Клиент-серверная архитектура: что это, как работает и где применяется

Клиент-серверная архитектура — это модель организации компьютерных систем, в которой задачи чётко распределены между двумя основными участниками: клиентами и серверами. Представьте себе ресторан: вы (клиент) делаете заказ официанту, который передаёт его на кухню (сервер). Кухня готовит блюдо и возвращает его обратно через того же официанта. Примерно так же устроено взаимодействие в цифровом мире — клиент запрашивает информацию или услугу, а сервер обрабатывает этот запрос и отправляет ответ.
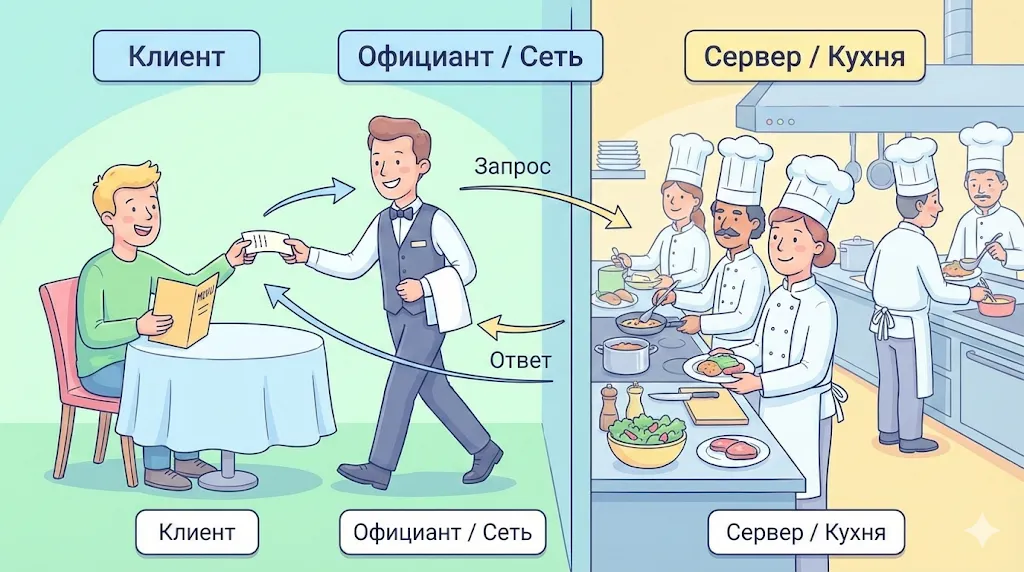
Аналогия с рестораном отлично иллюстрирует принцип работы. Клиент делает запрос (заказ) через официанта (сеть), а кухня (сервер) готовит и возвращает ответ (блюдо).
В основе этой модели лежит простой принцип разделения ответственности. Клиент — это устройство или приложение на стороне пользователя (браузер, мобильное приложение, программа на ПК), которое инициирует запросы. Сервер — мощный компьютер или набор компьютеров, которые хранят данные, выполняют сложные вычисления и предоставляют ресурсы по требованию. Такое разделение позволяет эффективно использовать вычислительные мощности: вместо того чтобы каждое устройство пользователя выполняло тяжёлые операции самостоятельно, эта работа делегируется централизованному узлу.
- Из чего состоит клиент-серверная система
- Как работает клиент-серверное взаимодействие (пошаговая схема)
- Архитектурные модели: двухуровневая, трёхуровневая и расширенные уровни
- Протоколы взаимодействия и сетевые технологии
- Где применяется клиент-серверная архитектура: примеры из реального мира
- Преимущества клиент-серверной архитектуры
- Недостатки и ограничения модели
- Альтернативные архитектуры и развитие модели
- Выбор архитектуры: когда и какую модель использовать
- Заключение
- Рекомендуем посмотреть курсы по веб разработке
Из чего состоит клиент-серверная система
Данная модель состоит из нескольких ключевых компонентов, каждый из которых выполняет свою специфическую роль. Давайте разберёмся, как эти элементы взаимодействуют друг с другом и почему их разделение имеет принципиальное значение для современных информационных решений.
Клиент — тонкий, толстый, гибридный
В мире клиент-серверных архитектур существует три основных подхода к реализации клиентской части, и выбор между ними определяет, где именно будет выполняться основная работа — на стороне пользователя или на сервере.
Тонкий клиент минимизирует логику на устройстве пользователя, делегируя практически все задачи серверу. По сути, это интерфейс для отображения данных и отправки команд. Веб-браузер, открывающий онлайн-приложение, — классический пример такого подхода.
Плюсы: простота обновлений (всё изменяется централизованно), минимальные требования к устройству пользователя, лёгкость в управлении.
Минусы: полная зависимость от сетевого подключения, ограниченная функциональность при отсутствии связи.
Толстый клиент содержит значительную часть бизнес-логики непосредственно на устройстве пользователя. Такие приложения могут работать автономно, обращаясь к серверу только для синхронизации данных или выполнения специфических операций.
Плюсы: высокая производительность, возможность работы без подключения к сети, быстрый отклик интерфейса.
Минусы: необходимость установки и обновления на каждом устройстве, двойной объём разработки (и клиентская, и серверная части), невозможность реализации некоторых ресурсоёмких вычислений на клиенте, ограничения безопасности при передаче данных.
