Копирование объектов в Python: простыми словами, с примерами и подводными камнями
В мире Python копирование объектов представляет собой одну из тех тем, которые кажутся простыми на первый взгляд, но скрывают множество подводных камней. Мы часто сталкиваемся с ситуацией, когда разработчики — даже опытные — допускают ошибки, связанные с неправильным пониманием механизма работы со ссылками и значениями.
Суть проблемы заключается в фундаментальном принципе Python: когда мы работаем с переменными, мы на самом деле оперируем ссылками на значения в памяти, а не самими объектами. Это означает, что простое присваивание (new_var = old_var) не создаёт независимую копию данных — оно лишь создаёт новое имя для того же самого объекта. Для неизменяемых типов данных (таких как строки, числа, кортежи) это редко приводит к проблемам, однако при работе с изменяемыми структурами — списками, словарями, пользовательскими значениями — ситуация кардинально меняется.

Почему это важно? Представьте, что вы работаете над проектом, где требуется модифицировать данные без влияния на исходный набор. Или вы разрабатываете систему машинного обучения, где необходимо создавать независимые копии датасетов для различных экспериментов. Непонимание механизмов копирования может привести к труднообнаружимым багам, когда изменения в одной части программы неожиданно влияют на другую. Давайте разберёмся, как избежать этих ловушек и научимся правильно работать с копиями значений.
- Присваивание переменных: почему это не копирование
- Способы копирования в Python
- Поверхностная копия (copy.copy)
- Глубокая копия (copy.deepcopy)
- Поведение копирования с разными типами объектов
- Альтернативные способы, помимо модуля copy
- Глубокое и поверхностное копирование: сравнение
- Частые ошибки и подводные камни
- Как копировать объекты в пользовательских классах
- Заключение
- Рекомендуем посмотреть курсы по Python
Присваивание переменных: почему это не копирование
Прежде чем погружаться в тонкости различных методов копирования, необходимо чётко понять, что происходит при обычном присваивании в Python. Это фундаментальная концепция, непонимание которой приводит к большинству ошибок при работе с объектами.
Что происходит при использовании оператора =
Когда мы используем оператор присваивания, Python не создаёт новое значение в памяти. Вместо этого создаётся новая переменная, которая указывает на тот же самый объект, что и исходная переменная. Можно сказать, что обе переменные становятся разными именами для одной и той же сущности в памяти.
Этот механизм работает эффективно с точки зрения использования ресурсов — зачем дублировать данные, если можно просто создать ещё одну ссылку? Однако для изменяемых объектов это создаёт неожиданное поведение: любая модификация через одну переменную автоматически отражается при обращении через другую.
Пример с изменяемыми объектами (список)
Рассмотрим конкретный пример, который наглядно демонстрирует эту проблему:
old_list = [[1, 2, 3], [4, 5, 6], [7, 8, 'a']]
new_list = old_list
new_list[2][2] = 9
print('Old List:', old_list)
print('ID of Old List:', id(old_list))
print('New List:', new_list)
print('ID of New List:', id(new_list))
Результат выполнения этого кода может удивить тех, кто ожидал независимых списков:
Old List: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
ID of Old List: 140673303268168
New List: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
ID of New List: 140673303268168
Обратите внимание: идентификаторы значений (получаемые через функцию id()) совершенно одинаковы. Это неопровержимое доказательство того, что old_list и new_list — это не два разных списка, а две ссылки на один и тот же объект в памяти. две переменные, указывающие на один список в памяти
Визуализация того, что происходит при new_list = old_list. Обе переменные являются лишь ссылками на один и тот же объект списка в памяти, поэтому изменения через одну переменную отражаются на другой.
