Service Mesh: что это, как работает и когда его стоит внедрять
Давайте начнём с понимания того, что представляет собой сервисная сеть в современной архитектуре распределённых систем. Service Mesh — это выделенный инфраструктурный уровень, который берёт на себя управление всеми сетевыми взаимодействиями между микросервисами. Ключевое преимущество этого подхода заключается в том, что вся логика коммуникации — маршрутизация, безопасность, мониторинг — реализуется полностью на уровне платформы, без необходимости вносить изменения в исходный код приложений. Можно сказать, что эта технология играет роль своеобразного невидимого дирижёра оркестра микросервисов, координируя их взаимодействие и обеспечивая слаженную работу всей системы.

Технически сервисная сеть работает через внедрение прокси-серверов (так называемых sidecar-контейнеров) в каждый под или компонент. Эти прокси перехватывают весь входящий и исходящий трафик, образуя data plane — распределённую сеть обработки данных. Управление всеми этими прокси осуществляется централизованно через control plane — компонент, который отвечает за конфигурацию политик безопасности, правил маршрутизации и сбор телеметрии. Важно понимать: само приложение общается только со своим локальным прокси, который затем обеспечивает связь с другими компонентами согласно заданным правилам. Такая архитектура позволяет реализовать сложные сценарии управления трафиком, шифрование по умолчанию и детальную наблюдаемость всей системы — и всё это прозрачно для разработчиков приложений.
- Почему Service Mesh важен
- Как работает Service Mesh
- Ключевые функции и возможности
- Когда стоит использовать Service Mesh
- Преимущества и недостатки
- Обзор популярных реализаций Service Mesh
- Практика внедрения
- Подводные камни и частые ошибки
- Рекомендации для успешного старта
- Часто задаваемые вопросы (FAQ)
- Заключение
- Рекомендуем посмотреть курсы по обучению DevOps
Почему Service Mesh важен
Чтобы понять ценность сервисной сети, давайте рассмотрим типичные проблемы, с которыми сталкиваются команды при масштабировании микросервисной архитектуры. Когда количество компонентов в системе начинает исчисляться десятками или сотнями, коммуникация между ними превращается в настоящий вызов. Каждый модуль должен знать, как находить другие элементы, как обрабатывать их временную недоступность, как повторять неудачные запросы и как защищать передаваемые данные. Традиционный подход предполагает встраивание всей этой логики непосредственно в код каждого приложения — что приводит к дублированию кода, увеличению технического долга и высокой вероятности ошибок при реализации критически важных функций безопасности.
Возникает закономерный вопрос: как обеспечить единообразное применение политик безопасности и надёжности во всей распределённой системе, если каждая команда разработчиков реализует эти аспекты самостоятельно? Инфраструктурная сеть решает эту проблему радикально — выносит всю сетевую логику за пределы приложений. Это означает, что безопасность становится встроенной на уровне платформы: автоматическое шифрование трафика через mutual TLS (mTLS), строгая идентификация компонентов, контроль доступа на основе политик. Наблюдаемость также переходит на новый уровень — мы получаем детальные метрики, распределённую трассировку запросов и логирование, причём всё это работает единообразно для всех элементов независимо от языка программирования или фреймворка, на котором они написаны.
Практика показывает, что без такой инфраструктуры архитектура микросервисов быстро достигает точки, когда управление ею становится экспоненциально сложнее. Представьте ситуацию: вам нужно внедрить новую политику безопасности или изменить правила маршрутизации — и для этого придётся вносить изменения в десятки компонентов, написанных разными командами на разных языках программирования. С сервисной сеткой такие изменения применяются централизованно, через конфигурацию control plane, что драматически снижает операционную сложность и риски при внесении изменений.
Наконец, нельзя не упомянуть аспект разгрузки команд разработки. Когда инфраструктурные concerns — retry-логика, circuit breakers, rate limiting, timeout-политики — реализованы на уровне платформы, разработчики могут сосредоточиться на бизнес-логике приложений, а не на решении инфраструктурных задач. Это особенно важно в контексте современных DevSecOps-практик и Zero Trust архитектур, где требования к безопасности и надёжности постоянно ужесточаются.
Как работает Service Mesh
Архитектура service mesh: компоненты и их взаимодействие
Рассмотрим детально, из каких элементов состоит сервисная сеть и как они взаимодействуют друг с другом. В основе архитектуры лежит разделение на два ключевых слоя: data plane и control plane — концепция, хорошо знакомая инженерам по сетевым технологиям, но адаптированная для мира микросервисов.
Data plane представляет собой распределённую сеть прокси-серверов, которые внедряются как sidecar-контейнеры в каждый под приложения. Наиболее популярным выбором для этой роли является Envoy — высокопроизводительный прокси, написанный на C++, хотя существуют и альтернативы, например, легковесный прокси на Rust в Linkerd. Эти прокси перехватывают абсолютно весь сетевой трафик — как входящий, так и исходящий — и именно на этом уровне происходит реальная обработка запросов: применяются правила маршрутизации, выполняется шифрование, собираются метрики и трассировки. Важно понимать, что приложение даже не подозревает о существовании прокси — оно продолжает отправлять запросы как обычно, а весь функционал инфраструктуры работает прозрачно благодаря перехвату трафика на уровне сетевого стека.
