Нормализация данных: что это, зачем и как применить правильно
Нормализация данных — один из тех терминов, который звучит умно на совещаниях, но на практике часто вызывает больше вопросов, чем ответов. Особенно когда выясняется, что под одним названием скрывается целых несколько совершенно разных процессов — от организации баз данных до подготовки признаков для машинного обучения.

В этой статье мы разберем, что такое нормализация данных в различных контекстах, почему она важна для современной аналитики и разработки, какие методы существуют и когда их стоит применять. Поговорим о практических примерах, подводных камнях и том, почему иногда лучше не переусердствовать с «правильностью» данных. В конце концов, идеально нормализованная база данных — это красиво, но если запросы выполняются полчаса, красота становится сомнительной.
- Что такое нормализация данных?
- Почему нормализация важна
- Методы нормализации
- Сравнение методов и выбор подхода
- Практические примеры и кейсы
- Когда не нужно переусердствовать (ограничения и компромиссы)
- FAQ и частые ошибки
- Заключение
- Рекомендуем посмотреть курсы по SQL
Что такое нормализация данных?
Здесь начинается самое интересное — под термином «нормализация данных» скрывается минимум два совершенно разных процесса, которые объединяет разве что желание привести данные к какому-то «правильному» виду. И если вы думали, что это одно и то же — добро пожаловать в клуб тех, кто когда-то пытался применить Min-Max scaling к таблицам в PostgreSQL.
| Контекст применения | Основная цель | Когда используется |
| Базы данных | Устранение избыточности и применение нормальных форм (1NF–3NF и дальше) | При проектировании реляционных баз данных для предотвращения аномалий и дублирования |
| ML/Аналитика | Масштабирование числовых признаков (feature scaling) | Перед обучением моделей машинного обучения для приведения признаков к единому масштабу |
В контексте баз данных нормализация — это структурирование таблиц по определенным правилам (нормальным формам), чтобы избежать дублирования информации и обеспечить целостность данных. Простыми словами: вместо того чтобы в каждой строке заказа писать полное имя клиента, мы создаем отдельную таблицу клиентов и ссылаемся на неё по ID.
В машинном обучении нормализация — это приведение числовых признаков к сопоставимому масштабу. Потому что когда у вас зарплата в рублях (от 50 000 до 200 000) соседствует с возрастом (от 18 до 65), алгоритм может решить, что зарплата в тысячи раз важнее возраста. Что, кстати, иногда и правда так — но пусть модель до этого додумается сама, а не из-за разницы в масштабах.
Почему нормализация важна
Для баз данных: порядок вместо хаоса
Представьте магазин, где каждый день фиксируются покупки клиентов. Без нормализации в таблице заказов каждый раз записывается полное имя покупателя — «Александр Сушков», «Иван Иванов», «Егор Кузнецов». Если каждый из сотни постоянных клиентов делает в среднем 300 покупок в год, получается 450 000 символов только на имена и фамилии.
Нормализация решает эту проблему элегантно — создается отдельная таблица клиентов с уникальными ID, и в основной таблице заказов вместо имени хранится просто цифра. Экономия в 3-4 раза, и это только начало.
