Как использовать библиотеку BeautifulSoup4 в Python для веб-парсинга: пошаговое руководство
В современном мире данных автоматизация сбора информации из веб-источников стала неотъемлемой частью работы разработчиков, аналитиков и маркетологов. Мы живем в эпоху, когда ценность информации определяется не только её качеством, но и скоростью получения. Именно здесь на помощь приходит веб-парсинг — технология, которая позволяет извлекать структурированные данные из HTML-страниц автоматически.

BeautifulSoup4 представляет собой одну из наиболее популярных Python-библиотек для веб-скрейпинга, и это неслучайно. Её элегантный API и интуитивно понятный синтаксис делают процесс парсинга доступным даже для начинающих разработчиков. В то же время библиотека обладает достаточной мощностью для решения сложных задач извлечения данных.
В этом руководстве мы рассмотрим все ключевые аспекты работы с BeautifulSoup4 — от базовых принципов HTTP-взаимодействия до практических примеров парсинга реальных сайтов. Особое внимание уделим не только техническим вопросам, но и этическим аспектам веб-скрейпинга, которые становятся все более актуальными в контексте современного законодательства о защите данных.
- Что такое веб-парсинг и зачем он нужен
- Основы работы веб-парсинга: HTTP и форматы данных
- Пример простого GET-запроса
- Примеры форматов
- Библиотека BeautifulSoup: что это и в чем её преимущества
- Подготовка окружения и установка библиотек
- Как анализировать HTML-код перед парсингом
- Основные возможности BeautifulSoup на практике
- Навигация по DOM-дереву
- Изменение HTML-структуры
- Очистка и форматирование данных
- Пошаговый пример: парсинг температуры с сайта
- Расширенные возможности: динамический контент и Selenium
- Типичные сценарии применения Selenium:
- Где можно применить BeautifulSoup в реальных проектах
- Заключение
- Рекомендуем посмотреть курсы по Python
Что такое веб-парсинг и зачем он нужен
Веб-парсинг (web scraping) — это процесс автоматизированного извлечения данных с веб-страниц с последующим преобразованием их в структурированный формат для дальнейшего анализа или использования. По сути, мы имеем дело с программным эмулированием действий человека, который вручную копирует информацию с сайтов, только в тысячи раз быстрее и точнее.
Сферы применения веб-парсинга охватывают практически все области современного бизнеса и исследований:
- Маркетинг и конкурентная разведка. Компании используют парсинг для мониторинга цен конкурентов, анализа их ассортимента и маркетинговых стратегий. Например, ретейлеры автоматически собирают данные о ценах на товары с сайтов конкурентов для динамической корректировки своих прайс-листов.
- Финансовая аналитика. Инвестиционные компании парсят новостные ленты, биржевые сводки и отчеты компаний для принятия торговых решений. Алгоритмические трейдеры используют эти данные для автоматической торговли на основе новостного фона.
- Научные исследования. Социологи и лингвисты собирают данные из социальных сетей для анализа общественного мнения, исследователи медицины парсят научные публикации для мета-анализов.
- SEO и контент-маркетинг. Специалисты анализируют контентные стратегии конкурентов, отслеживают позиции в поисковых системах, собирают идеи для создания собственного контента.
Веб-парсинг позволяет извлекать различные типы данных: текстовый контент (статьи, описания товаров), метаданные (цены, рейтинги, даты), мультимедиа-ссылки (изображения, видео), структурированные данные (таблицы, списки) и навигационную информацию (ссылки между страницами).
