Собеседование Devops Junior и Middle: актуальные вопросы и темы 2026 года
Рынок труда DevOps в 2026 году выглядит парадоксально: вакансий много, а закрываются они медленно. Причина — разрыв между тем, что кандидат умеет делать руками, и тем, что компания ожидает увидеть на собеседовании. Эта статья написана для тех, кто либо делает первый шаг в профессию (Junior), либо готовится обосновать переход на следующий уровень (Middle) — и хочет понять, по каким критериям его будут оценивать, а не просто получить список вопросов.

Важно сразу обозначить контекст: в 2026 году интервьюеры ценят не энциклопедическое знание инструментов, а способность поддерживать доставку, надёжность и безопасность системы в условиях неопределённости. Можно знать наизусть все флаги команды kubectl, но провалиться на вопросе «как вы решали инцидент» — именно потому, что за инструментом не видно инженерного мышления.
Нил Форд, Software Architect в ThoughtWorks, автор концепции Evolutionary Architecture: «Инженерная зрелость сегодня измеряется не владением YAML, а пониманием ‘Mean Time to Detect’ и ‘Mean Time to Recover’. Если вы строите пайплайн, не понимая, как он влияет на эти метрики, вы не DevOps, вы — скрипт-кидди».
Статья организована по доменам: Linux и сети, CI/CD и GitOps, контейнеры и Kubernetes, облако и IaC, Observability и безопасность. Каждый блок закрывает конкретные темы собеседования и заканчивается мини-чеком «что достаточно для Junior / что ожидают от Middle» — чтобы вы могли честно оценить свой уровень без самообмана. Читать можно последовательно или точечно — по тем доменам, где чувствуете пробелы.
- Какие вопросы DevOps Junior/Middle задают в 2026 и как пройти интервью?
- Какие вопросы по Linux и сетям нужно закрыть в первую очередь?
- Какие вопросы по CI/CD и GitOps задают в 2026?
- Какие вопросы по Docker, Kubernetes и деплою в прод самые частые?
- Какие вопросы по Cloud и IaC (Terraform/OpenTofu) актуальны в 2026?
- Observability/SRE/Security: что отличает Middle в 2026?
- Как упаковать опыт: портфолио, кейсы и чек-лист подготовки
- Рекомендуем посмотреть курсы по обучению DevOps
Какие вопросы DevOps Junior/Middle задают в 2026 и как пройти интервью?
Типовое собеседование на DevOps-позицию редко ограничивается одним техническим экраном. Чаще всего пайп выглядит так: скрининг с рекрутером (мотивация, стек, зарплатные ожидания) → техническое интервью с инженером или лидом (теория + практические сценарии) → системный дизайн или разбор кейса (для Middle и выше) → финальный культурный фит с менеджером. На каждом этапе проверяют разное, и провалиться можно не только на технике — но именно технический блок определяет, дойдёте ли вы до оффера.
Что проверяют на техническом интервью
На уровне Junior интервьюер прежде всего хочет убедиться, что кандидат понимает базовые принципы и не боится дебажить незнакомую ситуацию. Глубина знаний здесь вторична — важнее логика рассуждений и готовность признать границы своей компетентности. Типичный вопрос звучит не как «назовите флаги утилиты X», а как «что вы сделаете, если сервис перестал отвечать» — и правильный ответ начинается с гипотезы, а не с магического перезапуска.
От Middle ждут качественно другого: самостоятельности в принятии решений, понимания trade-offs («почему blue-green, а не canary в данном контексте»), опыта влияния на архитектуру или процессы и — обязательно — истории про инциденты. Если Junior может сказать «я такого не встречал», то Middle без убедительного постмортема производит тревожное впечатление.
Тренды 2026 в вопросах
Собеседования этого года сместились в сторону нескольких устойчивых тем. GitOps перестал быть «продвинутой темой» и стал базовым ожиданием для Middle: интервьюеры спрашивают про drift, reconciliation и операционные риски, а не просто «слышали ли вы про Argo CD». OpenTelemetry вытесняет разговоры про конкретные системы мониторинга — важнее объяснить принцип корреляции сигналов, чем перечислить дашборды. Supply-chain security (SBOM, подписи артефактов, SLSA) из нишевой темы превратилась в ожидаемый контекст для любого, кто работает с CI/CD в продакшне. Наконец, вопрос «Terraform или OpenTofu» из провокационного стал вполне рабочим — и требует осознанного ответа, а не уклонения.
Келси Хайтауэр, независимый эксперт, экс-Principal Engineer в Google: «Мы перегрузили DevOps-инженеров. Требовать от Middle-инженера глубоких знаний в Supply-chain security, GitOps, SRE и еще пяти доменах — это путь к выгоранию и созданию ‘бутылочного горлышка’. Будущее за Platform Engineering, где DevOps-инженер создает самообслуживаемую платформу, а не бегает дебажить чужие поды».
Красные флаги на собеседовании
Три паттерна, которые гарантированно снижают оценку вне зависимости от уровня позиции: ответы без причинно-следственной связи («просто перезапустил — заработало»), отсутствие понимания границ ответственности и рисков («это не моя зона»), и попытка перейти к решению без базовой диагностики. Последнее особенно показательно: инженер, который тянется к kubectl delete pod раньше, чем к kubectl describe, сигнализирует о системной проблеме с подходом.
