Legacy-код: определение, причины, примеры, преимущества, проблемы и способы работы
Термин «legacy» в контексте программирования имеет несколько иное значение, чем в повседневной жизни. Если в общем смысле слово «наследие» вызывает ассоциации с чем-то ценным и заслуживающим сохранения, то в разработке программного обеспечения legacy-код часто становится источником головной боли для команд разработчиков.

В самом широком понимании legacy-код — это код, который используется в проекте, но был написан не текущей командой разработчиков. Чаще всего он переходит «по наследству» от предыдущих программистов, которые уже покинули компанию или перешли на другие проекты. Представьте ситуацию: у вас есть модуль синхронизации с сервером, написанный восемь лет назад программистом по имени Михалыч, который давно работает в другой компании. Документации к этому коду нет, комментарии отсутствуют, но он работает — и все боятся к нему прикасаться, опасаясь, что «вся система рухнет».
Однако простое определение legacy-кода как «старого» было бы неполным. Давайте рассмотрим ключевые характеристики, которые отличают legacy-код от просто устаревшего программного обеспечения:
Основные признаки legacy-кода:
- Использование устаревших технологий — код написан на старых версиях языков программирования или с применением фреймворков, которые больше не поддерживаются разработчиками.
- Отсутствие документации — нет внятного описания архитектуры, бизнес-логики или особенностей реализации, что делает понимание кода крайне затруднительным.
- Нулевое тестовое покрытие — отсутствие автоматизированных тестов превращает любое изменение в русскую рулетку: непонятно, какие части системы могут сломаться.
- Потеря контекста — разработчики, создававшие код, недоступны для консультаций, а текущая команда не понимает логику принятых архитектурных решений.
Важно понимать, что legacy-код возникает естественным образом в процессе развития любого крупного проекта. Возьмем, к примеру, Windows — в последних версиях этой операционной системы до сих пор обнаруживаются фрагменты кода, написанные более двадцати лет назад. Это не признак низкой квалификации разработчиков Microsoft, а скорее свидетельство эволюции сложных программных систем.
- Как и почему появляется legacy-код: жизненный цикл и реальные сценарии
- Преимущества legacy-кода: когда старый код полезнее нового
- Недостатки и риски legacy-кода
- Легаси — это всегда плохо? Объективный разбор мифа
- Как работать с legacy-кодом: практическое руководство
- Нужно ли переписывать legacy-код полностью: критерии решения
- Заключение
- Рекомендуем посмотреть курсы по веб разработке
Как и почему появляется legacy-код: жизненный цикл и реальные сценарии
Если legacy-код настолько проблематичен, почему же он появляется практически в каждом достаточно крупном проекте? Ответ на этот вопрос кроется в самой природе разработки программного обеспечения. Давайте разберём основные причины, по которым работающий код постепенно превращается в legacy.
- Смена состава команды разработчиков. Это, пожалуй, наиболее распространённый сценарий появления legacy-кода. Разработчики приходят и уходят — кто-то находит более привлекательные предложения, кто-то меняет сферу деятельности, кто-то уходит на пенсию. Вместе с уходом программистов исчезает и ценнейший ресурс — знание о том, почему код написан именно так, какие архитектурные решения были приняты и почему выбраны те или иные подходы к реализации. Новые члены команды сталкиваются с кодом, логика которого им неочевидна, и начинают воспринимать его как legacy.
- Эволюция технологий и инструментов. Индустрия разработки программного обеспечения развивается стремительными темпами. Фреймворки, которые считались передовыми пять лет назад, сегодня могут быть устаревшими или вовсе не поддерживаться. Команда переходит на новую версию языка программирования или современный фреймворк, но полностью переписать весь существующий код нереально с точки зрения затрат времени и ресурсов. В результате в проекте сосуществуют части, написанные на разных технологических стеках, что создаёт дополнительную сложность.
