Полное руководство по хешированию в Python: алгоритмы, примеры, безопасность, пароли

Хеширование — это процесс преобразования входных данных произвольной длины в строку фиксированной длины с использованием определённого алгоритма. Полученная строка называется хешем или дайджестом. Можно сказать, что это своеобразный «отпечаток пальца» файла: он весит практически ничего, но является уникальным для каждого набора данных.
Скриншот онлайн-генератора хешей (MD5 / SHA-256) с одним и тем же текстом. Показывает, как один и тот же текст превращается в строку фиксированной длины.
В Python хеширование играет фундаментальную роль во множестве областей: от быстрого поиска в словарях и множествах до надёжной защиты конфиденциальных данных. Рассмотрим ключевые свойства, которые делают этот процесс столь незаменимым инструментом в арсенале разработчика.
Качественная функция должна соответствовать нескольким критическим требованиям: она должна быть детерминированной, устойчивой к коллизиям, обладать свойством необратимости и демонстрировать лавинный эффект. Давайте разберёмся, что означает каждое из этих свойств и почему они важны для практической разработки.
- Основные свойства хеш-функций
- Что такое коллизия и почему она возникает
- Где хеширование используется в Python на практике
- Встроенная функция hash() в Python: как работает и когда использовать
- Модуль hashlib: криптографическое хеширование в Python
- HMAC: когда нужен и как работает
- Хеширование паролей: как делать безопасно
- Как выбрать подходящий тип хеширования для задачи
- Частые вопросы (FAQ)
- Заключение
- Рекомендуем посмотреть курсы по Python
Основные свойства хеш-функций
Чтобы алгоритм был действительно полезным и надёжным, он должен обладать несколькими ключевыми характеристиками:
- Детерминированность. Одинаковые входные данные всегда должны давать одинаковый результат. Это фундаментальное свойство позволяет использовать хеширование для проверки целостности данных и организации эффективного поиска в структурах данных. Если бы функция возвращала разные результаты для одних и тех же данных, её практическая ценность была бы нулевой.
- Устойчивость к коллизиям. Коллизия происходит, когда разные входные данные дают одинаковый результат. Хорошая функция минимизирует вероятность таких совпадений. В идеальном мире каждый уникальный набор данных должен давать уникальное значение, хотя на практике это недостижимо из-за ограниченности пространства выходных значений.
- Необратимость. Процесс получения дайджеста односторонний — из хешированных данных нельзя восстановить исходную информацию. Это критически важно для безопасности: даже зная отпечаток пароля, злоумышленник не сможет автоматически узнать сам пароль.
- Лавинный эффект. Даже минимальное изменение входных данных — изменение одного бита — должно радикально менять выходной результат. Это свойство гарантирует, что похожие данные будут иметь совершенно разные отпечатки, что особенно важно для обнаружения даже незначительных изменений в файлах или сообщениях.
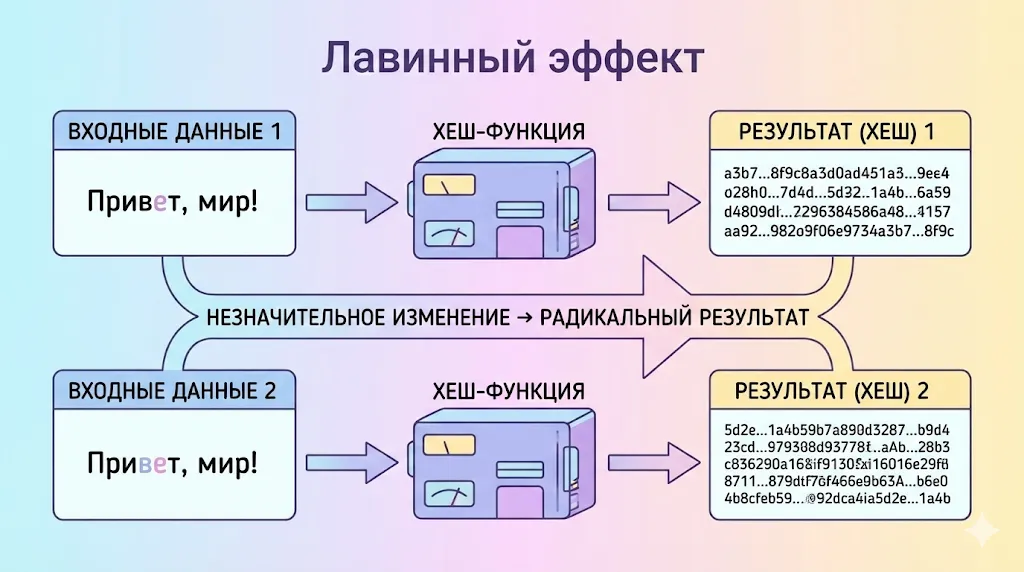
Иллюстрация показывает одно из важнейших свойств криптографических хеш-функций — лавинный эффект. Даже минимальное изменение во входных данных (например, одна буква) приводит к кардинальному и непредсказуемому изменению выходного хеша, что делает невозможным восстановление исходных данных по их отпечатку.