Junior vs Middle: что проверяют по доменам
| Домен | Ожидание Junior | Ожидание Middle | Типовой вопрос | Признак сильного ответа |
|---|---|---|---|---|
| Linux/сети | Знает базовые команды, понимает процессы и логи | Выстраивает диагностику по слоям, объясняет сетевой путь | «Сервис не отвечает — с чего начнёте?» | Чёткая последовательность гипотез |
| CI/CD | Умеет настроить простой пайплайн | Проектирует надёжный пайплайн с безопасностью и откатом | «Как обеспечить воспроизводимость релиза?» | Упоминание immutable artifacts и версионирования |
| Kubernetes | Знает базовые объекты, умеет дебажить CrashLoop | Настраивает RBAC, autoscaling, prod-ready деплой | «Как обновить деплой без даунтайма?» | rolling update + probes + PodDisruptionBudget |
| IaC | Писал Terraform, знает state | Управляет модулями, окружениями, политиками | «Как не сломать прод при apply?» | plan + review + state locking + разделение прав |
| Observability | Знает метрики и логи | Выстраивает корреляцию, формулирует SLO | «Как вы поняли, что проблема на стороне БД?» | Trace → метрика → лог по единому trace_id |
Какие вопросы по Linux и сетям нужно закрыть в первую очередь?
Linux и сети — это фундамент, который проверяют на любом DevOps-собеседовании вне зависимости от уровня. Принципиальная разница между Junior и Middle здесь не в количестве знакомых команд, а в способности выстроить диагностику системно: от симптома — к гипотезе — к проверке — к выводу. Интервьюер, задающий вопрос «сервис недоступен — что делаете?», ждёт не перечисления утилит, а демонстрации инженерного мышления.
Linux: где смотреть и что искать
Базовая диагностика начинается с понимания того, где в Linux живёт информация о состоянии системы. Логи приложений и системы — в /var/log и через journalctl; состояние процессов — ps aux, top, htop; потребление ресурсов — df -h, free -m, iostat, vmstat. Отдельного внимания заслуживают три концепции, которые регулярно всплывают на интервью: load average (средняя нагрузка за 1/5/15 минут — важно понимать, что высокий load не всегда означает проблему CPU), OOM Killer (ядро убивает процессы при нехватке памяти — след остаётся в dmesg или journalctl -k) и ulimits (ограничения на файловые дескрипторы и процессы, которые часто становятся причиной «странных» отказов под нагрузкой).
Для Middle добавляется умение читать /proc напрямую, понимать strace и lsof как инструменты глубокой диагностики, и — что особенно ценится — объяснять разницу между проблемой на уровне ОС и проблемой на уровне приложения.
Сеть: сквозной сценарий диагностики
Классический вопрос на собеседовании — «сервис недоступен, HTTP 502, с чего начнёте» — проверяет именно способность пройти сетевой путь по слоям, не перескакивая. Правильная последовательность выглядит так:
DNS → TCP → TLS → HTTP → LB/Ingress → App logs
Сначала проверяем резолвинг: dig или nslookup покажут, отдаёт ли DNS нужный IP. Затем TCP-связность: telnet host port или nc -zv — есть ли вообще соединение. Если TLS — openssl s_client -connect покажет цепочку сертификатов и возможные ошибки. HTTP-уровень — curl -v с подробным выводом заголовков. Дальше смотрим на балансировщик или Ingress: правильно ли роутится трафик, нет ли health-check failures. И только в конце — логи самого приложения.
Типовая ошибка кандидата — начать с логов приложения, минуя сетевые слои. Это не просто неэффективно — это сигнал об отсутствии системного подхода.
Шпаргалка диагностики Linux + сеть за 10 минут
| Симптом | Проверка | Команда | Что означает результат | Следующий шаг |
|---|---|---|---|---|
| Сервис не отвечает | DNS-резолвинг | dig service.example.com | Нет ответа / неверный IP | Проверить /etc/resolv.conf, CoreDNS |
| Нет TCP-соединения | Порт открыт? | nc -zv host 443 | Connection refused | Проверить firewall / iptables / security group |
| TLS-ошибка | Сертификат | openssl s_client -connect host:443 | Expired / untrusted chain | Обновить сертификат, проверить CA |
| HTTP 502/504 | Upstream alive? | curl -v http://backend | Таймаут / connection reset | Логи LB, health checks бэкенда |
| Высокий load average | CPU vs I/O | iostat -x 1 + top | %iowait высокий | Дисковые операции, медленный storage |
| OOM / убитый процесс | Kernel log | dmesg | grep -i oom | Out of memory: Kill process | Проверить limits, увеличить память / оптимизировать |
| Лимит дескрипторов | ulimits | ulimit -n + lsof -p PID | wc -l | Близко к лимиту | Поднять fs.file-max, настроить systemd limits |
Мини-чек: Junior vs Middle по Linux и сетям
Junior: знает 10–15 команд диагностики, понимает load average и OOM, умеет пройти сетевой путь по подсказке.
Middle: выстраивает диагностику самостоятельно, формулирует гипотезы до запуска команд, умеет объяснить, почему именно этот слой проверяется первым.
Какие вопросы по CI/CD и GitOps задают в 2026?
CI/CD — одна из тех тем, где кандидаты чаще всего переоценивают свою готовность. Настроить пайплайн в GitHub Actions или GitLab CI умеют многие, но объяснить, почему он спроектирован именно так, какие гарантии он даёт и как он ведёт себя при отказе — могут единицы. Именно эта разница между «я настраивал» и «я проектировал» отделяет Junior от Middle на собеседовании.
