Как удалить дубликаты в Excel и Google Таблицах: полное руководство с примерами
Дубликаты — это повторяющиеся записи в таблицах, которые содержат идентичные значения в одном или нескольких столбцах. На первый взгляд может показаться, что речь идет о незначительной косметической проблеме, однако на практике наличие дублирующихся данных представляет серьезную угрозу для качества аналитики и принятия бизнес-решений.

Давайте разберемся, откуда берутся эти цифровые двойники и почему они требуют немедленного внимания.
Основные причины появления дубликатов:
- Множественный ввод данных — когда несколько операторов вносят одинаковую информацию независимо друг от друга.
- Объединение информации из разных источников — при слиянии таблиц без предварительной проверки на совпадения.
- Периодический импорт из внешних систем — особенно если процесс происходит автоматически и без контроля уникальности.
- Копирование и вставка фрагментов — когда пользователи дублируют части таблицы, не отслеживая повторы.
- Технические сбои при автоматизации — системы без встроенной проверки на уникальность могут создавать дубли при каждой загрузке.
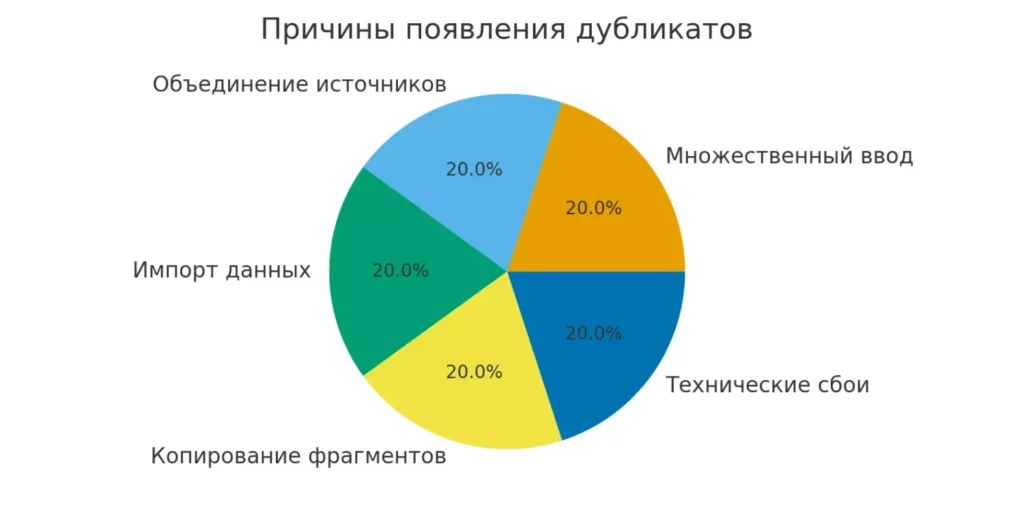
Диаграмма отражает основные источники появления дубликатов в данных. Она помогает быстро оценить, какие процессы чаще всего приводят к ошибкам и требуют оптимизации.
- Быстрые способы найти и выделить дубликаты в Excel
- Простые и продвинутые способы
- Формулы и функции Excel для работы с дублями
- Удаление в больших таблицах: Power Query
- Удаление и поиск дублей в Google Таблицах
- Автоматизация и предотвращение появления
- Практические сценарии работы с дубликатами
- Какой метод выбрать
- Заключение
- Рекомендуем посмотреть курсы по обучению Excel
Быстрые способы найти и выделить дубликаты в Excel
Прежде чем приступать к удалению повторяющихся записей, необходимо их обнаружить и визуально оценить масштаб проблемы. Excel предлагает несколько инструментов для быстрого выявления дублей, которые не требуют глубоких технических знаний и работают буквально в несколько кликов. Давайте рассмотрим наиболее эффективные методы поиска повторов.
Метод №1: Условное форматирование
Условное форматирование — это один из самых наглядных способов визуального выделения дубликатов в таблице. Инструмент автоматически подсвечивает все повторяющиеся значения цветом, что позволяет мгновенно оценить, с какими данными мы имеем дело.
Пошаговая инструкция для одного столбца:
- Выделите диапазон ячеек, который необходимо проверить на наличие дублей (например, весь столбец с фамилиями сотрудников).
- Перейдите на вкладку «Главная» в верхней панели Excel.
- Найдите раздел «Условное форматирование» и нажмите на него.
- В выпадающем меню выберите «Правила выделения ячеек» → «Повторяющиеся значения».
- В открывшемся окне выберите формат выделения — например, «Светло-красная заливка с темно-красным текстом».
- Нажмите «ОК».
Excel мгновенно подсветит все ячейки, значения которых встречаются в выбранном диапазоне более одного раза. Важный нюанс: инструмент выделяет цветом не только дубли, но и первоначальные значения — то есть если фамилия «Иванов» встречается трижды, все три ячейки будут окрашены.
Применение к нескольким столбцам:
Когда необходимо найти повторы по комбинации нескольких столбцов (например, выявить сотрудников с одинаковыми именем И фамилией одновременно), действуем иначе:
- Выделите весь диапазон, включающий все столбцы для проверки.
- Примените условное форматирование тем же способом.
- Excel будет искать строки, где совпадают все значения во всех выделенных столбцах.
Однако здесь есть ограничение: стандартное условное форматирование при выделении нескольких столбцов будет анализировать каждую ячейку отдельно, а не строку целиком. Для более точного контроля можно использовать вспомогательный столбец с формулой СЦЕПИТЬ (CONCATENATE), объединяющей значения из нескольких колонок, и уже к нему применять условное форматирование.
Метод №2: Фильтрация с выделением повторов
После того как дубли выделены цветом с помощью условного форматирования, мы можем воспользоваться фильтрацией для более детального анализа. Этот метод особенно удобен, когда не требуется немедленное удаление, а нужна ручная проверка каждого случая.
Как настроить фильтрацию по цвету:
- Выделите любую ячейку внутри таблицы с информацией.
- Перейдите на вкладку «Данные» и нажмите кнопку «Фильтр».
