Сверточные нейронные сети (CNN): что это, как работают и где применяются
Представьте: вы показываете компьютеру фотографию, а он не только говорит, что на ней изображено, но и находит мельчайшие детали, которые может пропустить человеческий глаз.

Именно такие возможности открывают сверточные нейронные сети — технология, которая за последние полтора десятилетия кардинально изменила представления о машинном зрении.
- Что такое сверточные нейронные сети (CNN)
- Как появились сверточные нейронные сети: история и прорывы
- Из чего состоят CNN — слои и их функции
- Как работают сверточные нейронные сети — пошаговый разбор
- Примеры архитектур CNN
- Где применяют сверточные нейронные сети
- Ограничения сверточных сетей
- Плюсы и минусы CNN
- Как начать работать с CNN: практические советы
- Что ждёт CNN в будущем
- Заключение
- Рекомендуем посмотреть курсы по Python для анализа данных
Что такое сверточные нейронные сети (CNN)
Представьте, что вы смотрите на фотографию кота. Ваш мозг мгновенно понимает: вот усы, вот глаза, вот характерная форма ушей — и делает вывод, что это именно кот, а не собака или хомяк. Сверточные нейронные сети (CNN) работают по похожему принципу, только гораздо медленнее и с претензией на математическую точность.
CNN — это специальный тип нейронных сетей, заточенный под анализ изображений и видео. В отличие от обычных нейросетей, которые пытаются переварить каждый пиксель картинки как отдельную переменную (что примерно как пытаться понять симфонию, анализируя каждую ноту в отрыве от остальных), сверточные сети понимают: соседние пиксели связаны между собой. Если в одном пикселе нейросеть видит часть кошачьего уха, то логично предположить, что в соседних пикселях она найдёт продолжение этого самого уха.
Сверточные нейронные сети (CNN, Convolutional Neural Networks) — класс алгоритмов глубокого обучения, специально разработанных для обработки данных с пространственной структурой, таких как изображения. Основаны на математической операции свёртки, которая позволяет выделять локальные признаки в данных.
В 2025 году CNN остаются одним из ключевых стандартов и фундаментальной технологией для задач компьютерного зрения, хотя активно конкурируют с новыми архитектурами на основе трансформеров
Как появились сверточные нейронные сети: история и прорывы
История сверточных сетей — это классическая технологическая драма с долгим периодом забвения и триумфальным возвращением. Идея витала в воздухе ещё в 1950-х годах, когда нейрофизиологи изучали, как работает зрительная кора головного мозга. Оказалось, что некоторые нейроны реагируют только на определённые паттерны — линии, углы, движение.
В 1980-х Янн Лекун создал LeNet — первую практически работающую сверточную архитектуру. Она умела распознавать рукописные цифры для почтовой службы США. Казалось бы, прорыв! Но нет — вычислительных мощностей катастрофически не хватало, а традиционные алгоритмы машинного обучения справлялись с простыми задачами не хуже.
Настоящий переворот случился в 2012 году, когда Алекс Крижевский и Джефф Хинтон из Университета Торонто представили AlexNet на конкурсе ImageNet. Их нейросеть снизила количество ошибок распознавания с 26% до 15% — почти в два раза! Это был момент, когда индустрия поняла: игра изменилась навсегда.
Ключевые вехи:
- 1950-60е: Изучение зрительной коры мозга.
- 1980е: LeNet от Янна Лекуна.
- 2012: Прорыв AlexNet на ImageNet.
- 2012-2025: CNN становятся стандартом компьютерного зрения.
С тех пор каждый год приносил новые архитектуры, каждая из которых была «революционнее» предыдущей, пока трансформеры не начали теснить CNN даже в их родной стихии.
Из чего состоят CNN — слои и их функции
Сверточная нейросеть — это такая слоёная технологическая выпечка, где каждый слой выполняет свою строго определённую функцию. Правда, в отличие от торта, здесь нельзя просто взять и съесть самый вкусный кусочек — всё работает только в комплексе.
Сверточный слой
Это сердце всей архитектуры. Представьте детектив, который изучает место преступления через увеличительное стекло, методично перемещаясь по каждому сантиметру. Сверточный слой работает похожим образом — он использует небольшие фильтры (обычно размером 3×3 пикселя), которые «сканируют» изображение в поисках определённых признаков.
