. SQL-кейс с интерпретацией результата — отвечает.
Хорошее портфолио junior-аналитика состоит из пяти типов артефактов — и каждый из них можно начать собирать уже в процессе обучения, не откладывая на «после курса».
Пять артефактов портфолио аналитика
- SQL-кейс на реальном датасете. Не учебный пример из лекции, а самостоятельно сформулированная задача: взять открытый датасет (например, с Kaggle или data.gov), написать серию запросов и — главное — сформулировать вывод. Что показывают данные? Какое бизнес-решение из этого следует?
- Python-ноутбук с EDA. Exploratory Data Analysis — разведочный анализ данных. Загрузка датасета, очистка, визуализация распределений, поиск аномалий, базовые корреляции. Ноутбук должен читаться как связный нарратив: не просто код, а код с объяснением, что и зачем делается.BI-дашборд. Tableau Public или Looker Studio позволяют публиковать дашборды бесплатно — это прямая ссылка в портфолио. Дашборд должен решать конкретную задачу: не «красивая визуализация», а «инструмент для ответа на бизнес-вопрос».
- A/B-мини-проект. Возьмите открытый датасет с результатами эксперимента (их много на Kaggle), проведите проверку гипотезы, посчитайте статистическую значимость, сформулируйте вывод с рекомендацией. Это один из самых востребованных навыков на собеседованиях в продуктовые команды.
- Финальный проект курса. Если курс предполагает итоговый проект — это потенциально самый сильный артефакт портфолио. Но только при условии, что он оформлен как самостоятельная работа, а не «сдал и забыл». Добавьте README, опишите задачу, методологию и выводы.
Структура README для проекта
## Название проекта (Одна строка: что это и зачем) ## Задача (Какой бизнес-вопрос решается) ## Данные (Источник, объём, краткое описание) ## Методология (Какие инструменты и подходы использованы и почему) ## Ключевые выводы (2–3 вывода, которые отвечают на бизнес-вопрос) ## Что можно улучшить (Честный раздел — показывает зрелость мышления)
Чек-лист «Портфолио аналитика за 30 дней»
- Создать GitHub-аккаунт и настроить профиль (фото, краткое bio, ссылка на LinkedIn).
- Закоммитить первый учебный SQL-скрипт с комментариями.
- Найти открытый датасет и сформулировать к нему три бизнес-вопроса.
- Написать Python-ноутбук с EDA — минимум 10 осмысленных ячеек с пояснениями.
- Опубликовать первый дашборд в Tableau Public или Looker Studio.
- Оформить README для каждого проекта по шаблону выше.
- Провести мини A/B-анализ на открытом датасете и зафиксировать вывод.
- Попросить куратора или ментора сделать ревью портфолио до выхода на собеседования.
Как оценить окупаемость: модель «время → скилл → собес → оффер»
Окупаемость обучения — это не просто «сколько стоит курс vs сколько буду зарабатывать». Это временна́я модель: когда именно вложенные часы начнут конвертироваться в рыночную стоимость. Давайте сделаем эту модель прозрачной.
Таблица: Модель окупаемости обучения
| Период | Часов/нед | Фокус | Результат к концу периода |
|---|---|---|---|
| Месяц 1–2 | 7–10 | База: SQL, Python-основы, Excel/BI | Уверенный L1–L2, первые скрипты в GitHub |
| Месяц 3–4 | 7–10 | Практика: реальные датасеты, EDA, статистика | 2–3 проекта в портфолио, понимание A/B |
| Месяц 5–6 | 10–12 | Углубление + финальный проект | Полное портфолио, выход на собес-практику |
| Месяц 7–8 | 5–7 | Собеседования + доработка слабых мест | Первые офферы или чёткое понимание gaps |
Несколько важных оговорок, которые стоит держать в голове.
- «Помощь с трудоустройством» — поддержка, не гарантия. Большинство платформ предлагают карьерные консультации, помощь с резюме и базы вакансий партнёров. Это реальная ценность — но она не заменяет собственную активность. Рекрутер из партнёрской базы не даст оффер автоматически: нужно проходить те же технические интервью, что и при самостоятельном поиске.
