Ошибки при работе с SQL: примеры, риски и решения
Ах, SQL – этот древний язык общения с базами данных, который, казалось бы, должен быть простым и понятным (ведь он так похож на английский!), но умудряется регулярно преподносить сюрпризы даже опытным разработчикам. За свои 15+ лет работы с базами данных я повидал такое количество креативных способов «уронить» продакшен одним SQL-запросом, что впору писать книгу «1001 способ сделать DBAнесчастным».

Но давайте серьёзно: ошибки в SQL-запросах – это не просто повод для шуток в офисе (хотя и это тоже). Это реальные проблемы, которые могут привести к неправильным бизнес-решениям, падению производительности и – в особо «весёлых» случаях – к потере данных. И что самое интересное, большинство этих ошибок повторяются из проекта в проект, как будто существует какое-то негласное соревнование по их воспроизведению.
В этой статье я собрал самые «популярные» грабли, на которые наступают разработчики (и да, я тоже на них наступал, причём не раз). Разберём каждую из них, посмотрим на последствия и, конечно, научимся их избегать. Потому что, как говорится, лучше учиться на чужих ошибках – особенно когда речь идёт о сохранности данных вашей компании.
- Ошибки при написании SQL-запросов
- Неправильное использование JOIN
- Проблемы с обработкой пропусков (NULL-значений)
- Мудрые советы от того, кто наступил на все грабли
- Недооценка индексов
- Ошибки в использовании подзапросов и агрегатных функций
- Управление транзакциями
- Другие частые ошибки и советы
- Рекомендации и выводы
- Рекомендуем посмотреть курсы по SQL
Ошибки при написании SQL-запросов
Знаете, что общего между релизом в пятницу вечером и SQL-запросом без предварительной проверки? Оба они способны превратить ваши выходные в незабываемое приключение! Давайте разберем самые «популярные» способы создать себе проблемы при написании SQL.
Синтаксические «шедевры»
Начнем с классики жанра – синтаксических ошибок. Казалось бы, что может быть проще, чем написать FROM, но нет – обязательно найдется креативный разработчик, который напишет FORM. И база данных, как истинный grammar nazi, не преминет указать на эту ошибку:
SELECT * FORM dish -- Упс! WHERE NAME = 'Prawn Salad';
Результат? «Syntax error» и саркастическое «Did you mean ‘FROM’?» от вашей СУБД (если вам повезло с её чувством юмора).
Инструменты спасения
Чтобы не становиться героем анекдотов в офисе, используйте современные IDE и редакторы SQL с подсветкой синтаксиса. DataGrip, DBeaver, VS Code с SQL-расширениями – выбор богатый. Они подчеркнут ваши ошибки ещё до того, как вы успеете нажать Enter (и опозориться перед коллегами).
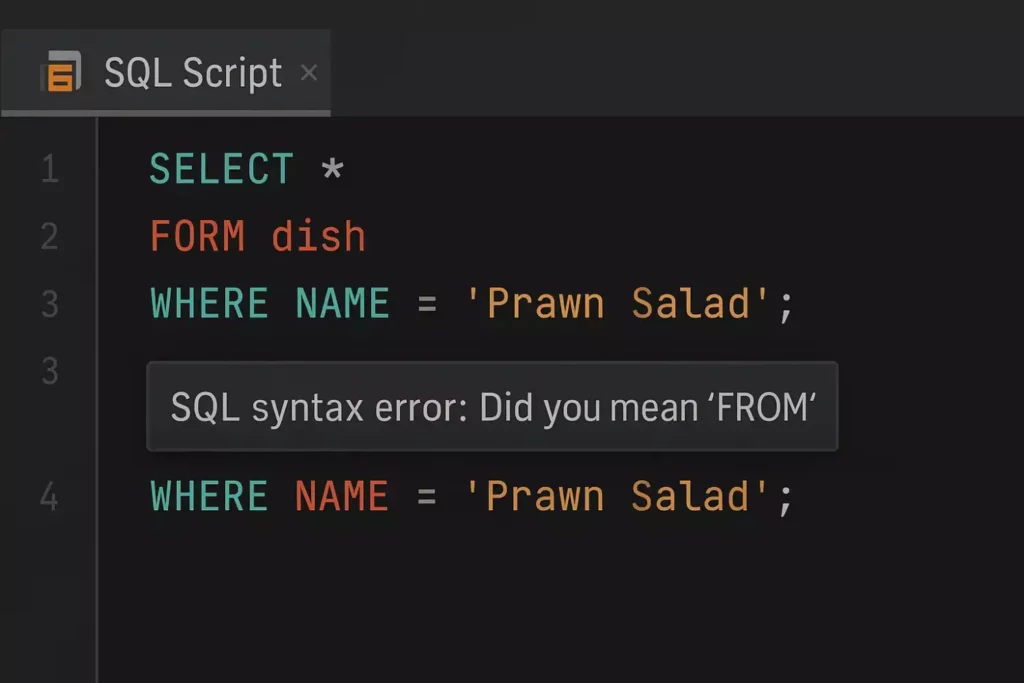
На изображении показан тёмный интерфейс SQL-редактора с фрагментом запроса, в котором допущена синтаксическая ошибка: вместо ключевого слова FROM написано FORM. Ошибка автоматически подчеркнута, а система выводит подсказку: «SQL syntax error: Did you mean ‘FROM'».