Что такое коллизия и почему она возникает
Коллизия возникает, когда функция возвращает одинаковое значение для разных входных данных. Представьте ситуацию: у вас есть два различных файла, но их дайджесты совпадают. Это и есть коллизия.
Почему это происходит? Дело в математике. Входные данные могут быть бесконечно разнообразными и любой длины, а выходное значение всегда имеет фиксированную длину. Например, SHA-256 всегда возвращает 256-битное значение, независимо от того, хешируете ли вы слово «Python» или целую книгу. Получается, что бесконечное множество возможных входных данных должно уместиться в конечное множество выходных значений — коллизии неизбежны по принципу Дирихле.
Однако в криптографически стойких алгоритмах вероятность случайной коллизии настолько мала, что её можно считать практически нулевой. Для SHA-256, к примеру, найти коллизию вычислительно настолько сложно, что на это потребуются миллионы лет работы современных компьютеров. В некриптографических функциях, используемых в структурах данных Python, коллизии встречаются чаще, но система умеет с ними справляться.
Где хеширование используется в Python на практике
Хеширование в Python — это не абстрактная теоретическая концепция, а мощный инструмент, решающий реальные задачи. От оптимизации структур данных до обеспечения безопасности конфиденциальной информации — правильно применённые алгоритмы трансформируют подход к разработке.
Мы рассмотрим четыре ключевых сценария использования, с которыми сталкивается практически каждый Python-разработчик. Понимание этих применений не только расширит ваш технический арсенал, но и поможет выбирать оптимальные решения для конкретных задач. Давайте разберём каждый случай подробнее.
Хеши в структуре данных: dict, set, frozenset
Словари (dict) и множества (set, frozenset) в Python работают на основе хеш-таблиц, что обеспечивает им феноменальную скорость поиска — O(1) в среднем случае. Когда вы добавляете элемент в словарь или множество, Python вычисляет его хеш и использует это значение для определения позиции в памяти.
Благодаря таким отпечаткам интерпретатор устанавливает номера ячеек в памяти. Когда у каждого элемента есть номер, не нужно перебирать весь набор — достаточно посмотреть на номер ячейки. Даже если hash() создаёт коллизии и программа может попытаться использовать уже занятую ячейку, работа с хешами остаётся быстрее простого перебора элементов. сравнение скорости поиска в списке и словаре.
Эта диаграмма наглядно демонстрирует ключевое преимущество хеш-таблиц (словарей) — скорость поиска. В то время как время поиска в списке растет пропорционально количеству элементов (O(n)), в словаре оно остается практически мгновенным и постоянным (O(1)) независимо от объема данных.

Эта диаграмма наглядно демонстрирует ключевое преимущество хеш-таблиц (словарей) — скорость поиска. В то время как время поиска в списке растет пропорционально количеству элементов (O(n)), в словаре оно остается практически мгновенным и постоянным (O(1)) независимо от объема данных.
Критическое требование: только неизменяемые (иммутабельные) объекты могут быть хешируемыми. Почему? Если бы объект мог изменяться после добавления в словарь, его отпечаток изменился бы, и Python не смог бы найти его в структуре данных. Поэтому списки нельзя использовать как ключи словаря, а кортежи — можно.
Проверка целостности данных
Хеширование позволяет эффективно контролировать, не были ли изменены файлы или данные в процессе передачи или хранения. Принцип прост: вы вычисляете контрольную сумму файла до передачи, а получатель вычисляет её после получения. Если значения совпадают — данные не повреждены и не изменены.
Этот механизм активно применяется в системах контроля версий, таких как Git, где каждый коммит идентифицируется по дайджесту содержимого. Изменение даже одного символа в коде приведёт к совершенно другому результату, что позволяет мгновенно обнаруживать любые модификации.
В сфере распространения программного обеспечения разработчики часто публикуют контрольные суммы дистрибутивов. Например, загружая образ операционной системы, вы можете проверить его SHA-256 отпечаток и убедиться, что файл не был подменён или повреждён при скачивании. Это особенно критично для обновлений, где целостность данных напрямую влияет на безопасность и стабильность системы.
Согласно нашим наблюдениям, многие разработчики недооценивают важность проверки целостности данных до тех пор, пока не столкнутся с реальной проблемой повреждённых файлов в production-окружении.
Создание уникальных идентификаторов
Хеширование часто используется для генерации уникальных идентификаторов на основе содержимого данных. Вместо того чтобы создавать случайные ID, можно вычислить дайджест от значимых атрибутов объекта — и получить стабильный, воспроизводимый идентификатор.
Такой подход особенно полезен при работе с большими объёмами данных: если два объекта имеют идентичное содержимое, они получат одинаковый ID, что позволяет легко обнаруживать дубликаты. В системах обработки миллионов транзакций ежедневно быстрая проверка на дубликаты через контрольную сумму может значительно повысить производительность.