- В заголовке столбца появятся значки выпадающего меню — нажмите на них.
- Выберите «Фильтр по цвету» → укажите цвет заливки, которым были выделены дубликаты.
- Excel отобразит только те строки, которые содержат повторяющиеся значения, скрыв остальные.
Такой подход позволяет сосредоточиться исключительно на проблемных записях, не отвлекаясь на уникальные данные. Мы можем пролистать отфильтрованный список, изучить каждый дубль и принять решение: действительно ли это повтор, или речь идет о разных сущностях с совпадающими атрибутами (например, два разных клиента с одинаковой фамилией).
Сценарии, когда фильтр удобнее удаления:
- Клиентские базы — когда необходимо вручную решить, какую из двух записей оставить (например, сохранить контакт с более свежей датой взаимодействия).
- Финансовые операции — требуется пометить дубликаты специальным флагом для последующего аудита, а не удалять их физически.
- Сложные случаи — когда повторяются не все параметры, и нужна экспертная оценка каждой ситуации.
Комбинация условного форматирования и фильтрации дает нам мощный инструмент визуального контроля информации. Мы не только видим проблему, но и можем методично её проанализировать перед принятием окончательного решения об удалении записей. Однако для массового автоматического устранения дубликатов существуют более эффективные методы — о них мы поговорим в следующем разделе.
Простые и продвинутые способы
После того как мы научились находить и визуально выделять повторяющиеся записи, переходим к их устранению. Excel предлагает несколько инструментов различной сложности — от простейших встроенных функций до продвинутых техник работы с информацией. Выбор метода зависит от объема таблицы, структуры данных и конкретной бизнес-задачи.
Инструмент «Удалить дубликаты» (базовый способ)
Самый известный и прямолинейный способ избавления от повторяющихся строк — встроенная функция «Удалить дубликаты». Этот инструмент доступен во всех версиях Excel начиная с 2007 года и позволяет очистить таблицу буквально за несколько секунд.
Инструмент “удалить дубликат” на панели в Экселе. Источник: Rutube, FluidCourse.
Удаление дублей по одному столбцу:
- Выделите диапазон, который нужно очистить (или выделите весь столбец).
- Перейдите на вкладку «Данные» в верхней панели.
- Найдите кнопку «Удалить дубликаты» в разделе «Работа с данными».
- В открывшемся окне оставьте галочку только напротив того столбца, по которому ищем повторы.
- Нажмите «ОК».
Excel проанализирует выбранный столбец и удалит все строки, где значения повторяются, оставив только первое вхождение каждого уникального значения. Система выдаст отчет: сколько дублей найдено и удалено, сколько уникальных значений осталось.
Удаление дублей по нескольким столбцам:
Более распространенный сценарий — когда необходимо идентифицировать дубликаты по комбинации нескольких параметров. Представим таблицу с автомобилями, где есть столбцы: марка, цвет, год выпуска, цена. Нам нужно удалить записи, где совпадают все четыре параметра одновременно.
- Выделите весь диапазон с информацией, включая все столбцы.
- Перейдите в «Данные» → «Удалить дубликаты».
- В появившемся окне отметьте галочками все столбцы, которые должны учитываться при поиске повторов.
- Убедитесь, что стоит галочка «Мои данные содержат заголовки», если первая строка — это названия столбцов
- Нажмите «ОК».
Критически важный момент: алгоритм считает строку дублем только если совпадают значения во ВСЕХ выбранных столбцах одновременно. Если два автомобиля совпадают по марке, цвету и году, но различаются по цене — Excel посчитает их разными записями и оставит обе. Именно поэтому перед удалением необходимо тщательно продумать логику: какие именно поля должны быть идентичны, чтобы запись считалась дубликатом.
Типовые ошибки при использовании инструмента:
- Забыли включить ключевой столбец — например, не учли поле «email», и система удалила записи разных клиентов с одинаковыми именами.
- Не проверили сортировку — Excel оставляет первое вхождение, поэтому если данные не отсортированы по дате, может остаться устаревшая запись вместо актуальной.
- Не сделали резервную копию — удаление необратимо, и восстановить информацию можно только через Ctrl+Z сразу после операции.
Продвинутый способ: оставлять только уникальные значения
Существует альтернативный подход, который не удаляет дубли физически, а фильтрует данные так, чтобы отображались только уникальные записи. Этот метод полезен, когда требуется сохранить исходную таблицу нетронутой, но работать только с уникальными значениями.
Как использовать расширенный фильтр:
- Выделите диапазон с информацией.
- Перейдите на вкладку «Данные» → «Дополнительно» (или «Фильтрация» → «Расширенный фильтр»).
- В открывшемся окне установите переключатель «Скопировать результат в другое место».
- Поставьте галочку напротив «Только уникальные записи».
- Укажите, куда поместить результат (например, на новый лист).
- Нажмите «ОК».
Отличие «удалить» vs «показать только уникальные»:
| Критерий | Удалить дубликаты | Только уникальные записи |
|---|---|---|
| Изменение исходных данных | Да, безвозвратно | Нет, создается копия |
| Возможность отката | Только Ctrl+Z | Всегда можно вернуться |
| Скорость работы | Очень быстро | Немного медленнее |
| Применение | Окончательная очистка | Анализ и проверка |
Этот метод особенно ценен на этапе аудита, когда мы хотим увидеть, что останется после удаления дубли, но не готовы принимать окончательное решение.