Порядок выполнения – это не просто слова
Отдельный вид «творчества» – это попытки использовать алиасы колонок там, где их ещё не существует:
SELECT price - discount AS final_price FROM orders WHERE final_price > 100; -- Спойлер: не сработает
СУБД в этом случае вежливо (или не очень) напомнит вам, что WHERE выполняется раньше, чем SELECT, и о final_price она ещё ничего не знает. Правильный вариант:
SELECT price - discount AS final_price FROM orders WHERE price - discount > 100; -- Вот теперь все в порядке
Кстати, для тех, кто любит эксперименты, – попробуйте написать такой запрос:
SELECT * FROM my_table WHERE 1 = 1;
Работает? Конечно! Но ваши коллеги будут долго думать над тем, зачем вы это сделали (особенно если это единственное условие в WHERE).
Помните: хороший SQL-запрос – это как хороший анекдот: все понимают, в чем суть, и никому не нужно объяснять, почему это работает. А использование современных инструментов для написания и проверки запросов – это не признак слабости, а признак того, что вы цените своё время и нервы своих коллег.
Неправильное использование JOIN
Ах, JOIN – любимая головная боль всех, кто работает с базами данных! Знаете, это как в отношениях: вроде бы все просто – соединяем две таблицы, но на практике получается… интересно (мягко говоря).
Самая популярная ошибка – «случайное» декартово произведение
SELECT * FROM employees, departments; -- "О, а почему у меня вдруг 10000 строк вместо 100?"
Поздравляю! Вы только что создали то, что в базах данных называют декартовым произведением, а в реальной жизни – «способ уложить сервер спать в разгар рабочего дня». Каждая строка первой таблицы соединяется с каждой строкой второй. Математики в восторге, сервер – не очень.
Типы JOIN и где они обитают
Давайте разберём основные типы, как будто объясняем их пятилетнему ребёнку (или менеджеру проекта – нужное подчеркнуть):
INNER JOIN
SELECT e.name, d.department_name FROM employees e INNER JOIN departments d ON e.dept_id = d.id;
Это как вечеринка, на которую пускают только тех, у кого есть пара. Нет пары – нет вечеринки. Одинокие записи остаются дома.
LEFT JOIN
SELECT c.id, COUNT(o.id) as orders_count FROM customers c LEFT JOIN orders o ON c.id = o.customer_id;
Все клиенты приглашены, даже те, кто ни разу ничего не заказал (да, мы про вас, которые только каталог листают).
RIGHT JOIN
По сути, то же самое, что LEFT JOIN, только наоборот. Используется так редко, что
некоторые разработчики считают его городской легендой.
FULL JOIN
SELECT * FROM table1 FULL JOIN table2 ON table1.id = table2.id;
Как корпоратив, на который пришли все: и те, кто работает, и те, кто уже уволился, и те, кто только собирается устроиться. Полный хаос, но иногда именно это и нужно.