Каждый фильтр — это матрица весов, которая учится распознавать конкретные паттерны: вертикальные линии, горизонтальные границы, углы. Фильтр накладывается на участок изображения, перемножает значения пикселей на свои веса, суммирует результат и записывает одно число в выходную карту признаков. Затем сдвигается на один пиксель и повторяет операцию.
Слой подвыборки (Pooling)
После того как сверточный слой наплодил кучу карт признаков, нужно как-то уменьшить объём данных — иначе даже самый мощный компьютер захлебнётся в вычислениях. Здесь на сцену выходит pooling, который работает как безжалостный редактор, оставляющий только самое важное.
MaxPooling берёт окно размером, скажем, 2×2 пикселя и оставляет только максимальное значение из четырёх. AveragePooling действует мягче — усредняет все значения в окне. Результат: размер изображения уменьшается в четыре раза, но самые важные признаки сохраняются.
Полносвязные слои (Dense)
В конце концов, всю эту красоту из карт признаков нужно превратить в конкретный ответ: «кот» или «собака», «злокачественная опухоль» или «всё в порядке». Полносвязные слои работают как традиционная нейросеть — каждый нейрон соединён со всеми нейронами предыдущего слоя и принимает финальное решение.
Дополнительные элементы
Batch Normalization — это такой внутренний стабилизатор, который следит, чтобы значения между слоями не улетали в космос и не падали в ноль. Dropout случайно «отключает» часть нейронов во время обучения — звучит контринтуитивно, но помогает сети не запоминать тренировочные данные наизусть, а учиться обобщать.
| Слой | Задача | Что происходит |
| Свёрточный | Выделение признаков | Фильтры ищут паттерны |
| Pooling | Уменьшение размерности | Сжимает данные, сохраняя главное |
| Dense | Классификация | Принимает финальное решение |
| Batch Norm | Стабилизация | Нормализует значения между слоями |
| Dropout | Регуляризация | Предотвращает переобучение |
Как работают сверточные нейронные сети — пошаговый разбор
Теперь давайте проследим весь путь от загрузки картинки до получения ответа «это определённо кот» — или, что более вероятно в реальности, «это кот с вероятностью 73,2%».
Подготовка данных
Компьютер, как известно, понимает только числа. Поэтому первым делом нашу красивую фотографию кота нужно превратить в трёхмерный массив чисел — тензор. Каждый пиксель цветного изображения представляется тремя числами от 0 до 255: интенсивность красного, зелёного и синего каналов (RGB).
Получается что-то вроде многослойного бутерброда: красный канал — это одна матрица чисел, зелёный — вторая, синий — третья. Для изображения 224×224 пикселя мы получим тензор размером 224×224×3. Черно-белые изображения проще — там всего один канал.
Но это ещё не всё. Нейросеть капризна и требует, чтобы все изображения были одного размера. Поэтому фотографии приходится масштабировать, обрезать или дополнять до стандартного формата.
Обработка фильтрами (свёртка)
А теперь начинается магия. Представьте, что у вас есть фильтр размером 3×3, который «умеет» находить вертикальные линии. Этот фильтр последовательно накладывается на каждый участок изображения размером 3×3 пикселя.
Пример операции свёртки:
Участок изображения: Фильтр: Результат:
(1*1) + (2*0) + (1*(-1)) = 1 + 0 — 1 = 0
(0*1) + (1*0) + (2*(-1)) = 0 + 0 — 2 = -2
(1*1) + (0*0) + (1*(-1)) = 1 + 0 — 1 = 0
Итоговый результат: 0 + (-2) + 0 = -2
Фильтр перемножает свои веса на значения пикселей, складывает результаты и записывает одно число в выходную карту признаков. Затем сдвигается на один пиксель вправо и повторяет операцию. Дошёл до края — переходит на следующую строку.операция свёртки
Иллюстрация демонстрирует, как работает свёртка: фильтр 3×3 последовательно перемножается с фрагментами изображения. В результате получается новое значение, которое отражает наличие искомого признака, например — вертикальной границы.
