Объектное хранилище S3: что это, как работает и как использовать
Облачные технологии кардинально изменили подходы к хранению и управлению данными, а объектное хранилище S3 стало одним из краеугольных камней этой революции. Сегодня S3 используют миллионы разработчиков и компаний — от небольших стартапов до технологических гигантов вроде Netflix и Airbnb. Но что стоит за этой популярностью и почему именно S3 стал стандартом для облачного хранения данных?

В этой статье мы разберем принципы работы объектного хранилища S3, рассмотрим его ключевые преимущества и ограничения, а также предоставим практические рекомендации по внедрению этой технологии в бизнес-процессы. Независимо от того, планируете ли вы миграцию корпоративных данных в облако или ищете надежное решение для хранения медиаконтента, понимание возможностей S3 поможет принять обоснованные архитектурные решения и избежать типичных ошибок при работе с облачными хранилищами.
- Что такое объектное хранилище S3
- История и предпосылки появления S3
- Принцип работы объектного хранилища
- Основные компоненты и возможности S3
- Классы хранения данных в S3
- Преимущества использования S3-хранилищ
- Недостатки и ограничения
- Практические сценарии применения S3
- Как подключиться и начать использовать
- Безопасность и защита данных
- Подключение S3 к CDN
- Заключение
- Рекомендуем посмотреть курсы по системному администрированию
Что такое объектное хранилище S3
Объектное хранилище S3 (Simple Storage Service) представляет собой технологию облачного хранения данных, которая кардинально отличается от традиционных подходов к организации файлов. В отличие от привычной файловой системы с папками и подпапками, S3 работает с объектами — самостоятельными единицами данных, каждая из которых содержит сам файл, его метаданные и уникальный идентификатор.
Главная страница S3 Amazon.
Давайте разберемся, что делает объектное хранение особенным. В традиционной файловой системе мы привыкли к иерархической структуре: диск C, папка «Документы», подпапка «Отчеты за 2024 год» и так далее. Блочное хранение, используемое в базах данных, разбивает данные на блоки фиксированного размера. Объектное хранение идет по другому пути — каждый файл становится независимым объектом с собственными характеристиками и метаданными, что позволяет быстро находить нужную информацию по уникальному ключу без навигации по сложной структуре папок.
Важно понимать, что когда мы говорим «S3», то имеем в виду не только оригинальный сервис Amazon Web Services. S3 стал своеобразным стандартом протокола, подобно тому как «джип» стал синонимом внедорожника. Сегодня множество компаний предлагают S3-совместимые решения: от открытых платформ MinIO и Ceph до российских провайдеров — Timeweb Cloud, VK Cloud Solutions, Yandex Cloud, Selectel. Эта совместимость означает, что приложения и инструменты, созданные для работы с Amazon S3, могут без модификаций использоваться с любым другим S3-совместимым хранилищем.
Оригинальный сервис Amazon Web Services, пример консоли.
Такой подход открывает интересные возможности для бизнеса. Компания может начать с одного провайдера, а затем мигрировать к другому или даже использовать несколько хранилищ одновременно, не переписывая код приложений. Это особенно актуально в условиях изменяющегося технологического ландшафта, когда гибкость архитектуры становится конкурентным преимуществом.
История и предпосылки появления S3
В начале 2000-х годов компании сталкивались с растущими вызовами в области хранения данных. Традиционный подход с локальными серверами превращался в настоящую головную боль: каждый новый проект требовал закупки дорогостоящего оборудования, найма системных администраторов и постоянных инвестиций в масштабирование инфраструктуры. Представьте ситуацию стартапа, которому нужно было заложить в бюджет десятки тысяч долларов на серверы еще до того, как станет понятно, будет ли их продукт успешным.
Amazon Web Services столкнулась с этой проблемой в полной мере. Будучи одной из крупнейших интернет-компаний, Amazon нуждалась в надежной и масштабируемой инфраструктуре для собственных нужд. Вместо того чтобы держать это решение при себе, компания приняла революционное решение — превратить внутреннюю инфраструктуру в коммерческий продукт.
В марте 2006 года был запущен Amazon S3, ставший одним из первых массовых облачных сервисов. Запуск S3 можно считать моментом рождения современной облачной индустрии — впервые небольшие команды разработчиков получили доступ к корпоративной инфраструктуре по модели pay-as-you-go. Вместо капитальных затрат на оборудование стартапы могли платить центы за гигабайт и масштабироваться по мере роста.