- Дефицит времени и ресурсов. В условиях жёсткой конкуренции и постоянного давления дедлайнов команды часто вынуждены выбирать между написанием качественного, хорошо документированного кода и быстрой доставкой функциональности. Результат предсказуем: документация откладывается «на потом», которое никогда не наступает, тесты не пишутся из-за нехватки времени, а комментарии в коде ограничиваются туманными пометками вроде «это работает, не трогать».
- Изменение требований и архитектуры. По мере роста продукта меняются и требования к нему. То, что изначально проектировалось для работы с несколькими сотнями пользователей, внезапно должно обслуживать миллионы. Архитектурные решения, оптимальные для MVP, становятся узким местом в масштабируемой системе. При этом части старой архитектуры сохраняются, так как их полная замена требует значительных инвестиций.
- Отсутствие практик документирования. Во многих командах, особенно на ранних этапах развития продукта, процессы документирования либо отсутствуют, либо реализуются формально. Разработчики полагаются на устную передачу знаний, считая, что «код сам себя документирует». Однако без формальной документации любое изменение в составе команды приводит к потере критически важного контекста.
Важно отметить, что legacy-код — это не результат злого умысла или непрофессионализма. Это естественное следствие жизненного цикла любого сложного программного продукта, работающего на рынке достаточно долгое время.
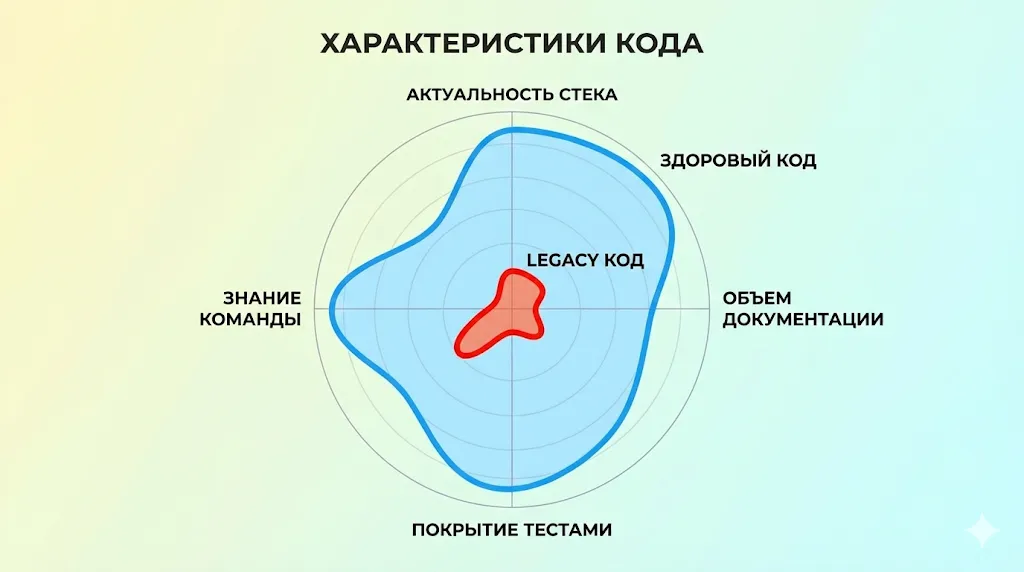
Эта диаграмма наглядно показывает разницу между здоровым и legacy-кодом. Legacy-код проигрывает по всем ключевым показателям, сжимаясь в красную зону риска.
Типовой путь превращения рабочего кода в legacy
Чтобы лучше понять механизм возникновения legacy-кода, проследим типичный жизненный цикл превращения нормального рабочего кода в проблемный legacy. Этот процесс можно разделить на несколько характерных этапов.
- Этап 1: Разработка под текущие требования. Команда создаёт функциональность, полностью соответствующую существующим на тот момент требованиям бизнеса и техническим возможностям. Код пишется на актуальных технологиях, архитектурные решения выбираются исходя из текущего масштаба проекта и предполагаемой нагрузки.