Бонус: когда всё идёт не так
Особый вид «веселья» – это когда вы используете LEFT JOIN, а потом в WHERE добавляете условие по правой таблице:
SELECT c.name, o.order_date FROM customers c LEFT JOIN orders o ON c.id = o.customer_id WHERE o.order_date > '2024-01-01'; -- Упс, теперь это фактически INNER JOIN
Поздравляю, вы только что превратили LEFT JOIN в INNER JOIN! Ваши клиенты без заказов машут вам ручкой и исчезают из выборки.
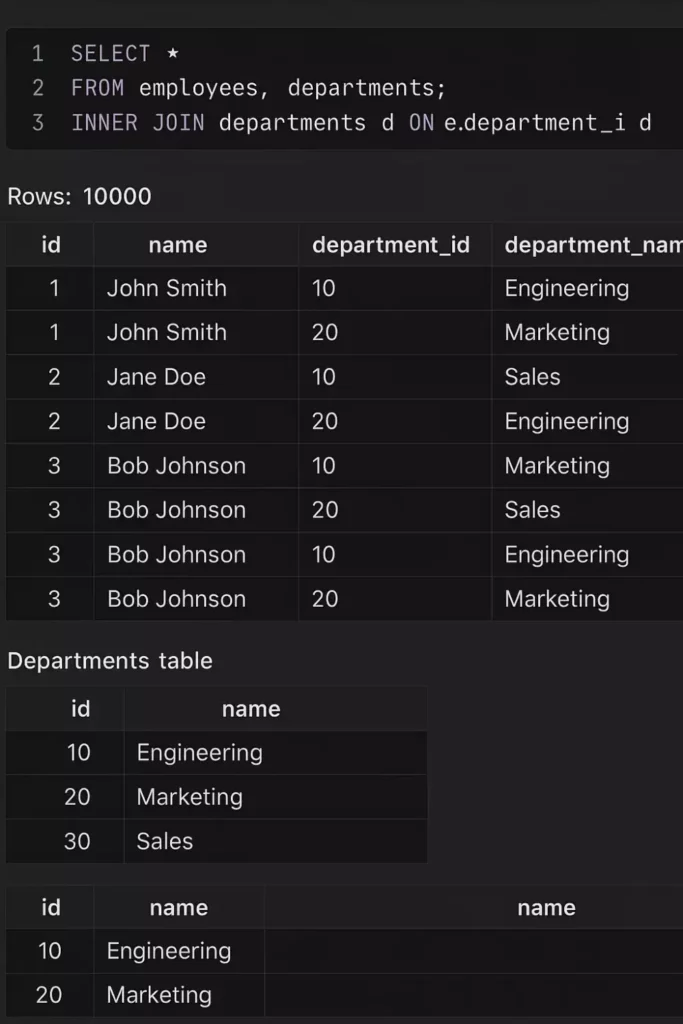
На изображении представлен интерфейс SQL-редактора с двумя вариантами выполнения запроса: первый использует перечисление таблиц без условия соединения (FROM employees, departments), в результате чего формируется 10 000 строк — типичное декартово произведение. Второй вариант показывает корректный INNER JOIN с указанием условия ON, что позволяет получить логичный и упрощённый результат.
Помните: правильный JOIN – это как правильный брак: важно не только соединить, но и понимать, что именно вы хотите получить в результате. И да, иногда лучше побыть одному (использовать подзапрос), чем создавать токсичные отношения между таблицами.
Проблемы с обработкой пропусков (NULL-значений)
А теперь поговорим о самом загадочном явлении в SQL – значении NULL. Это как квантовая механика в мире баз данных: значение вроде бы есть, но его как бы и нет. И если вы думаете, что NULL = NULL даст TRUE – поздравляю, вы попались в одну из самых коварных ловушек SQL
Почему NULL – это не то, чем кажется
SELECT * FROM users WHERE email = NULL; -- Спойлер: это никогда не работает
Если вы написали такой запрос, то скорее всего вы большой оптимист. NULL нельзя сравнивать через обычные операторы сравнения. Это как пытаться измерить температуру линейкой – инструмент не тот.
Правильный вариант:
SELECT * FROM users WHERE email IS NULL; -- Вот теперь мы говорим на одном языке с базой
Ловушка для самых маленьких: сравнение NULL-значений
Давайте проведем небольшой эксперимент:
SELECT CASE WHEN NULL = NULL THEN 'Равны' WHEN NULL != NULL THEN 'Не равны' ELSE 'Что происходит?' END AS result;
И получим… «Что происходит?». Потому что в мире SQL:
NULL = NULL → False
NULL != NULL → False
NULL > NULL → False
NULL < NULL → False
Это как квантовая суперпозиция – пока вы не проверите значение специальным образом, оно находится во всех состояниях одновременно.