Успех Amazon S3 не остался незамеченным. Вскоре появились конкуренты и открытые альтернативы, что привело к формированию целой экосистемы S3-совместимых решений. Сегодня мы видим результат этой эволюции: от корпоративных решений вроде MinIO до специализированных российских сервисов, каждый из которых предлагает свои преимущества, сохраняя совместимость с оригинальным протоколом S3.
Принцип работы объектного хранилища
Архитектура S3 строится на четырех основных компонентах: бакетах, объектах, ключах и метаданных. Бакет можно представить как корневой контейнер — аналог диска в традиционной файловой системе, но без внутренней иерархии. Внутри каждого бакета размещаются объекты — это могут быть документы, изображения, видеофайлы или любые другие данные.
Каждый объект идентифицируется уникальным ключом, который выполняет роль адреса в хранилище. Например, ключ reports/2024/january/sales.pdf может указывать на отчет о продажах, но важно понимать: слэши в ключе не создают реальных папок, это просто часть имени. Вместе с данными хранятся метаданные — информация о размере файла, типе содержимого, дате создания и пользовательские атрибуты, которые можно использовать для поиска и категоризации.
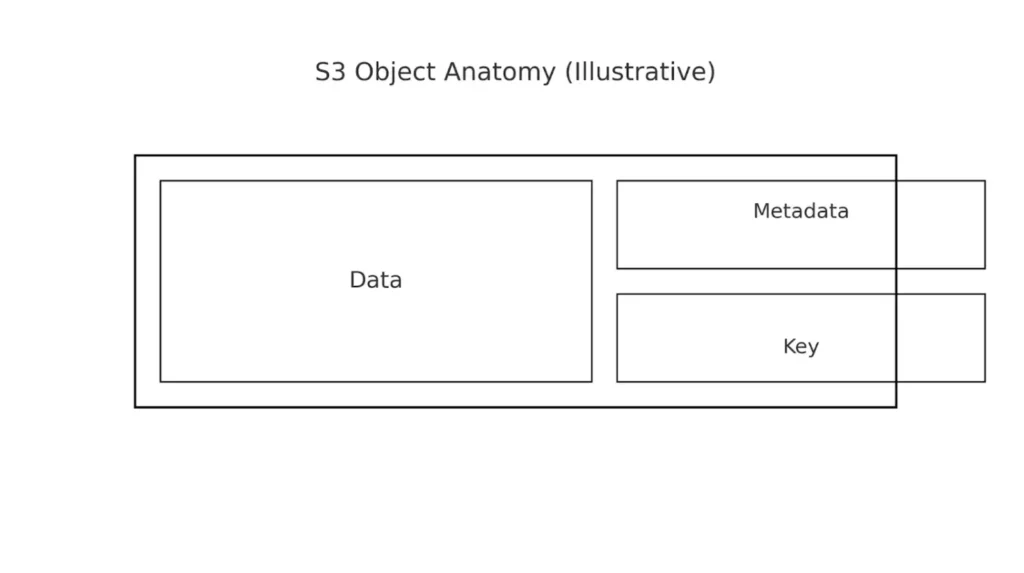
Схема показывает состав объекта: сами данные, метаданные и уникальный ключ для адресации. Визуально отделяет объектное хранение от традиционной файловой модели.
Взаимодействие с S3 происходит через REST API, что делает его универсальным для любых приложений, способных работать с HTTP-запросами. Операции загрузки, скачивания, удаления и управления объектами выполняются через стандартные HTTP-методы: GET для получения данных, PUT для загрузки, DELETE для удаления. Эта простота архитектуры объясняет широкую поддержку S3 в различных языках программирования и инструментах.
Для работы с крупными файлами S3 использует технологию multipart-загрузки. Большой файл разбивается на части (чанки), которые загружаются параллельно, что значительно ускоряет процесс и повышает надежность. Если загрузка одной части прервется, нужно повторить только ее, а не весь файл целиком. После успешной загрузки всех частей S3 автоматически собирает их в единый объект.
Подключение к S3 возможно несколькими способами. Веб-консоль подходит для разовых операций и управления настройками. Инструменты командной строки вроде AWS CLI или s3cmd позволяют автоматизировать рутинные задачи и интегрировать S3 в скрипты развертывания. Сторонние клиенты с графическим интерфейсом, такие как Cyberduck или WinSCP, предоставляют привычный пользователям способ работы с файлами через drag-and-drop интерфейс.