Из чего состоит хороший пайплайн
Зрелый CI/CD пайплайн — это не просто последовательность шагов, а система гарантий. Минимальный состав, который ожидают увидеть от Middle: build (воспроизводимая сборка с фиксированными зависимостями) → test (unit + integration, с порогом покрытия) → security checks (SAST, проверка зависимостей на CVE, например через trivy или grype) → artifact (immutable, версионированный, подписанный) → deploy (с механизмом отката) → verify (smoke-тесты или health-check после деплоя). Ключевое слово здесь — immutable artifact: то, что задеплоили в прод, должно быть байт-в-байт идентично тому, что прошло тесты. Пересборка на этапе деплоя — красный флаг.
Путь релиза схематично выглядит так:
Commit → CI (build + test + security) → Artifact (immutable) → Deploy → Verify → Rollback (если нужно)
Вопрос «как доказать, что релиз воспроизводим» — один из самых показательных на Middle-интервью. Сильный ответ включает: фиксацию версий зависимостей (lockfile), хранение артефакта в registry с immutable tag, логирование всех шагов сборки и — в идеале — attestation/provenance (кто, когда и из какого коммита собрал).
Стратегии деплоя и откат
Rolling update, blue-green и canary — три стратегии, которые регулярно всплывают на собеседованиях, причём интервьюер ждёт не определений, а понимания trade-offs. Rolling update прост в реализации, но во время обновления в кластере одновременно живут две версии приложения — это проблема, если API несовместимы. Blue-green даёт мгновенный откат (переключение трафика), но требует удвоенных ресурсов. Canary позволяет выкатить изменение на часть пользователей и измерить метрики до полного релиза — но требует зрелой observability, иначе сигнал просто некуда смотреть.
Вопрос «как откатываетесь» — тоже показательный. Ответ «просто деплоим предыдущую версию» технически верен, но не учитывает миграции базы данных, изменения конфигурации и состояние внешних систем. Middle должен понимать, что откат — это не кнопка, а процедура.
GitOps: drift, reconciliation и почему это важно
GitOps — это операционная модель, в которой Git является единственным источником истины о желаемом состоянии системы. Два ключевых концепта, которые проверяют на интервью: reconciliation (контроллер непрерывно сравнивает желаемое состояние в Git с реальным и приводит их в соответствие) и drift (расхождение между тем, что в Git, и тем, что реально запущено — например, кто-то сделал kubectl edit вручную). Умение объяснить, чем drift опасен в продакшне и как его детектировать, — маркер осознанного подхода.
Сравнение Argo CD и Flux на уровне концепции: оба реализуют GitOps, но Argo CD делает акцент на UI и удобстве визуализации, Flux — на операторном подходе и гибкости интеграции. На собеседовании важнее объяснить принцип, чем защищать конкретный инструмент.
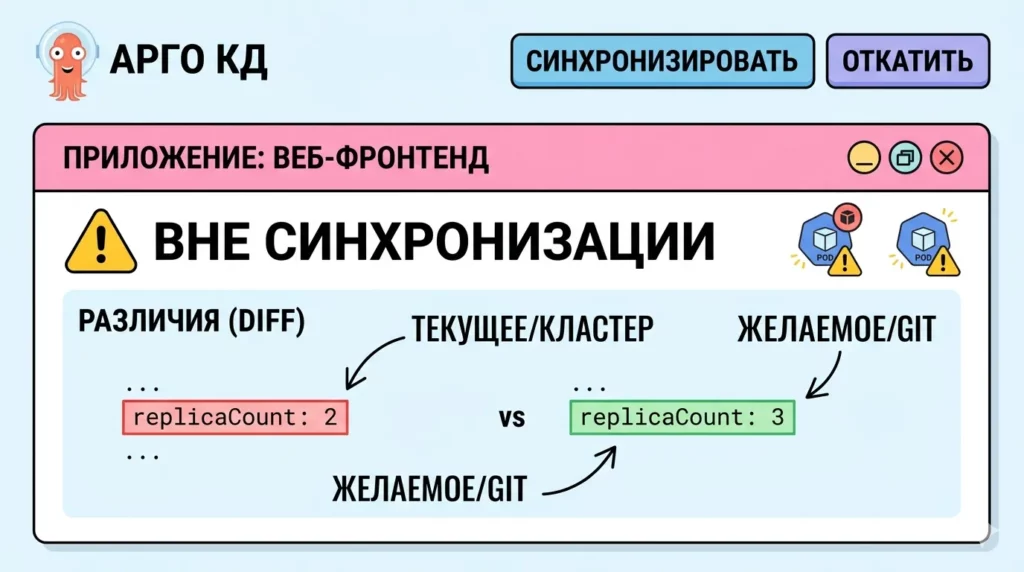
Этот стилизованный скриншот визуализирует дрифт конфигурации в Argo CD. Выделенный статус «ВНЕ СИНХРОНИЗАЦИИ» и пометка replicaCount: 2 (текущее) в красной рамке против replicaCount: 3 (в Git) наглядно объясняют, почему GitOps необходим для обнаружения ручных изменений.
CI/CD vs GitOps: в чём разница на языке собеседования
| Критерий | CI/CD | GitOps | Риски | Когда выбирать |
|---|---|---|---|---|
| Источник истины | Пайплайн / скрипт | Git-репозиторий | Drift при ручных изменениях в GitOps | GitOps — когда нужна аудируемость и откат через PR |
| Триггер деплоя | Событие в CI (push, tag) | Reconciliation loop контроллера | CI/CD — риск несинхронизированного состояния | CI/CD — для сложных многошаговых деплоев |
| Откат | Повторный запуск пайплайна | Revert коммита в Git | Оба требуют учёта DB-миграций | GitOps проще для Kubernetes-окружений |
| Аудит изменений | Логи CI | Git history + PR | CI-логи могут ротироваться | GitOps даёт полный trail без доп. инструментов |
| Зрелость команды | Низкий порог входа | Требует GitOps-дисциплины | Ручные правки «сломают» модель | CI/CD — стартовая точка, GitOps — зрелая практика |
Мини-чек: Junior vs Middle по CI/CD и GitOps
Junior: умеет настроить базовый пайплайн, знает стратегии деплоя на уровне определений, слышал про GitOps.