Основные преимущества для БД: • Экономия места — устранение дублирования данных значительно сжимает размер базы • Консистентность — изменение данных клиента происходит в одном месте, а не в тысяче записей • Предотвращение аномалий — невозможно случайно написать «Александр» в одном заказе и «Aleksander» в другом
Для ML/анализа: равные возможности для всех признаков
В машинном обучении нормализация решает проблему доминирования признаков с большим масштабом. Алгоритмы вроде k-NN, SVM или нейронных сетей крайне чувствительны к масштабу данных — они буквально «думают», что большие числа важнее маленьких.scatter-график зарплаты и возраста до нормализации
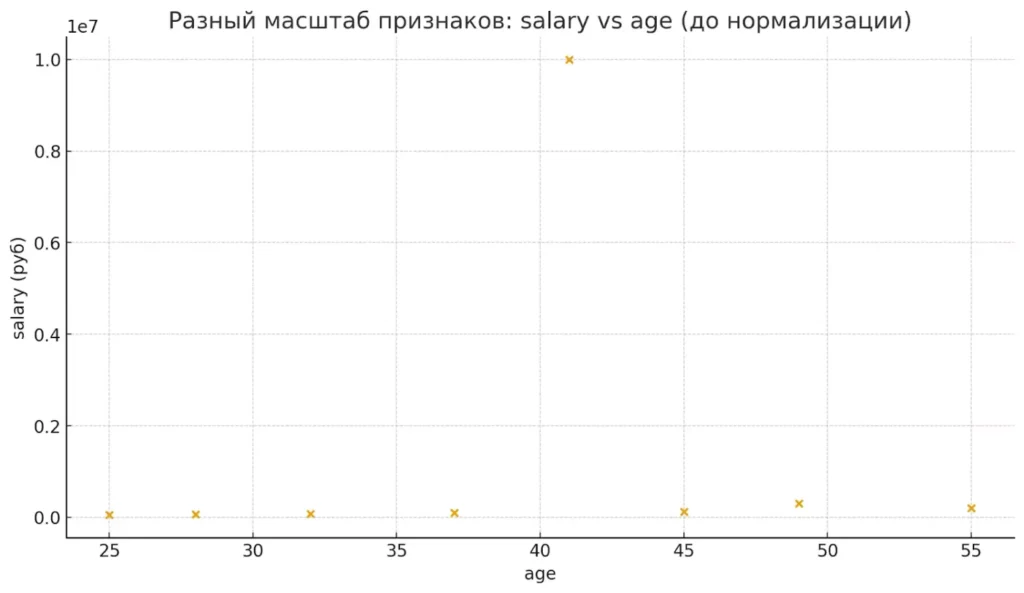
До нормализации «salary» масштабируется в сотни тысяч, полностью перекрывая влияние «age».
Ключевые эффекты:
- Ускорение обучения — градиентный спуск сходится быстрее на нормализованных данных.
- Улучшение точности — модель учитывает все признаки, а не только те, что случайно оказались в большем масштабе.
- Стабильность алгоритмов — особенно критично для методов, основанных на расстояниях между точками.
Методы нормализации
Масштабирование (feature scaling)
Min-Max нормализация Самый интуитивный метод — берем минимальное и максимальное значение признака и линейно сжимаем весь диапазон в отрезок [0, 1]. Формула простая как топор:
x' = (x - min(x)) / (max(x) - min(x))
Работает отлично, пока в данных не появляется выброс — один клиент с зарплатой в 10 миллионов сожмет всех остальных в крохотный диапазон возле нуля. Но зато красиво и понятно.
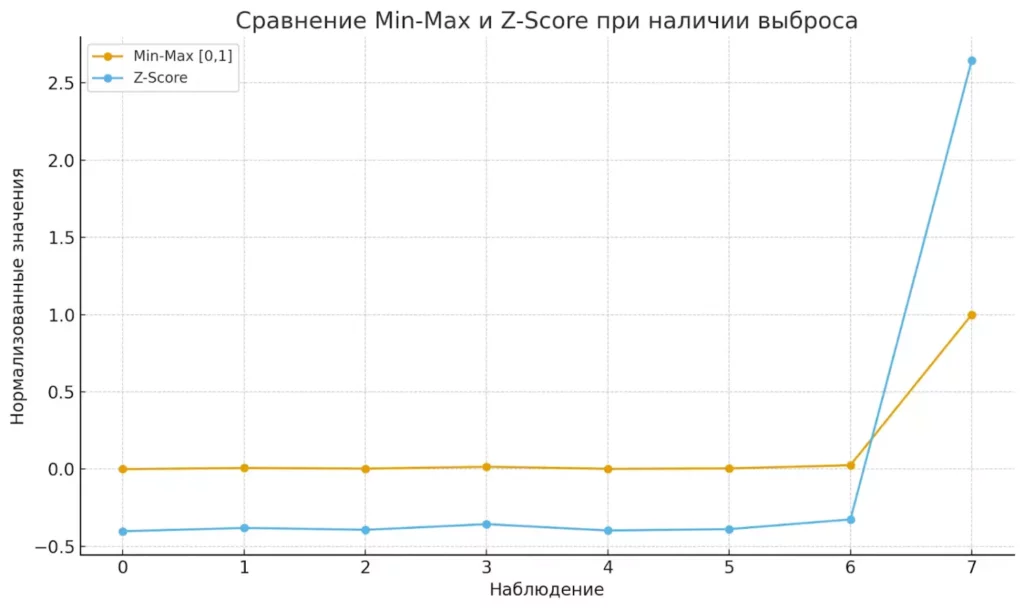
При наличии выбросов Min-Max сжимает все данные почти в ноль, тогда как Z-Score сохраняет относительные различия.