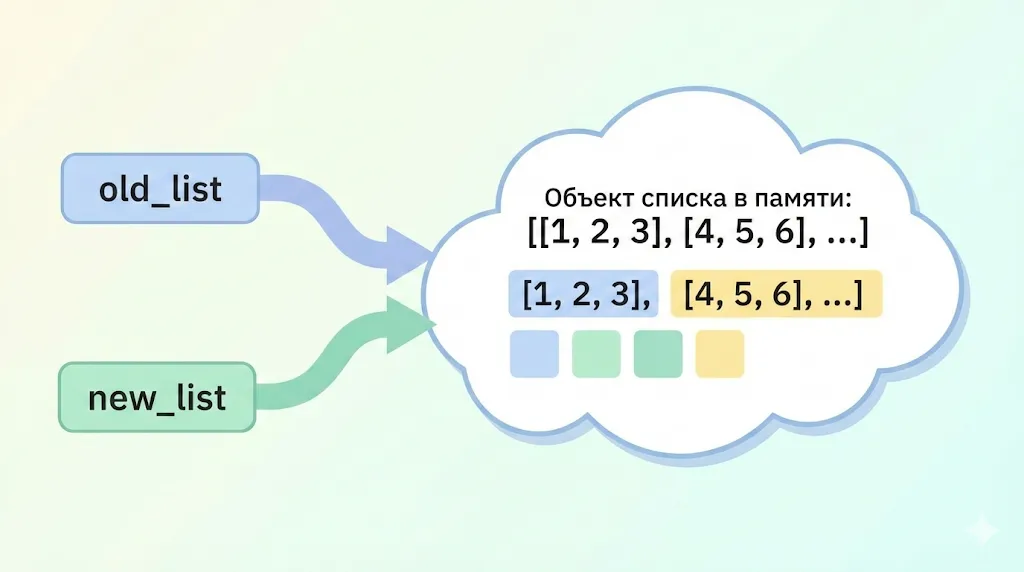
Визуализация того, что происходит при new_list = old_list. Обе переменные являются лишь ссылками на один и тот же объект списка в памяти, поэтому изменения через одну переменную отражаются на другой.
Ключевые выводы:
- Оператор = создаёт новую ссылку, но не новое значение.
- Функция id() позволяет проверить, указывают ли переменные на один объект.
- Изменения через любую из переменных влияют на общий объект.
- Для создания настоящей копии требуются специальные методы.
Способы копирования в Python
Теперь, когда мы понимаем ограничения простого присваивания, возникает логичный вопрос: как же создать настоящую независимую копию объекта? Python предоставляет встроенные инструменты для решения этой задачи, и все они сосредоточены в специальном модуле copy.
Важно понимать, что копирование в Python не является однородным процессом. Существует два принципиально разных подхода к созданию копий, каждый из которых решает свой круг задач. Первый подход — поверхностное копирование — создаёт новый контейнер, но сохраняет ссылки на вложенные значения. Второй — глубокое — рекурсивно копирует всю структуру данных, создавая полностью независимую копию.
Выбор между этими методами зависит от структуры ваших данных и того, какую степень независимости копии вам необходимо обеспечить. Давайте разберёмся, какие инструменты предоставляет модуль copy и для каких сценариев они предназначены.
Модуль copy: какие функции он содержит
Модуль copy предоставляет две основные функции для работы:
copy.copy(x) — создаёт поверхностную (shallow) копию объекта
- Копирует значение верхнего уровня.
- Сохраняет ссылки на вложенные элементы.
- Быстрая операция с минимальным использованием памяти.
- Подходит для простых структур без глубокой вложенности.
copy.deepcopy(x) — создаёт глубокую (deep) копию объекта:
- Рекурсивно копирует все вложенные значения.
- Создаёт полностью независимую структуру данных.
- Требует больше времени и памяти.
- Необходима для сложных вложенных структур.
Эти две функции покрывают практически все сценарии, с которыми мы сталкиваемся при необходимости копирования данных. Выбор между ними определяется тем, насколько глубокую независимость копии нам нужно обеспечить.
Поверхностная копия (copy.copy)
Это первый уровень создания независимых объектов в Python. Этот метод представляет собой компромисс между производительностью и независимостью данных, и понимание его механики критически важно для избежания распространённых ошибок.
Как работает поверхностная копия
При использовании copy.copy() Python создаёт новый объект-контейнер (например, список или словарь), но не копирует элементы, находящиеся внутри этого контейнера. Вместо этого новое значение получает ссылки на те же самые вложенные элементы, что и оригинал.