Middle: проектирует пайплайн с учётом безопасности и воспроизводимости, объясняет trade-offs стратегий деплоя, понимает drift и reconciliation и может обосновать выбор подхода.
Какие вопросы по Docker, Kubernetes и деплою в прод самые частые?
Контейнеры и Kubernetes — сердцевина большинства DevOps-собеседований в 2026 году. Показательно, что вопросы здесь редко бывают академическими: интервьюер почти всегда приходит с конкретным сценарием — «под в CrashLoopBackOff, что делаете» или «ingress не работает, с чего начнёте». Именно поэтому готовиться к этому блоку лучше не по документации, а по реальным debug-сессиям — желательно собственным.
Docker: слои, multi-stage и что ломается в runtime
Понимание слоёв Docker-образа — базовое ожидание даже от Junior. Каждая инструкция в Dockerfile создаёт новый слой; слои кешируются, и порядок инструкций напрямую влияет на эффективность сборки. Типовая ошибка — копировать весь проект до установки зависимостей: тогда любое изменение кода инвалидирует кеш зависимостей. Правильный порядок: сначала COPY файлов зависимостей (например, package.json или requirements.txt), затем их установка, затем остальной код.
Multi-stage builds — ожидаемая тема для Middle. Суть: сборочное окружение (с компилятором, dev-зависимостями) отделяется от runtime-образа, в финальный образ копируются только артефакты. Результат — меньший размер образа и меньшая поверхность атаки. Вопрос «почему ваш образ весит 1.2 ГБ» на собеседовании — не риторический.
Что ломается в runtime: три наиболее частые проблемы — неправильные права доступа (процесс запущен от root внутри контейнера, но volume смонтирован с другими правами), лимиты памяти и CPU (контейнер убивается OOM-киллером без очевидного сообщения в логах приложения) и отсутствие graceful shutdown (приложение не обрабатывает SIGTERM, Kubernetes ждёт таймаут и убивает принудительно).
Kubernetes: база, которую проверяют всегда
Минимальный набор объектов, который должен уверенно объяснить Junior: Deployment (управляет ReplicaSet и стратегией обновления), Service (абстракция над подами, DNS-имя внутри кластера), Ingress (маршрутизация внешнего HTTP/HTTPS трафика), ConfigMap и Secret (конфигурация и чувствительные данные — с оговоркой, что Secret в base64 — не шифрование). Отдельно — liveness и readiness probes: их различие критично и регулярно проверяется. Liveness определяет, жив ли контейнер (при неудаче — рестарт); readiness определяет, готов ли он принимать трафик (при неудаче — убирается из балансировки, но не рестартует).
Debug-сценарии: что спрашивают чаще всего
Четыре сценария, которые встречаются на собеседованиях стабильно:
- CrashLoopBackOff — под запускается и сразу падает. Диагностика: kubectl describe pod (события, причина рестарта) → kubectl logs pod —previous (логи предыдущего контейнера) → проверка liveness probe, entrypoint, переменных окружения.
- Pending — под не может быть назначен на ноду. Причины: недостаточно ресурсов (requests не удовлетворяются), node selector / affinity не совпадают, PVC не bound. Диагностика: kubectl describe pod → секция Events.
- DNS не резолвится внутри кластера — проверить, запущен ли CoreDNS (kubectl get pods -n kube-system), проверить resolv.conf внутри пода (kubectl exec), проверить NetworkPolicy на блокировку UDP/53.
- Ingress не работает — проверить, установлен ли ingress-controller, просмотреть аннотации, убедиться, что Service и порты указаны корректно, посмотреть логи контроллера.
Middle: RBAC, autoscaling и prod readiness
От Middle ожидают понимания нескольких продвинутых тем. RBAC: разница между Role/ClusterRole и RoleBinding/ClusterRoleBinding, принцип least privilege применительно к сервис-аккаунтам. HPA (Horizontal Pod Autoscaler): масштабирование по метрикам CPU/memory или custom metrics; важно понимать, что HPA не работает без metrics-server. Network Policies: по умолчанию в Kubernetes весь трафик между подами разрешён — Network Policy позволяет это ограничить, что критично для prod-окружений.
Prod readiness в контексте обновлений без даунтайма — комплексная тема: rolling update + корректно настроенные probes + minReadySeconds + PodDisruptionBudget (гарантирует, что при обновлении или дренаже ноды не упадёт больше допустимого числа реплик).
Kubernetes: вопросы → что хотят услышать → как проверить руками
| Тема | Ожидаемое объяснение | Команда kubectl | Типовая ошибка кандидата |
|---|---|---|---|
| CrashLoopBackOff | Цикл рестартов из-за падения контейнера | kubectl logs pod —previous | Смотрит только текущие логи, не видит причину |
| Pending pod | Нет ресурсов / не совпадают selectors / PVC не bound | kubectl describe pod → Events | Не смотрит Events, гадает |
| DNS внутри кластера | CoreDNS + resolv.conf + NetworkPolicy | kubectl exec -it pod — nslookup svc | Не проверяет NetworkPolicy |
| Ingress не работает | Controller + аннотации + Service + порты | kubectl logs -n ingress-nginx controller | Не проверяет логи контроллера |
| Обновление без даунтайма | Rolling update + probes + PDB | kubectl rollout status deployment | Забывает про readiness probe и PDB |
| RBAC | Role/ClusterRole + least privilege | kubectl auth can-i —list —as=sa | Выдаёт ClusterAdmin «для простоты» |
Мини-чек: Junior vs Middle по Kubernetes
Junior: знает базовые объекты и их назначение, умеет дебажить CrashLoopBackOff и Pending, понимает разницу liveness/readiness.