Полезная таблица: сравнение методов удаления дубликатов
Давайте систематизируем все доступные подходы и поймем, в каких ситуациях какой инструмент оптимален:
| Метод | Сложность | Скорость | Гибкость | Когда использовать |
|---|---|---|---|---|
| Условное форматирование | Низкая | Мгновенно | Только визуализация | Первичная оценка масштаба проблемы |
| Удалить дубликаты | Низкая | Очень быстро | Средняя | Стандартные таблицы до 100 тыс. строк |
| Расширенный фильтр | Средняя | Быстро | Высокая | Когда нужно сохранить оригинал |
| Формулы (СЧЁТЕСЛИ) | Высокая | Медленно на больших данных | Очень высокая | Сложная логика, условия |
| Power Query | Высокая | Отлично на любых объемах | Максимальная | Большие данные (100 тыс.+ строк), автоматизация |
Выбор конкретного инструмента должен основываться на балансе между сложностью задачи и доступными техническими навыками. Для повседневной работы с небольшими таблицами достаточно встроенного инструмента «Удалить дубликаты». Когда же речь заходит о регулярной обработке больших массивов или необходимости применять сложные условия отбора, стоит обратиться к формулам или Power Query — об этих продвинутых методах мы подробно поговорим в следующих разделах.
Формулы и функции Excel для работы с дублями
Когда встроенных инструментов Excel недостаточно — например, требуется не просто удалить дубли, а пометить их, подсчитать или применить сложную логику отбора — на помощь приходят формулы. Они дают максимальную гибкость и позволяют реализовать практически любой сценарий работы с повторяющимися данными.
Поиск повторов формулой СЧЁТЕСЛИ / COUNTIF
Функция СЧЁТЕСЛИ (в английской версии COUNTIF) — это базовый инструмент для подсчета количества вхождений конкретного значения в диапазоне. С её помощью мы можем определить, сколько раз встречается каждая запись.
Базовый синтаксис:
=СЧЁТЕСЛИ(диапазон; критерий)
Практический пример: предположим, у нас есть список email-адресов клиентов в столбце A (с A2 по A1000). Чтобы выявить дубли, создаем вспомогательный столбец B и в ячейке B2 пишем формулу:
=СЧЁТЕСЛИ($A$2:$A$1000; A2)
Протягиваем формулу вниз на весь диапазон. Теперь в столбце B каждая ячейка показывает, сколько раз соответствующий email встречается в таблице. Значение «1» означает уникальную запись, «2» и более — дубли.
Зачем нужны абсолютные ссылки ($A$2:$A$1000): они фиксируют диапазон поиска, чтобы при копировании формулы вниз он не смещался. При этом вторая ссылка (A2) остается относительной — она меняется на A3, A4 и так далее при протягивании.
Проверка нескольких условий: СЧЁТЕСЛИМН / COUNTIFS
Когда необходимо искать дубли по комбинации нескольких столбцов, функция СЧЁТЕСЛИ уже не справляется. Здесь нужна её расширенная версия — СЧЁТЕСЛИМН (COUNTIFS), которая позволяет задать множественные критерии.
Синтаксис:
=СЧЁТЕСЛИМН(диапазон1; критерий1; диапазон2; критерий2; ...)
Пример: таблица сотрудников содержит столбцы «Имя» (A), «Фамилия» (B), «Отдел» (C). Нужно найти людей с одинаковыми именем И фамилией одновременно. В столбце D пишем:
=СЧЁТЕСЛИМН($A$2:$A$1000; A2; $B$2:$B$1000; B2)
Формула подсчитает, сколько раз встречается конкретная комбинация имени и фамилии. Если добавить третье условие (отдел), формула усложнится:
=СЧЁТЕСЛИМН($A$2:$A$1000; A2; $B$2:$B$1000; B2; $C$2:$C$1000; C2)
Пометка «Уникальное» или «Повтор» во вспомогательной колонке
Числовой подсчет повторов удобен для анализа, но часто требуется простая текстовая метка: «Уникальное» или «Дубликат». Для этого комбинируем СЧЁТЕСЛИ с функцией ЕСЛИ (IF).
Формула для пометки:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$1000; A2)>1; "Дубликат"; "Уникальное")
Логика простая: если значение встречается больше одного раза, помечаем как «Дубликат», иначе — «Уникальное». Такой подход позволяет затем легко отфильтровать таблицу по этой колонке и увидеть все проблемные записи.
Усложненный вариант — пометка только второго и последующих вхождений:
Иногда требуется оставить первое вхождение без пометки, а маркировать только повторы. Для этого используем более хитрую конструкцию:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:A2; A2)>1; "Дубликат"; "Уникальное")
Обратите внимание: диапазон поиска теперь начинается с $A$2, но заканчивается на A2 (без знака $). При копировании вниз диапазон расширяется: в строке 3 это будет $A$2:A3, в строке 4 — $A$2:A4 и так далее. Это означает, что формула проверяет, встречалось ли значение ВЫШЕ текущей строки. Первое вхождение получит метку «Уникальное», все последующие — «Дубликат».
Комбинации ИНДЕКС + ПОИСКПОЗ (INDEX + MATCH)
Для более сложных сценариев — например, когда нужно извлечь уникальные значения в отдельный список — используется связка функций ИНДЕКС и ПОИСКПОЗ. Однако этот метод требует создания массивов формул и подходит для опытных пользователей.
Базовая идея: функция ПОИСКПОЗ находит позицию первого уникального значения в диапазоне, а ИНДЕКС извлекает его. Комбинируя эти функции с вспомогательными столбцами, мы можем автоматически формировать список только уникальных записей.
Функции Excel 365: UNIQUE, FILTER
Пользователи современных версий Excel (Microsoft 365, Excel 2021) получили доступ к революционным динамическим функциям, которые радикально упрощают работу с дублями.