Гибридный подход сочетает преимущества обеих моделей. Сервер может передавать клиенту не только данные, но и алгоритмы их обработки. Это позволяет динамически балансировать нагрузку и адаптировать поведение под конкретные условия.
| Тип клиента | Где выполняется логика | Зависимость от сервера | Типичные примеры |
|---|---|---|---|
| Тонкий клиент | Почти полностью на сервере | Высокая | Веб-приложения в браузере |
| Толстый клиент | В основном на стороне клиента | Низкая | Десктопные программы |
| Гибридный клиент | Распределена между клиентом и сервером | Средняя | Современные SPA, мобильные приложения |
Сервер — центр обработки и управления
Он выполняет роль центрального узла. Основные функции включают обработку бизнес-логики, управление доступом, выполнение вычислений и координацию работы с базой данных. Именно здесь происходит проверка прав пользователей, валидация запросов, выполнение сложных операций и формирование ответов.
Важно понимать, что это не просто хранилище данных. Он активно обрабатывает информацию, применяет правила и алгоритмы, контролирует бизнес-процессы. Когда мы говорим о серверной логике, речь идёт обо всём коде, который определяет, как должна реагировать вся инфраструктура на те или иные действия пользователей.
База данных — фундамент надёжности
База данных представляет собой отдельный компонент, специализирующийся на долговременном хранении структурированной информации. Её отделение от сервера приложений — не просто архитектурная прихоть, а необходимость, обусловленная несколькими факторами.
Во-первых, данные должны сохраняться даже при перезагрузке. Если бы информация хранилась только в оперативной памяти, любой сбой или перезапуск приводил бы к полной потере данных — сценарий, недопустимый с точки зрения бизнеса. Во-вторых, разделение позволяет оптимизировать каждый компонент под свою задачу: сервер приложений фокусируется на обработке логики, а база данных — на эффективном хранении и быстром извлечении информации. В-третьих, это упрощает масштабирование и обеспечение отказоустойчивости.
Как работает клиент-серверное взаимодействие (пошаговая схема)
Взаимодействие между клиентом и сервером представляет собой циклический процесс, который повторяется при каждом действии пользователя. Давайте разберём этот цикл запроса-ответа пошагово, чтобы понять, как именно происходит обмен информацией.
Шаги взаимодействия
- Клиент формирует запрос. Процесс начинается с действия пользователя — клик по кнопке, ввод данных в форму, переход по ссылке. Клиентское приложение преобразует это действие в структурированный запрос, который может содержать данные, авторизационную информацию, команды или параметры операции. Например, когда вы входите в социальную сеть, клиент формирует запрос с вашими учётными данными.
- Передача запроса по сети. Сформированный запрос отправляется на адрес сервера по определённому протоколу связи — чаще всего это HTTP или HTTPS для веб-приложений. Запрос проходит через сетевую инфраструктуру, включая маршрутизаторы, межсетевые экраны и другие сетевые устройства, прежде чем достигнет целевого узла.
- Сервер принимает запрос. Получив запрос, он регистрирует поступление и подготавливает к обработке. На этом этапе запрос помещается в очередь обработки, если в данный момент происходит выполнение других операций, или сразу передаётся на следующий этап.
- Проверка и валидация. Происходит проверка корректности запроса: валидность формата данных, аутентичность пользователя (проверка токенов, сессий), права доступа к запрашиваемому ресурсу. Если проверка не пройдена, формируется ответ об ошибке и цикл завершается. Если всё в порядке — переходим к следующему шагу.
- Выполнение бизнес-логики. Здесь происходит основная работа: применяются правила обработки данных, выполняются вычисления, обрабатываются бизнес-процессы. Например, при оформлении заказа проверяется наличие товара на складе, рассчитывается стоимость с учётом скидок, формируются документы.
- Обращение к базе данных. Для выполнения большинства операций требуется работа с данными — извлечение информации из базы, её обновление, добавление новых записей или удаление существующих. База данных обрабатывает SQL-запросы или другие команды и возвращает результат серверу приложений.
- Формирование и отправка ответа. Обработав запрос и получив необходимые данные, сервер создаёт ответ в нужном формате (HTML-страница, JSON-объект, файл) и отправляет его обратно клиенту. Клиентское приложение получает ответ, обрабатывает его и отображает результат пользователю — обновляет страницу, показывает уведомление, выводит данные на экран.
Этот цикл может повторяться десятки и сотни раз в рамках одного сеанса работы пользователя с приложением. Каждое взаимодействие — новый запрос, новая обработка, новый ответ. Эффективность этого процесса во многом определяет общее впечатление пользователя от работы.