COALESCE спешит на помощь
SELECT first_name, COALESCE(middle_name, 'Нет отчества') as middle_name, COALESCE(phone, email, 'Нет контактов') as contact FROM employees;
COALESCE – это как страховка от NULL. Он берет первое не-NULL значение из списка. Очень удобно, когда вы не уверены, что данные в базе такие же идеальные, как ваш код.
Мудрые советы от того, кто наступил на все грабли
Всегда используйте IS NULL или IS NOT NULL для проверки на NULL-значения
Помните, что NULL в арифметических операциях даёт NULL (NULL + 1 = NULL)
Используйте COALESCE для подстановки значений по умолчанию
Никогда не доверяйте сравнению NULL-значений через обычные операторы
И помните: NULL – это не пустая строка, не ноль и не false. Это особое состояние «неизвестности», как суперпозиция кота Шрёдингера, только в базе данных. И относиться к нему нужно соответственно!
Недооценка индексов
Поговорим об индексах – этой загадочной сущности, которую многие разработчики воспринимают как какую-то магию. «Добавь индекс» – любимая мантра DBA, когда запросы начинают работать медленнее, чем ваша бабушка печатает SMS.
Почему индексы важны (или история о том, как я ждал один запрос целую вечность)
Представьте, что вы ищете книгу в библиотеке. Есть два варианта:
- Просмотреть все книги подряд (full table scan – привет, производительность!)
- Воспользоваться каталогом (индекс – наш спаситель)
-- Запрос без индекса (aka "пойду сварю кофе, пока это выполняется") SELECT * FROM customers WHERE email = 'john.doe@example.com';
Основные ошибки при работе с индексами
Ошибка #1: «Больше индексов – лучше!»
-- Создаём индексы на все столбцы, потому что "а вдруг пригодится" CREATE INDEX idx_1 ON users(name); CREATE INDEX idx_2 ON users(email); CREATE INDEX idx_3 ON users(phone); CREATE INDEX idx_4 ON users(city); CREATE INDEX idx_5 ON users(favorite_color); -- серьёзно?
Спойлер: каждый индекс замедляет операции вставки и обновления. Это как заполнять анкету в пяти копиях – вроде и надёжно, но утомительно и обычно бессмысленно.
Ошибка #2: «Индексы для неселективных полей»
-- Создаём индекс на поле "пол" (всего два значения) CREATE INDEX idx_gender ON users(gender);
Это всё равно что создавать оглавление для книжки из двух глав. База данных просто посмеётся над вами и сделает full table scan.
Советы по оптимальному использованию индексов:
Создавайте индексы на полях, которые часто используются в WHERE, JOIN и ORDER BY:
CREATE INDEX idx_email_phone ON users(email, phone);
Помните о составных индексах (но порядок колонок важен!):
-- Хороший вариант CREATE INDEX idx_lastname_firstname ON employees(last_name, first_name);
Периодически проверяйте использование индексов:
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'test@test.com';
Бонус: история из жизни