Кроме того, такие идентификаторы находят применение в кешировании, где ключом кеша становится отпечаток параметров запроса. Это гарантирует, что одинаковые запросы будут использовать один и тот же кешированный результат, избегая избыточных вычислений.
Хеширование в безопасности и криптографии
В области безопасности хеширование играет центральную роль. Криптографические алгоритмы, такие как SHA-256 или SHA-3, используются для защиты паролей, создания цифровых подписей и обеспечения аутентификации сообщений.
Когда пользователь создаёт пароль, система не должна хранить его в открытом виде — только дайджест. При попытке входа система хеширует введённый пароль и сравнивает результат с сохранённым значением. Поскольку отпечатки уникальны и необратимы, даже при утечке базы данных злоумышленник не получит доступа к исходным паролям.
В криптографии используется также механизм HMAC (Hash-based Message Authentication Code) — хеширование с секретным ключом. Это позволяет проверять подлинность сообщений в API и платёжных системах, где необходимо убедиться, что данные действительно пришли от легитимного отправителя и не были изменены в процессе передачи.
Возникает вопрос: как правовая система должна обеспечивать баланс между безопасностью данных и требованиями доступа правоохранительных органов, когда криптографическое хеширование делает восстановление исходной информации практически невозможным?
Встроенная функция hash() в Python: как работает и когда использовать
Python предоставляет встроенную функцию hash(), которая возвращает целочисленное значение для любого хешируемого объекта. Это базовый инструмент, который интерпретатор использует внутренне для работы со словарями и множествами, но он доступен и разработчикам для решения собственных задач.
Функция hash() работает быстро и удобна для простых операций, таких как поиск элементов в коллекциях. Однако у неё есть важные ограничения: результат непостоянен между запусками программы и может различаться на разных машинах. Это делает hash() непригодной для задач, требующих стабильности результата — например, для проверки целостности файлов или криптографической защиты.
Ключевое ограничение заключается в том, что хешировать можно только неизменяемые (иммутабельные) объекты. Попытка вычислить отпечаток списка или словаря приведёт к ошибке TypeError. Это критично для сохранения целостности структур данных, основанных на хешах: если бы объект мог изменяться после добавления, Python не смог бы его найти по первоначально вычисленному значению.
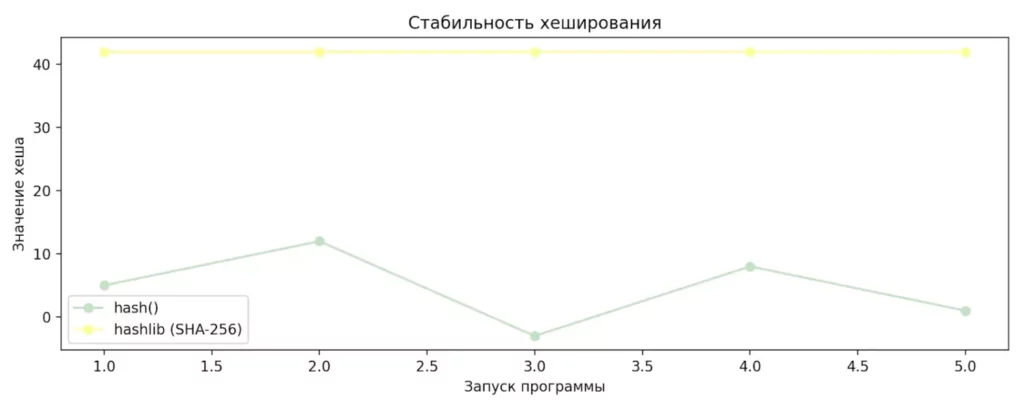
Иллюстрация сравнивает поведение встроенной функции hash() и криптографического хеширования из hashlib. Значения hash() меняются между запусками программы, тогда как SHA-256 всегда возвращает один и тот же результат. Это наглядно показывает, почему hash() нельзя использовать для безопасности.
Давайте рассмотрим, как hash() ведёт себя с различными типами данных и почему её поведение отличается от криптографических алгоритмов.
Особенности hash() для разных типов данных
Поведение встроенной функции hash() зависит от типа данных, с которым она работает. Рассмотрим основные случаи:
- Числа. Для целых чисел результат обычно равен самому числу (в определённом диапазоне). Для чисел с плавающей точкой Python вычисляет значение таким образом, чтобы равные численно величины давали одинаковый результат — например, hash(42) и hash(42.0) вернут одинаковое значение.
- Строки. Отпечаток строки вычисляется на основе её содержимого, но между разными запусками интерпретатора результат будет отличаться из-за механизма рандомизации. Это защитная мера против определённых типов атак.
- Кортежи. Кортеж хешируем только в том случае, если все его элементы также хешируемы. Кортеж, содержащий список, вызовет TypeError при попытке хеширования. Отпечаток кортежа вычисляется на основе отпечатков всех его элементов.
