Собеседование по Python: частые вопросы и как на них отвечать

Эта статья — практический гайд для тех, кто готовится к техническому интервью на Python-разработчика. Мы разберём типовые вопросы по Core, ООП и алгоритмам, дадим шаблоны структурных ответов, стратегию лайвкода и честно покажем, чего ждут от junior, middle и senior. Никаких гарантий трудоустройства — только рабочие инструменты.
- Как пройти Python-интервью: какие этапы будут, что ждут по уровням и где чаще всего «сыпятся»?
- Какие вопросы по Python Core задают чаще всего и как отвечать структурно?
- Какие вопросы по ООП и дизайну в Python задают и как отвечать без теории ради теории?
- Как решать алгоритмические задачи и лайвкод по Python так, чтобы интервьюер вам «помогал»?
- Big-O и выбор структуры данных: как объяснять решение за 30–60 секунд
- Что спрашивают про инженерную практику: тесты, качество кода, отладка и производительность?
- Какие поведенческие вопросы задают и как отвечать уверенно (включая «я не знаю»)?
- STAR-ответы: конфликт, ошибка, провал, ответственность (готовые каркасы)
- Рекомендуем посмотреть курсы по Python
Как пройти Python-интервью: какие этапы будут, что ждут по уровням и где чаще всего «сыпятся»?
Прежде чем готовиться к конкретным вопросам, полезно понять, как устроен сам процесс. Большинство кандидатов проваливают интервью не потому, что не знают Python, — а потому что не понимают, что именно и на каком этапе от них ожидают. Давайте разберём структуру типового найма и то, как она влияет на подготовку.
Пайплайн выглядит примерно так:
HR-скрининг → технический скрин → техническое интервью → лайвкод или домашнее задание → финальный раунд.
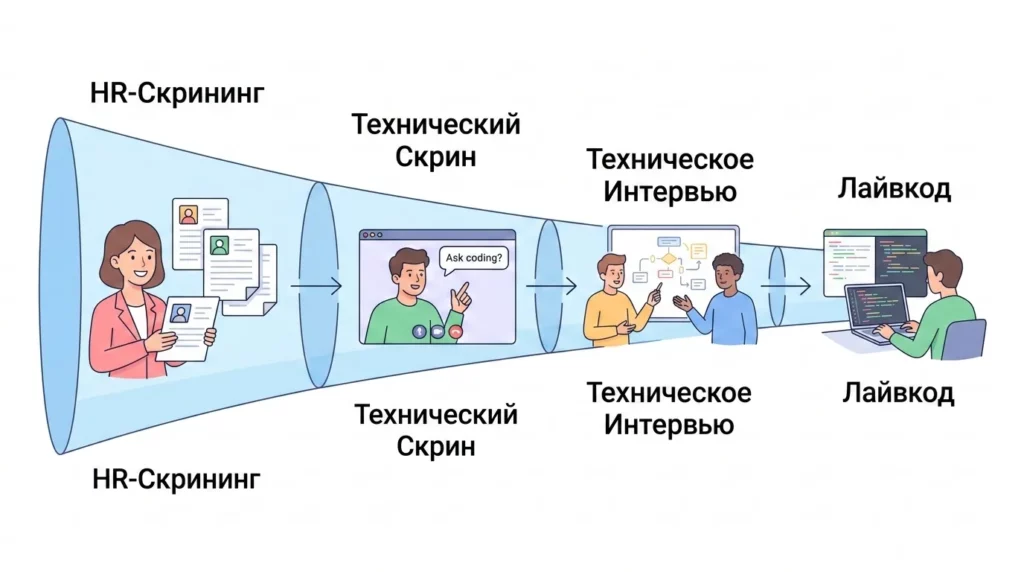
Схема наглядно показывает путь кандидата от первого контакта до заветного оффера. На каждом этапе воронка сужается, отсеивая соискателей по разным критериям: soft skills, знание базы, инженерное мышление и культурное соответствие.
На каждом этапе проверяется что-то своё, и провалиться можно на любом — даже на том, где, казалось бы, «нет ничего сложного».
Важно учитывать контекст роли: backend-разработчик, data engineer и automation QA — это три разных профиля, и вопросы будут отличаться. Backend сфокусируется на архитектуре и API, data — на pandas/numpy и работе с данными, QA — на pytest и интеграционном тестировании. Структура пайплайна при этом похожа, но акценты смещаются.
Какие этапы интервью бывают и что на каждом проверяют?
- HR-скрининг (15–30 минут). Цель — убедиться, что кандидат адекватен, мотивирован и примерно соответствует грейду. Проверяют: зарплатные ожидания, причину смены работы, общий опыт. Типичная ситуация: кандидат описывает стек из резюме, но не может объяснить, зачем использовал конкретный инструмент. Этого достаточно, чтобы не пустить дальше.
- Технический скрин (30–45 минут). Обычно проводит техлид или старший разработчик. Задача — проверить базу: типы данных, функции, основы ООП, иногда пару простых задач на логику. Критерии оценки: знает ли кандидат базовые концепции, умеет ли объяснять, не паникует ли при первом же уточняющем вопросе.
- Техническое интервью (45–90 минут). Здесь глубже: архитектурные вопросы, обсуждение прошлых проектов, работа с базами данных, тесты, обработка ошибок. Проверяют инженерное мышление, а не только знание синтаксиса. Типичный вопрос: «Расскажи о самом сложном баге, который ты дебажил».
- Лайвкод или домашнее задание. Лайвкод — это задача в реальном времени (CoderPad, Google Docs, доска). Домашка — более объёмная, с проверкой архитектуры и тестов. Критерии: читаемость кода, коммуникация процесса, тест-кейсы, обработка краевых случаев.
- Финальный раунд. Как правило, включает поведенческие вопросы, обсуждение культуры команды, иногда — задачу на системный дизайн. Для senior-позиций здесь часто оценивают лидерство и принятие решений в условиях неопределённости.
| Этап | Что проверяют | Типичный вопрос / ситуация |
|---|---|---|
| HR-скрининг | Мотивация, опыт, адекватность | «Почему хотите уйти с текущего места?» |
| Технический скрин | База Python, умение объяснять | «Чем list отличается от tuple?» |
| Техническое интервью | Глубина опыта, инженерное мышление | «Как вы организуете обработку ошибок в проекте?» |
| Лайвкод | Процесс мышления, коммуникация | Задача на строки / словарь в реальном времени |
| Домашнее задание | Архитектура, тесты, читаемость | Мини-сервис с API и покрытием тестами |
| Финал | Поведение, культура, лидерство | «Опишите конфликт с коллегой и как вы его решили» |
Что должен показать junior/middle/senior: глубина, примеры, самостоятельность
Одна из самых частых ошибок — кандидат не понимает, на какой грейд его оценивают, и либо отвечает слишком поверхностно (теряя очки), либо пытается казаться опытнее, чем есть (и «сыпется» на уточняющих вопросах). Вот рабочая карта ожиданий.
- Junior. От junior ждут честности и базы — не энциклопедических знаний. Вы должны уверенно объяснить ключевые типы данных, написать простую функцию без синтаксических ошибок и внятно описать учебный или пет-проект. Обучаемость важнее готовых ответов. Пример сильной формулировки: «Я не работал с asyncio в продакшене, но читал документацию и написал небольшой пример — могу рассказать, что понял». Пример слабой: «Я это не проходил» — и тишина.
