Как контейнеризировать приложение в Docker: пошаговая инструкция от подготовки кода до деплоя
Представьте ситуацию: вы написали приложение, оно прекрасно работает на вашей машине, но стоит развернуть его на сервере коллеги — и начинается магия в худшем смысле этого слова. То версия Python не та, то библиотеки конфликтуют, то переменные окружения настроены иначе, то вообще что-то загадочно падает с ошибкой, которую Google находит в трёх результатах на Stack Overflow, причём все три датированы 2014 годом и помечены как «unsolved». Знакомо? Вот именно поэтому контейнеризация — это не модный хайп из конференций а практичное решение проблем.

Система контейнеризации решает фундаментальную задачу: она превращает ваше приложение в самодостаточную единицу, которая несёт в себе всё необходимое для работы — код, зависимости, конфигурацию окружения. Контейнер — это, в первую очередь, артефакт поставки приложения. Вы собираете его один раз, и он будет запускаться одинаково везде: на вашем ноутбуке, на сервере в датацентре, в облаке у любого провайдера, на машине коллеги с Windows. Это избавляет от классического «а у меня работает» и позволяет сосредоточиться на разработке, а не на шаманских плясках с настройкой окружений. Кроме того, контейнеризация — это первый шаг к современным практикам CI/CD, оркестрации через Kubernetes и вообще ко всему тому, что делает деплой приложений предсказуемым и воспроизводимым процессом, а не актом веры в лучшее.
- Подготовка приложения к контейнеризации
- Создание Dockerfile: базовые инструкции и логика
- Сборка образа (docker build)
- Запуск контейнера (docker run)
- Проверка работоспособности и диагностика проблем
- Заключение
- Рекомендуем посмотреть курсы по обучению DevOps
Подготовка приложения к контейнеризации
Структура проекта
Прежде чем кидаться писать Dockerfile (а вы уже наверняка хотите, признайтесь), нужно привести проект в состояние, пригодное для упаковки. Изолированная среда — штука консервативная: она любит порядок, предсказуемость и минимализм. Поэтому сначала разберёмся со структурой.
Минимальная структура проекта для контейнеризации выглядит примерно так:
myapp/ ├── app.py # основной файл приложения ├── requirements.txt # список зависимостей Python ├── .dockerignore # что не копировать в сборку ├── Dockerfile # инструкция по сборке └── .env.example # пример файла с переменными окружения
Если у вас веб-приложение, то может быть ещё папка static/ для статики, templates/ для шаблонов, config/ для конфигов — в общем, всё зависит от проекта. Главное — чтобы корень проекта был чистым и понятным, без мусора вроде venv/, .git/, кеша IDE или случайных файлов test123.py, которые вы создали полгода назад и забыли удалить. Кстати, именно для этого и существует .dockerignore — но об этом чуть позже. Сейчас важно понять: структура должна быть логичной, потому что всё, что лежит в корне проекта, потенциально может попасть в сборку (если вы не настроите исключения), а итоговый пакет должен быть максимально лёгким и содержать только то, что действительно нужно для работы приложения.
Docker решает проблему «на моем компьютере работает»: приложение со всеми зависимостями упаковывается в единый контейнер, который гарантированно запускается одинаково в любой среде.
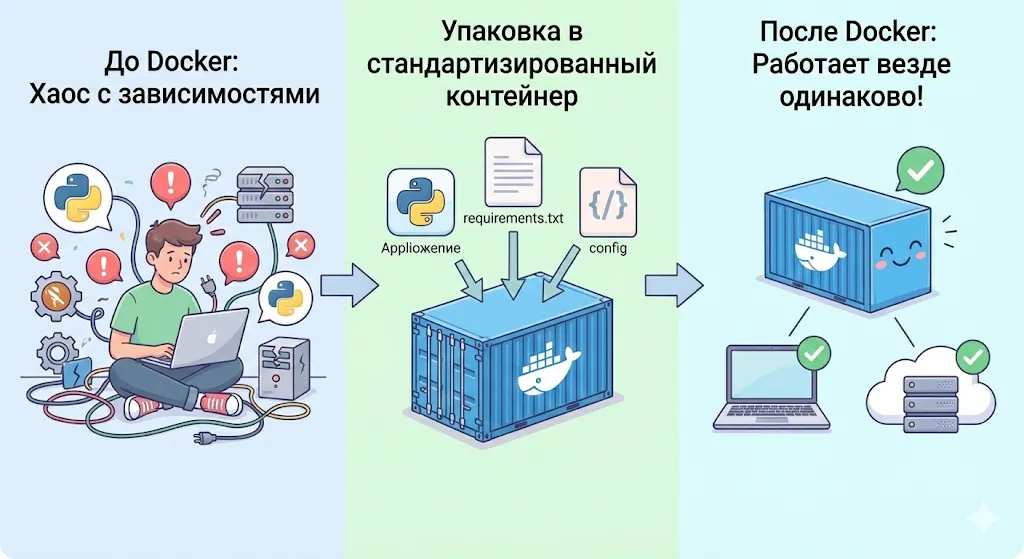
Иллюстрация принципа работы Docker: от проблем с зависимостями к универсальному контейнеру.
Docker решает проблему «на моем компьютере работает»: приложение со всеми зависимостями упаковывается в единый контейнер, который гарантированно запускается одинаково в любой среде.
