Natural Language Processing — что это, как работает и зачем нужно изучать NLP
Natural Language Processing (NLP) — это направление искусственного интеллекта, которое помогает компьютерам понимать, интерпретировать и генерировать человеческий язык. Сегодня эта технология лежит в основе чат-ботов, голосовых помощников, переводчиков и аналитических систем. В этом курсе вы узнаете, как работает обработка естественного языка, какие задачи решает NLP и почему она стала ключевой технологией в развитии искусственного интеллекта.

Мы подробно разберём основные этапы обработки текста — от токенизации до генерации речи, познакомимся с нейронными сетями и современными моделями вроде BERT и GPT. После изучения материала вы поймёте, как NLP используется в маркетинге, медицине, финансах и поисковых системах, а также как начать обучение этой перспективной специальности.
- Что такое NLP? Простыми словами
- Как работает NLP: основные этапы обработки текста
- Сбор и подготовка данных
- Предобработка текста
- Анализ и обработка текста
- Машинное обучение в NLP
- Основные задачи NLP и их применение
- Распознавание речи
- Машинный перевод
- Анализ тональности текста
- Извлечение информации
- Генерация текста
- Где применяется NLP: реальные кейсы
- Маркетинг и реклама
- Финансы
- Медицина
- Поисковые системы
- Ограничения и проблемы NLP
- Многозначность слов и контекст
- Непонимание иронии и сарказма
- Этические вопросы
- Как изучить NLP и с чего начать?
- Лучшие книги и курсы по NLP
- Инструменты и библиотеки для работы с NLP
- Заключение
- Рекомендуем посмотреть курсы по робототехнике для взрослых
Что такое NLP? Простыми словами
Обработка естественного языка (NLP) — это технология, которая позволяет компьютерам взаимодействовать с людьми на их родном языке. Представьте, что вы можете разговаривать с машиной так же естественно, как с другом или коллегой, а она не только понимает ваши слова, но и улавливает контекст, эмоции и даже подтекст. Именно к этому идеалу стремится Natural Language Processing.
В отличие от традиционных алгоритмов, которые просто реагируют на шаблонные фразы или ключевые слова, современные NLP-системы действительно «понимают» язык. Классический пример: старые алгоритмы не могли увидеть разницу между столовой ложкой и школьной столовой, потому что просто сравнивали наборы символов. Современные же модели учитывают контекст и могут различать подобные омонимы.
Natural Language Processing решает множество задач, связанных с обработкой текста и речи:
- Распознает человеческую речь и переводит её в текст (как это делают голосовые помощники)
- Анализирует структуру и смысл написанного (что позволяет поисковым системам находить релевантные ответы)
- Классифицирует тексты по темам, жанрам, эмоциональной окраске
- Извлекает ключевую информацию из больших объемов данных
- Генерирует собственные тексты — от простых ответов до полноценных статей
- Переводит с одного языка на другой с учетом контекста и культурных особенностей
Для этого NLP-системам недостаточно просто «знать слова» — они должны понимать структуру языка, правила грамматики, контекст употребления и множество других лингвистических нюансов. Такое понимание достигается благодаря сложным алгоритмам машинного обучения, которые анализируют огромные массивы текстов и учатся на них распознавать закономерности.
Можно сказать, что Natural Language Processing — это своеобразный переводчик между миром естественных человеческих языков и формализованным языком компьютерных алгоритмов. И с каждым годом этот переводчик становится всё более искусным и точным.
Как работает NLP: основные этапы обработки текста
Чтобы компьютер мог работать с человеческим языком, текст должен пройти несколько этапов преобразования. Этот процесс можно сравнить с переводом с человеческого языка на машинный. Давайте рассмотрим, как Natural Language Processing превращает обычный текст в структуры данных, с которыми могут работать алгоритмы машинного обучения.
Сбор и подготовка данных
Любая NLP-система начинается с данных — и чем их больше, тем лучше. Дата-сайентисты используют два основных подхода:
- Сбор данных из открытых источников — социальных сетей, новостных агрегаторов, цифровых библиотек, форумов и других публичных ресурсов. Это позволяет создавать универсальные языковые модели, способные работать с разнообразными текстами. Именно на таких данных обучались ChatGPT и другие крупные языковые модели.