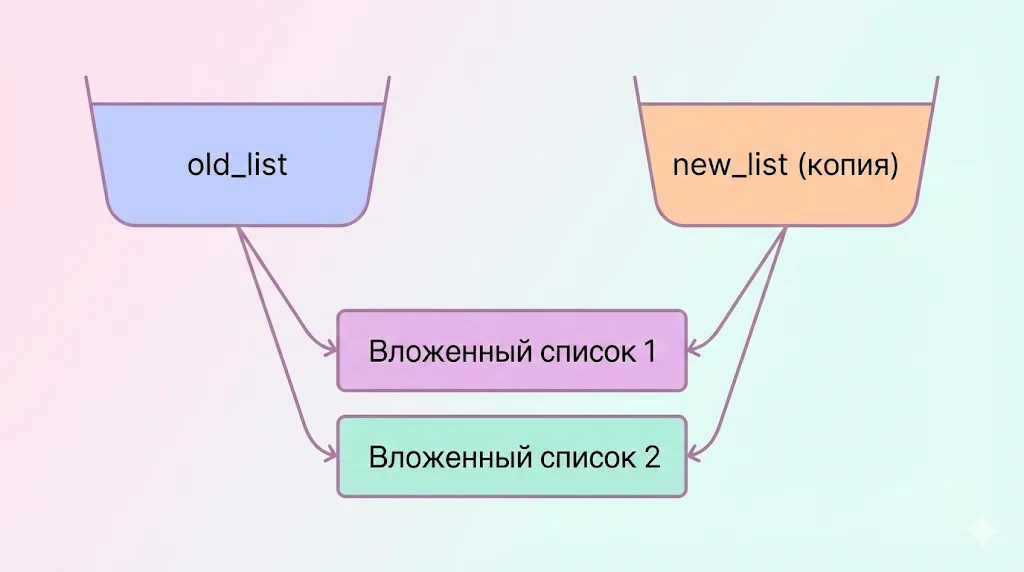
При поверхностном копировании создается новый контейнер (новый список), но его элементы — это ссылки на те же самые вложенные объекты, что и в оригинале. Изменение вложенного списка отразится в обеих копиях.
Можно представить это как создание новой коробки, в которую помещаются не копии предметов, а указатели на те же самые предметы из исходной коробки. Сама коробка — новая и независимая, но её содержимое остаётся общим с оригиналом.
Это означает, что операции на верхнем уровне структуры (например, добавление или удаление элементов из списка) не влияют на оригинал. Однако изменения внутри вложенных значений отразятся в обеих копиях, поскольку они указывают на одни и те же объекты в памяти.
Пример: вложенный список и изменение элементов
Давайте рассмотрим, как поверхностная копия ведёт себя в различных сценариях:
import copy
old_list = [[1, 1, 1], [2, 2, 2], [3, 3, 3]]
new_list = copy.copy(old_list)
# Сценарий 1: добавление нового элемента в old_list
old_list.append([4, 4, 4])
print("Old list:", old_list)
print("New list:", new_list)
Результат:
Old list: [[1, 1, 1], [2, 2, 2], [3, 3, 3], [4, 4, 4]]
New list: [[1, 1, 1], [2, 2, 2], [3, 3, 3]]
В этом случае изменение не затронуло new_list, потому что мы модифицировали сам контейнер верхнего уровня, который является независимым. Однако посмотрим на другой сценарий:
import copy
old_list = [[1, 1, 1], [2, 2, 2], [3, 3, 3]]
new_list = copy.copy(old_list)
# Сценарий 2: изменение вложенного элемента
old_list[1][1] = 'AA'
print("Old list:", old_list)
print("New list:", new_list)
Результат:
Old list: [[1, 1, 1], [2, 'AA', 2], [3, 3, 3]]
New list: [[1, 1, 1], [2, 'AA', 2], [3, 3, 3]]
Здесь изменение отразилось в обоих списках, поскольку вложенные списки [2, 2, 2] в old_list и new_list — это один и тот же объект в памяти, просто доступный через разные контейнеры.