Z-Score (стандартизация). Более изощренный подход — приводим данные к стандартному нормальному распределению со средним 0 и стандартным отклонением 1:
x' = (x - μ) / σ
Где μ — среднее значение, σ — стандартное отклонение. Менее чувствителен к выбросам, чем Min-Max, и не ограничивает значения конкретным диапазоном.
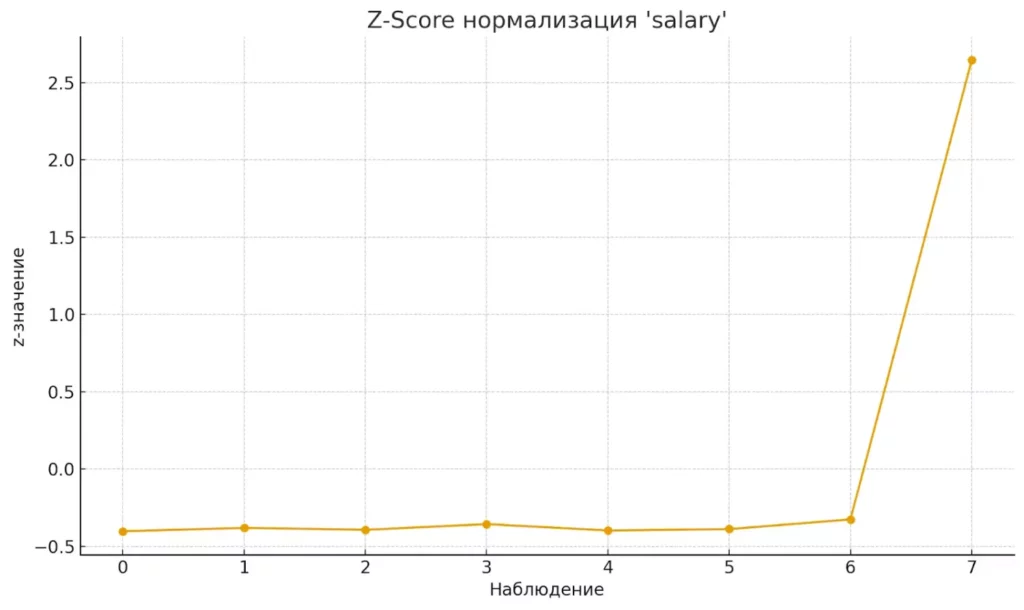
Z-Score нормализация центрирует данные вокруг нуля и снижает влияние выбросов.
Mean normalization. Гибрид предыдущих методов — центрируем относительно среднего, но масштабируем по размаху:
x' = (x - mean(x)) / (max(x) - min(x))
Decimal scaling. Экзотический метод — смещаем десятичную точку так, чтобы максимальное абсолютное значение стало меньше 1:
x' = x / 10^j
Где j — наименьшее целое число, обеспечивающее нужный результат.
Нормализация баз данных (нормальные формы)
Первая нормальная форма (1NF) Никаких составных данных в ячейках! Вместо «Александр Петрович Сушков» в одном поле — три отдельных: имя, отчество, фамилия. Иначе как вы будете искать всех Александров для именинной рассылки? Переберете еще и всех Александровичей с Александровнами.
Вторая нормальная форма (2NF) У каждой записи должен быть уникальный первичный ключ. Когда два Егора Кузнецова покупают одинаковый хлеб в один день — без номера чека (или другого уникального идентификатора) не разберешь, где чья покупка.
Третья нормальная форма (3NF) Убираем транзитивные зависимости — когда неключевые поля зависят друг от друга. Если в таблице сотрудников указан отдел и руководитель отдела, то связь между сотрудником и руководителем получается косвенной через отдел. Лучше вынести информацию о руководителях в отдельную таблицу.
Сравнение методов и выбор подхода
| Метод | Диапазон | Чувствительность к выбросам | Применимость | Пример использования |
| Min-Max | [0, 1] | Очень высокая | Когда нужен конкретный диапазон | Нормализация пикселей изображения |
| Z-Score | Неограничен | Умеренная | При нормальном распределении | Финансовые данные, метрики производительности |
| Mean normalization | Центрирован вокруг 0 | Высокая | Компромисс между Min-Max и Z-Score | Данные с известным средним значением |
| Нормальные формы БД | — | — | Реляционные базы данных | Проектирование таблиц CRM, ERP систем |
Практические советы по выбору:
→ Min-Max scaling выбирайте, когда точно знаете диапазон данных и уверены в отсутствии критичных выбросов. Идеально для изображений (пиксели всегда от 0 до 255) или процентов.