Работа с зависимостями
Зависимости — это то, что превращает ваше приложение из беззаботного скрипта в нечто, требующее внимания и дисциплины. В мире контейнеров особенно важно фиксировать версии всех библиотек, потому что «установить последнюю версию flask» сегодня и через полгода — это два совершенно разных действия, которые могут привести к совершенно разным результатам (и один из них почти наверняка будет включать в себя сломанное приложение и ваши нервы).
Для Python стандартный подход — это файл requirements.txt. Создать его можно командой:
pip freeze > requirements.txt
Эта команда зафиксирует все установленные в текущем окружении пакеты с их точными версиями. Выглядеть это будет примерно так:
flask==3.0.0 requests==2.31.0 gunicorn==21.2.0
Почему важны версии? Потому что если вы напишете просто flask без указания версии, то при каждой пересборке система будет устанавливать самую свежую версию из PyPI, и в один прекрасный момент разработчики Flask выпустят breaking change, который положит ваше приложение. А вы даже не поймёте, что именно сломалось, потому что код-то вы не меняли. Фиксация версий — это воспроизводимость сборки, а воспроизводимость — это святое в мире контейнеров (и вообще в инженерии, если мы говорим о взрослых проектах, а не о pet-projects на коленке).
Конфигурация через переменные окружения
Хардкодить настройки в коде — это как татуировка: вроде кажется хорошей идеей, пока не понадобится что-то изменить. А в случае с контейнерами это вообще путь к страданиям, потому что один и тот же артефакт должен запускаться в разных окружениях (разработка, тестирование, продакшн), и каждый раз с разными настройками — разные базы данных, разные API-ключи, разные порты.
Правильный подход — выносить всё, что может меняться, в переменные окружения. Вместо того чтобы писать в коде DATABASE_URL = «postgresql://localhost:5432/mydb», вы пишете:
import os
DATABASE_URL = os.getenv('DATABASE_URL', 'postgresql://localhost:5432/mydb')
Второй параметр в getenv() — это значение по умолчанию, которое используется, если переменная не установлена (удобно для локальной разработки). Таким образом, один и тот же код будет работать и на вашей машине, и в изолированной среде, и на продакшене — просто с разными настройками, которые вы передадите через переменные окружения при запуске.
Для удобства можно создать файл .env.example с примерами всех необходимых переменных (только без реальных значений, естественно — секреты в Git не коммитим, это азы безопасности). А сам .env с реальными данными добавляем в .gitignore и .dockerignore, чтобы не светить чувствительную информацию где не надо.
Создание файла .dockerignore
Файл .dockerignore работает по тому же принципу, что и .gitignore, только для процесса сборки: он указывает, что не нужно копировать в итоговый пакет. Это критически важно, потому что без него вы рискуете затащить кучу мусора — виртуальные окружения, кеш, логи, временные файлы, .git (зачем истории коммитов?), и всё это раздует результат до неприличных размеров, а заодно замедлит процесс.
Создайте файл .dockerignore в корне проекта и добавьте туда:
- pycache/ — кеш Python.
- *.pyc, *.pyo, *.pyd — скомпилированные файлы Python.
- .Python — служебные файлы.
- venv/, env/, .venv/ — виртуальные окружения.
- .git/, .gitignore — Git-данные.
- .env — файлы с секретами (никогда не должны попадать!).
- *.log — логи.
- .DS_Store, Thumbs.db — системный мусор.
- README.md, docs/ — документация (если она не нужна для работы приложения).
- .pytest_cache/, .coverage — артефакты тестирования.
- *.sqlite, *.db — локальные базы данных.
Этот список можно дополнять в зависимости от проекта, но главное правило простое: в финальный артефакт должно попасть только то, что необходимо для работы приложения в продакшене, и ничего больше.
Создание Dockerfile: базовые инструкции и логика
Dockerfile — это рецепт сборки вашего контейнера, только вместо «взбить яйца» и «добавить муку» у вас будет «взять базу Python», «скопировать зависимости», «установить пакеты». По сути, это текстовый файл с инструкциями, которые платформа выполняет последовательно, создавая на каждом шаге новый слой. Можно сравнить это с инструкцией по сборке мебели из ИКЕА (только Dockerfile, в отличие от инструкций ИКЕА, обычно работает с первого раза, если вы не налажали с синтаксисом).
Каждая строка в Dockerfile — это команда, и система обрабатывает их строго по порядку. Изменили одну строку в середине файла? Все слои после неё пересоберутся заново. Поэтому важно понимать не только что писать, но и в каком порядке — это напрямую влияет на скорость сборки и размер итогового результата.
Выбор базового образа
Первая и самая важная инструкция в Dockerfile — это FROM. Она указывает, на основе чего вы будете строить свой контейнер. По сути, вы выбираете фундамент: можете взять полноценную Ubuntu и поставить туда всё руками, а можете взять готовый Python со всем предустановленным.
Для Python есть несколько официальных вариантов:
python:3.13 — полная версия (~1 ГБ), включает всё подряд python:3.13-slim — облегчённая версия (~150 МБ), без лишних пакетов python:3.13-alpine — минималистичная версия на базе Alpine Linux (~50 МБ)
Казалось бы, выбор очевиден — берём alpine и радуемся размеру. Но не всё так просто. Alpine использует musl вместо glibc, и некоторые Python-пакеты (особенно те, что содержат C-расширения) могут отказаться компилироваться или работать нестабильно. Для большинства задач оптимальный выбор — это python:3.13-slim: достаточно лёгкий, чтобы не раздувать результат, и достаточно полный, чтобы не возникало проблем с зависимостями.
