ORM — что это такое, как работает и зачем нужно разработчикам
ORM (Object-Relational Mapping, объектно-реляционное отображение) — это технология программирования, которая преобразует данные между несовместимыми системами типов в объектно-ориентированных языках. Проще говоря, ORM позволяет нам работать с базой данных через объекты нашего кода, а не через SQL-запросы — и в этом заключается его главная ценность для современной разработки.

В основе лежит концепция маппинга (отображения) — процесса связывания объектов кода с таблицами базы данных, а свойств этих объектов — с колонками таблиц. Благодаря этому механизму мы получаем возможность абстрагироваться от конкретной СУБД и упрощаем весь процесс разработки.
Давайте рассмотрим, как это работает на практике. Представим, что нам нужно создать нового пользователя в базе данных. Без ОРМ мы бы написали SQL-запрос вроде:
INSERT INTO users (name, email) VALUES ('John', 'john@example.com')
С использованием ORM этот процесс превращается в простое создание объекта:
user = User(name='John', email='john@example.com') session.add(user) session.commit()
Object-Relational Mapping формирует подобие «виртуальной объектной базы данных», которая существует лишь в коде приложения и затем синхронизируется с реальной базой данных. Эта концепция радикально меняет подход к работе с данными — вместо того чтобы думать о таблицах, строках и колонках, мы оперируем привычными классами, объектами и их свойствами.
- Зачем нужен ORM и какие проблемы он решает
- Как работает ORM: пошаговый механизм
- Основные понятия ORM, которые нужно знать
- Преимущества для разработки
- Недостатки и когда он может навредить проекту
- Практический пример использования ORM
- Популярные фреймворки: полный обзор по языкам программирования
- JavaScript: Sequelize, Knex, Objection.js
- Как выбрать подходящую ORM для проекта
- Заключение
- Рекомендуем посмотреть курсы по Frontend разработке
Зачем нужен ORM и какие проблемы он решает
Прямое взаимодействие с базами данных через SQL сопряжено с рядом проблем, которые становятся особенно заметными по мере роста проекта. Давайте разберемся, какие именно задачи решает ОРМ и почему эта технология стала практически стандартом в современной разработке.
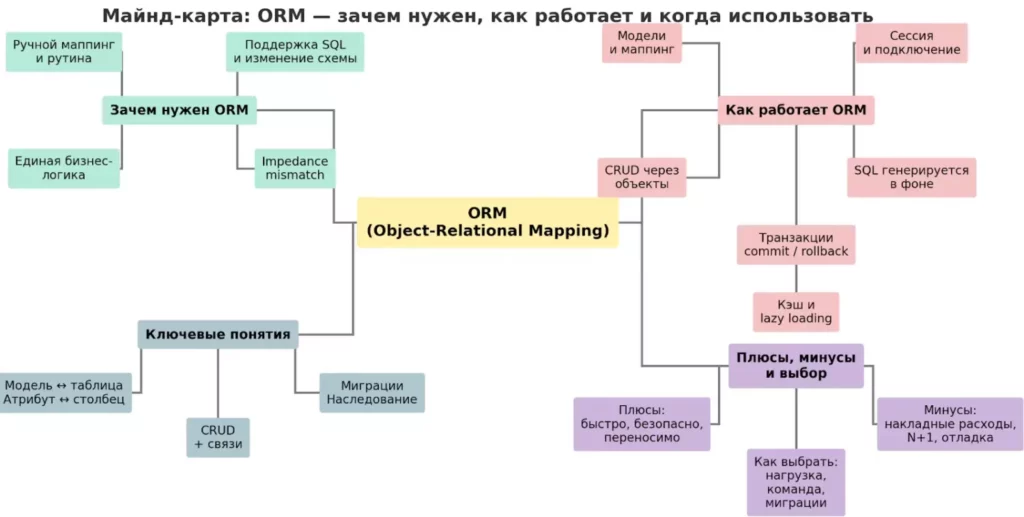
Майнд-карта структурирует ключевые идеи статьи: назначение ORM, принцип работы, основные понятия, преимущества и ограничения. Ломаные связи помогают визуально отделить блоки и быстро считать логику темы. Схема подходит как навигация по материалу и итоговая шпаргалка.
- Необходимость ручного маппинга данных. Без ORM разработчику приходится самостоятельно преобразовывать результаты SQL-запросов в объекты приложения и обратно. Представьте: мы получаем список пользователей из базы — нужно вручную создать объекты, заполнить их поля данными из каждой строки результата, обработать возможные NULL-значения. Это рутинная работа, которая дублируется от запроса к запросу и неизбежно ведет к ошибкам.