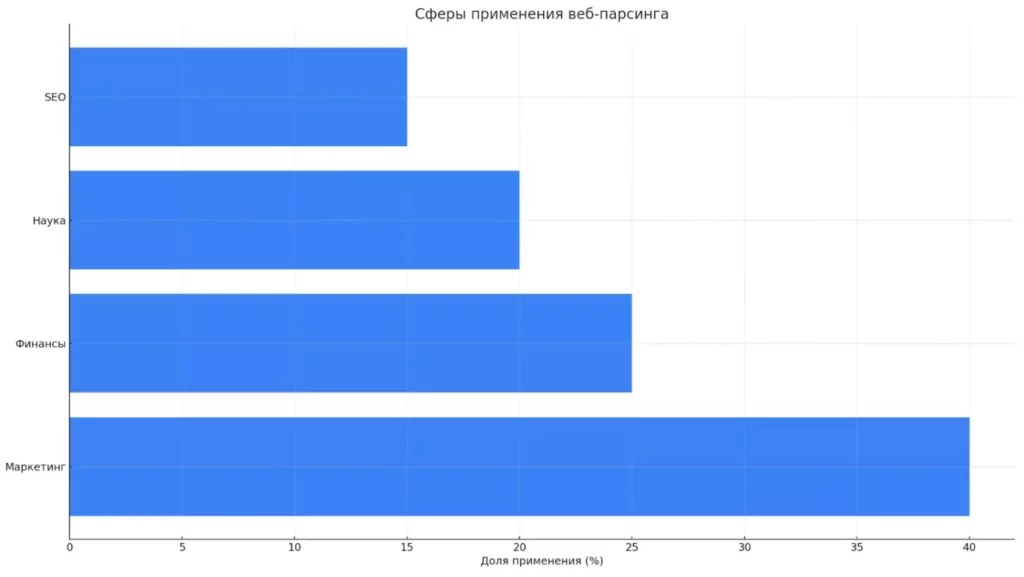
Горизонтальная диаграмма показывает примерное распределение сфер, где веб-парсинг применяется чаще всего. Маркетинг лидирует, за ним следуют финансы, наука и SEO.
Однако существуют серьезные ограничения, которые необходимо учитывать. Правовые аспекты становятся все более строгими — многие сайты явно запрещают автоматический сбор данных в своих пользовательских соглашениях. Технические защитные механизмы включают CAPTCHA, системы обнаружения ботов, ограничения частоты запросов и динамическую генерацию контента через JavaScript. Постоянные изменения в HTML-структуре сайтов требуют регулярного обновления парсеров.
Основы работы веб-парсинга: HTTP и форматы данных
Прежде чем погружаться в практику парсинга, важно понимать, как устроено взаимодействие между клиентом и сервером в сети. Веб-парсинг базируется на том же протоколе HTTP (HyperText Transfer Protocol), который используют браузеры для загрузки веб-страниц.
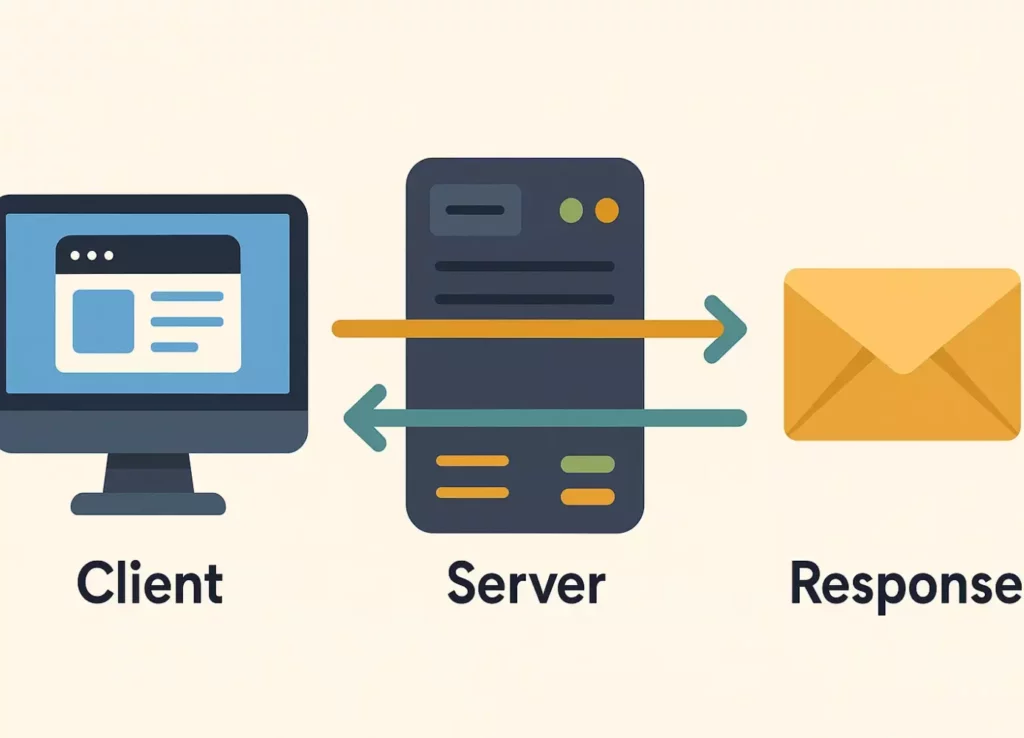
Схема демонстрирует классическое взаимодействие парсера с сервером: запрос по HTTP, обработка на стороне сервера и получение ответа для дальнейшего анализа.