Основные компоненты и возможности S3
Бакеты и объекты
Бакеты в S3 представляют собой верхний уровень организации данных, и их именование следует строгим правилам. Имя бакета должно быть уникальным в пределах всего сервиса, содержать только строчные буквы, цифры и дефисы, а также соответствовать требованиям DNS-имен. Это означает, что если кто-то уже зарегистрировал бакет с именем my-company-backups, вы не сможете создать бакет с таким же именем, независимо от провайдера S3.
Объекты внутри бакета могут иметь размер от 0 байт до 5 терабайт, что покрывает практически любые потребности — от небольших конфигурационных файлов до полнометражных фильмов в высоком разрешении. Каждый объект сопровождается системными метаданными (размер, дата изменения, ETag) и может содержать пользовательские метаданные для расширенной категоризации.
Управление версиями объектов
Версионирование в S3 работает как система контроля версий для файлов. Когда эта функция активирована, каждое изменение объекта создает новую версию, сохраняя предыдущие. Это особенно ценно в ситуациях, когда важные данные могут быть случайно перезаписаны или повреждены. Мы можем восстановить любую предыдущую версию файла, что делает S3 надежным решением для критически важных данных.
Доступ и безопасность
Система безопасности S3 построена на нескольких уровнях. Access Control Lists (ACL) позволяют настроить базовые права доступа для отдельных объектов или бакетов. Identity and Access Management (IAM) предоставляет более гранулярный контроль, позволяя создавать политики с условиями доступа по IP-адресам, времени суток или другим параметрам. Эта гибкость позволяет реализовать сложные сценарии безопасности, от полностью публичных CDN до строго контролируемых корпоративных архивов.
Жизненный цикл объектов
Политики жизненного цикла автоматизируют управление данными на основе возраста или других критериев. Например, можно настроить автоматическое перемещение файлов логов старше 30 дней в более дешевое хранилище, а затем их полное удаление через год. Такая автоматизация помогает оптимизировать затраты без постоянного ручного вмешательства.
Интеграция с другими сервисами
S3 API стал де-факто стандартом для объектных хранилищ, что обеспечивает широкие возможности интеграции. CDN-сервисы могут использовать S3 как источник контента, аналитические платформы — как источник данных для обработки, а ML-модели — как репозиторий обучающих данных и результатов. Эта универсальность превращает S3 в центральный компонент современной облачной архитектуры.
Классы хранения данных в S3
S3 предлагает несколько классов хранения, каждый из которых оптимизирован под определенные сценарии использования и частоту доступа к данным. Выбор правильного класса хранения может значительно повлиять на стоимость и производительность решения.
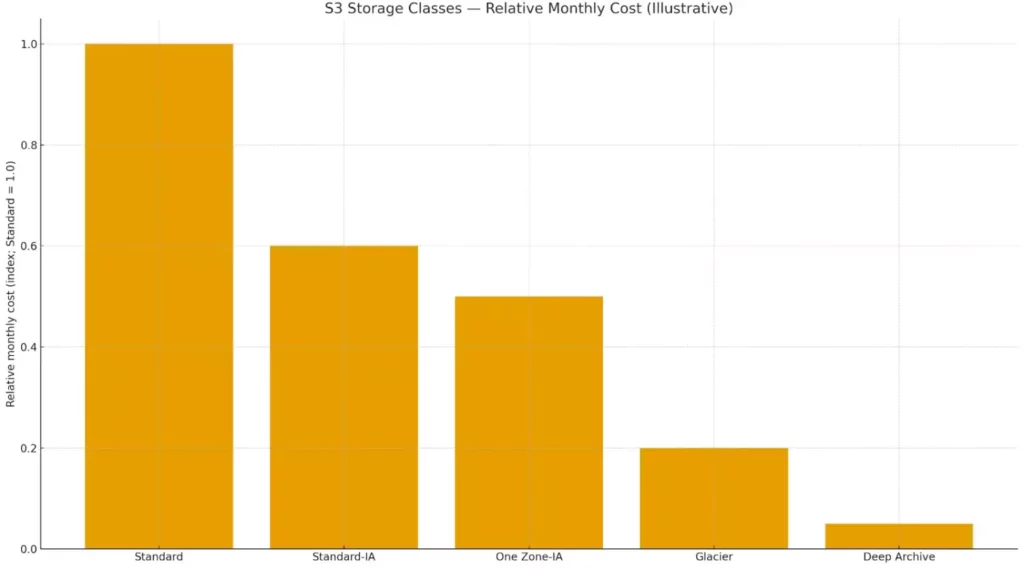
Иллюстративное сравнение относительной месячной стоимости хранения по классам S3 (Standard принят за 1.0). Помогает быстро понять, где классы IA и архивные уровни экономят бюджет ценой ограничений.