- Неизменяемость vs изменяемость. Изменяемые типы — списки, словари, множества — принципиально нехешируемы. Если бы Python позволял их хешировать, изменение содержимого привело бы к изменению результата, что нарушило бы работу словарей и множеств.
Пример кода:
# Хеширование разных типов
print(hash(42)) # Целое число
print(hash(3.14)) # Число с плавающей точкой
print(hash("Python")) # Строка
print(hash((1, 2, 3))) # Кортеж (неизменяемый)
# Ошибка: нельзя хешировать изменяемые объекты
try:
print(hash([1, 2, 3])) # Список (изменяемый)
except TypeError as e:
print(f"Ошибка: {e}")
Почему значение hash() меняется между запусками интерпретатора
Если вы запустите один и тот же код дважды, отпечаток строки будет отличаться при каждом запуске Python. Это не ошибка, а преднамеренная функция безопасности, называемая hash randomization.
Начиная с Python 3.3, интерпретатор добавляет случайную «соль» (salt) к вычислениям для строк и байтов при каждом запуске. Эта мера защищает от специфического типа атак — алгоритмической сложности (algorithmic complexity attacks), когда злоумышленник специально подбирает данные, создающие множество коллизий, чтобы замедлить работу словарей и множеств до неприемлемого уровня.
Рандомизация делает такие атаки практически невозможными, поскольку атакующий не может предсказать, какие именно данные вызовут коллизии в конкретном запуске программы. Однако это означает, что hash() категорически непригодна для задач, требующих постоянства результата между сеансами — проверки целостности файлов, создания стабильных идентификаторов или любых форм персистентного хранения.
Для таких сценариев необходимо использовать криптографические алгоритмы из модуля hashlib, которые всегда дают одинаковый результат на любой машине и при любом запуске.
Модуль hashlib: криптографическое хеширование в Python
Для задач, требующих стабильных и криптографически стойких результатов, Python предоставляет модуль hashlib. В отличие от встроенной функции hash(), алгоритмы из hashlib всегда возвращают одинаковое значение для одних и тех же данных — независимо от машины, операционной системы или момента запуска программы.
Модуль hashlib поддерживает множество алгоритмов: от устаревших MD5 и SHA-1 до современных SHA-256, SHA-512 и SHA-3. Каждый алгоритм имеет свои характеристики по скорости, длине выходного значения и уровню безопасности. Выбор конкретного алгоритма зависит от требований вашей задачи: для проверки целостности файлов достаточно SHA-256, для хранения паролей требуются специализированные медленные алгоритмы вроде bcrypt или Argon2.
Работа с hashlib достаточно проста: вы создаёте объект алгоритма, передаёте ему данные методом update(), а затем получаете результат через hexdigest() в виде шестнадцатеричной строки или через digest() в виде байтов. Возможность инкрементального обновления особенно полезна при работе с большими файлами — не нужно загружать весь файл в память, можно обрабатывать его частями.
Рассмотрим подробнее популярные алгоритмы и их практическое применение.
Популярные алгоритмы: MD5, SHA-1, SHA-256, SHA-3
Каждый алгоритм хеширования представляет собой компромисс между безопасностью, скоростью и длиной выходного значения. Сравним основные характеристики популярных вариантов:
| Алгоритм | Длина (бит) | Уровень безопасности | Скорость | Рекомендации по использованию |
| MD5 | 128 | Небезопасен | Очень высокая | Только для некриптографических задач (контрольные суммы в не-критичных системах) |
| SHA-1 | 160 | Компрометирован | Высокая | Устаревший, не использовать для новых проектов |
| SHA-256 | 256 | Безопасен | Средняя | Универсальный выбор для большинства задач |
| SHA-512 | 512 | Очень безопасен | Средняя | Для повышенных требований безопасности |
| SHA-3 | 224-512 (настраиваемая) | Очень безопасен | Средняя | Современный стандарт, альтернатива SHA-2 |
- MD5 когда-то был стандартом, но сейчас считается небезопасным из-за возможности создания коллизий. Исследователи продемонстрировали практические атаки, позволяющие создавать разные файлы с одинаковым MD5-отпечатком. Используйте его только для быстрых проверок контрольных сумм в некритичных сценариях.
- SHA-1 также компрометирован — в 2017 году Google продемонстрировал реальную коллизию. Крупные платформы вроде GitHub прекратили его использование для обеспечения целостности кода.
- SHA-256 из семейства SHA-2 остаётся надёжным выбором для большинства применений: от проверки целостности данных до блокчейн-технологий. Вероятность коллизии настолько мала, что её можно считать практически нулевой.
- SHA-3 — относительно новый стандарт, основанный на принципиально другой математической конструкции. Он не заменяет SHA-2, а дополняет его как альтернативный безопасный вариант.