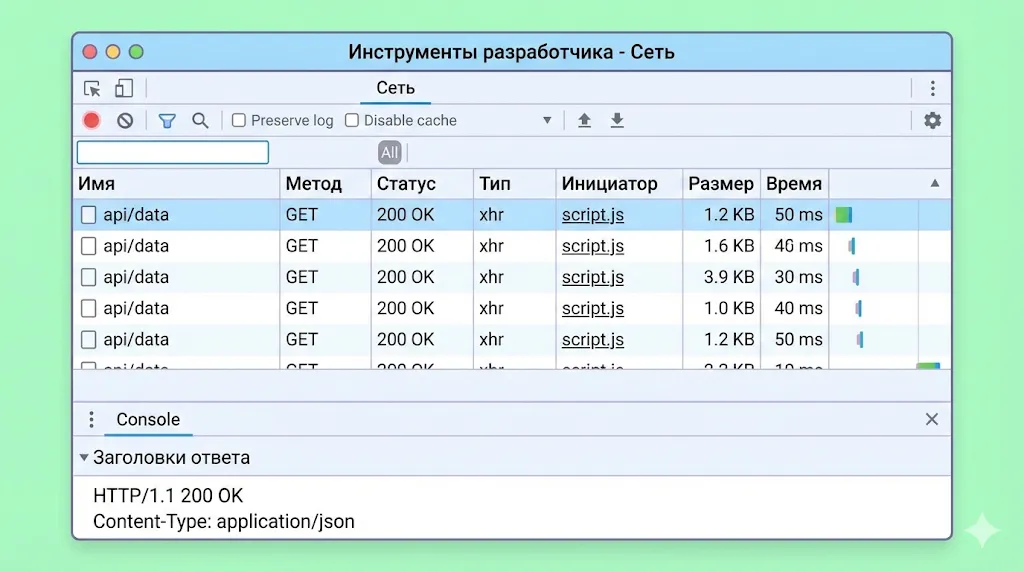
«Под капотом» браузера: вкладка «Сеть» в инструментах разработчика показывает реальные HTTP-запросы и ответы. Здесь можно увидеть метод запроса, статус ответа (например, 200 OK) и передаваемые данные.
Архитектурные модели: двухуровневая, трёхуровневая и расширенные уровни
Клиент-серверная архитектура не существует в единственном варианте — в зависимости от требований, её сложности и масштаба применяются различные модели. Рассмотрим основные подходы.
Двухуровневая архитектура
Это наиболее простая реализация клиент-серверной модели, в которой взаимодействие происходит напрямую между клиентом и сервером. Клиент отправляет запросы, они обрабатываются, и все данные хранятся в оперативной памяти или на диске в простейшем виде.
Двухуровневая архитектура удобна для небольших решений с ограниченным числом пользователей — например, локальных приложений в малом офисе или простых веб-сервисов. Основное преимущество — простота разработки и развёртывания. Однако здесь кроется существенный недостаток: если происходит перезагрузка или выход из строя, данные из оперативной памяти теряются. Это делает такую архитектуру неприемлемой для бизнес-критичных решений, где потеря информации недопустима.
Трёхуровневая архитектура
Трёхуровневая модель решает проблему надёжности, разделяя всё на три независимых компонента: клиент (уровень представления), сервер приложений (уровень бизнес-логики) и база данных (уровень хранения данных). Это разделение не просто техническое усложнение — оно даёт ряд принципиальных преимуществ.
Во-первых, информация теперь хранятся отдельно от логики ее обработки. База данных может работать на отдельном сервере, обеспечивая долговременное и надёжное хранение. Во-вторых, появляется возможность независимого масштабирования каждого уровня. Если нагрузка растёт на уровне обработки запросов — можно добавить серверы приложений; если проблема в скорости доступа к данным — оптимизировать или масштабировать базу данных. В-третьих, такая архитектура упрощает обслуживание: изменения в бизнес-логике не затрагивают структуру хранения данных и наоборот.
Преимущества трёхуровневой архитектуры:
- Надёжность хранения данных.
- Возможность независимого масштабирования каждого уровня.
- Упрощение разработки за счёт разделения ответственности.
- Повышение безопасности (прямой доступ к базе данных извне невозможен).
- Гибкость в изменении и обновлении отдельных компонентов.
Ограничения:
- Более сложная инфраструктура.
- Выше требования к квалификации разработчиков.
- Больше точек потенциальных сбоев.
- Необходимость организации взаимодействия между уровнями.
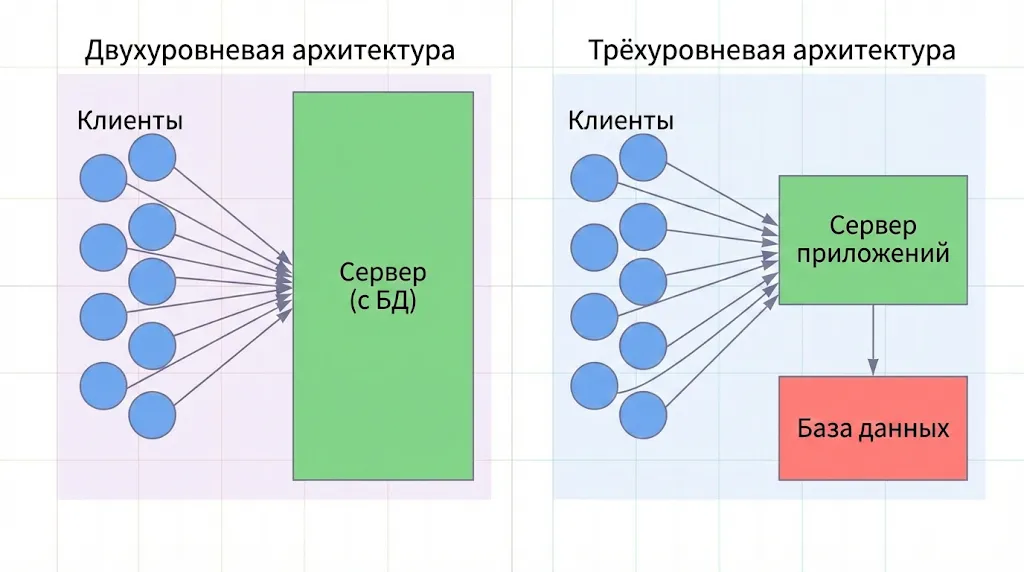
Наглядное сравнение двух основных моделей. Слева — простая двухуровневая архитектура, где логика и данные объединены. Справа — более сложная и надежная трёхуровневая модель с выделенным сервером приложений и базой данных.