И ещё один важный момент: никогда не используйте тег latest. Почему? Потому что latest — это не «самая стабильная версия», а просто «последняя собранная», и она может измениться в любой момент. Сегодня python:latest указывает на Python 3.13, через полгода — на 3.14, и ваш проект внезапно сломается. Всегда фиксируйте конкретную версию.

Сравнение «веса» разных базовых образов. Использование slim или alpine версий позволяет сократить размер итогового контейнера в 10–20 раз по сравнению с полной версией.
Добавление зависимостей и файлов проекта
После выбора базы нужно скопировать в неё файлы проекта и установить зависимости. Здесь работают две ключевые инструкции: COPY и RUN.
COPY делает именно то, что написано на упаковке — копирует файлы с вашей машины внутрь. Синтаксис простой: COPY <что_копировать> <куда_копировать>. Например, COPY requirements.txt . скопирует файл зависимостей в текущую рабочую директорию.
RUN выполняет команды внутри на этапе сборки. Чаще всего это установка пакетов через pip, apt-get или другие пакетные менеджеры. Например, RUN pip install -r requirements.txt установит все зависимости из файла.
А теперь важный момент: порядок имеет значение. Правильная последовательность выглядит так:
COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . .
Почему сначала копируем только requirements.txt, а не весь проект целиком? Потому что система кеширует слои. Если вы измените код приложения, но не тронете зависимости, будет использован закешированный слой с уже установленными пакетами, и их не придётся ставить заново. А если бы вы скопировали всё сразу (COPY . .), то любое изменение кода инвалидировало бы кеш, и зависимости пришлось бы устанавливать каждый раз с нуля. Это экономит кучу времени при разработке — установка всех пакетов может занимать минуты, а использование кеша — секунды.
Флаг —no-cache-dir в pip install отключает кеширование загруженных пакетов, что уменьшает размер итогового результата (зачем хранить кеш, если он одноразовый?).
Переменные окружения в Dockerfile
Инструкция ENV позволяет устанавливать переменные окружения прямо в Dockerfile. Синтаксис простой: ENV ИМЯ_ПЕРЕМЕННОЙ значение или ENV ИМЯ_ПЕРЕМЕННОЙ=значение. Эти переменные будут доступны как на этапе сборки (в последующих инструкциях RUN), так и во время работы экземпляра.
Типичные сценарии использования:
ENV PYTHONUNBUFFERED=1 ENV APP_HOME=/app ENV PORT=8000
PYTHONUNBUFFERED=1 — особенно важная штука для Python: она отключает буферизацию вывода, благодаря чему логи приложения появляются моментально, а не с задержкой (иначе вы будете смотреть в пустые логи и недоумевать, почему ничего не происходит, хотя на самом деле всё давно упало с ошибкой).
Важно понимать разницу: ENV задаёт переменные по умолчанию, которые можно переопределить при запуске через флаг -e. То есть если вы прописали ENV PORT=8000, но при запуске указали -e PORT=3000, то приоритет будет у значения из командной строки. Это удобно для разных окружений: в Dockerfile задаёте разумные дефолты для разработки, а в продакшене переопределяете через переменные окружения то, что нужно.
CMD и ENTRYPOINT: различия и примеры
CMD и ENTRYPOINT — две инструкции, которые определяют, что будет выполняться при запуске. На первый взгляд они делают одно и то же, но есть нюансы, которые важно понимать (иначе вы потратите полчаса на то, чтобы разобраться, почему ваша сборка игнорирует команды).
CMD — это команда по умолчанию. Если вы запустите просто как docker run myapp, выполнится то, что указано в CMD. Но если вы добавите свою команду (docker run myapp python other_script.py), то CMD будет полностью переопределён.
Пример:
CMD ["python", "app.py"]
ENTRYPOINT — это основная команда, которая выполняется всегда, и её нельзя переопределить просто так (только через флаг —entrypoint). А всё, что вы передаёте при запуске, становится аргументами к ENTRYPOINT.
Пример:
ENTRYPOINT ["python"] CMD ["app.py"]
В этом случае ENTRYPOINT задаёт исполнитель (python), а CMD — аргументы по умолчанию (app.py). Запустите docker run myapp — выполнится python app.py. Запустите docker run myapp other_script.py — выполнится python other_script.py (CMD переопределился, а ENTRYPOINT остался).
Когда что использовать?
Если ваша сборка делает одно конкретное действие (например, всегда запускает веб-приложение) — используйте CMD. Если это инструмент, которому нужно передавать разные параметры (например, CLI-утилита) — используйте ENTRYPOINT + CMD для гибкости.
Обе инструкции поддерживают два формата: exec-форму (список [«executable», «param1», «param2»]) и shell-форму (executable param1 param2). Предпочтительнее exec-форма, потому что она не запускает shell и позволяет корректно обрабатывать сигналы завершения.
Оптимизация Dockerfile и кеширование слоёв
Каждая инструкция в Dockerfile создаёт новый слой, и эти слои система кеширует — это одна из ключевых особенностей, которая делает сборку быстрой и эффективной (когда вы понимаете, как это работает) или мучительно медленной (когда не понимаете).