Примеры использования hashlib (MD5, SHA-256)
Работа с модулем hashlib интуитивна и следует единообразному паттерну для всех алгоритмов. Рассмотрим практические примеры:
import hashlib
# Хеширование с помощью MD5
text = "Python Hash"
md5_hash = hashlib.md5(text.encode('utf-8')).hexdigest()
print(f"MD5: {md5_hash}")
# Вывод: MD5: 8f14e45fceea167a5a36dedd4bea2543
# Хеширование с помощью SHA-256
sha256_hash = hashlib.sha256(text.encode('utf-8')).hexdigest()
print(f"SHA-256: {sha256_hash}")
# Вывод: SHA-256: 2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824
Обратите внимание: методу необходимо передавать байты, поэтому строки нужно кодировать через .encode(‘utf-8’). Метод hexdigest() возвращает результат в виде шестнадцатеричной строки, удобной для чтения и хранения. Если нужны сырые байты, используйте digest().
Для более гибкой работы можно использовать инкрементальное хеширование:
# Поэтапное добавление данных hasher = hashlib.sha256() hasher.update(b"Python ") hasher.update(b"Hash") print(hasher.hexdigest()) # Результат идентичен предыдущему примеру
Этот подход особенно полезен, когда данные поступают частями или обрабатываются потоком.
Хеширование больших файлов по частям
При работе с большими файлами загрузка всего содержимого в память неэффективна и может привести к её исчерпанию. Инкрементальное хеширование решает эту проблему — файл читается и обрабатывается блоками фиксированного размера.
import hashlib
def hash_file(filename, algorithm='sha256', chunk_size=8192):
"""Вычисляет контрольную сумму файла, читая его частями"""
hasher = hashlib.new(algorithm)
with open(filename, 'rb') as f:
while chunk := f.read(chunk_size):
hasher.update(chunk)
return hasher.hexdigest()
# Пример использования
file_hash = hash_file('large_dataset.csv')
print(f"SHA-256 файла: {file_hash}")
В этом примере файл читается блоками по 8 КБ — достаточно маленькими, чтобы не перегружать память, и достаточно большими для эффективной работы с диском. Метод update() можно вызывать многократно, и каждый вызов добавляет новую порцию данных к вычисляемому отпечатку.
Такой подход позволяет обрабатывать файлы размером в гигабайты, используя лишь несколько килобайт оперативной памяти. Это критично для систем, работающих с большими объёмами данных — видеофайлами, архивами, дампами баз данных. Согласно нашим наблюдениям, правильная реализация инкрементального хеширования может стать разницей между работающей системой и той, которая падает с ошибкой OutOfMemory.
HMAC: когда нужен и как работает
HMAC (Hash-based Message Authentication Code) — это механизм, объединяющий хеширование с секретным ключом для создания кода аутентификации сообщения. В отличие от обычного дайджеста, HMAC требует знания секретного ключа для генерации и проверки подписи, что делает его значительно более защищённым.
Зачем это нужно? Представьте, что вы отправляете данные через API. Обычная контрольная сумма позволяет проверить целостность данных, но не их подлинность — злоумышленник может изменить данные и пересчитать отпечаток. С HMAC это невозможно: без знания секретного ключа нельзя создать корректную подпись для изменённых данных.
HMAC активно применяется в платёжных системах, протоколах аутентификации и API от сторонних сервисов. Когда вы интегрируетесь с внешним API, часто требуется подписывать запросы с помощью HMAC — сервис проверяет подпись своим ключом и убеждается, что запрос действительно пришёл от легитимного клиента и не был изменён в процессе передачи.
Критически важно использовать функцию hmac.compare_digest() для проверки подписей вместо обычного сравнения строк. Эта функция выполняет сравнение за постоянное время, защищая от timing attacks — атак, при которых злоумышленник анализирует время ответа для подбора корректной подписи.
Пример HMAC в Python (SHA-256 + ключ)
Реализация HMAC в Python проста благодаря встроенному модулю hmac. Рассмотрим практический пример создания и проверки подписи:
import hmac
import hashlib
# Секретный ключ и данные (должны быть в байтах)
secret_key = b"my_secret_key"
message = b"Important data to sign"
# Создание HMAC-подписи с использованием SHA-256
signature = hmac.new(secret_key, message, hashlib.sha256).hexdigest()
print(f"HMAC подпись: {signature}")
# Проверка подписи (безопасное сравнение)
def verify_signature(key, msg, received_signature):
expected_signature = hmac.new(key, msg, hashlib.sha256).hexdigest()
return hmac.compare_digest(expected_signature, received_signature)
# Проверка корректной подписи
is_valid = verify_signature(secret_key, message, signature)
print(f"Подпись корректна: {is_valid}") # True
# Проверка изменённых данных
tampered_message = b"Modified data"
is_valid = verify_signature(secret_key, tampered_message, signature)
print(f"Изменённые данные: {is_valid}") # False
Обратите внимание на использование hmac.compare_digest() — эта функция защищает от атак по времени, выполняя сравнение за постоянное время независимо от того, в каком месте строки обнаружено различие. Обычное сравнение через == останавливается на первом несовпадающем символе, что позволяет атакующему постепенно подбирать правильную подпись, анализируя время ответа.