- Использование корпоративных данных — истории заказов, запросов в службу поддержки, внутренней документации. Такой подход характерен для специализированных NLP-систем, заточенных под конкретную индустрию или задачу.
Интересно, что модели можно обучать даже на данных одного человека. Например, американский инфлюенсер Карин Марджори создала свою виртуальную копию на основе видео с собственного YouTube-канала. Эта модель имитирует её речь и манеру общения, став, по сути, цифровым двойником.
Предобработка текста
Полученные «сырые» данные необходимо структурировать и привести к виду, понятному машине. Этот этап включает:
- Очистку данных — удаление дублей, ненужных символов, приведение текста к единому регистру. Чем «чище» данные, тем проще модели выделить в них значимые закономерности.
- Токенизацию — разбиение текста на минимальные смысловые единицы (токены). В зависимости от задачи токенами могут быть слова, символы, фразы или даже предложения. Например:
«Привет, как дела?» → [«Привет», «,», «как», «дела», «?»]
«Hello» → [«H», «e», «l», «l», «o»]
«Купите сегодня и получите скидку 20%!» → [«Купите сегодня», «и получите скидку», «20%!»]
- Лемматизацию — приведение слов к их базовой форме (лемме). В русском и многих других языках слова имеют множество форм с одинаковым смыслом. Например, «горячий», «горячая», «горячее» сводятся к лемме «горячий».
- Стемминг — более грубый процесс выделения основы слова путем отсечения окончаний и суффиксов. Например, слова «горячий», «горячка», «горячо» сводятся к основе «горяч».
- Удаление стоп-слов — исключение слов, которые встречаются слишком часто и не несут самостоятельной смысловой нагрузки (предлоги, союзы, междометия).
- Разметку данных — присвоение меток токенам для обучения модели. Например, для переводчика нужно указать язык и часть речи каждого слова.
Анализ и обработка текста
На этом этапе происходит глубинный анализ подготовленного текста:
- POS-теггинг (Part-of-Speech Tagging) — определение частей речи для каждого слова в предложении. Это критически важно для понимания роли слова в предложении.
- Синтаксический анализ — выявление грамматических связей между словами и структуры предложения. Например, определение подлежащего, сказуемого, дополнений.
- Семантический анализ — извлечение смысла из слов и предложений. Здесь системы Natural Language Processing пытаются понять, о чем говорится в тексте на уровне значений, а не просто грамматических структур.
- Прагматический анализ — учет контекста и скрытых смыслов. На этом уровне система пытается понять, что именно имелось в виду, учитывая ситуацию, в которой создавался текст.
Машинное обучение в NLP
Завершающий и, пожалуй, самый важный этап — применение алгоритмов машинного обучения для решения конкретных задач. На сегодняшний день наиболее эффективны следующие подходы:
- Нейронные сети — особенно рекуррентные (RNN) и трансформеры, способные учитывать контекст и взаимосвязи между словами.
- Глубинное обучение — многослойные нейронные сети, позволяющие выявлять сложные закономерности в данных.
- Языковые модели — алгоритмы, предсказывающие вероятность следующего слова или фразы на основе предыдущих.