Представьте результат как слоёный пирог (да, опять кулинарные метафоры, но они работают). Каждая инструкция — это слой теста или начинки. Система запоминает каждый слой и при следующей сборке проверяет: изменился ли этот слой? Если нет — использует закешированную версию и не выполняет инструкцию заново. Если да — пересобирает этот слой и все последующие (потому что они могут зависеть от изменений).
Отсюда главное правило оптимизации: располагайте редко меняющиеся инструкции в начале Dockerfile, а часто меняющиеся — в конце. Зависимости меняются редко, код — часто. Поэтому сначала копируем requirements.txt и ставим пакеты, а только потом копируем весь проект. Изменили код? Только последний слой пересоберётся. Добавили зависимость? Пересоберутся все слои после установки пакетов, но это логично.
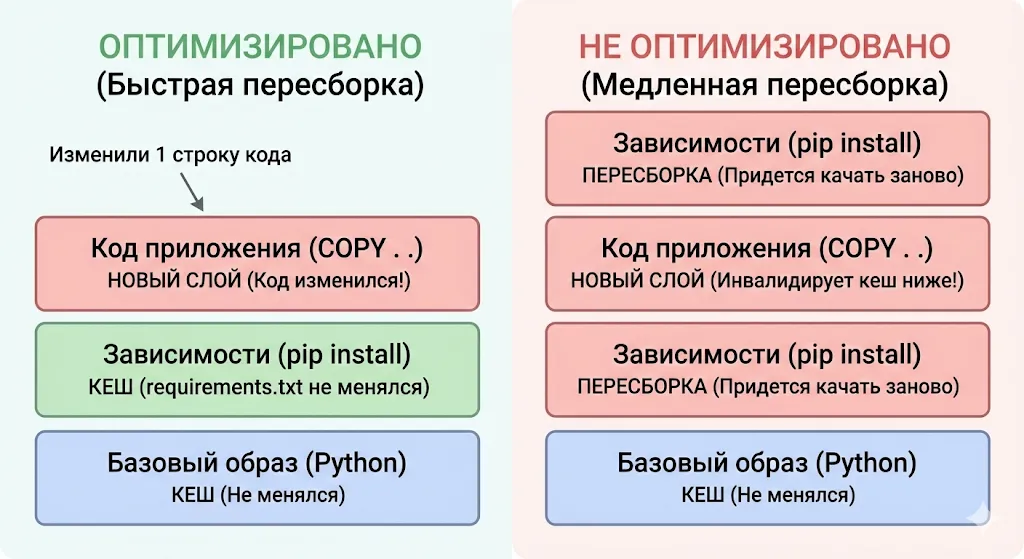
Слева — правильный порядок: тяжелые зависимости устанавливаются до копирования кода, поэтому они берутся из кеша. Справа — неправильный: любое изменение кода инвалидирует кеш и заставляет Docker переустанавливать все библиотеки заново.
Ещё один трюк — объединение RUN-команд. Вместо:
RUN apt-get update RUN apt-get install -y curl RUN apt-get clean
Пишите:
RUN apt-get update && \ apt-get install -y curl && \ apt-get clean && \ rm -rf /var/lib/apt/lists/*
Это создаст один слой вместо трёх, что уменьшит размер результата (промежуточные файлы не сохранятся в отдельных слоях). Плюс очистка кеша в той же команде гарантирует, что мусор не попадёт в финальную сборку.
Сборка образа (docker build)
Итак, Dockerfile написан, проект подготовлен, зависимости зафиксированы — пора собирать. Сборка — это процесс, в котором платформа берёт ваш Dockerfile, выполняет все инструкции по порядку и на выходе создаёт готовый артефакт, который можно запускать. Это как компиляция программы, только вместо исполняемого файла вы получаете самодостаточный пакет со всем необходимым внутри.
Базовая команда docker build
Команда сборки выглядит просто:
docker build -t myapp
Разберём по частям:
docker build — собственно, команда сборки -t myapp — флаг для тегирования (от слова «tag»). myapp — это имя вашего результата, по которому вы будете его запускать . — точка в конце указывает на контекст сборки, то есть директорию, из которой будут браться файлы (обычно это текущая директория, где лежит Dockerfile)
Контекст сборки — важная штука. Система отправляет все файлы из этой директории демону, поэтому если у вас в папке лежит гигабайт случайных файлов, процесс будет тормозить (именно для этого и нужен .dockerignore).
Полезные флаги:
- —no-cache — игнорировать кеш и пересобрать всё с нуля (нужно, если что-то пошло не так и вы хотите быть уверены, что сборка чистая).
- -f custom.Dockerfile — указать путь к Dockerfile, если он называется не стандартно или лежит в другой папке.
- —build-arg KEY=VALUE — передать аргументы сборки (переменные, которые доступны только на этапе сборки).
После запуска команды система начнёт выполнять инструкции из Dockerfile, и вы увидите вывод по каждому шагу. Если всё прошло успешно, в конце появится сообщение с ID.
Слои и кеш
Давайте разберёмся, что происходит внутри, потому что без понимания слоёв вы будете собирать по наитию, а это путь к страданиям (и к пересборкам, которые занимают по 10 минут вместо 10 секунд).
