Машинное обучение на Python — с чего начать новичку
Машинное обучение сегодня стало неотъемлемой частью технологического ландшафта — от рекомендательных систем Netflix до алгоритмов распознавания лиц в смартфонах. И если раньше эта область казалась доступной только избранным обладателям ученых степеней, то сегодня ситуация кардинально изменилась.

Python превратился в язык номер один для ML-разработки, и это не случайность. Его простота, мощная экосистема библиотек и низкий порог входа сделали машинное обучение доступным для широкого круга разработчиков. В этой статье мы разберем, как новичку войти в мир ML на Python: от базовых концепций до создания первых проектов.
Мы рассмотрим необходимые знания, ключевые библиотеки и практические подходы, которые помогут вам не просто изучить теорию, но и начать применять машинное обучение на практике. Готовы окунуться в один из самых перспективных разделов современного программирования?
- Почему Python — лучший язык для машинного обучения
- Что такое машинное обучение и как оно работает
- Какие знания понадобятся новичку
- Какие знания понадобятся новичку
- Основные библиотеки Python для машинного обучения
- Как устроен процесс создания модели
- Как и зачем делать свои проекты
- Где продолжать обучение
- Частые ошибки и советы новичкам
- Заключение
- Рекомендуем посмотреть курсы по машинному обучению
Почему Python — лучший язык для машинного обучения
Выбор языка программирования для изучения машинного обучения — это не просто техническое решение, а стратегический выбор, который определит ваш путь развития. Python завоевал позицию де-факто стандарта в ML-сообществе, и на то есть веские причины.
Скриншот подчеркивает реальное признание Python в области ML и его активное применение в индустрии.
Ключевые преимущества Python для машинного обучения:
- Минималистичный синтаксис — код читается практически как обычный английский текст, что критически важно при работе со сложными алгоритмами.
- Богатая экосистема библиотек — от NumPy для математических вычислений до TensorFlow для глубокого обучения.
- Интерактивная разработка — Jupyter Notebook позволяет экспериментировать с данными в режиме реального времени.
- Кроссплатформенность — один код работает на любой операционной системе.
- Активное сообщество — огромное количество туториалов, готовых решений и поддержки на форумах.
- Быстрое прототипирование — от идеи до работающей модели можно дойти за часы, а не дни.
Важно понимать: Python не самый быстрый язык с точки зрения производительности, но его библиотеки написаны на C/C++, что обеспечивает высокую скорость вычислений там, где это действительно необходимо. Для новичка это означает возможность сосредоточиться на понимании алгоритмов, а не на технических деталях реализации.
Что такое машинное обучение и как оно работает
Машинное обучение — это подраздел искусственного интеллекта, который позволяет компьютерам находить закономерности в данных и делать прогнозы без явного программирования каждого шага. Проще говоря, мы показываем алгоритму примеры, а он учится на них распознавать паттерны.
Представьте, что вы учите ребенка отличать кошек от собак. Вместо того чтобы объяснять словами («у кошек заостренные уши, а у собак висячие»), вы показываете тысячи фотографий с подписями. Машинное обучение работает похожим образом — алгоритм анализирует данные и самостоятельно выявляет признаки, по которым можно делать классификацию.
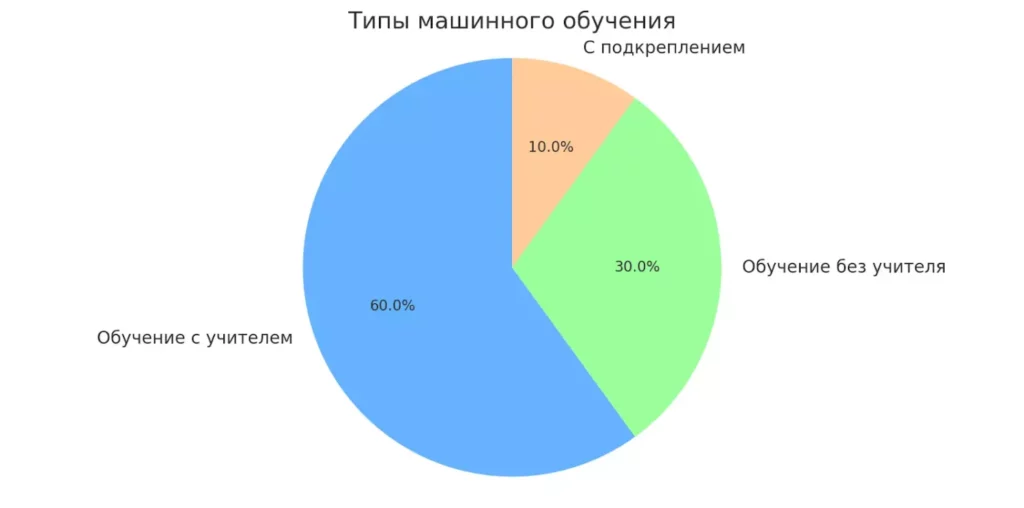
Диаграмма показывает три основных подхода в машинном обучении: обучение с учителем, без учителя и с подкреплением. Такое представление помогает лучше запомнить классификацию методов.
