Хранилища данных в Kubernetes: полное руководство по PV, PVC, StorageClass и CSI с примерами
Контейнеры по своей природе эфемерны — они создаются, выполняют задачу и исчезают, унося с собой все данные, которые успели накопить за время жизни. Эта особенность прекрасно работает для stateless-приложений, но становится серьёзным препятствием, когда речь заходит о базах данных, файловых хранилищах или любых сервисах, которым критически необходимо сохранять состояние между перезапусками.

Именно здесь возникает ключевое различие между ephemeral storage (временным хранилищем) и persistent storage (постоянным хранилищем). Первое живёт ровно столько же, сколько и контейнер — удалили Pod, потеряли данные. Второе же предоставляет возможность хранить информацию независимо от жизненного цикла отдельных подов, что открывает путь к развёртыванию stateful-приложений в Kubernetes.
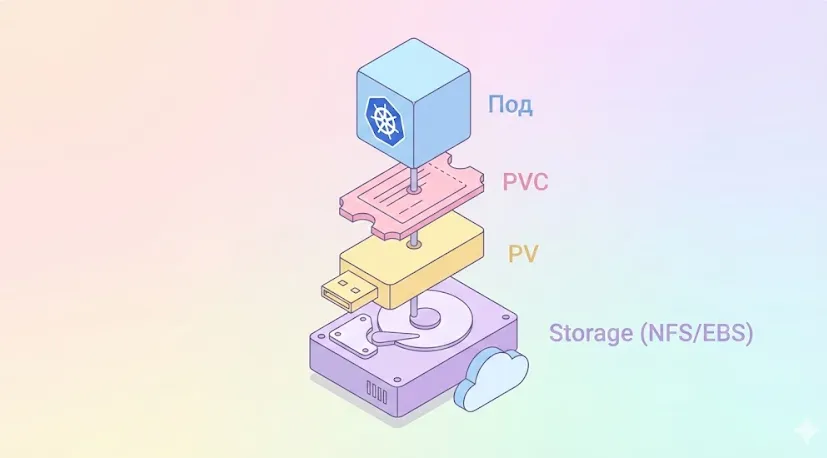
Данные проходят через три слоя абстракции. Pod держит «талончик» (PVC), талончик привязан к «ячейке» (PV), а ячейка — это реальное место на диске.
Данные проходят через три слоя абстракции. Pod держит «талончик» (PVC), талончик привязан к «ячейке» (PV), а ячейка — это реальное место на диске.
В этой статье мы разберём четыре фундаментальных абстракции, которые решают проблему постоянного хранения данных в кластере:
- Persistent Volume (PV) — представление физического хранилища на уровне кластера.
- Persistent Volume Claim (PVC) — запрос на выделение хранилища от пользователя или приложения.
- StorageClass — механизм автоматизации и динамического provisioning’а томов.
- Container Storage Interface (CSI) — унифицированный интерфейс для интеграции любых систем хранения.
- Как Kubernetes работает с данными: общий принцип
- Persistent Volume (PV) — что это и как работает
- Persistent Volume Claim: как работает запрос на хранилище
- StorageClass: автоматизация и динамическое выделение хранилища
- YAML-примеры PV, PVC и StorageClass (с подробным разбором)
- Использование NFS как хранилища в Kubernetes
- Local Persistent Volumes: работа с локальными дисками
- Container Storage Interface (CSI): как Kubernetes управляет хранилищами
- Пример минимального CSI-драйвера (описать на высоком уровне)
- Практический сценарий: развёртывание приложения с постоянным хранилищем
- Типичные ошибки и troubleshooting
- Заключение
- Рекомендуем посмотреть курсы по обучению DevOps
Как Kubernetes работает с данными: общий принцип
Контейнер — это изолированная среда выполнения, которая по умолчанию использует файловую систему образа и временные слои для записи. Когда Pod удаляется (а это может произойти по множеству причин: от обновления приложения до сбоя ноды), все данные, записанные в файловую систему контейнера, безвозвратно теряются. Для stateless-сервисов это приемлемо, но для баз данных, очередей сообщений или файловых хранилищ — катастрофа.
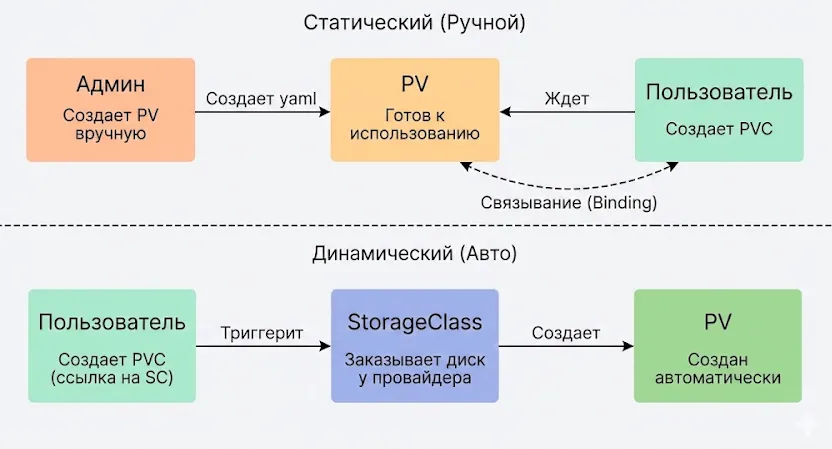
Сверху — старый путь: админу приходится создавать всё руками. Снизу — путь StorageClass: Kubernetes делает всю грязную работу за вас, создавая диск в облаке автоматически.
Кьюбернетс решает эту проблему через систему абстракций, которая отделяет логическое представление хранилища от его физической реализации. Общий принцип работы выглядит следующим образом:
Физическое хранилище (NFS, iSCSI, локальный диск) ↓ Persistent Volume (PV) -- описание хранилища в кластере ↓ Persistent Volume Claim (PVC) -- запрос на хранилище ↓ Pod -- использование через volumeMounts
Статический provisioning предполагает, что администратор заранее создаёт PV с конкретными параметрами (размер, тип доступа, backend). Когда пользователь создаёт Persistent Volume Claim, Kubernetes автоматически находит подходящий PV и связывает их. Этот подход даёт полный контроль над ресурсами, но требует ручного управления.