- Сложности с написанием и поддержкой SQL-запросов. SQL требует глубокого знания синтаксиса и особенностей конкретной СУБД. При работе с разными таблицами часто приходится писать похожие запросы, что приводит к избыточности кода. Более того, при изменении структуры базы данных нужно отслеживать и корректировать все связанные запросы — процесс трудоемкий и чреватый упущениями.
- Дублирование логики данных. Логика валидации, бизнес-правила и ограничения часто оказываются размазаны между кодом приложения и базой данных. Мы можем определить ограничения на уровне СУБД, но затем дублировать те же проверки в коде приложения для удобства работы и обработки ошибок. Object-Relational Mapping позволяет централизовать эту логику в моделях данных.
- Несовпадение реляционной и объектной моделей (impedance mismatch). Реляционные базы данных работают с таблицами и связями, в то время как объектно-ориентированные языки оперируют классами и наследованием. Это фундаментальное различие парадигм создает разрыв, который разработчику приходится преодолевать вручную. ОРМ выступает мостом между этими двумя мирами, беря на себя задачу согласования различий.
- Повышение скорости разработки. Итоговый эффект от использования ORM — это существенное ускорение разработки. Разработчик фокусируется на бизнес-логике приложения, а не на деталях взаимодействия с базой данных, что особенно ценно в динамичных проектах, где важна скорость выхода на рынок.
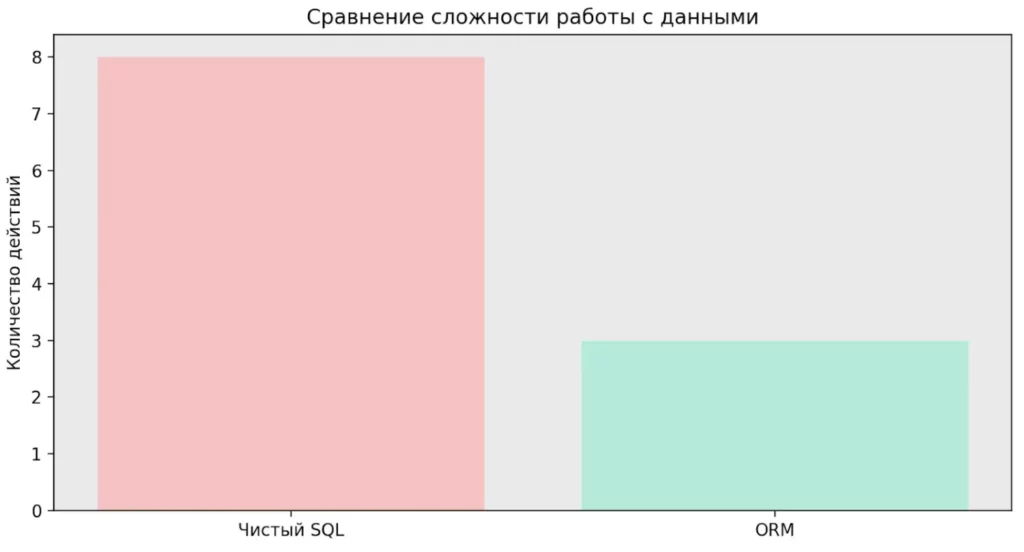
Диаграмма показывает, сколько действий требуется при работе с базой данных напрямую через SQL и с использованием ORM. Object-Relational Mapping сокращает количество рутинных шагов и делает код компактнее. Это напрямую ускоряет разработку и снижает вероятность ошибок.
Как работает ORM: пошаговый механизм
Чтобы понять, как ОРМ функционирует на практике, давайте разберем полный цикл работы с этой технологией — от определения моделей до выполнения запросов. Мы рассмотрим каждый этап, который проходит разработчик при интеграции ORM в свой проект.
- 1. Определение моделей данных (классов). Первый шаг — создание моделей, которые представляют сущности нашего приложения. Модель — это обычный класс на выбранном языке программирования, который описывает структуру данных. Например, для пользователя мы определяем класс User с полями name, email, age. Эти классы становятся своеобразным контрактом между приложением и базой данных, описывая, какие данные мы храним и как с ними работаем.