- Middle. Здесь ждут уверенной практики: вы умеете писать тесты, понимаете архитектурные компромиссы, можете объяснить, почему выбрали одно решение над другим. От middle ожидают ответственности за код — не «я сделал, как сказали», а «я предложил этот подход, потому что…». Пример: «Мы использовали композицию вместо наследования, потому что поведение объектов менялось в зависимости от контекста — это упростило тесты».
- Senior. Senior оценивают иначе: не только что он знает, но и как рассуждает о системе в целом. Важны дизайн, риски, масштабирование и умение объяснить техническое решение нетехническому коллеге. Плюс — лидерство: как вы онбордите новых разработчиков, как ведёте код-ревью, как принимаете решения при конфликте требований.
Николай Хиврин, CEO ALT-WEB: «Для Senior-позиций важнее всего умение обосновывать «цену решения» (Trade-offs). Знание того, как работает словарь — база, знание того, когда его не стоит использовать из-за потребления памяти — уровень инженера.»
| Уровень | Что должны показать | Ключевой сигнал для интервьюера |
|---|---|---|
| Junior | Базовый синтаксис, честность, обучаемость | «Не знаю, но вот что я думаю / проверю» |
| Middle | Практика, тесты, архитектурные компромиссы | «Я выбрал это решение, потому что…» |
| Senior | Дизайн, риски, коммуникация, лидерство | «Вот компромисс, который мы приняли и почему» |
Топ ошибок кандидатов и как их избежать (с примерами формулировок)
Практика показывает: большинство провалов на техническом интервью — не из-за незнания Python, а из-за предсказуемых поведенческих паттернов. Разберём семь самых частых.
- Молчание на лайвкоде. Кандидат видит задачу, уходит «в себя» и молчит три минуты. Интервьюер теряет контакт и не понимает, думает ли кандидат или просто не знает. Замена: проговаривайте вслух — «Ок, смотрю на входные данные, сначала проверю крайний случай с пустым списком».
- Попытка угадать «правильный» ответ. Вместо того чтобы рассуждать, кандидат пытается угадать, что хочет услышать интервьюер. Это считывается мгновенно. Замена: говорите, что вы думаете на самом деле, и объясняйте логику.
- Путаница в мутабельности. Классика: кандидат знает, что список мутабельный, но не может объяснить, почему это проблема в аргументах по умолчанию. Замена: готовьте не определения, а примеры с поведением.
- Отсутствие примеров. Ответ «декоратор — это функция, которая принимает функцию» формально верен, но не показывает понимания. Замена: всегда добавляйте «например, мы используем это для логирования времени выполнения».
- «Я не знаю» как финал. Признать незнание — нормально. Но останавливаться на этом — нет. Замена: «Я не уверен в деталях, но логика подсказывает мне вот что — давайте проверим гипотезу».
- Избыточная теория без практики. Кандидат цитирует определения SOLID, но не может привести ни одного живого примера из своего кода. Замена: готовьте 1–2 конкретных кейса из реальных или учебных проектов.
- Игнорирование крайних случаев. На лайвкоде написан код, который работает на примере из условия, но падает на пустом вводе или отрицательных числах. Замена: после написания кода всегда проговаривайте: «Теперь проверю крайние случаи».
Чек-лист подготовки за 7 дней
- День 1–2: повторить типы данных, мутабельность, функции (LEGB, замыкания).
- День 3: ООП — классы, наследование, dunder-методы.
- День 4: алгоритмы — Big-O, dict/set/list, 3–4 паттерна задач.
- День 5: тесты (pytest), качество кода (PEP8, mypy), отладка.
- День 6: поведенческие вопросы — подготовить 3–4 STAR-истории.
- День 7: mock-интервью вслух (с другом или записью себя), вопросы работодателю.
Какие вопросы по Python Core задают чаще всего и как отвечать структурно?
Python Core — это фундамент, на котором строится всё остальное. Именно здесь интервьюер отделяет тех, кто «писал на Python», от тех, кто понимает, как язык устроен изнутри. Хорошая новость: большинство вопросов предсказуемы. Плохая: поверхностный ответ виден сразу.
Прежде чем разбирать конкретные темы, введём универсальный шаблон, который работает для любого технического вопроса:
┌─────────────────────────────────────────────────────┐ │ ШАБЛОН СИЛЬНОГО ОТВЕТА НА ТЕХВОПРОС │ ├─────────────────────────────────────────────────────┤ │ 1. ОПРЕДЕЛЕНИЕ → простыми словами, без жаргона │ │ 2. ПРИМЕР → короткий код или сценарий │ │ 3. ЛОВУШКА → крайний случай / типичная ошибка│ │ 4. ПРИМЕНЕНИЕ → когда и зачем это использовать │ └─────────────────────────────────────────────────────┘
Интервьюер почти никогда не проверяет умение воспроизвести определение из документации. Он проверяет, понимаете ли вы причины — почему язык ведёт себя именно так и как это влияет на код в реальных условиях. Держите этот шаблон в голове на протяжении всего интервью.
Типы данных и мутабельность: list/tuple/set/dict и «ловушки» на примерах
Вопросы про типы данных — это не «разминка». Это проверка того, понимаете ли вы, как Python управляет памятью и почему некоторые решения приводят к неочевидным багам.
Базовые различия. list — упорядоченная мутабельная последовательность, обращение по индексу за O(1), вставка в конец амортизированно O(1), поиск элемента — O(n). tuple — неизменяемая последовательность, чуть быстрее и легче list, используется там, где данные не должны меняться: координаты, возвращаемые значения функций, ключи словаря. set — неупорядоченное множество уникальных элементов, проверка вхождения за O(1) — именно поэтому x in my_set на больших данных несопоставимо быстрее x in my_list. dict — отображение ключ→значение, с Python 3.7 сохраняет порядок вставки, доступ по ключу за O(1).
Как объяснять это на интервью? Не перечислять свойства, а отвечать на вопрос «когда что выбрать»: «Если мне нужна быстрая проверка принадлежности — беру set. Если нужен порядок и доступ по индексу — list. Если данные не должны меняться и будут ключом словаря — tuple».
Мутабельность и классические ловушки
Здесь кандидаты сыпятся чаще всего. Разберём два сценария.
Ловушка 1 — изменяемый аргумент по умолчанию:
def append_to(element, target=[]): target.append(element) return target print(append_to(1)) # [1] print(append_to(2)) # [1, 2] -- неожиданно?
Проблема в том, что значение по умолчанию вычисляется один раз — при определении функции, а не при каждом вызове. Список [] создаётся единожды и живёт между вызовами. Правильное решение — использовать None как значение по умолчанию и создавать список внутри функции.
Ловушка 2 — мутабельный объект внутри функции:
def modify(lst): lst.append(99) my_list = [1, 2, 3] modify(my_list) print(my_list) # [1, 2, 3, 99]
Python передаёт не копию, а ссылку на объект. Если вы мутируете объект внутри функции — изменение видно снаружи. Это не баг языка, это его намеренное поведение — но именно здесь и возникают неожиданные side effects в реальном коде.
