Хаос-инжиниринг: когда ошибки помогают развиваться
Представьте себе типичное утро в офисе крупной компании: сотни тысяч транзакций в минуту, миллионы пользователей онлайн, и вдруг — бам! — система падает. Знакомая ситуация, не правда ли? По данным исследований Gartner и IDC, стоимость простоя IT-систем может варьироваться от нескольких тысяч до десятков тысяч долларов в минуту, в зависимости от индустрии и масштаба бизнеса. Например, для финансовых организаций эта цифра может достигать $5,000-10,000 в минуту, для ритейла – $4,000-7,000, а для производственных компаний – $3,000-5,000. А теперь представьте масштаб потерь для таких гигантов как Amazon, где час простоя может обойтись в миллионы долларов. Впечатляет, не так ли?

Именно здесь на сцену выходит хаос-инжиниринг — этакий «контролируемый поджог» в мире IT, если хотите. Это практика, при которой мы намеренно (да-да, совершенно намеренно) создаём сбои в работе систем, чтобы сделать их более надёжными. Звучит как оксюморон? Возможно. Но работает это примерно как прививка для вашей IT-инфраструктуры — малая доза контролируемого хаоса помогает выработать иммунитет к серьёзным проблемам.
В России эту методику уже вовсю применяют такие гиганты как Яндекс, Ozon, Сбер и ВТБ (и, кстати, они не просто так это делают — у них действительно есть, что терять при сбоях). Особенно актуально это для финансовых сервисов, медицинских учреждений, телекома и, конечно же, тех самых интернет-магазинов, где каждая минута простоя равна потерянным заказам и недовольным клиентам.
Можете считать меня параноиком, но когда речь идёт о системах, где на кону стоят миллионы долларов и репутация компании, лучше быть готовым к худшему. И да, я видел достаточно «внезапных» сбоев, чтобы знать — они никогда не бывают действительно внезапными.
Давайте разберём, как это работает на практике (и почему вам, возможно, стоит начать беспокоиться прямо сейчас).
- История хаос-инжиниринга: как пожарный из Amazon изменил мир IT
- Принципы и методы: как (правильно) устроить хаос в вашей системе
- Подходы к тестированию: или как довести систему до истерики (профессионально)
- Четыре этапа хаос-инжиниринга: от теории к практике
- Chaos Monkey: когда обезьяна умнее системного администратора
- Кейсы из практики: когда хаос приносит пользу (да, такое бывает)
- Влияние на бизнес: когда хаос экономит деньги (звучит как оксюморон, но это правда)
- Будущее хаос-инжиниринга: когда хаос становится нормой
История хаос-инжиниринга: как пожарный из Amazon изменил мир IT
А знаете, кто стал одним из ключевых пионеров хаос-инжиниринга в его современном понимании? Бывший пожарный! (Нет, это не начало анекдота). Джесси Роббинс, работая в Amazon в 2003 году, совершил настоящий прорыв, формализовав и адаптировав принципы противопожарных учений к IT-системам через программу GameDay. И знаете что? Этот подход оказался настолько эффективным, что изменил индустрию!
Представьте себе ситуацию: вы пожарный, который внезапно решает, что лучший способ защитить здание от пожара — это… устроить небольшие контролируемые возгорания. Звучит безумно? Возможно. Но именно так родилась программа Game Day в Amazon Cloud.
История получила особенно интересный поворот в 2011 году, когда Netflix решил мигрировать в Amazon Cloud. Ребята из Netflix, вдохновившись идеей Game Day, создали свой инструмент с говорящим названием Chaos Monkey (да-да, буквально «обезьяна хаоса» — потому что, как мы все знаем, нет ничего более хаотичного, чем обезьяна в серверной).
Забавно, но факт: практика, начавшаяся как эксперимент бывшего пожарного, теперь является стандартом для крупнейших технологических компаний мира. Как говорится, из всех безумных идей получаются самые гениальные решения. По крайней мере, в мире IT это работает именно так.
Принципы и методы: как (правильно) устроить хаос в вашей системе
Знаете, что общего между хаос-инжинирингом и походом к стоматологу? В обоих случаях лучше немного поболеть сейчас, чем много потом. Давайте разберем, как это работает на практике (спойлер: без реального удаления зубов).
Основной принцип прост, как пять копеек: вы намеренно ломаете свою систему, чтобы понять, где она может сломаться сама. Звучит как план супер-злодея? Возможно. Но это работает.
Вот основные методы (или, как я их называю, «способы заставить DevOps-инженеров нервничать»):
- Определение «нормального» состояния системы
- Это как определить, что для вашего кота является нормальным поведением, только с серверами
- Фиксируем все метрики, чтобы потом было с чем сравнивать
- Формулировка гипотез
- «А что, если отключить вот этот сервер?»