Standard (горячее хранение) представляет собой классический вариант для данных с частым доступом. Этот класс обеспечивает мгновенный доступ к файлам с минимальной задержкой и гарантирует доступность на уровне 99,99%. Стоимость хранения здесь максимальная, но отсутствуют дополнительные платежи за обращения к данным. Standard идеально подходит для активных веб-приложений, баз данных и любого контента, к которому пользователи обращаются регулярно.
Standard-IA (Infrequent Access) рассчитан на данные, к которым обращаются реже — несколько раз в месяц или квартал. Стоимость хранения здесь ниже, но появляются платежи за каждое обращение к файлу. Этот класс подходит для резервных копий, архивов документов или медиафайлов, которые могут понадобиться, но не используются ежедневно. Время доступа остается мгновенным.
One Zone-IA предлагает еще более низкую стоимость за счет хранения данных только в одной зоне доступности вместо нескольких. Это означает меньшую отказоустойчивость, но подходит для данных, которые можно восстановить из других источников — например, обработанных копий исходных файлов или кэшированного контента.
Glacier предназначен для долгосрочного архивного хранения с редким доступом. Стоимость хранения минимальная, но восстановление данных занимает от нескольких минут до нескольких часов в зависимости от выбранной скорости. Glacier идеален для соблюдения требований законодательства о хранении данных, архивов электронной почты или исторических записей.
Glacier Deep Archive представляет самый экономичный вариант для данных, к которым обращаются крайне редко — несколько раз в год или реже. Восстановление может занимать до 12 часов, зато стоимость хранения составляет лишь доли цента за гигабайт в месяц. Этот класс используется для долгосрочных архивов, которые требуется хранить годами для соблюдения нормативных требований
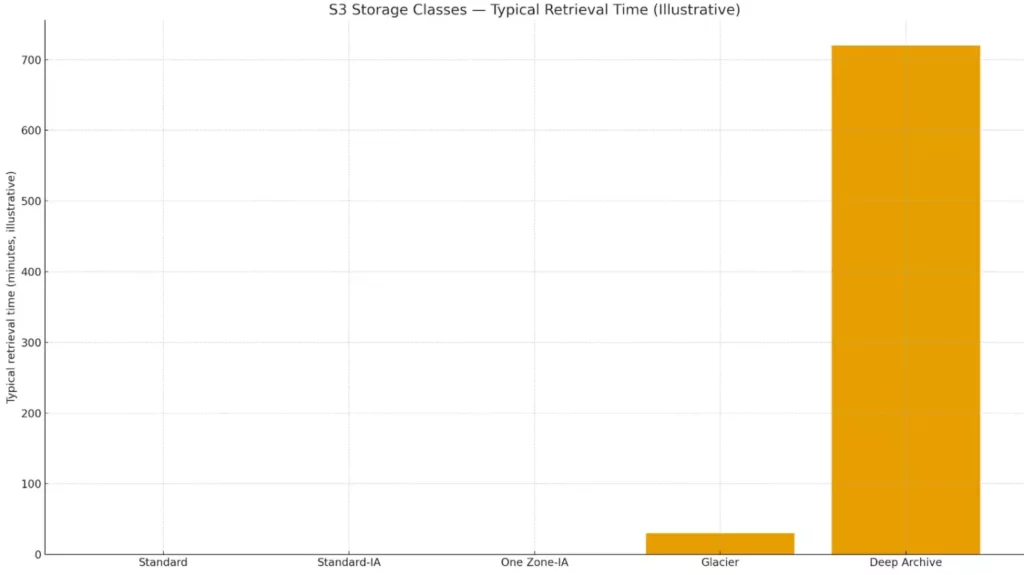
Иллюстративное сравнение ориентировочного времени доступа: «горячие» классы — мгновенно, архивные — от десятков минут до часов. Диаграмма подчеркивает компромисс между ценой и скоростью
Многие провайдеры позволяют настроить автоматические правила перехода между классами хранения, что помогает оптимизировать затраты без постоянного ручного управления.
Преимущества использования S3-хранилищ
Масштабируемость S3 практически не имеет ограничений — системы могут вырасти от нескольких гигабайт до петабайт данных без изменения архитектуры приложения. Это кардинально отличается от традиционных решений, где расширение хранилища требует планирования, закупки оборудования и миграции данных. В S3 масштабирование происходит прозрачно для пользователя, а инфраструктура автоматически адаптируется под растущие потребности.
