SQL и системный анализ: как данные помогают видеть наперёд
Знаете, что объединяет хорошего системного аналитика и опытного детектива? Оба должны уметь работать с данными так, чтобы не упустить ни одной важной детали. И если у детектива есть лупа и записная книжка, то у аналитика есть SQL – универсальный инструмент для работы с данными, без которого современному специалисту просто никуда.

Я много лет работаю на стыке технологий и аналитики, и могу с уверенностью сказать: знание SQL – это не просто строчка в резюме или модный тренд. Это ключ к пониманию того, как устроены информационные системы «под капотом». Без него вы будете как археолог без лопаты – вроде и знаете, где копать, но добраться до сути никак не получается.
В этом гиде я расскажу, почему SQL стал незаменимым инструментом для системного аналитика, как он помогает предотвращать критические ошибки в проектировании (поверьте, я навидался их предостаточно), и главное – как использовать его для повышения качества своей работы. И да, обещаю – никакой сухой теории, только проверенные практикой знания и реальные кейсы из жизни.
- Зачем системному аналитику нужен SQL?
- Базы данных и их роль в аналитике
- Основы SQL: Что нужно знать аналитику
- Проектирование БД: Как SQL помогает аналитикам
- Практическое применение SQL в аналитике
- Советы по изучению SQL для системного аналитика
- Заключение
- Рекомендуем посмотреть курсы по системной аналитике
Зачем системному аналитику нужен SQL?
Давайте начну с реальной истории из жизни (да-да, той самой, где я чуть не поседел раньше времени). Представьте: крупный проект, команда работает над системой учета клиентов, все идет гладко… пока не приходит время интеграции с CRM. И тут выясняется, что данные о клиентах хранятся в виде одной длинной строки – фамилия, имя, отчество слеплены вместе, как пластилин в руках первоклассника. «Подумаешь, – скажете вы, – просто разделим строку на части». Ха! Если бы все было так просто.
Результат? Три месяца работы, куча костылей в коде и нервный тик у разработчиков. А все почему? Потому что на этапе проектирования никто не подумал о структуре данных. И знаете что? Это даже не самый «веселый» пример из моей практики.
Вот почему SQL для системного аналитика – это как навигатор для водителя в незнакомом городе:
- Понимание «анатомии» системы
- Помогает видеть, как данные связаны между собой (и поверьте, иногда эти связи запутаны похлеще семейного древа Ланнистеров)
- Позволяет предсказывать, где могут возникнуть проблемы при масштабировании системы
- Дает возможность говорить с разработчиками на одном языке (а не изображать глухой телефон)
- Проверка требований на реализуемость. Знаете, что я теперь делаю первым делом, получая новые требования? Правильно – набрасываю структуру базы данных. Потому что именно здесь обычно всплывают все «скелеты в шкафу»:
- Противоречивые требования (как те самые «уникальные» записи, которые должны дублироваться)
- Нереализуемые сценарии (помните историю про «простое» разделение ФИО?)
- Потенциальные проблемы с производительностью
- Предотвращение архитектурных ошибок. SQL помогает увидеть, как сегодняшние решения повлияют на завтрашние возможности системы. Это как игра в шахматы – нужно думать на несколько ходов вперед. И поверьте моему опыту – лучше потратить день на проектирование правильной структуры БД, чем месяцы на исправление последствий неправильных решений.
Короче говоря, SQL для системного аналитика – это не просто навык, это своего рода суперсила. Которая, кстати, еще и неплохо оплачивается на рынке труда (намек понят, надеюсь?).
Базы данных и их роль в аналитике
Знаете, что общего между базами данных и швейцарским ножом? Правильно – для каждой задачи есть свой инструмент. И если выбрать неправильный – результат может быть… скажем так, неоптимальным (читай: катастрофическим).
Давайте разберем основных «игроков» на поле баз данных, и я расскажу, где какой инструмент лучше использовать (основываясь на личном опыте набивания шишек).
- Реляционные БД (SQL) Это как старый добрый «Мерседес» – надежно, проверено временем, но иногда немного медлительно.