- Этап 2: Эволюция архитектуры системы. Проект растёт, появляются новые требования, меняются подходы к разработке. Команда принимает решение о переходе на более современный технологический стек или новую архитектуру. Однако полная переработка всего кода экономически нецелесообразна, поэтому часть функциональности остаётся на прежних технологиях — ведь она работает стабильно и не требует доработок.
- Этап 3: Смена состава команды. Проходит время, и разработчики, создававшие исходный код, покидают проект. Вместе с ними уходит неформализованное знание о причинах принятых решений, особенностях реализации и потенциальных подводных камнях.
- Этап 4: Потеря контекста. Новая команда сталкивается с кодом, написанным на устаревших технологиях, в стиле, отличающемся от текущих стандартов команды, без документации и тестового покрытия. При этом все остальные части системы уже написаны по-другому, что создаёт когнитивный диссонанс. Попытки разобраться в логике работы натыкаются на отсутствие комментариев и документации. Так рождается legacy.
Любопытно, что этот цикл может повторяться: сегодняшний новый код через пять лет вполне может стать legacy-кодом для следующего поколения разработчиков, если не будут предприняты меры по его документированию и поддержке в актуальном состоянии.
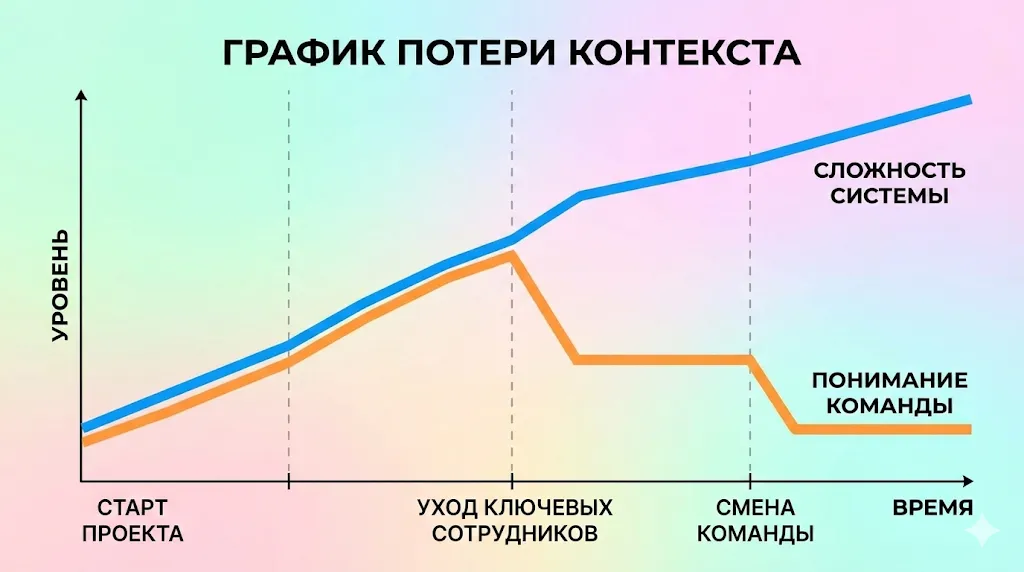
График демонстрирует, как со временем растет сложность системы, в то время как понимание её работы командой может резко падать из-за ухода сотрудников. Этот разрыв и порождает legacy.
Пример реальной ситуации с legacy-кодом
Рассмотрим типичную ситуацию, с которой сталкиваются многие команды разработки. Представьте крупное веб-приложение, в котором есть модуль синхронизации данных с сервером. Этот модуль был написан восемь лет назад опытным разработчиком — назовём его Михалычем — когда продукт только выходил на рынок.
На момент создания модуль представлял собой элегантное решение: он отправлял запросы к серверу в определённой последовательности, сначала указывая адрес сервера, затем номер запроса, и всё работало безупречно. Михалыч заложил в код несколько неочевидных оптимизаций и обработчиков специфичных случаев, которые казались ему настолько очевидными, что документировать их он не стал.