Динамический provisioning работает иначе: при создании PVC система автоматически добавляет соответствующий PV через StorageClass и настроенный provisioner. Это удобно в облачных окружениях (AWS EBS, GCP Persistent Disk), где создание дисков можно автоматизировать через API провайдера.
Выбор между статическим и динамическим подходом зависит от вашей инфраструктуры: если у вас есть заранее выделенные хранилища или специфические требования к производительности — используйте статический provisioning. Если работаете в облаке и нужна гибкость — динамический provisioning с правильно настроенными StorageClass станет оптимальным решением.
Persistent Volume (PV) — что это и как работает
Определение и назначение PV
Persistent Volume представляет собой ресурс кластера, который абстрагирует физическое хранилище и предоставляет его приложениям в унифицированном виде. Можно сказать, что PV играет роль своеобразного моста между «железом» (будь то сетевое хранилище, облачный диск или локальный SSD) и логическим представлением хранилища в Кьюбернетс.
В отличие от других ресурсов Kubernetes, PV существует на уровне кластера, а не namespace’а. Это означает, что администратор может создать пул хранилищ с различными характеристиками, а разработчики затем будут запрашивать нужные им ресурсы через Persistent Volume Claim, не заботясь о деталях реализации — какой именно диск, на каком сервере, через какой протокол подключен.
Какие типы физических хранилищ можно использовать
Kubernetes поддерживает внушительное количество backend’ов для организации постоянного хранения. Вот наиболее распространённые варианты:
- NFS — сетевая файловая система, идеальна для сценариев, когда несколько подов должны одновременно читать и писать данные (ReadWriteMany). Простота настройки делает NFS популярным выбором для on-premise развёртываний, хотя производительность может быть ограничена сетевой пропускной способностью.
- iSCSI — блочное хранилище по IP-сети. Обеспечивает лучшую производительность по сравнению с NFS для баз данных, но обычно поддерживает только режим ReadWriteOnce (один под с правами на запись).
- RBD (RADOS Block Device) — блочные устройства Ceph. Отличный выбор для продакшена, где требуется распределённое хранилище с репликацией и высокой доступностью.
- CephFS — файловая система поверх Ceph, поддерживает ReadWriteMany и хорошо масштабируется.
- GlusterFS — распределённая файловая система, альтернатива CephFS для построения отказоустойчивых кластерных хранилищ.
- Локальные диски — быстрые SSD/NVMe на нодах кластера. Максимальная производительность, но привязка к конкретной ноде и отсутствие репликации требуют тщательного планирования.
- Облачные провайдеры — AWS EBS, GCP Persistent Disk, Azure Disk — управляемые решения с автоматическим provisioning’ом через StorageClass.
Выбор бэкенда зависит от ваших требований: для высоконагруженных баз данных с низкой latency стоит рассматривать локальные NVMe или RBD; для файловых хранилищ с общим доступом — NFS или CephFS; для облачных развёртываний — нативные решения провайдера.
Ключевые параметры PV
При создании Persistent Volume необходимо определить несколько критически важных параметров:
- capacity — размер хранилища. Указывается в формате storage: 100Gi. При связывании PVC с PV Kubernetes ищет том с достаточным объёмом, но не обязательно точно соответствующим запросу.
- accessModes — режимы доступа к тому. Определяют, сколько подов и в каком режиме могут одновременно использовать хранилище: ReadWriteOnce (RWO), ReadOnlyMany (ROX), ReadWriteMany (RWX). Важно понимать, что поддержка конкретных режимов зависит от backend’а.
- storageClassName — ссылка на StorageClass, которая группирует тома по характеристикам. Если PV создаётся статически, этот параметр связывает его с соответствующим классом хранилища.
- persistentVolumeReclaimPolicy — политика обработки PV после освобождения: Retain (сохранить данные для ручной обработки), Delete (автоматически удалить том и данные), Recycle (устаревший вариант, очистить том для повторного использования).
Грамотная настройка этих параметров определяет не только производительность и доступность данных, но и общую стратегию управления жизненным циклом хранилищ в вашем кластере.
Persistent Volume Claim: как работает запрос на хранилище
PVC как способ запроса ресурсов
Если PV — это доступное хранилище в кластере, то Persistent Volume Claim представляет собой запрос на это хранилище от пользователя или приложения. Аналогию можно провести с заказом ресурсов: разработчик указывает желаемый объём и характеристики, а Кьюбернетс ищет подходящий том или создаёт его динамически.
Процесс сопоставления PVC с PV происходит автоматически и основывается на нескольких критериях: размер хранилища, режим доступа, StorageClass и, опционально, селекторы меток. Kubernetes сканирует доступные PV и находит тот, который удовлетворяет всем требованиям Persistent Volume Claim. После успешного связывания (binding) PVC переходит в состояние Bound, и под может использовать это хранилище.
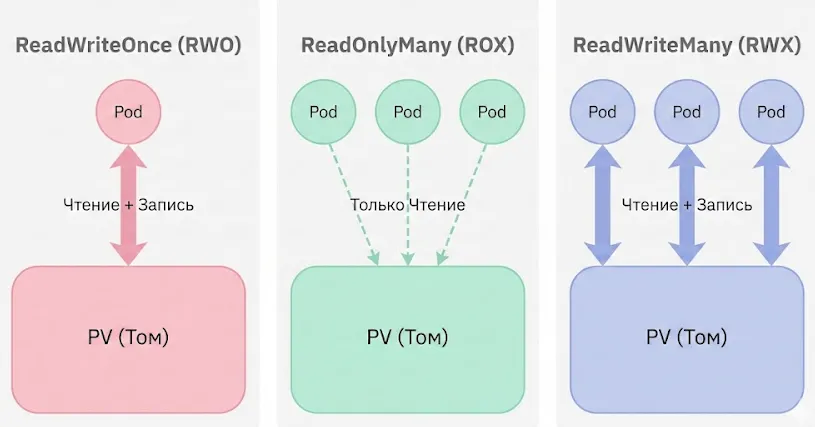
Наглядно о том, кто и как может писать в том. RWO — эгоист (один к одному), ROX — библиотека (все читают, никто не пишет), RWX — общая доска (все читают и пишут).