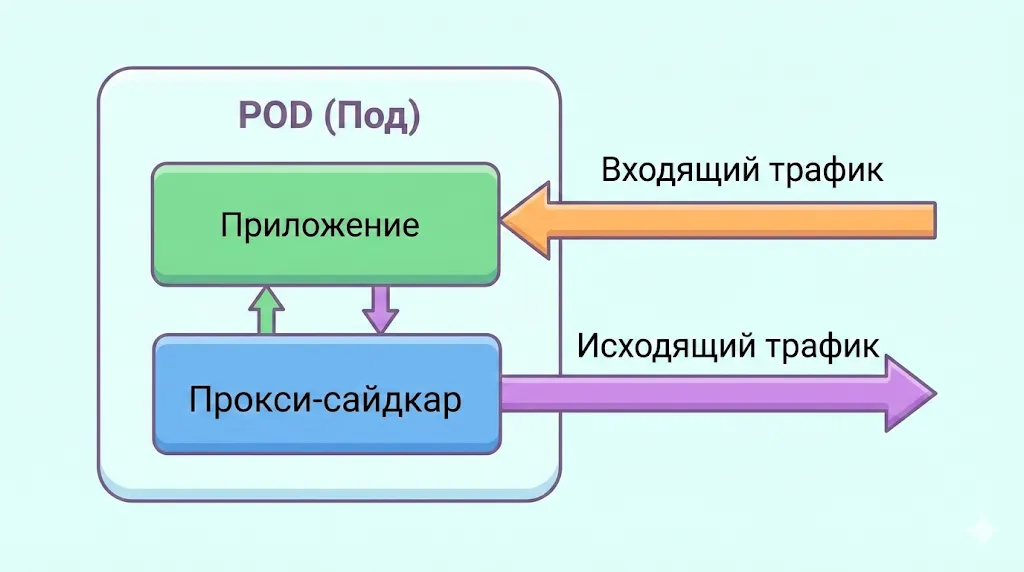
Эта иллюстрация наглядно показывает, как работает sidecar-паттерн: весь сетевой трафик, как входящий, так и исходящий, перехватывается прокси-контейнером, который находится в том же поде, что и основное приложение.
Control plane, в свою очередь, выступает в роли централизованного мозга всей системы. Именно здесь задаются конфигурации, политики безопасности, правила маршрутизации и параметры наблюдаемости. В архитектуре Istio, например, control plane включает компоненты вроде Pilot (управление конфигурацией и обнаружением компонентов) и Citadel (управление сертификатами и идентификацией). Control plane постоянно синхронизирует состояние с data plane, отправляя обновления конфигурации всем прокси в режиме, близком к реальному времени. Это позволяет администраторам изменять поведение всей сети микросервисов без перезапуска или модификации самих приложений.
Обработка трафика: путь запроса через Service Mesh
Давайте проследим, что происходит, когда один микросервис отправляет запрос другому в среде с сервисной сетью. Представим, что компонент A хочет обратиться к компоненту B. Вместо прямого HTTP-запроса, обращение сначала перехватывается локальным sidecar-прокси источника. Этот прокси анализирует запрос согласно заданным правилам: проверяет, какие политики маршрутизации применимы (возможно, нужно направить запрос к определённой версии модуля или распределить нагрузку между несколькими инстансами), применяет retry-логику и timeout-ограничения, а также инициирует шифрование с помощью mTLS.
Затем запрос отправляется к sidecar-прокси целевого компонента через защищённое соединение. На принимающей стороне прокси расшифровывает запрос, проверяет авторизацию (имеет ли источник право обращаться к получателю согласно заданным AuthorizationPolicy), собирает метрики о запросе и, наконец, передаёт его локальному экземпляру приложения. Весь этот процесс происходит за миллисекунды, добавляя минимальную задержку — хотя накладные расходы (накладные расходы) действительно существуют, и их нужно учитывать при проектировании системы.
Критически важно, что на каждом этапе этого пути собирается телеметрия: время обработки запроса, статус-коды, информация о возникших ошибках, трейсы для распределённой трассировки. Эта информация агрегируется и становится доступной в системах мониторинга вроде Prometheus и Grafana, позволяя инженерам видеть полную картину здоровья системы и быстро локализовать проблемы.
Интеграция с Kubernetes и другими платформами
Исторически технология возникла и получила наибольшее распространение именно в экосистеме Kubernetes — и это неслучайно. Kubernetes предоставляет идеальную среду для развёртывания благодаря своей архитектуре с подами, возможности автоматического внедрения sidecar-контейнеров и богатым API для управления конфигурацией через Custom Resource Definitions (CRD). При установке инфраструктурной сети в Kubernetes-кластер обычно настраивается автоматическое внедрение sidecar-прокси: это может происходить через admission webhooks, которые перехватывают создание новых подов и модифицируют их спецификацию, добавляя контейнер с прокси.
Однако было бы ошибкой считать сервисную сеть технологией, эксклюзивной для Kubernetes. Решения вроде Consul Connect или Istio поддерживают развёртывание в гетерогенных средах, включая виртуальные машины и даже физические серверы. Это особенно актуально для организаций, находящихся в процессе миграции устаревших систем в облако — инфраструктура может обеспечить единообразное управление коммуникацией между компонентами, работающими как в Kubernetes, так и на традиционной инфраструктуре. Более того, концепция multi-mesh набирает популярность: это подход, при котором несколько сетей в разных кластерах или даже у разных облачных провайдеров объединяются в единую федерацию, обеспечивая seamless-коммуникацию в мультиоблачных и мультикластерных архитектурах.
