Лучшие библиотеки Python для Data Science
Python завоевал статус де-факто стандарта в области анализа данных не случайно. Мы наблюдаем уникальное сочетание простоты синтаксиса и мощной экосистемы готовых решений, которая делает этот язык незаменимым инструментом для специалистов по данным.
Представьте себе ситуацию: вам нужно проанализировать миллионы строк данных, построить несколько моделей машинного обучения и создать интерактивную визуализацию результатов. Писать весь код с нуля означало бы потратить месяцы на решение задач, которые другие разработчики уже решили и оптимизировали. Библиотеки Python — это своеобразные «строительные блоки», которые позволяют сосредоточиться на решении бизнес-задач, а не на реализации базовой функциональности.

Экосистема Python охватывает все ключевые этапы работы с данными: сбор и очистку информации, исследовательский анализ, статистическое моделирование, машинное обучение и визуализацию результатов. Каждая библиотека специализируется на определенной области, но при этом они прекрасно интегрируются друг с другом — принцип, который делает Python столь эффективным для комплексных проектов в Data Science.
- Базовые библиотеки для численных вычислений и работы с массивами
- Работа с табличными данными и подготовка датасетов
- Статистический анализ и тестирование гипотез
- Визуализация данных: от простого к интерактивному
- Библиотеки машинного обучения (ML)
- Глубокое обучение (Deep Learning)
- Обработка естественного языка (NLP)
- Компьютерное зрение (Computer Vision)
- Как выбрать нужную библиотеку: краткий путеводитель
- Часто задаваемые вопросы (FAQ)
- Заключение
- Рекомендуем посмотреть курсы по Data Science
Базовые библиотеки для численных вычислений и работы с массивами
NumPy — работа с массивами, векторизация, линейная алгебра
NumPy (Numerical Python) является фундаментом всей экосистемы научных вычислений в Python. Эта библиотека предоставляет высокопроизводительные многомерные массивы и инструменты для работы с ними, написанные на языке C для максимальной скорости выполнения.
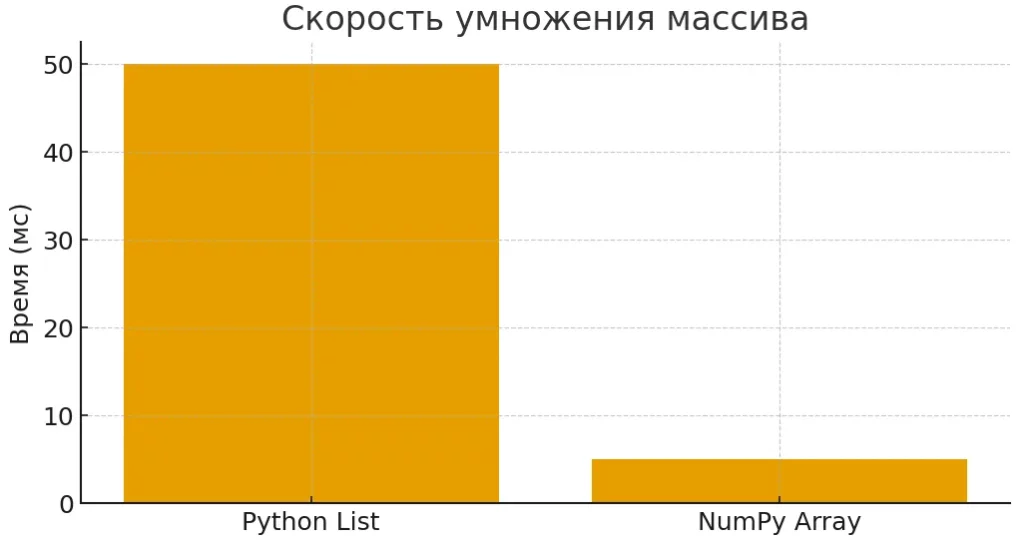
Диаграмма сравнивает скорость выполнения простой операции (умножения массива) в обычном Python и NumPy. График наглядно показывает преимущество векторизации и оптимизаций NumPy на низком уровне.