| Модель | Разработчик | Год выпуска | Особенности |
|---|---|---|---|
| BERT | 2018 | Двунаправленная модель, учитывающая контекст с обеих сторон слова | |
| GPT-4 | OpenAI | 2023 | Генеративная модель с глубоким пониманием контекста и способностью создавать тексты различных стилей |
| T5 | 2019 | Универсальная модель, рассматривающая все NLP-задачи как задачи преобразования текста | |
| XLNet | Google/CMU | 2019 | Автореграссивная модель, превзошедшая BERT в ряде задач |
| RoBERTa | 2019 | Оптимизированная версия BERT с улучшенной производительностью |
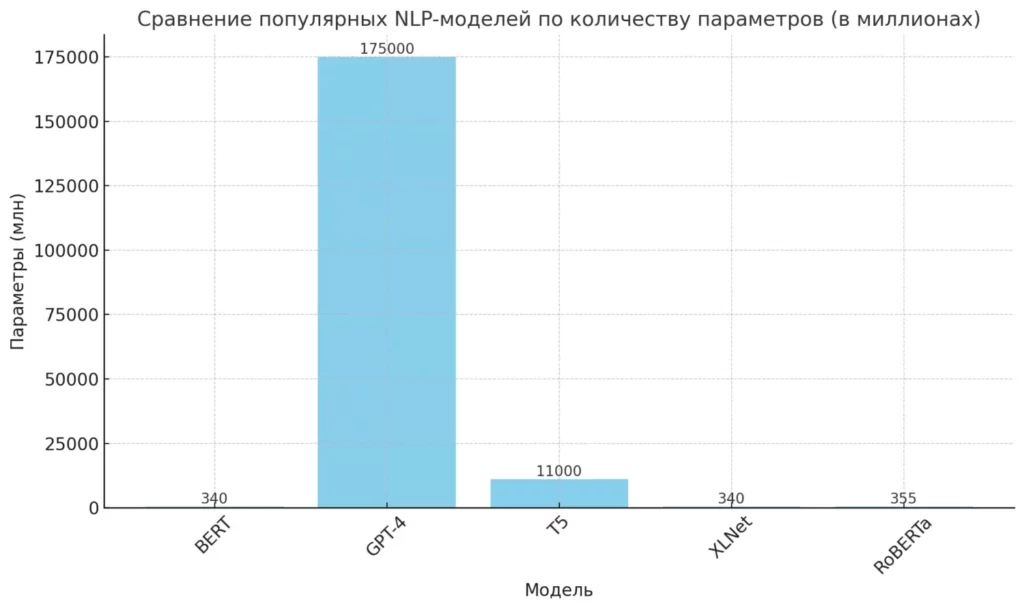
Диаграмма, показывающая сравнение популярных NLP-моделей по количеству параметров (в миллионах)
Каждый из этих этапов вносит свой вклад в способность машины понимать человеческий язык. От качества выполнения каждого из них зависит, насколько точно и осмысленно система сможет работать с текстом, будь то анализ документов, перевод или генерация новых текстов.
Основные задачи NLP и их применение
В современном мире обработка естественного языка решает множество практических задач, которые еще недавно казались прерогативой исключительно человеческого интеллекта. Рассмотрим ключевые направления Natural Language Processing и их реальное применение.
Распознавание речи
Технология, преобразующая устную речь в текстовый формат, стала неотъемлемой частью нашей повседневности. Умные колонки с Алисой, Siri и другими голосовыми помощниками «слушают» нас и интерпретируют наши команды благодаря алгоритмам распознавания речи.
Процесс работает следующим образом: сначала аудиоустройство записывает звуковые волны, затем NLP-система разбивает их на фонемы (минимальные звуковые единицы языка), после чего алгоритм сопоставляет последовательности фонем со словами из своего словаря и, наконец, формирует из них осмысленный текст.
Интересный кейс — технология синтеза речи для людей с нарушениями коммуникации. Знаменитый физик Стивен Хокинг общался с миром именно благодаря Natural Language Processing: он вводил текст в систему с помощью единственной доступной ему мышцы щеки, а программа преобразовывала его в речь. Современные системы могут даже генерировать уникальный голос, имитирующий речь конкретного человека.
Машинный перевод
От примитивных пословных переводчиков до контекстно-зависимых нейросетевых систем — эволюция машинного перевода наглядно демонстрирует прогресс в области NLP.
Современные системы, такие как Google Translate или DeepL, используют нейронный машинный перевод (NMT), который учитывает не только отдельные слова, но и контекст всего предложения. Вместо прямого преобразования «слово в слово» они работают с векторными представлениями предложений, сохраняя смысловые нюансы и учитывая грамматические особенности языков.
Показательный пример: фраза «Я не могу с ним разговаривать, у него горячая голова» при дословном переводе на английский потеряла бы смысл, но современные Natural Language Processing-системы способны распознать идиому и перевести её как «I can’t talk to him, he’s hot-headed» — сохраняя смысл, а не буквальный перевод.
Анализ тональности текста
Эта задача включает определение эмоциональной окраски текста — положительной, отрицательной или нейтральной. Бизнес активно использует данную технологию для мониторинга отзывов клиентов, анализа репутации бренда и отслеживания настроений в социальных сетях.