- PostgreSQL: мой личный фаворит. Как швейцарский нож среди СУБД – есть всё, что нужно, и даже больше. Особенно хорош для сложных аналитических запросов и работы с геоданными.
- MySQL: как Toyota Corolla – берут все, работает везде. Особенно хорош для веб-приложений среднего размера.
- Oracle: это как Rolls-Royce – дорого, пафосно, но если можете себе позволить – берите (корпоративный стандарт, как-никак).
- NoSQL Это уже как электросамокат – модно, быстро, но не для всех задач подходит.
- MongoDB: документоориентированная БД. Идеальна для проектов, где структура данных постоянно меняется (стартапы, я на вас смотрю).
- Redis: как спортивный болид – безумно быстрый, но только по прямой (кэширование и простые операции).
- Cassandra: для тех, кому нужно хранить ОЧЕНЬ много данных и не умереть при этом (привет, Big Data).
- Специализированные БД
- ClickHouse: когда нужно считать метрики быстрее, чем пользователь моргнет. Буквально.
- Neo4j: для тех, кто работает с графами и связями (как LinkedIn, только без спама в личку).
- ElasticSearch: поиск во всём и везде (даже там, где вы не ожидали найти).
Вот вам сравнительная табличка (чтобы было проще выбрать свой инструмент):
| СУБД | Когда использовать | Когда НЕ использовать |
|---|---|---|
| PostgreSQL | Сложная аналитика, геоданные, корпоративные приложения | Простые блоги, где MySQL за глаза |
| MySQL | Веб-приложения, простая аналитика | Сложные аналитические запросы |
| MongoDB | Часто меняющаяся структура данных | Строгая отчетность с множеством связей |
| ClickHouse | Аналитика в реальном времени | OLTP-системы (там, где много изменений) |
Как выбрать СУБД для проекта?
- Оцените объем данных (от «помещается на флешке» до «нужен свой дата-центр»)
- Подумайте о структуре (если она меняется чаще, чем погода в Питере – смотрите в сторону NoSQL)
- Учтите нагрузку (сколько пользователей будут одновременно делать запросы?)
- Не забудьте про команду (если у вас все знают только MySQL, может не стоит брать экзотику?)
И помните главное правило выбора БД: нет идеального решения, есть подходящее для конкретной задачи. Как говорится, молотком можно забить гвоздь, а можно и палец – всё зависит от того, как использовать инструмент.
Основы SQL: Что нужно знать аналитику
Знаете, что меня всегда удивляло в изучении SQL? То, как быстро люди переходят от «SELECT * FROM table» к созданию запросов, похожих на код запуска космического корабля. Давайте разберем, что действительно нужно знать системному аналитику, без лишней академической шелухи.
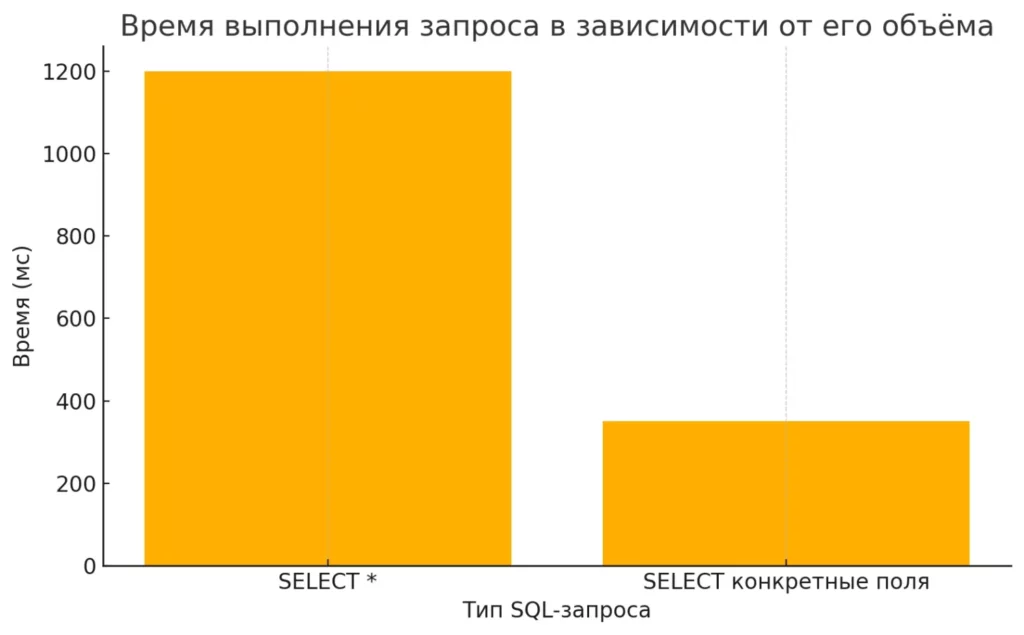
Диаграмма наглядно сравнивает время выполнения двух типов SQL-запросов: SELECT * и SELECT конкретные поля. Видно, что использование SELECT * существенно увеличивает время обработки, что может негативно сказаться на производительности базы данных при работе с большими таблицами. Визуализация подчёркивает необходимость оптимизации запросов — особенно в аналитических задачах, где важна скорость.