Ключевое преимущество NumPy заключается в векторизации операций — возможности выполнять математические операции над целыми массивами без явного написания циклов. Простой пример демонстрирует эту мощь:
import numpy as np # Обычный Python список python_list = [1, 2, 3, 4, 5] result = [x * 2 for x in python_list] # Требует цикла # NumPy массив numpy_array = np.array([1, 2, 3, 4, 5]) result = numpy_array * 2 # Векторизованная операция
SciPy — научные расчёты, оптимизация, интегралы, статистика
SciPy расширяет возможности NumPy, предоставляя специализированные модули для решения сложных научных задач. Мы получаем готовые решения для оптимизации функций, численного интегрирования, работы с вероятностными распределениями и преобразованиями Фурье.
Библиотека особенно ценна для исследователей и инженеров, которым необходимо решать дифференциальные уравнения, проводить статистические тесты или выполнять сложные математические вычисления. SciPy превращает Python в полноценную замену специализированных пакетов вроде MATLAB для многих задач научного моделирования.
Работа с табличными данными и подготовка датасетов
Pandas — фильтрация, агрегации, временные ряды
Pandas представляет собой мощную библиотеку для манипуляции и анализа структурированных данных, которая фактически заменяет Excel для большинства аналитических задач в Python. Основу библиотеки составляют два ключевых объекта: DataFrame (двумерные таблицы) и Series (одномерные массивы), которые обеспечивают интуитивную работу с данными любого размера.
Библиотека превосходно справляется с типичными задачами подготовки данных: очисткой от пропусков, дедупликацией, преобразованием типов данных и группировкой по различным критериям. Простой пример демонстрирует элегантность синтаксиса:
import pandas as pd
df = pd.read_csv('sales_data.csv')
df.head() # Просмотр первых строк
monthly_sales = df.groupby('month')['sales'].sum() # Группировка и агрегация
Особого внимания заслуживают возможности Pandas для работы с временными рядами — автоматическое парсинг дат, ресэмплинг данных и вычисление скользящих средних делают анализ временных данных максимально простым. Мы получаем инструмент, который позволяет обрабатывать миллионы строк данных с производительностью, недостижимой для традиционных электронных таблиц, сохраняя при этом читаемость и простоту кода.
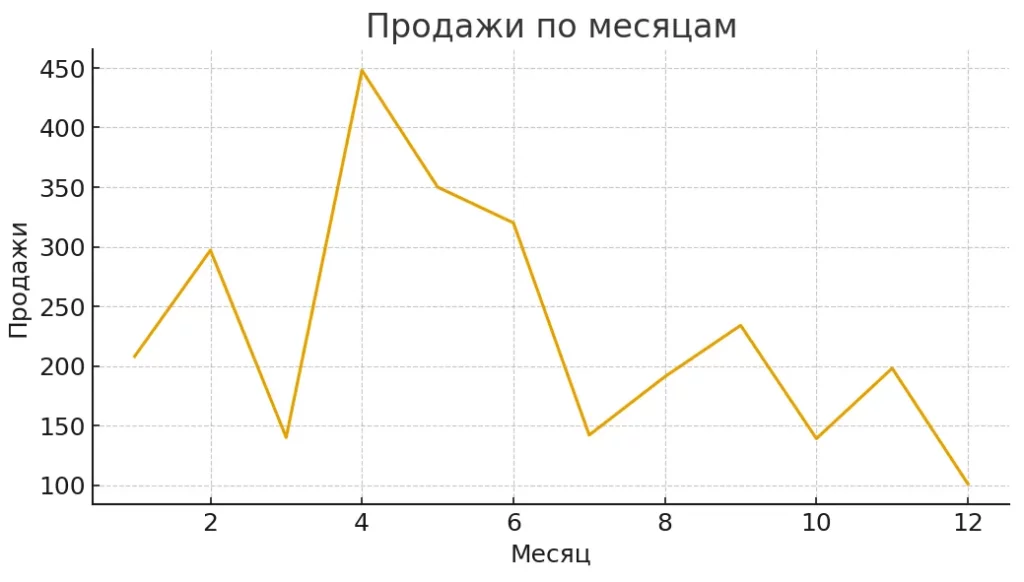
Линейный график демонстрирует пример агрегированных продаж по месяцам. Такая визуализация помогает читателю понять, как Pandas работает с группировкой, агрегацией и временными рядами.
Статистический анализ и тестирование гипотез
Statsmodels — регрессии, ANOVA, временные ряды
Statsmodels занимает особое место в экосистеме Python как специализированная библиотека для статистического моделирования и проверки гипотез. В отличие от scikit-learn, которая фокусируется на предсказательной точности моделей, statsmodels предоставляет детальную статистическую информацию о параметрах моделей, их значимости и доверительных интервалах.