Схема HTTP-взаимодействия
Схема HTTP-взаимодействия следует классической клиент-серверной архитектуре. Клиент (наш парсер) формирует запрос (request) и отправляет его на сервер. Сервер обрабатывает запрос, генерирует ответ (response) и передает его обратно клиенту. Весь этот цикл происходит за доли секунды.
Структура HTTP-запроса состоит из трех компонентов:
- Строка запроса содержит метод (GET, POST, PUT и др.), путь к ресурсу и версию протокола.
- Заголовки включают метаданные запроса: тип браузера, поддерживаемые форматы, cookies.
- Тело сообщения используется для передачи данных (например, при POST-запросах).
Пример простого GET-запроса
GET /weather/moscow HTTP/1.1 Host: example.com User-Agent: Mozilla/5.0 (compatible; ParserBot/1.0) Accept: text/html
В контексте парсинга мы чаще всего работаем с тремя форматами данных:
- HTML — основной формат веб-страниц, использующий систему тегов для структурирования контента. Именно HTML-код мы анализируем с помощью BeautifulSoup.
- XML — более строгий формат разметки, часто используемый для API и структурированного обмена данными. Отличается обязательным закрытием тегов и четкой иерархией.
- JSON — легковесный формат обмена данными, основанный на JavaScript, но независимый от языка программирования. Широко используется в современных веб-API.
Примеры форматов
JSON
{"temperature": 15, "city": "Moscow", "humidity": 65}
XML
<weather>
<temperature>15</temperature>
<city>Moscow</city>
</weather>
Выбор подходящего формата зависит от источника данных и конкретной задачи. HTML парсим для извлечения информации с веб-страниц, JSON — при работе с API, XML — для обмена структурированными данными между системами.
Библиотека BeautifulSoup: что это и в чем её преимущества
BeautifulSoup представляет собой Python-библиотеку для парсинга HTML и XML документов, которая превращает сложный процесс анализа разметки в интуитивно понятные операции. Название библиотеки отсылает к известной фразе из «Алисы в стране чудес» Льюиса Кэрролла — намек на способность инструмента разбираться даже в самом «запутанном» коде.

Иллюстрация символизирует баланс между простотой и мощностью, который делает BeautifulSoup оптимальным выбором для большинства задач парсинга.
Ключевые преимущества BeautifulSoup:
- Простота использования. Библиотека предоставляет элегантный API, который позволяет находить элементы HTML так же естественно, как мы бы описали их словами. Вместо сложных регулярных выражений можно использовать простые методы типа find(‘div’, class_=’content’).
- Гибкость в поиске. BeautifulSoup поддерживает множество способов поиска элементов: по тегам, классам, идентификаторам, атрибутам, содержимому текста и даже по CSS-селекторам. Это дает разработчику свободу выбора наиболее подходящего подхода для каждой конкретной задачи.
- Работа со сложными структурами. Библиотека отлично справляется с вложенными тегами, некорректно сформированным HTML и различными кодировками. Встроенный парсер автоматически исправляет многие ошибки в разметке, с которыми можно столкнуться на реальных сайтах.
- Толерантность к ошибкам. В отличие от строгих XML-парсеров, BeautifulSoup спокойно работает с «грязным» HTML — незакрытыми тегами, отсутствующими атрибутами, смешанными кодировками.