Ключевые функции и возможности
Перейдём к конкретным возможностям, которые получает инженерная команда при внедрении сервисной сети. Именно эти функции определяют практическую ценность технологии и обосновывают инвестиции в её развёртывание.
- Интеллектуальное управление трафиком. Платформа предоставляет мощный инструментарий для контроля над тем, как запросы движутся между компонентами. Мы можем настраивать маршрутизацию на основе различных критериев — версии модуля, HTTP-заголовков, параметров запроса или даже географического расположения. Например, можно направить пользователей с определённым User-Agent к beta-версии приложения, а всех остальных — к стабильной. Критически важные механизмы устойчивости также реализуются на этом уровне: автоматические повторы запросов (retry) при временных сбоях, timeout-ограничения для предотвращения каскадных отказов, circuit breakers для изоляции проблемных компонентов и rate limiting для защиты от перегрузок. Всё это настраивается декларативно, через конфигурацию, без изменения кода приложений.
- Безопасность по умолчанию. Одна из наиболее ценных возможностей — автоматическое шифрование всего внутреннего трафика через mutual TLS (mTLS). В традиционной архитектуре часто исходят из предположения, что внутренняя сеть является доверенной — подход, который полностью противоречит современным принципам Zero Trust. Инфраструктурная сеть устраняет эту проблему, обеспечивая end-to-end шифрование между всеми элементами автоматически, без необходимости управлять сертификатами вручную. Control plane берёт на себя весь жизненный цикл сертификатов: генерацию, ротацию, отзыв. Дополнительно мы получаем гибкие механизмы контроля доступа: можно определить политики авторизации на уровне компонентов (какие модули могут общаться друг с другом), использовать RBAC для детального управления правами и применять фильтрацию на основе SNI и CIDR для ограничения доступа по сетевым параметрам.
- Комплексная наблюдаемость. Сервисная сеть превращает «чёрный ящик» микросервисных коммуникаций в полностью прозрачную систему. Каждый запрос автоматически обогащается метриками — latency, throughput, error rates — которые собираются прокси и экспортируются в системы мониторинга вроде Prometheus. Распределённая трассировка (distributed tracing) позволяет проследить путь отдельного запроса через всю цепочку микросервисов, что критически важно для диагностики проблем производительности в сложных системах — интеграция с Jaeger или Zipkin делает это тривиальной задачей. Логи доступа также централизованно собираются и могут анализироваться для выявления аномалий или инцидентов безопасности. Важно, что вся эта observability-инфраструктура работает единообразно для всех компонентов, независимо от того, на каком языке они написаны.
- Продвинутые стратегии развёртывания. Платформа открывает новые возможности для безопасного выката новых версий приложений. Канареечные развёртывания становятся тривиальной задачей: мы можем направить 5% трафика на новую версию компонента, наблюдать за метриками и постепенно увеличивать процент, если всё работает корректно. Сине-зелёные развёртывания позволяют мгновенно переключаться между версиями с возможностью быстрого отката. A/B-тестирование даёт возможность направлять различные сегменты пользователей к разным версиям модуля для проверки гипотез — и всё это реализуется на уровне сетевой инфраструктуры, без необходимости встраивать логику feature flags в сам код приложения. Диаграмма разделения трафика при канареечном релизе.
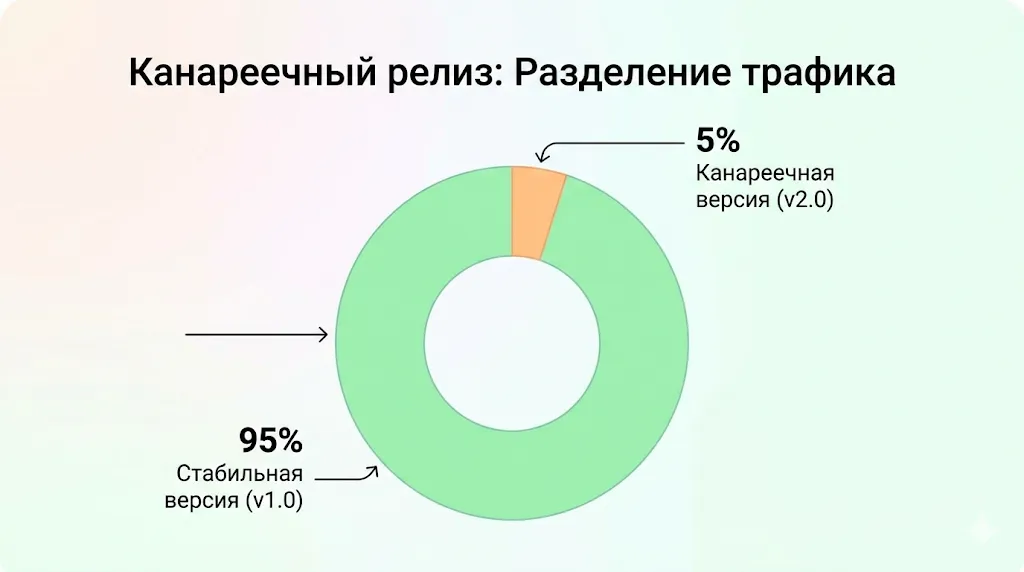
Пример того, как Service Mesh позволяет реализовать безопасный канареечный релиз: 95% пользователей направляются на стабильную версию приложения, а 5% — на новую, для тестирования в реальных условиях.
Возникает закономерный вопрос: не является ли это излишним усложнением? Практика показывает, что для команд, практикующих continuous delivery и частые релизы, эти возможности становятся незаменимыми.