- 2. Настройка маппинга объектов на таблицы. На этом этапе мы указываем ОРМ, как именно наши классы соотносятся с таблицами базы данных. Это может быть реализовано через аннотации, декораторы или конфигурационные файлы — в зависимости от выбранного фреймворка. Мы определяем, какая таблица соответствует какому классу, какие поля являются первичными ключами, как связаны между собой разные сущности. Многие современные Object-Relational Mapping следуют принципу «convention over configuration» — соглашение важнее конфигурации, автоматически создавая маппинг по стандартным правилам.
- 3. Подключение к базе и инициализация ORM. После определения моделей мы настраиваем подключение к базе данных. Здесь указываются параметры подключения: тип СУБД, адрес сервера, учетные данные. ORM инициализирует пул соединений и создает контекст для работы с данными — обычно это называется сессией или контекстом базы данных. Именно через этот контекст мы будем выполнять все операции с данными.
- 4. Выполнение CRUD-операций через объекты. Теперь мы можем работать с данными через привычный объектно-ориентированный интерфейс. Создание записи — это просто создание экземпляра класса и его сохранение. Чтение данных превращается в вызов методов вроде query(User).filter_by(name=’John’). Обновление — это изменение свойств объекта с последующим коммитом. Удаление — вызов метода delete для объекта. Вся работа ведется на языке программирования, без единой строки SQL.
- 5. Генерация SQL-запросов в фоне. За кулисами ОРМ анализирует наши операции с объектами и преобразует их в оптимизированные SQL-запросы. Когда мы вызываем user.save(), ORM формирует INSERT или UPDATE запрос в зависимости от того, новый это объект или существующий. При выборке данных он строит SELECT с нужными условиями WHERE, JOIN для связанных таблиц и другими конструкциями. Эта генерация происходит автоматически, и в большинстве случаев разработчик даже не задумывается о том, какой именно SQL выполняется.
- 6. Управление транзакциями. Object-Relational Mapping берет на себя управление транзакциями базы данных. Мы можем группировать несколько операций в одну транзакцию, и если что-то пойдет не так — ORM автоматически откатит все изменения. Это критически важно для поддержания целостности данных. Типичный паттерн работы: начать транзакцию, выполнить серию операций, зафиксировать изменения через commit или откатить через rollback в случае ошибки.
- 7. Кэширование и ленивая загрузка (lazy loading). Для оптимизации производительности ORM использует кэширование — повторные обращения к одним и тем же объектам не приводят к новым запросам к базе. Ленивая загрузка означает, что связанные объекты подгружаются только при непосредственном обращении к ним, а не сразу при загрузке родительского объекта. Это позволяет избежать излишней нагрузки на базу данных, но требует понимания механизмов работы ОРМ, чтобы не столкнуться с проблемой N+1 запросов.
Основные понятия ORM, которые нужно знать
Работа с Object-Relational Mapping предполагает понимание ряда ключевых концепций, которые составляют фундамент этой технологии. Давайте разберем базовые термины, с которыми вы неизбежно столкнетесь при использовании любого ORM-фреймворка.
- Модель → Таблица. Модель — это класс в коде приложения, который представляет определенную сущность (пользователь, товар, заказ). Каждая модель соответствует одной таблице в базе данных. Например, класс User будет отображаться на таблицу users. Модель инкапсулирует не только структуру данных, но и бизнес-логику, связанную с этой сущностью.
- Атрибут → Столбец. Атрибуты класса (свойства объекта) соответствуют столбцам таблицы. Если в модели User есть атрибут email, в таблице users будет колонка email. Object-Relational Mapping автоматически преобразует типы данных между языком программирования и базой данных — например, Python-строку в VARCHAR или целое число в INTEGER.
- CRUD-операции. Аббревиатура от Create, Read, Update, Delete — четыре базовые операции с данными. ОРМ предоставляет удобные методы для каждой из них: создание нового объекта и его сохранение, получение объектов по условиям, изменение существующих записей, удаление данных. Эти операции составляют основу взаимодействия с базой.
- Связи между моделями. Object-Relational Mapping позволяет определять отношения между сущностями: «один-к-одному» (каждый пользователь имеет один профиль), «один-ко-многим» (один автор написал множество статей), «многие-ко-многим» (студенты записаны на множество курсов, и у каждого курса множество студентов). Эти связи автоматически преобразуются в foreign keys и промежуточные таблицы.