Мини-Q&A по типам данных:
- Можно ли использовать list как ключ словаря? Нет — list мутабельный и не хэшируемый. Ключом может быть только hashable-объект: строка, число, tuple (если все его элементы тоже hashable).
- Чем dict.get(key) отличается от dict[key]? dict[key] бросает KeyError, если ключа нет. dict.get(key) возвращает None (или указанное значение по умолчанию) — это безопаснее в большинстве сценариев.
- Когда set лучше list? Когда нужна быстрая проверка вхождения или дедупликация. x in set работает за O(1), x in list — за O(n).
- Tuple неизменяем, но я могу сделать tuple из списков — они изменятся? Да. Неизменяемость tuple означает, что нельзя заменить сам элемент, но если элемент — мутабельный объект (список), его содержимое изменить можно. Это тонкость, которую стоит упомянуть.
Функции и «магия» Python: LEGB, замыкания, декораторы, генераторы
Эта тема — один из надёжных индикаторов глубины понимания языка. Junior знает, что функция принимает аргументы и возвращает значение. Middle понимает, как Python ищет имена и почему функции — объекты первого класса.
LEGB и замыкания. LEGB — это порядок, в котором Python ищет имя переменной: Local → Enclosing → Global → Built-in. Звучит просто, но именно здесь возникают неочевидные ошибки.
x = 10 def outer(): x = 20 def inner(): print(x) # выведет 20 -- берётся из Enclosing inner()
Замыкание — это функция, которая «запоминает» переменные из объемлющей области видимости, даже после того как внешняя функция завершила работу. Классический пример использования — фабрики функций:
def make_multiplier(n): def multiplier(x): return x * n # n «захвачена» из enclosing scope return multiplier double = make_multiplier(2) print(double(5)) # 10
На интервью часто спрашивают: «Что такое замыкание и зачем оно нужно?» Слабый ответ — пересказ определения. Сильный ответ — объяснение через пример и указание на практическое применение: параметризация поведения, частичное применение функций, декораторы.
Декораторы. Декоратор — это функция, которая принимает другую функцию и возвращает новую с расширенным поведением. Под капотом — просто синтаксический сахар:
@my_decorator def func(): pass # эквивалентно: func = my_decorator(func)
Типичные сценарии применения: логирование времени выполнения, проверка прав доступа, кэширование результатов (functools.lru_cache — готовый пример из стандартной библиотеки), валидация входных данных. На интервью стоит упомянуть functools.wraps — без него декоратор «перетирает» метаданные оригинальной функции (__name__, __doc__), что ломает интроспекцию и документацию.
Генераторы и итераторы. Генератор — функция с yield вместо return. Каждый раз, когда вы запрашиваете следующее значение, выполнение продолжается с места, где остановился yield. Главное преимущество — ленивые вычисления: данные генерируются по одному, не загружая всё в память сразу.
def read_large_file(path): with open(path) as f: for line in f: yield line.strip()
Это не просто «элегантный код» — это принципиальная разница при работе с большими объёмами данных. Если вы загружаете файл на 10 ГБ через readlines(), вы кладёте всё в память. Если через генератор — обрабатываете построчно.
На интервью yield — это сигнал намерения: «я осознанно откладываю вычисление и забочусь о памяти». Упоминание этого сразу поднимает ответ на уровень выше.
Исключения и контекст: try/except и with (как объяснять и где применять)
Обработка ошибок — это не техническая деталь, а инженерная позиция. То, как кандидат рассказывает про исключения, показывает, думает ли он о надёжности кода или просто «делает чтобы работало».
Анатомия try/except. Полная конструкция выглядит так:
try: result = do_something() except ValueError as e: handle_value_error(e) except (TypeError, KeyError): handle_type_or_key() else: process(result) # выполняется, если исключений не было finally: cleanup() # выполняется всегда
Блок else — часто забытый, но полезный: он явно отделяет «код, который выполняется при успехе» от обработки ошибок. finally — гарантированное завершение: освобождение ресурсов, закрытие соединений, логирование.
На интервью важно знать: когда ловить исключения. Правило простое — ловите то, с чем умеете работать. except Exception на весь модуль — почти всегда антипаттерн, потому что вы глушите ошибки, о которых даже не подозреваете.
Собственные исключения
Когда они уместны? Когда стандартные исключения недостаточно выразительны для вашего домена:
class InsufficientFundsError(ValueError):
def __init__(self, amount, balance):
self.amount = amount
self.balance = balance
super().__init__(f"Нельзя списать {amount}, доступно {balance}")
Наследование от встроенных исключений (а не от Exception напрямую) — хорошая практика: это сохраняет совместимость с чужим кодом, который ловит ValueError.
Контекстные менеджеры и with. with — это управление ресурсами через протокол контекстного менеджера (__enter__ / __exit__). Главная ценность: ресурс гарантированно освобождается, даже если внутри блока возникло исключение.
with open("data.txt") as f:
content = f.read()
# файл закрыт здесь, независимо от того, было ли исключение
Применяется не только для файлов: соединения с базой данных, сетевые сокеты, блокировки в многопоточном коде (threading.Lock), транзакции. Для собственных контекстных менеджеров можно использовать contextlib.contextmanager — это проще, чем реализовывать класс с __enter__/__exit__.
Типичные ошибки, которые видит интервьюер:
- except Exception: pass — исключение поглощается без следа, баг становится невидимым.
- Ловля слишком широких исключений там, где нужна конкретика.
- Ресурсы открываются без with — утечка при исключении.
- finally используется для логики, а не для очистки.
Сводная таблица: Python Core
| Вопрос | Что хотят услышать | Частая ошибка |
|---|---|---|
| Чем list отличается от tuple? | Мутабельность, производительность, hashability | Только «tuple неизменяем» без объяснения последствий |
| Что такое замыкание? | Захват переменных из enclosing scope + пример | Определение без примера |
| Зачем нужен декоратор? | Расширение поведения без изменения функции + functools.wraps | «Это как обёртка» — и всё |
| Когда использовать генератор? | Ленивые вычисления, экономия памяти, большие данные | «Когда нужен yield» — без объяснения зачем |
| Что плохого в except Exception: pass? | Глушит ошибки, делает отладку невозможной | «Ну это просто игнорирует ошибку» |
| Зачем with? | Гарантированное освобождение ресурса при любом исходе | «Это удобнее, чем try/finally» — без понимания механизма |
Какие вопросы по ООП и дизайну в Python задают и как отвечать без теории ради теории?
ООП на интервью — это не экзамен по определениям. Никто не ждёт, что вы процитируете учебник про инкапсуляцию и полиморфизм. Ждут другого: что вы умеете проектировать ответственность, принимать обоснованные решения и писать код, который можно поддерживать через полгода — другим человеком, в другом контексте. Это принципиально другой разговор.
Слабый ответ на вопрос «что такое наследование?» звучит как определение из Википедии. Сильный ответ начинается с «мы использовали наследование вот здесь, но потом переписали на композицию, потому что…» — и дальше идёт живая инженерная история. Именно такие ответы запоминаются.
Классы и методы: instance/class/static, dataclass как «инженерный ответ»
Три типа методов — когда какой выбирать.