Схема 2- и 3-уровневой архитектур
Наглядное сравнение двух основных моделей. Слева — простая двухуровневая архитектура, где логика и данные объединены. Справа — более сложная и надежная трёхуровневая модель с выделенным сервером приложений и базой данных.
| Критерий | Двухуровневая архитектура | Трёхуровневая архитектура |
|---|---|---|
| Количество уровней | Клиент + сервер | Клиент + сервер приложений + база данных |
| Надёжность хранения данных | Низкая | Высокая |
| Масштабируемость | Ограниченная | Высокая |
| Безопасность | Ниже | Выше |
| Подходит для крупных систем | Нет | Да |
Когда архитектура усложняется
Трёхуровневая архитектура — это базовая модель для большинства современных решений, однако при росте нагрузки или повышении требований к отказоустойчивости она требует дополнительных механизмов.
- Балансировщики нагрузки. Когда один сервер не справляется с потоком запросов от множества клиентов, в архитектуру вводится балансировщик нагрузки — специальное устройство или программа, которая распределяет входящий трафик между несколькими серверами приложений. Балансировщик может размещаться как перед серверами (на стороне клиентов), так и между различными уровнями архитектуры. Это позволяет равномерно распределить нагрузку и избежать перегрузки отдельных узлов.
- Кластеры серверов. Крупные компании не могут позволить себе простой даже на несколько минут — каждая секунда недоступности оборачивается потерями. Поэтому в бизнес-критичных решениях применяются кластеры — группы серверов, работающих как единое целое. Если один выходит из строя, остальные продолжают обрабатывать запросы, и пользователи даже не замечают проблемы.
- Горячий и холодный резерв. Существует два основных подхода к организации резервирования. Горячий резерв предполагает, что все машины в кластере активно работают параллельно, и балансировщик распределяет между ними входящие запросы. Это обеспечивает не только отказоустойчивость, но и повышение общей производительности — чем больше в горячем резерве, тем больше запросов можно обработать одновременно. Холодный резерв означает, что резервный узел находится в режиме ожидания и активируется только в случае отказа основного. Все запросы направляются на основной, а резервный синхронизирует с ним данные и готов взять на себя нагрузку в любой момент. Этот подход дешевле в эксплуатации, но не даёт прироста производительности в штатном режиме.
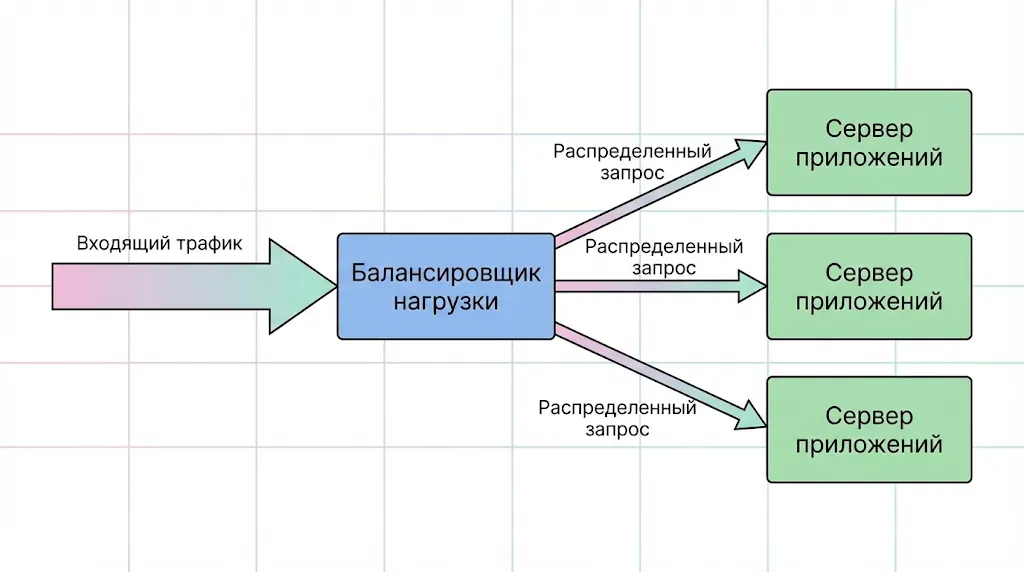
Балансировщик нагрузки действует как регулировщик. Он принимает большой поток запросов и равномерно распределяет их между несколькими серверами приложений, предотвращая перегрузку отдельных узлов.
Выбор между горячим и холодным резервом зависит от требований: если критична непрерывность работы и высокая производительность — выбирают горячий резерв; если важнее минимизировать затраты при сохранении базовой отказоустойчивости — холодный резерв будет разумным компромиссом.