Библиотека предлагает широкий спектр статистических моделей: от простой линейной регрессии до сложных моделей временных рядов и панельных данных. Особенно ценными являются возможности проведения ANOVA, построения обобщенных линейных моделей (GLM) и анализа остатков — инструменты, критически важные для академических исследований и бизнес-аналитики.
SciPy (повторно) — t‑тесты, распределения
Статистический модуль SciPy дополняет statsmodels, предоставляя обширную коллекцию статистических тестов и работу с вероятностными распределениями. Мы получаем готовые реализации t-тестов, критериев Манна-Уитни, тестов на нормальность и множества других процедур проверки гипотез.
Возможность работы с более чем 100 различными вероятностными распределениями делает SciPy незаменимым инструментом для моделирования случайных процессов и проведения статистических симуляций. Это превращает Python в полноценную альтернативу специализированным статистическим пакетам для многих исследовательских задач.
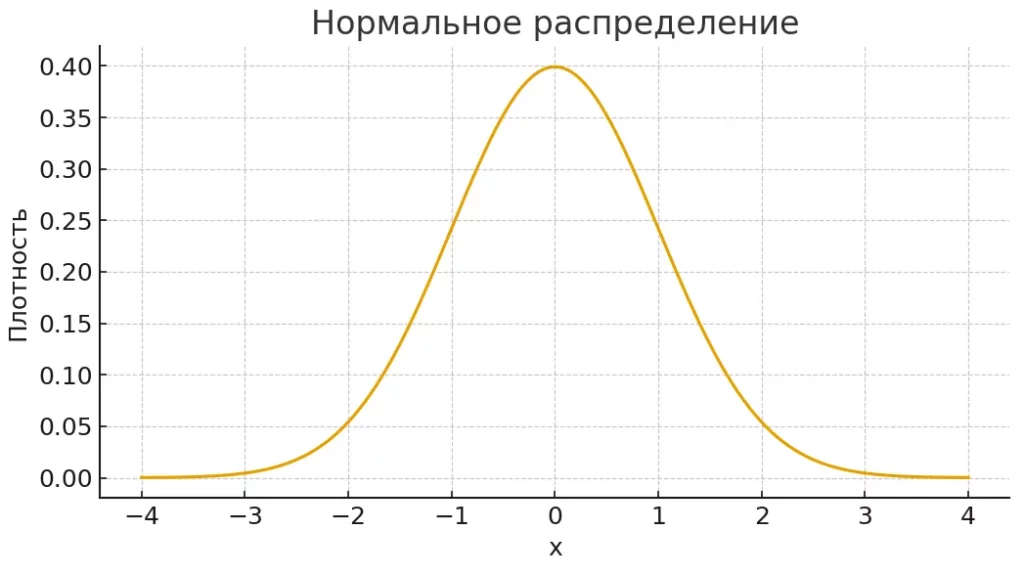
График показывает кривую нормального распределения — одну из ключевых моделей в статистике. В SciPy такие распределения используются для тестов, моделирования и анализа данных.
Визуализация данных: от простого к интерактивному
Matplotlib — базовая графика
Matplotlib служит фундаментом для визуализации данных в Python и остается незаменимым инструментом для создания публикационно-готовых графиков. Эта низкоуровневая библиотека предоставляет полный контроль над каждым элементом визуализации — от осей и подписей до цветовых схем и стилей линий.
Seaborn — статистическая визуализация
Seaborn построен поверх Matplotlib и значительно упрощает создание статистических графиков. Мы получаем элегантные решения для визуализации распределений, корреляций и взаимосвязей между переменными с минимальным количеством кода. Библиотека автоматически применяет современные цветовые палитры и стили, что делает графики привлекательными без дополнительной настройки.
Plotly и Bokeh — интерактивные графики
Plotly и Bokeh открывают новые возможности для создания интерактивных визуализаций, которые можно встраивать в веб-приложения. Plotly особенно силен в трехмерной визуализации и создании дашбордов, в то время как Bokeh специализируется на больших данных и обеспечивает высокую производительность рендеринга.
Dash — дашборды на основе Plotly
Dash позволяет создавать полноценные веб-приложения для анализа данных без глубоких знаний веб-разработки. Мы можем построить интерактивные дашборды с фильтрами, выпадающими меню и обновляемыми графиками, используя только Python.