- Кейсы выпускников — сигнал, не обещание. История «пришёл без опыта, через 8 месяцев получил оффер на 120к» — это реальный случай, но не средняя температура по больнице. Используйте такие истории как подтверждение того, что путь возможен — не как прогноз для себя лично.
- Главный фактор окупаемости — скорость выхода на собес-практику. Наблюдения рынка показывают: люди, которые начинают откликаться на вакансии ещё в процессе обучения — на 5–6 месяце, не дожидаясь «идеальной готовности» — в среднем получают первый оффер быстрее тех, кто ждёт полного завершения курса. Собеседование само по себе — лучший способ понять, каких навыков не хватает.
Окупаемость обучения — это не магия и не лотерея. Это функция от трёх переменных: качества программы, вашей дисциплины в процессе и скорости выхода на практику трудоустройства. Первую переменную вы выбираете сейчас. Две остальные — в ваших руках на протяжении всего пути.
FAQ: что выбрать под ваши ограничения
Если вы дочитали до этого раздела — скорее всего, общая картина уже сложилась, но остались конкретные «а как быть, если…». Именно для этого существует FAQ: не повторить сказанное выше, а закрыть точечные сомнения, которые мешают принять решение. Разберём два самых частых.
Если цель — «быстро на джуна» vs «вырасти и держать высокий уровень»
Это два принципиально разных маршрута — и попытка совместить их в одном подходе обычно не работает. Давайте зафиксируем, что реально означает каждый из них.
Маршрут 1. «Быстро на джуна»
Цель здесь конкретная и измеримая: получить первый оффер на позицию junior data analyst или junior BI-analyst в течение 6–9 месяцев. Это реалистично — при условии, что вы честно понимаете, что «быстро» означает не «легко», а «сфокусированно».
Минимальный стек для первого оффера выглядит так: уверенный SQL на уровне оконных функций, базовый Python с pandas, один BI-инструмент на уровне «могу собрать дашборд самостоятельно», понимание A/B-тестирования на уровне интерпретации результатов. Это не полный стек зрелого аналитика — но это достаточный минимум для прохождения большинства junior-интервью.
- Что здесь важнее всего: дисциплина и портфолио. Работодатель, нанимающий джуна, понимает, что берёт человека без опыта — и смотрит прежде всего на то, умеет ли кандидат учиться и структурировать мышление. Три хорошо оформленных проекта на GitHub с внятными README говорят об этом красноречивее любого сертификата.
- Что можно осознанно «срезать» на этом маршруте: глубокое погружение в ML, продвинутую статистику, оптимизацию SQL-запросов — всё это придёт с опытом на реальной работе. Сейчас важнее ширина базового стека, чем глубина в отдельных темах.
→ Для этого маршрута: GeekBrains даст структурированный вход и поддержку. Karpov.Courses — больший объём практики, который ускорит выход на собес-готовность, если база уже есть.
Маршрут 2. «Вырасти и держать высокий уровень»
Этот маршрут актуален для тех, кто уже работает в смежной роли или прошёл базовое обучение и хочет расти дальше — в сторону middle-аналитика, продуктовой аналитики или позиций на стыке с DS. Здесь горизонт планирования другой: не «первый оффер через 9 месяцев», а «устойчивый профессиональный рост на 2–3 года вперёд».
На этом маршруте важны три вещи: глубина задач (L3–L4 по нашей шкале), самостоятельность в принятии аналитических решений и умение работать с неопределённостью. Именно поэтому здесь имеет смысл смотреть на программы с выраженным «hard»-углублением и высоким объёмом практики — чтобы не просто знать инструменты, а уметь применять их в нестандартных ситуациях.
Высокий уровень в аналитике — это не финальная точка, а режим постоянного обновления. Инструменты меняются, стек расширяется, бизнес-контекст усложняется. Поэтому наравне с программой важно формировать привычку к самостоятельному обучению: читать профессиональные блоги, разбирать чужие кейсы, участвовать в соревнованиях на Kaggle.