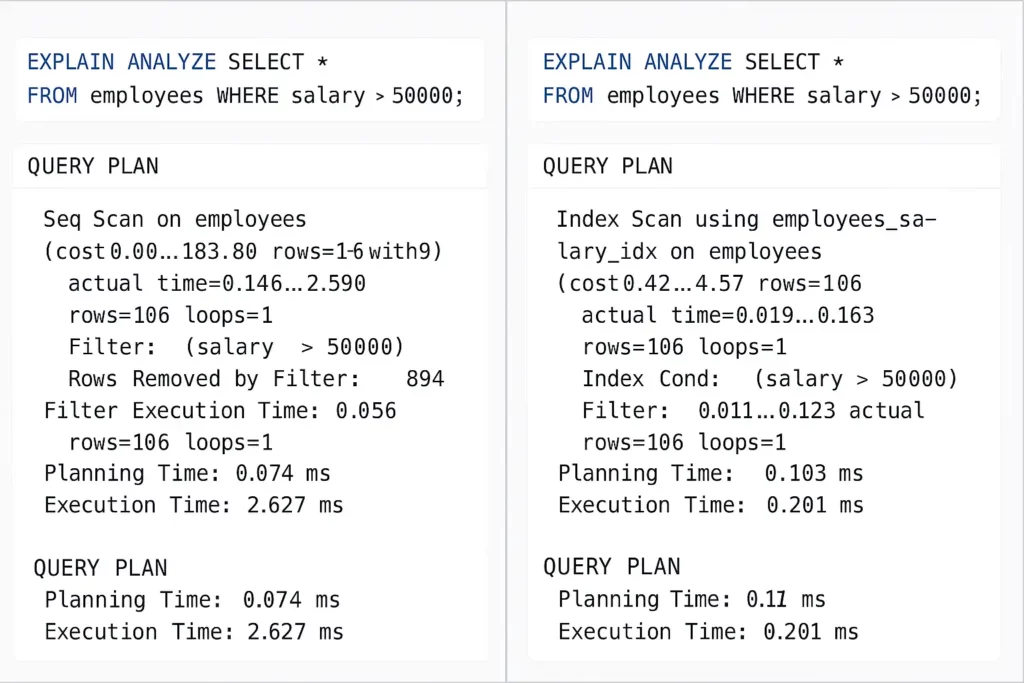
На изображении представлен наглядный сравнительный скриншот двух планов выполнения одного и того же SQL-запроса EXPLAIN ANALYZE SELECT * FROM employees WHERE salary > 50000; в PostgreSQL. Слева — результат без индекса, где используется Seq Scan (последовательное сканирование таблицы), приводящее к длительному времени выполнения. Справа — запрос с индексом, выполняемый через Index Scan, что резко сокращает время обработки.
Однажды я получил задачу оптимизировать запрос, который выполнялся 40 минут. После добавления правильного индекса время выполнения сократилось до 2 секунд. Заказчик был так впечатлён, что заподозрил меня в чёрной магии. А я просто добавил индекс на поле, по которому шла выборка миллиона записей.
Помните: индексы – это как специи в кулинарии. Правильное количество делает блюдо вкусным, избыток может всё испортить, а недостаток оставит вас с пресным результатом. И да, иногда лучше посоветоваться с шеф-поваром (DBA), прежде чем экспериментировать.
Ошибки в использовании подзапросов и агрегатных функций
Давайте поговорим о подзапросах – этом любимом инструменте начинающих разработчиков, которые ещё не знают, во что ввязываются, и агрегатных функциях, способных превратить простой SELECT в произведение искусства (или ужаса – зависит от точки зрения).
Подзапросы: когда «проще» не значит «лучше»
Классическая ошибка новичка:
SELECT * FROM orders WHERE customer_id IN ( SELECT id FROM customers WHERE country = 'USA' );
Выглядит красиво, правда? А теперь представьте, что в таблице customers миллион записей. База данных будет «счастлива» каждый раз перебирать их все заново для каждой строки из orders.
Как сделать правильно:
SELECT o.* FROM orders o JOIN customers c ON o.customer_id = c.id WHERE c.country = 'USA';
JOIN в данном случае – как брак по расчёту: может быть не так романтично, но гораздо практичнее.
Агрегатные функции: «групповая терапия» для данных
Самая популярная ошибка с GROUP BY:
SELECT
department_id, employee_name, -- Упс! COUNT(*) as emp_count FROM employees GROUP BY department_id;
База данных: «А что делать с employee_name? Я должен выбрать случайное имя? Или может все перечислить?»
Правильный вариант:
SELECT department_id, COUNT(*) as emp_count, MAX(salary) as max_salary, AVG(salary) as avg_salary FROM employees GROUP BY department_id;
Особый случай: подзапросы в SELECT
SELECT p.product_name, AVG(o.price) as avg_price FROM products p LEFT JOIN orders o ON p.id = o.product_id GROUP BY p.id, p.product_name;
-- Как НЕ надо делать SELECT product_name, (SELECT AVG(price) FROM orders WHERE product_id = products.id) as avg_price FROM products;
Это как отправлять отдельное письмо каждому участнику массовой рассылки – технически возможно, но крайне неэффективно.