Когда поверхностной копии достаточно
Поверхностное копирование отлично подходит для следующих сценариев:
- Работа со списками или словарями, содержащими только неизменяемые значения (числа, строки, кортежи).
- Ситуации, когда вам нужно изменять структуру контейнера (добавлять/удалять элементы), но не модифицировать их.
- Случаи, когда производительность критична, а глубокая вложенность отсутствует.
- Копирование простых структур данных без вложенных изменяемых объектов.
Глубокая копия (copy.deepcopy)
Глубокая копия решает проблему, с которой мы столкнулись при поверхностном копировании — проблему общих ссылок на вложенные значения. Этот метод обеспечивает полную независимость копии от оригинала, но за это приходится платить дополнительными вычислительными ресурсами.
Механика работы deepcopy
Функция copy.deepcopy() работает принципиально иначе, чем её поверхностный аналог. Вместо простой копии ссылок она рекурсивно обходит всю структуру данных, создавая новые копии каждого вложенного значения на любом уровне.
Процесс выглядит следующим образом: сначала создаётся новый объект-контейнер верхнего уровня, затем Python начинает обрабатывать каждый элемент внутри него. Если элемент сам является составным объектом (списком, словарём, пользовательским классом), то для него рекурсивно вызывается тот же процесс копирования. Это продолжается до тех пор, пока не будут скопированы все объекты на всех уровнях вложенности.
Результат — две полностью независимые структуры данных, которые не имеют общих ссылок на изменяемые значения. Любые модификации в одной структуре никак не влияют на другую.
Пример: независимость копии от оригинала
Давайте посмотрим, как глубокое копирование решает проблему, с которой мы столкнулись при поверхностной копии:
import copy
old_list = [[1, 1, 1], [2, 2, 2], [3, 3, 3]]
new_list = copy.deepcopy(old_list)
# Изменяем вложенный элемент в исходном списке
old_list[1][0] = 'BB'
print("Old list:", old_list)
print("New list:", new_list)
Результат демонстрирует полную независимость:
Old list: [[1, 1, 1], ['BB', 2, 2], [3, 3, 3]]
New list: [[1, 1, 1], [2, 2, 2], [3, 3, 3]]
Изменение затронуло только old_list, поскольку вложенные списки в new_list являются отдельными объектами с собственными адресами в памяти. Это фундаментальное отличие от поверхностного, где оба контейнера ссылались на общие вложенные объекты.Диаграмма глубокого копирования, показывающая две независимые структуры.
Глубокое копирование рекурсивно создает копии всех вложенных объектов. В результате получаются две полностью независимые структуры данных, и изменения в одной никак не влияют на другую.
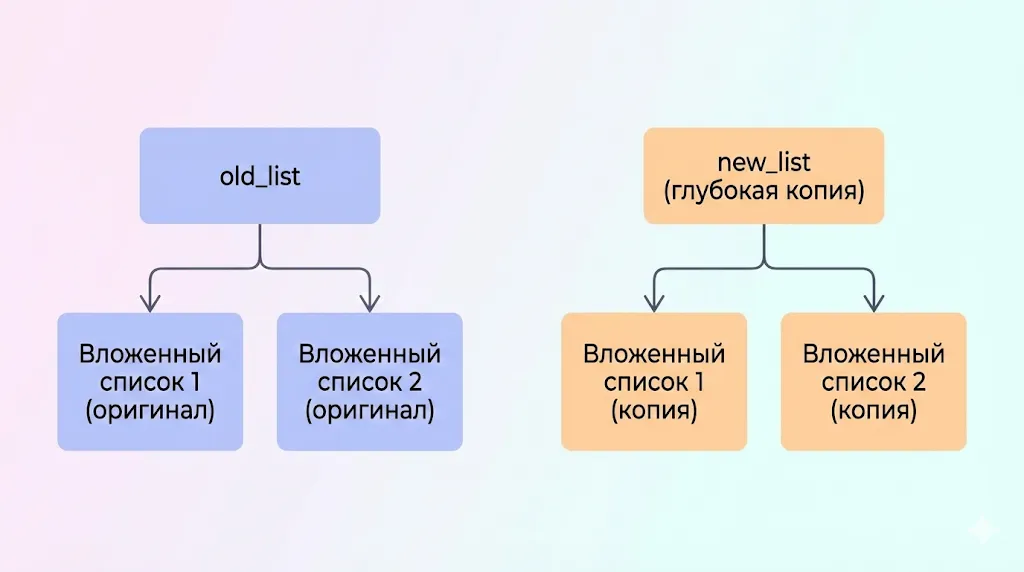
Глубокое копирование рекурсивно создает копии всех вложенных объектов. В результате получаются две полностью независимые структуры данных, и изменения в одной никак не влияют на другую.