Прошли годы. Михалыч давно перешёл в другую компанию, архитектура приложения несколько раз менялась, команда полностью обновилась. И вот сервер обновляется — теперь API требует сначала передавать номер запроса, а затем адрес. Казалось бы, простая задача: поменять порядок параметров.
Но когда текущая команда открывает код модуля синхронизации, они обнаруживают несколько сотен строк плотного кода без комментариев, написанного в стиле, который давно вышел из употребления. Непонятно, какие части можно безопасно изменить, а какие завязаны на другие модули системы. Тестов нет. Попытка что-то изменить может привести к непредсказуемым последствиям.
В итоге задача, которая должна была занять полчаса, превращается в недельный проект по реверс-инжинирингу чужого кода. Команда решает: «Это legacy, Михалыч писал, работает — не трогаем». Так модуль продолжает жить, становясь всё более изолированным техническим островком в современной кодовой базе.

Идеальная метафора для фразы «все боятся к нему прикасаться, опасаясь, что вся система рухнет». Это создаст эмоциональный отклик, так как чувство напряжения в Дженге знакомо каждому.
Преимущества legacy-кода: когда старый код полезнее нового
Несмотря на негативную репутацию, которую legacy-код заработал в сообществе разработчиков, было бы несправедливо рассматривать его исключительно как проблему. В определённых ситуациях старый код обладает рядом существенных преимуществ перед новыми решениями и их понимание помогает принимать взвешенные решения о судьбе legacy-систем.
- Проверенная временем стабильность и надёжность. Legacy-код, который успешно работает в production-среде на протяжении нескольких лет, прошёл через множество тестирований в реальных условиях. Он пережил периоды пиковых нагрузок, обработал миллионы запросов, столкнулся с различными граничными случаями и edge cases — и продолжает функционировать. Эта боевая закалка делает его надёжным и предсказуемым. В отличие от нового кода, который ещё не столкнулся с полным спектром возможных сценариев использования, legacy-система демонстрирует стабильность, выкованную опытом.
- Инкапсуляция критичной бизнес-логики. Старый код часто содержит ценнейшую информацию об особенностях бизнес-процессов компании, которая накапливалась годами. Разработчики, знакомые с legacy-системой, могут обладать глубоким пониманием работы всей системы и выступать ценным ресурсом для поддержки и обслуживания продукта. Эта бизнес-логика — результат многолетней работы аналитиков, менеджеров продукта и самих разработчиков — представляет собой интеллектуальный актив компании, воссоздание которого с нуля может оказаться чрезвычайно дорогостоящим.
- Экономическая целесообразность поддержки. Парадоксально, но иногда поддержка и модификация legacy-кода оказывается более экономически эффективной стратегией, чем его полная переработка. Переписывание работающей системы требует значительных инвестиций времени, человеческих ресурсов и финансов, при этом несёт риски внесения новых ошибок и потери части функциональности. Если legacy-код требует лишь периодических небольших правок и в целом справляется со своими задачами, затраты на его поддержку могут быть существенно ниже, чем стоимость разработки новой системы с нуля.
Конечно, эти преимущества не означают, что legacy-код следует сохранять любой ценой — речь скорее о необходимости взвешенного подхода к принятию решений о его судьбе.
Недостатки и риски legacy-кода
При всех потенциальных преимуществах было бы нечестным умолчать о существенных проблемах, которые legacy-код создаёт для команд разработки и бизнеса в целом. Давайте рассмотрим основные недостатки, с которыми приходится сталкиваться при работе со старыми системами.
- Повышенная сложность поддержки и понимания. Legacy-код часто лишён качественной документации и понятных комментариев, что превращает даже незначительные изменения в археологическую экспедицию. Разработчики, незнакомые с историей проекта, вынуждены тратить значительное время на изучение структуры кода, расшифровку его логики и понимание особенностей реализации. То, что в хорошо документированной системе заняло бы несколько минут, в legacy-коде может растянуться на часы или даже дни кропотливого анализа.