Важная особенность: один PV может быть связан только с одним PVC. Даже если вы запросили 50 ГБ, а нашёлся PV на 150 ГБ, он будет выделен полностью, и оставшееся место окажется недоступным для других Persistent Volume Claim. Это поведение стоит учитывать при планировании размеров томов.
Типы доступа (Access Modes)
Access modes определяют, как именно поды могут взаимодействовать с томом. Выбор правильного режима критически важен для корректной работы приложения:
- ReadWriteOnce (RWO) — том может быть смонтирован для чтения и записи только к одному поду. Это наиболее распространённый режим, поддерживаемый практически всеми backend’ами. Используется для БД, которые требуют эксклюзивного доступа к данным.
- ReadOnlyMany (ROX) — том может быть смонтирован в режиме только чтения к множеству подов одновременно. Подходит для сценариев распространения конфигурационных файлов или статического контента между несколькими репликами приложения.
- ReadWriteMany (RWX) — том доступен для чтения и записи нескольким подам одновременно. Требуется для приложений, которые должны совместно работать с данными (например, shared file storage). Поддерживается только файловыми системами вроде NFS, CephFS или GlusterFS — блочные устройства (iSCSI, RBD) этот режим не предоставляют.
Почему PVC может зависнуть в состоянии Pending
Одна из самых частых проблем при работе с хранилищами — PVC, который остаётся в состоянии Pending и не связывается с PV. Давайте рассмотрим типичные причины:
- Несоответствие размера — вы запросили 100 ГБ, но все доступные PV меньше этого объёма. Кьюбернетс не создаст том автоматически, если не настроен динамический provisioning через StorageClass.
- Несовместимые access modes — Persistent Volume Claim требует ReadWriteMany, а все доступные PV поддерживают только ReadWriteOnce. Проверьте, соответствует ли backend выбранному режиму доступа.
- Отсутствие подходящего StorageClass — если в PVC указан storageClassName, но такой класс не существует в кластере или у него нет настроенного provisioner’а, том не будет создан динамически.
- Политика VolumeBindingMode: WaitForFirstConsumer — в некоторых StorageClass используется отложенное связывание, которое ждёт создания пода перед выделением хранилища. В этом случае Pending — нормальное состояние до момента запуска приложения.
- NodeAffinity для локальных томов — при использовании local persistent volumes под может не запуститься, если нода, на которой расположен том, недоступна или не соответствует селекторам.
Для диагностики используйте команду kubectl describe pvc <имя> — в секции Events вы увидите причину, по которой связывание не произошло.
StorageClass: автоматизация и динамическое выделение хранилища
StorageClass — это механизм, который превращает статическое управление хранилищами в динамический, автоматизированный процесс. Вместо того чтобы администратор вручную создавал десятки PV с разными характеристиками, StorageClass позволяет описать «классы» хранилищ (быстрые SSD, медленные HDD, реплицированные тома) и автоматически выделять их по запросу.
Когда пользователь создаёт PVC с указанием определённого StorageClass, provisioner автоматически добавляет соответствующий PV и связывает его с запросом. Это особенно удобно в облачных окружениях, где создание дисков происходит через API провайдера за считанные секунды.
Ключевые параметры StorageClass
При определении StorageClass мы настраиваем несколько ключевых параметров, которые определяют поведение системы хранения:
- provisioner — компонент, отвечающий за создание томов. Kubernetes предоставляет встроенные provisioner’ы для популярных облачных провайдеров (kubernetes.io/aws-ebs, kubernetes.io/gce-pd, kubernetes.io/azure-disk), а также поддерживает внешние provisioner’ы через CSI-драйверы. Для статических томов можно использовать kubernetes.io/no-provisioner.
- parameters — специфичные для provisioner’а настройки, которые передаются при создании тома. Здесь могут быть указаны тип диска (SSD/HDD), уровень производительности (IOPS), политики репликации, файловая система и другие параметры. Например, для AWS EBS можно указать type: gp3, iopsPerGB: «10», для GCP — type: pd-ssd, replication-type: regional-pd.
- reclaimPolicy — определяет судьбу PV после удаления связанного PVC. Значение Delete приведёт к автоматическому удалению тома и всех данных (стандартное поведение для динамически созданных томов). Вариант Retain сохранит том для возможного восстановления данных, но потребует ручной очистки.
- volumeBindingMode — контролирует момент создания и связывания тома. Immediate создаёт PV сразу при появлении PVC. WaitForFirstConsumer откладывает добавление тома до момента, когда появится под, использующий этот PVC — это критично для топологически зависимых хранилищ, где том должен создаваться в той же зоне доступности, что и под.
| Параметр | Возможные значения | Назначение |
|---|---|---|
| provisioner | kubernetes.io/aws-ebs, kubernetes.io/gce-pd, CSI driver | Механизм создания томов |
| parameters | type, iopsPerGB, fsType и др. | Backend-специфичные настройки |
| reclaimPolicy | Delete, Retain | Политика после удаления PVC |
| volumeBindingMode | Immediate, WaitForFirstConsumer | Момент создания тома |
| allowVolumeExpansion | true, false | Возможность расширения тома |
Примеры использования StorageClass в облаках
AWS EBS — для создания дисков в Amazon можно использовать provisioner kubernetes.io/aws-ebs или современный CSI-драйвер ebs.csi.aws.com. Типичные параметры включают тип диска (gp3, io2), зону размещения и IOPS. StorageClass с volumeBindingMode: WaitForFirstConsumer гарантирует, что диск создастся в той же availability zone, где запустится под.
GCP Persistent Disk — для Google Cloud используется kubernetes.io/gce-pd или CSI pd.csi.storage.gke.io. Можно выбрать между pd-standard (HDD) и pd-ssd, настроить региональную репликацию для повышения надёжности.
Локальные StorageClass без provisioner — когда динамическое создание томов невозможно (например, для локальных дисков на нодах), используется provisioner: kubernetes.io/no-provisioner. В этом случае PV создаются вручную администратором, а StorageClass служит только для группировки и маркировки томов определённого типа.
YAML-примеры PV, PVC и StorageClass (с подробным разбором)
Пример PV + объяснение всех ключевых строк
apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv-example spec: capacity: storage: 50Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: nfs-storage nfs: server: 192.168.1.100 path: "/exports/data"
Разберём каждый параметр:
- capacity.storage: 50Gi — объём хранилища, который предоставляет этот PV. При сопоставлении с PVC Kubernetes найдёт том с достаточным размером.