- «Интересно, что будет, если база данных вдруг решит взять выходной?»
- Проведение экспериментов
- Контролируемое создание проблем (да, именно так)
- Тщательная фиксация всего, что происходит
- Автоматизация процесса
- Потому что делать это вручную — все равно что пытаться научить кота плавать: можно, но зачем?
А теперь самое интересное: все это делается с помощью специальных инструментов, самый известный из которых — уже упомянутый Chaos Monkey от Netflix. Представьте себе цифровую обезьяну, которая ходит по вашей инфраструктуре и случайным образом выключает серверы. Звучит пугающе? Так и должно быть!
И помните: хороший хаос-инжиниринг — это как хороший анекдот: если нужно объяснять, что-то пошло не так.
Подходы к тестированию: или как довести систему до истерики (профессионально)
Давайте поговорим о том, как именно проводятся эксперименты в хаос-инжиниринге. Представьте, что вы — врач, который намеренно создает стрессовые ситуации для пациента, чтобы проверить работу сердца. Только в нашем случае пациент — это ваша IT-система, а стресс-тест может быть весьма… креативным.
Вот основные типы «издевательств» над системой (простите, хотел сказать «тестов»):
- Сетевые сбои
- Имитация потери соединения (классика жанра)
- Высокая задержка (когда ваш запрос решил прогуляться вокруг земного шара)
- Потеря пакетов (спойлер: они не находятся)
- Ресурсные атаки
- Искусственная нагрузка на CPU (заставляем процессор попотеть)
- Заполнение диска (потому что все любят играть в «найди свободное место»)
- Исчерпание памяти (RAM решила уйти в отпуск)
- Состояния отказа
- Внезапная перезагрузка сервера (сюрприз!)
- Отключение критических сервисов (просто чтобы посмотреть, что будет)
- Имитация сбоев в базе данных (потому что кто не любит небольшой database drama?)
И помните: главное правило хаос-инжиниринга — всегда иметь план отступления. Потому что иногда хаос побеждает даже самых подготовленных (и тогда вам понадобится много кофе и умение быстро печатать).
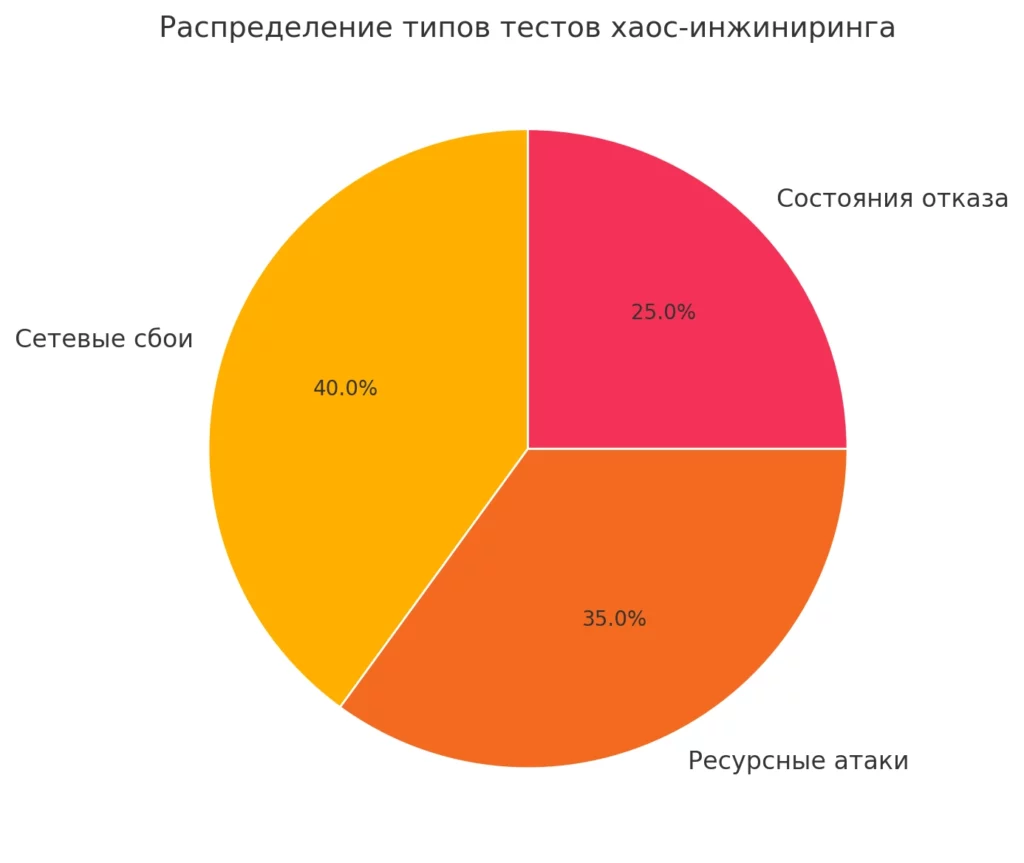
На круговой диаграмме показано распределение основных типов тестов хаос-инжиниринга: сетевые сбои занимают 40%, ресурсные атаки — 35%, а состояния отказа — 25%
Четыре этапа хаос-инжиниринга: от теории к практике
Знаете, что общего между приготовлением идеального стейка и хаос-инжинирингом? В обоих случаях успех зависит от четкого соблюдения этапов и постоянного контроля. Только вместо термометра для мяса мы используем мониторинг, а вместо степени прожарки следим за отказоустойчивостью системы.