Ограничения и особенности
Несмотря на свою мощь, глубокое имеет ряд важных ограничений, которые необходимо учитывать:
- Производительность и память. Рекурсивное копирование всех вложенных значений требует значительно больше времени и памяти по сравнению с поверхностным. Для больших и глубоко вложенных структур данных это может стать критичным фактором, особенно если операция выполняется часто.
- Проблемы с рекурсивными структурами. Если значение содержит циклические ссылки (например, объект A на B, который в свою очередь ссылается на A), deepcopy() обрабатывает это корректно, отслеживая уже скопированные объекты. Однако это добавляет дополнительные накладные расходы.
- Объекты, не поддерживающие копирование. Некоторые значения (например, файловые дескрипторы, сетевые соединения, потоки) принципиально не могут быть скопированы. В таких случаях deepcopy() может вызвать ошибку или потребовать специальной обработки через методы __deepcopy__.
Поведение копирования с разными типами объектов
Понимание того, как Python обрабатывает различные типы данных при копировании, помогает избежать множества ошибок и оптимизировать код. Не все объекты ведут себя одинаково, и это напрямую связано с фундаментальным разделением типов данных на изменяемые и неизменяемые.
Изменяемые и неизменяемые типы
Python различает два класса типов данных, которые принципиально по-разному ведут себя при копировании.
- Неизменяемые типы (immutable) включают числа, строки, кортежи и frozenset. Для этих типов копия фактически не требуется — когда вы пытаетесь «изменить» такой объект, Python создаёт новый с новым значением, а исходный остаётся нетронутым. Более того, copy.copy() и copy.deepcopy() для неизменяемых значений часто возвращают ссылку на тот же самый объект, поскольку создание копии было бы бессмысленной тратой ресурсов.
- Изменяемые типы (mutable) — списки, словари, множества, пользовательские классы — требуют внимательного подхода к копированию. Именно здесь различия между поверхностным и глубоким становятся критически важными.
Копирование списков, словарей и вложенных структур
Различные структуры данных демонстрируют разное поведение в зависимости от уровня вложенности:
import copy
# Простой список с неизменяемыми элементами
simple_list = [1, 2, 3, 'text']
shallow = copy.copy(simple_list)
deep = copy.deepcopy(simple_list)
# Оба метода работают идентично -- полная независимость
# Словарь с вложенными списками
complex_dict = {
'users': ['Alice', 'Bob'],
'scores': [100, 200],
'metadata': {'version': 1}
}
shallow_dict = copy.copy(complex_dict)
shallow_dict['users'].append('Charlie')
# Изменение отразится в оригинале!
deep_dict = copy.deepcopy(complex_dict)
deep_dict['users'].append('David')
# Изменение не затронет оригинал
Типичные ошибки:
- Использование поверхностной копии для вложенных структур в надежде на полную независимость.
- Забывание о том, что словари и множества также подвержены проблеме общих ссылок.
- Попытка копировать значения, содержащие некопируемые элементы (например, lambda-функции, файловые объекты).
- Неучёт того, что пользовательские классы могут требовать специальной обработки при создании копии.
- Излишнее использование deepcopy() там, где достаточно поверхностного копирования, что приводит к неоправданным затратам ресурсов.
Альтернативные способы, помимо модуля copy
Модуль copy — не единственный инструмент для создания копий объектов в Python. Язык предоставляет несколько встроенных механизмов, которые в определённых ситуациях могут быть более удобными или производительными. Давайте разберёмся, какие альтернативы существуют и когда их стоит использовать.