Алгоритмы анализа тональности работают на нескольких уровнях:
- Документный уровень: определение общей тональности текста
- Уровень предложений: анализ эмоциональной окраски каждого предложения
- Уровень аспектов: выявление отношения автора к конкретным аспектам (например, в отзыве о смартфоне отдельно оценивается отношение к камере, батарее, дизайну)
Крупные бренды используют эти технологии для быстрого реагирования на негативные отзывы и выявления проблемных аспектов продуктов, не дожидаясь, пока недовольство клиентов примет массовый характер.
Извлечение информации
Данное направление Natural Language Processing фокусируется на автоматическом выделении структурированных данных из неструктурированных текстов. Например, система может «прочитать» новостную статью и выделить из неё ключевые факты: кто участвовал, где и когда произошло событие, какие компании упоминались.
Одна из подзадач — распознавание именованных сущностей (Named Entity Recognition, NER). Алгоритм NER идентифицирует в тексте имена людей, названия организаций, географические локации, даты и другие объекты. Так, из фразы «Иван Петров работает в Google в Москве с 2020 года» система извлечет: «Иван Петров» (персона), «Google» (организация), «Москва» (локация), «2020 год» (дата).
Эта технология активно применяется в юридической сфере для анализа контрактов, в финансовом секторе для извлечения ключевых данных из отчетов и в медицине для структурирования информации из медицинских карт пациентов.
Генерация текста
Пожалуй, самое впечатляющее направление NLP сегодня — создание осмысленных текстов с нуля. Модели, подобные GPT-4 или GigaChat, способны генерировать статьи, рассказы, диалоги и даже программный код, часто на уровне, неотличимом от человеческого.
Механизм генерации текста основан на вероятностных моделях: система предсказывает, какие слова с наибольшей вероятностью должны следовать за уже имеющимся контекстом. При этом учитываются грамматические правила, стилистическая согласованность и тематическая релевантность.
Практические применения включают:
- Автоматическое создание отчетов и аналитических записок на основе данных
- Генерацию персонализированных маркетинговых материалов
- Написание новостных заметок (многие финансовые и спортивные новости уже создаются алгоритмами)
- Помощь в творческом письме и преодолении «писательского блока»
- Создание документации и технических описаний
Интересно, что сегодняшние генеративные модели не просто комбинируют заученные фрагменты текста — они демонстрируют элементы оригинальности и «креативности», способны поддерживать стилистическое единство и логическую связность на протяжении длинных текстов.
Возникает закономерный вопрос: не приведет ли развитие таких систем к вытеснению человека из творческих профессий? Вероятно, ответ заключается в трансформации, а не замене: NLP становится мощным инструментом усиления человеческих возможностей, но пока не способна воспроизвести глубину человеческого опыта и эмоций, лежащих в основе по-настоящему выдающихся произведений.
Где применяется NLP: реальные кейсы
Обработка естественного языка из сугубо академической области превратилась в мощный инструмент, трансформирующий множество индустрий. Рассмотрим конкретные примеры применения Natural Language Processing в различных секторах экономики и повседневной жизни.
Маркетинг и реклама
В эпоху информационного шума и перенасыщения рекламой NLP становится незаменимым инструментом для маркетологов. С его помощью компании:
- Анализируют настроения клиентов — парсинг отзывов и комментариев в социальных сетях с последующим семантическим анализом позволяет определить, насколько положительно аудитория отзывается о бренде или продукте.
- Оптимизируют маркетинговые кампании — NLP-алгоритмы помогают определить, какие ключевые сообщения находят наилучший отклик у целевой аудитории.
- Создают персонализированный контент — на основе предпочтений конкретного пользователя система генерирует уникальные предложения и рекламные тексты.
Например, крупные онлайн-ритейлеры используют Natural Language Processing для категоризации отзывов клиентов по темам (качество продукта, доставка, обслуживание) и автоматического выявления проблемных аспектов, требующих немедленного вмешательства.
Финансы
Финансовый сектор, оперирующий огромными массивами текстовой информации, активно внедряет NLP для:
- Анализа рыночных настроений — алгоритмы обрабатывают новости, финансовые отчеты и социальные медиа для прогнозирования движений рынка.