Middle: проектирует prod-ready деплой (probes + PDB + resource limits), настраивает RBAC по принципу least privilege, понимает autoscaling и network policies, может объяснить стратегию обновления с учётом рисков.
Какие вопросы по Cloud и IaC (Terraform/OpenTofu) актуальны в 2026?
Облако и Infrastructure as Code в 2026 году — это уже не «продвинутые темы», а базовый контекст работы большинства DevOps-инженеров. Показательно, что интервьюеры здесь редко спрашивают про конкретные сервисы конкретного провайдера — гораздо чаще проверяют понимание принципов: как устроено управление доступом, как изолированы сети, как безопасно применять изменения инфраструктуры. Провайдер вторичен; мышление — первично.
База облака: IAM и сети
IAM (Identity and Access Management) — первое, о чём спрашивают в облачном блоке. Ключевой принцип, который должен звучать в любом ответе: least privilege — каждая сущность (пользователь, сервис-аккаунт, роль) получает ровно те права, которые необходимы для выполнения конкретной задачи, и не больше. Типовая ошибка, которую интервьюер ждёт как антипример: сервис-аккаунт с правами Owner или AdministratorAccess «потому что так проще». Для Middle ожидается понимание разницы между аутентификацией (кто ты) и авторизацией (что тебе можно), а также умение объяснить, как работают федеративные идентификации и workload identity в контексте Kubernetes.
Сетевая база: понимание VPC/VNet как изолированного сетевого пространства, routing между подсетями, разница между Security Group (stateful, работает на уровне экземпляра — разрешение в одну сторону автоматически открывает ответный трафик) и NACL (stateless, работает на уровне подсети — нужно явно разрешать трафик в обе стороны). Вопрос «почему трафик не проходит, хотя security group разрешает» на собеседовании часто оказывается именно про NACL или про отсутствие route в таблице маршрутизации.
IaC: state, backends и модули
Terraform/OpenTofu state — центральный концепт, который проверяют всегда. State хранит актуальное представление об инфраструктуре и является основой для вычисления diff при следующем plan. Хранить state локально в файловой системе — допустимо для экспериментов, критично для продакшна: потеря state означает потерю связи между кодом и реальными ресурсами. Правильный ответ: remote backend (S3 + DynamoDB для блокировки в AWS, GCS + блокировка в GCP, Terraform Cloud / OpenTofu-совместимые backends) с включённым state locking — чтобы два одновременных apply не привели к конфликту.
Стратегия окружений — ещё одна стандартная тема. Два подхода: workspace (один backend, изоляция через workspace name — проще, но менее изолировано) и отдельные директории/репозитории на окружение (больше дублирования, но полная изоляция state и прав). Для Middle ожидается понимание trade-offs и способность обосновать выбор.
Модули: переиспользуемые блоки конфигурации с явными inputs/outputs. Признак зрелого подхода — модуль не содержит provider-конфигурацию, версионируется отдельно и не делает предположений об окружении, в котором используется.
Как не сломать прод при apply
Это неявный, но очень частый интент на собеседовании. Сильный ответ строится из нескольких уровней защиты: terraform plan с обязательным code review изменений (особенно на destroy-операции), политики через Sentinel или OPA (запрет опасных операций без явного подтверждения), разделение прав (CI применяет только в dev/staging, прод — через отдельный процесс с апрувом), и — для критичных изменений — target-применение с минимальным скоупом. Ответ «просто делаю apply и смотрю что будет» на Middle-позиции — это тот самый красный флаг.
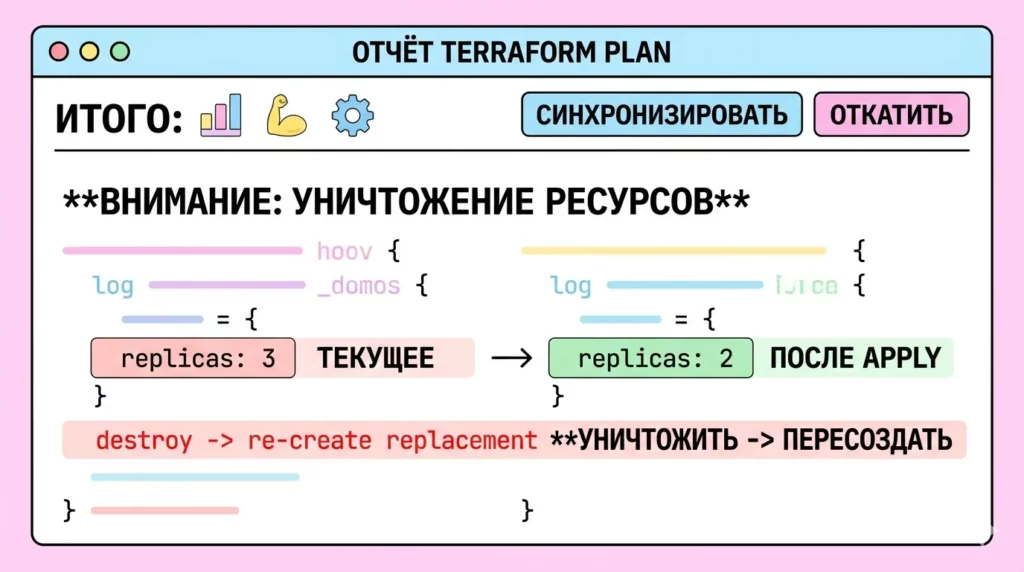
Этот скриншот визуализирует отчет terraform plan в терминале. Выделенная красная строка «ВНИМАНИЕ: УНИЧТОЖЕНИЕ РЕСУРСОВ» и красная метка replicas: 3 (ТЕКУЩЕЕ) -> метка replicas: 2 (ПОСЛЕ APPLY) с пометкой УНИЧТОЖИТЬ -> ПЕРЕСОЗДАТЬ наглядно объясняют, почему необходимо тщательно проверять результаты планирования перед применением изменений.