Когда стоит использовать Service Mesh
Сценарии, где Service Mesh становится необходимостью
Давайте разберёмся, при каких условиях внедрение сервисной сети перестаёт быть просто интересным техническим экспериментом и становится обоснованной инженерной необходимостью. Ключевой фактор — масштаб и сложность микросервисной архитектуры. Когда количество компонентов в системе переваливает за несколько десятков, а команды разработки работают независимо друг от друга, управление коммуникациями между ними превращается в серьёзный вызов. В таких условиях инфраструктурная сеть обеспечивает единообразие и управляемость, которые невозможно достичь через встраивание логики в каждое приложение отдельно. Особенно это актуально для распределённых систем, работающих в мультиоблачных или гибридных средах, где элементы могут быть развёрнуты в разных дата-центрах или у разных облачных провайдеров.
Жёсткие требования к безопасности и соответствие требованиям также служат весомым аргументом в пользу технологии. Финансовые организации, медицинские учреждения, государственные структуры — все они сталкиваются с необходимостью обеспечить шифрование данных в transit, детальное логирование всех взаимодействий и строгий контроль доступа между компонентами системы. Реализация этих требований на уровне приложений потребовала бы значительных усилий от каждой команды разработки и создала бы риски несогласованной реализации. Сервисная сеть предоставляет эти возможности out-of-the-box, с централизованным управлением и гарантией единообразного применения политик безопасности. Более того, если ваша организация движется в сторону Zero Trust архитектуры — где нет доверия к внутренней сети по умолчанию — такая инфраструктура становится практически обязательным компонентом.
Потребность в глубокой наблюдаемости системы также может стать решающим фактором. Когда бизнес-критичные процессы проходят через десятки микросервисов, способность быстро локализовать источник проблем становится критически важной. Платформа предоставляет детальную телеметрию, распределённую трассировку и визуализацию топологии — инструменты, которые драматически сокращают время на диагностику и устранение инцидентов.
Когда Service Mesh может быть избыточным
Однако было бы нечестно не упомянуть ситуации, когда внедрение может оказаться преждевременной оптимизацией. Если ваша система состоит из 3-5 микросервисов, развёрнутых в одном кластере, с простыми требованиями к безопасности и наблюдаемости — накладные расходы на установку и поддержку могут перевесить преимущества. Дополнительная сложность в конфигурации, потребление ресурсов sidecar-прокси, необходимость обучения команды — всё это имеет свою цену. Возникает вопрос: не стоит ли сначала использовать более простые решения вроде Ingress-контроллеров или базовых Kubernetes Services, и переходить к инфраструктурной сети только когда сложность системы действительно этого потребует? Наш опыт показывает, что для небольших проектов или MVP это вполне разумный подход — технология должна служить бизнес-целям, а не наоборот.
Преимущества и недостатки
Любая технология требует взвешенного подхода при принятии решения о её внедрении. Сервисная сеть не является исключением — при всех своих впечатляющих возможностях, эта технология несёт с собой определённые издержки и сложности. Давайте систематизируем плюсы и минусы, чтобы получить объективную картину.
| Преимущества | Недостатки |
|---|---|
| Централизованное управление трафиком и политиками безопасности для всей системы | Дополнительный overhead ресурсов: CPU, память, задержки на обработку в прокси |
| Повышенная безопасность: автоматическое mTLS-шифрование, строгая идентификация сервисов | Существенная сложность конфигурации и необходимость глубокого понимания архитектуры |
| Единая наблюдаемость: метрики, трассировка и логи для всех сервисов из коробки | Высокий порог входа для DevOps-команд, требуется специализированная экспертиза |
| Гибкое управление релизами: canary, blue-green, A/B без изменения кода | Необходимость обучения команды новым паттернам и инструментам |
| Независимость от языка программирования: работает одинаково для всех сервисов | Потенциальные проблемы при отладке из-за дополнительного уровня абстракции |
| Разгрузка разработчиков от инфраструктурных concerns | Риск vendor lock-in при выборе конкретной реализации |
Рассмотрим преимущества более детально. Централизация управления — это действительно революционное изменение в операционной модели. Вместо того чтобы каждая команда разработки реализовывала собственные механизмы retry, timeout и circuit breaking, мы получаем единую точку управления этими политиками. Обновление правил маршрутизации или политик безопасности происходит через изменение конфигурации в control plane, что занимает минуты вместо недель координации между командами. Безопасность также выходит на качественно новый уровень: когда каждое соединение между компонентами автоматически шифруется и аутентифицируется, целый класс атак становится неактуальным. Наблюдаемость перестаёт быть проблемой разрозненных решений — мы видим всю систему как единое целое в едином дашборде.
Однако недостатки также нельзя игнорировать. Накладные расходы на ресурсы — это реальность, с которой придётся столкнуться: каждый sidecar-прокси потребляет память и CPU, а прохождение запросов через дополнительный hop добавляет латентность (обычно 1-5 миллисекунд, но в высоконагруженных системах это может быть критично). Сложность конфигурации — ещё один серьёзный момент. CRD вроде VirtualService, DestinationRule, AuthorizationPolicy в Istio требуют понимания не только Kubernetes, но и сетевых концепций, TLS, и специфики самой платформы. Возникает вопрос: готова ли ваша команда к этой кривой обучения? Практика показывает, что организациям часто требуется несколько месяцев и помощь внешних консультантов, чтобы достичь уверенного владения технологией.