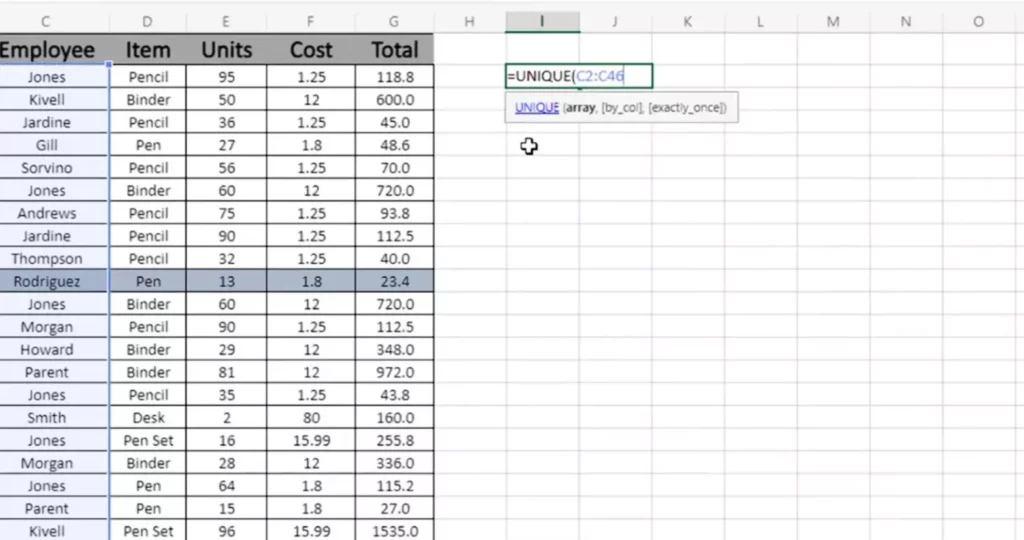
Функция UNIQUE, источник скриншота: Rutube, Python: кодовый бунт.
Функция UNIQUE:
=UNIQUE(диапазон; [по_столбцам]; [только_один_раз])
Эта формула мгновенно извлекает все уникальные значения из указанного диапазона. Например:
=UNIQUE(A2:A1000)
Результат — динамический массив только уникальных записей, который автоматически обновляется при изменении исходных данных. Третий параметр (только_один_раз) позволяет выбирать значения, которые встречаются ровно один раз, исключая даже первое вхождение дублей.
Функция FILTER:
=FILTER(массив; условие)
FILTER позволяет отобрать строки по сложным критериям. Например, чтобы вывести только дубликаты:
=FILTER(A2:A1000; СЧЁТЕСЛИ(A2:A1000; A2:A1000)>1)
Мини-таблица: когда какую функцию использовать
| Задача | Рекомендуемая функция | Уровень сложности |
|---|---|---|
| Подсчитать количество повторов для каждой записи | СЧЁТЕСЛИ | Начальный |
| Найти дубли по нескольким столбцам | СЧЁТЕСЛИМН | Средний |
| Пометить «Уникальное» / «Дубликат» | ЕСЛИ + СЧЁТЕСЛИ | Начальный |
| Извлечь список уникальных значений (Excel 365) | UNIQUE | Начальный |
| Отфильтровать только дубли (Excel 365) | FILTER + СЧЁТЕСЛИ | Средний |
| Создать сложную выборку уникальных записей (старые версии) | ИНДЕКС + ПОИСКПОЗ | Продвинутый |
Формулы дают нам то, чего не может обеспечить ни один встроенный инструмент — полный контроль над логикой обработки дублей. Мы можем не только находить и удалять повторы, но и создавать сложные системы пометок, условной фильтрации и автоматического мониторинга качества данных. Однако когда речь заходит о действительно больших массивах информации — десятках и сотнях тысяч строк — даже формулы начинают работать медленно. Для таких случаев существует специализированный инструмент, о котором мы поговорим в следующем разделе.
Удаление в больших таблицах: Power Query
Когда объем информации превышает 100 000 строк, стандартные инструменты Excel начинают демонстрировать свои ограничения. Встроенная функция «Удалить дубликаты» замедляется, формулы пересчитываются мучительно долго, а сам файл становится тяжелым и нестабильным. Именно для работы с масштабными массивами в Excel встроен мощный инструмент — Power Query.
Power Query (или «Редактор запросов») — это надстройка для импорта, трансформации и очистки данных, которая работает значительно быстрее обычных функций Excel. Ключевое преимущество: все операции выполняются в отдельном движке, не нагружая основную рабочую книгу, и могут быть автоматизированы для регулярного применения.
Меню функции Power Query. Источник: Rutube, Творческий Путь к Успеху
Почему Excel плохо справляется с большими наборами:
Традиционные инструменты Excel загружают все данные в оперативную память и обрабатывают их построчно. При работе с сотнями тысяч записей это приводит к:
- Медленному открытию и сохранению файлов.
- Зависаниям при применении фильтров и сортировки.
- Длительному пересчету формул (особенно массивных).
- Высокому риску потери информации при сбое программы.
Power Query использует другую архитектуру: информация обрабатывается потоком, операции запоминаются как последовательность шагов, а результат загружается в Excel только после завершения всех преобразований.
Базовый процесс удаления дубликатов в Power Query:
- Выделите таблицу или поставьте курсор внутри диапазона
- Перейдите на вкладку «Данные» → «Получить данные» → «Из таблицы/диапазона»
- Excel автоматически откроет окно Power Query с вашими данными
- Выделите один или несколько столбцов, по которым нужно искать дубли
- Щелкните правой кнопкой мыши на заголовке столбца → «Удалить дубликаты»
- Power Query мгновенно удалит повторяющиеся строки
- Нажмите «Закрыть и загрузить» в левом верхнем углу
Продвинутые возможности: группировка и агрегация:
Power Query позволяет не просто удалять дубликаты, но и работать с ними интеллектуально. Например, если в таблице транзакций одни и те же клиенты встречаются многократно, мы можем:
- Сгруппировать записи по клиенту.
- Подсчитать общее количество транзакций для каждого.
- Просуммировать суммы всех операций.
- Сохранить дату последней транзакции.
Для этого используется функция «Группировать по»:
- В Power Query выберите столбец для группировки (например, «ID клиента»)
- Нажмите «Группировать по» на вкладке «Преобразование»
- Задайте операции агрегации: подсчет строк, сумма, максимум, минимум и др.