- accessModes: ReadWriteMany — режим доступа позволяет нескольким подам одновременно читать и писать данные, что характерно для NFS.
- persistentVolumeReclaimPolicy: Retain — после удаления PVC данные сохраняются, а PV переходит в состояние Released, требуя ручной очистки перед повторным использованием.
- storageClassName: nfs-storage — связывает PV с определённым классом хранилища. PVC должен запросить тот же класс для успешного связывания.
- nfs.server и nfs.path — конфигурация backend’а, специфичная для NFS. Здесь указываем IP-адрес NFS-сервера и путь к экспортируемой директории.
Пример PVC
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: app-data-claim namespace: production spec: accessModes: - ReadWriteMany storageClassName: nfs-storage resources: requests: storage: 30Gi
Ключевые моменты:
- namespace: production — PVC существует в рамках namespace, в отличие от PV, который доступен на уровне кластера.
- accessModes: ReadWriteMany — должен соответствовать режиму доступа PV. Несовпадение приведёт к тому, что связывание не произойдёт.
- storageClassName: nfs-storage — запрашиваем хранилище из определённого класса. Если класс не указан явно, будет использован default StorageClass.
- resources.requests.storage: 30Gi — минимальный требуемый объём. Kubernetes может выделить PV большего размера (в нашем случае 50 ГБ), но меньшего — никогда.
Пример StorageClass
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast-ssd provisioner: kubernetes.io/aws-ebs parameters: type: gp3 iopsPerGB: "50" fsType: ext4 reclaimPolicy: Delete volumeBindingMode: WaitForFirstConsumer allowVolumeExpansion: true
Детальное объяснение:
- provisioner: kubernetes.io/aws-ebs — встроенный provisioner для AWS EBS. В продакшене рекомендуется использовать современный CSI-драйвер ebs.csi.aws.com.
- parameters.type: gp3 — тип диска AWS (General Purpose SSD третьего поколения), обеспечивающий баланс между производительностью и стоимостью.
- parameters.iopsPerGB: «50» — количество операций ввода-вывода в секунду на гигабайт. Для gp3 можно настраивать независимо от размера диска.
- parameters.fsType: ext4 — файловая система, которая будет создана на диске. Альтернативы: xfs, ext3.
- reclaimPolicy: Delete — автоматическое удаление EBS-диска при удалении PVC. Экономит средства, но требует осторожности с критичными данными.
- volumeBindingMode: WaitForFirstConsumer — создание диска откладывается до момента запуска пода. Гарантирует, что диск создастся в той же availability zone, что и нода с подом.
- allowVolumeExpansion: true — разрешает увеличение размера тома без пересоздания (требует поддержки бэкендом).
Пример Pod с volumeMounts
apiVersion: v1 kind: Pod metadata: name: web-application spec: containers: - name: nginx image: nginx:latest volumeMounts: - name: persistent-storage mountPath: /usr/share/nginx/html volumes: - name: persistent-storage persistentVolumeClaim: claimName: app-data-claim
Как работает монтирование:
- volumeMounts.name: persistent-storage — логическое имя тома внутри контейнера, должно совпадать с именем в секции volumes.
- volumeMounts.mountPath — путь внутри контейнера, куда будет смонтирован том. Все данные в этой директории будут сохраняться между перезапусками пода.
- volumes.persistentVolumeClaim.claimName — ссылка на созданный ранее PVC. Kubernetes автоматически найдёт связанный PV и смонтирует его.
Обратите внимание: под не запустится, пока PVC не перейдёт в состояние Bound. Если связывание не произошло, под будет находиться в состоянии Pending с соответствующим сообщением в Events.
Использование NFS как хранилища в Kubernetes
NFS (Network File System) остаётся одним из самых популярных вариантов для организации shared storage в on-premise кластерах Кьюбернетс. Простота настройки, поддержка режима ReadWriteMany и отсутствие зависимости от облачных провайдеров делают NFS привлекательным решением для многих сценариев — от хранения логов до организации общих файловых хранилищ.
Создание PV для NFS
Для подключения NFS-хранилища необходимо создать PersistentVolume с указанием параметров сервера:
apiVersion: v1 kind: PersistentVolume metadata: name: nfs-storage-pv spec: capacity: storage: 100Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: nfs mountOptions: - hard - nfsvers=4.1 nfs: server: nfs.example.local path: /exports/kubernetes
Параметр mountOptions позволяет передать специфичные для NFS настройки: hard обеспечивает повторные попытки при недоступности сервера (в отличие от soft), а nfsvers=4.1 явно указывает версию протокола.
Требования к серверу NFS
Перед использованием NFS в Kubernetes необходимо правильно настроить сам NFS-сервер:
- Экспорт директории — на сервере должна быть создана и экспортирована директория с соответствующими правами. В /etc/exports добавляется запись вроде /exports/kubernetes *(rw,sync,no_subtree_check,no_root_squash).
- Права доступа — критически важно настроить корректные permissions на экспортируемую директорию. Опция no_root_squash позволяет контейнерам, работающим от root, записывать файлы без смены владельца.
- Сетевая доступность — все ноды кластера должны иметь сетевой доступ к NFS-серверу. Firewall должен разрешать трафик на портах 2049 (NFSv4) и, возможно, 111 (portmapper для NFSv3).
- NFS-клиент на нодах — на каждой ноде Кьюбернетс должен быть установлен пакет nfs-common (Debian/Ubuntu) или nfs-utils (CentOS/RHEL).
Особенности подключения
В отличие от блочных устройств, NFS не требует эксклюзивного доступа и прекрасно работает в режиме ReadWriteMany. Это делает его идеальным для сценариев, когда несколько реплик приложения должны одновременно работать с общими данными.
Однако стоит учитывать, что производительность NFS сильно зависит от сетевой инфраструктуры. Для высоконагруженных баз данных с требованиями к низкой latency NFS может оказаться недостаточно быстрым решением.
Reclaim Policy в контексте NFS
Для NFS-хранилищ особенно важно правильно выбрать persistentVolumeReclaimPolicy:
Retain — рекомендуемый вариант для продакшена. После удаления PVC данные остаются на NFS-сервере, а PV переходит в состояние Released. Администратор может вручную проверить содержимое, создать резервную копию и затем либо очистить PV для повторного использования, либо удалить его.