Наконец, стоит упомянуть о проблеме отладки. Когда что-то идёт не так (а в сложных системах это неизбежно), дополнительный уровень прокси может усложнить диагностику: является ли проблема в приложении, в конфигурации инфраструктуры, или в самом прокси? Необходимость анализировать логи и метрики на нескольких уровнях требует дополнительных навыков и инструментов. Это не означает, что технология — плохая идея, но подчёркивает важность взвешенного подхода: она должна решать реальные проблемы вашей организации, а не создавать новые.
Обзор популярных реализаций Service Mesh
Рынок решений достаточно разнообразен, и выбор конкретной реализации зависит от специфики вашей инфраструктуры, требований к производительности и готовности команды работать со сложностью. Давайте рассмотрим наиболее зрелые и широко используемые варианты.
Istio — промышленный стандарт с максимальными возможностями
Istio можно без преувеличения назвать самым известным и функционально богатым решением. Разработанный при участии Google, IBM и Lyft, Istio использует Envoy в качестве data plane и предоставляет мощный набор возможностей через свой control plane компонент — Istiod. Что делает Istio особенно привлекательным для enterprise-сценариев? Прежде всего — глубина функциональности. Мы получаем детальный контроль над трафиком через VirtualService и DestinationRule, продвинутые возможности безопасности с автоматическим mTLS и гибкими AuthorizationPolicy, а также богатую интеграцию с экосистемой observability-инструментов вроде Prometheus, Grafana, Kiali и Jaeger.
Однако у этой мощности есть обратная сторона — Istio известен своей относительной сложностью и требовательностью к ресурсам. Установка и правильная конфигурация требуют значительной экспертизы, а количество CRD и параметров конфигурации может показаться overwhelming для команд, которые только начинают знакомство с концепцией. При этом для крупных организаций с сотнями микросервисов и строгими требованиями к безопасности Istio часто становится очевидным выбором — зрелость проекта, активное сообщество и проверенность в продакшне у таких гигантов как eBay и Airbnb говорят сами за себя.
Linkerd — философия простоты и производительности
Если Istio — это швейцарский нож с множеством функций, то Linkerd — это хорошо заточенный скальпель, сфокусированный на простоте и производительности. Разработанный компанией Buoyant, Linkerd делает ставку на минимализм: легковесный прокси на Rust вместо Envoy, простота установки (буквально одна команда linkerd install), и мгновенное включение mTLS по умолчанию. Возникает вопрос: не приводит ли такая простота к ограничениям в функциональности? В определённой степени — да. Linkerd предоставляет меньше возможностей для тонкой настройки трафика по сравнению с Istio, но покрывает 80% типичных сценарии использования.
Ключевое преимущество Linkerd — минимальный накладные расходы на производительность. Благодаря использованию специализированного прокси на Rust, Linkerd добавляет существенно меньшую задержку и потребляет меньше ресурсов по сравнению с решениями на базе Envoy. Для организаций, где каждая миллисекунда latency имеет значение, или где бюджет на инфраструктуру ограничен, это может стать решающим фактором. Linkerd также отлично подходит для команд, которые хотят получить core-возможности сервисной сети — безопасность, наблюдаемость, reliability — без необходимости погружаться в сложную конфигурацию.
Consul Connect, Kuma, OSM и альтернативные решения
Помимо двух лидеров рынка, существует ряд других интересных реализаций, каждая со своими уникальными характеристиками. Consul Connect от HashiCorp представляет собой гибрид service discovery и инфраструктурной сети — логичный выбор для организаций, уже использующих экосистему HashiCorp (Vault, Nomad, Terraform). Consul обеспечивает автоматическое mTLS-шифрование и service discovery, но может работать не только в Kubernetes, но и с виртуальными машинами и другими оркестраторами.
Kuma, разработанный Kong, позиционируется как универсальное решение с упором на multi-mesh federation — возможность управлять несколькими сетями как единой системой. Это особенно актуально для крупных организаций с множеством кластеров. Kuma также использует Envoy в качестве data plane, но предлагает более простой подход к конфигурации через GUI и REST API.
Open Service Mesh (OSM) — инициатива Microsoft, ориентированная на лёгкость и соответствие SMI (Service Mesh Interface) спецификации, которая призвана стандартизировать API различных реализаций. OSM подойдёт организациям, работающим в Azure и желающим получить простое в использовании решение с поддержкой от крупного вендора.
Выбор между этими решениями часто зависит не столько от технических возможностей, сколько от существующей экосистемы инструментов, экспертизы команды и долгосрочной стратегии организации. Стоит ли идти с проверенным, но более сложным Istio, или выбрать минималистичный Linkerd? Наш опыт показывает, что универсального ответа нет — важно честно оценить свои требования и возможности команды.
Практика внедрения
Теория — это прекрасно, но настоящее понимание технологии приходит только через столкновение с реальностью продакшн-среды. Давайте рассмотрим практические аспекты внедрения, основываясь на опыте команд, которые прошли этот путь.
Реальные кейсы: уроки из практики крупных компаний
Опыт крупных tech-компаний демонстрирует, что путь к успешному внедрению редко бывает прямолинейным. Рассмотрим типичные сценарии. Организации с сотнями микросервисов, такие как крупные booking-платформы или маркетплейсы, часто начинают внедрение с решения конкретной болевой точки — например, необходимости обеспечить end-to-end шифрование для соответствия требованиям или получить детальную visibility в сложной цепочке компонентов для диагностики performance-проблем. Характерная особенность успешных внедрений — постепенный развёртывание, когда инфраструктура сначала применяется к небольшому, некритичному набору элементов в качестве подтверждение концепции.