Это один из самых частых вопросов на техническом интервью, и провал здесь почти всегда один и тот же: кандидат знает синтаксис, но не может объяснить логику выбора.
instance-метод — стандартный, принимает self, работает с состоянием конкретного объекта. Выбирайте его по умолчанию, когда метод зависит от данных экземпляра.
classmethod — принимает cls, работает с классом как таким. Типичное применение — альтернативные конструкторы:
class User: def __init__(self, name, email): self.name = name self.email = email @classmethod def from_dict(cls, data: dict): return cls(data["name"], data["email"])
Это не просто «другой способ создать объект» — это явный сигнал намерения: вот публичный интерфейс для создания из словаря, например из JSON-ответа API.
staticmethod — не принимает ни self, ни cls. Это обычная функция, логически связанная с классом, но не зависящая от его состояния. Пример: утилитарный метод валидации формата email внутри класса User. Если метод не использует ни экземпляр, ни класс — staticmethod делает это явным.
На интервью формулируйте выбор через вопрос: «Нужен ли этому методу доступ к состоянию объекта или класса? Если нет — static. Если к классу — classmethod. Если к экземпляру — instance».
dataclass как инженерный ответ. dataclass — это не просто синтаксический сахар. Это декларативный способ сказать: «этот класс — контейнер данных, а не объект с поведением». Python автоматически генерирует __init__, __repr__, __eq__ и при необходимости __hash__.
from dataclasses import dataclass, field @dataclass class Point: x: float y: float tags: list = field(default_factory=list) # правильно # tags: list = [] # неправильно -- мутабельный дефолт
Обратите внимание: field(default_factory=list) — это именно та ловушка с мутабельными аргументами по умолчанию, о которой мы говорили в разделе Core. dataclass заставляет вас решать эту проблему явно.
Когда стоит осторожничать с dataclass: если объект сложный, имеет нетривиальную логику инициализации или требует валидации — лучше явный __init__. dataclass отлично работает для DTO (Data Transfer Objects), конфигурационных объектов, результатов парсинга.
Мини-Q&A:
— В чём разница между __init__ и __new__? __new__ создаёт экземпляр, __init__ его инициализирует. В большинстве случаев вам нужен только __init__. __new__ переопределяют при создании иммутабельных типов или метаклассов — это продвинутая тема, и честное «обычно не нужен» — хороший ответ.
— Можно ли вызвать classmethod из экземпляра? Да, Python перенаправит вызов правильно. Но семантически правильнее вызывать через класс — это делает намерение очевидным.
Наследование vs композиция + dunder-методы: что реально важно на интервью
Наследование vs композиция — это не выбор синтаксиса, это выбор архитектуры.
Классический вопрос на интервью звучит как «когда вы используете наследование, а когда композицию?» — и большинство кандидатов отвечают теорией. Работающий ответ строится на примере.
Наследование оправдано, когда существует настоящее отношение «является»: Dog является Animal, AdminUser является User. Нарушение: наследоваться ради доступа к методу — это антипаттерн. Если вы пишете class EmailSender(DatabaseConnection) только потому, что хотите использовать метод соединения — это ломает инварианты и создаёт неочевидные зависимости.
Композиция предпочтительна, когда поведение может меняться или комбинироваться:
class ReportGenerator: def __init__(self, formatter, exporter): self.formatter = formatter self.exporter = exporter def generate(self, data): formatted = self.formatter.format(data) self.exporter.export(formatted)
Здесь ReportGenerator не знает о конкретных реализациях форматтера и экспортёра — их можно менять и комбинировать без изменения основного класса. Это упрощает тесты (легко подменить заглушкой) и расширение (новый формат — новый класс, а не изменение существующего).
| Ситуация | Наследование | Композиция |
|---|---|---|
| Отношение «является» (is-a) | ✓ | — |
| Поведение меняется в runtime | — | ✓ |
| Нужно комбинировать несколько поведений | — | ✓ |
| Общий интерфейс для группы классов | ✓ (ABC) | — |
| Хочу переиспользовать метод | — | ✓ (не наследовать ради этого) |
Dunder-методы: что важно знать. dunder (double underscore) — это протокол Python. Переопределяя их, вы встраиваете свои объекты в стандартные механизмы языка.
- __repr__ vs __str__: __repr__ — для разработчика, должен быть однозначным (идеально — воспроизводимым: Point(x=1.0, y=2.0)). __str__ — для пользователя, человекочитаемый. Если определён только __repr__ — str() использует его. Обратное неверно.
- __eq__ и __hash__: если вы переопределяете __eq__, Python автоматически устанавливает __hash__ в None, делая объект нехэшируемым. Если хотите использовать объект в set или как ключ словаря — нужно явно определить и __hash__. Это частая ловушка на интервью.
- __len__, __getitem__, __contains__ — протокол последовательности. Реализовав их, вы получаете поддержку len(), обращения по индексу и оператора in без наследования от встроенных типов. Именно так работает «утиная типизация» в Python.
SOLID/паттерны без фанатизма: как показать мышление, а не словарь терминов
Здесь кандидаты делятся на три группы: те, кто не знает SOLID вообще, те, кто знает все пять принципов наизусть, но не может привести пример из своего кода, и те — немногочисленные — кто понимает, зачем это нужно и где это реально помогает. Интервьюер хочет видеть третью группу.
SOLID: два-три принципа, которые реально объяснить
Не нужно выучивать все пять как мантру. Достаточно уверенно говорить о тех, которые вы действительно применяли.
- Single Responsibility: класс делает одно дело и имеет одну причину для изменения. Практический тест: если вы не можете назвать класс одним существительным без союза «и» — он, скорее всего, нарушает SRP. UserAuthenticatorAndEmailSender — тревожный сигнал.
- Open/Closed: код открыт для расширения, закрыт для изменения. На практике это значит: добавляя новое поведение, вы создаёте новый класс, а не правите существующий. Паттерн Strategy — прямая реализация этого принципа.
- Dependency Inversion: зависеть от абстракций, а не от конкретных реализаций. На интервью это часто звучит как «я передаю зависимости через конструктор, а не создаю их внутри» — это делает код тестируемым.

Визуализация Принципа Единственной Ответственности. Слева показан один «раздутый» класс с запутанными связями, а справа — его рефакторинг в три чистых, разделенных компонента, каждый из которых отвечает только за одну задачу.
Паттерны с живыми примерами.
- Strategy — инкапсулирует алгоритм и делает его заменяемым. Пример: система скидок, где алгоритм расчёта передаётся снаружи, а не зашит в класс заказа. Результат — новый тип скидки добавляется без изменения Order.
- Factory — создание объектов через фабричный метод или класс. Пример: парсер документов, где ParserFactory.get_parser(«pdf») возвращает нужный объект. Клиентский код не знает о конкретных классах — только об интерфейсе.
- Adapter — обёртка, которая приводит интерфейс одного класса к ожидаемому другим. Типичный сценарий: интеграция со сторонней библиотекой, чей интерфейс не совпадает с вашим доменным.
Как говорить о компромиссах? Интервьюер оценивает не знание паттернов, а зрелость суждений. Хорошая формулировка звучит так: «Мы рассматривали Strategy, но в итоге не стали усложнять — вариантов поведения было всего два, и простой if был понятнее. YAGNI победил». Умение сказать «мы намеренно не стали применять паттерн» — признак зрелого инженера, а не незнания.