Результат — это не монолитный блок, а стопка слоёв, где каждый слой соответствует одной инструкции из Dockerfile. Представьте это как прозрачные плёнки, которые накладываются друг на друга: первая плёнка — базовый Python, вторая — установленные зависимости, третья — скопированный код приложения. Когда вы запускаете экземпляр, система берёт все эти слои, складывает их вместе, и получается файловая система.
Каждый слой неизменяемый (immutable) и кешируется. Если система видит, что инструкция не изменилась с прошлой сборки, она не выполняет её заново, а просто берёт готовый слой из кеша. Это работает быстро и экономит ресурсы — установка пакетов через pip install может занимать минуты, а использование кеша — доли секунды.
Но есть нюанс: как только один слой изменился, все последующие слои инвалидируются и пересобираются заново, даже если их инструкции не менялись. Именно поэтому порядок инструкций в Dockerfile так важен. Изменили одну строку кода в app.py? Если COPY . . стоит в конце — пересоберётся только последний слой. Если в начале — пересоберётся всё, включая установку зависимостей, хотя они не менялись.
Система кеширует слои локально, поэтому если вы собираете на CI/CD-сервере, который каждый раз поднимается с нуля, кеша там не будет. Для таких случаев существуют продвинутые техники вроде —cache-from, но это уже тема для отдельного разговора (или для того момента, когда вы дорастёте до серьёзного CI/CD).
Версионирование и теги
Тег — это метка, которую вы присваиваете, чтобы различать разные версии. Когда вы запускаете docker build -t myapp, вы создаёте артефакт с тегом latest по умолчанию (полное имя будет myapp:latest). Это удобно для разработки, но совершенно неприемлемо для продакшена, потому что latest — это как надпись «свежее» на продуктах: вы не знаете, что именно там внутри и когда это было упаковано.
Правильный подход — явно указывать версии:
docker build -t myapp:1.0.0 . docker build -t myapp:1.0.0 -t myapp:1.0 -t myapp:latest .
Второй пример показывает, как присвоить несколько тегов одной сборке за один раз. Это удобно для семантического версионирования: тег 1.0.0 указывает на конкретную версию, 1.0 — на последнюю патч-версию в ветке 1.0.x, а latest — ну, вы поняли, на самую свежую (хотя лучше от него вообще отказаться в продакшене).
Можно использовать и другие схемы тегирования: дату сборки (myapp:2025-12-27), номер коммита (myapp:a3f5b2c), номер сборки в CI/CD (myapp:build-482). Главное — чтобы по тегу было понятно, что это за версия, и можно было воспроизвести сборку или откатиться на предыдущую версию, если что-то пошло не так.
В продакшене всегда деплойте конкретные версии, а не latest. Иначе в один прекрасный момент на разных серверах окажутся разные версии приложения, и вы будете часами искать баг, который воспроизводится только на одном сервере (спойлер: там просто другая версия).
Запуск контейнера (docker run)
Сборка готова, протегирована, лежит в локальном хранилище и ждёт своего часа. Но это всего лишь шаблон, blueprint, если хотите. Чтобы он заработал, нужно создать из него экземпляр и запустить. Команда docker run — это ваш швейцарский нож для запуска, и у неё столько флагов и опций, что можно написать отдельную книгу (но мы обойдёмся основными, чтобы не превратить это в справочник на 200 страниц).
Базовый запуск
Самая простая команда выглядит так:
docker run myapp
Система создаст экземпляр из myapp, запустит команду, указанную в CMD (или ENTRYPOINT), и покажет вывод в терминале. Когда приложение завершится, экземпляр остановится, но не удалится — он останется в системе в статусе «Exited». Посмотреть все экземпляры (включая остановленные) можно командой docker ps -a.
Проблема в том, что эти остановленные экземпляры накапливаются и занимают место. Чтобы они удалялись автоматически после завершения работы, используйте флаг —rm:
docker run --rm myapp
Теперь как только приложение завершится (или вы нажмёте Ctrl+C), экземпляр будет удалён. Удобно для разработки и одноразовых задач.
Ещё один важный флаг — -d (detached mode), который запускает в фоновом режиме:
docker run -d myapp
Вместо вывода в терминал вы получите ID, и он будет работать в фоне. Это стандартный режим для продакшена — веб-приложения же не должны блокировать ваш терминал. Посмотреть, что происходит внутри, можно через docker logs <container_id>, но об этом чуть позже.
Можно комбинировать флаги: docker run -d —name myapp-container —restart unless-stopped myapp запустит в фоне, даст понятное имя и настроит автоматический перезапуск.
Проброс портов (-p)
Экземпляры изолированы от внешнего мира, и это включает сетевые порты. Если ваше приложение внутри слушает порт 8000, это не значит, что вы можете открыть браузер и зайти на localhost:8000 — нужно явно пробросить (замапить) порт на порт хост-машины.
Синтаксис флага -p:
docker run -p 8000:8000 myapp
Формат: -p ХОСТ_ПОРТ:ПОРТ_ВНУТРИ. В данном случае порт 8000 на вашей машине будет перенаправлять трафик на порт 8000 внутри. Можно использовать разные порты: docker run -p 3000:8000 myapp
Теперь приложение доступно по адресу localhost:3000, хотя внутри оно слушает 8000. Удобно, если на хосте уже занят порт 8000 чем-то другим.