Отказоустойчивость обеспечивается автоматической репликацией данных в несколько независимых узлов или даже географических зон. Amazon гарантирует долговечность данных на уровне 99,999999999% (11 девяток), что означает вероятность потери одного объекта раз в 10 миллионов лет при хранении 10 миллионов объектов. Эти цифры могут показаться маркетинговым преувеличением, но на практике случаи потери данных в S3 настолько редки, что каждый из них становится новостью в технологической прессе.
Универсальность S3 позволяет хранить любые типы данных без предварительной обработки. В отличие от реляционных баз данных, которые требуют определенной структуры, S3 одинаково хорошо справляется с текстовыми документами, видеофайлами, образами виртуальных машин, логами приложений или данными IoT-устройств. Эта гибкость особенно важна в эпоху больших данных, когда компании работают с неструктурированной информацией.
Простота интеграции через REST API делает S3 совместимым практически с любой технологической платформой. Разработчики могут использовать S3 из Python, Java, JavaScript, .NET и десятков других языков программирования. Более того, множество готовых инструментов и библиотек упрощают внедрение S3 в существующие проекты — от простых скриптов резервного копирования до сложных аналитических платформ.
Модель оплаты «по факту» исключает капитальные затраты на инфраструктуру. Стартапы могут начать с нескольких долларов в месяц, а крупные компании платят только за реально используемые ресурсы. Это особенно выгодно для проектов с непредсказуемой нагрузкой — например, новостных сайтов, которые могут получить вирусный трафик, или сезонного бизнеса.
Дополнительным преимуществом становится глобальная доступность — S3 работает из любой точки мира, что критически важно для распределенных команд и международных проектов. В сочетании с CDN это обеспечивает быструю доставку контента пользователям независимо от их географического расположения.
Недостатки и ограничения
Несмотря на многочисленные преимущества, S3 имеет особенности, которые могут создавать сложности в определенных сценариях использования. Понимание этих ограничений поможет принять взвешенное решение о применимости технологии для конкретных задач.
Отсутствие привычной файловой структуры становится препятствием для пользователей, ожидающих традиционную иерархию папок и подпапок. Хотя многие клиентские приложения эмулируют файловую структуру через интерфейс, на самом деле S3 работает с плоским пространством имен. Это может усложнить миграцию существующих приложений, особенно тех, которые активно используют файловые операции типа переименования директорий или атомарного перемещения файлов между папками.
Невозможность частичного редактирования объектов представляет серьезное ограничение для некоторых применений. В S3 нельзя изменить отдельные байты в середине файла — любая модификация требует перезаписи всего объекта. Это делает S3 неподходящим для баз данных, файлов логов, которые требуют дозаписи, или больших документов с частыми локальными изменениями. Разработчикам приходится проектировать архитектуру приложений с учетом этой особенности.
Задержки при восстановлении данных из архивных классов хранения могут стать критичными в чрезвычайных ситуациях. Восстановление из Glacier может занимать до нескольких часов, а из Deep Archive — до 12 часов. Представьте ситуацию, когда важные данные срочно нужны для расследования инцидента безопасности, а они находятся в архивном хранилище. Эту проблему можно решить правильным планированием жизненного цикла данных, но она требует дополнительного внимания.
Стоимость может стать неожиданно высокой при определенных паттернах использования. Частые обращения к данным в классах IA генерируют дополнительные платежи за запросы. Исходящий трафик тарифицируется отдельно, что может создать значительные расходы для приложений с интенсивной отдачей контента. Некоторые провайдеры также взимают плату за DELETE-операции, что может удивить при массовой очистке старых данных.
Еще одним потенциальным ограничением становится eventual consistency в некоторых операциях. Хотя современные реализации S3 обеспечивают strong consistency для большинства операций, в распределенных системах все еще возможны ситуации, когда изменения не сразу видны во всех регионах или при использовании определенных API-вызовов.
Практические сценарии применения S3
Резервное копирование и архивирование
S3 стал стандартом де-факто для корпоративных стратегий резервного копирования благодаря сочетанию надежности и экономичности. Компании могут настроить автоматическое создание снимков критических систем, которые затем сохраняются в разных классах хранения в зависимости от важности и частоты обращений. Финансовые организации используют S3 для хранения транзакционных данных в соответствии с требованиями регуляторов, автоматически перемещая старые записи в архивные классы для долгосрочного хранения при минимальных затратах.