Как решать алгоритмические задачи и лайвкод по Python так, чтобы интервьюер вам «помогал»?
Лайвкод — самый стрессовый этап для большинства кандидатов. И главное заблуждение здесь: что интервьюер оценивает правильность финального решения. На самом деле он оценивает процесс — как вы думаете, как общаетесь, как реагируете на неопределённость. Идеальный код, написанный в тишине за три минуты, производит меньше впечатления, чем живой разговор с промежуточными гипотезами и проверкой крайних случаев.
Прежде чем разбирать конкретные паттерны, введём алгоритм работы на лайвкоде — он применим к любой задаче:
┌──────────────────────────────────────────────────────────────┐ │ АЛГОРИТМ ЛАЙВКОДА │ ├──────────────────────────────────────────────────────────────┤ │ 1. УТОЧНИТЬ → ограничения, формат входных данных, │ │ допустимые крайние случаи │ │ 2. ПРИМЕРЫ → разобрать 1–2 примера вслух │ │ 3. ПЛАН → назвать подход до написания кода │ │ 4. КОД → писать, комментируя намерения │ │ 5. ТЕСТЫ → проверить крайние случаи вслух │ │ 6. УЛУЧШЕНИЯ → назвать, что можно оптимизировать и как │ └──────────────────────────────────────────────────────────────┘
Этот порядок — не формальность. Он защищает вас от того, чтобы написать полное решение не той задачи, и даёт интервьюеру возможность направить вас, если вы идёте не туда.
Big-O и выбор структуры данных: как объяснять решение за 30–60 секунд
Big-O на интервью — это не математика. Это инструмент коммуникации: способ быстро и точно объяснить, как ваше решение ведёт себя при росте данных. Никто не ждёт строгого доказательства — ждут уверенного рассуждения.
Как говорить про сложность человеческим языком.
Вместо «сложность O(n²)» скажите: «При удвоении входных данных время работы вырастет в четыре раза — это дорого на больших объёмах». Вместо «O(1)» — «время не зависит от размера входных данных, обращение по ключу словаря всегда одинаково быстрое». Это звучит как инженерное рассуждение, а не как зазубренная таблица.
Быстрый чек-лист выбора структуры данных:
- Нужна быстрая проверка вхождения или дедупликация → set (O(1) для in).
- Нужно считать частоту элементов → dict или collections.Counter.
- Нужен порядок и доступ по индексу → list.
- Нужна очередь FIFO с быстрым добавлением/удалением с обоих концов → collections.deque (не list — list.pop(0) работает за O(n)).
- Нужна структура с приоритетом → heapq.
- Нужно отображение с сохранением порядка вставки → dict (Python 3.7+).
На интервью проговаривайте выбор явно: «Здесь мне нужна быстрая проверка вхождения, поэтому беру set, а не list — это сразу даёт O(1) вместо O(n) на каждой итерации». Одна фраза — и интервьюер видит, что вы думаете о сложности, а не просто пишете первое, что пришло в голову.
Пространственная сложность — не забывайте о ней. Частая ошибка: кандидат оптимизирует время, не замечая, что создаёт дополнительную структуру размером O(n). Иногда это оправдано — явный time-space trade-off. Но это нужно назвать: «Я использую дополнительный словарь — это O(n) по памяти, зато даёт O(n) по времени вместо O(n²)».

Диаграмма визуализирует рост времени выполнения алгоритмов при увеличении размера входных данных. Сравнение кривых позволяет мгновенно понять разницу между эффективным O(1) и «дорогим» O(n²) подходами.
Типовые паттерны задач: частотный словарь, два указателя, стек/очередь (с мини-примерами)
Большинство задач на лайвкоде — это вариации нескольких десятков паттернов. Научившись их распознавать, вы перестаёте решать каждую задачу «с нуля» и начинаете выбирать из знакомого инструментария. Разберём четыре наиболее частых.
Паттерн 1: Частотный словарь. Применять, когда нужно посчитать элементы, найти дубликаты, определить анаграммы, найти наиболее частый элемент.
from collections import Counter def is_anagram(s: str, t: str) -> bool: return Counter(s) == Counter(t)
Как тестировать крайние случаи: пустые строки, строки с одним символом, строки с повторяющимися символами, разный регистр (если условие это предполагает).
Паттерн 2: Два указателя. Применять, когда работаете с отсортированным массивом или строкой и ищете пару/тройку элементов с заданным свойством. Позволяет избежать вложенного цикла O(n²) и решить задачу за O(n).
def two_sum_sorted(nums: list, target: int) -> list: left, right = 0, len(nums) - 1 while left < right: current = nums[left] + nums[right] if current == target: return [left, right] elif current < target: left += 1 else: right -= 1 return []
Крайние случаи: пустой список, список из одного элемента, target не достигается, несколько подходящих пар.
Паттерн 3: Стек. Применять, когда нужно проверить корректность скобочной последовательности, обработать вложенные структуры, найти ближайший больший элемент.
def is_valid_brackets(s: str) -> bool:
stack = []
mapping = {')': '(', '}': '{', ']': '['}
for char in s:
if char in mapping:
top = stack.pop() if stack else '#'
if mapping[char] != top:
return False
else:
stack.append(char)
return not stack
Сигнал на применение стека: задача упоминает «последний вошёл — первый вышел», вложенность, «ближайший предыдущий».
Паттерн 4: Скользящее окно. Применять, когда нужно найти подмассив или подстроку с заданным свойством (максимальная сумма, уникальные символы, фиксированная длина).
def max_sum_subarray(nums: list, k: int) -> int: window_sum = sum(nums[:k]) max_sum = window_sum for i in range(k, len(nums)): window_sum += nums[i] - nums[i - k] max_sum = max(max_sum, window_sum) return max_sum
Здесь мы не пересчитываем сумму окна с нуля на каждом шаге — добавляем новый элемент и убираем ушедший. Это снижает сложность с O(n·k) до O(n).
| Паттерн | Сигнал в условии задачи | Крайние случаи для проверки |
|---|---|---|
| Частотный словарь | «сколько раз», «дубликаты», «анаграммы» | Пустой ввод, один элемент, все одинаковые |
| Два указателя | «отсортированный массив», «пара с суммой» | Нет решения, несколько решений, граничные индексы |
| Стек | «вложенность», «скобки», «ближайший больший» | Пустая строка, несбалансированные скобки |
| Скользящее окно | «подмассив длиной k», «максимум в окне» | k > len(nums), все одинаковые элементы |
Что делать, если застрял: стратегия, вопросы, частичные решения, тест-кейсы
Застрять на лайвкоде — нормально. Это случается с опытными разработчиками, и интервьюер это знает. Вопрос не в том, застрянете ли вы, а в том, как будете себя вести в этот момент.
Стратегия выхода из тупика, работает в такой последовательности:
- Шаг 1 — переформулировать задачу своими словами. Иногда тупик возникает потому, что вы решаете не ту задачу, которую имел в виду интервьюер. Скажите: «Дайте я проверю, правильно ли понимаю: нам нужно найти… при условии… и вернуть…». Это не слабость — это профессиональная привычка уточнять требования.