- Первичные ключи. Уникальный идентификатор записи в таблице, обычно называемый id. ORM автоматически управляет первичными ключами — генерирует их при создании записей, использует для поиска и обновления конкретных объектов. Мы можем как полагаться на автоматическую генерацию, так и определять собственные стратегии создания ключей.
- Миграции. Механизм управления изменениями структуры базы данных. Когда мы добавляем новое поле в модель или создаем новую таблицу, миграция генерирует SQL-скрипт для применения этих изменений. Миграции позволяют версионировать схему базы данных и синхронизировать ее между разными окружениями — разработка, тестирование, продакшн.
- Полиморфизм. Некоторые ОРМ поддерживают полиморфные отношения, позволяя хранить объекты разных типов в одной таблице или связывать одну запись с записями различных типов. Это расширенная функциональность, которая упрощает реализацию сложных доменных моделей.
- Наследование моделей. Object-Relational Mapping позволяет отображать иерархии наследования классов на структуры базы данных. Например, если у нас есть базовый класс Person и наследники Employee и Customer, ORM может реализовать это через single table inheritance, class table inheritance или другие стратегии — в зависимости от требований проекта.
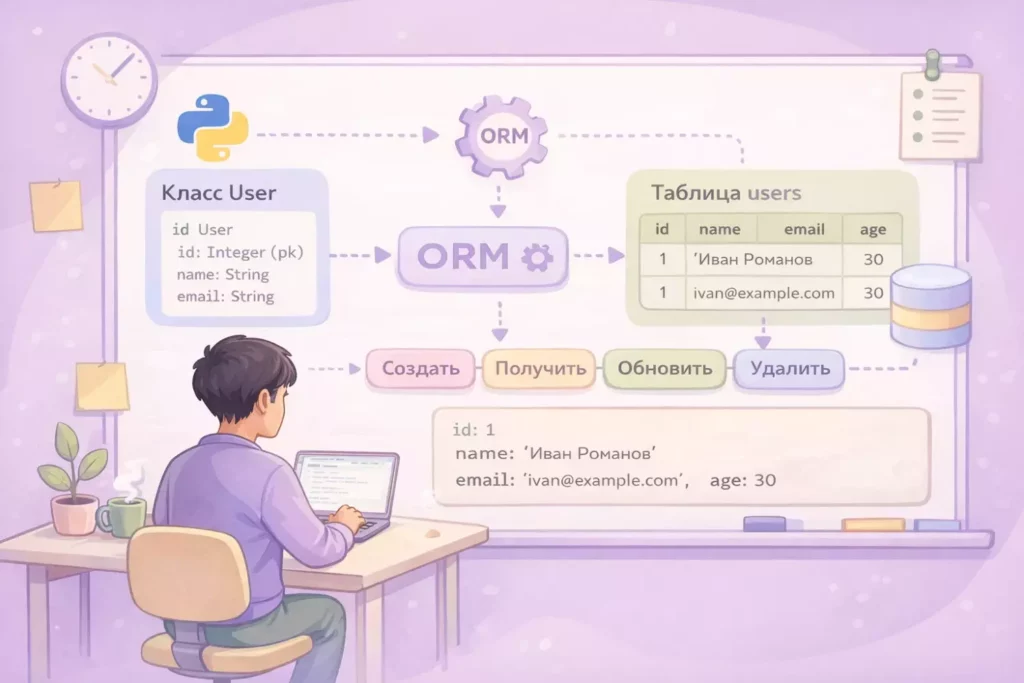
Иллюстрация показывает, как разработчик работает с базой данных через ORM, не обращаясь напрямую к SQL. Классы и объекты в коде автоматически преобразуются в таблицы и записи базы данных. Такой подход упрощает работу с CRUD-операциями и снижает количество рутинного кода.
Преимущества для разработки
Популярность ORM в современной разработке неслучайна — эта технология предоставляет разработчикам целый ряд существенных преимуществ, которые делают процесс создания приложений быстрее, безопаснее и удобнее.
- Скорость разработки. Ключевое преимущество Object-Relational Mapping — это радикальное ускорение процесса разработки. Нам не нужно писать десятки однотипных SQL-запросов для стандартных операций, не требуется вручную преобразовывать результаты запросов в объекты. Разработчик фокусируется на бизнес-логике приложения, а рутинную работу по взаимодействию с базой данных берет на себя ORM. Особенно это заметно при быстрой разработке MVP или прототипов.