Хранение медиафайлов и стриминг
Медиаиндустрия активно использует S3 для хранения и распространения контента. Netflix, например, хранит свою библиотеку фильмов и сериалов в S3, интегрируя хранилище с CDN для быстрой доставки контента пользователям по всему миру. Фотостоки и видеохостинги используют S3 для хранения исходных файлов в высоком разрешении, автоматически генерируя превью и сжатые версии для веб-отображения. Интеграция с транскодинговыми сервисами позволяет автоматически конвертировать загруженные видео в различные форматы и разрешения.
Big Data и аналитика
В эпоху больших данных S3 служит центральным репозиторием для аналитических платформ. Data lakes на основе S3 позволяют хранить петабайты неструктурированных данных — от логов веб-серверов до показаний IoT-датчиков. Аналитические инструменты вроде Apache Spark, Amazon Athena или Google BigQuery могут напрямую обрабатывать данные из S3, что исключает необходимость в дорогостоящем копировании и трансформации. Машинное обучение также активно использует S3 для хранения обучающих наборов данных и результатов экспериментов.
Статический хостинг сайтов
S3 предоставляет простое и экономичное решение для хостинга статических веб-сайтов. Современные фреймворки вроде React, Vue или Angular генерируют статические файлы, которые можно разместить в S3 и раздавать через CDN. Этот подход особенно популярен для документации проектов, лендингов и блогов, построенных на генераторах статических сайтов типа Jekyll или Hugo.
DevOps и CI/CD
В процессах непрерывной интеграции и развертывания S3 служит хранилищем для артефактов сборки, Docker-образов и пакетов приложений. CI/CD-пайплайны могут автоматически загружать результаты сборки в S3, откуда они затем развертываются на продакшн-серверах. Версионирование S3 обеспечивает возможность быстрого отката к предыдущим версиям приложений. Крупные технологические компании используют S3 для хранения логов сборок, результатов тестирования и метрик производительности, создавая централизованную систему мониторинга качества разработки.
Как подключиться и начать использовать
AWS CLI
AWS Command Line Interface остается одним из самых популярных инструментов для работы с S3 благодаря своей универсальности и мощности. Установка начинается с загрузки пакета с официального сайта Amazon или через менеджеры пакетов вроде pip для Python. После установки проверьте корректность командой aws —version — должна отобразиться версия установленного клиента.
Настройка подключения выполняется командой aws configure, которая запросит четыре ключевых параметра: Access Key ID и Secret Access Key (получаются при создании хранилища), регион (например, eu-west-1 или s-dt2 для российских провайдеров) и формат вывода данных. Для работы с не-Amazon провайдерами потребуется дополнительный параметр —endpoint-url, указывающий на адрес S3-сервиса.
Основные команды включают: aws s3 ls для просмотра списка бакетов, aws s3 cp file.txt s3://mybucket/ для загрузки файла, aws s3 sync ./folder s3://mybucket/folder/ для синхронизации директорий. AWS CLI поддерживает параллельную загрузку, автоматическое разбиение больших файлов на части и возобновление прерванных операций.
S3cmd
S3cmd представляет более простую альтернативу AWS CLI, особенно популярную среди системных администраторов. Установка обычно выполняется через пакетные менеджеры: apt install s3cmd в Ubuntu или yum install s3cmd в CentOS.
Конфигурация запускается командой s3cmd —configure, которая интерактивно запросит необходимые параметры: ключи доступа, endpoint (URL хранилища), регион и настройки шифрования. После завершения настройки s3cmd создает конфигурационный файл, который можно редактировать вручную для тонкой настройки.
Тестирование подключения выполняется командой s3cmd ls — при успешной настройке отобразится список доступных бакетов. Основные операции включают: s3cmd put file.txt s3://bucket/ для загрузки, s3cmd get s3://bucket/file.txt для скачивания, s3cmd sync folder/ s3://bucket/folder/ для синхронизации.
Графические интерфейсы
Для пользователей, предпочитающих визуальные инструменты, существует множество графических клиентов. Cyberduck предоставляет удобный интерфейс drag-and-drop для Mac и Windows, поддерживая S3-совместимые хранилища через настройку соединения с указанием custom endpoint. WinSCP, популярный среди Windows-пользователей, также поддерживает S3 через плагины.
CloudBerry Explorer (теперь MSP360) предлагает расширенные возможности управления, включая настройку политик жизненного цикла, управление метаданными и мониторинг использования. Эти инструменты особенно полезны для разовых операций, миграции данных или ситуаций, когда командная строка неудобна.