- Шаг 2 — упростить задачу. Что если входных данных всего два? Что если массив отсортирован? Что если все числа положительные? Решение упрощённой версии часто подсказывает подход к общей.
- Шаг 3 — назвать частичное решение. Если оптимальное не приходит — скажите об этом прямо: «Пока вижу решение за O(n²) через вложенный цикл. Напишу его, а потом попробую оптимизировать». Рабочий медленный код лучше, чем красивый несуществующий.
- Шаг 4 — проверить гипотезу на примере. Возьмите конкретный маленький ввод и пройдите через него руками, проговаривая вслух. Это и помогает найти ошибку в логике, и показывает интервьюеру, что вы методичны.
Какие вопросы задавать интервьюеру::
- «Входные данные всегда валидны, или нужно обрабатывать некорректный ввод?»
- «Есть ли ограничения по памяти, или важна только скорость?»
- «Числа могут быть отрицательными?»
- «Нужно вернуть одно решение или все возможные?»
Почему честность лучше молчания?
Фраза «Не уверен, но моя гипотеза такая — давайте проверим» — это сигнал инженерного мышления. Молчание на две минуты — это сигнал растерянности. Интервьюер часто готов подсказать, если видит, что вы думаете в правильном направлении, но застряли на детали. Но подсказать тому, кто молчит, невозможно.
Григорий Петров, DevRel Evrone, эксперт по Python и нейрофизиологии обучения: «Интервьюер ищет не того, кто знает синтаксис, а того, кто умеет в «совместное решение проблем». Лайвкод — это не экзамен, это симуляция рабочего дня. Если кандидат молчит, он симулирует худшего коллегу в мире».
Чек-лист лайвкода
- Уточнил ограничения и формат данных до написания кода.
- Разобрал пример вслух.
- Назвал подход и сложность до начала реализации.
- Проговариваю код по мере написания, не молчу.
- После написания проверил крайние случаи: пустой ввод, один элемент, максимальный размер.
- Назвал возможные улучшения, даже если не реализовал.
- При тупике — упростил задачу или попросил уточнение, не молчал.
Что спрашивают про инженерную практику: тесты, качество кода, отладка и производительность?
На уровне middle и выше вопросы про инженерную практику нередко оказываются важнее, чем вопросы про тонкости языка. Причина проста: компания нанимает не того, кто знает Python, а того, кто умеет писать код, который можно читать, тестировать, поддерживать и отлаживать в реальных условиях. Кандидат, который уверенно отвечает про декораторы, но не может объяснить, как организует тесты — вызывает вопросы.
Хорошая новость: эти вопросы предсказуемы, и на них можно подготовить честные, конкретные ответы из собственного опыта — даже если этот опыт пока учебный.
Тестирование: unit/integration, pytest, мокирование — как отвечать с опытом
Разница между unit и integration тестами.
Это первое, что спрашивают — и первое, на чём путаются. Unit-тест проверяет одну функцию или метод в изоляции: никаких баз данных, сетевых запросов и файлов. Integration-тест проверяет взаимодействие нескольких компонентов — например, что ваш репозиторий корректно читает данные из реальной тестовой базы.
Практическое правило, которое хорошо звучит на интервью: «Unit-тесты я пишу для логики — они быстрые и запускаются при каждом коммите. Integration-тесты — для границ системы, где важно убедиться, что компоненты работают вместе. Их меньше, они медленнее, но они ловят другой класс ошибок».
pytest: что важно знать
Базовый синтаксис pytest знают все. Интервьюер проверяет, умеете ли вы организовывать тесты на практике.
Фикстуры — ключевой инструмент: они позволяют переиспользовать подготовку тестового окружения и управлять его временем жизни:
import pytest
@pytest.fixture
def user():
return {"id": 1, "name": "Alice", "email": "alice@example.com"}
def test_user_name(user):
assert user["name"] == "Alice"
Параметризация позволяет запустить один тест с несколькими наборами данных — это чище, чем копировать тест несколько раз:
@pytest.mark.parametrize("input,expected", [
("hello", 5),
("", 0),
("привет", 6),
])
def test_string_length(input, expected):
assert len(input) == expected
На интервью стоит упомянуть организацию: тесты живут рядом с кодом или в отдельной директории tests/, файлы называются test_*.py, функции — test_*. Это не банальность — это сигнал, что вы работали с реальной кодовой базой, а не только писали учебные примеры.Иллюстрация pytest УСПЕХ.
Стилизованный монитор показывает процесс проверки кода с помощью pytest. Успешное выполнение теста (PASSED) с зеленым чекмарком визуализирует конечную цель разработчика при написании тестов.
Стилизованный монитор показывает процесс проверки кода с помощью pytest. Успешное выполнение теста (PASSED) с зеленым чекмарком визуализирует конечную цель разработчика при написании тестов.
Мокирование: где уместно, где вредно. unittest.mock и pytest-mock позволяют подменить реальные зависимости — внешние API, базы данных, файловую систему. Главный принцип: мокируйте на границах системы, а не внутри логики.
from unittest.mock import patch
def test_send_email(mock_smtp):
with patch("myapp.email.smtplib.SMTP") as mock_smtp:
send_welcome_email("alice@example.com")
mock_smtp.return_value.__enter__.return_value.sendmail.assert_called_once()
Типичная ошибка, о которой стоит сказать на интервью: «Когда мокируешь слишком много, тесты перестают проверять реальное поведение — они просто проверяют, что ты правильно написал mock. Я стараюсь мокировать только внешние зависимости: HTTP-запросы, отправку писем, запись в файл».
| Что тестировать | Unit | Integration | Mock нужен? |
|---|---|---|---|
| Бизнес-логика, вычисления | ✓ | — | Нет |
| Работа с базой данных | — | ✓ | Иногда (тестовая БД) |
| Внешний API / HTTP | ✓ | ✓ | Да (в unit) |
| Файловая система | ✓ | — | Да |
| Взаимодействие сервисов | — | ✓ | Нет |
Качество: PEP8, линтеры, типизация, код-ревью — «зрелые» формулировки
Инструменты — не самоцель, а привычка. Интервьюер не ждёт, что вы перечислите все существующие линтеры. Он хочет понять, есть ли у вас культура работы с кодом — или вы пишете «как получится» и надеетесь, что коллеги разберутся.
Базовый стек, о котором стоит говорить уверенно:
- black — форматтер, который убирает дискуссии о стиле. Настраивается один раз, запускается автоматически. Формулировка на интервью: «Black избавляет от споров о форматировании на ревью — мы просто договорились, что он финальный арбитр».
- flake8 / ruff — линтеры, ловят стилистические нарушения и очевидные ошибки. ruff значительно быстрее и постепенно вытесняет связку flake8 + плагины.
- mypy — статическая проверка типов. Не обязательна везде, но критично полезна в публичных интерфейсах и функциях с нетривиальными входными данными.
Типизация — тема, которая часто возникает на middle+ интервью. Рабочая позиция: «Я типизирую публичные функции и интерфейсы модулей — это документация, которую проверяет инструмент. Внутри функции, где всё очевидно, аннотации добавляю по необходимости». Это звучит взвешенно — не «типизирую всё» и не «типизация это лишнее».