- Отсутствие тестового покрытия и страх изменений. Пожалуй, одна из самых серьёзных проблем legacy-кода — это отсутствие автоматизированных тестов. Без них любое изменение превращается в рискованную операцию: невозможно с уверенностью сказать, что модификация одной части системы не приведёт к непредвиденным последствиям в других компонентах. Этот страх перед изменениями порождает ситуацию, когда разработчики предпочитают обходить проблемные участки кода стороной, добавляя костыли и workaround-решения вместо исправления корневых причин проблем.
- Ограничение возможностей расширения функциональности. Legacy-код может быть написан на устаревших языках программирования или использовать библиотеки, которые больше не поддерживаются. Это серьёзно ограничивает возможности интеграции с современными технологиями и расширения функциональности системы. Когда бизнес требует добавить новые возможности, оказывается, что legacy-компоненты становятся узким местом, препятствующим внедрению инноваций.
- Потенциальные уязвимости и угрозы безопасности. Legacy-код, особенно если он не обновлялся и не обслуживался длительное время, может содержать критические уязвимости безопасности. Устаревшие библиотеки и фреймворки, в которых обнаружены security-проблемы, представляют реальную угрозу для всей системы. При этом исправление таких уязвимостей в legacy-коде оказывается нетривиальной задачей из-за отсутствия понимания всех зависимостей и взаимосвязей в системе.
Эти недостатки делают работу с legacy-кодом не просто неудобной, но и потенциально опасной для бизнеса, особенно в долгосрочной перспективе.
Легаси — это всегда плохо? Объективный разбор мифа
После рассмотрения преимуществ и недостатков legacy-кода возникает закономерный вопрос: можем ли мы однозначно считать его негативным явлением? Ответ, как это часто бывает в сложных технических вопросах, находится где-то посередине.
Главная проблема legacy-кода заключается не в том, что он плохо работает или содержит критические ошибки — напротив, зачастую такой код демонстрирует завидную стабильность и надёжность. Основная сложность связана с неудобством его поддержки и модификации. Представьте ситуацию: у вас есть старый, но исправно работающий автомобиль, запчасти для которого больше не производятся, а схема его устройства утеряна. Машина едет, но любой ремонт превращается в квест по поиску решений и адаптации современных компонентов к устаревшей конструкции.
Аналогично и с legacy-кодом: если он стабильно выполняет свои функции и не требует частых изменений, то его существование вполне оправдано. Проблемы начинаются в момент, когда бизнес-требования меняются, и этот код необходимо модифицировать или интегрировать с новыми системами. Вот тогда и проявляются все его недостатки: отсутствие документации, непонятная архитектура, устаревшие паттерны проектирования.
Важно понимать, что legacy-код — это не показатель низкой квалификации разработчиков, а естественная часть жизненного цикла любого достаточно крупного и долгоживущего программного продукта. Даже в таких технологических гигантах, как Microsoft, Apple или Google, существуют legacy-компоненты, которые продолжают функционировать десятилетиями. Вопрос не в том, чтобы полностью избавиться от legacy-кода — это утопия, — а в том, чтобы научиться эффективно с ним работать и минимизировать связанные с ним риски.
Таким образом, legacy-код следует рассматривать не как абсолютное зло, требующее немедленного искоренения, а как техническую реальность, требующую взвешенного и прагматичного подхода.
Как работать с legacy-кодом: практическое руководство
Работа с legacy-кодом представляет собой специфическую задачу, требующую особого подхода и методологии. Нельзя просто взять и начать вносить изменения наугад — такая стратегия с высокой вероятностью приведёт к появлению новых ошибок и дестабилизации системы. Давайте рассмотрим систематический подход к работе со старым кодом, который позволит минимизировать риски и повысить эффективность разработки.