Протоколы взаимодействия и сетевые технологии
Клиент-серверная архитектура не может функционировать без стандартизированных протоколов связи — правил, определяющих, как именно данные передаются между компонентами. Рассмотрим основные протоколы, которые обеспечивают взаимодействие в современных информационных решениях.
HTTP/HTTPS — основа веб-коммуникаций
HTTP (HyperText Transfer Protocol) и его защищённая версия HTTPS остаются наиболее распространёнными протоколами клиент-серверного взаимодействия в веб-среде. Эти протоколы работают по модели запрос-ответ: клиент отправляет HTTP-запрос (например, GET для получения данных или POST для отправки информации), а сервер обрабатывает его и возвращает HTTP-ответ с соответствующим кодом статуса и данными.
HTTPS добавляет к этому механизму шифрование с помощью SSL/TLS, что критически важно для защиты конфиденциальной информации — паролей, данных банковских карт, личных сведений. В современном интернете HTTPS стал фактическим стандартом для любых приложений, работающих с пользовательскими данными.
Важная особенность HTTP/HTTPS — это протокол без сохранения состояния (stateless). Каждый запрос независим, и сервер не «помнит» предыдущие обращения клиента. Для поддержания сеансов используются дополнительные механизмы — куки, токены авторизации, сессии.
WebSocket — двустороннее общение в реальном времени
Классический HTTP имеет ограничение: инициатором взаимодействия всегда выступает клиент. Сервер не может самостоятельно отправить данные клиенту — он лишь отвечает на запросы. Для приложений, требующих обмена данными в реальном времени, это создаёт проблему.
WebSocket решает эту задачу, устанавливая постоянное двустороннее соединение между клиентом и сервером. После установки WebSocket-соединения обе стороны могут отправлять данные друг другу в любой момент, без необходимости постоянно инициировать новые запросы. Это идеально подходит для онлайн-игр, чатов, уведомлений, биржевых торговых платформ — везде, где важна минимальная задержка и мгновенная доставка обновлений.
Другие протоколы клиент-серверной модели
Помимо веб-протоколов, клиент-серверная архитектура использует множество специализированных протоколов для конкретных задач.
- SMTP (Simple Mail Transfer Protocol) — протокол отправки электронной почты. Почтовый клиент использует SMTP для передачи писем на сервер, который затем доставляет их получателю.
- POP3 (Post Office Protocol) и IMAP (Internet Message Access Protocol) — протоколы получения почты. POP3 загружает письма на клиент и обычно удаляет их с сервера, тогда как IMAP позволяет работать с почтой непосредственно на сервере, синхронизируя состояние между устройствами.
- FTP (File Transfer Protocol) — протокол передачи файлов между клиентом и сервером, широко применяемый для загрузки контента на веб-серверы и обмена большими объёмами данных.
Выбор протокола зависит от специфики задачи: для веб-приложений используется HTTP/HTTPS, для обмена сообщениями в реальном времени — WebSocket, для работы с почтой — комбинация SMTP и IMAP/POP3. Понимание возможностей и ограничений каждого протокола помогает архитекторам принимать обоснованные решения при проектировании приложений.
Где применяется клиент-серверная архитектура: примеры из реального мира
Клиент-серверная модель стала фундаментом практически всех современных информационных решений. Мы взаимодействуем с ней ежедневно, зачастую даже не задумываясь об этом. Давайте рассмотрим конкретные примеры применения этой архитектуры в различных сферах.
Веб-сайты и веб-приложения
Каждый раз, когда вы открываете браузер и переходите на сайт, происходит клиент-серверное взаимодействие. Браузер (клиент) отправляет HTTP-запрос на веб-сервер, который возвращает HTML-код страницы вместе с изображениями, стилями оформления, скриптами и другими элементами. Современные веб-приложения — от онлайн-редакторов документов до систем управления проектами — полностью построены на этом принципе.
Электронная почта
Почтовые системы представляют собой классический пример клиент-серверной архитектуры. Почтовые сервисы (Яндекс.Почта, Mail.ru, Outlook) выступают в роли клиентов, которые обращаются к почтовым серверам для отправки и получения писем. Когда вы отправляете письмо, клиент передаёт его на SMTP-сервер, который маршрутизирует сообщение к серверу получателя. Для чтения почты клиент подключается по протоколу IMAP или POP3.
Онлайн-игры
Многопользовательские онлайн-игры функционируют на базе клиент-серверной модели с особыми требованиями к скорости обмена данными. Игровые платформы (Steam, PlayStation Network, Xbox Live) используют мощные серверные кластеры, к которым подключаются клиенты игроков. Центральный узел обрабатывает действия всех участников, синхронизирует игровой мир, проверяет правила и предотвращает читерство. Игроки обмениваются данными через него в режиме реального времени — любая задержка может повлиять на игровой процесс.
Социальные сети и мобильные приложения
Все популярные социальные сети — «ВКонтакте», «Одноклассники», Facebook, Instagram — построены на клиент-серверной архитектуре. Когда вы публикуете пост, загружаете фотографию или просматриваете ленту новостей, мобильное приложение или браузер отправляет запросы на серверы социальной сети, которые хранят контент, обрабатывают рекомендации и управляют связями между пользователями.