Terraform vs OpenTofu: как отвечать на вопрос «что выберешь в 2026?»
| Критерий | Terraform | OpenTofu | Рекомендация формулировки |
|---|---|---|---|
| Лицензия | BSL 1.1 (не OSS с 2023) | MPL 2.0 (открытая) | «Если важна открытая лицензия и независимость от вендора — OpenTofu» |
| Экосистема | Зрелая, большой registry, Enterprise-поддержка | Растущая, совместима с большинством провайдеров | «Terraform — если уже используется и нет лицензионных ограничений» |
| Совместимость | Референсная реализация | Форк, ~полная совместимость с HCL | «Миграция обычно прозрачна, но требует проверки провайдеров» |
| Процесс миграции | — | tofu CLI, совместимый state | «Миграция — это sed + проверка провайдеров, не переписывание» |
| Выбор в 2026 | Если нет лицензионных ограничений | Если open-source критичен или есть ограничения на BSL | «Осознанный выбор важнее религиозных войн» |
Мини-чек: Junior vs Middle по Cloud и IaC
Junior: понимает IAM и least privilege, знает что такое state и зачем remote backend, писал базовые Terraform-конфигурации.
Middle: проектирует стратегию окружений и модулей, настраивает state locking и политики, осознанно объясняет выбор между Terraform и OpenTofu с учётом лицензии и рисков.
Observability/SRE/Security: что отличает Middle в 2026?
Этот блок — пожалуй, самый показательный с точки зрения разницы между Junior и Middle. Junior может настроить Prometheus и Grafana, написать alert и считать это достаточным. Middle понимает, что observability — это не набор инструментов, а способность задать вопрос о системе и получить ответ, даже если вопрос возник впервые. Именно здесь проверяется зрелость инженерного мышления: умение балансировать скорость и надёжность, снижать шум алертов и улучшать MTTR (Mean Time To Recovery).
Observability: три столпа и почему корреляция важнее коллекции
Классическое разделение на метрики, логи и трейсы — не просто академическая классификация, а практический инструмент диагностики. Метрики дают агрегированную картину состояния системы во времени (latency, error rate, saturation) — хороши для алертинга и трендов, но не объясняют причину. Логи содержат детальный контекст конкретного события — незаменимы для root cause analysis, но плохо масштабируются как основной инструмент диагностики под нагрузкой. Трейсы показывают путь конкретного запроса через распределённую систему — критичны для микросервисов, где проблема в одном сервисе может проявляться как деградация в совершенно другом.
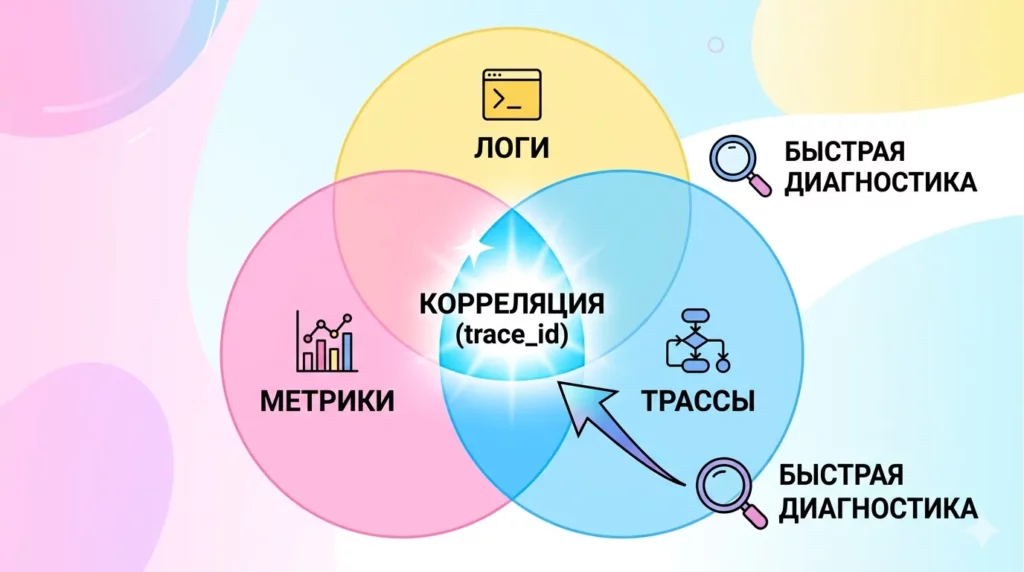
Эта иллюстрация визуализирует пересечение трех столпов наблюдаемости: Метрик, Логов и Трасс. Пересечение всех трех сигналов через общий trace_id (КОРРЕЛЯЦИЯ) позволяет инженеру превратить диагностику из искусства в процедуру.