- Погружение в контекст и архитектуру. Прежде чем приступать к каким-либо изменениям, критически важно потратить время на изучение существующего кода и понимание его архитектуры. Это не пустая трата времени, а необходимая инвестиция, которая окупится в процессе дальнейшей работы. Начните с высокоуровневого обзора: какие компоненты существуют в системе, как они взаимодействуют друг с другом, где находятся критические точки интеграции. Затем углубляйтесь в детали интересующих вас модулей, прослеживая потоки данных и логику выполнения. Понимание текущего функционала и основных проблем поможет определить, какие изменения необходимо внести и какие риски могут возникнуть.
- Создание защитной сети из тестов. Один из главных страхов при работе с legacy-кодом — это возможность что-то сломать, причём так, что последствия проявятся не сразу. Решение этой проблемы — написание автоматизированных тестов перед внесением любых изменений. Тесты выступают в роли страховочной сети: они позволяют проверить, что после модификации система продолжает работать так же, как и раньше. Начните с высокоуровневых интеграционных тестов, покрывающих основные сценарии использования, затем постепенно добавляйте более детальные юнит-тесты для отдельных компонентов.
- Модульная декомпозиция и рефакторинг. Если legacy-код представляет собой монолитную структуру, слишком сложную для понимания и изменения в целом, имеет смысл разбить его на более мелкие, управляемые компоненты или модули. Это позволит работать с небольшими, понятными частями кода, упрощая процесс внесения изменений и обеспечивая более чистую архитектуру. Каждый выделенный модуль должен иметь чётко определённую ответственность и минимальное количество зависимостей от других частей системы.
- Инкрементальный подход к изменениям. Вместо попыток переписать весь legacy-код за один подход — что почти всегда заканчивается провалом — используйте стратегию постепенных улучшений. Вносите изменения небольшими порциями, тщательно тестируя каждую модификацию перед переходом к следующей. Поэтапное внедрение нового кода позволяет контролировать риски и проверять работоспособность системы на каждом этапе, минимизируя вероятность катастрофических сбоев.
- Документирование процесса и результатов. Важно фиксировать все вносимые изменения и причины, по которым они были сделаны. Это поможет будущим разработчикам (включая вас самих через несколько месяцев) понять, что было изменено и почему. Документация становится тем мостом знаний, отсутствие которого и превратило оригинальный код в legacy.
- Коллаборация и обмен знаниями. Не стесняйтесь обращаться за помощью к коллегам, особенно к тем, кто имел опыт работы с данным кодом ранее. Часто коллективное обсуждение проблемы позволяет найти решение быстрее и эффективнее, чем одиночные попытки разобраться в сложном коде.
Создание тестового покрытия перед изменениями
Написание тестов для legacy-кода — это, пожалуй, самая важная подготовительная работа перед любыми модификациями. Парадоксально, но именно код, который больше всего нуждается в тестовом покрытии, обычно не имеет ни одного теста. Давайте разберём систематический подход к созданию тестов для старого кода.
- Начните с интеграционных тестов. Первым шагом должно стать написание высокоуровневых тестов, проверяющих работу системы в целом. Эти тесты должны покрывать основные пользовательские сценарии и бизнес-процессы. Преимущество такого подхода в том, что для написания интеграционных тестов не требуется глубокого понимания внутренней структуры кода — достаточно знать, что система должна делать с точки зрения пользователя.
- Идентифицируйте критические участки кода. Не пытайтесь покрыть тестами весь legacy-код сразу — это нереалистично и неэффективно. Вместо этого сосредоточьтесь на тех частях системы, которые вы планируете модифицировать, а также на критичных для бизнеса компонентах. Определите, какие функции используются наиболее часто и какие сбои могут привести к наиболее серьёзным последствиям.
- Применяйте технику характеризационного тестирования. Этот подход заключается в написании тестов, которые фиксируют текущее поведение системы, даже если оно неидеально. Цель — не проверить правильность работы, а зафиксировать то, как система работает сейчас. После внесения изменений эти тесты покажут, не изменилось ли поведение непредвиденным образом.