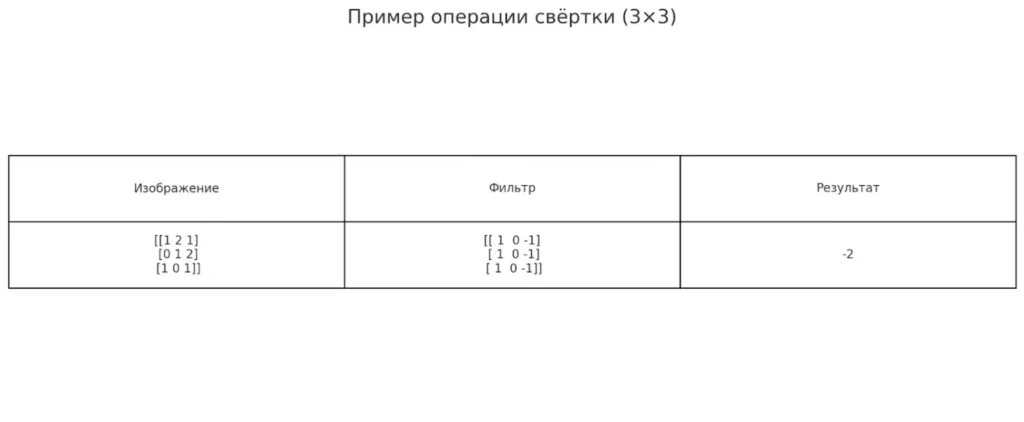
Иллюстрация демонстрирует, как работает свёртка: фильтр 3×3 последовательно перемножается с фрагментами изображения. В результате получается новое значение, которое отражает наличие искомого признака, например — вертикальной грани
Снижение размерности (Pooling)
После свёртки у нас появилась куча карт признаков, каждая из которых выделяет что-то своё: одна находит горизонтальные линии, другая — углы, третья — круглые формы. Но данных стало слишком много, и компьютер начинает задыхаться.
MaxPooling решает проблему радикально: берёт окно 2×2 и оставляет только самое большое значение из четырёх. Логика простая — если нейрон сильно активировался, значит, он что-то важное нашёл. Слабые активации можно смело выбросить.
Классификация и выходные слои
В конце этого технологического конвейера все карты признаков разворачиваются в один длинный вектор и подаются на полносвязные слои. Здесь происходит финальный анализ: нейросеть смотрит на комбинации найденных признаков и выносит вердикт.
Последний слой обычно содержит столько нейронов, сколько у нас классов (кот, собака, хомяк, инопланетянин). Функция активации softmax превращает выходные значения в вероятности, которые в сумме дают 100%. И вот мы получаем долгожданный ответ: «Кот — 73,2%, собака — 15,1%, хомяк — 11,7%».
Примеры архитектур CNN
За десятилетия развития сверточных сетей человечество наплодило такое количество архитектур, что разобраться в них стало отдельной профессией. Каждая новая модель обещала стать «революционной» и «превзойти все предыдущие результаты» — что, честно говоря, довольно часто и происходило.
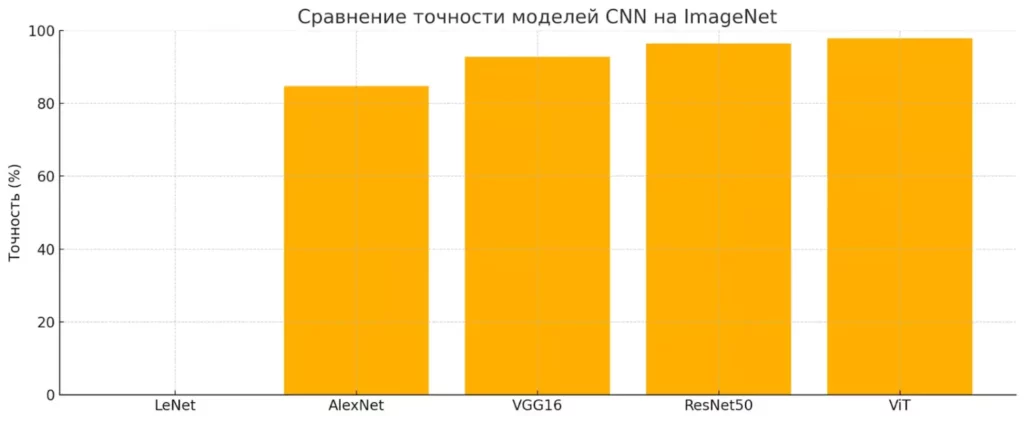
На диаграмме показана точность различных моделей сверточных нейронных сетей на датасете ImageNet. Видно, как архитектуры постепенно улучшались — от нуля у LeNet (MNIST) до почти 98% у Vision Transformer.