Ключевой концепт, который проверяют на Middle-интервью: корреляция через trace_id. Когда все три сигнала связаны общим идентификатором, диагностика перестаёт быть искусством и становится процедурой.
Logs ↔ Metrics ↔ Traces ↘ ↓ ↙ общий trace_id (propagation context)
OpenTelemetry становится общим языком observability именно потому, что стандартизирует этот контекст: одна инструментация — любой бэкенд (Jaeger, Tempo, Datadog, Honeycomb). В мультиоблачных и гибридных окружениях это особенно ценно: не нужно переинструментировать приложение при смене провайдера. Вопрос «почему OTel, а не просто vendor SDK» — стандартный маркер на Middle-позиции.
SRE: SLI, SLO, error budget и как говорить про инцидент
SRE-блок на собеседовании почти всегда начинается с треугольника SLI/SLO/Error Budget — и почти всегда кандидаты путают определения или дают их без практического контекста.
SLI (Service Level Indicator) — измеримый показатель качества сервиса: доля успешных запросов, p99 latency, доступность. SLO (Service Level Objective) — целевое значение SLI: «99.9% запросов успешны за скользящие 30 дней». Error Budget — допустимый объём ненадёжности: разница между 100% и SLO. Если SLO = 99.9%, error budget = 0.1% от времени или запросов — это «лицензия на риск», которую команда может тратить на деплои и эксперименты.
Практический смысл error budget: когда он исчерпан — команда фокусируется на надёжности, а не на фичах. Это не карательный механизм, а инструмент приоритизации.
Как говорить про инцидент на собеседовании — отдельный навык. Сильный ответ строится по структуре: timeline (когда что произошло) → impact (кто и как пострадал, в измеримых единицах) → root cause vs contributing factors (первопричина отличается от факторов, которые сделали её возможной) → action items (конкретные задачи, а не «будем внимательнее»). Ответ без цифр и без action items — слабый ответ.
Supply-chain security: SBOM, подписи, provenance и SLSA
Supply-chain атаки (SolarWinds, XZ Utils) сделали эту тему обязательной для Middle в 2026 году. Базовый словарь, который ожидается на интервью:
- SBOM (Software Bill of Materials) — машиночитаемый манифест всех компонентов артефакта: зависимости, версии, лицензии. Позволяет быстро ответить на вопрос «есть ли у нас Log4Shell» без ручного аудита каждого репозитория.
- Подписи артефактов — криптографическое доказательство того, что образ или бинарник не был изменён после публикации. Инструмент: cosign (проект Sigstore). Внедряется на этапе CI после сборки и проверяется при деплое или в admission controller.
- Provenance — attestation о том, кто, когда, из какого коммита и в какой среде собрал артефакт. Отвечает на вопрос «этот образ действительно собран нашим CI, а не подменён».
- SLSA (Supply-chain Levels for Software Artifacts) — фреймворк уровней зрелости (1–4), описывающий, какие гарантии даёт процесс сборки. Уровень 1: базовое логирование сборки. Уровень 2: подписанный provenance от CI. Уровень 3: изолированная среда сборки. Уровень 4: двусторонняя верификация. На практике большинство команд в 2026 году находятся на уровне 1–2 и движутся к 3 — и честный ответ об этом лучше, чем декларация о «полном соответствии SLSA 4».
SLO/SLI/Error Budget: мини-словарь с примерами
| Термин | Определение | Пример для API | Как используют на практике |
|---|---|---|---|
| SLI | Измеримый показатель качества | Доля запросов с кодом 2xx за 5 минут | Собирается через метрики, является основой SLO |
| SLO | Целевое значение SLI | 99.9% успешных запросов за 30 дней | Согласуется с бизнесом, фиксируется в runbook |
| Error Budget | Допустимый объём ненадёжности | 0.1% × 30 дней ≈ 43 минуты даунтайма | Тратится на деплои; при исчерпании — freeze фич |
| MTTR | Среднее время восстановления | Время от алерта до восстановления SLO | Метрика зрелости incident response |
| Burn Rate | Скорость расхода error budget | 2x burn rate = бюджет кончится вдвое быстрее | Используется для многоуровневого алертинга |
Supply-chain security: минимум в 2026
| Контроль | Инструментальный пример | Где внедряется | Какой риск снимает |
|---|---|---|---|
| SBOM | syft image:tag -o spdx-json | CI после сборки, registry | Быстрый аудит уязвимых зависимостей |
| Подпись артефакта | cosign sign image:tag | CI после push в registry | Подмена образа в registry или при доставке |
| Provenance | SLSA provenance via GitHub Actions / Tekton | CI, registry | Сборка из неавторизованного источника |
| Политика деплоя | OPA/Gatekeeper: требовать подпись | Kubernetes admission controller | Деплой неподписанного или неизвестного образа |
| Сканирование CVE | trivy image:tag в CI | CI (блокирует при critical), registry | Известные уязвимости в зависимостях |
Мини-чек: Junior vs Middle по Observability/SRE/Security
Junior: знает разницу метрики/логи/трейсы, слышал про SLO, понимает зачем сканировать образы на CVE.
Middle: выстраивает корреляцию сигналов через trace_id, формулирует SLO с error budget, рассказывает про инцидент по структуре timeline/impact/root cause/actions, понимает supply-chain риски и может описать минимальный набор контролей для prod-окружения.
Как упаковать опыт: портфолио, кейсы и чек-лист подготовки
Техническое собеседование DevOps — это не экзамен на знание команд, а разговор об опыте решения реальных проблем. Именно поэтому финальный этап подготовки — не повторение теории, а упаковка того, что уже есть, в форму, понятную интервьюеру. Три мини-кейса, оформленных по структуре «проблема → диагностика → решение → результат», дают больше, чем идеальные ответы на все теоретические вопросы.