- Меньше SQL вручную. ОРМ генерирует SQL автоматически для подавляющего большинства операций. Это не только экономит время, но и снижает порог входа для разработчиков, которые не являются экспертами в SQL. Конечно, знание основ SQL остается важным, но повседневная работа существенно упрощается.
- Переносимость между СУБД. Одно из наиболее ценных преимуществ — независимость от конкретной системы управления базами данных. Большинство ORM поддерживают различные СУБД: PostgreSQL, MySQL, SQLite, Oracle и другие. Мы можем разрабатывать на SQLite локально, тестировать на PostgreSQL и деплоить на MySQL — при этом код приложения остается практически неизменным. Переход с одной СУБД на другую требует лишь изменения строки подключения и, возможно, небольшой корректировки специфичных запросов.
- Защита от SQL-инъекций. ОРМ автоматически экранирует пользовательский ввод при формировании запросов, что существенно снижает риск SQL-инъекций — одной из наиболее распространенных уязвимостей веб-приложений. Параметры запросов обрабатываются безопасным образом, и разработчику не нужно помнить о правильном экранировании каждый раз.
- Удобная работа со связями. ORM делает работу с отношениями между таблицами интуитивно понятной. Вместо написания сложных JOIN-запросов мы просто обращаемся к свойствам объекта: user.orders автоматически подгружает все заказы пользователя. Навигация по связанным объектам становится естественной частью работы с данными.
- Единый стиль доступа к данным. Object-Relational Mapping стандартизирует способ работы с базой данных во всем приложении. Это облегчает поддержку кода и упрощает онбординг новых разработчиков в проект — им не нужно разбираться в различных подходах к работе с данными, используемых в разных частях системы.
- Поддержка миграций. Встроенные инструменты миграций позволяют версионировать изменения схемы базы данных, применять их последовательно на разных окружениях и при необходимости откатывать. Это критически важно для командной разработки и управления изменениями в продакшн-системах.
Недостатки и когда он может навредить проекту
При всех своих преимуществах он не является универсальным решением для всех сценариев. Давайте честно рассмотрим ситуации, когда использование ORM может создать больше проблем, чем решить.
- Накладные расходы производительности. Object-Relational Mapping добавляет дополнительный слой абстракции между приложением и базой данных, что неизбежно влияет на производительность. Генерация SQL-запросов, маппинг данных, управление сессиями — всё это требует вычислительных ресурсов. В высоконагруженных системах, где критична каждая миллисекунда, эти накладные расходы могут оказаться неприемлемыми. Ручной SQL часто работает быстрее оптимизированных ORM-запросов.
- Сложность отладки сгенерированных SQL.
- Когда ORM генерирует запрос автоматически, разработчик не всегда понимает, какой именно SQL выполняется. При возникновении проблем с производительностью или неожиданными результатами отладка становится сложнее — нужно сначала выяснить, какой запрос сформировал ОРМ, затем понять, почему он неэффективен, и найти способ оптимизировать его через API фреймворка.
- Проблема N+1 запросов. Одна из наиболее частых ловушек при работе с Object-Relational Mapping. Когда мы получаем список объектов и затем обращаемся к их связанным сущностям в цикле, ORM может выполнить отдельный запрос для каждого элемента. Результат — вместо одного эффективного JOIN-запроса база получает сотни отдельных запросов, что катастрофически влияет на производительность.
- Сложность оптимизации сложных запросов. Для нетривиальных аналитических запросов, использующих подзапросы, оконные функции или специфичные возможности конкретной СУБД, ОРМ может оказаться недостаточно гибким. Попытки выразить сложную логику через API фреймворка иногда приводят к громоздкому коду, который сложнее понять, чем эквивалентный SQL-запрос.
- Избыточность для малых проектов. Для небольших приложений с простой структурой данных внедрение полноценного Object-Relational Mapping может быть излишним. Настройка фреймворка, изучение его особенностей, написание моделей — всё это требует времени, которое в маленьком проекте можно было бы потратить на решение бизнес-задач. Иногда несколько прямых SQL-запросов — более прагматичное решение.
- Кривая обучения. Эффективное использование ORM требует понимания не только API конкретного фреймворка, но и принципов его работы. Разработчику нужно знать, когда применяется ленивая загрузка, как работает кэширование, как избежать типичных проблем производительности. Парадоксально, но для грамотной работы с ORM нужно хорошо понимать SQL и реляционные базы данных.