Банковские и финансовые системы
Банковские приложения и системы онлайн-платежей критически зависят от надёжной клиент-серверной инфраструктуры. Когда вы проверяете баланс счёта или совершаете перевод, запрос проходит через несколько уровней защиты к банковским серверам, которые проверяют подлинность операции, обрабатывают транзакцию и обновляют данные в базе. Здесь особенно важны требования к безопасности, скорости обработки и отказоустойчивости — банковские решения не могут позволить себе простой.
Эти примеры демонстрируют универсальность клиент-серверной модели: она одинаково эффективно работает и в развлекательных сервисах, и в критически важной финансовой инфраструктуре. Различия заключаются лишь в конкретных требованиях к производительности, безопасности и надёжности.
Преимущества клиент-серверной архитектуры
Клиент-серверная модель стала доминирующей в современной IT-индустрии не случайно — она предлагает ряд существенных преимуществ, которые делают её оптимальным выбором для большинства информационных решений.
- Централизованное управление данными и ресурсами. Все критически важные данные хранятся централизованно, что упрощает их администрирование, резервное копирование и обеспечение безопасности. Нет необходимости управлять информацией на сотнях или тысячах клиентских устройств — достаточно контролировать серверную инфраструктуру.
- Экономическая эффективность. Один мощный узел обходится значительно дешевле, чем сотни высокопроизводительных клиентских машин. Компании могут использовать относительно простые устройства на стороне пользователей, перенося тяжёлые вычисления на централизованные ресурсы.
- Отсутствие дублирования кода. Основная логика приложения хранится и выполняется централизованно. Это означает, что обновления и исправления ошибок вносятся в одном месте и мгновенно становятся доступны всем пользователям без необходимости обновлять программное обеспечение на каждом клиентском устройстве.
- Масштабируемость. Решение можно наращивать по мере роста нагрузки — добавлять серверы, увеличивать мощности баз данных, внедрять балансировщики нагрузки. Клиентская часть при этом остаётся неизменной.
- Безопасность данных. Конфиденциальная информация хранится на защищённых серверах, а не распределена по множеству клиентских устройств. Пользователи получают доступ только к тем данным, которые им необходимы для работы, и не видят всю картину целиком.
- Единая точка доступа к актуальной информации. Все пользователи работают с одной версией данных, хранящейся централизованно. Это исключает проблемы с рассинхронизацией информации между различными устройствами.
- Гибкость в выборе клиентских платформ. Пользователи могут работать с различных устройств — компьютеров, планшетов, смартфонов — используя разные операционные системы, при этом серверная часть остаётся универсальной.
Недостатки и ограничения модели
При всех своих преимуществах клиент-серверная архитектура имеет ряд существенных ограничений, о которых важно помнить при проектировании информационных решений.
- Единая точка отказа. Если сервер выходит из строя или становится недоступен, все клиенты теряют возможность работать. Отказ одного звена парализует всю инфраструктуру. Хотя эта проблема решается через кластеризацию и резервирование, такие решения значительно усложняют и удорожают всё.
- Зависимость от сетевого подключения. Клиент не может работать без связи с сервером. Даже кратковременные проблемы с сетью приводят к недоступности функциональности. Это особенно критично для мобильных приложений, где качество связи может быть нестабильным.
- Узкое место производительности. Центральный узел может стать узким местом при высокой нагрузке. Если количество одновременных запросов превышает возможности серверной инфраструктуры, страдает производительность всего решения. Время отклика увеличивается, запросы обрабатываются медленнее.
- Сложность инфраструктуры при масштабировании. Для обеспечения высокой доступности и производительности требуется развёртывание сложной инфраструктуры: кластеров, балансировщиков нагрузки, резервных компонентов, средств мониторинга. Это требует значительных финансовых вложений и высококвалифицированного персонала.
- Высокие требования к серверному оборудованию. Серверы должны быть достаточно мощными, чтобы обрабатывать запросы всех клиентов одновременно. При росте числа пользователей требования к оборудованию растут пропорционально.
- Ограниченная автономность клиентов. Клиентские приложения в значительной степени зависят от центрального узла и не могут полноценно функционировать без него. Это ограничивает возможности работы в автономном режиме.
- Потенциальные проблемы с безопасностью. Централизованное хранение данных делает сервер привлекательной целью для злоумышленников. Успешная атака компрометирует данные всех пользователей.
Альтернативные архитектуры и развитие модели
Несмотря на доминирование клиент-серверной архитектуры, существуют альтернативные подходы, которые в определённых сценариях оказываются более эффективными. Давайте рассмотрим основные из них и разберёмся, как они решают ограничения традиционной модели.
P2P — равноправные узлы
Peer-to-peer (P2P) представляет собой децентрализованную сеть, в которой все участники равноправны и обмениваются данными напрямую друг с другом, без посредничества центрального сервера. Каждый узел в такой сети одновременно выступает и клиентом, и сервером.
Классические примеры P2P — протоколы обмена файлами BitTorrent, ранние версии Skype, блокчейн-сети. Когда вы скачиваете файл через торрент, вы получаете его фрагменты от множества других пользователей одновременно, а сами становитесь источником этих данных для следующих участников сети.
Главное преимущество P2P — отсутствие единой точки отказа и высокая отказоустойчивость. Выход из строя одного или даже нескольких узлов не влияет на работу сети в целом. Кроме того, такая архитектура минимизирует нагрузку на инфраструктуру — не нужны мощные центральные узлы.