Интересно, что многие компании приходят к технологии не от хорошей жизни, а когда альтернативные подходы уже исчерпали себя. Ситуация, когда каждая команда разработки реализует собственные библиотеки для retry-логики, circuit breaking и service discovery на разных языках программирования, приводит к фрагментации и несогласованному поведению системы. Сервисная сеть в таких случаях становится инструментом унификации и стандартизации. Однако важно понимать: внедрение не ограничивается технической установкой — это организационная трансформация, требующая изменения процессов, обучения команд и пересмотра подходов к диагностировать.
Практика показывает, что наибольшую ценность технология приносит в следующих сценариях: миграция монолита в микросервисы (когда платформа обеспечивает observability и контроль в хаосе переходного периода), реализация Zero Trust архитектуры (автоматическое mTLS-шифрование между всеми компонентами), и продвинутые стратегии развёртывания (канареечные развёртывания с автоматическим откатом на основе метрик). Компании, работающие в высокорегулируемых индустриях, отмечают, что инфраструктура существенно упрощает прохождение аудитов безопасности благодаря централизованному управлению политиками и детальному логированию всех взаимодействий.
Подводные камни и частые ошибки
Возникает закономерный вопрос: что может пойти не так при внедрении? К сожалению, список довольно обширный. Первая и наиболее распространённая ошибка — недооценка сложности. Команды, вдохновлённые маркетинговыми материалами о «простоте установки», часто сталкиваются с суровой реальностью в момент, когда начинают настраивать сложные routing rules или разбираться с проблемами performance. Технология добавляет ещё один уровень в и без того сложную систему, и этот уровень требует глубокого понимания сетевых протоколов, TLS, и специфики конкретной реализации.
Проблемы с производительностью — ещё одна типичная категория неприятностей. Накладные расходы от sidecar-прокси может быть незаметным на dev-среде с низкой нагрузкой, но в продакшн с тысячами RPS дополнительные миллисекунды latency и потребление памяти каждым sidecar могут привести к неожиданному масштабированию инфраструктуры. Мы наблюдали случаи, когда после внедрения компаниям приходилось увеличивать количество нод в кластере на 20-30% только для компенсации накладные расходы от прокси. Это не означает, что решение неэффективно, но подчёркивает важность capacity planning и тщательного тестирования под нагрузкой до продакшн-развёртывание.
Конфигурационные ошибки — третья категория проблем, которая может привести к серьёзным инцидентам. Неправильно настроенная AuthorizationPolicy может заблокировать легитимный трафик между компонентами, некорректная VirtualService может создать routing loop, а ошибка в DestinationRule — направить весь трафик на несуществующий subset. Отладка таких проблем осложняется тем, что симптомы проявляются на уровне приложений, а причина кроется в конфигурации инфраструктуры. Именно поэтому многие организации внедряют практику peer review для изменений в конфигурации и используют тестовые среды для валидации перед применением в продакшн.
Рекомендации для успешного старта
Что же важно учесть, если вы решили двигаться в сторону сервисной сети?
- Первое и главное — начинайте с образования команды. Инвестируйте время в изучение концепций, пройдите официальные tutorial, поэкспериментируйте в безопасной среде. Команда должна понимать не только как установить систему, но и как она работает внутри, как читать логи прокси, как интерпретировать метрики, и как диагностировать-ить проблемы.
- Второе — определите конкретные сценарии использования для внедрения. Не пытайтесь решить все проблемы сразу. Начните с одной болевой точки — например, внедрите mTLS для соответствия требованиям, или используйте канареечные развёртывания для одного критичного компонента. Успешный подтверждение концепции на ограниченном объёме даст команде уверенность и опыт для дальнейшего масштабирования.
- Третье — подготовьте observability-инфраструктуру до внедрения. У вас должны быть настроены Prometheus для сбора метрик, Grafana для визуализации, система для distributed tracing. Платформа генерирует огромное количество телеметрии, и без правильной инфраструктуры для её обработки вы упустите значительную часть ценности.
Наконец, будьте готовы к итеративному подходу. Ваша первая конфигурация не будет идеальной, и это нормально. Важно настроить процесс continuous improvement: регулярно пересматривайте политики, оптимизируйте конфигурацию, обучайтесь на инцидентах. Это не проект с финальной датой завершения, а постоянно развивающаяся часть вашей инфраструктуры.
Часто задаваемые вопросы (FAQ)
В чём разница между Service Mesh и API Gateway?
Это один из наиболее частых источников путаницы, поскольку обе технологии работают с сетевым трафиком, но решают принципиально разные задачи. API Gateway — это точка входа для внешнего трафика в вашу систему, своего рода «вышибала» на входе, который занимается аутентификацией внешних клиентов, rate limiting для защиты от abuse, и маршрутизацией запросов к соответствующим backend-компонентам. Сервисная сеть, напротив, управляет коммуникацией внутри системы, между микросервисами. Эти технологии комплементарны и часто используются совместно: API Gateway обрабатывает north-south трафик (клиент-система), а инфраструктурная сеть — east-west трафик (компонент-компонент).