Давайте разберем каждый этап подробно (и нет, это не очередной скучный список из документации):
- Определение устойчивого состояния
- Начинаем с тщательного мониторинга системы в нормальном режиме
- Фиксируем все ключевые метрики: латентность, пропускную способность, процент ошибок
- Создаем базовый профиль производительности (своего рода «медицинскую карту» вашей системы)
- Совет от бывалых: используйте не менее двух недель наблюдений, чтобы поймать все типичные паттерны нагрузки
- Формирование гипотез
- Определяем «радиус взрыва» — масштаб потенциальных проблем
- Прописываем ожидаемое поведение системы при сбоях
- Устанавливаем границы допустимых отклонений
- Важно: гипотезы должны быть конкретными, например: «При отказе 30% инстансов система сохранит 95% производительности»
- Проведение экспериментов
- Начинаем с малого (никто не начинает с отключения всего дата-центра)
- Постепенно увеличиваем сложность тестов
- Тщательно документируем каждый шаг
- Золотое правило: всегда имейте кнопку «отмена» под рукой!
- Автоматизация
- Создаем скрипты для регулярного выполнения успешных экспериментов
- Интегрируем тесты в CI/CD pipeline
- Настраиваем автоматический откат при превышении пороговых значений
- Лайфхак: начните с автоматизации самых простых тестов и постепенно усложняйте их
И теперь про наш любимый инструмент — Chaos Monkey. Помните, я упоминал его раньше? Давайте копнем глубже.
Chaos Monkey: когда обезьяна умнее системного администратора
Netflix не просто так назвал свой инструмент «Обезьяной Хаоса». Представьте себе цифровую обезьяну, которая с хирургической точностью и абсолютно бесстрастно выводит из строя части вашей инфраструктуры. Звучит пугающе? Так и должно быть!
Вот как это работает на практике:
- Базовые возможности
- Случайное отключение инстансов (классика жанра)
- Внесение задержек в сетевые запросы (потому что иногда медленнее = интереснее)
- Симуляция отказов целых регионов AWS (для тех, кто любит масштабные катастрофы)
- Настройка и конфигурация
Кейсы из практики: когда хаос приносит пользу (да, такое бывает)
Знаете, как говорят: «На чужих ошибках учатся умные, на своих — все остальные». Давайте посмотрим на опыт компаний, которые решили учиться на контролируемых ошибках (очень умно, надо признать).
В России хаос-инжиниринг уже вовсю применяют наши технологические гиганты. И нет, это не потому, что им нечем заняться:
- Яндекс
- Применяет хаос-тестирование для проверки отказоустойчивости своих сервисов
- Спойлер: когда у вас миллионы пользователей, лучше знать заранее, где может что-то пойти не так
- Сбер
- Использует практику для тестирования банковских систем
- Потому что «упс, система упала» в банковском приложении — это не то сообщение, которое хочет видеть клиент
- Ozon
- Тестирует устойчивость платформы электронной коммерции
- Особенно актуально во время «черной пятницы» (когда все действительно может пойти по-черному)
А вот интересный кейс из недавнего: один крупный банк (назовем его «Точка» — потому что это действительно Точка) столкнулся с 7-часовым сбоем из-за проблем в центре обработки данных. Представляете, сколько нервных клеток это стоило и клиентам, и сотрудникам? А ведь можно было предотвратить…
Особенно забавно (или грустно, это как посмотреть) то, что большинство компаний начинают задумываться о хаос-инжиниринге только после серьезного инцидента. Как говорится, пока гром не грянет, DevOps не перекрестится.
И да, если вы думаете, что ваша система слишком маленькая для таких экспериментов — подумайте еще раз. Потому что когда система упадет в самый неподходящий момент (а она упадет, поверьте моему опыту), вы пожалеете, что не устроили ей небольшой хаос заранее.