Delete — автоматически удаляет PV, но сами данные на NFS-сервере остаются! Kubernetes не имеет механизма для очистки NFS-директорий, поэтому потребуется отдельный процесс для управления дисковым пространством.
Ключевые ограничения NFS:
- Производительность ограничена пропускной способностью сети.
- Одна точка отказа (single point of failure) — сбой NFS-сервера делает данные недоступными для всех подов.
- Не подходит для приложений с высокими требованиями к IOPS.
- Возможны проблемы с file locking в некоторых сценариях.
- Требует дополнительной настройки безопасности (Kerberos для enterprise-окружений).
Local Persistent Volumes: работа с локальными дисками
Когда стоит использовать локальные PV
Local Persistent Volumes представляют собой хранилище на физических дисках конкретных нод кластера. В отличие от сетевых решений (NFS, iSCSI, Ceph), данные физически находятся на том же сервере, где работает под — это обеспечивает максимально возможную производительность и минимальную latency.
Типичные сценарии использования локальных PV включают высоконагруженные БД (PostgreSQL, MySQL), распределённые системы хранения данных (Cassandra, MongoDB), где приложение само управляет репликацией, а также кэширующие слои, требующие быстрого доступа к SSD или NVMe дискам.
Возникает резонный вопрос: если производительность настолько хороша, почему бы не использовать локальные диски везде? Ответ кроется в отсутствии переносимости — под жёстко привязан к конкретной ноде, и при её сбое данные становятся недоступны до восстановления сервера.
Особенности: NodeAffinity, отсутствие динамического провиженинга
Критическая особенность local volumes — обязательное использование NodeAffinity. Поскольку данные физически находятся на конкретной ноде, Кьюбернетс должен гарантировать, что под всегда запустится именно там, где расположен диск. Без правильно настроенного NodeAffinity под может попытаться запуститься на другой ноде и зависнет в состоянии Pending.
Динамический provisioning для локальных дисков не поддерживается из коробки. Администратор должен вручную подготовить директории или блочные устройства на нодах и создать соответствующие PV. Существуют сторонние операторы (например, local-path-provisioner от Rancher), которые автоматизируют этот процесс, но стандартный Kubernetes такой функциональности не предоставляет.
При использовании локальных томов необходимо тщательно планировать размещение данных: убедитесь, что на ноде достаточно реплик приложения для обеспечения отказоустойчивости, а система мониторинга отслеживает состояние дисков.
Пример StorageClass и PV для локального диска
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: local-storage provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer
Обратите внимание на provisioner: kubernetes.io/no-provisioner — явное указание на отсутствие автоматического создания томов. Параметр volumeBindingMode: WaitForFirstConsumer критически важен: он откладывает связывание PVC с PV до момента создания пода, гарантируя, что под и том окажутся на одной ноде.
apiVersion: v1 kind: PersistentVolume metadata: name: local-pv-node1 spec: capacity: storage: 500Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-storage local: path: /mnt/nvme-disk nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - worker-node-01
Ключевые параметры:
- local.path — путь к примонтированному диску на ноде (должен существовать заранее).
- nodeAffinity — жёсткая привязка к ноде worker-node-01.
- accessModes: ReadWriteOnce — локальные диски не поддерживают ReadWriteMany.
Пример Pod, привязанного к конкретной ноде
apiVersion: v1 kind: Pod metadata: name: database-pod spec: containers: - name: postgres image: postgres:14 volumeMounts: - name: db-storage mountPath: /var/lib/postgresql/data volumes: - name: db-storage persistentVolumeClaim: claimName: local-db-claim
При создании этого пода Kubernetes автоматически учтёт NodeAffinity из PV и разместит под на ноде worker-node-01. Если эта нода недоступна или на ней недостаточно ресурсов, под останется в состоянии Pending до устранения проблемы.
Именно поэтому локальные PV рекомендуется использовать для stateful-приложений, которые сами реализуют репликацию данных (например, database clusters с несколькими репликами на разных нодах), а не для критичных single-instance сервисов.
Container Storage Interface (CSI): как Kubernetes управляет хранилищами
Что такое CSI и зачем он нужен
Container Storage Interface (CSI) — это стандартизированный интерфейс, который определяет, как системы оркестрации контейнеров взаимодействуют с различными сервисами хранения данных. До появления CSI каждая система хранения требовала написания специфичного плагина, встроенного непосредственно в код Kubernetes — это создавало проблемы с поддержкой, тестированием и выпуском новых версий.
CSI решает эту проблему через унификацию подключаемых хранилищ: производители storage-решений создают драйверы, соответствующие спецификации CSI, и эти драйверы работают с любой системой оркестрации, поддерживающей CSI (Kubernetes, Mesos, Cloud Foundry). Разработчикам Кьюбернетс больше не нужно встраивать код каждого нового хранилища в ядро — они просто предоставляют механизм взаимодействия с CSI-драйверами.
Второе ключевое преимущество — независимость от релизного цикла Kubernetes. Обновление драйвера для AWS EBS или добавление поддержки нового функционала в Ceph CSI больше не требует ожидания следующего релиза Kubernetes. Производители хранилищ выпускают обновления своих драйверов независимо, что значительно ускоряет внедрение новых возможностей.
Архитектура CSI
CSI-драйвер состоит из нескольких компонентов, каждый из которых выполняет специфическую роль в управлении жизненным циклом томов:
Identity Service — отвечает за идентификацию драйвера и предоставление информации о его capabilities (возможностях). Когда Kubernetes впервые взаимодействует с CSI-драйвером, он запрашивает через Identity Service название драйвера, версию и список поддерживаемых операций.
Node Service — выполняет операции на уровне конкретной ноды: монтирование тома к файловой системе ноды, размонтирование, получение статистики использования дискового пространства. Этот сервис работает на каждой ноде через DaemonSet и взаимодействует напрямую с локальной файловой системой.
Controller Service — управляет операциями на уровне кластера: создание томов, удаление, snapshot’ы, расширение размера. Controller обычно развёртывается как Deployment с одной или несколькими репликами и взаимодействует с API backend’а хранилища (например, AWS API для создания EBS дисков).