- Постепенно увеличивайте покрытие. По мере работы с кодом добавляйте новые тесты, расширяя защитную сеть. Каждый раз, когда вы обнаруживаете баг или неочевидное поведение, пишите тест, который это фиксирует. Такой инкрементальный подход позволяет постепенно повышать качество кодовой базы без необходимости останавливать всю разработку.
Постепенный рефакторинг без риска сломать приложение
Рефакторинг legacy-кода — это искусство постепенных улучшений, требующее терпения и методичности. Попытка переписать всё сразу обречена на провал, поэтому мы рекомендуем использовать стратегию небольших, контролируемых изменений.
- Правило бойскаута: оставляйте код чище, чем нашли. При работе с любым участком legacy-кода старайтесь внести хотя бы небольшие улучшения: переименуйте непонятные переменные, добавьте комментарии, выделите магические числа в константы. Эти маленькие изменения накапливаются со временем, постепенно улучшая качество всей кодовой базы.
- Используйте паттерн «Strangler Fig». Эта стратегия, названная в честь растения-душителя, заключается в постепенной замене старого кода новым. Вы создаёте новую реализацию функциональности параллельно со старой, постепенно переключая на неё трафик. Когда новая версия полностью протестирована и стабильна, старый код можно безопасно удалить. Этот подход особенно эффективен для крупных компонентов, полная переработка которых заняла бы слишком много времени.
- Изолируйте изменения. Каждый рефакторинг должен быть атомарным и независимым. Вносите одно изменение за раз, тщательно тестируйте его, фиксируйте в системе контроля версий, и только потом переходите к следующему. Такой подход позволяет легко откатить изменения, если что-то пошло не так, и упрощает поиск причин возможных проблем.
Документирование старого и нового кода
Документация — это инвестиция в будущее проекта, которая предотвращает превращение сегодняшнего кода в завтрашний legacy. При работе со старым кодом документирование становится критически важным аспектом, который нельзя игнорировать.
- Фиксируйте архитектурные решения. Создавайте документы, описывающие общую архитектуру системы, взаимодействие между компонентами и ключевые принципы, на которых построена система. Это особенно важно для legacy-кода, где такая документация часто полностью отсутствует. Используйте диаграммы и схемы — визуальное представление часто понятнее текстовых описаний.
- Документируйте обнаруженные особенности. Когда в процессе работы вы обнаруживаете неочевидное поведение или скрытые зависимости, обязательно фиксируйте эту информацию в комментариях или отдельных документах. Эти знания могут сэкономить часы работы следующим разработчикам, столкнувшимся с тем же кодом.
- Описывайте причины изменений. В комментариях к коммитам и пул-реквестам подробно объясняйте не только что было изменено, но и почему. Контекст принятия решений бесценен для понимания эволюции системы. Будущие разработчики (включая вас самих) будут благодарны за эту информацию, когда будут пытаться понять логику изменений спустя месяцы или годы.
Нужно ли переписывать legacy-код полностью: критерии решения
Вопрос о целесообразности полной переработки legacy-кода не имеет универсального ответа и зависит от множества факторов, специфичных для каждого конкретного проекта. Решение о судьбе старого кода должно приниматься на основе тщательного анализа текущего состояния системы, бизнес-требований и доступных ресурсов. Давайте рассмотрим критерии, которые помогут принять взвешенное решение.
Когда legacy-код можно и нужно оставить без изменений.
Если старый код стабилен, надёжен и успешно выполняет свою функцию без проблем, то радикальное вмешательство может быть не просто необязательным, но и контрпродуктивным. Принцип «работает — не трогай» имеет под собой вполне рациональное основание: зачем инвестировать значительные ресурсы в переписывание кода, который справляется со своими задачами? В таких случаях поддержка и модификация существующего legacy-кода оказывается более разумной стратегией с экономической точки зрения.