Основные типы машинного обучения:
| Тип обучения | Описание | Примеры задач |
|---|---|---|
| Supervised Learning (Обучение с учителем) | Алгоритм учится на данных с известными ответами | Распознавание спама, прогноз цен на недвижимость |
| Unsupervised Learning (Обучение без учителя) | Поиск скрытых закономерностей в данных без известных ответов | Сегментация клиентов, поиск аномалий |
| Reinforcement Learning (Обучение с подкреплением) | Алгоритм учится через взаимодействие со средой и получение наград/штрафов | Игровые AI, управление роботами |
Ключевые задачи ML включают классификацию (отнесение объекта к определенной категории), регрессию (предсказание числового значения) и кластеризацию (группировка похожих объектов). Понимание этих базовых концепций — фундамент для дальнейшего изучения более сложных алгоритмов и техник.
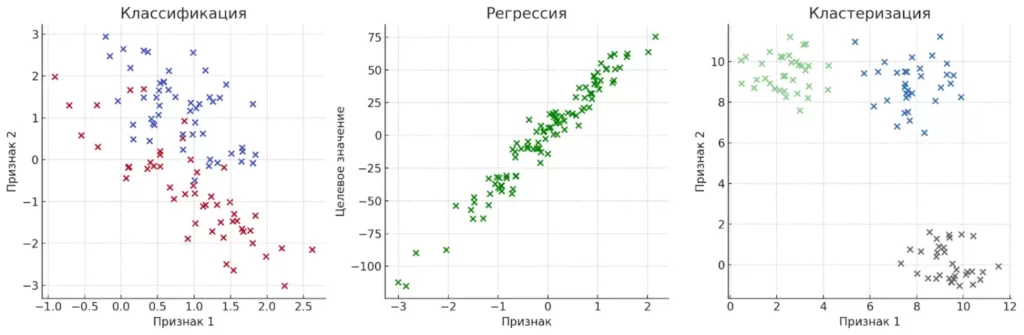
На этой диаграмме представлены три типа задач машинного обучения: классификация (разделение по классам), регрессия (предсказание числовых значений) и кластеризация (группировка по схожести). Визуальное сравнение помогает понять различия между ними на интуитивном уровне.
Какие знания понадобятся новичку
Математика для ML
Вопреки распространенному мифу, для начала работы с машинным обучением не нужна степень по математике. Однако базовое понимание ключевых концепций существенно облегчит ваш путь и поможет не просто копировать код, а понимать, что происходит «под капотом».
Основные математические области:
- Линейная алгебра — векторы, матрицы и операции с ними лежат в основе большинства ML-алгоритмов.
- Статистика и теория вероятностей — понимание распределений, корреляций и статистических тестов.
- Математический анализ — производные и градиенты необходимы для понимания оптимизации моделей.
- Градиентный спуск — ключевой алгоритм обучения нейронных сетей.
Рекомендуемые бесплатные ресурсы: Khan Academy для базовых концепций, MIT OpenCourseWare для более глубокого изучения, YouTube-канал 3Blue1Brown для визуального понимания линейной алгебры. Главное правило — изучайте математику параллельно с практикой, а не изолированно.
Основы Python и среды разработки
Для успешного старта в ML достаточно знать Python на базовом уровне. Не нужно быть экспертом — важнее понимать основные концепции и уметь читать чужой код.
Необходимый минимум Python:
- Базовые типы данных — числа, строки, списки, словари.