Однако важно понимать, когда стоит выбрать BeautifulSoup, а когда — альтернативные решения. Для простого и среднего по сложности парсинга BeautifulSoup является оптимальным выбором. Если требуется максимальная производительность при обработке больших объемов данных, стоит рассмотреть lxml — более быструю, но менее удобную библиотеку. Для масштабных проектов парсинга с необходимостью обхода тысяч страниц, управления сессиями и обработки JavaScript лучше подойдет фреймворк Scrapy.
BeautifulSoup занимает золотую середину между простотой использования и функциональностью, что делает её идеальным инструментом для изучения основ веб-парсинга и решения повседневных задач извлечения данных.
Подготовка окружения и установка библиотек
Прежде чем приступить к практике парсинга, необходимо подготовить рабочее окружение. Мы рассмотрим несколько вариантов настройки, подходящих для разных уровней подготовки и предпочтений разработчика.
Установка необходимых библиотек.
pip install beautifulsoup4 pip install requests pip install lxml
BeautifulSoup4 — основная библиотека для парсинга, requests — для выполнения HTTP-запросов к веб-серверам, lxml — высокопроизводительный парсер, который значительно ускоряет обработку больших HTML-документов.
Варианты рабочего окружения:
- Локальная установка Python. Классический подход предполагает установку Python на собственный компьютер с последующим использованием командной строки, IDE (PyCharm, VSCode) или Jupyter Notebook. Этот вариант обеспечивает максимальную гибкость и производительность.
- Облачные решения. Google Colab предоставляет готовую среду разработки с предустановленными библиотеками, доступную через браузер. Особенно удобен для экспериментов и обучения, не требует настройки локального окружения.
- Онлайн-редакторы. Сервисы типа JupyterLite или CodePen позволяют писать и запускать код прямо в браузере, хотя имеют ограничения по функциональности.
Импорт библиотек в Python-скрипте:
from bs4 import BeautifulSoup import requests import time # для пауз между запросами import json # для работы с JSON-данными from urllib.parse import urljoin, urlparse # для работы с URL
Рекомендуется создать отдельную виртуальную среду для проектов парсинга, чтобы избежать конфликтов зависимостей:
python -m venv parsing_env source parsing_env/bin/activate # Linux/Mac parsing_env\Scripts\activate # Windows
После активации виртуальной среды можно устанавливать библиотеки, не опасаясь влияния на другие Python-проекты.
Как анализировать HTML-код перед парсингом
Успешный парсинг начинается с тщательного анализа структуры HTML-кода целевой веб-страницы. Этот этап критически важен — без понимания архитектуры документа невозможно написать эффективный парсер. Давайте рассмотрим систематический подход к исследованию HTML-структуры.
Открытие инспектора элементов.
Современные браузеры предоставляют мощные инструменты разработчика, доступные через горячие клавиши: F12 в большинстве браузеров, Ctrl+Shift+I в Chrome/Firefox на Windows, или ⌥⌘I в Chrome/Safari на macOS. Инспектор открывает панель с несколькими вкладками, где вкладка «Elements» содержит интерактивное представление HTML-кода страницы.
Поиск целевых элементов.
Основная задача — найти HTML-элементы, содержащие нужную информацию, и определить их уникальные характеристики (теги, классы, атрибуты). Эффективная стратегия включает:
- Визуальная навигация: наведение курсора на элементы в инспекторе подсвечивает соответствующие области на странице
- Поиск по содержимому: использование Ctrl+F в инспекторе для поиска конкретного текста в HTML-коде
- Анализ иерархии: изучение родительских и дочерних элементов для понимания структуры
Практический пример: анализ блока температуры на Яндекс.Погоде.
- Идентификация целевого элемента: находим на странице отображение температуры
- Трассировка в HTML: используя инспектор, находим соответствующий тег — например, <span class=»temp__value»>
- Анализ селекторов: определяем, является ли класс temp__value уникальным или встречается в других местах страницы
- Проверка стабильности: обновляем страницу несколько раз, чтобы убедиться, что структура и классы остаются неизменными
Ключевые моменты анализа:
- Уникальность селекторов: предпочтительно использовать ID (уникальны по определению) или специфичные классы
- Стабильность структуры: некоторые сайты используют динамически генерируемые классы, которые изменяются при каждом обновлении
- Вложенность данных: часто целевая информация находится внутри нескольких уровней тегов
Грамотный анализ HTML-структуры на этапе подготовки сэкономит значительное время при написании кода парсера и поможет избежать ошибок, связанных с неточными селекторами.