Хеширование паролей: как делать безопасно
Хеширование паролей — это не просто применение SHA-256 к строке. Это критически важная область, где неправильный подход может привести к катастрофическим последствиям для безопасности пользовательских данных. К сожалению, многие разработчики до сих пор совершают фундаментальные ошибки, храня пароли в виде обычных дайджестов.
Почему простое хеширование недостаточно? Современные видеокарты способны вычислять миллиарды отпечатков в секунду. Если злоумышленник получит доступ к базе данных с SHA-256 дайджестами паролей, он сможет проверить миллионы наиболее популярных паролей за считанные минуты. Поскольку результаты детерминированы, одинаковые пароли дают одинаковые отпечатки — атакующий автоматически узнает пароль при совпадении.
Профессиональное хеширование паролей требует трёх компонентов: медленного алгоритма, уникальной соли для каждого пароля и достаточного количества итераций. Медленные алгоритмы, такие как bcrypt, Argon2 или scrypt, специально разработаны так, чтобы их вычисление занимало значительное время — это делает массовый подбор практически невозможным. Соль — случайные данные, добавляемые к паролю перед хешированием — гарантирует, что даже одинаковые пароли будут иметь разные результаты.
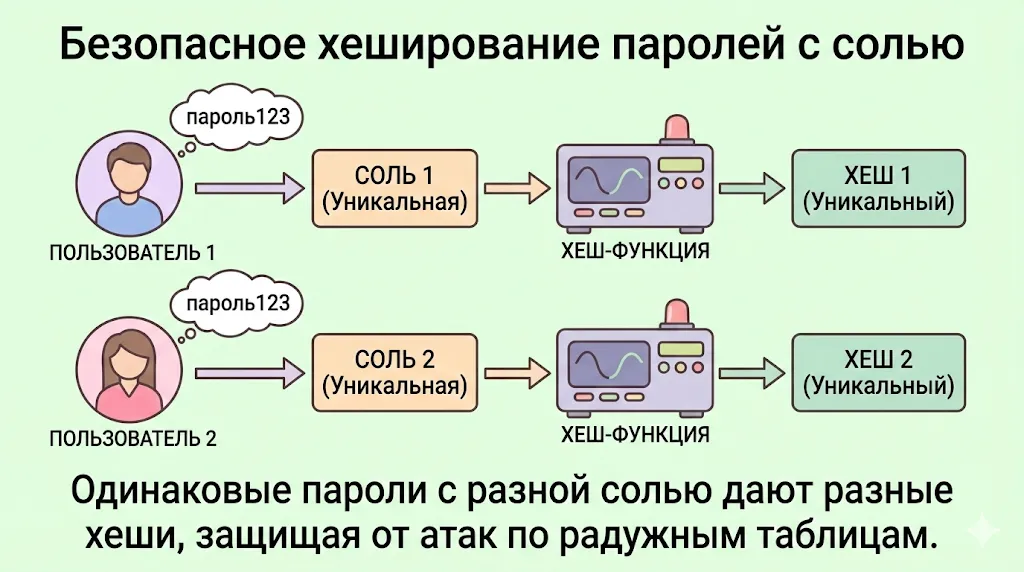
Данная иллюстрация показывает, почему для безопасного хранения паролей необходимо использовать «соль». Добавление уникальной случайной строки к каждому паролю перед хешированием гарантирует, что даже одинаковые пароли будут иметь разные хеши, защищая базу данных от атак с использованием радужных таблиц.
Давайте разберём, почему классические алгоритмы не подходят для паролей и как правильно использовать специализированные решения.
Почему MD5 и SHA-1 не подходят для хранения паролей
MD5 и SHA-1 были разработаны для быстрого вычисления дайджестов, что делает их отличным выбором для проверки целостности файлов, но катастрофически плохим — для защиты паролей. Скорость здесь становится уязвимостью, а не преимуществом.
Современные GPU способны вычислять миллиарды MD5-отпечатков в секунду. Если злоумышленник украдёт базу данных с MD5-дайджестами паролей, он сможет проверить все комбинации из словаря самых популярных паролей за минуты. Алгоритм SHA-256, хотя и более стойкий к коллизиям, страдает от той же проблемы — он слишком быстрый.
Кроме того, детерминированная природа этих функций создаёт дополнительную проблему: одинаковые пароли дают одинаковые результаты. Даже если вы используете SHA-256, атакующий может создать таблицу отпечатков популярных паролей (rainbow table) и мгновенно идентифицировать все учётные записи, использующие слабые пароли.
Значения, полученные таким образом, всегда одинаковые, поэтому при совпадении злоумышленник автоматически узнаёт и сам пароль. Для защиты паролей необходимы специализированные медленные алгоритмы с автоматическим добавлением уникальной соли.