Практический пример использования ORM
Теория становится понятнее на конкретных примерах. Давайте рассмотрим, как выглядит работа с ОРМ на практике, используя Python и SQLAlchemy — одну из наиболее популярных и зрелых ORM-библиотек.
Пример на Python + SQLAlchemy (базовый CRUD)
Установка библиотеки. Первым делом устанавливаем SQLAlchemy через pip:
pip install sqlalchemy
Создание модели. Определяем класс, который представляет пользователя в нашей системе:
from typing import Optional
from sqlalchemy import String, create_engine, select
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, Session
# Создаем базовый класс для всех моделей
class Base(DeclarativeBase):
pass
# Определяем модель пользователя
class User(Base):
__tablename__ = 'users'
# Используем Mapped и mapped_column для строгого описания типов
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(50))
email: Mapped[str] = mapped_column(String(120), unique=True)
age: Mapped[Optional[int]] # Optional означает, что поле может быть пустым (NULL)
def __repr__(self) -> str:
return f"<User(name='{self.name}', email='{self.email}')>"
Подключение к базе. Создаем подключение к SQLite (для простоты) и инициализируем таблицы:
engine = create_engine('sqlite:///example.db', echo=True)
# Создаем таблицы в базе данных (если их нет)
Base.metadata.create_all(engine)
# Создаем сессию для выполнения операций
session = Session(engine)
Создание записи. Добавляем нового пользователя в базу:
new_user = User(name='Иван Петров', email='ivan@example.com', age=30)
session.add(new_user)
session.commit() # Фиксируем изменения в базе
print(f"Создан пользователь с ID: {new_user.id}")
Выборка данных. Получаем пользователей из базы различными способами:
# Получить всех пользователей stmt = select(User) all_users = session.scalars(stmt).all() # Найти пользователя по первичному ключу (ID) user = session.get(User, 1) # Фильтрация по условию (WHERE) stmt = select(User).where(User.age < 25) young_users = session.scalars(stmt).all() # Сортировка (ORDER BY) stmt = select(User).order_by(User.name) sorted_users = session.scalars(stmt).all()
Обновление записи. Изменяем данные существующего пользователя:
# Находим пользователя
stmt = select(User).where(User.email == 'ivan@example.com')
user = session.scalars(stmt).first()
if user:
user.age = 31
session.commit()
print("Возраст пользователя обновлен")
Удаление записи. Удаляем пользователя из базы:
if user:
session.delete(user)
session.commit()
print("Пользователь удален")
Этот пример демонстрирует базовый цикл работы с ORM: мы определяем структуру данных через класс, создаем объекты и работаем с ними привычными методами объектно-ориентированного программирования. SQLAlchemy берет на себя всю работу по генерации SQL и управлению транзакциями — нам остается лишь оперировать объектами на Python.
Популярные фреймворки: полный обзор по языкам программирования
Выбор ОРМ-фреймворка часто определяется языком программирования и экосистемой проекта. Давайте рассмотрим наиболее зрелые и популярные решения для основных языков разработки.
Python: SQLAlchemy, Django ORM
- SQLAlchemy — мощная и гибкая библиотека с открытым исходным кодом, которая предоставляет как высокоуровневый Object-Relational Mapping, так и низкоуровневый SQL Expression Language. Это решение для тех, кто ценит контроль и готов потратить время на настройку. SQLAlchemy считается одним из наиболее зрелых ORM в Python-экосистеме и широко используется в enterprise-проектах.
- Django ORM — встроенный компонент популярного веб-фреймворка Django, который славится своей простотой и удобством. Он следует принципу «batteries included» и идеально интегрирован с остальными компонентами Django. Отлично подходит для быстрой разработки веб-приложений, хотя и менее гибок по сравнению с SQLAlchemy.
Пример работы с Django. Источник: официальный сайт.
Java: Hibernate, JPA
Hibernate — де-факто стандарт ОРМ для Java-разработки, существующий уже более двадцати лет. Это полнофункциональное решение с богатой экосистемой, поддержкой кэширования нескольких уровней и интеграцией с большинством Java-фреймворков. Hibernate реализует спецификацию JPA и предоставляет дополнительные возможности сверх стандарта.
JPA (Java Persistence API) — не конкретная реализация, а спецификация для Object-Relational Mapping в Java. Hibernate, EclipseLink и другие фреймворки реализуют эту спецификацию, что обеспечивает определенную степень переносимости кода между разными ORM-решениями.