Основные возможности BeautifulSoup на практике
Извлечение информации
BeautifulSoup предоставляет интуитивно понятные методы для поиска и извлечения элементов из HTML-документа. Основу функциональности составляют методы find() и find_all(), которые позволяют находить элементы по различным критериям.
Поиск по тегам — самый базовый способ навигации:
from bs4 import BeautifulSoup
# Поиск первого элемента определенного тега
title = soup.find('title')
first_paragraph = soup.find('p')
# Поиск всех элементов определенного тега
all_links = soup.find_all('a')
all_images = soup.find_all('img')
Поиск по атрибутам предоставляет более точный контроль:
# Поиск по ID (уникальный идентификатор)
header = soup.find('div', id='main-header')
# Поиск по классу CSS
content = soup.find('div', class_='content') # Обратите внимание: class_ с подчеркиванием!
# Поиск по любым атрибутам
external_links = soup.find_all('a', target='_blank')
required_inputs = soup.find_all('input', required=True)
# Поиск по множественным атрибутам
specific_div = soup.find('div', {'class': 'article', 'data-type': 'news'})
Комбинированный поиск для сложных селекторов:
# Поиск элементов с несколькими классами
elements = soup.find_all('div', class_=['primary', 'featured'])
# Поиск по частичному совпадению атрибута
price_elements = soup.find_all('span', class_=lambda x: x and 'price' in x)
# CSS-селекторы (аналогично jQuery)
products = soup.select('.product-card .price')
navigation = soup.select('#header ul li a')
Извлечение текстового содержимого:
# Получение только текста без HTML-тегов
element = soup.find('h1', class_='title')
clean_text = element.text # или element.get_text()
# Получение атрибутов элементов
link = soup.find('a')
url = link.get('href') # или link['href']
link_text = link.text
# Получение всех атрибутов элемента
image = soup.find('img')
all_attributes = image.attrs # возвращает словарь
Продвинутые методы поиска:
# Поиск по содержимому текста
elements = soup.find_all(text='Специальное предложение')
# Поиск по регулярным выражениям
import re
phone_pattern = re.compile(r'\+7\(\d{3}\)\d{3}-\d{2}-\d{2}')
phone_elements = soup.find_all('span', text=phone_pattern)
# Функциональные селекторы
def has_price_class(tag):
return tag.has_attr('class') and any('price' in cls for cls in tag['class'])
price_tags = soup.find_all(has_price_class)
Эти методы покрывают подавляющее большинство задач по извлечению информации из HTML-документов. Ключевое преимущество BeautifulSoup — возможность комбинировать различные подходы для достижения максимальной точности при поиске нужных элементов.
Навигация по DOM-дереву
BeautifulSoup предоставляет удобные способы перемещения по иерархической структуре HTML-документа, что особенно полезно когда нужные данные расположены относительно найденного элемента, но не имеют собственных уникальных идентификаторов.
Навигация к дочерним элементам:
# Получение всех прямых дочерних элементов
parent_div = soup.find('div', class_='container')
direct_children = parent_div.children # генератор
children_list = list(parent_div.children) # преобразование в список
# Получение всех потомков (включая вложенные)
all_descendants = parent_div.descendants
# Поиск конкретного дочернего элемента
first_child = parent_div.find('p') # первый абзац внутри div
Навигация к родительским элементам:
# Найти родительский элемент
price_span = soup.find('span', class_='price')
product_card = price_span.parent # непосредственный родитель
# Поиск конкретного родителя вверх по иерархии
article_parent = price_span.find_parent('article')
container_parent = price_span.find_parent('div', class_='container')
# Получение всех родительских элементов до корня
all_parents = list(price_span.parents)
Навигация между соседними элементами:
# Следующий и предыдущий элемент на том же уровне
current_element = soup.find('li', class_='active')
next_item = current_element.next_sibling
previous_item = current_element.previous_sibling
# Поиск следующих/предыдущих элементов определенного типа
next_li = current_element.find_next_sibling('li')
previous_link = current_element.find_previous_sibling('a')
# Получение всех соседних элементов
all_next_siblings = current_element.find_next_siblings()
all_previous_siblings = current_element.find_previous_siblings()
Эти методы навигации особенно эффективны при парсинге таблиц, списков или карточек товаров, где данные структурированы предсказуемым образом, но не всегда имеют уникальные идентификаторы.