Можно пробросить несколько портов: docker run -p 8000:8000 -p 5432:5432 myapp
Или вообще пробросить все порты автоматически через флаг -P (большая буква), но это работает только если в Dockerfile была инструкция EXPOSE. В продакшене лучше явно указывать порты — так меньше сюрпризов. Диаграмма проброса портов с хоста в контейнер Docker.
Визуализация команды -p 3000:8000. Внешний запрос обращается к вашему компьютеру (HOST) на порт 3000, а Docker перенаправляет этот трафик внутрь контейнера на порт 8000, где запущено ваше приложение.
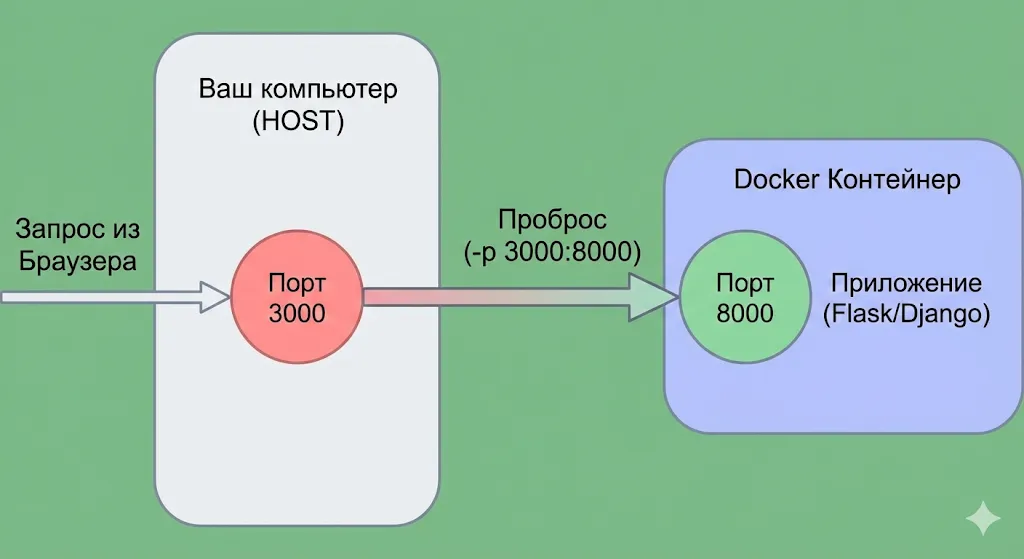
Визуализация команды -p 3000:8000. Внешний запрос обращается к вашему компьютеру (HOST) на порт 3000, а Docker перенаправляет этот трафик внутрь контейнера на порт 8000, где запущено ваше приложение.
Монтирование томов (-v)
Экземпляры эфемерны — это значит, что всё, что вы сохраните внутри, исчезнет, как только вы его удалите. База данных SQLite, загруженные пользователями файлы, логи — всё превратится в цифровую пыль. Чтобы данные переживали запущенный пакет, используются тома (volumes) — они монтируют директорию с хост-машины внутрь или создают именованное хранилище, которым система управляет сама.
Синтаксис простой:
docker run -v /path/on/host:/path/in/container myapp
Это называется bind mount — вы берёте конкретную папку на вашей машине и «прикручиваете» её внутрь. Например:
docker run -v $(pwd)/data:/app/data myapp
Теперь папка data из текущей директории будет доступна по пути /app/data, и всё, что приложение туда запишет, останется на вашем диске даже после удаления экземпляра.
Второй вариант — именованные тома:
docker run -v myapp-data:/app/data myapp
Система сама создаст том myapp-data и будет управлять его хранением (обычно где-то в недрах /var/lib/docker/volumes/). Это удобнее для продакшена, потому что не нужно думать о путях на хосте, плюс такие тома можно легко бэкапить и переносить между экземплярами.
Передача переменных окружения
Помните, мы выносили все настройки в переменные окружения? Так вот, пришло время передавать их при запуске. Платформа предлагает два способа: через флаг -e для отдельных переменных и через —env-file для целого файла.
Передача через -e:
docker run -e DATABASE_URL=postgresql://db:5432/mydb -e DEBUG=True myapp
Каждая переменная — отдельный флаг. Удобно для пары переменных, но если их десяток, команда превращается в нечитаемую простыню.
Для большого количества переменных лучше использовать файл:
docker run --env-file .env myapp
Файл .env выглядит как обычный список:
DATABASE_URL=postgresql://db:5432/mydb SECRET_KEY=super-secret-key-dont-commit-this DEBUG=False REDIS_URL=redis://localhost:6379
Важно: этот файл с реальными секретами должен быть в .gitignore и никогда не коммититься в репозиторий (а в .dockerignore, чтобы случайно не попал в сборку). Для примеров создавайте .env.example с фейковыми значениями.
Переменные из -e имеют приоритет над переменными из ENV в Dockerfile, поэтому можно задать дефолты в инструкции, а конкретные значения передавать при запуске. Это даёт гибкость: один артефакт работает и в dev, и в prod — просто с разными переменными окружения.