→ Z-Score normalization — ваш выбор для данных с приблизительно нормальным распределением. Особенно хорош для финансовых показателей, где выбросы — это жизнь, а не ошибка.
→ Нормальные формы в БД применяйте на этапе проектирования. Попытка нормализовать уже заполненную базу — это как переделывать фундамент в построенном доме. Технически возможно, но лучше до этого не доводить.
→ Текстовые данные требуют своих подходов — стемминг и лемматизация помогают привести слова к базовой форме, что особенно важно для поисковых систем и анализа тональности.
Практические примеры и кейсы
SQL и проектирование (нормальные формы)
Возьмем классический пример — таблицу покупок в интернет-магазине. До нормализации выглядит примерно так:
— Ненормализованная таблица
CREATE TABLE orders_bad ( order_id INT, customer_full_name VARCHAR(100), -- "Александр Петрович Сушков" customer_phone VARCHAR(20), customer_address VARCHAR(200), product_name VARCHAR(100), category VARCHAR(50), price DECIMAL(10,2) );
После применения нормализации получаем систему связанных таблиц — отдельно клиенты, отдельно товары, отдельно заказы. ER-диаграмма становится похожей на схему метро, но зато данные не дублируются и легко поддерживаются.
Python/ML пример
Классический кейс — подготовка данных для модели машинного обучения:
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import pandas as pd
# Исходные данные
data = pd.DataFrame({
'salary': [50000, 120000, 80000, 200000],
'age': [25, 45, 32, 55],
'experience': [2, 20, 8, 30]
})
# Z-Score нормализация
scaler = StandardScaler()
data_zscore = pd.DataFrame(
scaler.fit_transform(data),
columns=data.columns
)
# Min-Max нормализация
minmax_scaler = MinMaxScaler()
data_minmax = pd.DataFrame(
minmax_scaler.fit_transform(data),
columns=data.columns
)
После нормализации зарплата перестает «кричать громче всех» и модель начинает адекватно учитывать все признаки.
Текстовая нормализация
Приведение текста к единообразному виду — отдельная песня:
import nltk
from nltk.stem import PorterStemmer
from pymystem3 import Mystem
# Стемминг (обрубание окончаний)
stemmer = PorterStemmer()
words = ["running", "runs", "ran", "runner"]
stemmed = [stemmer.stem(word) for word in words] # ['run', 'run', 'ran', 'runner']
# Лемматизация (приведение к словарной форме)
mystem = Mystem()
lemmatized = mystem.lemmatize("хожу ходишь ходил") # ['ходить', 'ходить', 'ходить']
Разница кардинальная — стемминг просто отрубает окончания (иногда с мясом), а лемматизация находит правильную словарную форму.
Когда не нужно переусердствовать (ограничения и компромиссы)
Нормализация — это как диета: в меру полезно, но если довести до фанатизма, можно навредить. Идеально нормализованная база данных теоретически прекрасна, но на практике может превратиться в кошмар производительности.
Проблемы с перенормализацией БД:
Представьте базу данных, разнесенную по нормальным формам до седьмого колена — каждая сущность в своей таблице, связи через ключи, красота и элегантность. А теперь попробуйте выбрать простой отчет по продажам. Запрос превращается в JOIN-fest из 15 таблиц, выполняется полчаса, и администратор базы данных плачет кровавыми слезами.
Иногда разумное дублирование данных (денормализация) может значительно ускорить работу — особенно в аналитических системах, где данные читаются гораздо чаще, чем изменяются.
Подводные камни в ML:
В машинном обучении тоже не все так однозначно. Некоторые алгоритмы (например, деревья решений) вообще не чувствительны к масштабу признаков — вы можете нормализовать данные до посинения, но результат не изменится.
Более того, существуют ситуации, когда нормализация может навредить. Если в данных есть естественная иерархия важности признаков, принудительное приведение их к одному масштабу может смазать эту информацию.