Создание копий стандартными конструкторами
Python позволяет создавать копии встроенных типов данных с помощью их конструкторов:
list(original_list) — создаёт новый список на основе существующего
original = [1, 2, [3, 4]] copied = list(original) # Эквивалентно copy.copy() -- поверхностная копия
dict(original_dict) — создаёт новый словарь
original = {'a': 1, 'b': [2, 3]}
copied = dict(original)
# Также поверхностная копия
set(original_set) — создаёт новое множество
original = {1, 2, 3}
copied = set(original)
# Поверхностная копия множества
Важно понимать: все эти конструкторы создают именно поверхностные копии, аналогично copy.copy(). Вложенные изменяемые объекты остаются общими между оригиналом и копией.
Копирование срезами ([:])
Один из наиболее распространённых идиоматических способов копирования списков в Python — использование полного среза:
original = [1, 2, [3, 4], 5] copied = original[:] # Создаёт поверхностную копию списка
Этот метод работает только для списков и также создаёт поверхностную копию. Несмотря на свою лаконичность, он менее очевиден для читателей кода, особенно для тех, кто не имеет большого опыта работы с Python. Однако в Python-сообществе это устоявшаяся идиома, которая мгновенно распознаётся опытными разработчиками.
Для словарей существует аналогичный метод .copy():
original_dict = {'key': [1, 2, 3]}
copied_dict = original_dict.copy()
# Поверхностная копия словаря
Отличия по производительности и удобству
Выбор между различными методами копирования часто сводится к балансу между читаемостью кода и производительностью:
Преимущества альтернативных методов:
- Более высокая скорость выполнения для простых структур (конструкторы и срезы оптимизированы на уровне интерпретатора).
- Не требуют импорта дополнительных модулей.
- Более идиоматичны для простых случаев.
- Меньше накладных расходов при работе с небольшими объектами.
Недостатки:
- Работают только с базовыми типами данных (списки, словари, множества).
- Всегда создают только поверхностные копии — нет аналога deepcopy().
- Для пользовательских классов требуют дополнительной реализации.
- Менее универсальны — для каждого типа нужен свой подход.
- Могут быть менее очевидны для читателей кода (особенно срезы).
Мы рекомендуем использовать конструкторы и срезы для простых случаев, когда вам точно известно, что работаете с базовыми типами и поверхностного копирования достаточно. Для более сложных сценариев модуль copy остаётся предпочтительным выбором благодаря своей явности и универсальности.
Глубокое и поверхностное копирование: сравнение
Теперь, когда мы детально рассмотрели оба метода, настало время систематизировать полученные знания и провести прямое сравнение. Это поможет быстро принимать правильные решения в реальных проектах.
Табличное сравнение двух видов
| Характеристика | Поверхностное (copy.copy()) | Глубокое (copy.deepcopy()) |
|---|---|---|
| Как создаётся объект | Создаётся новый контейнер, копируются ссылки на элементы | Рекурсивно создаются копии всех объектов на всех уровнях |
| Вложенные объекты | Остаются общими с оригиналом | Полностью независимы от оригинала |
| Скорость | Быстрая операция | Медленнее, особенно для глубоких структур |
| Память | Минимальное потребление | Значительное потребление при глубокой вложенности |
| Типичные области применения | Простые структуры, списки с неизменяемыми элементами, временные модификации структуры контейнера | Сложные вложенные структуры, полная изолированность данных, работа с конфигурациями |
Как выбрать правильный тип копии
Выбор метода должен основываться на конкретных требованиях вашей задачи. Вот практические рекомендации для различных сценариев:
Используйте поверхностное копирование, когда:
- Работаете со списками или словарями, содержащими только неизменяемые объекты (числа, строки, кортежи).
- Планируете изменять только структуру контейнера (добавлять/удалять элементы), но не содержимое вложенных значений.
- Производительность критична, а количество копирований велико.
- Уверены в отсутствии глубокой вложенности изменяемых объектов.
Используйте глубокое, когда:
- Работаете со сложными вложенными структурами данных.
- Требуется полная независимость копии от оригинала.
- Модифицируете данные на любом уровне вложенности.