Полезные флаги (—name, —restart, —cpus, —memory)
Система генерирует случайные имена экземплярам (типа quirky_einstein или boring_tesla), что забавно, но непрактично — попробуйте вспомнить, какой из пяти peaceful_something был вашим веб-приложением. Флаг —name решает эту проблему:
docker run --name myapp-web myapp
Теперь экземпляр называется понятно, и к нему можно обращаться по имени: docker logs myapp-web, docker stop myapp-web — всё читаемо и предсказуемо.
Флаг —restart управляет политикой перезапуска:
docker run --restart unless-stopped myapp
Варианты:
- no — не перезапускать (дефолт).
- on-failure — перезапускать только если упал с ошибкой.
- always — перезапускать всегда, даже после.
- docker stop unless-stopped — перезапускать всегда, кроме случаев, когда вы явно остановили.
Для продакшена обычно используют unless-stopped или always — чтобы приложение автоматически поднималось после сбоя или перезагрузки сервера.
Флаги —cpus и —memory ограничивают ресурсы:
docker run --cpus="1.5" --memory="512m" myapp
Экземпляр сможет использовать максимум 1.5 CPU-ядра и 512 МБ оперативной памяти. Полезно, чтобы один экземпляр не сожрал все ресурсы сервера и не положил остальные сервисы.
Проверка работоспособности и диагностика проблем
Экземпляр запущен, порты пробросили, переменные окружения передали — казалось бы, всё должно работать. Но в реальности что-то обязательно пойдёт не так (это не пессимизм, а статистика, основанная на многолетнем опыте отладки в три часа ночи). Приложение не отвечает, в браузере ошибка 502, а может вообще всё стартует и тут же падает. Что делать? Паниковать рано — сначала нужно разобраться, что происходит внутри.
Просмотр логов (docker logs)
Первое и главное — логи. Если что-то упало или работает не так, как ожидалось, логи скажут вам почти всё (если, конечно, вы не забыли добавить логирование в приложение, но это уже другая история).
docker logs myapp-web
Покажет весь вывод с момента запуска — всё, что приложение писало в stdout и stderr. Полезные флаги:
- -f (follow) — следить за логами в реальном времени.
- tail -f —tail 100 — показать только последние 100 строк.
- —since 5m — показать логи за последние 5 минут.
- -t — добавить временные метки к каждой строке.
Пример для продакшена:
docker logs -f --tail 200 myapp-web
Если логи пустые или там ничего разумного нет, проверьте, что в вашем Python-приложении установлена переменная PYTHONUNBUFFERED=1 (помните, мы говорили про это в ENV?), иначе вывод буферизуется, и вы не увидите логи сразу.
Проверка состояния (docker ps, docker inspect)
Логи посмотрели, но экземпляр всё равно ведёт себя странно? Пора проверить его состояние. Команда docker ps покажет список всех запущенных экземпляров:
docker ps
Вы увидите таблицу с ID, именем сборки, командой, временем создания, статусом, портами и именем. Если экземпляра в списке нет — он либо упал, либо не запустился вовсе. Добавьте флаг -a, чтобы увидеть все, включая остановленные:
docker ps -a
Обратите внимание на колонку STATUS. Если там Exited (1) 2 minutes ago — упал с ошибкой (код выхода 1). Если Exited (0) — завершился нормально. Если Restarting — бесконечно перезапускается, что обычно означает, что приложение падает сразу после старта (проверьте логи).
Для детальной информации используйте docker inspect:
docker inspect myapp-web
Вывалится огромный JSON с абсолютно всей информацией: переменные окружения, примонтированные тома, сетевые настройки, статус, ресурсы. Можно фильтровать через —format:
docker inspect --format='{{.State.Status}}' myapp-web
Покажет только статус. Полезно для скриптов и автоматизации.
Вход внутрь (docker exec)
Иногда нужно залезть внутрь работающего экземпляра и посмотреть, что там вообще происходит — проверить, существуют ли нужные файлы, правильно ли установились зависимости, какие процессы запущены. Для этого используется docker exec: docker exec -it myapp-web /bin/bash
Флаг -it — это комбинация -i (interactive) и -t (tty), которая даёт вам интерактивную оболочку. /bin/bash — команда, которую нужно выполнить (в данном случае запустить bash).
Теперь вы внутри и можете делать всё, что угодно: смотреть файлы через ls, проверять переменные окружения через env, запускать команды Python, читать конфиги. Выйти можно через exit или Ctrl+D.
Если bash недоступен (например, в alpine-сборках), используйте /bin/sh:
docker exec -it myapp-web /bin/sh
Можно выполнять разовые команды без интерактивного режима:
docker exec myapp-web python manage.py migrate
Это запустит миграции базы данных внутри без необходимости входить в shell.
Диагностика загрузки, очистка, анализ ошибок
Платформа имеет тенденцию накапливать мусор: остановленные экземпляры, неиспользуемые артефакты, оборванные тома, сетевые интерфейсы-призраки. Со временем это съедает гигабайты дискового пространства, и в один прекрасный момент сборка падает с ошибкой «no space left on device», хотя на диске вроде бы ещё была куча места (спойлер: было, но всё сожрала система).
Команда docker system df покажет, сколько места занимают артефакты, экземпляры и тома:
docker system df
Увидите таблицу с размерами и количеством неиспользуемых объектов. Если там цифры в десятках гигабайт — пора чистить.