Изменение HTML-структуры
BeautifulSoup позволяет не только читать, но и модифицировать HTML-документы, что полезно для очистки данных, создания отчетов или подготовки контента для дальнейшей обработки.
Создание новых элементов:
# Создание нового тега
new_paragraph = soup.new_tag('p')
new_paragraph.string = 'Новый абзац текста'
# Создание тега с атрибутами
new_link = soup.new_tag('a', href='https://example.com', target='_blank')
new_link.string = 'Внешняя ссылка'
# Создание тега с классами
new_div = soup.new_tag('div', **{'class': 'highlight important'})
Добавление элементов в документ:
# Добавление в конец родительского элемента
body = soup.find('body')
body.append(new_paragraph)
# Вставка в определенную позицию
container = soup.find('div', class_='content')
container.insert(0, new_div) # вставка в начало
# Вставка перед/после определенного элемента
target_element = soup.find('h2')
target_element.insert_before(new_paragraph)
target_element.insert_after(new_link)
Модификация существующих элементов:
# Изменение текстового содержимого
heading = soup.find('h1')
heading.string = 'Обновленный заголовок'
# Изменение атрибутов
image = soup.find('img')
image['src'] = 'new-image.jpg'
image['alt'] = 'Обновленное описание'
# Добавление CSS-классов
element = soup.find('div')
if 'class' in element.attrs:
element['class'].append('new-class')
else:
element['class'] = ['new-class']
Удаление элементов:
# Полное удаление элемента из документа
unwanted_div = soup.find('div', class_='advertisement')
unwanted_div.decompose() # освобождает память
# Альтернативный способ удаления
unwanted_element = soup.find('script')
unwanted_element.extract() # возвращает удаленный элемент
Эти возможности модификации делают BeautifulSoup универсальным инструментом не только для извлечения, но и для преобразования HTML-контента.
Очистка и форматирование данных
Одной из частых задач при веб-парсинге является очистка извлеченных данных от лишних HTML-тегов и форматирование результата для удобного использования. BeautifulSoup предоставляет несколько полезных методов для решения этих задач.
Извлечение чистого текста:
# Базовое извлечение текста без HTML-тегов
article = soup.find('div', class_='article-content')
clean_text = article.get_text()
# Управление разделителями при извлечении текста
clean_text_with_spaces = article.get_text(separator=' ')
clean_text_with_newlines = article.get_text(separator='\n')
# Удаление лишних пробелов и переносов строк
import re
cleaned_text = re.sub(r'\s+', ' ', clean_text).strip()
Структурированное форматирование HTML:
# Красивое форматирование HTML с отступами
formatted_html = soup.prettify()
print(formatted_html)
# Форматирование конкретного элемента
specific_element = soup.find('div', class_='product-info')
formatted_element = specific_element.prettify()
# Контроль кодировки при выводе
formatted_html_utf8 = soup.prettify(encoding='utf-8')
Методы очистки и форматирования особенно важны при подготовке данных для анализа или сохранения в структурированные форматы типа CSV или JSON. Правильная очистка данных на этапе парсинга существенно упрощает их дальнейшую обработку и анализ.
Пошаговый пример: парсинг температуры с сайта
Давайте рассмотрим полный цикл создания парсера на практическом примере извлечения информации о погоде. Этот пример демонстрирует все основные этапы: от подключения библиотек до получения финального результата.