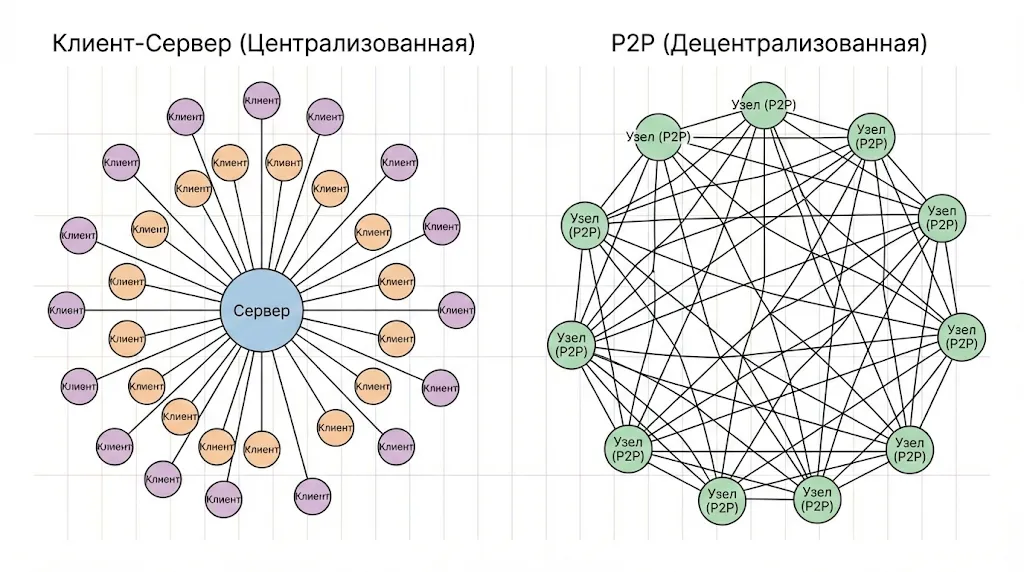
Две фундаментальные сетевые топологии. Слева — централизованная модель (клиент-сервер), где все узлы зависят от одного центра. Справа — децентрализованная P2P-сеть, где все участники равноправны и связаны между собой, что обеспечивает высокую отказоустойчивость.
Однако P2P имеет и существенные ограничения. Эта модель плохо подходит для сценариев, требующих строгой централизации данных, контроля доступа или гарантированной доступности информации. Сложно обеспечить конфиденциальность и защиту данных, когда они распределены по множеству узлов. Производительность зависит от количества и качества активных участников сети.
Edge Computing — вычисления ближе к пользователю
Edge computing (граничные вычисления) представляет собой подход, при котором обработка данных происходит не в централизованных дата-центрах, а на устройствах, расположенных ближе к источникам данных и конечным пользователям. По сути, вычислительные ресурсы размещаются на «краю» сети.
Этот подход особенно актуален для IoT-устройств (интернета вещей), умного дома, автономных транспортных средств, промышленной автоматизации. Представьте видеонаблюдение: вместо того чтобы передавать весь видеопоток на удалённый узел для анализа, камера с поддержкой edge computing может самостоятельно распознавать объекты и отправлять только значимые события.
Преимущества очевидны: снижается задержка обработки данных (критично для работы в реальном времени), уменьшается нагрузка на сеть и центральные узлы, повышается надёжность (устройство может работать даже при потере связи). Однако edge computing не отменяет необходимость в серверной инфраструктуре — скорее, это гибридный подход, дополняющий традиционную клиент-серверную модель.
Serverless — логика без выделенного сервера
Serverless architecture (бессерверная архитектура) — это модель, при которой разработчики не занимаются управлением серверной инфраструктурой напрямую. Облачные провайдеры (AWS Lambda, Google Cloud Functions, Azure Functions) берут на себя всю техническую сторону: выделение ресурсов, масштабирование, обслуживание.
Разработчики пишут небольшие функциональные модули кода, которые автоматически запускаются в ответ на определённые события или запросы. Например, функция может срабатывать при загрузке файла в облачное хранилище, при поступлении HTTP-запроса или по расписанию.
Название «serverless» несколько вводит в заблуждение — серверы, разумеется, существуют, просто разработчикам не нужно о них думать. Провайдер автоматически масштабирует ресурсы в зависимости от нагрузки, а оплата производится только за фактическое время выполнения кода, а не за постоянно работающие машины.
Serverless идеально подходит для приложений с нерегулярной нагрузкой, микросервисных архитектур, обработки событий. Однако этот подход имеет ограничения: холодный старт функций (задержка при первом вызове), ограничения на время выполнения, сложность отладки, зависимость от конкретного облачного провайдера.
Важно понимать, что эти альтернативные архитектуры не отменяют клиент-серверную модель, а скорее дополняют и развивают её. В реальных проектах часто применяются гибридные решения, сочетающие элементы различных подходов в зависимости от конкретных требований и задач.
Выбор архитектуры: когда и какую модель использовать
Выбор архитектурной модели — это не абстрактное теоретическое упражнение, а практическое решение, которое определяет эффективность, стоимость и надёжность всего проекта. Давайте разберёмся, какие факторы влияют на этот выбор и в каких случаях предпочтительна та или иная модель.