Классические модели
LeNet (1989) — динозавр среди CNN, но динозавр уважаемый. Янн Лекун создал её для распознавания рукописных цифр, и она честно трудилась в американской почтовой службе, сортируя письма. Архитектура простая как топор: пара сверточных слоёв, пулинг, полносвязные слои — и готово.
AlexNet (2012) — та самая сеть, которая всё изменила. По сути, это LeNet на стероидах: больше слоёв, больше фильтров, больше параметров. Плюс пара технических новшеств вроде ReLU активации и dropout. Результат — историческая победа на ImageNet и начало эры глубокого обучения.
VGG (2014) — британский ответ на американское доминирование. Команда из Оксфорда решила: «А что если просто наделать очень много маленьких сверточных слоёв?» Получилось элегантно и эффективно. VGG16 и VGG19 до сих пор используют как основу для transfer learning.
Современные варианты
ResNet (2015) — настоящий прорыв в архитектурном мышлении. Microsoft Research решил проблему исчезающих градиентов с помощью «остаточных соединений» — skip connections. Теперь информация могла «перепрыгивать» через слои, что позволило строить сети глубиной в сотни слоёв.
Inception (2014) — Google показал, что можно думать не только в глубину, но и в ширину. Вместо одного типа фильтров на каждом слое они применяли несколько разных параллельно: 1×1, 3×3, 5×5. Получилось что-то вроде «швейцарского ножа» для признаков.
Модели с трансформерами — самый горячий тренд последних лет. Vision Transformer (ViT) разрезает изображение на патчи и обрабатывает их как последовательность, словно это предложение из слов. Звучит безумно, но работает порой лучше классических CNN.
| Модель | Год | Особенность | Точность ImageNet |
| LeNet | 1989 | Первая практичная CNN | Только MNIST |
| AlexNet | 2012 | Прорыв в глубоком обучении | 84.7% |
| VGG16 | 2014 | Много маленьких фильтров | 92.7% |
| ResNet50 | 2015 | Skip connections | ~93% |
| Vision Transformer | 2020 | Трансформеры для изображений | 97.8% |
Каждая архитектура — это попытка решить определённую проблему: увеличить точность, уменьшить количество параметров, ускорить обучение или улучшить интерпретируемость результатов.
Где применяют сверточные нейронные сети
Сверточные сети проникли практически везде, где есть хоть какие-то изображения для анализа. И даже туда, где их, казалось бы, быть не должно — но об этом чуть позже.
Основные сферы
Компьютерное зрение — родная стихия CNN. Здесь они классифицируют объекты, детектируют лица, сегментируют изображения на части и решают тысячи других задач. От банального «найти все фотографии с котами в Google Photos» до сложного анализа спутниковых снимков для мониторинга лесных пожаров.
Медицина стала одной из самых перспективных областей применения. CNN анализируют рентгеновские снимки, МРТ-изображения, результаты КТ — и часто находят патологии, которые пропустил человеческий глаз. Особенно впечатляют результаты в дерматологии: в ряде исследований нейросети показывают точность в диагностике меланомы по фотографиям, сравнимую или превосходящую средние показатели врачей-дерматологов.
Автопилоты и беспилотники — здесь CNN работают в режиме реального времени, анализируя видеопоток с камер. Распознают дорожные знаки, разметку, пешеходов, другие автомобили. Яндекс.Такси, Tesla, Waymo — все используют сверточные сети как основу своих систем компьютерного зрения.
Распознавание лиц и документов — от разблокировки смартфона до автоматической обработки паспортов в аэропортах. Точность современных систем достигает 99,8%, что выше, чем у среднего человека при распознавании лиц в толпе.
Генерация изображений — тот самый Midjourney, DALL-E, Stable Diffusion. Здесь CNN работают «в обратную сторону»: не анализируют изображения, а создают их с нуля на основе текстового описания. Правда, в современных генеративных моделях сверточные сети часто комбинируются с трансформерами, но архитектурная основа остаётся.
Нетипичные применения
А вот здесь становится интересно. Оказывается, CNN можно адаптировать для работы с данными, которые совсем не похожи на изображения.
1D CNN для текста — если развернуть предложение в одну строку и представить каждое слово как вектор, получится что-то вроде «одномерного изображения». Такие сети неплохо справляются с анализом тональности текстов и классификацией документов.