Лучше использовать:
Мудрость дня:
Подзапрос в WHERE – это как рекурсия: иногда необходима, но чаще есть способ лучше
GROUP BY требует чёткого понимания, что именно мы хотим сгруппировать
Агрегатные функции без GROUP BY превращают вашу таблицу в одну строку (сюрприз!)
И помните: каждый раз, когда вы пишете подзапрос в SELECT, где-то грустит один DBA. Не заставляйте DBA грустить – они и так достаточно настрадались от наших запросов!
Управление транзакциями
А теперь давайте поговорим о транзакциях – этом чуде ACID-мира, которое либо случается целиком, либо не случается совсем. Как в известной поговорке: «Нельзя быть немножко беременной» – так и с транзакциями: они либо полностью завершены, либо полностью откачены.
«Забывчивость» как искусство
BEGIN TRANSACTION; UPDATE accounts SET balance = balance - 1000 WHERE id = 1; UPDATE accounts SET balance = balance + 1000 WHERE id = 2; -- *ушёл на обед, забыв про COMMIT*
Поздравляю! Вы только что создали идеальный рецепт для блокировки таблицы и увлекательного квеста «Найди, кто держит блокировку».
Правильный способ:
BEGIN TRANSACTION; UPDATE accounts SET balance = balance - 1000 WHERE id = 1; UPDATE accounts SET balance = balance + 1000 WHERE id = 2; COMMIT; -- Или ROLLBACK, если что-то пошло не так
Изоляция: уровни и грабли
Помните историю про то, как один разработчик решил, что READ UNCOMMITTED – отличная идея для повышения производительности? Спойлер: закончилось всё «весело».
-- Никогда так не делайте в продакшене! SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; SELECT * FROM important_data;
Это как читать черновик книги до того, как автор решил, какие персонажи выживут в конце.
PostgreSQL и его особенности:
-- Сюрприз: в PostgreSQL это не работает так, как вы думаете BEGIN TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; -- PostgreSQL: "Ха-ха, всё равно будет READ COMMITTED"
Советы от того, кто терял данные:
- Всегда явно завершайте транзакции (COMMIT или ROLLBACK)
- Не держите транзакции открытыми дольше необходимого
- Выбирайте правильный уровень изоляции (спойлер: обычно это не READ UNCOMMITTED)
- Используйте try-catch блоки в коде (если ваш язык это поддерживает)
Помните: транзакции – это как парашют. Лучше иметь его и не нуждаться в нем, чем нуждаться в нем и не иметь его. И да, проверяйте, застегнут ли он (COMMIT), прежде чем прыгать!
Другие частые ошибки и советы
А теперь поговорим о тех «прелестях» SQL, которые не попали в основные категории, но регулярно становятся причиной седых волос у разработчиков и DBA.
Порядок выполнения запроса: когда интуиция подводит
Знаете ли вы, что SQL – это как сборка мебели из IKEA? Порядок действий критически важен, и нет, ваша интуиция здесь не поможет.
SELECT product_name, unit_price * 1.2 AS marked_up_price FROM products WHERE marked_up_price > 50; -- Упс! База данных: "А что такое marked_up_price?"
База данных выполняет операции в следующем порядке (спойлер: не так, как вы их написали):
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
Правильный вариант:
SELECT * FROM ( SELECT product_name, unit_price * 1.2 AS marked_up_price FROM products ) AS subquery WHERE marked_up_price > 50;
Оконные функции: недооцененное сокровище
Помню времена, когда для расчёта накопительного итога писали что-то вроде:
-- Как не надо делать SELECT date, amount, (SELECT SUM(amount) FROM transactions t2 WHERE t2.date <= t1.date) as running_total FROM transactions t1 ORDER BY date;
А можно было просто:
SELECT date, amount, SUM(amount) OVER (ORDER BY date) as running_total FROM transactions;
Ещё один шедевр оконных функций:
SELECT department, employee_name, salary, AVG(salary) OVER (PARTITION BY department) as avg_dept_salary, salary - AVG(salary) OVER (PARTITION BY department) as difference_from_avg
Бонусная ошибка: забытый WHERE
DELETE FROM products; -- "Ой..."
Это как нажать Ctrl+A и Delete в продакшен-базе. Технически работает, но последствия… впечатляющие.