Краткий справочник выбора:
- Matplotlib — статичные графики для публикаций.
- Seaborn — быстрая статистическая визуализация.
- Plotly — интерактивность и 3D-графики.
- Bokeh — большие данные и веб-интеграция.
- Dash — полноценные аналитические приложения.
Библиотеки машинного обучения (ML)
Scikit-learn — основной инструмент ML
Scikit-learn представляет собой золотой стандарт машинного обучения в Python, объединяя простоту использования с мощным функционалом. Библиотека предоставляет единообразный API для всех типов задач машинного обучения: классификации, регрессии, кластеризации и снижения размерности.
Мы получаем готовые реализации десятков алгоритмов — от классических линейных моделей до современных ансамблевых методов. Особенно ценными являются встроенные инструменты для предобработки данных, валидации моделей и оценки качества предсказаний. Scikit-learn идеально подходит для быстрого прототипирования и решения большинства практических задач ML.
PyCaret — AutoML
PyCaret радикально упрощает процесс создания моделей машинного обучения, автоматизируя рутинные операции. Мы можем сравнить десятки алгоритмов, настроить гиперпараметры и оценить качество моделей буквально в несколько строк кода. Это делает машинное обучение доступным для аналитиков без глубоких знаний ML.
LightGBM и XGBoost — градиентный бустинг
LightGBM и XGBoost доминируют в соревнованиях по машинному обучению благодаря выдающейся точности предсказаний на табличных данных. XGBoost обеспечивает максимальную точность и стабильность, в то время как LightGBM оптимизирован для скорости обучения и работы с большими объемами данных.
Выбор библиотеки: используйте LightGBM для больших данных и быстрого прототипирования, XGBoost — когда критически важна точность предсказаний.
Глубокое обучение (Deep Learning)
TensorFlow — мощная библиотека от Google
TensorFlow остается одной из наиболее зрелых и производственно-готовых библиотек для глубокого обучения. Разработанная Google, она обеспечивает масштабируемость от мобильных приложений до распределенных кластеров. Мы получаем мощную экосистему инструментов: TensorBoard для визуализации обучения, TensorFlow Serving для развертывания моделей и TensorFlow Lite для мобильных устройств.
PyTorch — гибкая и популярная среди исследователей
PyTorch завоевал популярность в академических кругах благодаря динамическим вычислительным графам и интуитивному Python-подобному синтаксису. Библиотека предоставляет большую гибкость при создании нестандартных архитектур нейронных сетей и упрощает процесс отладки моделей. Исследователи ценят PyTorch за возможность быстрого экспериментирования и прототипирования.
Keras — высокоуровневая обёртка
Keras (теперь интегрированный в TensorFlow как tf.keras) предоставляет простой и понятный API для создания нейронных сетей. Библиотека идеально подходит для начинающих в области глубокого обучения, позволяя создавать сложные модели с минимальным количеством кода.
Области применения Deep Learning:
- Компьютерное зрение (распознавание изображений, детекция объектов).
- Обработка естественного языка (переводы, чат-боты, генерация текста).
- Распознавание речи и синтез голоса.
- Рекомендательные системы.
- Генеративные модели (создание изображений, музыки, текста).
Выбор библиотеки: используйте PyTorch для исследований и экспериментов, TensorFlow — для production-решений, Keras — для быстрого старта в глубоком обучении.
Обработка естественного языка (NLP)
NLTK — базовые инструменты
NLTK (Natural Language Toolkit) служит классическим введением в обработку естественного языка и остается ценным образовательным ресурсом. Библиотека предоставляет обширную коллекцию корпусов текстов, словарей и базовых алгоритмов для токенизации, стемминга и синтаксического анализа. Мы получаем готовые решения для фундаментальных задач NLP, хотя производительность NLTK уступает более современным альтернативам.
spaCy — современный, быстрый парсинг
spaCy представляет собой промышленное решение для обработки текста, оптимизированное для производительности и точности. Библиотека обеспечивает быстрое выполнение сложных задач: распознавание именованных сущностей, определение частей речи, синтаксический разбор и выделение зависимостей между словами. Предобученные модели для десятков языков делают spaCy готовым к использованию решением для большинства практических задач.