Использование bcrypt в Python
Один из самых популярных и проверенных временем алгоритмов для хранения паролей — bcrypt. Перед использованием его необходимо установить через терминал командой pip install bcrypt.
Ключевая особенность bcrypt заключается в том, что к каждому паролю перед вычислением добавляется уникальная соль — случайные данные. Это означает, что даже одинаковые пароли будут иметь разные результаты, что делает невозможным использование предварительно вычисленных таблиц (rainbow tables). Кроме того, алгоритм работает медленно и настраивается так, что каждому паролю требуется создавать свою таблицу при попытке подбора.
import bcrypt
# Генерация соли и хеширование пароля
password = b"secret_password_123"
hashed = bcrypt.hashpw(password, bcrypt.gensalt())
print(f"Хеш: {hashed}")
# Проверка пароля
input_password = b"secret_password_123"
if bcrypt.checkpw(input_password, hashed):
print("Пароль верный!")
else:
print("Пароль неверный!")
# Проверка неправильного пароля
wrong_password = b"wrong_password"
if bcrypt.checkpw(wrong_password, hashed):
print("Пароль верный!")
else:
print("Пароль неверный!")
Метод bcrypt.gensalt() генерирует случайную соль, которая автоматически встраивается в итоговый результат. Функция bcrypt.checkpw() умеет извлекать соль из сохранённого значения и повторно хешировать предоставленный пароль с той же солью для сравнения. Этот механизм обеспечивает как безопасность, так и удобство использования.
Лучшие современные алгоритмы (упомянуть): Argon2, PBKDF2, scrypt
Помимо bcrypt, существуют другие специализированные алгоритмы для хеширования паролей, каждый со своими особенностями и преимуществами:
Argon2 — победитель конкурса Password Hashing Competition 2015 года, считается оптимальным выбором для большинства современных систем. Алгоритм устойчив как к атакам с использованием GPU, так и к атакам с применением специализированного оборудования (ASIC). Argon2 требователен к памяти, что значительно затрудняет массовый подбор паролей. В Python доступен через библиотеку argon2-cffi.
PBKDF2 (Password-Based Key Derivation Function 2) — более старый стандарт, рекомендованный NIST. Он подходит для совместимости со старыми системами и хорошо изучен, но требует большого количества итераций (минимум 100 000 для современных стандартов) для обеспечения адекватной защиты. Доступен в стандартной библиотеке через hashlib.pbkdf2_hmac().
scrypt — алгоритм, требовательный к памяти, что затрудняет атаки с использованием специализированного оборудования. Он создаёт высокие барьеры для масштабного подбора паролей, но может быть ресурсоёмким для легитимных серверов при высокой нагрузке.
Для новых проектов мы рекомендуем Argon2 как наиболее сбалансированное решение, сочетающее высокую безопасность и разумную производительность.
Как выбрать подходящий тип хеширования для задачи
Правильный выбор алгоритма зависит от конкретной задачи и требований к безопасности, производительности и стабильности результатов. Использование неподходящего варианта может привести либо к избыточным затратам ресурсов, либо к серьёзным уязвимостям в безопасности.
Давайте систематизируем подходы к выбору для различных сценариев. Ключевой вопрос, который следует задать: нужна ли криптографическая стойкость? Если да — требуется ли защита от подбора (как в случае с паролями), или достаточно обеспечить целостность и аутентификацию данных? Если криптография не критична — приоритетом становится скорость работы.
Некриптографические хеши — где подходят
Встроенная функция hash() оптимальна для внутренних операций программы, где не требуется стабильность результата между запусками:
- Работа со словарями и множествами — Python автоматически использует hash() для организации этих структур данных.
- Временные идентификаторы внутри одной сессии программы.
- Быстрое сравнение объектов в памяти без необходимости персистентности.
Некриптографические алгоритмы вроде xxHash или MurmurHash подходят для задач, где критична скорость, но не требуется защита от злонамеренных модификаций: дедупликация данных, разбиение данных по шардам, контрольные суммы во внутренних системах.
Криптографические — где необходимы
Алгоритмы из модуля hashlib (SHA-256, SHA-3) необходимы, когда результат должен быть стабильным и защищённым от манипуляций:
- Проверка целостности файлов — убедиться, что данные не были изменены при передаче или хранении.
- Создание цифровых подписей и HMAC для аутентификации сообщений.
- Генерация стабильных идентификаторов на основе содержимого.
- Блокчейн и распределённые системы, где требуется консенсус о контрольных суммах данных.
Для большинства задач оптимален SHA-256 — он обеспечивает надёжную защиту при разумной производительности.
Хеширование паролей — какие алгоритмы выбирать
Для паролей категорически нельзя использовать ни hash(), ни обычные криптографические функции. Необходимы специализированные медленные алгоритмы:
- Argon2 — лучший выбор для новых проектов (победитель Password Hashing Competition).
- bcrypt — проверенный временем, широко поддерживаемый стандарт.
- scrypt — хорош для защиты от аппаратных атак, но требователен к ресурсам.