Ключевые ограничения: • Понятность данных — чрезмерно нормализованные структуры становятся нечитаемыми для человека • Производительность — множественные JOIN’ы замедляют запросы • Сложность поддержки — чем больше таблиц и связей, тем сложнее вносить изменения
Золотое правило: нормализация должна решать реальные проблемы, а не создавать новые.
FAQ и частые ошибки
Можно ли нормализовать категориальные данные?
Прямое масштабирование категорий — плохая идея. Нельзя просто взять и присвоить цветам числа: красный=1, синий=2, зеленый=3. Алгоритм решит, что зеленый «больше» красного в три раза. Для категорий используйте one-hot encoding или другие методы кодирования.
Когда нормализация ухудшает модель?
Классический случай — деревья решений и случайный лес. Эти алгоритмы разбивают данные по пороговым значениям и абсолютно не заботятся о масштабе признаков. Нормализация им не помогает, но и не вредит — просто тратите время впустую.
Что делать с выбросами?
Зависит от контекста. В финансовых данных миллиардер среди обычных людей — это выброс, но важная информация. В датчике температуры значение 1000°C — скорее ошибка измерения. Min-Max scaling убьет первый случай, а robust scaling поможет во втором.
Нужно ли нормализовать целевую переменную?
В задачах регрессии — часто да, особенно для нейронных сетей. В классификации целевая переменная обычно уже категориальная, так что вопрос не актуален. Но не забудьте потом вернуть предсказания в исходный масштаб!
Заключение
Нормализация данных — это искусство баланса между теоретической правильностью и практической применимостью. В базах данных она помогает устранить избыточность и обеспечить целостность, в машинном обучении — дает всем признакам равные шансы на внимание алгоритма. Подведем итоги:
- Нормализация данных используется в разных контекстах. В базах данных она устраняет избыточность и повышает целостность, в машинном обучении — выравнивает масштаб признаков.
- Основные методы нормализации включают Min-Max, Z-Score и другие. Каждый из них подходит для определённых типов данных и задач.
- Чрезмерная нормализация может снижать производительность. Важно находить баланс между теорией и практикой.
- Для категориальных данных и текстов применяются отдельные подходы. Стемминг, лемматизация и кодирование категорий помогают улучшить результаты анализа.
- Выбор метода нормализации всегда зависит от задачи. Универсального решения нет — тестирование на реальных данных помогает подобрать оптимальный способ.
Рекомендуем обратить внимание на подборку курсов по SQL. Если вы только начинаете осваивать профессию аналитика, такие курсы помогут разобраться в теории и закрепить знания на практике. В них есть как фундаментальные основы, так и упражнения для самостоятельной работы.
Рекомендуем посмотреть курсы по SQL
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
SQL с нуля для анализа данных
|
Eduson Academy
109 отзывов
|
Цена
49 900 ₽
|
От
4 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
1 месяц
|
Старт
21 февраля
|
Подробнее |
|
Продвинутый SQL
|
Нетология
46 отзывов
|
Цена
41 600 ₽
77 018 ₽
с промокодом kursy-online
|
От
2 567 ₽/мес
Рассрочка на 1 год.
|
Длительность
1 месяц
|
Старт
26 февраля
2 раза в неделю по будням
|
Подробнее |
|
SQL-разработчик
|
Eduson Academy
109 отзывов
|
Цена
79 900 ₽
|
От
6 658 ₽/мес
0% на 12 месяцев
|
Длительность
6 месяцев
|
Старт
23 февраля
|
Подробнее |

Как улучшить производительность SQL-запросов: советы и ловушки
Оптимизация SQL-запросов — не волшебство, а навык. В этом гайде — простые шаги, которые помогут избавиться от медленных выборок и ресурсоёмких операций.

Что такое технология upscale
Апскейлинг это не просто увеличение картинки — это способ вдохнуть новую жизнь в старые фото, кино и даже игры. Хотите узнать, как работает технология и почему она так востребована?

LiDAR — что это такое, как работает и где применяется
Система лидар — это не просто лазерный дальномер, а технология, меняющая транспорт, науку и промышленность. Хотите понять, как она работает и где применяется? Рассказываем просто и по делу.

PHP удерживает 75% рынка веб-разработки в 2025 году
В мире веб-разработки, где технологии меняются с головокружительной скоростью, PHP продолжает удерживать свои позиции. Несмотря на периодические заявления о «смерти» этого языка, статистика говорит об обратном.