- Управляющие конструкции — условия (if/else), циклы (for/while).
- Функции — создание и использование, понимание области видимости.
- Основы ООП — классы и объекты (базовое понимание).
- Работа с библиотеками — импорт модулей, использование документации.
Jupyter Notebook — ваш главный инструмент. Эта интерактивная среда позволяет писать код, визуализировать данные и документировать процесс в одном месте. Изучите базовые команды, научитесь создавать ячейки с кодом и markdown-текстом. Рекомендуем начать с Anaconda — она включает Python, Jupyter и основные библиотеки в одном пакете.
Какие знания понадобятся новичку
Математика для ML
Вопреки распространенному мифу, для начала работы с машинным обучением не нужна степень по математике. Однако базовое понимание ключевых концепций существенно облегчит ваш путь и поможет не просто копировать код, а понимать, что происходит «под капотом».
Основные математические области:
- Линейная алгебра — векторы, матрицы и операции с ними лежат в основе большинства ML-алгоритмов.
- Статистика и теория вероятностей — понимание распределений, корреляций и статистических тестов.
- Математический анализ — производные и градиенты необходимы для понимания оптимизации моделей.
- Градиентный спуск — ключевой алгоритм обучения нейронных сетей.
Рекомендуемые бесплатные ресурсы: Khan Academy для базовых концепций, MIT OpenCourseWare для более глубокого изучения, YouTube-канал 3Blue1Brown для визуального понимания линейной алгебры. Главное правило — изучайте математику параллельно с практикой, а не изолированно.
Основы Python и среды разработки
Для успешного старта в ML достаточно знать Python на базовом уровне. Не нужно быть экспертом — важнее понимать основные концепции и уметь читать чужой код.
Необходимый минимум Python:
Базовые типы данных — числа, строки, списки, словари.
Управляющие конструкции — условия (if/else), циклы (for/while).
Функции — создание и использование, понимание области видимости.
Основы ООП — классы и объекты (базовое понимание).
Работа с библиотеками — импорт модулей, использование документации.
Jupyter Notebook — ваш главный инструмент. Эта интерактивная среда позволяет писать код, визуализировать данные и документировать процесс в одном месте. Изучите базовые команды, научитесь создавать ячейки с кодом и markdown-текстом. Рекомендуем начать с Anaconda — она включает Python, Jupyter и основные библиотеки в одном пакете.
Основные библиотеки Python для машинного обучения
Экосистема Python для машинного обучения напоминает хорошо организованную мастерскую — каждый инструмент решает свою специфическую задачу, но все они прекрасно работают вместе. Давайте разберем ключевые библиотеки, которые стали стандартом индустрии.
| Библиотека | Область применения | Типичные задачи |
|---|---|---|
| NumPy | Математические вычисления | Работа с массивами, линейная алгебра, базовые операции |
| Pandas | Анализ и обработка данных | Загрузка CSV, очистка данных, группировка, агрегация |
| Matplotlib | Базовая визуализация | Линейные графики, гистограммы, scatter plots |
| Seaborn | Статистическая визуализация | Тепловые карты, распределения, корреляционные матрицы |
| Scikit-learn | Классическое машинное обучение | Регрессия, классификация, кластеризация, метрики |
| TensorFlow | Глубокое обучение | Нейронные сети, компьютерное зрение, NLP |
| Keras | Высокоуровневый API для DL | Быстрое прототипирование нейронных сетей |
| PyTorch | Исследовательское глубокое обучение | Динамические графы вычислений, академические исследования |
NumPy и Pandas — ваш фундамент. NumPy превращает Python в мощный инструмент для численных вычислений, а Pandas делает работу с табличными данными интуитивно понятной. Scikit-learn — идеальная точка входа в машинное обучение: простой API, отличная документация и реализация всех классических алгоритмов.
Исторически TensorFlow считался более ориентированным на production, а PyTorch — на исследования. Однако сегодня обе библиотеки являются мощными универсальными инструментами, подходящими как для разработки, так и для внедрения моделей. Выбор между ними часто зависит от предпочтений команды или специфики проекта
Начинайте с освоения первых четырех библиотек — этого набора достаточно для решения подавляющего большинства стандартных задач в области анализа данных и классического машинного обучения.