Анализ временных рядов — биржевые котировки, показания датчиков, медицинские кардиограммы. Если нарисовать график, получится изображение, которое можно скормить обычной CNN. Иногда это работает удивительно хорошо.
Аудио-обработка — звук можно превратить в спектрограмму (визуальное представление частот), и вот уже CNN может распознавать речь, классифицировать музыкальные жанры или детектировать аномальные звуки в промышленном оборудовании.
Кто бы мог подумать, что архитектура, созданная для анализа фотографий кошек, окажется настолько универсальной инструментом для работы с паттернами в данных любого типа?
Ограничения сверточных сетей
Несмотря на весь этот технологический восторг, CNN — далеко не панацея от всех проблем машинного обучения. У них есть вполне конкретные ограничения, которые иногда превращают жизнь разработчика в увлекательную головоломку «как же это обойти».
Проблемы с последовательными данными — главная ахиллесова пята сверточных сетей. Они прекрасно понимают пространственные связи (соседние пиксели связаны между собой), но совершенно теряются в временных зависимостях. Попробуйте скормить CNN текст — и получите результат уровня «понял что-то, но не очень понятно что».
Для анализа текстов, где важен контекст между словами, разделёнными десятками других слов, CNN подходят как корове седло. Здесь нужны рекуррентные сети или трансформеры, которые умеют «помнить» информацию на больших дистанциях.
Чувствительность к размеру входных данных — ещё одна болевая точка. Обучили сеть на изображениях 224×224 пикселя? Отлично! А теперь попробуйте подать ей картинку 150×300 — и она растеряется как первоклассник на экзамене по высшей математике.
Это особенно критично при работе с документами разного формата: A3, A4, A5 — для CNN это три совершенно разных мира, даже если текст на всех документах абсолютно идентичный.
Требовательность к ресурсам — современные сверточные сети прожорливы как подросток в период роста. Обучение больших моделей требует мощных GPU, терабайты данных и недели вычислений. И это только обучение — инференс тоже может быть ресурсоёмким, особенно для задач реального времени.
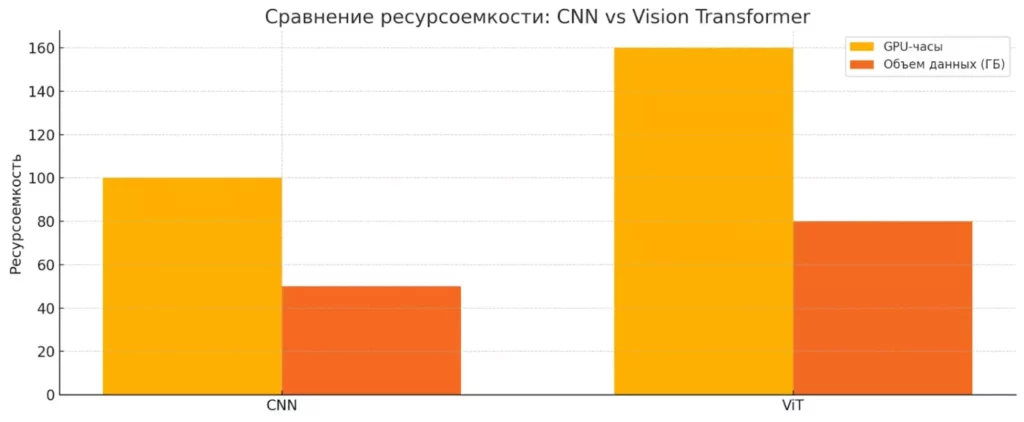
Диаграмма показывает, насколько ресурсоемкими могут быть современные нейросетевые архитектуры. Vision Transformer требует больше GPU-времени и данных по сравнению с классической CNN, что делает проблему оптимизации особенно актуальной.
Плюсы и минусы CNN
Плюсы:
- Отлично работают с изображениями и видео.
- Автоматически выделяют признаки.
- Инвариантны к сдвигам объектов.
- Эффективнее полносвязных сетей за счёт разделения весов.
Минусы:
- Плохо обрабатывают последовательности.
- Чувствительны к размеру входных данных.
- Требовательны к вычислительным ресурсам.
- Нужны большие объёмы данных для обучения.
Кажется, в каждой технологии есть своя ложка дёгтя. Но понимание ограничений — это половина успеха в выборе правильного инструмента для конкретной задачи.