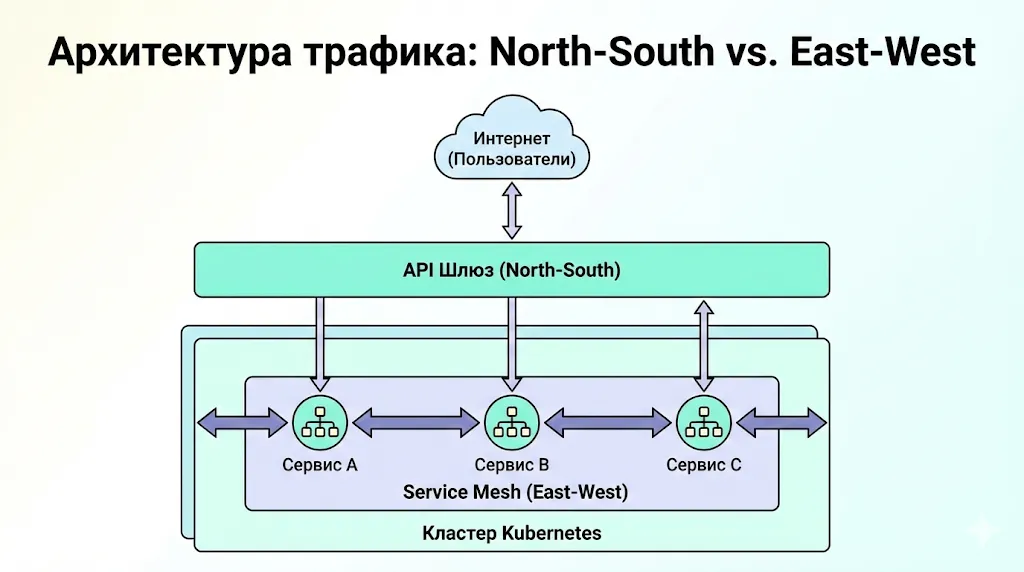
Эта диаграмма четко разграничивает роли: API Шлюз управляет внешним трафиком (North-South), в то время как Service Mesh контролирует внутреннюю коммуникацию между сервисами внутри кластера (East-West).
Нужно ли изменять код приложения при внедрении Service Mesh?
В идеале — нет, и это одно из ключевых преимуществ технологии. Система работает на уровне инфраструктуры, перехватывая сетевой трафик через sidecar-прокси, поэтому приложения продолжают работать как обычно, отправляя запросы на стандартные HTTP/gRPC endpoints. Однако на практике могут потребоваться небольшие адаптации: например, если приложение жёстко задаёт timeout меньше, чем настроенный в платформе, или если используются нестандартные протоколы. Также для максимальной пользы от distributed tracing желательно, чтобы приложения пробрасывали trace headers (хотя это опционально).
Как выбрать между Istio и Linkerd?
Выбор зависит от ваших приоритетов. Если вам нужна максимальная функциональность, глубокий контроль над трафиком, и команда готова инвестировать время в освоение сложной системы — Istio станет логичным выбором. Это особенно актуально для enterprise-сред с сотнями компонентов и сложными требованиями. Если же приоритет — простота, минимальный накладные расходы и быстрое время до получения value — Linkerd будет предпочтительнее. Linkerd отлично подходит для команд, которые хотят получить core-функциональность без излишней сложности. Наш опыт показывает, что для большинства организаций среднего размера Linkerd покрывает 80% потребностей при значительно меньших операционных издержках.
Увеличивает ли Service Mesh latency запросов?
Да, добавление дополнительного hop через sidecar-прокси неизбежно вносит некоторую задержку. Типичный накладные расходы составляет 1-5 миллисекунд на запрос, что для большинства приложений является приемлемым. Однако в высоконагруженных системах с жёсткими SLA по latency это может стать проблемой. Linkerd обычно показывает меньший накладные расходы благодаря своему легковесному прокси на Rust, в то время как Istio с Envoy может добавлять больше latency, особенно при включенных продвинутых возможности вроде детальной трассировки. Важно проводить performance-тестирование на realistic workloads перед принятием решения.
Можно ли использовать Service Mesh в небольших проектах?
Технически — да, практически — вопрос спорный. Для проекта с 3-5 микросервисами сложность установки и поддержки может превысить получаемую пользу. Возникает резонный вопрос: стоит ли инвестировать усилия в освоение и поддержку, если базовые Kubernetes Services и Ingress-контроллер решают ваши текущие задачи? Разумным подходом будет start simple и переходить к инфраструктурной сети когда сложность системы действительно этого требует — обычно это происходит при масштабировании за пределы 10-15 компонентов или когда появляются строгие требования к безопасности и observability.
Как Service Mesh влияет на потребление ресурсов кластера?
Каждый sidecar-прокси потребляет память (обычно 50-100 МБ для Envoy, меньше для Linkerd) и CPU. В кластере с сотнями подов это может привести к существенному увеличению общего потребления ресурсов — на практике мы наблюдали увеличение на 15-30% в зависимости от конфигурации и нагрузки. Control plane компоненты также требуют ресурсов, хотя и значительно меньше. Это необходимо учитывать при capacity planning и может потребовать пересмотра sizing кластера. Важно понимать, что эти ресурсы идут на реализацию функциональности, которую иначе пришлось бы встраивать в сами приложения, так что компромисс не всегда очевиден.