Gensim — тематическое моделирование, Word2Vec
Gensim специализируется на неконтролируемом обучении для текстовых данных и тематическом моделировании. Библиотека предоставляет эффективные реализации Word2Vec, Doc2Vec, FastText и алгоритмов тематического моделирования (LDA, LSI). Мы можем обрабатывать огромные текстовые корпуса, которые не помещаются в оперативную память, благодаря потоковой обработке данных.
Сравнение NLTK vs spaCy:
| Критерий | NLTK | spaCy |
| Скорость | Медленная | Высокая |
| Простота использования | Требует настройки | Готов к работе |
| Академические задачи | Отлично | Хорошо |
| Production | Ограниченно | Оптимально |
Компьютерное зрение (Computer Vision)
OpenCV — работа с изображениями и видео
OpenCV (Open Source Computer Vision Library) представляет собой наиболее полную и зрелую библиотеку для задач компьютерного зрения. Разработанная изначально Intel, она предоставляет более 2500 оптимизированных алгоритмов для обработки изображений и видео — от базовых операций (изменение размера, фильтрация) до сложных задач распознавания объектов и трекинга.
Библиотека поддерживает работу с различными источниками данных: статические изображения, видеофайлы, веб-камеры и IP-камеры. Мы получаем готовые инструменты для детекции лиц, распознавания текста, анализа движения и многих других задач компьютерного зрения.
Простой пример чтения и отображения изображения демонстрирует базовый функционал:
import cv2
# Загрузка изображения
image = cv2.imread('photo.jpg')
# Отображение в окне
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
OpenCV интегрируется с современными фреймворками глубокого обучения (TensorFlow, PyTorch), что позволяет комбинировать классические методы компьютерного зрения с нейронными сетями для решения комплексных задач. Это делает библиотеку универсальным инструментом как для простых проектов обработки изображений, так и для создания сложных систем машинного зрения.
Как выбрать нужную библиотеку: краткий путеводитель
Выбор подходящей библиотеки зависит от специфики решаемой задачи и уровня экспертизы разработчика. Мы составили практическое руководство, которое поможет сориентироваться в многообразии инструментов Python для Data Science.
| Задача | Рекомендуемая библиотека | Альтернатива |
| Работа с числовыми массивами | NumPy | — |
| Обработка табличных данных | Pandas | Polars (для больших данных) |
| Статистический анализ | Statsmodels + SciPy | R (через rpy2) |
| Простая визуализация | Matplotlib + Seaborn | — |
| Интерактивные графики | Plotly | Bokeh |
| Машинное обучение (начальный уровень) | Scikit-learn | PyCaret (AutoML) |
| Градиентный бустинг | XGBoost | LightGBM |
| Глубокое обучение (исследования) | PyTorch | JAX |
| Глубокое обучение (production) | TensorFlow | PyTorch Lightning |
| Обработка текста | spaCy | NLTK (для обучения) |
| Тематическое моделирование | Gensim | — |
| Компьютерное зрение | OpenCV | Pillow (базовая обработка) |
| Веб-скрапинг | Scrapy | BeautifulSoup + requests |
Принцип выбора: начинайте с наиболее популярных и стабильных решений (NumPy, Pandas, Scikit-learn), затем переходите к специализированным инструментам по мере углубления в конкретную область. Помните: лучшая библиотека — та, которая решает вашу задачу с минимальными усилиями и максимальной надежностью.
Часто задаваемые вопросы (FAQ)
Какая библиотека самая важная для Data Science?
NumPy и Pandas образуют фундамент экосистемы Python для анализа данных. Без этих библиотек практически невозможно эффективно работать с числовыми данными и таблицами. Мы рекомендуем начать именно с них, поскольку большинство других библиотек строятся на их основе.
Что учить первым — машинное обучение или статистику?
Начните со статистики и исследовательского анализа данных. Освойте Pandas для работы с данными, Matplotlib/Seaborn для визуализации и основы статистики через SciPy/Statsmodels. Машинное обучение (Scikit-learn) имеет смысл изучать после понимания природы данных и статистических закономерностей.
Где искать документацию и примеры кода?
Официальная документация Python-библиотек остается лучшим источником информации. Дополнительно используйте Jupyter notebooks на GitHub, курсы на Coursera/edX, а также платформы вроде Kaggle Learn для практических примеров. Stack Overflow поможет решить конкретные технические проблемы.
Нужно ли изучать все перечисленные библиотеки?