Sidecar-контейнеры — вспомогательные компоненты, которые обеспечивают интеграцию CSI-драйвера с Kubernetes API:
- external-provisioner — отслеживает создание PVC и вызывает метод CreateVolume у CSI-драйвера, затем создаёт соответствующий PV в Kubernetes.
- external-attacher — обрабатывает VolumeAttachment objects и вызывает ControllerPublishVolume для подключения тома к ноде.
- external-snapshotter — управляет снэпшотами томов.
- node-driver-registrar — регистрирует CSI-драйвер в kubelet через Unix Domain Socket и добавляет информацию о драйвере в объект Node.
Взаимодействие между компонентами происходит через gRPC — kubelet и сайдкары отправляют запросы CSI-драйверу, который выполняет необходимые операции с физическим хранилищем.
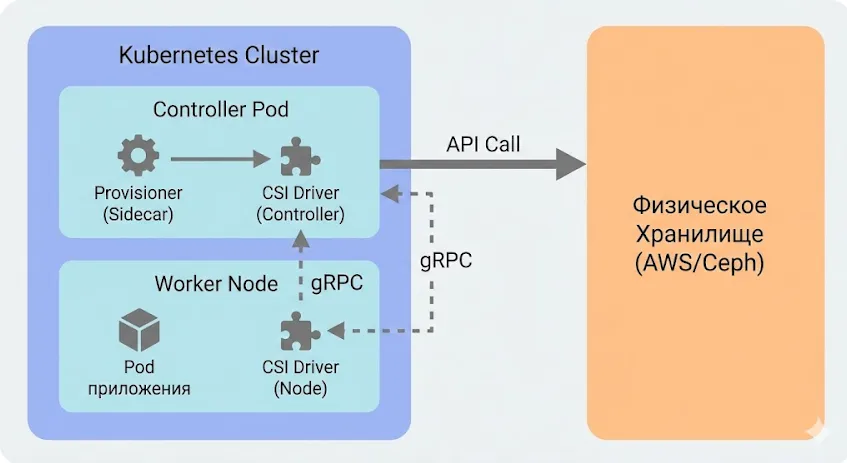
CSI — это переводчик. Kubernetes (слева) говорит «хочу диск», CSI-драйвер (в центре) переводит это на язык конкретного железа (справа), будь то AWS или локальный диск.
Жизненный цикл операций CSI
Рассмотрим типичный сценарий создания и использования тома через CSI:
- CreateVolume — когда пользователь создаёт Persistent Volume Claim с StorageClass, использующим CSI-provisioner, external-provisioner обнаруживает новый PVC и вызывает метод CreateVolume у Controller Service. Драйвер обращается к backend’у (например, создаёт EBS диск в AWS), получает идентификатор созданного тома и возвращает его provisioner’у. На основе этой информации создаётся PV в Kubernetes.
- ControllerPublishVolume — после того как scheduler назначил под на конкретную ноду, external-attacher создаёт VolumeAttachment и вызывает ControllerPublishVolume. Эта операция «подключает» том к ноде на уровне инфраструктуры — например, attach’ит EBS диск к EC2 инстансу. Важно понимать, что на этом этапе том ещё не смонтирован в файловую систему.
- NodeStageVolume и NodePublishVolume — kubelet на ноде вызывает эти методы Node Service для фактического монтирования. NodeStageVolume подготавливает том (например, форматирует файловую систему, если это первое использование), а NodePublishVolume монтирует том в конкретную директорию, указанную в спецификации пода.
- DeleteVolume — при удалении PVC (если reclaimPolicy установлена в Delete) external-provisioner вызывает DeleteVolume у Controller Service, и драйвер удаляет том из backend’а.
Такая многоступенчатая архитектура может показаться избыточной, но она обеспечивает гибкость и надёжность: разделение ответственности между Controller и Node позволяет обрабатывать сложные сценарии вроде миграции подов между нодами или расширения томов без остановки приложений.
Пример минимального CSI-драйвера (описать на высоком уровне)
Структура кода
Создание собственного CSI-драйвера может показаться сложной задачей, но минимальная реализация требует всего нескольких компонентов. Давайте рассмотрим, как устроен простейший драйвер на примере Python-реализации с использованием gRPC.
Основной модуль начинается с определения protobuf-спецификаций. CSI предоставляет готовые .proto файлы, описывающие все необходимые RPC-методы и структуры данных. С помощью утилиты protoc мы генерируем Python-код, который содержит классы и методы для взаимодействия через gRPC:
protoc -I ./protos --python_out=. --grpc_python_out=. ./protos/csi.proto
Обработка gRPC методов Identity Service — первый необходимый компонент. Этот сервис отвечает за идентификацию драйвера:
class IdentityServicer(csi_pb2_grpc.IdentityServicer): def GetPluginInfo(self, request, context): return csi_pb2.GetPluginInfoResponse( name='my-custom-storage', vendor_version='1.0.0' ) def GetPluginCapabilities(self, request, context): # Возвращаем список поддерживаемых возможностей # например, CONTROLLER_SERVICE, VOLUME_ACCESSIBILITY_CONSTRAINTS
Node Service реализует операции на уровне ноды — монтирование и размонтирование томов:
class NodeServicer(csi_pb2_grpc.NodeServicer): def NodePublishVolume(self, request, context): # Монтируем том в target_path # Здесь вызываем системные команды mount def NodeUnpublishVolume(self, request, context): # Размонтируем том
Sidecar-контейнеры не являются частью самого драйвера — это стандартные компоненты Kubernetes, которые работают вместе с вашим драйвером. External-provisioner, external-attacher и node-driver-registrar поставляются готовыми и требуют только правильной конфигурации через параметры запуска.