Шаг 1. Подключение библиотек и подготовка:
from bs4 import BeautifulSoup
import requests
import time
# Настройка headers для имитации браузера
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
Шаг 2. Выполнение HTTP-запроса:
# URL страницы с прогнозом погоды
url = 'https://yandex.ru/weather/moscow'
try:
# Отправка запроса с заголовками
response = requests.get(url, headers=headers)
response.raise_for_status() # проверка успешности запроса
print(f"Статус запроса: {response.status_code}")
print(f"Размер полученных данных: {len(response.text)} символов")
except requests.exceptions.RequestException as e:
print(f"Ошибка при выполнении запроса: {e}")
exit()
Шаг 3. Создание объекта BeautifulSoup:
# Парсинг HTML-кода страницы
soup = BeautifulSoup(response.text, 'lxml')
# Проверка корректности парсинга
title = soup.find('title')
print(f"Заголовок страницы: {title.text if title else 'Не найден'}")
Шаг 4. Извлечение целевых данных:
# Поиск элемента с текущей температурой
# (селектор может отличаться в зависимости от структуры сайта)
temp_element = soup.find('span', class_='temp__value temp__value_with-unit')
if temp_element:
current_temp = temp_element.get_text()
print(f"Текущая температура: {current_temp}")
else:
print("Элемент с температурой не найден")
# Поиск дополнительной информации
condition_element = soup.find('div', class_='link__condition day-anchor')
if condition_element:
weather_condition = condition_element.get_text()
print(f"Погодные условия: {weather_condition}")
Шаг 5. Обработка и форматирование результата:
# Создание структурированного результата
weather_data = {
'temperature': current_temp if temp_element else 'Не найдено',
'condition': weather_condition if condition_element else 'Не найдено',
'timestamp': time.strftime('%Y-%m-%d %H:%M:%S')
}
print("Итоговые данные о погоде:")
for key, value in weather_data.items():
print(f"{key}: {value}")
Этот пример демонстрирует полный цикл парсинга: от первоначального запроса до получения структурированных данных. Важно отметить использование обработки ошибок, проверки существования элементов и форматирования результата для дальнейшего использования.
Расширенные возможности: динамический контент и Selenium
При всех достоинствах BeautifulSoup, существуют ситуации, когда её возможностей оказывается недостаточно для решения задач парсинга. Современные веб-приложения все чаще используют технологии, которые создают контент динамически, что требует более продвинутых подходов.
Ограничения BeautifulSoup становятся очевидными при работе с:
- JavaScript-генерируемым контентом: многие сайты загружают данные асинхронно через AJAX-запросы после загрузки основной HTML-страницы
- Single Page Applications (SPA): приложения на React, Vue.js или Angular, где весь контент формируется на стороне клиента
- Защитными механизмами: сайты с обнаружением ботов, CAPTCHA или сложными системами авторизации
- Интерактивными элементами: контент, появляющийся при наведении, клике или прокрутке страницы
В таких случаях BeautifulSoup получает лишь «скелет» HTML-страницы без реального содержимого, поскольку данные подгружаются уже после первоначальной загрузки.

Сравнение времени выполнения показывает, что Selenium значительно медленнее при парсинге, чем BeautifulSoup. Это важно учитывать при выборе инструментов для больших объёмов данных.
Selenium как решение предоставляет принципиально иной подход — полноценную автоматизацию браузера. Библиотека управляет реальным экземпляром браузера (Chrome, Firefox, Safari), что позволяет:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Инициализация браузера
driver = webdriver.Chrome()
try:
# Переход на страницу
driver.get('https://example.com/dynamic-content')
# Ожидание загрузки динамического контента
wait = WebDriverWait(driver, 10)
element = wait.until(
EC.presence_of_element_located((By.CLASS_NAME, 'dynamic-data'))
)
# Получение HTML после загрузки JavaScript
html_content = driver.page_source
# Дальнейшая обработка с помощью BeautifulSoup
soup = BeautifulSoup(html_content, 'lxml')
finally:
driver.quit()
Типичные сценарии применения Selenium:
- Авторизация на сайте с последующим парсингом закрытых разделов
- Имитация пользовательских действий: клики, прокрутка, ввод текста в формы
- Обход простых защитных механизмов через имитацию человеческого поведения
- Скриншоты страниц для визуального контроля работы парсера
Комбинация Selenium + BeautifulSoup представляет собой мощный инструментарий: Selenium обеспечивает доступ к динамическому контенту, а BeautifulSoup — удобный парсинг полученного HTML. Однако стоит учитывать, что использование Selenium значительно увеличивает потребление ресурсов и время выполнения операций по сравнению с простыми HTTP-запросами.