- Выявления мошенничества — Natural Language Processing-системы выявляют подозрительные паттерны в финансовых транзакциях и коммуникациях.
- Автоматизации комплаенса — анализ юридических документов и нормативных актов для обеспечения соответствия деятельности компании законодательным требованиям.
Интересный пример — IndexGPT от JPMorgan Chase, который, согласно имеющейся информации, будет использовать NLP для создания структурированных инвестиционных отчетов, анализируя данные о компаниях из новостей, финансовых документов и социальных сетей.
Медицина
В здравоохранении NLP помогает справиться с огромным объемом неструктурированной медицинской информации:
- Анализ медицинских записей — извлечение ключевой информации из историй болезни, результатов исследований и заключений врачей.
- Поддержка диагностики — сопоставление симптомов пациента с медицинской литературой и базами данных заболеваний.
- Мониторинг побочных эффектов лекарств — анализ отзывов пациентов о лекарственных препаратах для раннего выявления неизвестных ранее нежелательных реакций.
Кроме того, Natural Language Processing используется для синтеза речи в программах и устройствах для людей с нарушениями речи, позволяя им коммуницировать с окружающим миром.
Поисковые системы
Современные поисковики давно переросли примитивное сопоставление ключевых слов и активно используют NLP для понимания смысла запросов:
- Семантический поиск — понимание намерения пользователя, а не просто поиск по ключевым словам. Например, на запрос «высокие здания в мире» система покажет список небоскребов, даже если слово «небоскреб» в запросе отсутствует.
- Ответы на естественно-языковые вопросы — современные поисковики часто выдают прямой ответ на вопрос, а не просто список ссылок.
- Учет контекста — понимание многозначных слов на основе контекста запроса и предыдущих поисков пользователя.
Яндекс и Google используют сложные Natural Language Processing-алгоритмы для определения релевантности страниц не только по наличию ключевых слов, но и по смысловому соответствию содержимого запросу пользователя. Это позволяет бороться с искусственным «заспамливанием» текстов ключевыми словами и повышает качество поисковой выдачи.
Интересно, что развитие Natural Language Processing постепенно меняет и сам характер поисковых запросов: пользователи всё чаще формулируют их в виде полноценных вопросов, а не наборов ключевых слов, зная, что современные поисковики способны понимать естественную речь.
Таким образом, NLP из вспомогательной технологии превращается в центральный элемент многих бизнес-процессов, позволяя компаниям автоматизировать рутинные задачи, связанные с обработкой текстовой информации, и извлекать ценные инсайты из, казалось бы, неструктурированных данных.
Ограничения и проблемы NLP
Несмотря на впечатляющий прогресс последних лет, технологии обработки естественного языка сталкиваются с рядом фундаментальных вызовов. Эти ограничения важно понимать, чтобы реалистично оценивать возможности современных Natural Language Processing-систем и осознавать направления их дальнейшего совершенствования.
Многозначность слов и контекст
Одна из главных проблем NLP — это семантическая неоднозначность, свойственная человеческим языкам. Компьютерам до сих пор сложно работать с:
- Омонимами и омографами — словами, которые пишутся и/или звучат одинаково, но имеют разные значения. Классические примеры: «ключ» (для замка или источник воды), «лук» (растение или оружие), «коса» (прическа, инструмент или географический объект).
- Многозначными словами — где значение определяется исключительно контекстом. Например, в предложении «Человек носил костюм, и он был синий» системе нужно определить, что именно было синим — костюм или человек.
- Сложными конструкциями с множественной вложенностью. Известный пример из английского языка: «Will, will Will will Will Will’s will?» («Уилл, завещает ли Уилл Уиллу завещание Уилла?») демонстрирует, как одно и то же слово может выполнять в предложении совершенно разные функции.
Хотя современные модели на основе трансформеров (например, BERT и GPT) значительно продвинулись в разрешении таких неоднозначностей, они всё еще часто совершают ошибки в особенно сложных случаях или при недостатке контекста.
Непонимание иронии и сарказма
Распознавание непрямого, имплицитного смысла — особенно сложная задача для NLP-систем. Проблемы возникают с:
- Сарказмом и иронией — когда буквальное значение высказывания противоположно тому, что имел в виду говорящий. Фраза «Какая прекрасная погода!» в дождливый день будет воспринята Natural Language Processing-системой буквально, если нет дополнительных указаний на иронию.