Как устроен процесс создания модели
Шаг 1. Подготовка данных
Подготовка данных — это не самая гламурная, но критически важная часть машинного обучения. В индустрии принято считать, что на подготовку и очистку данных может уходить до 80% времени проекта и не зря — качество модели напрямую зависит от качества входных данных.
Основные этапы подготовки:
- Импорт и первичный анализ — загрузка данных через Pandas, изучение структуры с помощью .info(), .describe(), .head().
- Обработка пропущенных значений — заполнение средними значениями, удаление строк или использование более сложных методов импутации.
- Очистка данных — удаление дубликатов, исправление опечаток, приведение к единому формату.
- Нормализация и масштабирование — приведение числовых признаков к одному диапазону (например, от 0 до 1).
- Кодирование категориальных переменных — преобразование текстовых меток в числовые значения.
Визуализация играет ключевую роль на этом этапе. Гистограммы помогают понять распределение данных, корреляционные матрицы выявляют взаимосвязи между признаками, а box plots показывают выбросы. Помните: хорошо подготовленные данные могут сделать простую модель эффективнее сложной, обученной на «грязных» данных.
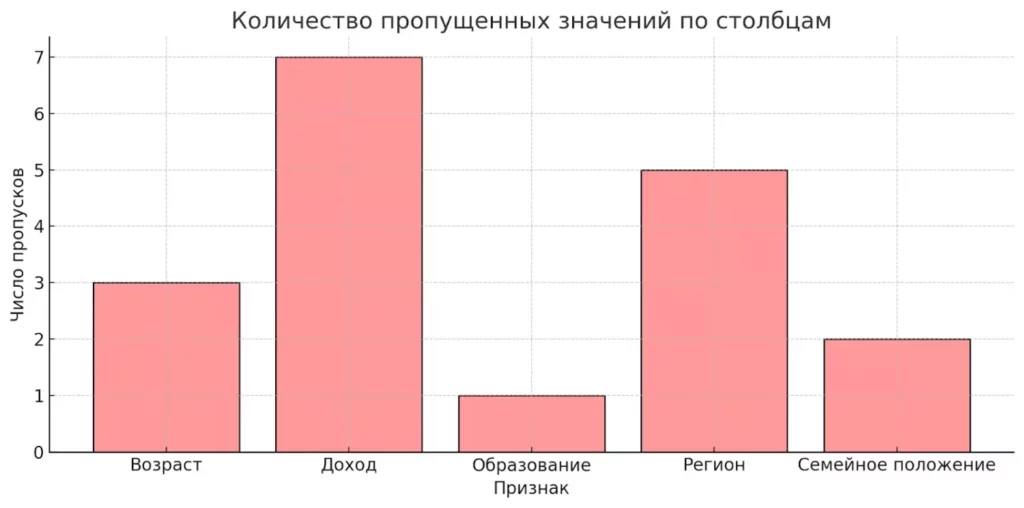
Гистограмма отображает количество пропущенных значений в разных столбцах. Такая визуализация помогает быстро выявить проблемные признаки, которые нуждаются в очистке или импутации.
Шаг 2. Обучение модели
После подготовки данных начинается самое интересное — создание и обучение модели. Этот процесс включает несколько критически важных решений, которые определят успех всего проекта.
Ключевые этапы:
- Разделение данных — классическое соотношение 80/20 для train/test, иногда добавляется validation set.
- Выбор алгоритма — начинайте с простых моделей (линейная регрессия, логистическая регрессия), затем переходите к более сложным.
- Обучение — используйте метод .fit() в Scikit-learn для настройки параметров модели на обучающих данных.
- Предсказание — применение обученной модели к тестовым данным через .predict().
Важный принцип: модель никогда не должна «видеть» тестовые данные во время обучения — это гарантирует объективную оценку ее способности к обобщению на новых данных.
Шаг 3. Оценка качества модели
Создать модель — это только половина дела. Понимание того, насколько хорошо она работает, требует правильного выбора метрик оценки в зависимости от типа задачи.
Основные метрики для регрессии:
- MAE (Mean Absolute Error) — средняя абсолютная ошибка, легко интерпретируется.
- MSE (Mean Squared Error) — средняя квадратичная ошибка, сильнее штрафует большие ошибки.
- R² (коэффициент детерминации) — показывает долю объясненной дисперсии.