Базовый набор команд (или «Джентльменский набор аналитика»)
-- Это как "Здравствуйте" в SQL-мире SELECT column1, column2 FROM table WHERE condition; -- А это уже "Давайте дружить таблицами" SELECT t1.name, t2.order_count FROM table1 t1 JOIN table2 t2 ON t1.id = t2.user_id;
Кстати, забавный факт из моей практики: однажды джуниор-разработчик написал запрос с 12 джойнами, и база данных зависла так, что пришлось перезагружать сервер. Поэтому давайте договоримся: JOIN – это хорошо, но в меру.
Основные операторы (или «Без чего вас не возьмут на работу»):
- WHERE – ваш лучший друг для фильтрации. Как охранник в клубе: этих пускаем, этих – нет.
WHERE status = 'active' AND registration_date > '2024-01-01' AND (age > 18 OR parent_approval = true)
- GROUP BY – для тех, кто любит считать:
SELECT department, COUNT(*) as employee_count, AVG(salary) as avg_salary FROM employees GROUP BY department HAVING COUNT(*) > 5 -- Это как "постфильтрация" для групп
- ORDER BY – потому что хаос – это не наш метод:
ORDER BY priority DESC, -- Сначала важное created_at ASC -- Потом по времени
Продвинутые техники (или «Как произвести впечатление на собеседовании»):
- Подзапросы – это как матрёшка, только в SQL:
SELECT * FROM users WHERE id IN ( SELECT user_id FROM orders WHERE total_amount > 1000 )
- Оконные функции – когда нужно посчитать что-то, не теряя детализации:
SELECT department, salary, AVG(salary) OVER (PARTITION BY department) as dept_avg FROM employees
Оптимизация запросов (или «Как не положить продакшн»):
- Используйте индексы правильно:
- Да: WHERE indexed_column = value
- Нет: WHERE LOWER(indexed_column) = ‘value’ (функции убивают индексы)
- **Избегайте SELECT ***:
- Это как заказывать «всё меню» в ресторане – звучит круто, но на практике не очень умно
- Следите за планом выполнения запроса:
EXPLAIN ANALYZE SELECT ...
(Спойлер: если видите «Sequential Scan» на большой таблице – пора что-то менять)
Работа с большими данными (или «Как не уснуть, ожидая результат запроса»):
- Используйте LIMIT при отладке:
SELECT * FROM huge_table LIMIT 1000
- Разбивайте сложные запросы на части:
WITH filtered_data AS ( SELECT * FROM huge_table WHERE ... ), aggregated_data AS ( SELECT ... FROM filtered_data GROUP BY ... ) SELECT * FROM aggregated_data
И помните главное правило работы с SQL: сначала подумать, потом написать, потом ещё раз подумать, и только потом запускать. Потому что иногда проще переписать запрос, чем объяснять, почему база данных лежит уже второй час.