Когда переписывание становится экономически оправданным
Ситуация меняется, когда затраты на поддержку legacy-кода начинают превышать потенциальную стоимость его полной переработки. Если каждое небольшое изменение требует недель разбирательств, если регулярно возникают ошибки из-за непонимания логики работы системы, если отсутствие документации приводит к постоянным задержкам в разработке — всё это сигналы о том, что переписывание может быть экономически целесообразным. Важно провести оценку: сколько времени команда тратит на поддержку старого кода сейчас, и сколько потребуется для создания новой, чистой реализации с современными практиками разработки.
Критерии, указывающие на необходимость переработки:
- Блокировка развития продукта — legacy-код ограничивает возможности добавления новой функциональности или интеграции с современными технологиями, что напрямую влияет на конкурентоспособность продукта.
- Критические уязвимости безопасности — старый код содержит известные security-проблемы, которые невозможно исправить без масштабной переработки, что представляет реальную угрозу для данных пользователей и бизнеса.
- Невозможность найти специалистов — технологии настолько устарели, что на рынке практически отсутствуют разработчики с необходимыми компетенциями, что делает поддержку системы крайне рискованной.
- Несоответствие современным требованиям — система не может масштабироваться или обеспечивать требуемую производительность, что критично для бизнес-задач.
Решение о полной переработке legacy-кода должно приниматься не эмоционально, а на основе объективного анализа рисков, затрат и долгосрочных перспектив развития продукта.
Заключение
Подводя итоги нашего разбора феномена legacy-кода, мы можем сформулировать несколько ключевых тезисов, которые помогут выработать правильное отношение к этому явлению и эффективные стратегии работы с ним.
- Легаси-код формируется постепенно в ходе развития продукта. Он отражает историю архитектурных и бизнес-решений.
- Старые системы могут быть надёжными. Их стабильность часто выше, чем у недавно написанных модулей.
- Сложности возникают при изменениях. Без тестов и документации любое вмешательство становится рискованным.
- Поддержка легаси требует подготовки. Анализ архитектуры помогает избежать ошибок.
- Создание тестов снижает страх изменений. Они фиксируют текущее поведение системы.
- Инкрементальный рефакторинг безопаснее переписывания. Постепенные улучшения позволяют контролировать результат.
- Документация превращает хаос в управляемую систему. Зафиксированные знания экономят время команды.
- Решение о переписывании должно быть обоснованным. Оно принимается с учётом стоимости, рисков и планов развития продукта.
Если вы только начинаете осваивать профессию программиста и хотите увереннее разбираться в старых и новых кодовых базах, рекомендуем обратить внимание на подборку курсов по веб-разработке. В программах есть теоретическая и практическая часть, что помогает закрепить знания на реальных задачах.
Рекомендуем посмотреть курсы по веб разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Веб-разработчик
|
Eduson Academy
114 отзывов
|
Цена
119 000 ₽
|
От
9 917 ₽/мес
|
Длительность
12 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Веб-разработчик с нуля до PRO
|
Skillbox
232 отзыва
|
Цена
294 783 ₽
589 565 ₽
Ещё -20% по промокоду
|
От
8 670 ₽/мес
Без переплат на 1 год.
|
Длительность
10 месяцев
|
Старт
23 марта
|
Подробнее |
|
Веб-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
163 300 ₽
302 470 ₽
с промокодом kursy-online
|
От
5 041 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 апреля
|
Подробнее |
|
Fullstack-разработчик на python (с нуля)
|
Eduson Academy
114 отзывов
|
Цена
158 760 ₽
|
От
13 230 ₽/мес
20 642 ₽/мес
|
Длительность
7 месяцев
|
Старт
24 марта
|
Подробнее |
|
Профессия Веб-разработчик
|
Skillbox
232 отзыва
|
Цена
152 538 ₽
305 075 ₽
Ещё -20% по промокоду
|
От
4 486 ₽/мес
Без переплат на 34 месяца с отсрочкой платежа 3 месяца.
|
Длительность
24 месяца
|
Старт
23 марта
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.