- Получите сводную таблицу без дублей, но с сохранением важной статистики
Автоматизация регулярных задач:
Главное преимущество Power Query — возможность создать шаблон очистки данных один раз и применять его многократно. Представим ситуацию: каждую неделю вы получаете CSV-файл с выгрузкой из CRM-системы, который неизбежно содержит дубли. Вместо ручной очистки каждый раз:
- Настройте запрос Power Query для первого файла
- Примените все необходимые преобразования (удаление дубликатов, фильтрация, переименование столбцов)
- Сохраните запрос
- При получении нового файла просто замените источник данных и нажмите «Обновить»
Power Query автоматически повторит всю последовательность операций за секунды. Это экономит десятки часов рабочего времени для аналитиков, работающих с регулярными импортами информации.
Когда стоит использовать Power Query:
- Таблицы объемом от 100 000 строк и более.
- Регулярная обработка данных из одних и тех же источников.
- Необходимость объединить несколько файлов перед удалением дубли.
- Сложные сценарии очистки с множественными условиями.
- Работа с информацией из внешних источников (БД, веб-сервисы, облачные хранилища).
Для небольших одноразовых задач Power Query может показаться избыточным инструментом — в таких случаях достаточно стандартной функции «Удалить дубликаты». Однако для профессиональной аналитики освоение Power Query становится необходимостью, позволяя масштабировать и автоматизировать процессы обработки информации.
Удаление и поиск дублей в Google Таблицах
Хотя Google Таблицы и Excel решают схожие задачи, подходы к работе с дублями в этих платформах имеют свои особенности. Google Таблицы — облачный инструмент с собственной логикой и интерфейсом, который в некоторых аспектах даже проще и интуитивнее, чем Excel. Давайте рассмотрим, как эффективно очищать данные от повторов в экосистеме Google.
Инструмент «Удалить повторы»
Google Таблицы предлагают встроенную функцию удаления дублей, которая работает по принципу, аналогичному Excel, но находится в другом разделе меню.
Пошаговая инструкция:
- Выделите диапазон информации, который необходимо очистить (или выделите отдельную ячейку внутри таблицы, если хотите обработать весь массив).
- Перейдите в меню «Данные» в верхней панели.
- Выберите «Очистка данных» → «Удалить дубликаты».
- В появившемся диалоговом окне отметьте, содержат ли они строку заголовков.
- Выберите столбцы для проверки на дубли.
- Нажмите «Удалить дубликаты».
Google Таблицы проанализируют выбранный диапазон и удалят все строки, где значения в указанных столбцах полностью совпадают. Система выдаст отчет о количестве найденных и удаленных дубликатов.
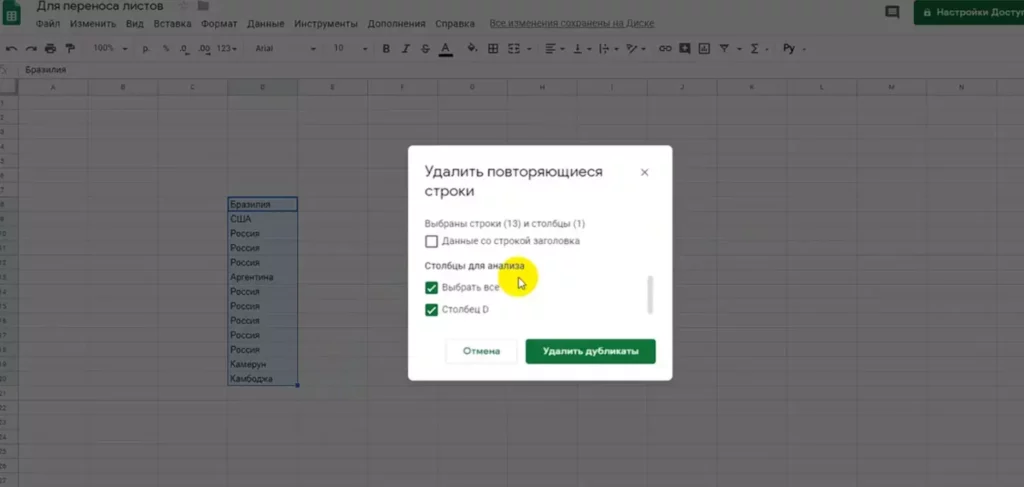
Удаление дубликатов в Гугл-таблицах. Источник: Rutube, Учим Мастерить
Важное отличие от Excel: Google Таблицы сразу предупреждают о необратимости операции и рекомендуют создать копию листа перед удалением. В облачной среде отмена действий работает иначе, чем в десктопных приложениях, поэтому такая предосторожность оправдана.
Выбор столбцов для проверки дубликатов
Механизм выбора столбцов в Google Таблицах интуитивно понятен и визуально нагляден. В диалоговом окне удаления дубликатов отображается список всех столбцов выделенного диапазона с чекбоксами.
Логика работы:
- Если отмечен только один столбец (например, «Email»), система удалит строки с повторяющимися email-адресами, независимо от различий в других полях.
- Если отмечены несколько столбцов (например, «Имя» + «Фамилия» + «Телефон»), строка считается дублем только при совпадении всех трех параметров одновременно.
- Если отмечены все столбцы, удаляются только полностью идентичные строки.
Практический пример: в таблице интернет-магазина есть столбцы «ID заказа», «Дата», «Клиент», «Товар», «Сумма». Если мы хотим удалить повторные заказы одного и того же товара одним клиентом в один день, отмечаем столбцы «Дата» + «Клиент» + «Товар», но НЕ отмечаем «ID заказа» и «Сумма». Даже если суммы различаются (скажем, из-за разных скидок), система посчитает такие записи дублями и оставит только первую.
Автоматизация и предотвращение появления
Удаление уже существующих дублей — это лишь половина решения проблемы. Гораздо эффективнее выстроить систему, которая предотвращает появление повторов на этапе ввода данных. Давайте рассмотрим проактивные методы, позволяющие минимизировать риск возникновения дубликатов и автоматизировать контроль качества информации.
Проверка данных (Data Validation) — запрет на ввод дублей
Excel и Google Таблицы позволяют настроить валидацию данных так, чтобы система автоматически блокировала ввод повторяющихся значений. Это особенно полезно для полей, где уникальность критична: ID клиента, номер заказа, email, номер договора.