Клиент-серверная архитектура оптимальна когда:
- Требуется централизованное управление данными и строгий контроль доступа.
- Необходима синхронизация информации между множеством пользователей в реальном времени.
- Важна безопасность данных и их защита от несанкционированного доступа.
- Решение должно работать на различных платформах и устройствах с единым источником данных.
- Планируется частое обновление функциональности без необходимости вмешательства пользователей.
- Требуются ресурсоёмкие вычисления, которые нецелесообразно выполнять на клиентских устройствах.
Клиент-серверная модель может быть избыточной или неэффективной когда:
- Приложение должно работать в автономном режиме без доступа к сети.
- Предполагается равноправный обмен данными между участниками без централизованного контроля.
- Критична минимальная задержка, и данные должны обрабатываться локально.
- Нагрузка крайне нерегулярна, и содержание постоянно работающих серверов экономически неоправданно.
- Требования к конфиденциальности не допускают передачу данных третьей стороне.
P2P-архитектура подходит для:
- Файлообменных сетей и распределённого хранения данных.
- Приложений, где не требуется строгая централизация и контроль.
- Сценариев, где критична отказоустойчивость и отсутствие единой точки отказа.
- Решений с большим количеством равноправных участников, готовых предоставлять ресурсы.
Edge computing целесообразен для:
- IoT-устройств и интернета вещей, генерирующих большие объёмы данных.
- Приложений реального времени с жёсткими требованиями к задержкам (промышленная автоматика, автономные транспортные средства).
- Сценариев, где передача всех данных в облако нецелесообразна из-за ограничений пропускной способности сети.
- Решений, которые должны сохранять базовую функциональность при потере связи с центральным узлом.
Serverless architecture эффективна когда:
- Нагрузка непредсказуема или имеет выраженные пики и спады.
- Требуется быстрое развёртывание и минимальные затраты на инфраструктуру.
- Разрабатывается микросервисная архитектура с независимыми функциональными модулями.
- Задачи хорошо декомпозируются на отдельные функции с чёткими границами.
На практике чистые архитектурные модели встречаются редко. Современные крупные проекты часто представляют собой гибридные решения: клиент-серверная база с элементами edge computing для критичных по времени операций, serverless-функции для обработки событий, P2P-компоненты для распределения нагрузки. Искусство архитектора заключается в том, чтобы найти оптимальный баланс между различными подходами, учитывая специфику конкретной задачи, доступные ресурсы и долгосрочные перспективы развития.
Заключение
Клиент-серверная архитектура остаётся фундаментальной моделью организации современных информационных решений. Мы рассмотрели её ключевые принципы — от базового взаимодействия между клиентом и сервером до сложных многоуровневых конструкций с балансировщиками нагрузки и резервированием. Подведем итоги:
- Клиент-серверная архитектура — это модель взаимодействия, где клиент отправляет запросы, а сервер их обрабатывает. Такой подход позволяет чётко разделить ответственность между пользовательской и серверной частью.
- В системе выделяются клиент, сервер приложений и база данных. Это повышает надёжность хранения информации и упрощает управление логикой приложения.
- Клиенты могут быть тонкими, толстыми или гибридными. Выбор типа влияет на производительность, автономность и требования к инфраструктуре.
- Взаимодействие строится по циклу «запрос — обработка — ответ». Эффективность этого процесса напрямую отражается на скорости работы и удобстве для пользователя.
- Трёхуровневая архитектура обеспечивает масштабируемость и безопасность по сравнению с двухуровневой. При росте нагрузки её дополняют балансировщиками и резервированием.
- Клиент-серверная модель широко применяется в веб-сервисах, мобильных приложениях и финансовых системах. Несмотря на ограничения, она остаётся основой большинства современных решений.
Рекомендуем обратить внимание на подборку курсов по веб-разработке., если вы только начинаете осваивать эту профессию. В программах обычно есть теоретическая и практическая часть, которые помогают разобраться в принципах клиент-серверной архитектуры и закрепить знания на реальных примерах.
Рекомендуем посмотреть курсы по веб разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Веб-разработчик
|
Eduson Academy
114 отзывов
|
Цена
119 000 ₽
|
От
9 917 ₽/мес
|
Длительность
12 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Веб-разработчик с нуля до PRO
|
Skillbox
232 отзыва
|
Цена
294 783 ₽
589 565 ₽
Ещё -20% по промокоду
|
От
8 670 ₽/мес
Без переплат на 1 год.
|
Длительность
10 месяцев
|
Старт
23 марта
|
Подробнее |
|
Веб-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
163 300 ₽
302 470 ₽
с промокодом kursy-online
|
От
5 041 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 апреля
|
Подробнее |
|
Fullstack-разработчик на python (с нуля)
|
Eduson Academy
114 отзывов
|
Цена
158 760 ₽
|
От
13 230 ₽/мес
20 642 ₽/мес
|
Длительность
7 месяцев
|
Старт
24 марта
|
Подробнее |
|
Профессия Веб-разработчик
|
Skillbox
232 отзыва
|
Цена
152 538 ₽
305 075 ₽
Ещё -20% по промокоду
|
От
4 486 ₽/мес
Без переплат на 34 месяца с отсрочкой платежа 3 месяца.
|
Длительность
24 месяца
|
Старт
23 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.