Развёртывание CSI-плагина в Kubernetes
После реализации gRPC-сервисов необходимо упаковать приложение в Docker-контейнер и развернуть в кластере. Развёртывание CSI-драйвера требует нескольких типов ресурсов:
Сервис-аккаунты и RBAC — CSI-драйверу нужны разрешения для взаимодействия с Kubernetes API: создание и удаление PV, обновление VolumeAttachment, чтение информации о нодах. Создаём ServiceAccount и привязываем к нему ClusterRole с необходимыми правами:
apiVersion: v1 kind: ServiceAccount metadata: name: csi-driver-sa namespace: kube-system --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: csi-driver-role rules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["create", "delete", "get", "list", "watch", "update"] # ... другие необходимые permissions
DaemonSet для Node Service — поскольку Node Service должен работать на каждой ноде кластера, развёртываем его как DaemonSet. В манифесте указываем hostPath volume для доступа к Unix Domain Socket kubelet:
kind: DaemonSet apiVersion: apps/v1 metadata: name: csi-node-driver spec: selector: matchLabels: app: csi-node-driver template: spec: serviceAccountName: csi-driver-sa containers: - name: csi-driver image: my-registry/csi-driver:1.0 volumeMounts: - name: socket-dir mountPath: /csi - name: node-driver-registrar image: k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.5.0 volumes: - name: socket-dir hostPath: path: /var/lib/kubelet/plugins/my-csi-driver
StatefulSet/Deployment для Controller Service — Controller обычно развёртывается с одной репликой (или несколькими для HA) и содержит сайдкары external-provisioner и external-attacher.
StorageClass — финальный шаг: создаём StorageClass, который указывает на наш CSI-драйвер через параметр provisioner.
Основные шаги развёртывания:
- Подготовка Docker-образа с CSI-драйвером.
- Создание namespace (обычно kube-system) и ServiceAccount.
- Настройка RBAC permissions.
- Развёртывание DaemonSet с Node Service и node-driver-registrar.
- Развёртывание Controller с сайдкарами provisioner/attacher.
- Создание StorageClass для использования драйвера.
- Тестирование с помощью PVC и тестового пода.
Разработка собственного CSI-драйвера — задача нетривиальная, но для простых сценариев (например, интеграции с корпоративным NAS или специфическим блочным хранилищем) вполне реализуемая. Для продакшен-окружений рекомендуется изучить существующие open-source реализации (например, NFS CSI driver или local-path-provisioner) и адаптировать их под свои нужды.
Практический сценарий: развёртывание приложения с постоянным хранилищем
Теория становится понятнее на практике, поэтому давайте пройдём весь процесс создания приложения с persistent storage от начала до конца. Мы создадим простое веб-приложение, которое сохраняет данные между перезапусками.
Шаг 1: Создание StorageClass
Предположим, мы работаем в облачном окружении AWS. Создаём файл storageclass.yaml:
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast-storage provisioner: ebs.csi.aws.com parameters: type: gp3 encrypted: "true" volumeBindingMode: WaitForFirstConsumer reclaimPolicy: Delete allowVolumeExpansion: true
Применяем конфигурацию:
kubectl apply -f storageclass.yaml kubectl get storageclass
Шаг 2: Создание PVC
Теперь запрашиваем хранилище через pvc.yaml:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: app-storage namespace: default spec: accessModes: - ReadWriteOnce storageClassName: fast-storage resources: requests: storage: 10Gi
Применяем и проверяем статус:
kubectl apply -f pvc.yaml kubectl get pvc app-storage
На этом этапе PVC будет в состоянии Pending — это нормально при использовании WaitForFirstConsumer. Том создастся только после запуска пода.
Шаг 3: Создание Pod с примонтированным хранилищем
Создаём pod.yaml с простым nginx-приложением:
apiVersion: v1 kind: Pod metadata: name: web-app spec: containers: - name: nginx image: nginx:latest volumeMounts: - name: data mountPath: /usr/share/nginx/html volumes: - name: data persistentVolumeClaim: claimName: app-storage
Запускаем:
kubectl apply -f pod.yaml
Шаг 4: Проверка статуса тома
Теперь можем проверить, что произошло:
# Проверяем статус PVC -- должен быть Bound kubectl get pvc app-storage # Проверяем созданный PV kubectl get pv # Смотрим детали пода kubectl describe pod web-app
В выводе kubectl describe pvc app-storage в секции Events увидим создание тома, а в kubectl get pv появится новый PersistentVolume, автоматически созданный provisioner’ом.
Шаг 5: Работа с данными в примонтированной директории
Проверим, что хранилище действительно работает:
# Заходим в контейнер kubectl exec -it web-app -- /bin/bash # Создаём тестовый файл echo "<h1>Persistent Data Test"> /usr/share/nginx/html/index.html # Проверяем содержимое cat /usr/share/nginx/html/index.html # Выходим exit
Теперь удалим под и создадим заново:
kubectl delete pod web-app kubectl apply -f pod.yaml # Ждём запуска нового пода kubectl wait --for=condition=Ready pod/web-app --timeout=60s # Проверяем, что данные сохранились kubectl exec -it web-app -- cat /usr/share/nginx/html/index.html
Файл index.html остался на месте — данные пережили удаление пода. Это и есть суть persistent storage: жизненный цикл данных отделён от жизненного цикла приложения.
Шаг 6: Очистка ресурсов
По завершении тестирования удаляем созданные ресурсы в обратном порядке:
kubectl delete pod web-app kubectl delete pvc app-storage # PV удалится автоматически благодаря reclaimPolicy: Delete kubectl delete storageclass fast-storage
Этот простой сценарий демонстрирует основной workflow работы с хранилищами в Kubernetes. В продакшене вместо отдельных Pod’ов вы, скорее всего, будете использовать StatefulSet для приложений, требующих постоянного хранилища, но принцип остаётся тем же: StorageClass определяет тип хранилища, PVC запрашивает ресурсы, а Pod использует их через volumeMounts.
Типичные ошибки и troubleshooting
При работе с хранилищами в Kubernetes неизбежно возникают проблемы. Рассмотрим наиболее частые ошибки и способы их диагностики.
PVC Pending
Симптомы: Persistent Volume Claim остаётся в состоянии Pending, том не создаётся.
Возможные причины и решения:
- Нет подходящего PV — проверьте, существуют ли PV с достаточным размером и совместимыми accessModes. Используйте kubectl get pv и сравните с требованиями PVC.
- Отсутствует StorageClass — убедитесь, что указанный storageClassName существует: kubectl get storageclass. Если класс не указан, проверьте наличие default StorageClass.
- Provisioner не работает — для динамического provisioning проверьте логи controller’а: kubectl logs -n kube-system deployment/ebs-csi-controller (или соответствующего вашему backend’у).