- PBKDF2 — для совместимости со старыми системами или нормативными требованиями.
Критически важно: никогда не используйте MD5, SHA-1 или SHA-256 напрямую для паролей.
Частые вопросы (FAQ)
Можно ли восстановить данные по хешу?
Нет, хеширование — это односторонний процесс. Из дайджеста невозможно получить исходные данные математическими методами. Однако для слабых паролей существует угроза подбора: злоумышленник может перебирать варианты и сравнивать их отпечатки с целевым. Именно поэтому для паролей используют медленные алгоритмы вроде bcrypt, которые делают массовый подбор непрактичным.
Почему hash() даёт разные результаты при каждом запуске?
Это защитный механизм Python против атак алгоритмической сложности. Начиная с версии 3.3, интерпретатор добавляет случайную «соль» к вычислениям для строк при каждом запуске. Это делает hash() непригодной для задач, требующих стабильности результата — используйте hashlib для таких сценариев.
MD5 считается небезопасным?
Да, для криптографических задач MD5 давно компрометирован — исследователи создали практические примеры коллизий. Однако для некритичных задач вроде быстрой проверки целостности файлов в доверенной среде MD5 всё ещё применим благодаря высокой скорости. Для любых задач, связанных с безопасностью, используйте минимум SHA-256.
Можно ли хешировать большие файлы?
Да, и это делается эффективно через инкрементальное хеширование. Файл читается небольшими блоками (обычно 8-64 КБ), каждый блок последовательно передаётся в функцию через метод update(). Это позволяет обрабатывать файлы любого размера, используя минимум оперативной памяти.
Как проверить совпадение хеша?
Для обычных дайджестов достаточно простого сравнения строк через оператор ==. Однако для проверки HMAC-подписей или паролей всегда используйте hmac.compare_digest() — эта функция защищает от timing attacks, выполняя сравнение за постоянное время независимо от количества совпадающих символов.
Заключение
Хеширование в Python — это фундаментальная технология, которая находит применение на всех уровнях разработки. Правильное понимание и применение различных алгоритмов позволяет создавать эффективные, надёжные и безопасные приложения. Подведем итоги:
- Хеширование в python лежит в основе работы словарей, множеств и систем безопасности. Понимание принципов позволяет использовать язык эффективнее и безопаснее.
- Разные типы хеш-функций подходят для разных задач. Встроенная hash() удобна для внутренних структур, а hashlib необходим для стабильных и криптографических сценариев.
- Коллизии неизбежны, но современные алгоритмы сводят их вероятность к минимуму. Это делает хеширование надёжным инструментом для проверки целостности данных.
- Для защиты паролей нельзя использовать обычные хеш-функции. Безопасное хранение требует медленных алгоритмов с солью, таких как bcrypt или Argon2.
- Правильный выбор алгоритма хеширования напрямую влияет на производительность и безопасность системы. Ошибки на этом уровне могут привести к серьёзным уязвимостям.
Если вы рекомендуем обратить внимание на системное изучение темы и только начинаете осваивать профессию python-разработчика, стоит посмотреть подборку курсов по python. В таких курсах обычно есть теоретическая и практическая часть, что помогает быстрее разобраться в работе с хешированием и другими базовыми механизмами языка.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
112 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
13 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
12 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
36 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
17 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
226 отзывов
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
15 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
100 отзывов
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
12 марта
|
Подробнее |

Skypro vs ProductStar: куда идти аналитику, чтобы стать продактом — траектория и кейсы
Если вы аналитик и хотите перейти в продакт-менеджмент, но не знаете, с чего начать, эта статья для вас. Мы расскажем, какие шаги и курсы помогут вам освоить нужные навыки, чтобы успешно перейти в продуктовую роль. Задайтесь вопросом: готовы ли вы на решение проблем, а не просто на анализ данных?

Собеседование Devops Junior и Middle: актуальные вопросы и темы 2026 года
Вопросы на собеседовании DevOps могут сильно различаться в зависимости от уровня кандидата. Какие навыки и знания проверяют у Junior и Middle в 2026 году? Мы расскажем, как подготовиться к собеседованию и что важно знать для успешного прохождения интервью.

Собеседование по Python: частые вопросы и как на них отвечать
Готовитесь к техническому интервью и хотите понять, какие вопросы на собеседование Python разработчик слышит чаще всего? Разбираем реальные примеры задач, вопросы для junior, middle и senior, а также типичные ошибки кандидатов и стратегию подготовки.

Skypro vs Contented: Web/UX дизайн — где сильнее разборы работ и быстрее растёт качество
В этой статье мы расскажем, как выбрать лучший курс по веб-дизайну. Если вы только начинаете изучать эту профессию, то вам наверняка будет полезно узнать, что важно учитывать при выборе курса и какие именно аспекты обучения могут ускорить ваш профессиональный рост. Откроем основные моменты, которые помогут вам сделать правильный выбор и избежать распространенных ошибок.