P.S. А если кто-то скажет вам, что EXISTS быстрее, чем IN, или наоборот – не верьте. Тестируйте на своих данных. В мире SQL нет абсолютных истин, кроме одной: бэкапы должны быть всегда.
Проектирование БД: Как SQL помогает аналитикам
Помните историю про три поросенка? Так вот, проектирование базы данных – это примерно как строительство того самого домика. Построишь из соломы (читай: плохо спроектируешь) – придет серый волк (масштабирование, новые требования) и сдует твою работу в тартарары.
Искусство выявления сущностей (или «Как не запутаться в собственной схеме»)
Давайте рассмотрим реальный кейс из моей практики. Система автосервиса, простая на первый взгляд:
CREATE TABLE cars ( id INT PRIMARY KEY, owner_id INT, -- Упс, а что если машина в совместном владении? model VARCHAR(100) );
Казалось бы, что может пойти не так? О, много чего! Например:
- Совместное владение автомобилем
- История владения
- Разные СТС на одну машину
- Временное владение (лизинг)
Правильное решение:
CREATE TABLE cars (...); CREATE TABLE owners (...); CREATE TABLE car_ownership ( car_id INT, owner_id INT, ownership_type VARCHAR(50), start_date DATE, end_date DATE, PRIMARY KEY (car_id, owner_id, start_date) );
ER-диаграммы: Визуализация связей (или «Как объяснить заказчику, почему всё сложно»)
Вот типичная ER-диаграмма для нашего автосервиса:
erDiagram
CARS ||--o{ CAR_OWNERSHIP : has
OWNERS ||--o{ CAR_OWNERSHIP : owns
CARS ||--o{ SERVICES : receives
MECHANICS ||--o{ SERVICES : performs
Типичные ошибки проектирования (или «Грабли, на которые наступают все»):
- «Всё в одну таблицу» синдром
- Было: user_info (id, name, address_street, address_city, address_country)
- Стало: Отдельные таблицы для адресов и нормализация данных
- «Авось потом доделаем» подход
- Спойлер: не доделаете. Никогда.
- Пример: «Давайте пока сохраним как TEXT, потом разберем на поля»
- «Жесткая связь» там, где нужна гибкость
- Было: order (user_id, product_id)
- Стало: order_items для множественных позиций
Как SQL помогает улучшать требования
- Проверка целостности данных
-- Если этот запрос возвращает строки, у нас проблемы SELECT * FROM orders o LEFT JOIN users u ON o.user_id = u.id WHERE u.id IS NULL;
- Выявление узких мест
-- Сколько записей затронет изменение схемы? SELECT COUNT(*) FROM legacy_table WHERE field_to_change IS NOT NULL;
- Тестирование гипотез
-- Проверяем, действительно ли нам нужна новая фича SELECT COUNT(*) as use_cases FROM user_actions WHERE action_type = 'potential_new_feature';
Советы от того, кто наступил на все грабли:
- Начинайте с простого, но оставляйте место для роста
- Документируйте связи и ограничения (поверьте, через полгода вы сами не вспомните, почему сделали именно так)
- Используйте инструменты проектирования (dbdiagram.io, например)
- Всегда думайте о миграции данных (особенно когда меняете существующую схему)
И помните: хорошая схема БД – это та, которую можно расширить без боли и страданий. Как говорил мой первый тимлид: «Лучше потратить день на проектирование, чем месяц на исправление».
P.S. А если заказчик спрашивает, почему нельзя просто хранить всё в Excel – покажите ему эту статью. Или лучше не показывайте, целее будете.
Практическое применение SQL в аналитике
Знаете, что общего между хорошим детективом и системным аналитиком? Оба умеют задавать правильные вопросы данным. И если детектив использует допросы и улики, то мы вооружаемся SQL-запросами. Давайте я покажу, как это работает на практике (и почему иногда простой SELECT может рассказать больше, чем десяток совещаний).