- Юмором — понимание шуток требует не только языковых знаний, но и понимания культурного контекста, социальных норм и часто — способности к нестандартному мышлению.
- Метафорами и идиомами — распознавание выражений, значение которых не сводится к смыслу составляющих их слов («зарубить на носу», «держать язык за зубами» и т.д.).
Эти аспекты коммуникации подразумевают глубокое понимание как лингвистического, так и экстралингвистического контекста — того, что находится за пределами текста. Даже самые продвинутые нейросетевые модели часто «спотыкаются» на таких неоднозначностях.
Этические вопросы
По мере развития Natural Language Processing всё острее встают этические вопросы использования этой технологии:
- Генерация дезинформации — современные языковые модели способны создавать убедительные фальшивые новости, академические статьи и другой контент, который трудно отличить от созданного человеком.
- Алгоритмическая предвзятость — модели обучаются на существующих текстах, которые могут содержать социальные предрассудки и стереотипы. В результате NLP-системы нередко воспроизводят и даже усиливают существующие в обществе предубеждения по отношению к определенным группам людей.
- Конфиденциальность данных — использование Natural Language Processing для анализа личных сообщений, электронной почты и других приватных текстов поднимает вопросы о границах частной жизни.
- Деперсонализация коммуникации — когда всё больше текстов создается автоматически (от ответов на электронные письма до маркетинговых материалов), возникает риск потери подлинного человеческого взаимодействия.
Стоит отметить, что эти проблемы не являются непреодолимыми. Исследователи активно работают над их решением: создаются датасеты с минимальной предвзятостью, разрабатываются методы для определения сарказма и непрямых значений, формируются этические принципы использования NLP.
Однако важно осознавать эти ограничения, чтобы не возлагать на технологию необоснованных ожиданий и понимать, в каких контекстах автоматизированная обработка текста может требовать человеческого контроля или вмешательства. Ведь при всей своей впечатляющей мощи, современные NLP-системы — это инструменты, расширяющие человеческие возможности, а не полноценная замена человеческому интеллекту с его глубиной понимания и эмпатией.
Как изучить NLP и с чего начать?
Обработка естественного языка находится на пересечении лингвистики, компьютерных наук и искусственного интеллекта, что делает её одновременно увлекательной и сложной для изучения. Мы подготовили руководство, которое поможет структурировать процесс погружения в мир Natural Language Processing — от базовых концепций до практического применения.
Лучшие книги и курсы по NLP
Для эффективного изучения NLP рекомендуем комбинировать теоретические материалы с практическими курсами.
Книги для начинающих:
- «Natural Language Processing with Python» (Steven Bird, Ewan Klein, Edward Loper) — классическое введение в NLP с использованием библиотеки NLTK.
- «Speech and Language Processing» (Daniel Jurafsky, James H. Martin) — фундаментальный учебник, охватывающий все аспекты NLP от базовых до продвинутых.
- «Introduction to Natural Language Processing» (Якоб Эйзенштейн) — современный взгляд на основы NLP с акцентом на машинное обучение.
Книги для продвинутого уровня:
- «Neural Network Methods for Natural Language Processing» (Йоав Голдберг) — глубокий анализ применения нейронных сетей в NLP.
- «Foundations of Statistical Natural Language Processing» (Кристофер Мэннинг, Хинрих Шютце) — математические основы NLP.
- «Natural Language Understanding» (Джеймс Аллен) — продвинутые концепции семантического анализа и понимания текста.