→ Для этого маршрута: Karpov.Courses с треком Hard — логичный выбор за счёт глубины практики и наличия ML-минимума.
Если времени 5–7 часов в неделю / если 10–15 часов
Время — самое честное ограничение. Его нельзя компенсировать мотивацией или «буду стараться больше». Давайте зафиксируем две траектории и правила для каждой.
Траектория А: 5–7 часов в неделю
Это рабочий режим — но только при правильной расстановке приоритетов. При таком бюджете каждый час на счету, и тратить его на «пересмотр лекции, которую не до конца понял» — слишком дорого.
- Что нельзя пропускать: практические задания — это единственное, что реально формирует навык; живые разборы сложных тем — их тяжелее восстановить по записи; оформление проектов в GitHub — это инвестиция, которая накапливается.
- Что можно срезать: повторный просмотр понятных лекций — достаточно конспекта; участие во всех активностях комьюнити — выбирайте одну-две наиболее полезных; углублённые темы за рамками основной программы — до них дойдёте позже.
- Главное правило: при 5–7 часах в неделю горизонт обучения увеличивается — и это нормально. Не пытайтесь «уложиться в срок» любой ценой. Лучше пройти программу за 10 месяцев с реальным усвоением, чем за 6 месяцев с ощущением, что «что-то прослушал».
Траектория Б: 10–15 часов в неделю
Комфортный режим для большинства программ. При таком бюджете можно не только проходить основную программу, но и параллельно расширять практику: решать дополнительные задачи на sql-ex.ru или Kaggle, читать профессиональные материалы, участвовать в разборах.
- Что нельзя пропускать: всё то же, что и в траектории А — плюс живые занятия в режиме реального времени, если формат программы это предполагает.
- Что можно добавить сверх программы: один дополнительный проект в портфолио каждые два месяца; участие в Kaggle-соревнованиях начального уровня начиная с третьего-четвёртого месяца; практика собеседований на платформах типа Leetcode или аналогичных SQL-тренажёрах — за два месяца до планируемого выхода на рынок.
- Главное правило: при 10–15 часах в неделю главная угроза — не нехватка времени, а его неэффективное использование. Следите за тем, чтобы соотношение «лекции vs практика» не смещалось в сторону пассивного потребления контента.
Если вы только начинаете осваивать профессию аналитика данных или хотите выбрать подходящий формат обучения, рекомендуем обратить внимание на подборку курсов по системной аналитике. В них есть теоретическая и практическая часть, что помогает быстрее закрепить навыки и подготовиться к реальным задачам.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
115 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
31 марта
|
|
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 апреля
|
|
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
115 отзывов
|
Цена
109 900 ₽
257 760 ₽
Ещё -12% по промокоду
|
От
4 579 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|

HTML Academy vs Яндекс Практикум: где сильнее «с нуля» по вёрстке и фронтенду
Ищете курсы по фронтенду и не понимаете, с чего начать? Где проще освоить HTML и CSS, а где быстрее выйти в профессию? Разбираем ключевые отличия и помогаем выбрать подходящий формат обучения.

Moscow Digital Academy vs Нетология: где лучше учат под работу, а где — под диплом
Moscow Digital Academy или Нетология — что лучше выбрать, если вы хотите выйти в профессию или получить диплом? Разбираем ключевые различия, формат обучения и реальные сценарии выбора без лишнего шума.

Слёрм vs Яндекс Практикум: где полезнее, если цель — инженерная практика, а не «мягкий старт»
Слёрм или Яндекс Практикум DevOps — что выбрать, если уже есть опыт и нужна реальная практика? Разбираем форматы обучения, стек технологий и сценарии, где каждый вариант даёт максимум пользы.

LoftSchool vs Яндекс Практикум: где быстрее собрать портфолио и не застрять на теории
LoftSchool или Яндекс Практикум — что выбрать, если хочется быстрее получить проекты и не утонуть в теории? Разбираем формат обучения, портфолио и реальные сценарии выбора.