Защита от таких «опечаток»:
BEGIN TRANSACTION; DELETE FROM products WHERE category_id = 5; -- Проверяем результат -- COMMIT только если всё ок, иначе ROLLBACK
Помните: хороший SQL-запрос похож на хорошую шутку – он должен быть понятным, эффективным и не должен вызывать нервный смех у DBA. И да, всегда делайте бэкапы – они дешевле, чем новая работа!
Рекомендации и выводы
Как говорил один мудрый DBA (возможно, это был я после третьей чашки кофе): «SQL прост, пока вы не начинаете им пользоваться». После всего вышесказанного предлагаю несколько золотых правил, которые помогут вам избежать большинства подводных камней.
ТОП-5 правил выживания в мире SQL:
Всегда тестируйте на малых данных
Поверьте моему опыту: запрос, который прекрасно работает на таблице из 100 строк, может превратить вашу базу в задумчивую улитку на миллионе записей.
Используйте современные инструменты
IDE с подсветкой синтаксиса и автодополнением – не признак слабости, а признак здравого смысла. Это как GPS в машине: можно и по звёздам ориентироваться, но зачем?
Начинайте с EXPLAIN
EXPLAIN ANALYZE SELECT * FROM huge_table WHERE ...
Потратьте минуту на анализ плана запроса сейчас, сэкономьте часы на оптимизации потом.
Делайте бэкапы перед любыми изменениями
Потому что «упс…» в продакшене – это не то объяснение, которое хочет услышать ваш руководитель.
Не стесняйтесь спрашивать
У каждого из нас есть история о том, как простой запрос превратился в детективный роман. Иногда свежий взгляд коллеги может сэкономить вам часы отладки.
И помните: в мире SQL нет простых решений, есть только рабочие и те, которые «вроде работают, но лучше не трогать». Выбирайте первые, ваше будущее я скажет вам спасибо!
Если вы хотите не просто избегать типичных ошибок, но и научиться писать эффективные SQL-запросы с нуля, стоит обратить внимание на специализированные обучающие программы. На странице с курсами по SQL собраны актуальные онлайн-курсы по направлению — от базовых до продвинутых, которые помогут систематизировать знания и прокачать практические навыки работы с базами данных.
Рекомендуем посмотреть курсы по SQL
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
SQL с нуля для анализа данных
|
Eduson Academy
110 отзывов
|
Цена
49 900 ₽
|
От
4 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
1 месяц
|
Старт
27 февраля
|
Подробнее |
|
Продвинутый SQL
|
Нетология
46 отзывов
|
Цена
41 600 ₽
77 018 ₽
с промокодом kursy-online
|
От
2 567 ₽/мес
Рассрочка на 1 год.
|
Длительность
1 месяц
|
Старт
26 февраля
2 раза в неделю по будням
|
Подробнее |
|
SQL-разработчик
|
Eduson Academy
110 отзывов
|
Цена
79 900 ₽
|
От
6 658 ₽/мес
0% на 12 месяцев
|
Длительность
6 месяцев
|
Старт
2 марта
|
Подробнее |

Минимализм в дизайне: что это за стиль и почему он так популярен
Минимализм в дизайне кажется простым, но скрывает множество тонких решений. Хотите понять, почему он делает интерфейсы удобнее и визуально чище? В материале вы найдёте ответы и практические ориентиры.

Что такое распределённые транзакции и как они работают: протоколы, паттерны и практические решения
Распределённые транзакции это одна из самых сложных тем в микросервисной архитектуре — особенно если вы сталкиваетесь с отказами, задержками и несогласованными данными. Как работают 2PC и SAGA, почему ACID не спасает и какие паттерны используют на практике? Разбираемся пошагово и без лишней теории.

Цветокоррекция видео: секреты профессионального качества
Цветокоррекция – это не просто исправление ошибок съемки, а способ сделать видео выразительным и атмосферным. Давайте разберемся, как добиться впечатляющего результата

Cinema 4D — что это, зачем нужен и как с ним работать
Cinema 4D — не просто редактор 3D-графики, а целая экосистема для моделирования, анимации, визуальных эффектов и motion-дизайна. В статье рассказываем, как она устроена и кому будет особенно полезна.