Инструменты и библиотеки для работы с NLP
Современные библиотеки значительно упрощают разработку NLP-приложений, предоставляя готовые инструменты для решения типовых задач.
| Библиотека | Язык программирования | Особенности | Лучше подходит для |
|---|---|---|---|
| NLTK | Python | Богатый набор инструментов и корпусов, хорошая документация, образовательная направленность | Новичков, академических проектов, изучения основ NLP |
| spaCy | Python | Высокая производительность, современные алгоритмы, интеграция с нейросетевыми моделями | Промышленных приложений, задач с высокими требованиями к скорости |
| Gensim | Python | Специализированная библиотека для тематического моделирования и векторных представлений слов | Семантического анализа, работы с большими текстовыми корпусами |
| Stanford CoreNLP | Java (с API для Python и других языков) | Высокая точность, широкий спектр инструментов, поддержка многих языков | Задач, требующих высокой лингвистической точности |
| Transformers (Hugging Face) | Python | Доступ к современным предобученным языковым моделям (BERT, GPT, T5 и др.) | Передовых задач NLP, трансферного обучения |
| TensorFlow Text | Python | Интеграция с экосистемой TensorFlow, оптимизация для нейросетевых моделей | Создания кастомных моделей с использованием TensorFlow |
| PyTorch-NLP | Python | Удобные инструменты для работы с текстом в экосистеме PyTorch | Исследований и экспериментов с новыми архитектурами |
| TextBlob | Python | Простой и интуитивный интерфейс, хорошо подходит для быстрого прототипирования | Простых приложений, быстрой проверки концепций |
| natasha | Python | Специализация на русском и других славянских языках | Проектов, где основным языком является русский |
Как структурировать обучение?
- Начните с основ — изучите базовые концепции NLP (токенизация, лемматизация, векторные представления) и основы Python.
- Освойте ключевые библиотеки — начните с NLTK или TextBlob для понимания базовых принципов, затем переходите к более специализированным инструментам.
- Погрузитесь в машинное обучение — изучите основы ML и нейронных сетей, которые применяются в современном NLP.
- Изучите современные архитектуры — разберитесь с трансформерами и другими продвинутыми моделями, используя библиотеку Hugging Face Transformers.
- Реализуйте собственные проекты — применяйте полученные знания на практике, начиная с простых задач (классификация текста, анализ тональности) и постепенно переходя к более сложным.
- Следите за новостями в области — NLP развивается стремительно, регулярно появляются новые архитектуры и подходы. Полезно следить за ресурсами вроде arXiv, конференциями ACL, EMNLP, NAACL, а также блогами Hugging Face и OpenAI.
Независимо от выбранного пути, помните, что ключом к успеху в изучении NLP является баланс между теорией и практикой. Лучше всего новые знания усваиваются, когда вы сразу применяете их к реальным задачам, пусть даже небольшим и учебным.
Заключение
Обработка естественного языка прошла огромный путь от простых алгоритмов сопоставления ключевых слов до сложных нейросетевых систем, способных понимать контекст, генерировать связные тексты и даже улавливать эмоциональные оттенки человеческой речи. Как мы убедились в этой статье, NLP сегодня — это не просто академическая дисциплина, а мощная технология, трансформирующая множество отраслей и аспектов нашей повседневной жизни. Подведем итоги:
- Natural Language Processing — ключевое направление ИИ. Оно учит компьютеры понимать и использовать человеческий язык.
- NLP объединяет лингвистику и машинное обучение. Благодаря этому модели способны анализировать смысл и контекст.
- Основные этапы NLP включают обработку, анализ и генерацию текста. Каждый шаг влияет на точность и качество результата.
- Технологии NLP применяются в бизнесе и повседневной жизни. От чат-ботов до голосовых помощников — всё основано на обработке языка.
- Современные модели, такие как BERT, GPT и T5, определяют развитие области. Они задают стандарты точности и понимания контекста.
- Проблемы NLP связаны с контекстом и этикой. Машины пока не способны до конца понимать сарказм и социальные подтексты.
- NLP открывает путь к новым профессиям. Разработчики и аналитики, владеющие этой технологией, востребованы в ИТ, финансах и маркетинге.
Если вы только начинаете осваивать новую профессию, рекомендуем обратить внимание на курсы по робототехнике. В этом курсе изучаются ключевые принципы NLP — от лингвистических основ до нейронных сетей, с теоретической и практической частью, где можно закрепить знания на реальных проектах.
Рекомендуем посмотреть курсы по робототехнике для взрослых
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Факультет инженер умных устройств
|
GeekBrains
68 отзывов
|
Цена
132 498 ₽
264 996 ₽
с промокодом kursy-online15
|
От
4 275 ₽/мес
До 36 месяцев.
|
Длительность
24 месяца
|
Старт
29 марта
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.