Настройка запрета дублей в Excel:
- Выделите диапазон ячеек, в который будет вводиться информация (например, столбец A с A2 по A1000)
- Перейдите на вкладку «Данные» → «Проверка данных»
- В поле «Тип данных» выберите «Другой» или «Пользовательский»
- В поле «Формула» введите:
=СЧЁТЕСЛИ($A$2:$A$1000; A2)=1
- Перейдите на вкладку «Сообщение об ошибке».
- Настройте текст предупреждения: «Это значение уже существует в таблице. Ввод дубликатов запрещен.».
- Нажмите «ОК».
Теперь при попытке ввести повторяющееся значение Excel выдаст предупреждение и заблокирует ввод (или предложит отменить, в зависимости от настройки типа ошибки: «Останов», «Предупреждение» или «Сообщение»).
Настройка в Google Таблицах:
Процесс аналогичен, но интерфейс немного отличается:
- Выделите диапазон → «Данные» → «Проверка данных».
- В критериях выберите «Пользовательская формула».
- Введите: =COUNTIF($A$2:$A$1000, A2)=1.
- Настройте сообщение об ошибке и уровень строгости.
Ограничения метода:
- Валидация работает только для новых данных — существующие дубли не удаляются автоматически.
- Формула должна быть тщательно протестирована, чтобы избежать блокировки легитимных записей.
- При копировании больших фрагментов данных валидация может замедлить работу.
Стандартизация данных: приведение форматов, регистра, очистка пробелов
Значительная часть «псевдодубликатов» возникает не из-за реального повтора информации, а из-за различий в форматировании. Например: «Иванов Иван», «иванов иван», » Иванов Иван » (с пробелами) — технически это три разных значения, хотя очевидно речь об одном человеке.
Ключевые методы стандартизации:
- Приведение к единому регистру: используйте функции для нормализации текста:
- =СТРОЧН(A2) — преобразует весь текст в нижний регистр.
- =ПРОПИСН(A2) — преобразует в верхний регистр.
- =ПРОПНАЧ(A2) — делает заглавной первую букву каждого слова.
- Удаление лишних пробелов: функция =СЖПРОБЕЛЫ(A2) (TRIM) удаляет пробелы в начале и конце строки, а также заменяет множественные пробелы внутри текста на одинарные.
- Очистка невидимых символов: формула =ПЕЧСИМВ(A2) (CLEAN) удаляет непечатаемые символы, которые часто появляются при импорте данных из внешних систем.
- Единый формат дат: даты могут записываться по-разному: «01.12.2024», «1.12.24», «01-дек-2024». Используйте функцию =ТЕКСТ(A2; «ДД.ММ.ГГГГ») для приведения к единому формату.
- Стандартизация телефонных номеров: номера телефонов часто вводятся в разных форматах: «+7 (916) 123-45-67», «89161234567», «9161234567». Создайте формулу для извлечения только цифр:
=ПОДСТАВИТЬ(ПОДСТАВИТЬ(ПОДСТАВИТЬ(ПОДСТАВИТЬ(A2;" ";"");"(";"");")";"");"-";"")
Практический подход:
Создайте отдельный столбец для стандартизированных данных, примените к нему все необходимые функции очистки, а затем используйте именно этот столбец для поиска дублей. Исходные данные при этом сохраняются в неизменном виде.
Регулярная проверка перед анализом
Очистка данных должна стать обязательным этапом любого аналитического процесса — своего рода «гигиеной данных», которую невозможно игнорировать без последствий.
Рекомендуемый чек-лист перед началом анализа:
- Визуальная инспекция — просмотрите первые 50–100 строк, чтобы понять структуру и выявить очевидные проблемы.
- Проверка на пустые значения — используйте фильтр или формулы для поиска незаполненных критических полей.
- Стандартизация форматов — приведите текст, даты и числа к единому виду.
- Поиск дублей — примените условное форматирование или формулы СЧЁТЕСЛИ для первичной оценки.
- Решение о методе удаления — выберите подходящий инструмент в зависимости от объема данных и сложности логики.
- Документирование процесса — зафиксируйте, какие действия были предприняты, чтобы при необходимости повторить или объяснить коллегам.
Автоматизация регулярных проверок:
Для задач, которые повторяются еженедельно или ежемесячно, создайте шаблон:
- В Excel: запишите макрос с последовательностью действий по очистке данных.
- В Google Таблицах: используйте Google Apps Script для автоматизации.
- В Power Query: настройте запрос, который будет применяться автоматически при обновлении источника.

Эта иллюстрация показывает специалиста, работающего в Excel и анализирующего данные. Такой визуальный образ помогает подчеркнуть реальный сценарий работы с таблицами и делает материал ближе к практическому опыту читателя. Изображение усиливает понимание того, как выглядят процессы обработки и очистки данных в повседневной работе.
Практические сценарии работы с дубликатами
Теория важна, но настоящее понимание приходит через практику. Давайте рассмотрим реальные бизнес-ситуации, где дубли создают конкретные проблемы, и разберем оптимальные подходы к их решению для каждого случая.
Клиентские базы данных
Клиентские базы — одна из самых уязвимых областей для появления дубликатов. Контакты вводятся вручную разными менеджерами, импортируются из различных источников, обновляются при изменении данных — и в результате один клиент может присутствовать в системе под несколькими записями.
Типичные проблемы:
- Повторяющиеся контакты — один клиент записан как «Иван Петров», «И. Петров», «Петров Иван Сергеевич».
- Множественные email-адреса — у одного человека есть рабочая и личная почта, каждая создала отдельную запись.
- Ошибки рассылок — клиент получает одно и то же предложение несколько раз, что раздражает и снижает конверсию на 10–25% согласно исследованиям email-маркетинга.
Оптимальный подход:
- Используйте комбинированный ключ для идентификации дублей: email + телефон + имя
- Примените формулу СЦЕПИТЬ для создания уникального идентификатора:
=СЦЕПИТЬ(СТРОЧН(СЖПРОБЕЛЫ(A2)); B2; C2)
где A2 — имя, B2 — email, C2 — телефон
- Используйте «нечеткое сопоставление» через Power Query для поиска похожих, но не идентичных записей.