- Копируете конфигурационные объекты или состояния для последующего восстановления.
- Работаете с данными, которые будут обрабатываться параллельно в разных потоках или процессах.
Используйте альтернативные методы (конструкторы, срезы), когда:
- Работаете с простыми базовыми типами.
- Хотите избежать импорта дополнительных модулей.
- Код должен быть максимально идиоматичным для Python-сообщества.
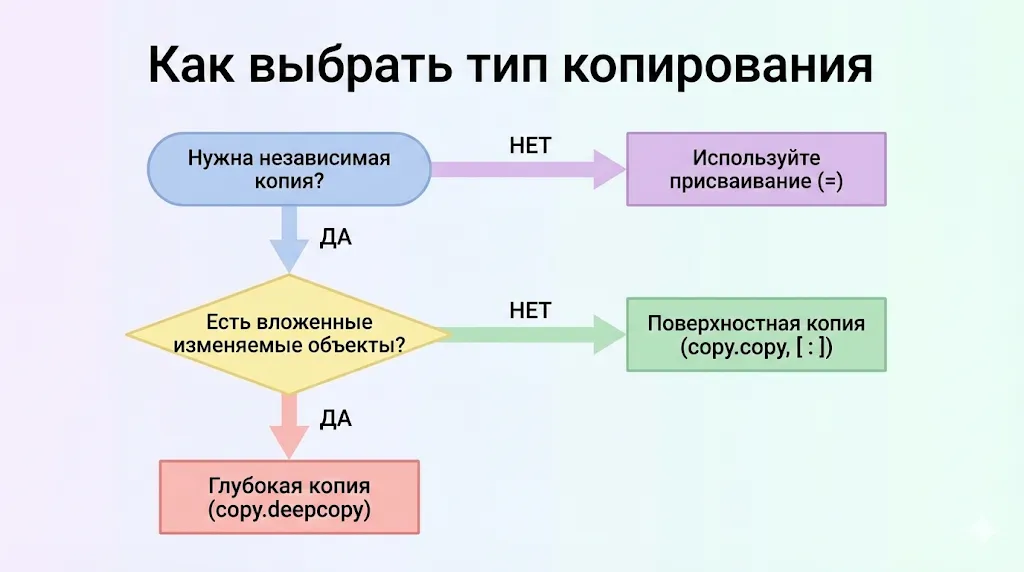
Простая схема, помогающая определить, какой метод копирования использовать в зависимости от ваших задач и структуры данных.
Частые ошибки и подводные камни
Даже опытные разработчики регулярно сталкиваются с ошибками при работе с копированием объектов. Мы собрали наиболее распространённые проблемы, которые возникают в реальных проектах, чтобы помочь вам избежать этих ловушек.
- Ожидание полной независимости при поверхностной копии. Это, пожалуй, самая частая ошибка. Разработчики используют copy.copy() или срезы [:], ожидая получить полностью независимую копию, но забывают о вложенных изменяемых значениях. Результат — неожиданные изменения в исходных данных при модификации копии.
- Изменение вложенных объектов без понимания последствий. Даже понимая разницу между видами копирования, легко забыть проверить, на каком уровне вложенности происходит изменение. Модификация элемента внутри вложенного списка может незаметно повлиять на оригинальные данные.
- Проблемы с копированием пользовательских классов. Стандартные методы могут некорректно работать с пользовательскими классами, особенно если они содержат специфические атрибуты — файловые дескрипторы, соединения с базами данных, потоки. Без реализации методов __copy__ и __deepcopy__ результат может быть непредсказуемым.
- Забытый импорт модуля copy. Тривиальная, но удивительно распространённая ошибка — попытка использовать copy.copy() или copy.deepcopy() без предварительного импорта модуля. Python выдаст ошибку NameError, и время на отладку будет потрачено зря.
- Использование deepcopy() там, где он избыточен. Противоположная проблема — избыточное использование глубокого копирования для простых структур. Это приводит к неоправданным затратам производительности и памяти, особенно если операция выполняется в цикле или при обработке больших объёмов данных.