Безопасность и защита данных
Система безопасности S3 построена на принципе многоуровневой защиты, где каждый слой выполняет определенную функцию в общей архитектуре безопасности. Понимание этих механизмов критически важно для защиты данных в современной угрозной среде.
Управление доступом начинается с Access Control Lists (ACL) — базового механизма, позволяющего настроить права на уровне бакетов и отдельных объектов. ACL подходят для простых сценариев, где нужно быстро сделать объект публичным или ограничить доступ определенным пользователям. Однако для сложных корпоративных требований более подходящим решением становятся IAM-политики.
Identity and Access Management (IAM) предоставляет гранулярный контроль доступа через JSON-политики, которые могут учитывать множество условий: IP-адрес пользователя, время суток, используемое шифрование, размер файлов и другие параметры. Например, можно создать политику, разрешающую загрузку файлов только из корпоративной сети в рабочие часы, или ограничить доступ к архивным данным определенной группой сотрудников.
Шифрование данных реализуется на двух уровнях. Server-Side Encryption (SSE) автоматически шифрует данные при сохранении в хранилище, используя ключи, управляемые провайдером, или собственные ключи клиента. Client-Side Encryption (CSE) выполняет шифрование на стороне клиента до передачи данных, что обеспечивает дополнительный уровень защиты для особо чувствительной информации. При этом ключи шифрования остаются под полным контролем клиента.
Настройка приватности бакетов требует особого внимания, поскольку случайное открытие доступа может привести к утечке данных. Современные провайдеры S3 предлагают функции Block Public Access, которые предотвращают публичную доступность данных даже при ошибочной конфигурации. Эти настройки действуют как страховочная сеть против человеческих ошибок.
Соответствие нормативным требованиям становится все более важным аспектом. Ведущие S3-провайдеры сертифицированы по международным стандартам ISO 27001, SOC 2, PCI DSS и соответствуют требованиям GDPR и российского ФЗ-152. Это означает, что технические и организационные меры защиты данных проходят регулярный независимый аудит.
Журналирование и мониторинг обеспечивают видимость всех операций с данными. CloudTrail или аналогичные сервисы фиксируют каждое обращение к S3, включая успешные и неудачные попытки доступа, изменения конфигурации и административные действия. Эти логи можно анализировать для выявления аномальной активности, расследования инцидентов безопасности и демонстрации соответствия требованиям аудиторов.
Подключение S3 к CDN
Интеграция S3 с сетью доставки контента (CDN) решает фундаментальную проблему современного интернета — обеспечение быстрого доступа к данным независимо от географического расположения пользователей. Без CDN запрос файла из S3 проходит весь путь до дата-центра провайдера, что может занимать сотни миллисекунд для пользователей с других континентов.
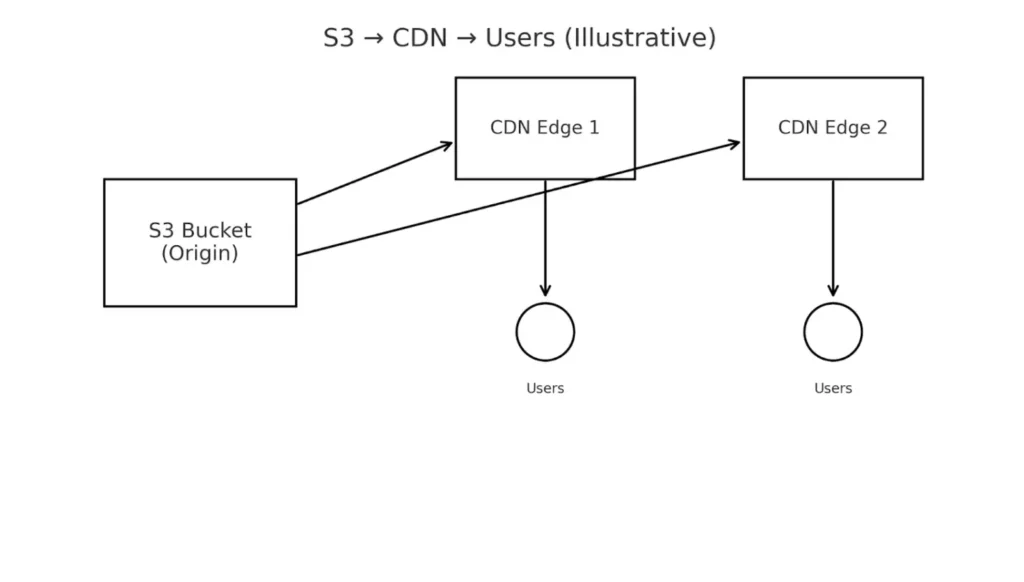
Поток раздачи контента: S3 выступает как origin, CDN кэширует файлы на edge-узлах и доставляет их ближе к пользователям. Это снижает задержки и разгружает исходное хранилище.