Анализ данных: поиск закономерностей
- Выявление трендов
-- Динамика заказов по месяцам
SELECT
DATE_TRUNC('month', order_date) as month,
COUNT(*) as orders_count,
SUM(total_amount) as revenue,
AVG(total_amount) as avg_order_value
FROM orders
GROUP BY DATE_TRUNC('month', order_date)
ORDER BY month;
Забавный случай из практики: однажды такой простой запрос помог обнаружить, что каждый второй вторник месяца продажи падают на 30%. Оказалось, в это время проводились технические работы у основного платежного провайдера. Случайность? Не думаю!
- Поиск аномалий
-- Находим подозрительно активных пользователей WITH user_stats AS ( SELECT user_id, COUNT(*) as action_count, AVG(COUNT(*)) OVER () as avg_actions, STDDEV(COUNT(*)) OVER () as std_dev FROM user_actions GROUP BY user_id ) SELECT * FROM user_stats WHERE action_count > avg_actions + 2 * std_dev;
SQL для проверки гипотез
Помните, как в школе нас учили научному методу? Так вот, в аналитике всё то же самое, только вместо лабораторных мышей у нас данные:
- Проверка предположений
-- Гипотеза: пользователи, которые начинают с бесплатного периода, -- чаще становятся постоянными клиентами WITH user_journey AS ( SELECT u.id, CASE WHEN MIN(s.subscription_type) = 'trial' THEN 1 ELSE 0 END as started_with_trial, COUNT(DISTINCT CASE WHEN s.subscription_type = 'paid' THEN s.id END) as paid_subscriptions FROM users u LEFT JOIN subscriptions s ON u.id = s.user_id GROUP BY u.id ) SELECT started_with_trial, COUNT(*) as total_users, AVG(CASE WHEN paid_subscriptions > 0 THEN 1.0 ELSE 0 END) as conversion_rate FROM user_journey GROUP BY started_with_trial;
- A/B тестирование
-- Сравниваем конверсию для разных вариантов дизайна SELECT experiment_group, COUNT(DISTINCT user_id) as users, COUNT(DISTINCT CASE WHEN converted = 1 THEN user_id END) as conversions, ROUND(COUNT(DISTINCT CASE WHEN converted = 1 THEN user_id END)::decimal / COUNT(DISTINCT user_id) * 100, 2) as conversion_rate FROM ab_test_results GROUP BY experiment_group;
Автоматизация отчётов
А теперь мой любимый трюк – как превратить часы ручной работы в автоматический процесс:
-- Создаём представление для регулярного отчёта
CREATE VIEW monthly_metrics AS
WITH revenue_data AS (
SELECT
DATE_TRUNC('month', transaction_date) as month,
SUM(amount) as revenue,
COUNT(DISTINCT user_id) as paying_users
FROM transactions
GROUP BY DATE_TRUNC('month', transaction_date)
),
engagement_data AS (
SELECT
DATE_TRUNC('month', activity_date) as month,
COUNT(DISTINCT user_id) as active_users,
AVG(session_duration) as avg_session_time
FROM user_activities
GROUP BY DATE_TRUNC('month', activity_date)
)
SELECT
r.month,
r.revenue,
r.paying_users,
e.active_users,
e.avg_session_time,
ROUND(r.paying_users::decimal / e.active_users * 100, 2) as conversion_rate
FROM revenue_data r
JOIN engagement_data e ON r.month = e.month;
Лайфхак от бывалого: если часто выполняете сложные запросы – создавайте представления (VIEW). Это как консервы в походе – открыл и пользуйся. Только не забывайте документировать, что и зачем вы законсервировали!