Код-ревью: как вы в нём участвуете. Это вопрос про коммуникацию, а не про технику. Два сценария, которые стоит подготовить:
Как реагируете на замечания: не защищаетесь автоматически — сначала понимаете, потом отвечаете. Если не согласны — объясняете логику, а не настаиваете на своём.
Как сами комментируете чужой код: ответ должен объяснять «почему», а не только «что не так». Вместо «это неправильно» — «здесь может возникнуть race condition при параллельных запросах, потому что…».
Типичный фейл, который сразу снижает оценку:
«Я не пишу тесты, потому что нет времени». Это не честность — это сигнал о приоритетах. Лучше: «В учебных проектах покрытие неполное, но я понимаю, что в команде тесты — это не опция, и готов к этому стандарту».
Отладка и скорость: логирование, профилирование, оптимизация без преждевременной магии
Логирование — это не print(). Один из надёжных признаков инженерной зрелости: кандидат использует logging, а не print для диагностики. На интервью достаточно показать понимание уровней:
import logging
logger = logging.getLogger(__name__)
logger.debug("Начинаем обработку записей: %d", len(records))
logger.info("Запись успешно сохранена: id=%s", record_id)
logger.warning("Значение близко к лимиту: %d", current_value)
logger.error("Ошибка при обращении к API: %s", str(e))
Ключевые моменты: DEBUG — для разработки, INFO — для значимых событий в продакшене, WARNING — для ситуаций, требующих внимания, ERROR — для сбоев. print в продакшене — сигнал о том, что логирование не настроено.
Воспроизведение бага. На интервью часто спрашивают: «Как вы подходите к отладке?» Сильный ответ строится на методичности: изолировать — воспроизвести — проверить гипотезу — зафиксировать. Первый шаг — минимальный воспроизводимый пример: убрать всё лишнее и оставить только то, что стабильно воспроизводит проблему. Это и помогает найти причину, и упрощает обращение за помощью к коллегам.
Профилирование: измерять, а не угадывать. Преждевременная оптимизация — известная ловушка. Правильный подход: сначала измерить, потом оптимизировать то, что реально медленно. Базовый инструментарий:
- cProfile / profile — стандартная библиотека, показывает, сколько времени тратится в каждой функции.
- line_profiler — построчное профилирование для горячих участков.
- memory_profiler — если проблема в памяти, а не во времени.
Формулировка на интервью: «Перед оптимизацией я сначала профилирую и нахожу реальное узкое место. Часто оказывается, что проблема не там, где казалось — например, не в алгоритме, а в количестве запросов к базе». Это звучит как опыт, а не как теория.
Чек-лист инженерной зрелости
- Пишу unit-тесты для бизнес-логики, integration — для границ системы.
- Использую pytest с фикстурами и параметризацией.
- Мокирую только внешние зависимости, не внутреннюю логику.
- Запускаю black / ruff / flake8 как часть рабочего процесса.
- Типизирую публичные интерфейсы с помощью аннотаций и mypy.
- На ревью объясняю «почему», а не только «что не так».
- Использую logging с уровнями вместо print.
- Перед оптимизацией профилирую — не угадываю узкое место.
Какие поведенческие вопросы задают и как отвечать уверенно (включая «я не знаю»)?
Поведенческий блок — это не формальность в конце интервью. Это проверка того, насколько вы предсказуемы как коллега: как принимаете ответственность, как ведёте себя в конфликте, как реагируете на неопределённость. Технически сильный кандидат, который уходит от ответа на поведенческие вопросы или даёт абстрактные ответы без конкретики, вызывает у интервьюера обоснованные сомнения.
Хорошая новость: поведенческие вопросы полностью предсказуемы. К ним можно подготовиться заранее — и это не значит «заучить скрипт». Это значит заранее обдумать несколько историй из своего опыта и научиться рассказывать их структурно.
┌─────────────────────────────────────────────────────────────┐ │ ЕСЛИ НЕ ЗНАЕШЬ ОТВЕТ — АЛГОРИТМ │ ├─────────────────────────────────────────────────────────────┤ │ 1. ПРИЗНАТЬ → «Честно говоря, с этим не сталкивался» │ │ 2. УТОЧНИТЬ → «Правильно ли я понимаю контекст?» │ │ 3. ГИПОТЕЗА → «Логика подсказывает мне вот что...» │ │ 4. ПЛАН → «Вот как я бы это проверил / изучил» │ └─────────────────────────────────────────────────────────────┘
Этот алгоритм работает и для технических вопросов, и для поведенческих — везде, где у вас нет готового ответа. Молчание или попытка угадать «правильный» ответ проигрывают честной неопределённости с планом действий.
«Расскажите о себе/проекте»: шаблон ответа под вакансию
Этот вопрос задают на каждом интервью — и почти всегда кандидаты отвечают на него хуже, чем могли бы. Типичная ошибка: пересказ резюме в хронологическом порядке. Интервьюер уже прочитал резюме. Он хочет понять, кто вы как инженер и почему вы здесь.
Шаблон ответа: четыре элемента.
- Кто вы профессионально — одно-два предложения о текущем уровне и специализации. Не «я Python-разработчик», а «я backend-разработчик с фокусом на REST API и асинхронном коде, последние два года работал в финтехе».
- Что делали — один-два конкретных проекта или задачи, релевантных вакансии. Не список технологий, а что именно вы сделали и какую проблему решили.
- Какой результат — измеримый или хотя бы конкретный: «сократили время обработки запросов вдвое», «перевели монолит на сервисную архитектуру», «с нуля выстроили покрытие тестами до 80%».
- Почему эта роль — одно предложение, которое связывает ваш опыт с конкретной вакансией. Это показывает, что вы готовились, а не рассылаете резюме всем подряд.
Пример сборки для middle-позиции: «Я backend-разработчик, последние три года пишу на Python — в основном FastAPI и Django, работал с PostgreSQL и Redis. На последнем месте основной проект — система обработки платёжных уведомлений, где мы переписали синхронный пайплайн на async и снизили задержку с 800 мс до 120 мс. Ваша вакансия привлекла тем, что здесь похожая задача — высоконагруженный сервис с упором на надёжность, и это именно то, чем я хочу заниматься дальше».
Для junior — акцент смещается. Реального продакшн-опыта мало или нет — и это нормально. Говорите о пет-проектах и учебных работах конкретно: что за проект, какую задачу решали, что было сложно, что узнали. «Я написал Telegram-бота для трекинга привычек — там разобрался с asyncio, научился работать с SQLite через SQLAlchemy и впервые настроил деплой на сервер» — это лучше, чем «у меня есть пет-проекты».
STAR-ответы: конфликт, ошибка, провал, ответственность (готовые каркасы)
STAR — это структура поведенческого ответа: Situation (контекст), Task (задача/ответственность), Action (что именно вы сделали), Result (что получилось и чему научились). Без этой структуры ответы на поведенческие вопросы превращаются либо в абстракцию («я всегда стараюсь найти компромисс»), либо в бессвязный рассказ.
Важный акцент: интервьюер хочет слышать ваши действия, а не команды. «Мы решили», «мы сделали» — слабая формулировка. «Я предложил», «я взял на себя», «я договорился» — сильная.