Как начать работать с CNN: практические советы
Итак, вы прочитали всё вышенаписанное и подумали: «Звучит интересно, хочу попробовать!» Прекрасно. Только не ждите, что через неделю вы будете создавать собственный аналог GPT-4 для изображений. Путь к просветлению в области сверточных сетей тернист, но вполне проходим.
Минимальный стек для новичков
Python — альфа и омега современного машинного обучения. Если вы до сих пор пишете на Pascal или решили, что JavaScript подойдёт для нейросетей, у меня для вас плохие новости. Да, теоретически можно использовать R, Julia или даже C++, но зачем усложнять себе жизнь, когда есть Python с его богатейшей экосистемой?
TensorFlow или PyTorch — две основные библиотеки для глубокого обучения, между которыми идёт вечная холодная война. TensorFlow и PyTorch — две самые популярные библиотеки, предлагающие мощные инструменты как для исследований, так и для внедрения моделей в реальные продукты. Выбирайте любой — в 90% случаев разницы не почувствуете.
OpenCV — швейцарский нож для работы с изображениями. Загрузить картинку, изменить размер, применить фильтры, сделать предобработку — всё это OpenCV. Без него в компьютерном зрении делать нечего.
Что нужно знать из математики
Линейная алгебра — основа основ. Матрицы, векторы, операции над ними. Особенно важно понимать операцию свёртки на интуитивном уровне: как фильтр накладывается на изображение, что происходит с размерностями, почему результат получается именно такой.
Основы градиентного спуска — как нейросеть учится, что такое функция потерь, зачем нужно обратное распространение ошибки. Необязательно выводить формулы с нуля, но понимать общий принцип критично важно. Иначе вы будете как автомеханик, который не знает, как работает двигатель внутреннего сгорания.
Статистика тоже пригодится — понимание распределений, overfitting’а, cross-validation’а поможет избежать классических ошибок новичков.
Где учиться дальше
Fast.ai — более практико-ориентированный подход. Сначала показывают, как заставить работать, а потом объясняют, почему это работает.
Kaggle — платформа для соревнований по машинному обучению. Здесь можно попрактиковаться на реальных задачах, посмотреть решения других участников, украсть пару идей (это нормально в ML!).
Google Colab — бесплатные GPU в облаке для экспериментов. Можете не покупать дорогую железку, а арендовать вычислительные мощности на время обучения моделей.
Начните с простого: возьмите готовый датасет (тот же MNIST с рукописными цифрами), загрузите в Google Colab, скачайте чужой код с GitHub и попробуйте запустить. Сломается — отлично! Починка чужого кода учит лучше любых учебников.
Что ждёт CNN в будущем
Предсказывать будущее в IT — дело неблагодарное. Ещё пять лет назад никто не мог предположить, что трансформеры захватят не только обработку текста, но и начнут теснить сверточные сети в их родной стихии — компьютерном зрении. Но попробуем заглянуть за горизонт и понять, куда движутся CNN.
Слияние с трансформерами — самый очевидный тренд. Vision Transformer уже показал, что архитектура «внимания» может работать с изображениями не хуже классических свёрток. Но зачем выбирать что-то одно? Гибридные модели, которые используют сильные стороны обеих архитектур, становятся всё популярнее. CNN отлично выделяют локальные признаки, трансформеры хорошо улавливают глобальные зависимости — почему бы не объединить?
Новые архитектуры появляются с завидной регулярностью. EfficientNet, RegNet, ConvNeXt — каждая обещает стать «следующим прорывом». В основном усилия направлены на поиск оптимального баланса между точностью, скоростью и потреблением ресурсов. Потому что хорошо, когда модель выдаёт 99% точности, но не очень хорошо, когда для этого нужна ферма из тысячи GPU.
Оптимизация скорости обучения — головная боль всей индустрии. Обучение современных моделей занимает недели и стоит десятки тысяч долларов. Исследователи работают над более эффективными алгоритмами оптимизации, лучшими стратегиями инициализации весов, умным использованием transfer learning’а. Цель — получить приемлемый результат за часы, а не месяцы.
Применение в новых сферах — CNN постепенно проникают туда, где их раньше и не ждали. Анализ молекулярных структур в химии, обработка геологических данных, даже финансовая аналитика — везде, где есть паттерны, которые можно «увидеть», найдётся место для сверточных сетей.