- При обнаружении дублей сохраняйте запись с наиболее свежей датой взаимодействия.
- Создайте автоматический процесс регулярной дедупликации перед каждой рассылкой.
Рекомендация: для клиентских баз особенно эффективен подход с использованием «нечеткого сопоставления» через Power Query, который позволяет находить похожие, но не идентичные записи (например, с опечатками в имени).
Финансовые таблицы
В финансовой отчетности дубли могут привести к катастрофическим последствиям — от искажения показателей до прямых денежных потерь.
Критические риски:
- Двойные списания — одна и та же транзакция учтена дважды, что завышает расходы.
- Повторные платежи поставщикам — счет оплачен дважды из-за дублирования записи.
- Искажение финансовых показателей — выручка, прибыль, обороты рассчитаны неверно.
- Проблемы с аудитом — несоответствия между системами вызывают вопросы проверяющих.
Реальный кейс: финансовый аналитик обнаружил, что система автоматически выгружала данные каждый час, и при объединении отчетов за месяц некоторые транзакции дублировались. Компания едва не закупила избыточное количество продукции на сумму более миллиона рублей, полагаясь на завышенные показатели спроса.
Оптимальный подход:
- НЕ удаляйте физически — в финансах критичен аудиторский след
- Используйте формулу для пометки дубликатов специальным флагом:
=ЕСЛИ(СЧЁТЕСЛИМН($A$2:A2; A2; $B$2:B2; B2)>1; "ДУБЛИКАТ"; "")
где A — номер транзакции, B — дата
- Создайте сводную таблицу с фильтрацией дубликатов, но сохраните исходные данные нетронутыми
- Примените формулы, возвращающие TRUE только для первого вхождения транзакции
- Внедрите систему валидации данных, предотвращающую ввод дубликатов
Для сложных случаев: используйте комбинацию VBA и Power Query с логированием всех изменений для соблюдения требований финансового аудита.
Склад и логистика
Складской учет требует абсолютной точности — дубли здесь приводят к пересорту, ошибкам инвентаризации и проблемам с отгрузкой.
Типичные проблемы:
- Повторные записи товара — один артикул учтен несколько раз с разными наименованиями
- Дублирование позиций при инвентаризации — товар посчитан дважды, создается иллюзия избытка
- Ошибки при заказе — система считает, что товара достаточно, хотя реальных единиц меньше
Оптимальный подход:
- Стандартизируйте артикулы и SKU — используйте единую систему кодирования
- Применяйте функцию UNIQUE (в Excel 365) для создания мастер-списка уникальных позиций:
=UNIQUE(A2:A1000)
- Используйте группировку с агрегацией в Power Query для подсчета реального количества:
- Группировать по: Артикул
- Агрегация: Сумма количества
- Внедрите систему штрих-кодирования для исключения ручного ввода
- Создайте автоматические отчеты расхождений между системой и фактическим наличием
Большие аналитические таблицы
При работе с сотнями тысяч строк данных из различных источников дубли становятся неизбежностью, а их поиск и удаление — отдельной технической задачей.
Специфика больших данных:
- Стандартные инструменты Excel работают медленно или вызывают зависания
- Формулы пересчитываются слишком долго
- Визуальная проверка невозможна из-за объема
Оптимальный подход:
- Обязательно используйте Power Query — это единственный эффективный инструмент для масштабных массивов
- Разделите процесс на этапы:
- Предварительная фильтрация (удаление явно некорректных данных)
- Удаление очевидных дублей
- Обработка пограничных случаев
- Примените индексирование данных перед поиском дубликатов для повышения производительности
- Используйте группировку с агрегацией вместо простого удаления для сохранения целостности аналитики
- Создайте шаблон Power Query с настроенным процессом дедупликации для регулярного применения
- Рассмотрите возможность переноса информации в специализированные системы (SQL базы данных, Google BigQuery) для действительно больших объемов (миллионы строк)
Для регулярных задач: настройте автоматический процесс, который будет применяться при каждой загрузке новых данных. Это превращает часы ручной работы в несколько минут автоматической обработки.
Какой метод выбрать
После изучения всех доступных инструментов возникает закономерный вопрос: какой метод применить в конкретной ситуации? Выбор зависит от множества факторов — от объема данных и частоты задачи до уровня технических навыков пользователя. Давайте систематизируем все рассмотренные подходы и создадим практическое руководство для быстрого принятия решения.
Маленькая таблица / один столбец → «Удалить дубликаты»
Если вы работаете с таблицей до 10 000 строк и вам нужно просто очистить один или несколько столбцов от повторов — встроенный инструмент «Удалить дубликаты» станет оптимальным выбором. Он работает мгновенно, не требует специальных знаний и решает задачу в три клика. Этот метод подходит для разовых операций, когда нет необходимости в автоматизации или сложной логике.
Типичные случаи: очистка списка email-адресов перед рассылкой, удаление повторяющихся артикулов в прайс-листе, дедупликация списка участников мероприятия.
Несколько столбцов → Условное форматирование + фильт
Когда требуется визуально оценить масштаб проблемы или принять решение о каждом дубликате вручную, комбинация условного форматирования и фильтрации даёт максимальный контроль. Вы видите все повторяющиеся записи, можете отфильтровать их по цвету и методично проверить каждый случай.
Типичные случаи: работа с клиентской базой, где нужно решить, какую из двух записей сохранить; финансовые данные, требующие ручной проверки перед удалением; ситуации, когда «похожие» записи могут быть легитимно разными.
Большие данные (100 000+ строк) → Power Query
Для масштабных массивов данных альтернативы Power Query практически не существует. Стандартные инструменты Excel замедляются, формулы пересчитываются минутами, а файл становится нестабильным. Power Query обрабатывает данные в отдельном движке, работает быстро и позволяет сохранить последовательность действий для повторного применения.
Типичные случаи: регулярная обработка выгрузок из CRM, объединение данных из нескольких источников перед анализом, работа с логами веб-сервисов, подготовка данных для BI-систем.