- Игнорирование циклических ссылок. При работе со сложными структурами данных, где объекты ссылаются друг на друга, можно столкнуться с проблемами. Хотя deepcopy() обрабатывает циклические ссылки корректно, это добавляет накладные расходы, о которых следует помнить.
- Копирование объектов с внешними зависимостями. Попытка скопировать объекты, которые имеют состояние, зависящее от внешних ресурсов (открытые файлы, активные соединения, блокировки), часто приводит к ошибкам во время выполнения или к созданию нерабочих копий.
Как копировать объекты в пользовательских классах
Когда мы работаем с собственными классами, стандартное поведение копирования может оказаться недостаточным или некорректным. Python предоставляет механизм для определения кастомного поведения при создании копии через специальные методы.
Методы __copy__ и __deepcopy__
Для управления процессом копирования пользовательских объектов Python использует два специальных метода:
__copy__(self) определяет поведение при поверхностной копии:
import copy class CustomObject: def __init__(self, value, nested_list): self.value = value self.nested_list = nested_list def __copy__(self): # Создаём новый экземпляр класса new_obj = CustomObject(self.value, self.nested_list) return new_obj obj = CustomObject(42, [1, 2, 3]) shallow = copy.copy(obj) # Вызовется наш метод __copy__
__deepcopy__(self, memo) определяет поведение при глубоком копировании:
import copy class CustomObject: def __init__(self, value, nested_list): self.value = value self.nested_list = nested_list def __deepcopy__(self, memo): # memo используется для отслеживания уже скопированных объектов new_obj = CustomObject( copy.deepcopy(self.value, memo), copy.deepcopy(self.nested_list, memo) ) return new_obj obj = CustomObject(42, [1, 2, 3]) deep = copy.deepcopy(obj) # Вызовется наш метод __deepcopy__
Параметр memo в методе __deepcopy__ — это словарь, который отслеживает уже скопированные объекты для корректной обработки циклических ссылок.
Когда нужно определять своё поведение копирования
Реализация собственных методов копирования необходима в следующих ситуациях:
- Сложные объекты с нестандартной структурой. Если ваш класс содержит атрибуты, которые не должны копироваться стандартным образом — например, кэши, временные данные или вычисляемые свойства — вам нужен контроль над процессом копирования.
- Объекты с внешними ресурсами. Когда класс управляет файловыми дескрипторами, соединениями с базами данных, сетевыми сокетами или другими ресурсами, которые нельзя просто скопировать, необходимо определить, как должна вести себя копия — возможно, она должна открыть новое соединение или использовать то же самое.
- Оптимизация производительности. Иногда вы знаете, какие части объекта нужно копировать, а какие можно безопасно разделить между копиями. Кастомная реализация позволяет оптимизировать использование памяти и времени выполнения.
Заключение
Копирование объектов в Python — тема, которая кажется простой на первый взгляд, но скрывает множество нюансов. Давайте систематизируем ключевые выводы, которые помогут вам избежать распространённых ошибок и выбирать оптимальные решения:
- Копирование в Python основано на работе со ссылками. Простое присваивание не создаёт новый объект, а лишь добавляет новое имя для уже существующего значения.
- Поверхностная копия создаёт новый контейнер, но сохраняет ссылки на вложенные объекты. Это может приводить к неочевидным изменениям данных.
- Глубокое копирование обеспечивает полную независимость структуры. Оно подходит для сложных и вложенных объектов, но требует больше ресурсов.
- Разные типы данных ведут себя по-разному при копировании. Неизменяемые объекты не создают проблем, а изменяемые требуют осознанного подхода.
- Альтернативные способы копирования работают быстрее, но всегда создают только поверхностные копии. Их стоит использовать только в простых сценариях.
- Пользовательские классы могут требовать собственной логики копирования. Реализация copy и deepcopy позволяет избежать ошибок и утечек ресурсов.
Если вы только начинаете осваивать профессию python-разработчика, рекомендуем обратить внимание на подборку курсов по Python. В программах обычно есть и теоретическая часть, и практические задания, которые помогают лучше понять работу с объектами и памятью. Это удобный способ закрепить знания на реальных примерах.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
21 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.