Основные тренды:
- Гибридные CNN+Transformer архитектуры.
- Автоматическое проектирование архитектур (Neural Architecture Search).
- Более эффективные методы обучения с меньшими данными.
- Edge computing — запуск моделей на мобильных устройствах.
- Федеративное обучение для приватности данных.
Одно можно сказать точно: похороны CNN пока откладываются. Да, трансформеры наступают, но сверточные сети адаптируются, эволюционируют и находят новые ниши. В конце концов, инструмент, который так хорошо понимает пространственные зависимости, вряд ли исчезнет в мире, где данных с пространственной структурой становится всё больше.
Заключение
Время подводить итоги нашего путешествия по миру сверточных нейронных сетей — технологии, которая за последние пятнадцать лет перевернула представления о том, что компьютеры могут делать с изображениями. Подведем итоги:
- Сверточные сети — это мощный инструмент анализа изображений. Они имитируют работу зрительной системы человека.
- Основные элементы CNN — свёрточные, pooling и полносвязные слои. Каждый из них выполняет конкретную задачу в обработке данных.
- CNN нашли применение в медицине, автопилотах, генерации изображений и других областях. Их используют, когда важен анализ визуальных паттернов.
- У технологии есть ограничения: ресурсоёмкость, чувствительность к размеру входа и слабая работа с последовательностями. Это важно учитывать при выборе архитектуры.
- Чтобы освоить CNN, нужны Python, библиотеки PyTorch/TensorFlow и понимание линейной алгебры. Практика через Kaggle и Colab — лучший старт.
Если вы только начинаете осваивать профессию аналитика данных, рекомендуем обратить внимание на подборку курсов по анализу данных на Python. В них собраны теоретические материалы и практические задания для уверенного старта.
Рекомендуем посмотреть курсы по Python для анализа данных
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Аналитик данных
|
Eduson Academy
112 отзывов
|
Цена
125 900 ₽
|
От
10 492 ₽/мес
На 1 год.
5 686 ₽/мес
|
Длительность
6 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Python для анализа данных
|
Нетология
46 отзывов
|
Цена
45 800 ₽
84 737 ₽
с промокодом kursy-online
|
От
2 824 ₽/мес
4 116 ₽/мес
|
Длительность
4 месяца
|
Старт
22 марта
|
Подробнее |
|
Курс Аналитик данных
|
Karpov.Courses
75 отзывов
|
Цена
96 700 ₽
135 800 ₽
|
От
5 658 ₽/мес
|
Длительность
5 месяцев
|
Старт
26 марта
|
Подробнее |
|
Apache Airflow для аналитика
|
Stepik
33 отзыва
|
Цена
4 490 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Аналитик данных с нуля
|
Skillbox
226 отзывов
|
Цена
126 751 ₽
253 503 ₽
Ещё -20% по промокоду
|
От
5 761 ₽/мес
Без переплат на 22 месяца.
|
Длительность
6 месяцев
|
Старт
11 марта
|
Подробнее |

Вопросы и задачи на собеседовании по Java в 2026 году: полный гид
Собеседование на позицию java разработчик собеседование сегодня включает не только вопросы по синтаксису языка. Какие темы проверяют, какие задачи дают и как подготовиться к интервью по Java — разбираем ключевые блоки, типовые вопросы и практические советы.

Skypro vs Karpov.Courses: где проще освоить A/B и статистику без боли
Курсы A/B-тестирования обещают научить работать с экспериментами и статистикой, но форматы обучения могут сильно отличаться. Какая программа подойдет новичкам, а какой курс лучше выбрать специалистам с опытом? В статье разбираем ключевые критерии выбора и базовые принципы экспериментов.

Яндекс Практикум vs Eduson Academy: project management — где больше инструментов и симуляций
Выбираете курсы по управлению проектами и пытаетесь понять, где больше практики, инструментов и реального опыта работы? В этом материале разбираем программы Яндекс Практикума и Eduson Academy: какие навыки вы получите, какие инструменты освоите и какой формат обучения подойдёт именно вам.

Skillbox vs Eduson Academy: менеджер маркетплейсов — где больше шаблонов и прикладных задач
Курсы менеджера маркетплейсов обещают практику, шаблоны и быстрый старт, но что из этого действительно работает? Разбираем, как проверить программу до оплаты и выбрать обучение под свою цель.