Google Sheets → «Очистка данных»
Если вы работаете в экосистеме Google и вам нужна простая очистка без сложных условий — встроенный инструмент «Данные → Очистка данных → Удалить повторы» справится с задачей. Он особенно удобен для командной работы, когда несколько человек одновременно работают с одним документом.
Типичные случаи: совместные проекты с удаленными командами, данные, которые должны быть доступны из любой точки мира, интеграция с другими сервисами Google (Forms, Analytics, Ads).
Сложные логики → Формулы COUNTIF / COUNTIFS
Когда встроенные инструменты не позволяют реализовать нужную логику — например, требуется пометить дубликаты, но не удалять их, или нужно учитывать сложные комбинации условий — формулы дают максимальную гибкость. СЧЁТЕСЛИ и СЧЁТЕСЛИМН позволяют создавать вспомогательные столбцы с любой необходимой логикой проверки.
Типичные случаи: финансовая отчетность, где дубликаты нужно отметить флагом, но не удалять; ситуации, когда критерии повтора нестандартны (например, «считать дубликатом, если email совпадает ИЛИ телефон совпадает»); создание дашбордов с динамическими показателями уникальности данных.
Быстрая матрица решений:
| Ситуация | Рекомендуемый метод | Время выполнения |
|---|---|---|
| Небольшой список, простая задача | «Удалить дубликаты» | 30 секунд |
| Нужен визуальный контроль | Условное форматирование + фильтр | 2–3 минуты |
| Сложные условия отбора | Формулы СЧЁТЕСЛИ | 5–10 минут |
| Регулярная обработка больших данных | Power Query с сохраненным шаблоном | 5 минут настройки, затем 1 минута на применение |
| Командная работа в облаке | Google Таблицы | 1–2 минуты |
| Финансовая отчетность | Формулы с пометкой + аудит | 15–30 минут |
Универсального решения не существует — каждая ситуация требует своего подхода. Однако понимание доступных инструментов и их ограничений позволяет принимать обоснованные решения и выбирать оптимальный баланс между затраченным временем и качеством результата. Главное правило: чем критичнее данные, тем тщательнее должна быть проверка; чем регулярнее задача, тем важнее автоматизация.
Заключение
Работа с дубликатами в Excel и Google Таблицах — это не просто техническая процедура, а фундаментальный элемент культуры работы с данными. Мы рассмотрели широкий спектр инструментов: от простейших встроенных функций до продвинутых методов автоматизации через Power Query, и теперь становится очевидно, что качество аналитики напрямую зависит от чистоты исходных данных.
- Дубликаты снижают точность анализа данных. Поэтому важно своевременно их находить и устранять.
- Excel предлагает несколько инструментов для очистки таблиц. Простое удаления дублей и продвинутых фильтров и формул.
- Формулы и Power Query дают максимальную гибкость. Они позволяют автоматизировать сложные сценарии работы с данными.
- Google Таблицы также поддерживают функции поиска дублей. Это делает облачную работу удобной и безопасной.
- Регулярная проверка качества данных — необходимая часть аналитики. Она помогает избежать ошибок и ускорить работу.
Если вы только начинаете осваивать работу с данными, рекомендуем обратить внимание на подборку курсов по Excel. В них есть теоретическая и практическая часть, которая поможет уверенно работать с Excel. Такой формат подойдёт всем, кто делает первые шаги в профессии.
Рекомендуем посмотреть курсы по обучению Excel
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Excel и Google-таблицы: от новичка до эксперта
|
Eduson Academy
100 отзывов
|
Цена
Ещё -13% по промокоду
31 992 ₽
79 992 ₽
|
От
2 666 ₽/мес
6 666 ₽/мес
|
Длительность
2 недели
|
Старт
6 февраля
|
Подробнее |
|
Мини-курс Microsoft Excel: с нуля до уверенного пользователя
|
CORS Academy
45 отзывов
|
Цена
8 400 ₽
|
|
Длительность
4 месяца
|
Старт
в любое время
|
Подробнее |
|
Excel для анализа данных
|
Нетология
46 отзывов
|
Цена
с промокодом kursy-online
27 500 ₽
50 965 ₽
|
От
2 548 ₽/мес
Это минимальный ежемесячный платеж за курс.
2 491 ₽/мес
|
Длительность
2 месяца
|
Старт
2 февраля
|
Подробнее |
|
Excel для рабочих и личных задач
|
Skillbox
219 отзывов
|
Цена
Ещё -20% по промокоду
27 864 ₽
55 728 ₽
|
От
2 322 ₽/мес
На 10 месяцев
4 644 ₽/мес
|
Длительность
2 месяца
|
Старт
21 февраля
|
Подробнее |
|
Excel для эффективной работы
|
Академия Синергия
35 отзывов
|
Цена
с промокодом KURSHUB
21 900 ₽
43 800 ₽
|
От
1 460 ₽/мес
0% на 12 месяцев
|
Длительность
2 месяца
|
Старт
в любое время
|
Подробнее |

Почему мягкие навыки важны для IT-архитектора?
Мягкие навыки IT-архитектора — не просто дополнение к техническим компетенциям. Они помогают эффективно учитывать SLA и ROI, работая с бизнесом и стейкхолдерами

Как посмотреть логи Docker: полный разбор команд, инструментов и практических сценариев
Разбираемся, как посмотреть логи в докере и что делать, если docker logs не показывает новые записи. Почему возникает задержка вывода, откуда берутся нечитаемые символы и как быстрее находить причины ошибок?

UML: универсальный инструмент для разработчиков и бизнеса
UML (Unified Modeling Language) — это универсальный язык, который упрощает проектирование систем и улучшает коммуникацию между разработчиками, аналитиками и бизнесом.

Топ популярных стилей интерьера: как найти свой идеальный вариант
Классика или хай-тек? Скандинавский минимализм или эклектика? Разбираем самые востребованные стили интерьера, их главные черты и практические советы по оформлению.