Каркас 1: Конфликт с коллегой или несогласие с решением.
- S: «На проекте возникло разногласие с коллегой по поводу архитектурного решения — он предлагал X, я считал, что Y лучше по такой-то причине».
- T: «Нужно было прийти к решению, не затягивая спринт, и сохранить рабочие отношения».
- A: «Я предложил формализовать оба варианта письменно с плюсами и минусами, вынести на короткое обсуждение с техлидом и принять решение на основе конкретных критериев».
- R: «Выбрали вариант коллеги с одним моим изменением. Для меня главный вывод — разногласия лучше решаются через конкретику, а не через убеждение».
Каркас 2: Ошибка, которую вы допустили.
- S: «Я задеплоил изменение без полноценного тестирования в пятницу вечером — в субботу сервис упал».
- T: «Нужно было восстановить работу сервиса и разобраться в причинах».
- A: «Я откатил изменение, написал постмортем, предложил добавить интеграционный тест на этот сценарий и договорился с командой не деплоить в пятницу без approve второго разработчика».
- R: «Сервис восстановили за 40 минут. Процесс деплоя стал строже — и это было моей инициативой».
Обратите внимание: ответ не заканчивается на «было плохо». Он заканчивается на «вот что я изменил». Именно это интервьюер хочет услышать.
Каркас 3: Ситуация под давлением / дедлайн.
- S: «За три дня до релиза обнаружили баг, который ломал основной флоу — времени на полную переработку не было».
- T: «Нужно было принять решение: фиксировать частично, переносить релиз или искать обходное решение».
- A: «Я оценил риски, предложил временное решение с флагом, закрывающим проблему для основных случаев, и сразу завёл задачу на полный фикс в следующий спринт. Согласовал это с менеджером».
- R: «Релиз вышел в срок, баг не задел пользователей, в следующем спринте закрыли полностью. Научился раньше эскалировать риски, а не ждать последнего момента».
Каркас 4: Провал или проект, который не получился.
Это вопрос-ловушка, на котором кандидаты либо начинают хвалить себя («ну, мы не успели, но зато…»), либо уходят в самокритику без вывода. Сильный ответ — честный разбор с конкретным уроком:
- S + T: кратко, без деталей.
- A: что вы делали и где ошиблись — конкретно.
- R: «Проект не достиг цели. Главное, что я вынес — нужно раньше проверять гипотезы на реальных данных, а не строить систему до конца и только потом тестировать. Сейчас я подхожу к новым задачам с этим в голове».
| Тип вопроса | Чего ждёт интервьюер | Частая ошибка |
|---|---|---|
| Конфликт | Как вы управляете разногласиями | «Я всегда нахожу компромисс» — без примера |
| Ошибка | Ответственность + вывод | Перекладывание на обстоятельства |
| Провал | Честность + рост | Маскировка провала под «трудный успех» |
| Дедлайн | Приоритизация и коммуникация | «Я просто работал больше» |
Если не знаешь ответ + вопросы работодателю
Скрипт ответа «я не знаю».
Это один из самых ценных навыков на собеседовании — и один из самых недооценённых. Интервьюер, как правило, знает ответ и понимает, знаете ли его вы. Попытка угадать или уйти от ответа считывается мгновенно и снижает доверие сильнее, чем честное незнание.
Рабочий скрипт из четырёх шагов:
«С этим конкретно не сталкивался [признать] — но если я правильно понимаю контекст задачи [уточнить] — то логика подсказывает мне вот что... [гипотеза] — проверил бы это через документацию / небольшой эксперимент / коллегу с опытом в этой области» [план].
Это не слабость — это демонстрация того, как вы будете вести себя в реальной работе, когда столкнётесь с незнакомой проблемой. А это случается постоянно.
Вопросы работодателю — как закончить интервью сильнее
«У вас есть вопросы к нам?» — это не вежливый ритуал. Это ещё одна точка оценки: думаете ли вы о работе серьёзно, интересует ли вас команда и процессы, или вы просто хотите получить оффер.
Хорошие вопросы — конкретные, показывают, что вы думаете о работе в долгую:
- «Как устроен процесс код-ревью в команде? Есть ли формализованные стандарты или это больше по ситуации?»
- «Как команда подходит к техническому долгу — есть ли выделенное время на рефакторинг?»
- «Что считается успехом для этой роли в первые три-шесть месяцев?»
- «Как устроен онбординг — есть ли ментор, документация по проекту?»
- «Как часто происходят релизы и как устроен процесс деплоя?»
- «Какие инструменты использует команда для CI/CD и code quality?»
- «С какой самой интересной технической проблемой команда столкнулась за последний год?»
- «Как в команде принимаются архитектурные решения — есть ли RFC-процесс или это неформально?»
Вопросы про зарплату, отпуск и бонусы — для HR-этапа, не для технического интервью. Вопрос «а что вы предложите?» без предварительного обсуждения ожиданий — тоже не лучший финал.
Чек-лист вопросов работодателю
- Про процессы разработки: код-ревью, тесты, CI/CD.
- Про технический долг и рефакторинг.
- Про онбординг и поддержку нового сотрудника.
- Про критерии успеха в первые месяцы.
- Про интересные технические вызовы команды.
- Про принятие архитектурных решений.
- Про релизный процесс и частоту деплоев.
- Про рост: есть ли возможность менторства, конференции, обучение.
Если вы только начинаете осваивать профессию Python-разработчика или хотите системно подготовиться к интервью, рекомендуем обратить внимание на подборку курсов по Python-разработке. В них есть теоретическая и практическая часть, которые помогают разобраться в языке, алгоритмах и типичных задачах собеседований.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
112 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
13 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
12 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
36 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
17 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
226 отзывов
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
11 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
100 отзывов
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
12 марта
|
Подробнее |

Skypro vs Contented: Web/UX дизайн — где сильнее разборы работ и быстрее растёт качество
В этой статье мы расскажем, как выбрать лучший курс по веб-дизайну. Если вы только начинаете изучать эту профессию, то вам наверняка будет полезно узнать, что важно учитывать при выборе курса и какие именно аспекты обучения могут ускорить ваш профессиональный рост. Откроем основные моменты, которые помогут вам сделать правильный выбор и избежать распространенных ошибок.

Skypro vs Bang Bang Education: где дизайнера лучше прокачивают «думать руками»
Выбираете курсы дизайна и пытаетесь понять, где действительно учат работать с реальными задачами? В этом материале разбираем, как сравнивать программы обучения, на что смотреть в практике, ревью и портфолио, и какие критерии помогут выбрать курс осознанно.

Собеседование PHP-разработчика: вопросы, задачи и подготовка
Если вы только начинаете осваивать профессию PHP-разработчика или хотите увереннее чувствовать себя на интервью, рекомендуем обратить внимание на подборку курсов по PHP-разработке. В таких программах обычно есть теоретическая и практическая часть: изучение языка, фреймворков, баз данных и решение реальных задач.

Вопросы и задачи на собеседовании по Java в 2026 году: полный гид
Собеседование на позицию java разработчик собеседование сегодня включает не только вопросы по синтаксису языка. Какие темы проверяют, какие задачи дают и как подготовиться к интервью по Java — разбираем ключевые блоки, типовые вопросы и практические советы.