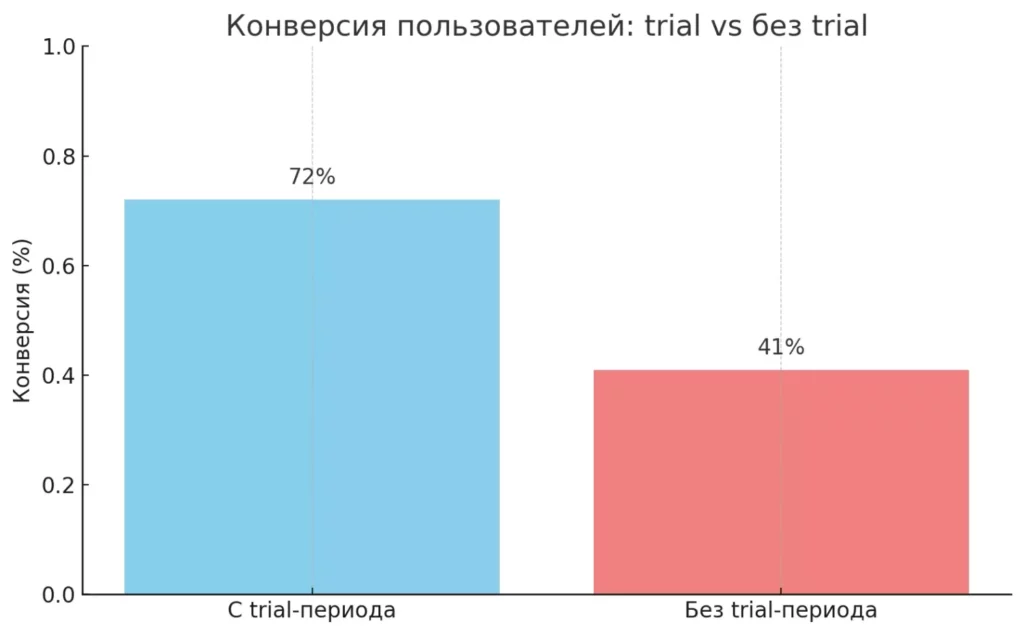
Диаграмма сравнивает конверсию двух групп пользователей: тех, кто начал с бесплатного trial-периода, и тех, кто его не использовал. Видно, что пользователи, начавшие с trial, переходят на платные услуги значительно чаще (72% против 41%). Это наглядный пример того, как SQL-запросы помогают проверять бизнес-гипотезы и принимать обоснованные продуктовые решения.
И помните главное правило анализа данных: если результат кажется слишком хорошим, чтобы быть правдой – перепроверьте запрос. Дважды. А лучше трижды. Особенно перед презентацией руководству (говорю по опыту).
Советы по изучению SQL для системного аналитика
Знаете, что я отвечаю, когда меня спрашивают: «С чего начать изучение SQL?» Я говорю: «С признания того факта, что вы будете писать ужасные запросы первые пару месяцев. И это нормально!» А теперь давайте я расскажу, как сделать этот путь менее болезненным (и желательно без случайного удаления продакшен-базы).
Путь джедая SQL (или план обучения для тех, кто не любит учиться впустую)
- Старт: основы без боли
- PostgreSQL Tutorial – как учебник для первого класса, только для взрослых
- SQLBolt – интерактивные уроки для тех, кто не может без практики
- Mode Analytics SQL Tutorial – когда хочется понять, а не просто запомнить
- Практика: где набить руку
- LeetCode SQL – как спортзал, только для мозга
- HackerRank SQL – когда хочется почувствовать себя хакером
- SQL Fiddle – песочница для экспериментов (никто не пострадает)
Лайфхаки для быстрого старта
- Начните с малого
-- День 1: Просто SELECT SELECT * FROM users; -- День 2: Добавляем WHERE SELECT * FROM users WHERE age > 18; -- День 3: JOIN входит в чат SELECT u.name, o.order_date FROM users u JOIN orders o ON u.id = o.user_id;
- Создайте свою тестовую базу
- Возьмите любой открытый датасет (например, AdventureWorks)
- Или создайте свою на основе реальных бизнес-кейсов
- Главное – работайте с данными, которые понимаете!
Типичные ловушки новичков (грабли, на которые я наступал лично)
- «Я выучу всё сразу!» – Нет, не выучите. И это нормально.
- «Мне нужно запомнить все команды!» – На самом деле хватит базовых 20%.
- «Я буду учиться по видео на YouTube» – Лучше начните с официальной документации.