Подробную документацию и примеры использования Selenium можно найти на официальном сайте selenium-python.readthedocs.io, где представлены все аспекты автоматизации браузера для задач парсинга и тестирования.
Где можно применить BeautifulSoup в реальных проектах
Понимание теоретических основ парсинга — это только первый шаг. Рассмотрим конкретные области применения BeautifulSoup, где эта технология решает реальные бизнес-задачи и создает измеримую ценность.
- Мониторинг цен и конкурентная разведка. E-commerce компании используют парсеры для отслеживания ценовых стратегий конкурентов в режиме реального времени. Автоматизированные системы собирают данные о стоимости аналогичных товаров, позволяя динамически корректировать собственные прайс-листы. Например, интернет-магазин электроники может ежедневно парсить цены на популярные модели смартфонов с сайтов основных конкурентов, автоматически формируя отчеты о рыночной ситуации.
- Агрегация новостей и контент-анализ. Медиа-компании и аналитические агентства создают системы мониторинга информационного поля, собирая новости с сотен источников по определенным тематикам. BeautifulSoup извлекает заголовки, тексты статей, даты публикации и метаданные, формируя единую базу для дальнейшего анализа тональности, выявления трендов или подготовки сводок.
- Сбор данных для исследований и аналитики. Маркетинговые агентства парсят социальные сети, форумы и отзывы для анализа потребительских предпочтений. Исследовательские компании собирают данные с государственных порталов, статистических ресурсов и отраслевых сайтов для подготовки аналитических отчетов. Научные организации используют парсинг для мета-анализа публикаций и систематизации исследовательских данных.
- Контроль качества и тестирование веб-ресурсов. QA-инженеры применяют BeautifulSoup для автоматизированной проверки HTML-структуры сайтов: валидации наличия обязательных элементов, корректности метатегов, проверки работоспособности внутренних ссылок. Такие инструменты особенно ценны при поддержке крупных корпоративных сайтов с множеством разделов и частыми обновлениями контента.
Эти применения демонстрируют универсальность BeautifulSoup как инструмента для решения разнообразных задач автоматизации работы с веб-данными. Важно отметить, что во всех случаях необходимо соблюдать этические принципы и правовые требования при сборе информации из открытых источников.
Заключение
BeautifulSoup4 представляет собой элегантное решение для большинства задач веб-парсинга, сочетающее простоту освоения с достаточной функциональностью для профессиональных проектов. Мы рассмотрели весь цикл работы с библиотекой — от базовых принципов HTTP-взаимодействия до практических примеров извлечения данных из реальных веб-сайтов. Подведем итоги:
- BeautifulSoup — мощный инструмент для извлечения данных из HTML. Он сочетает простоту синтаксиса с гибкостью поиска элементов.
- Библиотека поддерживает работу с HTML и XML. Это позволяет использовать её в широком спектре задач — от парсинга сайтов до обработки структурированных данных.
- Использование BeautifulSoup требует понимания HTTP и структуры документа. Это повышает точность и устойчивость парсеров.
- Комбинация с requests и Selenium расширяет возможности. Можно обрабатывать динамические страницы и сложные сценарии.
- BeautifulSoup востребован в аналитике, маркетинге и исследованиях. Он помогает автоматизировать сбор данных и ускоряет работу специалистов.
Если вы только начинаете осваивать профессию веб-разработчика или аналитика данных, рекомендуем обратить внимание на подборку курсов по Python-разработке. В них есть как теоретическая база, так и практические задания, которые помогут быстро закрепить навыки работы с BeautifulSoup и другими инструментами.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

Hexlet vs Skillbox: что выгоднее по цене «за навык», если считать проекты и ревью?
Что лучше — Hexlet или Skillbox, если считать не цену курса, а результат? Где быстрее прокачать навыки, получить проекты в портфолио и не потерять деньги — разберём в статье.

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!