Как упаковать опыт в кейсы
Четыре темы, которые стоит подготовить как истории: пайплайн («я спроектировал CI/CD, который сократил время релиза с N часов до M минут и добавил security-сканирование»), Kubernetes-дебаг («сервис падал в прод каждые несколько часов — оказалось, liveness probe была настроена агрессивнее, чем GC приложения»), IaC («перевёл инфраструктуру на Terraform с нуля — выстроил remote state, разделил окружения, добавил обязательный plan-review через PR»), инцидент («в 3 ночи упал платёжный сервис — через 12 минут восстановили, через 2 дня закрыли root cause и написали постмортем»). Каждая история должна содержать цифры и личный вклад — не «мы делали», а «я сделал, потому что».
Что показать в портфолио
Минимально убедительное портфолио для DevOps в 2026 году: репозиторий с IaC (Terraform/OpenTofu) или Helm-чартами с понятной структурой и README, который объясняет, как поднять стенд с нуля. Плюс — хотя бы один runbook: документ, описывающий, как диагностировать и устранять типовую проблему. Runbook показывает, что инженер думает не только о том, как построить систему, но и о том, как её эксплуатировать. Для Middle — добавить постмортем (анонимизированный) или ADR (Architecture Decision Record) с обоснованием технического выбора.
Подготовка за 7 дней: Junior
- Повторить 10–15 команд Linux/сети и пройти сквозной сценарий «сервис недоступен».
- Настроить один рабочий CI-пайплайн (GitHub Actions / GitLab CI) с build + test + lint.
- Задеплоить приложение в Kubernetes (Minikube/Kind), разобрать CrashLoopBackOff руками.
- Подготовить один мини-кейс «как я дебажил проблему» по структуре проблема/диагностика/решение.
- Прочитать про SLO и error budget — уметь объяснить концепцию своими словами.
Подготовка за 10 дней: Middle
- GitOps: объяснить drift и reconciliation, сравнить Argo CD и Flux на уровне концепций.
- IaC: проверить понимание remote state / backends / locking, подготовить ответ про стратегию окружений.
- Terraform vs OpenTofu: сформулировать осознанный ответ с учётом лицензии и рисков миграции.
- SLO + инцидент: подготовить одну постмортем-историю по шаблону timeline/impact/root cause/actions.
- Observability: объяснить роль OTel, корреляцию через trace_id, как снизить alert noise.
- Supply-chain: уметь объяснить SBOM, cosign и SLSA уровни без заучивания — через смысл контролей.
- Оформить портфолио: README + IaC/Helm + хотя бы один runbook.
Собеседование DevOps — это всегда разговор о том, как вы думаете под давлением неопределённости. Инструменты меняются каждые два года; инженерное мышление, системный подход к диагностике и честность в оценке рисков — остаются. Именно это и стоит демонстрировать.
Если вы только начинаете осваивать профессию девопса, рекомендуем обратить внимание на курсы по DevOps, которые предлагают как теоретическую, так и практическую часть. Это поможет вам быстрее освоить все нужные инструменты и подходы.
Рекомендуем посмотреть курсы по обучению DevOps
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
112 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 марта
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
DevOps-инженер
|
Нетология
46 отзывов
|
Цена
101 800 ₽
226 321 ₽
с промокодом kursy-online
|
От
3 143 ₽/мес
Без переплат на 2 года.
4 861 ₽/мес
|
Длительность
16 месяцев
|
Старт
15 марта
|
Подробнее |
|
Профессия DevOps-инженер
|
Skillbox
226 отзывов
|
Цена
161 751 ₽
323 502 ₽
Ещё -20% по промокоду
|
От
4 757 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
4 месяца
|
Старт
15 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
100 отзывов
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Профессия DevOps-инженер PRO
|
Skillbox
226 отзывов
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца с отсрочкой платежа 3 месяца.
|
Длительность
6 месяцев
|
Старт
15 марта
|
Подробнее |

Skypro vs ProductStar: куда идти аналитику, чтобы стать продактом — траектория и кейсы
Если вы аналитик и хотите перейти в продакт-менеджмент, но не знаете, с чего начать, эта статья для вас. Мы расскажем, какие шаги и курсы помогут вам освоить нужные навыки, чтобы успешно перейти в продуктовую роль. Задайтесь вопросом: готовы ли вы на решение проблем, а не просто на анализ данных?

Собеседование по Python: частые вопросы и как на них отвечать
Готовитесь к техническому интервью и хотите понять, какие вопросы на собеседование Python разработчик слышит чаще всего? Разбираем реальные примеры задач, вопросы для junior, middle и senior, а также типичные ошибки кандидатов и стратегию подготовки.

Skypro vs Contented: Web/UX дизайн — где сильнее разборы работ и быстрее растёт качество
В этой статье мы расскажем, как выбрать лучший курс по веб-дизайну. Если вы только начинаете изучать эту профессию, то вам наверняка будет полезно узнать, что важно учитывать при выборе курса и какие именно аспекты обучения могут ускорить ваш профессиональный рост. Откроем основные моменты, которые помогут вам сделать правильный выбор и избежать распространенных ошибок.

Skypro vs Bang Bang Education: где дизайнера лучше прокачивают «думать руками»
Выбираете курсы дизайна и пытаетесь понять, где действительно учат работать с реальными задачами? В этом материале разбираем, как сравнивать программы обучения, на что смотреть в практике, ревью и портфолио, и какие критерии помогут выбрать курс осознанно.