Определенно нет. Сосредоточьтесь на задачах, которые вы решаете. Для базовой аналитики достаточно NumPy, Pandas и Matplotlib. Специализированные библиотеки (TensorFlow, OpenCV, spaCy) изучайте по мере необходимости для конкретных проектов.
Заключение
Мы рассмотрели обширную экосистему Python для Data Science, которая продолжает активно развиваться. В 2025 году ключевыми трендами остаются автоматизация машинного обучения (AutoML), интеграция больших языковых моделей в аналитические процессы и растущая популярность инструментов для работы с большими данными. Подведем итоги:
- Экосистема Python охватывает все этапы работы с данными. Это помогает строить полный цикл от сбора информации до применения моделей.
- NumPy, Pandas и SciPy формируют фундамент Data Science. Они обеспечивают скорость вычислений, удобную работу с таблицами и статистические инструменты.
- Библиотеки для визуализации упрощают анализ. Matplotlib, Seaborn и Plotly позволяют быстро находить закономерности и представлять результаты.
- Scikit-learn и фреймворки глубокого обучения помогают создавать модели. С их помощью можно решать как базовые, так и продвинутые задачи ML.
- Инструменты для NLP и компьютерного зрения расширяют возможности аналитика. Они упрощают работу с текстами, изображениями и сложными структурами данных.
- Выбор библиотек зависит от типа задачи. Практика и последовательное изучение позволяют быстрее погрузиться в реальные проекты.
Рекомендуем обратить внимание на подборку курсов по Data Science — особенно если вы только начинаете осваивать профессию аналитика данных. В программах есть теоретическая и практическая часть, которые помогут разобраться в инструментах и научиться применять их в реальных задачах. Подборка подойдёт тем, кто хочет уверенно работать с Python и современными библиотеками.
Рекомендуем посмотреть курсы по Data Science
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Специалист Data Scientist с нуля
|
Eduson Academy
110 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
|
Длительность
9 месяцев
|
Старт
25 февраля
|
Подробнее |
|
Курс Аналитик данных
|
Karpov.Courses
75 отзывов
|
Цена
96 700 ₽
135 800 ₽
|
От
5 658 ₽/мес
|
Длительность
5 месяцев
|
Старт
5 марта
|
Подробнее |
|
Профессия Data Scientist PRO
|
Skillbox
226 отзывов
|
Цена
110 000 ₽
200 000 ₽
Ещё -27% по промокоду
|
От
4 583 ₽/мес
Без переплат на 31 месяц с отсрочкой платежа 6 месяцев.
|
Длительность
18 месяцев
|
Старт
27 февраля
|
Подробнее |
|
Data Scientist
|
Нетология
46 отзывов
|
Цена
96 400 ₽
178 464 ₽
с промокодом kursy-online
|
От
2 974 ₽/мес
Без переплат на 2 года.
|
Длительность
16 месяцев
|
Старт
10 марта
|
Подробнее |
|
Data Scientist с нуля до Junior
|
Skillbox
226 отзывов
|
Цена
141 496 ₽
282 993 ₽
Ещё -20% по промокоду
|
От
6 432 ₽/мес
Без переплат на 22 месяца.
|
Длительность
6 месяцев
|
Старт
27 февраля
|
Подробнее |

Что такое Helm и Helm Charts: полное руководство
Что такое Helm Chart и зачем он нужен? Если вы работаете с Kubernetes, наверняка слышали об этом инструменте. В статье простыми словами объясняем, как он помогает автоматизировать развёртывание и управлять сложными проектами.

Циклы в программировании: различия, примеры и рекомендации по выбору подходящей конструкции
Циклы с предусловием и постусловием часто вызывают путаницу у новичков — когда код выполнится хотя бы один раз, а когда может не запуститься вовсе? Разберём различия, примеры и практические ситуации, где каждая конструкция действительно уместна.

Не просто iOS-приложение, а умное — с Core ML внутри
Разберем, зачем разработчику разбираться в Core ML, как он упрощает работу с ИИ и что делать, если модель внезапно «съедает» всю оперативку.

Топ-14 программ для управления проектами: как выбрать подходящую
Если вы ищете удобные программы и инструменты для управления проектами, но теряетесь в десятках вариантов, этот материал поможет разобраться. Какие сервисы реально упрощают работу, а какие только создают хаос? Разобрали всё простыми словами и собрали конкретные рекомендации.