CDN размещает кэшированные копии контента на edge-серверах по всему миру, сокращая время отклика до десятков миллисекунд. Это критически важно для медиа-контента, где каждая секунда буферизации видео увеличивает отток аудитории. Дополнительным преимуществом становится снижение нагрузки на S3-хранилище, поскольку повторные запросы обслуживаются из кэша CDN.
Процесс подключения начинается с создания ресурса CDN в панели управления провайдера. В качестве источника (origin) указывается URL вашего S3-бакета — например, https://my-bucket.s3.amazonaws.com или https://my-bucket.s-dt2.cloud.edgecore.ru для российских провайдеров. Важно настроить правильные заголовки кэширования, чтобы CDN знал, как долго хранить различные типы файлов.
Настройка персонального домена требует создания CNAME-записи в DNS, которая будет указывать на домен CDN. Вместо сложного технического URL пользователи будут обращаться к понятному адресу вроде cdn.mywebsite.com. SSL-сертификат можно получить автоматически через Let’s Encrypt или загрузить собственный для корпоративных доменов.
После завершения настройки файлы становятся доступными по новому URL: https://cdn.mywebsite.com/photos/image.jpg вместо прямого обращения к S3. CDN автоматически загрузит файл из S3 при первом запросе и будет отдавать кэшированную копию последующим пользователям.
Для оптимизации работы можно настроить правила кэширования в зависимости от типа контента: статические ресурсы (CSS, JS, изображения) кэшируются на длительный срок, динамический контент — на минуты или часы. Функция предварительного разогрева (preloading) позволяет заранее разместить популярный контент во всех точках присутствия CDN.
Заключение
S3 превратился из эксперимента Amazon в фундаментальную технологию современной цифровой экономики. Мы видим, как объектное хранилище стало универсальным решением, которое одинаково хорошо подходит стартапам, разрабатывающим мобильные приложения, и крупным корпорациям, обрабатывающим петабайты данных. Простота архитектуры, надежность и экономичность S3 сделали его неотъемлемой частью облачной инфраструктуры. Подведем итоги:
- S3-хранилище — это объектная модель данных. Она отличается от файлового и блочного подхода и упрощает масштабирование.
- Основные компоненты S3 — бакеты, объекты, ключи и метаданные. Они обеспечивают гибкость и простоту работы с любыми файлами.
- Классы хранения S3 разделяются по стоимости и скорости доступа. Это позволяет выбирать оптимальный вариант для конкретных задач.
- Преимущества S3 заключаются в масштабируемости и надежности. Сервис обеспечивает глобальную доступность и высокую отказоустойчивость.
- Ограничения связаны с архитектурными особенностями. Отсутствие привычной файловой структуры и затраты на интенсивные запросы требуют учета при внедрении.
- Практическое применение S3 охватывает разные сферы. Оно используется для резервного копирования, медиаконтента, аналитики и DevOps.
Если вы только начинаете осваивать профессию инженера по облачным технологиям, рекомендуем обратить внимание на подборку курсов по системному администрированию. Там вы найдете и теоретические основы, и практические упражнения для закрепления навыков.
Рекомендуем посмотреть курсы по системному администрированию
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
114 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 мая
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
Инженер по автоматизации
|
Нетология
46 отзывов
|
Цена
102 700 ₽
190 197 ₽
с промокодом kursy-online
|
От
3 169 ₽/мес
Без переплат на 2 года.
|
Длительность
13 месяцев
|
Старт
5 апреля
|
Подробнее |
|
Старт в DevOps: системное администрирование для начинающих
|
Skillbox
232 отзыва
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца.
|
Длительность
4 месяца
|
Старт
23 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
102 отзыва
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Системный Администратор Linux. Базовый уровень
|
Otus
76 отзывов
|
Цена
93 600 ₽
104 000 ₽
|
От
9 360 ₽/мес
|
Длительность
5 месяцев
|
Старт
25 апреля
|
Подробнее |

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.

Яндекс Практикум vs Bang Bang Education: сравниваем методологию и упаковку кейсов для UX-исследователей
UX-исследования — с чего начать и какой курс выбрать? Разбираем методологию, формат обучения и портфолио, чтобы вы не ошиблись с выбором.