Влияние на бизнес: когда хаос экономит деньги (звучит как оксюморон, но это правда)
Давайте поговорим о деньгах — любимой теме всех руководителей. И тут есть о чем поговорить: одна минута простоя высоконагруженной системы обходится в $7,200-9,000 (и нет, это не опечатка). А теперь представьте, что ваша система лежит не минуту, а час. Или день. Чувствуете, как бюджет улетает в трубу?
Вот простая математика для скептиков:
- Без хаос-инжиниринга:
- Неожиданный сбой (потому что они всегда неожиданные)
- Паника команды (бесценно)
- Экстренное собрание 5-10 человек (помножьте на их часовые ставки)
- Срочные исправления (обычно неоптимальные)
- Репутационные потери (не поддаются исчислению)
- С хаос-инжинирингом:
- Контролируемые эксперименты (когда вы сами выбираете время)
- Работа 1-2 инженеров (вместо целой армии)
- Спокойное планирование решений
- Сохранение репутации (бесценно)
И знаете что самое интересное? Инвестиции в хаос-инжиниринг обычно в 2-3 раза меньше, чем стоимость одного серьезного сбоя. Это как страховка: платишь немного сейчас, чтобы не платить огромную сумму потом.
А еще это как прививка от гриппа: может быть немного неприятно сейчас, зато потом спасибо скажете. И да, я продолжу использовать медицинские метафоры, потому что они отлично работают!
Будущее хаос-инжиниринга: когда хаос становится нормой
Знаете, что общего между хаос-инжинирингом и облачными технологиями? Оба развиваются так быстро, что пока вы читаете эту статью, возможно, появилось что-то новое (и да, это не преувеличение).
По данным TAdviser (между прочим, весьма уважаемые ребята в области аналитики), спрос на облачные технологии в России растет на 40-44% ежегодно. А знаете, что это значит? Правильно — все больше систем будет нуждаться в хаос-инжиниринге. Потому что облако без хаос-тестирования — это как поход в джунгли без карты: теоретически возможно, но зачем рисковать?
Что нас ждет в ближайшем будущем:
- Автоматизация хаоса (звучит как название фильма-катастрофы, но на самом деле это хорошо)
- AI-powered системы для предсказания потенциальных сбоев
- Умные алгоритмы для автоматического восстановления
- Интеграция с DevOps
- Хаос-тестирование как обязательная часть CI/CD pipeline
- Потому что «работает на моем компьютере» больше не прокатит
- Новые инструменты
- Более точные симуляторы сбоев
- Лучшая визуализация результатов (потому что даже хаос должен быть красивым)
И знаете что? Я почти уверен, что через пару лет фраза «А вы проводите хаос-тестирование?» станет такой же обычной, как «А у вас есть бэкапы?». Потому что в мире, где каждая минута простоя стоит как подержанный автомобиль, лучше быть готовым к худшему.
И если после прочтения этой статьи вы загорелись идеей внедрить хаос-инжиниринг в своей компании — отлично! Но помните, что для эффективного применения этих практик нужна солидная база знаний системного администратора. Не знаете, с чего начать? На KursHub собрана подборка лучших курсов по системному администрированию, где вы найдете программы разного уровня сложности — от базовых основ до продвинутых практик. Инвестиция в знания сейчас поможет предотвратить критические сбои в будущем!
P.S. А знаете, что самое забавное? Пока вы читали эту статью, как минимум одна крупная система где-то в мире упала. Надеюсь, не ваша!

Собеседование проджект менеджера: актуальные вопросы и темы 2026 года
Собеседование на проджект менеджера всё чаще строятся вокруг реальных кейсов, срывов сроков, конфликтов и AI-сценариев. Как отвечать уверенно, какие артефакты подготовить и где кандидаты чаще всего теряют оффер? Разбираем кратко, по делу и с практическими подсказками.

CRM-маркетолог в 2026: почему бизнесу нужны специалисты по удержанию, а не только по рекламе
CRM-маркетолог — это уже не просто специалист по рассылкам, а человек, который помогает бизнесу возвращать клиентов и увеличивать LTV. Разберёмся, какие задачи он решает, какие метрики отслеживает и почему удержание становится важнее хаотичной закупки трафика.

Revenue Operations: почему компании ищут людей, которые связывают продажи, маркетинг и аналитику
Revenue Operations — направление для тех, кто хочет работать на стыке продаж, маркетинга, CRM и аналитики. Разберёмся, кому подходит RevOps, какие навыки нужны на старте и с каких проектов лучше начать.

Product Analyst с нуля: почему SQL и метрики могут быть выгоднее «общего курса аналитика»
Product Analyst с нуля — это не только про SQL и красивые графики. Разбираемся, какие навыки действительно нужны на старте, чем продуктовая аналитика отличается от общего анализа данных и как выбрать обучение без лишних модулей.