Основные метрики для классификации:
- Accuracy — доля правильных предсказаний, простая но не всегда показательная.
- Precision — точность, важна когда ложные срабатывания критичны.
- Recall — полнота, важна когда нельзя пропустить положительные случаи.
- F1-score — гармоническое среднее precision и recall.
- ROC-AUC — площадь под ROC-кривой, показывает способность модели к разделению классов.
Выбор метрики зависит от бизнес-задачи: для медицинской диагностики критичен высокий recall, для спам-фильтра — precision.
Как и зачем делать свои проекты
Теория без практики в машинном обучении — это как изучение вождения по учебникам. Собственные проекты не только закрепляют знания, но и создают портфолио, которое станет вашей визитной карточкой при поиске работы или фриланс-заказов.
Проекты демонстрируют работодателям гораздо больше, чем сертификаты курсов: умение работать с реальными данными, способность довести задачу до конца, навыки презентации результатов. Более того, в процессе работы над проектами вы столкнетесь с проблемами, которые не покрывают учебные материалы — и это бесценный опыт.
Идеи проектов для начинающих:
- Анализ данных о продажах — исследование сезонности, трендов, влияния различных факторов.
- Прогнозирование цен на недвижимость — классическая задача регрессии с понятной бизнес-логикой.
- Классификация отзывов клиентов — анализ тональности текстов, введение в NLP.
- Рекомендательная система фильмов — основы коллаборативной фильтрации.
- Детекция мошенничества в транзакциях — работа с несбалансированными данными.
- Анализ временных рядов — прогнозирование курсов валют или цен на акции.
Полезные источники данных:
- Kaggle Datasets — огромная коллекция качественных датасетов.
- UCI ML Repository — классические датасеты для обучения.
- Google Dataset Search — поисковик по открытым данным.
- Our World in Data — социально-экономические данные с хорошей документацией.
Начинайте с простых проектов, постепенно усложняя задачи. Обязательно документируйте процесс работы и выкладывайте код на GitHub — это покажет вашу способность к систематической работе и коммуникации результатов.
Где продолжать обучение
Машинное обучение — это область, где обучение никогда не заканчивается. Новые алгоритмы, библиотеки и подходы появляются постоянно, поэтому важно выстроить систему непрерывного образования и найти качественные источники знаний.
| Платформа | Что дает | Уровень сложности |
|---|---|---|
| Kaggle Learn | Практические микрокурсы, интеграция с соревнованиями | Начинающий-средний |
| Fast.ai | Практический подход «сверху вниз», быстрый старт | Средний |
| Papers with Code | Свежие исследования с реализацией | Продвинутый |
| Kaggle Competitions | Решение реальных задач, обучение у лучших | Средний-продвинутый |
Практические платформы:
- Kaggle — не только соревнования, но и датасеты, ноутбуки других участников, обсуждения.
- Google Colab — бесплатные GPU для экспериментов с глубоким обучением.
- Paperspace Gradient — альтернатива Colab с более мощными ресурсами.
Рекомендуем придерживаться принципа 70/20/10: 70% времени тратьте на практику и проекты, 20% на изучение новых концепций, 10% на чтение исследований и отслеживание трендов. Помните: в ML важнее регулярная практика, чем попытки охватить все сразу.
Частые ошибки и советы новичкам
Путь в машинном обучении полон подводных камней, которые могут существенно замедлить прогресс или привести к неверным выводам. Мы собрали наиболее типичные ошибки новичков и способы их избежать.
Основные антипаттерны в ML:
- Переобучение (overfitting) — модель отлично работает на обучающих данных, но плохо обобщается на новые. Решение: кросс-валидация, регуляризация, больше данных.
- Утечка данных (data leakage) — использование информации из будущего для предсказания прошлого. Критическая ошибка при работе с временными рядами.
- Игнорирование разведочного анализа — попытка сразу применить сложные алгоритмы без понимания структуры данных.
- Слепое копирование кода — использование готовых решений без понимания принципов работы.
- Неправильное разделение данных — тестирование модели на данных, которые она «видела» во время обучения.
- Недооценка важности визуализации — попытка анализировать данные только числовыми методами.
Мини-чеклист перед запуском модели:
✓ Данные разделены корректно (train/validation/test).
✓ Нет утечек информации между наборами.