JavaScript: Sequelize, Knex, Objection.js
- Sequelize — наиболее популярный Object-Relational Mapping для Node.js, поддерживающий PostgreSQL, MySQL, MariaDB, SQLite и Microsoft SQL Server. Предоставляет промисы из коробки, миграции и богатый API для работы с отношениями. Хороший выбор для серверной разработки на JavaScript.

Пример работы с Sequelize. Источник: официальный сайт.
- Knex.js — строго говоря, это SQL query builder, а не полноценный ORM, но часто используется как его основа. Предоставляет удобный fluent API для построения запросов и управления миграциями, оставляя разработчику больше контроля над SQL.
- Objection.js — ОРМ, построенный поверх Knex.js, который добавляет объектно-ориентированный интерфейс, поддержку отношений и валидацию. Балансирует между полным ORM и query builder, позволяя при необходимости работать с SQL напрямую.
PHP: Eloquent, Doctrine
- Eloquent — ОРМ из фреймворка Laravel, который покорил PHP-сообщество своей элегантностью и простотой использования. Active Record паттерн делает работу с моделями интуитивно понятной, а богатая функциональность покрывает большинство типичных сценариев.
- Doctrine — более мощный и сложный ORM, реализующий Data Mapper паттерн. Используется в Symfony и других enterprise PHP-проектах. Требует больше времени на освоение, но предоставляет более гибкую архитектуру для сложных доменных моделей.
C#/.NET: Entity Framework, Dapper
- Entity Framework — официальный вариант от Microsoft для .NET экосистемы. Entity Framework Core (современная версия) поддерживает множество баз данных и предоставляет два подхода: Code First и Database First, позволяя начать разработку как от моделей, так и от существующей базы.
- Dapper — микро-ОРМ, который называют «king of micro-ORM». Он выполняет только маппинг результатов запросов на объекты, оставляя написание SQL разработчику. Обеспечивает производительность, близкую к чистому ADO.NET, при этом избавляя от рутинного кода.
Ruby: ActiveRecord
ActiveRecord — часть Ruby on Rails, установившая стандарты для ORM во многих других языках. Реализация Active Record паттерна здесь достигла своего совершенства: модели интуитивно понятны, DSL для запросов читается почти как естественный язык. Стала образцом для подражания для многих ORM в других экосистемах.
Как выбрать подходящую ORM для проекта
Выбор Object-Relational Mapping — это стратегическое решение, которое влияет на архитектуру приложения, скорость разработки и долгосрочную поддерживаемость проекта. Давайте рассмотрим ключевые факторы, которые следует учитывать при принятии этого решения.
- Требования проекта. Первый вопрос, на который нужно ответить: насколько сложна доменная модель приложения и какие операции с данными будут выполняться чаще всего? Для простых CRUD-приложений подойдут легковесные решения вроде Eloquent или Django ORM, в то время как сложные корпоративные системы с запутанными отношениями между сущностями потребуют мощности Hibernate или SQLAlchemy с их продвинутыми возможностями управления жизненным циклом объектов и кэшированием.
- Баланс производительности и удобства. Здесь мы сталкиваемся с классическим компромиссом. Полнофункциональные ОРМ упрощают разработку, но добавляют накладные расходы. Микро-ORM вроде Dapper дают производительность, близкую к нативному SQL, но требуют больше ручной работы. Для высоконагруженных сервисов стоит рассмотреть гибридный подход: использовать ORM для стандартных операций и нативный SQL для критичных по производительности запросов.
- Экосистема и интеграция. Насколько хорошо ORM интегрируется с используемыми в проекте фреймворками и библиотеками? Django ORM естественным образом работает с Django, Entity Framework идеально вписывается в ASP.NET Core экосистему. Попытка использовать Object-Relational Mapping вне его естественной среды может привести к дополнительным сложностям интеграции, которые перевесят его преимущества.
- Порог входа и кривая обучения. Сколько времени команда готова потратить на освоение инструмента? Некоторые ORM, такие как ActiveRecord или Eloquent, можно освоить за день и начать продуктивно работать. Другие, например Hibernate, требуют недель изучения документации и экспериментов, прежде чем разработчик начнет понимать все нюансы работы с ними.
- Зрелость и активность сообщества. Возраст проекта и размер сообщества напрямую влияют на доступность документации, количество готовых решений типичных проблем и скорость исправления багов. ORM с многолетней историей и активным комьюнити, такие как Hibernate или SQLAlchemy, предоставляют больше гарантий стабильности и долгосрочной поддержки.