Команда docker system prune удалит весь мусор:
docker system prune
Удалятся остановленные экземпляры, неиспользуемые сети и артефакты без тегов. Флаг -a удалит вообще все неиспользуемые варианты (даже с тегами), —volumes — ещё и тома. Осторожно с этим — можно случайно снести что-то важное.
Команда docker events показывает события в реальном времени:
docker events
Полезно для отладки — увидите, когда экземпляр стартовал, упал, когда что-то было загружено. Можно фильтровать по типу событий. Запустите в отдельном терминале и наблюдайте, что происходит при сборке или запуске.
Деплой на сервер или VPS
Сборка готова, протестирована локально, всё работает — отлично, но это только половина пути. Теперь нужно доставить этот артефакт на сервер, где он будет работать в продакшене. И тут начинается самое интересное, потому что вариантов несколько, и у каждого свои плюсы и минусы (а также свои способы испортить вам день, если что-то пойдёт не так).
Передача на сервер
Существует три основных способа доставить артефакт на удалённый сервер, и выбор зависит от вашей инфраструктуры, паранойи относительно безопасности и желания возиться с настройками.
Способ 1: Hub или другой публичный registry
Самый простой вариант — залить в Hub:
docker tag myapp:1.0.0 yourusername/myapp:1.0.0 docker push yourusername/myapp:1.0.0
На сервере достаточно выполнить:
docker pull yourusername/myapp:1.0.0 docker run yourusername/myapp:1.0.0
Минус — артефакт станет публичным (если у вас не платный аккаунт), что не всегда приемлемо для корпоративных приложений со всякими секретами внутри (хотя секреты вообще не должны попадать в сборку, но это тема для другого разговора).
Способ 2: Приватный Registry
Можно поднять свой приватный registry (тот же Harbor или просто registry:2) и пушить туда. Настройка чуть сложнее, зато полный контроль и никаких утечек в публичный доступ.
Способ 3: Сохранение в архив
Если registry кажется избыточным, можно сохранить в tar-архив и перекинуть на сервер:
docker save myapp:1.0.0 > myapp.tar scp myapp.tar user@server:/tmp/
На сервере загружаете:
docker load < /tmp/myapp.tar
Работает, но неудобно для частых деплоев — каждый раз гонять гигабайтный архив по сети не самая эффективная идея.
Запуск на VPS
Артефакт на сервере, платформа установлена (если нет — curl -fsSL https://get.docker.com | sh, хотя в продакшене лучше ставить через пакетный менеджер с фиксацией версии) — пора запускать.
Базовая команда для продакшена выглядит примерно так:
docker run -d \ --name myapp-prod \ --restart unless-stopped \ -p 80:8000 \ -v /var/myapp/data:/app/data \ --env-file /etc/myapp/.env \ --memory="1g" \ --cpus="2" \ myapp:1.0.0
Разберём, что тут происходит: -d открывает в фоне, —restart unless-stopped обеспечивает автоперезапуск после сбоев или перезагрузки сервера, -p 80:8000 пробрасывает внешний порт 80 на внутренний 8000 приложения, -v монтирует том для данных (чтобы они пережили пересоздание), —env-file подгружает переменные окружения из защищённого файла, а ограничения по памяти и CPU не дают экземпляру сожрать все ресурсы сервера.
После запуска проверяйте статус через docker ps и логи через docker logs -f myapp-prod. Если что-то не работает — см. предыдущий раздел про диагностику.
Для обновления приложения: пулите новую версию, останавливаете старый экземпляр (docker stop myapp-prod), удаляете его (docker rm myapp-prod), запускаете новый с той же командой, но новой версией. Или заверните всё это в docker-compose и обновляйтесь одной командой — но это уже следующий уровень.
Заключение
Итак, вы упаковали приложение, собрали пакет, запустили его локально и даже задеплоили на сервер. Поздравляю — вы освоили базу контейнеризации, и это не шутка, а вполне себе востребованный навык, который пригодится практически в любом современном проекте. Подведем итоги:
- Контейнеризация устраняет проблемы с различиями окружений. Приложение работает одинаково на локальной машине, сервере и в продакшене.
- Подготовка проекта влияет на стабильность сборки. Чёткая структура, фиксированные зависимости и использование переменных окружения делают контейнер воспроизводимым.
- Правильный Dockerfile ускоряет работу. Грамотное кеширование слоёв снижает время сборки и упрощает поддержку.
- Сборка и запуск контейнера — управляемый процесс. Теги, порты, тома и переменные окружения дают гибкость при эксплуатации.
- Деплой контейнера упрощает обновления и диагностику. Развёртывание становится предсказуемым и масштабируемым.
Если вы только начинаете осваивать профессию DevOps-инженера или backend-разработчика, рекомендуем обратить внимание на подборку курсов по Devops. В них есть теоретическая и практическая часть, которая помогает закрепить навыки упаковки и деплоя приложений на реальных задачах.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
114 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 мая
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
DevOps-инженер
|
Нетология
46 отзывов
|
Цена
101 800 ₽
226 321 ₽
с промокодом kursy-online
|
От
3 143 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 апреля
|
Подробнее |
|
Профессия DevOps-инженер
|
Skillbox
232 отзыва
|
Цена
161 751 ₽
323 502 ₽
Ещё -20% по промокоду
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
23 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
102 отзыва
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Профессия DevOps-инженер PRO
|
Skillbox
232 отзыва
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
6 месяцев
|
Старт
23 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.