✓ Выбросы и аномалии проанализированы.
✓ Категориальные переменные закодированы правильно.
✓ Числовые признаки масштабированы при необходимости.
✓ Базовая модель (baseline) создана для сравнения.
✓ Метрики оценки соответствуют бизнес-задаче.
Помните главное правило: лучше простая модель, которую вы понимаете, чем сложная «черная коробка». Начинайте с линейных моделей, анализируйте их поведение, а затем постепенно переходите к более сложным алгоритмам.
Заключение
Машинное обучение — это не пункт назначения, а увлекательное путешествие, в котором каждый проект открывает новые горизонты и ставит новые вопросы. Мы рассмотрели фундаментальные основы, но это только начало вашего пути в мире искусственного интеллекта.
- Python — универсальный язык с богатой экосистемой для машинного обучения. Он сочетает простоту синтаксиса с мощью специализированных библиотек.
- Машинное обучение делится на три основных типа: с учителем, без учителя и с подкреплением. Каждый из них решает специфические задачи и требует разного подхода.
- Для старта достаточно базовых знаний Python и математики. Понимание линейной алгебры, вероятностей и основ анализа значительно облегчает обучение.
- Важнейшие библиотеки — NumPy, Pandas, Scikit-learn, TensorFlow, PyTorch. Они охватывают весь процесс: от подготовки данных до построения нейросетей.
- Процесс ML-проекта состоит из подготовки данных, обучения модели и оценки её качества. Каждый шаг критически важен для финального результата.
- Практика — залог успеха. Собственные проекты позволяют закрепить знания, собрать портфолио и уверенно двигаться в сторону профессионального роста.
Если вы только начинаете осваивать профессию в сфере машинного обучения, рекомендуем обратить внимание на подборку курсов по машинному обучению. В них вы найдете как теоретическую базу, так и практические задания — от работы с данными до создания моделей на Scikit-learn и TensorFlow.
Рекомендуем посмотреть курсы по машинному обучению
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Специалист Data Scientist с нуля
|
Eduson Academy
100 отзывов
|
Цена
Ещё -5% по промокоду
105 900 ₽
|
От
8 825 ₽/мес
|
Длительность
9 месяцев
|
Старт
28 января
|
Подробнее |
|
Машинное обучение для начинающих
|
Level UP
36 отзывов
|
Цена
52 990 ₽
|
От
17 663 ₽/мес
|
Длительность
3 месяца
|
Старт
12 марта
|
Подробнее |
|
Онлайн-курс по машинному обучению для начинающих
|
Karpov.Courses
73 отзыва
|
Цена
129 000 ₽
181 100 ₽
|
От
7 546 ₽/мес
|
Длительность
7 месяцев
|
Старт
8 февраля
|
Подробнее |
|
Машинное обучение
|
Нетология
46 отзывов
|
Цена
с промокодом kursy-online
53 900 ₽
94 541 ₽
|
От
2 363 ₽/мес
Без переплат на 18 месяцев.
|
Длительность
10 месяцев
|
Старт
28 января
|
Подробнее |
|
Пакет курсов Data Scientist: Python + SQL + Машинное обучение
|
Stepik
33 отзыва
|
Цена
3 900 ₽
|
От
975 ₽/мес
|
Длительность
3 месяца
|
Старт
в любое время
|
Подробнее |

Как проходить собеседование без стресса и нервов
Если вы ищете понятные советы о том, как пройти собеседование без стресса, этот материал поможет разобраться в тонкостях подготовки. Что спрашивать, как вести диалог и на что обращают внимание работодатели — разберем простым языком и с примерами, чтобы вы чувствовали себя увереннее.

Лендинг, который продает: что действительно работает?
Лендинг — это не просто красивая страница, а инструмент продаж. Как сделать его максимально эффективным, не допуская типичных ошибок? Рассказываем пошагово.

Прототип в Figma: от пустого холста до готового макета
Хотите создать интерактивный прототип в Figma, но не знаете, с чего начать? В этом руководстве разберем все этапы — от первых фреймов до финальной передачи проекта разработчикам.

Почему 2D-анимация до сих пор в тренде
2D-анимация – это не только яркие мультфильмы, но и мощный инструмент маркетинга, обучения и брендинга. Узнайте о её принципах, преимуществах и технологиях.