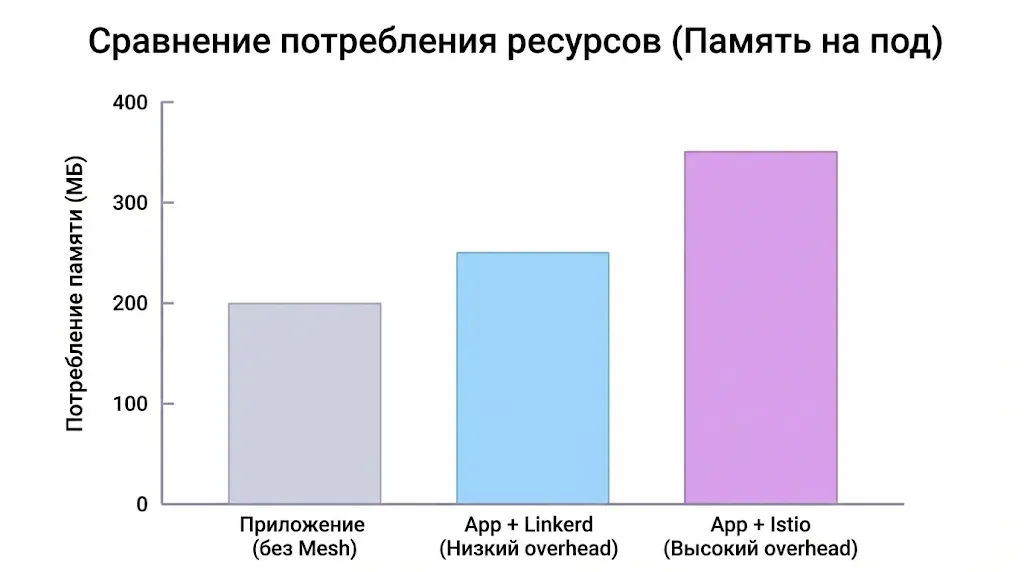
Эта диаграмма честно иллюстрирует цену внедрения: добавление sidecar-прокси неизбежно увеличивает потребление памяти. При этом различные реализации, например Linkerd и Istio, имеют разный «вес», что важно учитывать при планировании ресурсов кластера.
Что делать, если Service Mesh вызывает проблемы в продакшн?
Критически важно иметь откат-план до начала внедрения. Большинство решений позволяют отключить injection sidecar-контейнеров через аннотации или labels, что даёт возможность быстро вернуть систему к состоянию «до внедрения» путём перезапуска подов. Также рекомендуется внедрять технологию постепенно, namespace за namespace или даже компонент за компонентом, чтобы минимизировать blast radius в случае проблем. Наличие хорошего мониторинга и alerting на метриках прокси помогает выявлять проблемы до того, как они повлияют на end users.
Заключение
Мы прошли путь от базовых концепций до практических аспектов внедрения, и теперь подведем итоги:
- Service mesh — это инфраструктурный слой для микросервисов. Он берёт на себя управление сетевым трафиком, безопасностью и наблюдаемостью без изменений в коде приложений.
- Работа service mesh основана на data plane и control plane. Такое разделение позволяет централизованно управлять политиками и конфигурацией всей системы.
- Технология решает ключевые проблемы масштабирования микросервисов. Она снижает операционную сложность и устраняет дублирование сетевой логики в сервисах.
- Service mesh повышает уровень безопасности распределённых систем. Автоматическое mTLS-шифрование и контроль доступа реализуются на уровне платформы.
- Внедрение service mesh требует взвешенного подхода. Для небольших систем накладные расходы и сложность могут превысить получаемую пользу.
Рекомендуем обратить внимание на подборку курсов по девопс, если вы только начинаете осваивать профессию DevOps-инженера или SRE. В курсах есть как теоретическая часть с разбором архитектуры и принципов работы, так и практические задания по настройке и использованию service mesh в Kubernetes.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
112 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 марта
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
DevOps-инженер
|
Нетология
46 отзывов
|
Цена
101 800 ₽
226 321 ₽
с промокодом kursy-online
|
От
3 143 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 марта
|
Подробнее |
|
Профессия DevOps-инженер
|
Skillbox
226 отзывов
|
Цена
161 751 ₽
323 502 ₽
Ещё -20% по промокоду
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
11 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
100 отзывов
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Профессия DevOps-инженер PRO
|
Skillbox
226 отзывов
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
6 месяцев
|
Старт
11 марта
|
Подробнее |

Собеседование по Python: частые вопросы и как на них отвечать
Готовитесь к техническому интервью и хотите понять, какие вопросы на собеседование Python разработчик слышит чаще всего? Разбираем реальные примеры задач, вопросы для junior, middle и senior, а также типичные ошибки кандидатов и стратегию подготовки.

Skypro vs Contented: Web/UX дизайн — где сильнее разборы работ и быстрее растёт качество
В этой статье мы расскажем, как выбрать лучший курс по веб-дизайну. Если вы только начинаете изучать эту профессию, то вам наверняка будет полезно узнать, что важно учитывать при выборе курса и какие именно аспекты обучения могут ускорить ваш профессиональный рост. Откроем основные моменты, которые помогут вам сделать правильный выбор и избежать распространенных ошибок.

Skypro vs Bang Bang Education: где дизайнера лучше прокачивают «думать руками»
Выбираете курсы дизайна и пытаетесь понять, где действительно учат работать с реальными задачами? В этом материале разбираем, как сравнивать программы обучения, на что смотреть в практике, ревью и портфолио, и какие критерии помогут выбрать курс осознанно.

Собеседование PHP-разработчика: вопросы, задачи и подготовка
Если вы только начинаете осваивать профессию PHP-разработчика или хотите увереннее чувствовать себя на интервью, рекомендуем обратить внимание на подборку курсов по PHP-разработке. В таких программах обычно есть теоретическая и практическая часть: изучение языка, фреймворков, баз данных и решение реальных задач.