- Типизация и безопасность. В статически типизированных языках (Java, C#, TypeScript) ORM может обеспечить проверку типов на этапе компиляции, что существенно снижает количество ошибок. В динамических языках (Python, Ruby, JavaScript) эта проверка происходит в рантайме, что требует более тщательного тестирования.
- Инструменты миграций. Встроенная поддержка миграций значительно упрощает управление эволюцией схемы базы данных. Некоторые ORM (Django ORM, Sequelize) предоставляют мощные инструменты миграций из коробки, другие требуют использования сторонних библиотек вроде Alembic для SQLAlchemy или Flyway для Java.
Заключение
Мы разобрали механизмы работы ORM, его преимущества и недостатки, но остается главный вопрос: когда эта технология действительно оправдывает себя, а когда становится излишним балластом? Давайте подведем итоги:
- ORM — это слой между кодом и базой данных. Он позволяет работать с данными через объекты и классы, не обращаясь напрямую к SQL.
- Object-relational mapping решает проблему несоответствия объектной и реляционной моделей. Это упрощает разработку и снижает количество рутинного кода.
- ORM ускоряет разработку и упрощает поддержку проектов. Большинство CRUD-операций выполняется автоматически и единообразно.
- У технологии есть ограничения. Накладные расходы, проблема N+1 запросов и сложность отладки требуют осознанного использования ORM.
- Выбор ORM зависит от задач проекта. Для простых приложений подойдут легковесные решения, для сложных систем — полноценные фреймворки или гибридный подход.
Если вы только начинаете осваивать профессию backend-разработчика, рекомендуем обратить внимание на подборку курсов по frontend-разработке. В таких программах обычно есть теоретическая и практическая часть, что помогает быстрее понять принципы object-relational mapping и научиться применять их в реальных проектах.
Рекомендуем посмотреть курсы по Frontend разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Frontend-разработчик
|
Eduson Academy
111 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
12 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Frontend-разработчик
|
Нетология
46 отзывов
|
Цена
120 700 ₽
268 288 ₽
с промокодом kursy-online
|
От
3 726 ₽/мес
На 2 года
|
Длительность
13 месяцев
|
Старт
5 апреля
|
Подробнее |
|
Профессия Фронтенд-разработчик
|
Skillbox
226 отзывов
|
Цена
165 992 ₽
331 985 ₽
Ещё -20% по промокоду
|
От
4 882 ₽/мес
Без переплат на 1 год.
8 169 ₽/мес
|
Длительность
4 месяца
|
Старт
7 марта
|
Подробнее |
|
Мидл фронтенд-разработчик
|
Яндекс Практикум
100 отзывов
|
Цена
150 000 ₽
|
От
21 500 ₽/мес
На 2 года.
|
Длительность
5 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |
|
Fullstack-разработчик на python (с нуля)
|
Eduson Academy
111 отзывов
|
Цена
158 760 ₽
|
От
13 230 ₽/мес
20 642 ₽/мес
|
Длительность
7 месяцев
|
Старт
10 марта
|
Подробнее |

Яндекс Практикум vs Eduson Academy: project management — где больше инструментов и симуляций
Выбираете курсы по управлению проектами и пытаетесь понять, где больше практики, инструментов и реального опыта работы? В этом материале разбираем программы Яндекс Практикума и Eduson Academy: какие навыки вы получите, какие инструменты освоите и какой формат обучения подойдёт именно вам.

Skillbox vs Eduson Academy: менеджер маркетплейсов — где больше шаблонов и прикладных задач
Курсы менеджера маркетплейсов обещают практику, шаблоны и быстрый старт, но что из этого действительно работает? Разбираем, как проверить программу до оплаты и выбрать обучение под свою цель.

Skypro vs Нетология: где наставники помогают по делу, а где поддержка формальная
Skypro или Нетология — где наставники действительно помогают разобраться в заданиях, а где поддержка может оказаться формальной? Разбираем роли наставников, качество фидбэка, сроки проверки домашних работ и карьерное сопровождение, чтобы понять, как проверить онлайн-курс до оплаты.

Удалёнка заканчивается: 62% компаний возвращают сотрудников в офис уже в 2026 году
Большинство российских работодателей планируют свернуть удалёнку уже в этом году. По данным опроса 3 500 компаний, только 14% готовы полностью сохранить дистанционный формат. Разбираемся, кого это коснётся и что делать тем, кто не хочет возвращаться в офис.