- WaitForFirstConsumer — если volumeBindingMode установлен в WaitForFirstConsumer, PVC намеренно ждёт создания пода. Это нормальное поведение, не ошибка.
Ошибки монтирования NFS
Симптомы: Pod находится в состоянии ContainerCreating, в Events видны ошибки вроде MountVolume.SetUp failed или mount.nfs: Connection timed out.
Диагностика и решения:
- Сетевая недоступность NFS-сервера — проверьте connectivity с ноды: ping nfs-server.example.com, затем попробуйте ручное монтирование.
- Отсутствует nfs-common — на нодах должен быть установлен NFS-клиент. На Ubuntu/Debian: apt-get install nfs-common, на CentOS/RHEL: yum install nfs-utils.
- Неверный путь экспорта — убедитесь, что путь в спецификации PV соответствует экспортированной директории на сервере: проверьте /etc/exports на NFS-сервере.
- Права доступа — проблемы с permissions часто возникают из-за root_squash. Попробуйте no_root_squash в конфигурации экспорта.
- Firewall блокирует трафик — убедитесь, что порты 2049 (NFS) и 111 (portmapper) доступны с нод кластера.
Неверный accessMode
Симптомы: PVC создан, но не связывается с PV, или под не может примонтировать том.
Причины:
- Несоответствие между PVC и PV — Persistent Volume Claim запрашивает ReadWriteMany, а доступные PV поддерживают только ReadWriteOnce. Проверьте kubectl describe pv и kubectl describe pvc.
- Backend не поддерживает режим — блочные устройства (iSCSI, RBD) физически не могут предоставить ReadWriteMany. Для RWX используйте файловые системы: NFS, CephFS, GlusterFS.
- Множественные поды пытаются использовать RWO — если два пода на разных нодах пытаются использовать один PVC с accessMode ReadWriteOnce, второй под зависнет. Решение: либо используйте RWX-хранилище, либо настройте pod affinity, чтобы поды запускались на одной ноде.
Проблемы с локальными PV (NodeAffinity)
Симптомы: Pod в состоянии Pending с сообщением 0/N nodes are available: X node(s) didn’t find available persistent volumes to bind.
Типичные проблемы:
- Отсутствует NodeAffinity — локальные PV обязательно должны содержать nodeAffinity. Проверьте манифест PV.
- Нода недоступна — под не может запуститься, если нода, указанная в NodeAffinity, выключена или имеет taints. Используйте kubectl get nodes для проверки статуса.
- Ошибка в имени ноды — опечатка в kubernetes.io/hostname в nodeAffinity приводит к тому, что под никогда не найдёт подходящую ноду. Сравните с реальными именами нод: kubectl get nodes -o wide.
- Путь не существует — директория, указанная в local.path, должна быть создана на ноде заранее. Зайдите на ноду и проверьте: ls -la /mnt/local-storage.
Общий совет по диагностике: всегда начинайте с команды kubectl describe для проблемного ресурса — в секции Events содержится подробная информация о причине ошибки. Для более глубокого анализа смотрите логи kubelet на соответствующей ноде: journalctl -u kubelet -f.
Заключение
В этой статье мы разобрали четыре ключевых абстракции, которые составляют основу системы хранения данных в Kubernetes. Давайте подведем итоги:
- Persistent storage в Kubernetes решает проблему эфемерности контейнеров. Он позволяет отделить жизненный цикл данных от жизненного цикла Pod и безопасно хранить состояние приложений.
- Persistent Volume и Persistent Volume Claim разделяют ответственность между администратором и разработчиком. Это упрощает управление хранилищами и снижает связность с конкретным backend.
- StorageClass автоматизирует выделение томов и делает работу с хранилищами масштабируемой. Особенно это важно в облачных и динамически растущих кластерах.
- Container Storage Interface обеспечивает единый стандарт интеграции систем хранения. Благодаря CSI Kubernetes может работать с любыми современными backend без изменений в ядре.
- Корректная настройка access modes, reclaim policy и nodeAffinity напрямую влияет на стабильность приложений. Большинство проблем с PVC Pending связано именно с этими параметрами.
Если вы только начинаете осваивать DevOps-инженерию, рекомендуем обратить внимание на подборку курсов по Devops. В них подробно разбираются kubernetes persistent volume, работа с PVC и StorageClass, а также есть теоретическая и практическая часть для закрепления навыков.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
100 отзывов
|
Цена
Ещё -5% по промокоду
115 000 ₽
|
От
9 583 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 января
Пн, Ср, 19:00-22:00 по МСК
|
Ссылка на курсПодробнее |
|
Девопс-инженер. Интенсив
|
Level UP
36 отзывов
|
Цена
78 990 ₽
|
От
26 330 ₽/мес
|
Длительность
4 месяца
|
Старт
20 января
|
Ссылка на курсПодробнее |
|
DevOps-инженер
|
Нетология
45 отзывов
|
Цена
с промокодом kursy-online
84 800 ₽
178 600 ₽
|
От
3 720 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 января
|
Ссылка на курсПодробнее |
|
Профессия DevOps-инженер
|
Skillbox
214 отзывов
|
Цена
Ещё -20% по промокоду
161 751 ₽
323 502 ₽
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
18 января
|
Ссылка на курсПодробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
98 отзывов
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 февраля
|
Ссылка на курсПодробнее |

Что такое спонсорство и как бренды получают от него выгоду
Что такое спонсорство, почему бренды вкладываются в мероприятия и как превратить логотип на афише в мощный маркетинговый актив? Рассказываем без воды.

Что такое мобильное обучение
Мобильное обучение — это не просто тренд, а реальный инструмент для развития сотрудников и личного роста. Хотите понять, как внедрить его быстро и эффективно, избегая типичных ошибок? Здесь вы найдёте практические советы, примеры и проверенные методы.

Что такое OLAP и зачем он нужен
Хотите понять, что скрывается за аббревиатурой OLAP? Мы расскажем простыми словами, как работает многомерный анализ, чем OLAP отличается от OLTP и какие реальные задачи он решает.

Ребрендинг компании: что это такое и как его сделать
Ребрендинг — это не просто новый логотип. Когда действительно стоит менять облик компании? Разберёмся, зачем и как бизнесы делают ребрендинг, и что важно учесть на каждом этапе.