План развития на 3 месяца
Месяц 1: Основы
- Базовые запросы SELECT, WHERE, GROUP BY
- Простые JOIN’ы
- Работа с датами и строками
Месяц 2: Углубление
- Подзапросы
- Оконные функции
- Представления и временные таблицы
Месяц 3: Практика
- Оптимизация запросов
- Работа с реальными данными
- Решение бизнес-задач
Полезные ресурсы (которые реально помогут)
- Книги
- «SQL for Mere Mortals» – для тех, кто хочет понять, а не заучить
- «PostgreSQL: Up and Running» – когда решите погрузиться глубже
- «SQL Antipatterns» – чтобы не изобретать велосипед (особенно квадратный)
- Инструменты
- DBeaver – бесплатный и удобный клиент для БД
- DataGrip – для тех, кто готов платить за комфорт
- DbDiagram.io – для визуализации схем БД
И помните: главное – не количество выученных команд, а понимание того, как данные связаны между собой. Как говорил мой первый ментор: «SQL – это как конструктор LEGO. Главное – научиться собирать, а не выучить название каждого кубика».
P.S. И да, держите под рукой команду BEGIN TRANSACTION (и не забывайте про ROLLBACK). Когда-нибудь она спасёт вам жизнь. Или хотя бы работу.
Заключение
Знаете, что я понял за годы работы с данными? SQL – это не просто язык запросов, это способ мышления. Это как научиться читать – сначала мучительно складываешь буквы, а потом не замечаешь, как проглатываешь целые страницы. И точно так же, как чтение открывает перед нами целые миры, SQL открывает мир данных – со всеми его закономерностями, аномалиями и неожиданными открытиями.
Для системного аналитика владение SQL – это не просто строчка в резюме или модный навык. Это реальный инструмент, который помогает:
- Видеть картину целиком, а не отдельные пиксели
- Предотвращать проблемы до их возникновения
- Говорить на одном языке с разработчиками
- И, что немаловажно, экономить время (своё и команды)
Помните: каждый запрос, каждая спроектированная схема данных – это маленький шаг к лучшему пониманию систем, с которыми мы работаем. И если после прочтения этой статьи вы решите углубиться в мир SQL – считайте, что я свою миссию выполнил.
P.S. А если вы всё ещё сомневаетесь, стоит ли учить SQL, представьте, что вы пытаетесь собрать пазл с завязанными глазами. SQL – это возможность наконец-то прозреть и увидеть полную картину. Разве не этого мы все хотим?
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
112 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
17 марта
|
Подробнее |
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 марта
|
Подробнее |
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
112 отзывов
|
Цена
129 900 ₽
257 760 ₽
Ещё -10% по промокоду
|
От
10 825 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |

Skillbox vs ProductStar: где продакт-трек более прикладной (кейсы, метрики, решения)
Skillbox или ProductStar — где на самом деле больше практики для продакт-менеджера? Разбираем формат кейсов, работу с метриками, стажировки и портфолио, чтобы понять, какой курс действительно готовит к работе product manager.

Skypro vs ProductStar: куда идти аналитику, чтобы стать продактом — траектория и кейсы
Если вы аналитик и хотите перейти в продакт-менеджмент, но не знаете, с чего начать, эта статья для вас. Мы расскажем, какие шаги и курсы помогут вам освоить нужные навыки, чтобы успешно перейти в продуктовую роль. Задайтесь вопросом: готовы ли вы на решение проблем, а не просто на анализ данных?

Собеседование Devops Junior и Middle: актуальные вопросы и темы 2026 года
Вопросы на собеседовании DevOps могут сильно различаться в зависимости от уровня кандидата. Какие навыки и знания проверяют у Junior и Middle в 2026 году? Мы расскажем, как подготовиться к собеседованию и что важно знать для успешного прохождения интервью.

Собеседование по Python: частые вопросы и как на них отвечать
Готовитесь к техническому интервью и хотите понять, какие вопросы на собеседование Python разработчик слышит чаще всего? Разбираем реальные примеры задач, вопросы для junior, middle и senior, а также типичные ошибки кандидатов и стратегию подготовки.